The First Satellite Data Analysis Contest Report -The answers and what to look forward in the 2nd Challenge
We are glad to share the feedback on the 1st Tellus Satellite Challenge, the satellite data analysis competition, from Shu Saito, CEO of SIGNATE Inc. operator of the contests.
This article was written in collaboration with:Shu Saito (SIGNATE), Akira Mukaida (RESTEC)
We are glad to share the feedback on the 1st Tellus Satellite Challenge, the satellite data analysis competition, from Shu Saito, CEO of SIGNATE Inc. operator of the contests.
(1) Tellus Satellite Challenge - Who We Are and Our Goals
Tellus is a satellite data platform that allows industrial use of satellite data.
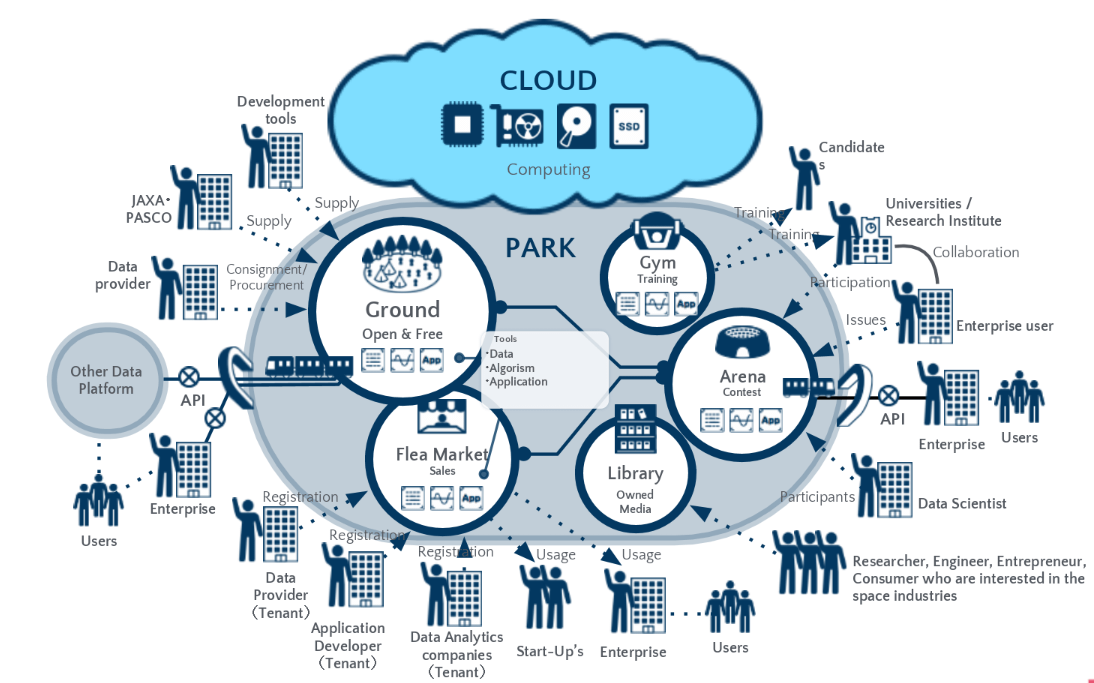
As a part of our Tellus projects, we host Tellus Satellite Challenge, a data analysis competition. Our initiative is to promote the use of Tellus by visualizing examples of satellite data usage, finding talented data scientists, and raising awareness to educate users about satellite data.
(2)The First Competition’s Challenge
The goal of the first contest was to detect landslides using Synthetic Aperture Radar (SAR) data.
We used pairs of images that were generated before and after an earthquake, as in the diagram below.

Out of 380,000 images, we provided contestants 250,000 labelled images as training data, and the remaining 130,000 images as validation data. The contestants were asked to interpret each of these validation data to see if they included landslides and these results were subsequently scored with IoU (Intersection over Union), for accuracy of their interpretation.
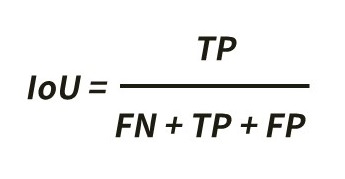
The above formula shows how to calculate IoU. The following explains what these abbreviations stand for and mean.
● TP (True Positive)= the number of the images they correctly interpreted the landslide image as landslide
● FN(False Negative)= the number of the landslide images they failed to interpret correctly (oversight)
● FP (False Positive)= the number of non-landslide images they mistakenly interpreted as landslide (mistake)
When one gives perfect answers, IoU will be 1.0. If FN or FP increase in denominator, the score will be smaller. This method of evaluation will allow us to penalize any oversights or mistakes. IoU of the top winner in this competition was 0.303.
