3rd Prize Approach of The 4th Tellus Satellite Challenge
This article was contributed by citron, the 3rd place winner of the 4th Tellus Satellite Challenge.
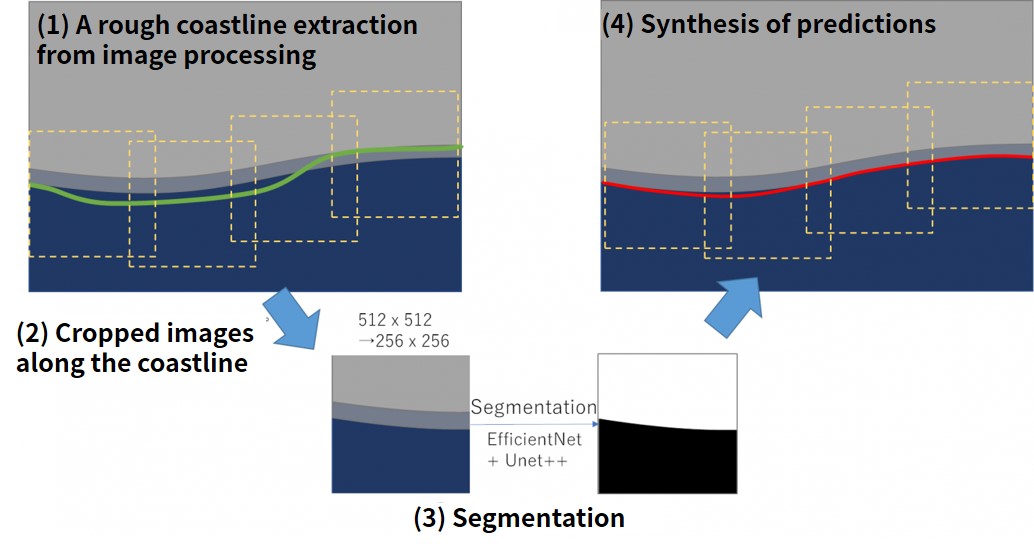
Preprocessing
What is the point of preprocessing?
All the original data has the same resolution, but since it was a dataset with variations in image size, it was necessary to crop images to the same image size and edit. Our team first adopted the image processing approach to roughly extract the coastline and then crop the image near the coastline along this line. In this way, the input image should be limited to the area near the coastline during segmentation and less affected by the missing area, which should facilitate learning.
The data was converted to 8bit for ease of handling and was treated as a grayscale image. The original data is a 32-bit image, but when I looked up the information, most of it was in the 16-bit range (0 to 65535), and some of the missing values were out of range (65536). All of these missing values were treated as 0, and after they were considered 16-bit images, preprocessing was done to convert only the information in a certain range to 8 bits.
I thought this preprocessing was most important and tried various patterns. I thought that the following two patterns would work.
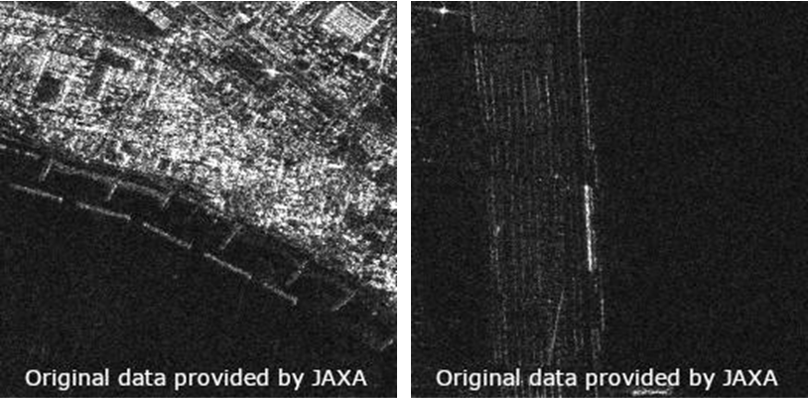
1. Crop the entire image after linear transformation to 8bit in a specific range
After limiting the brightness range (contrast conversion), the range was linearly set to 8-bit for 16-bit images.
In the data (shown on the left) where the brightness difference between land and sea is clear, you can see the coastline beautifully. However, with this method, in the data (shown on the right) where the difference in brightness between the land and the sea is small, both the sea and the land sometimes become pitch black.
2. Crop the 32-bit image and then convert it to 8-bit with gamma correction
Since the brightness range is different for each image, I thought it would be easier to see the difference between the coastline and the land by making adjustments for each cropped area. Therefore, we chose the method of applying gamma correction to each cropped area to create a difference in brightness.
