Super-Resolution Processing of Satellite Images Using Sharp’s Deep Learning Model
Super-resolution is a technique to artificially raise the resolution of an image. Super-resolution is one of the hot topics in the field of machine learning, but what happens when you combine it with satellite imagery? We went to the Sharp Corporation Research and Development HQ, and asked the manager of the 3rd Research Team for Communication & Image Technology Laboratories, Tomohiro Ikai, and researcher, Eiichi Sasaki about the future of this technology.
The Sharp Corporation is a participant in the xData Alliance, working together with Sakura Internet to make progress in satellite data application. This article looks at satellite super-resolution imagery made with machine learning as a part of the framework for the alliance.
Super-resolution is a technique to artificially raise the resolution of an image.


Super-resolution is one of the hot topics in the field of machine learning, but what happens when you combine it with satellite imagery? We went to the Sharp Corporation (referred to below as “Sharp”) Research and Development HQ, and asked the manager of the 3rd Research Team for Communication & Image Technology Laboratories, Tomohiro Ikai, and researcher, Eiichi Sasaki about the future of this technology.
(1) Sharp and Super-Resolution
– What brought Sharp to start doing research on super-resolution technology?
Mr. Sasaki:
When talking about our company, the first keyword that pops up right now is 8k. The birth of this keyword started with our LCD (TV) business but has extended beyond display screens to include creating an ecosystem around 8k for things like images and transmission. Another big word right now is the cross between AI and IoT, “AIoT”, which is currently growing into a new business.
For example, if you were to try and watch TV with an airborne signal, 8k broadcasts are limited to certain programs ran by certain channels, so an upconverter (*1) is required when displaying a full HD video or a 4K video.
Even if you wanted to watch 8k programs, there isn’t enough content being made in 8k right now, so finding a way to make regular content look like 8k is where “super-resolution” comes into play.
*1: A device that artificially increases insufficient resolution.
– Do you both specialize in machine learning?
Mr. Ikai:
What we originally worked with was less about machine learning and more about general image-processing, about how to efficiently transfer images to be displayed in high quality, but for the past three years we have shifted the focus of our research to deep learning after learning how effective it is for image processing.
The fact of the matter is that if there were 100 parameters, it would be better to fine-tune them manually, but when these numbers climb to 10,000, or say, 1,000,000, deep learning is far superior.
(2) Background - A Match Made in Heaven: Super-Resolution and Satellite Images?
– What brought you to test super resolution with satellite imagery?
Mr. Sasaki:
“Big data” has been a major keyword for the past few years, and there has been a trend for companies to make use of the many kinds of data that exist around the world. This trend hit our company as well, and satellites offered a kind of big data that really caught our interest.
Mr. Ikai:
We had a chance to speak with Tellus, and when we asked them what they thought about collaborating with Sharp, we found there was room for synergy with research we had been doing on high-resolution imagery.
– What was your first impression of satellite imagery?
Mr. Ikai:
In order to meet the full potential of super-resolution and deep learning, it is important to have a large volume of data.
Especially for research on super-resolution when working on faces, we knew that having large quantities of data on a particular category of the picture goes a really long way.
For maps and pictures of the sea and sky, even with satellite images, if we could make super-resolution categories for these kinds of pictures, we strongly believe that we could accurately pick out objects from them.
Being able to more accurately produce images leads to a direct increase in what objects can be extracted, which led us to believe that super-resolution and satellite imagery are a match made in heaven.
(3) Algorithm Overview - The Super-Resolution Model is Good for Complex Images

– Please teach us your requirements for super-resolution satellite imagery.
Mr. Sasaki: This time we used 15 high-resolution satellite images taken by IKONOS at a resolution of 3 m, and used low-resolution images taken by the AVNIR-2 at a resolution of 10m as our teacher data, pairing them together to make super-resolution images. Our goal is to make the pictures aesthetically pleasing for a person to look at.