(3) Results of the Competition
We will evaluate the results of this contest from two perspectives: technical and practical.
From the Technical Point of View
First of all, “the true data” containing landslides in this competition were manually labelled based on human interpretation of the aerial photographs taken by the Geospatial Information Authority of Japan. Consequently they include things that would be invisible in satellite data, especially SAR.
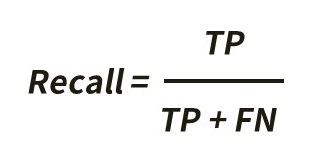
We used Recall, the formula shown below, to calculate how much the contestants were able to interpret from satellite data.
The proportion of data containing landslides, among all of the provided data, was around 0.6%. In machine learning, the smaller this proportion is, the more difficult the problem will be. Just like the old saying, it is like “looking for a needle in a haystack.”
The winning model’s recall score (the percentage of the images they correctly interpreted the landslide image as landslide) was 57%. In other words, this model correctly detected 57% of the landslides in the validation data. This numerical value could vary depending on which satellite data were used, but regardless it is not far from the interpretation done by alternative human experts.
From Practical Point of View
Now, if we put ourselves into the data users’ shoes, we can consider Precision, using the formula shown below.
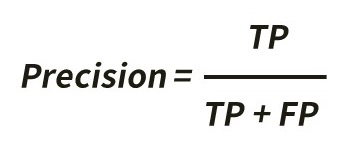
By looking at the precision score, we can see 39% of the data the winning model predicted as landslides would be actual landslides. In other words, around 40% of their predictions would detect real landslides.
If an expert interpreted the entire image manually, it would take about an hour. But what is excellent about these algorithms presented by the winners were that they would allow us to automate the interpretation process, so we can rapidly make a firm prediction on where landslides have occurred without having a large number of professionals do so in a time of natural disaster.
(4)Analysis of the Top three Models
We have summarized the analysis techniques used by the top three contestants in the diagram below.

First, we would like to mention their models were surprisingly similar to one another.
We are going to walk you through by breaking them down into three parts.
【Pre-processing】
All the top three contestants reconstructed the smaller images into a larger image, which they then processed.
Because landslides could occur in many sizes, some of them could span more than one segmented image. We could say that the method they used was appropriate.
【Their Models】
Each of them used Deep Learning models. Also, the true cases of landslides make up only 0.6% of all data. So, if we had the model learn the data as it is, it would end up identifying that not all the data are landslides. That is why these participants adjusted the ratio of true cases and error cases that they are giving to the model by increasing true cases with manually edited ones.
【Post-Processing】
Based on several images generated as part of pre-processing, each of the top three winners has built various Deep Learning models and calculated the average of the precision and used it as their final prediction. This kind of approach is called Ensemble Learning.
(5)What We Learned
●Can we combine different types of satellite data?
We provided optical satellite data along with SAR data in this contest to see if combining different kinds of satellite data could benefit. However, the contestants reported us that this did not contribute to improving accuracy.
●Algorithm’s Best Practices found in the Contest
As we saw a significant similarity in the winners’ techniques, we are now more confident that we can discover the best practice of algorithm that would allow us to make the most of what satellite data has to offer through these competitions.
Furthermore by sharing our knowledge with a broader audience through these competitions, we will continue to contribute to removing technical barriers related to satellite data and create momentum for the industrial use of satellite data from Tellus.
(6)What to look forward at the next Tellus Satellite Challenge
In our first competition, we utilized SAR data. Although SAR data, unlike optical satellite data, is observable regardless of weather conditions such as clouds, we still have a long way to go to make SAR data accessible to everyone, not just satellite experts.
In the second competition, we are introducing optical satellite data, used often in Google Maps and such. This type of data should be easy to handle for engineers who are familiar with image recognition.
The challenge in the second contest will be to detect vessels on the surface. Monitoring activity of ships on the water will enable us to apply this technology to industries such as marine transportation and fisheries, and ensure the safety and security of the sea area.
ASNARO-1, the satellite we are using in this contest provides high-resolution optical images. We are hoping that it will allow the contestants to identify if a vessel is in motion and what kind of vessel it is.
With the techniques that we will discover in the second contest, we are looking to develop a model that can detect the type or registry of the ships to apply the techniques to many other applications.