As you can see in the image on the left, there were cases where the coastal information was lost, but in the case on the right, the difference between land and sea is more obvious than with the method used in 1.

We adopted method 1, which had a good score in the preliminary evaluation. However, in the final evaluation, we found that we could also achieve a significant improvement with method 2, and so we thought we could have improved this method even more if we had adopted method 2 or both.
Learning
What is the reason behind choosing this model?
The following is a summary of the techniques used in the model we created:
– Efficientnetb5 + Unet ++
– Use of labels, Land (1) Sea (0), manually modified, based on the correct coastline
– Training image resized to 512×512 after cropping based on the correct coastline and evaluation line 216×216
– Random motion and rotation cropping
– Salt-and-pepper noise, random deletion, random flipping.
The following image is a graph of point trends. The vertical axis is the score, and the horizontal axis is the number of posts.
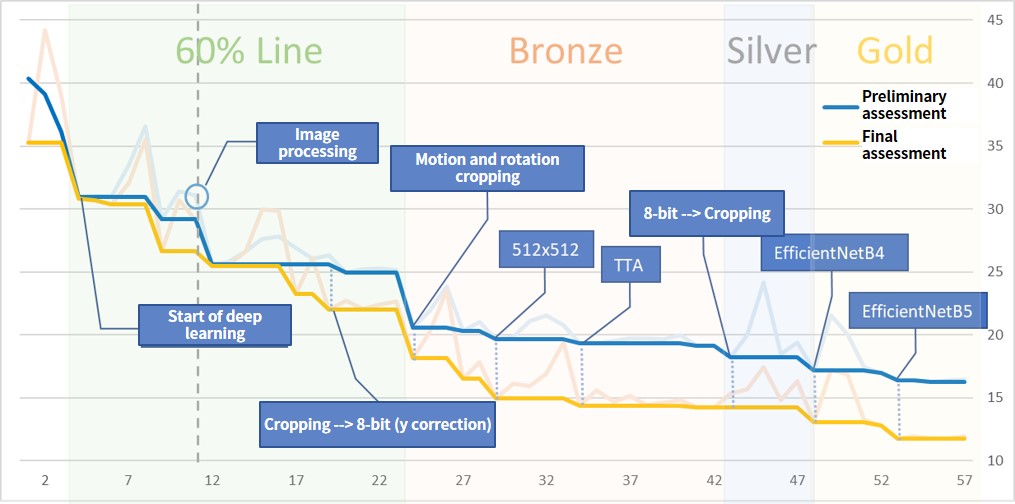
Of course, we repeated the experiment and checked the effect of each method by making only one change per experiment.
The model was created to segment the images around the coast into land and sea. The input image was cropped to 512×512 and scaled down to 256×256 based on the correct line for training and the coastline through image processing for testing. We originally cropped the image to 256×256 and used it at that size, but with a narrow field of view it seemed difficult to distinguish the coastline from the breakwater in some images. We also applied motion and rotation when cropping to increase the amount of data.
The labels are based on the correct coastline, which I manually modified and drew in land and sea.
For the network we chose UNet++, which is standard for segmentation tasks. For data enrichment with generators, we used sesame salt noise, random deletion, and random flipping, but the loss values in the validation data showed a strong tendency toward overtraining. However, the results were good when presented as test data, so we used them as is.
Initially, we used the trained ResNet18 for transfer learning, repeatedly checked pre-processing and post-processing, and switched to EfficientNet after pre-processing and post-processing were reasonably consolidated. EfficientNet tried B4 and B5, but the model with B5 that performed well was chosen as the final model.
Post-processing
What did we look for in the post-learning phase?
For prediction, we used cropped images based on the coastline extracted by image processing.
In this model, the predictions varied depending on the extent and direction of the cropping even for the same location. Therefore, we specified a certain overlap in the cropping. The larger the overlap, the better the accuracy. In addition, we performed TTA on images flipped on the x-, y-, and xy-axes and averaged each prediction.
The resulting predictions near the coast were binarized, and the edges were used as the final coastline.
While learning did not go well, prediction accuracy near the frame of each harvest image was poor, but after switching to EfficientNet, prediction values near the frame became stable. In this problem, I think we should have considered the padding method of the segmentation model.
Conclusion
We used 8-bit conversion to make the depth deeper and easier to handle than ordinary optical images, but it was both difficult and interesting to see how much the results depended on the preprocessing.
We hope this achievement is of some help to you.
Books and websites we referred to when entering this contest.
The 4th Tellus Satellite Challenge is now underway! The theme is “coastline extraction.”
https://sorabatake.jp/14130