When it comes to super-resolution, if you are able to use RGB when you are only trying to increase the brightness, it increases the image’s functionality, so this time we used RGB as input images. Previous research [1] [2] also used those, so we try to use 3 colors on top of brightness for the color component.
Mr. Ikai:
Considering the complexity of satellite images from the multiple models we have within our company, we chose a model that was strong for complex super-resolution images.
We also included something like residual structures and skip-connections so that we could learn in even deeper layers, and also used a variant of the Relu called the activation function considered to give a higher performance. It is also important to control the number of parameters, so they don’t overwhelm and explode halfway through. This will increase our ability to decipher characteristics, while improving the recreation of small objects when compared to the SRCNN described below.
– How did you proceed with developing something like this?
Mr. Ikai: First, we tried learning from a type of image that is common around the world (a DIV2K) to see how it would be different than using satellite data for learning.

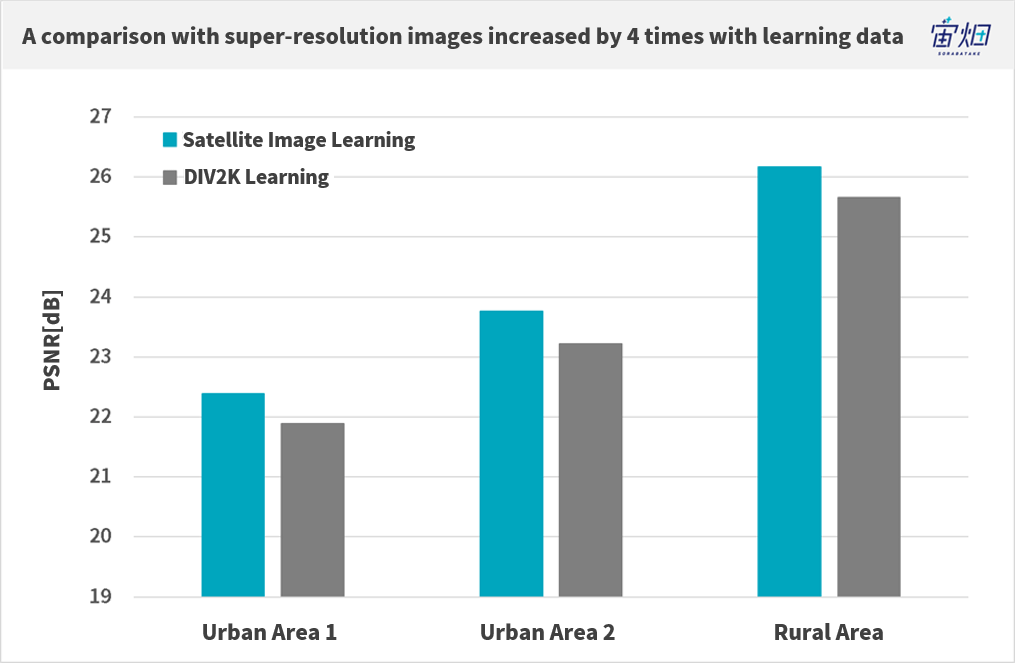
Mr. Ikai: Through doing this, the results were incredible.
At a glance, the learning model that used generic DIV2K images was able to produce good imagery, but the more you look at the details of objects, the more you can see how different they are. We knew at an early stage that super-resolution using satellite data for machine learning had a large impact on the quality of the image.
Of course we applied it to the PSNR (peak signal-to-noise ratio), a cost function, and looking at the images it feels like the difference is greater than the PSNR values.
After deciding on which model and learning data to use, we thought it would be done quickly, but there was still a long way to go. We continued to endlessly fine-tune the hurricane of parameters.
– What is the time-consuming part of fine-tuning the parameters?
Mr. Ikai: We ended up using a different cost function that wasn’t the PSNR, but adjusting them has been a little different from the images we have worked with up until now.
To be precise, with satellite images, you have to choose which images are okay and which aren’t. So I think it took us a lot of time to look at a vast quantity of satellite data, and pick out the passable images.
– Is one of the parameters the difference in appearance in urban areas and rural areas?

Mr. Ikai: It is really the urban areas where we struggle, the rest we can pretty much process as-is.
We would like to be able to process super-resolution images of urban areas which are full of buildings that are very angular, and roads that are laid out properly, but when we try to process images with lots of noise, this can cause what we like to call splitting, where lines split into two. Looking at roads for example, the machine sometimes decides to add an extra road where there should only be one (laughs).
– What do you look at to comprehensively evaluate the images that are produced?
Mr. Sasaki: We typically try different patterns by hand, then evaluate them with our eyes. We do this over and over, it is important to do it a lot. This gives us a numeric value, which we have to judge subjectively to get results.
NIQE is a popular cost function used in many recent studies, so we decided to try it, but to be honest, NIQE makes mistakes when judging strange objects, and it can give a high score based on something false. This isn’t something we can actually use, so it is nothing more than a reference to us.
– Please teach us some of your actual results.


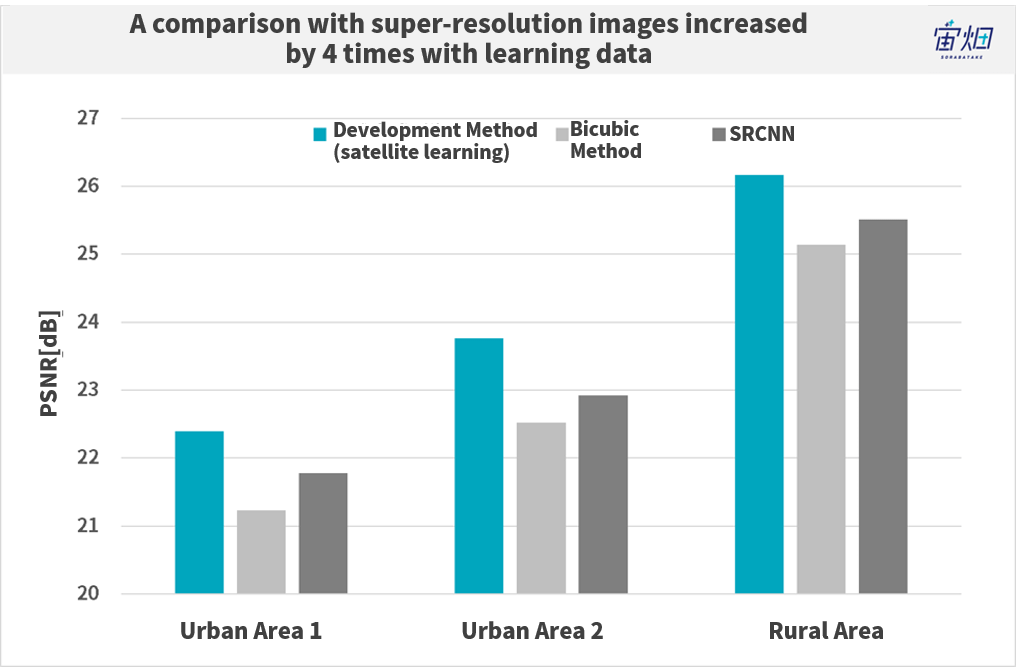
The example of pictures and their evaluation results using values like PSNR can be seen above. It turns out that interpolation (bicubic enlargement) as a cubic function is much sharper by comparison. The rural areas taken by IKONOS-2 in particular show very high values.
You can also compare the model with a simple AI super-resolution method such as SRCNN to see how great these values are. The difference is quite remarkable when it comes to cities in particular. You could consider the number of parameters to be the ultimate parameter, to an extent.
(4) Struggling with the Influence of Color and Noise with Satellite Data
– Were there any difficulties unique to satellite imagery?
Mr. Sasaki: The performance of the cameras built into satellites varies from satellite to satellite, meaning that patterns and colors that show up may be unique to that satellite, and can sometimes be very different. This is something we had trouble with.
The kind of images we tend to use for research are images that have had a lot of work done on them, and tend to have almost no traces of noise. The satellite images we use now may still have noise, or may vary in color depending on the sensor, it is almost like using a raw image.
When these different kinds of problems start showing up, we can’t use the same method for making them all super-resolution.
– So that means noise has a large impact on these images.
Mr. Sasaki: Essentially, when we give something super-resolution, we look at really minute details to speculate what that object actually is. Noise heavily affects our ability to do this, and if a machine tries to learn from something with noise covering it, it may mistake it for a different object, increasing the chance for a misrecognition.
To put it simply, we can’t tell if it is real or just noise.
– Did you have to do anything to the learning data to work around this?
Mr. Ikai: We added a small amount of generic DIV2K images, just enough so that it wouldn’t have a negative impact on the satellite images.
We believe it is better to make it somewhat more universal when you don’t know what kind of satellite images you will be working with. During the learning phase, learning from map images will produce good results when looking at other map images, but for this project, the high-resolution satellite images and the lower quality satellite images we used for input, contained different shapes and colors. Taking this into consideration, we think it is safer to add a little variation to the mix.
Mr. Sasaki: In actuality, I feel like mixing in these kinds of photos played a role in stabilizing the process where we used a network we learned from high-resolution satellite images and applied them to low resolution images to create super-resolution images without numeric values. This is true for satellite images as well.
(5) Improving the Accuracy of Object Recognition with Super-Resolution and Satellite Data
– What kind of applications can be considered using the algorithm you developed?
Mr. Sasaki: This time we focused on simply creating something that was nice to look at, but in regard to our contribution to utilizing big data, we hope to help in increasing the accuracy in recognizing objects captured by satellite imagery.
Instead of using the satellite images the way they are to pick out objects, we believe it could be useful to prep the images before turning them into super-resolution images. While it does increase their size it also increases their functionality.
– On Tellus, for example, we hold contests for sea vessel detection and sea ice detection, do you think it could have an impact on the accuracy of those kinds of data?
Mr. Ikai: I believe it could. It could be interesting for us to use the recognition algorithms produced by Tellus. This time we were more focused on making them visually appealing, but if we were to add a recognition algorithm to the mix, we would be able to gauge how correct the recognitions are.
– Are there any other studies you would like to perform?
Mr. Sasaki: As satellite data is macro data, rather than using it to show space, we would like to try to use it for learning things time related. I think that by looking at how things change over time, we can make new conclusions about things we didn’t know before. I would like to gather that kind of data and use a neural network to conduct learning and see what kind of interesting data we get.
This gets into the realm of using satellite images from the past to make predictions about the future.
(6) Summary
Sharp’s super-resolution satellite imagery can be summed up into the following three points.
– Super-resolution satellite images can be improved not only with generic images but through using satellite data for machine learning.
– Super-resolution has a harder time processing urban areas with complex objects, so the aesthetics of the images can’t be judged with a universal cost function such as PSNR, and requires people to actually look at the photos to judge.
– Satellite images contain a lot of noise and vary in color, so learning from generic images can help stabilize the process.
Sharp conducted their super-resolution learning with the purpose of making images look nice, but they were faced with the challenge of setting multiple parameters to deal with the large amount of noise and varying colors not found in regular pictures.
Looking at things from the perspective of the space industry, over the past ten years many new satellites have made their way up into space, resulting in a tremendous increase in the number of satellite images being taken. It would be impossible for humans to manually look at every picture to determine their contents, so super-resolution looks like a promising method for increasing object recognition accuracy.
Looking at examples abroad, technology that uses super-resolution derived from medium resolution images is being developed for the European satellite data platform UP42.

https://medium.com/up42/quadruple-image-resolution-with-super-resolution-6e5cbab81cd7
There were also many thesis papers written on super-resolution satellite imagery in 2019 alone.
https://www.mdpi.com/2072-4292/11/13/1588
If you are using machine learning to work with images, definitely take this chance to learn more!
Try using satellite data for free on "Tellus"!
Want to try using satellite data? Try out Japan’s open and free to use data platform, “Tellus”!
You can register for Tellus here
