【データサイエンス入門】Pythonでテーブルデータを扱いたい人のためのライブラリまとめ
テーブルデータを扱う上で押さえておきたいPythonライブラリの基礎をご紹介します。これからPythonを学びたいという方におすすめです。
今回は、テーブルデータを扱う上でのPythonライブラリをご紹介します。
本記事の読者は、以下のような方を想定しています。
・Python初心者
・Pythonでデータサイエンスをしたい方
・RとPythonのコードの違いに興味があるという希有な方
当てはまる!と思われた方はぜひご覧ください。
※本記事の関連記事として、後日「画像解析編」「自然言語処理編」を公開予定です。
(1)Pythonのライブラリとは
Pythonを学び始めるとライブラリとパッケージという言葉が混在していますが、この二つを厳密に区分することは、あまり重要ではありません。
ライブラリ、パッケージいずれにしても、何かをするための関数の集合体として捉えたほうが混乱しません。例をあげると、matplotlibはPythonの描画用パッケージとしてPyPlに登録されていますが、公式のサイトでは描画するためのライブラリであると記されています。
それでは、ライブラリとは何でしょうか。
例えば、ライブラリを、特定の何かをPythonで実現するための専門企業と考えてみます。上でも紹介したmatplotlibは高機能な可視化専門企業となり、会社内には様々な可視化の専門家(モジュール)がいます。専門家は色々な専門知識(メソッド)を用いて、顧客がやりたいことを実現してくれるということになります。
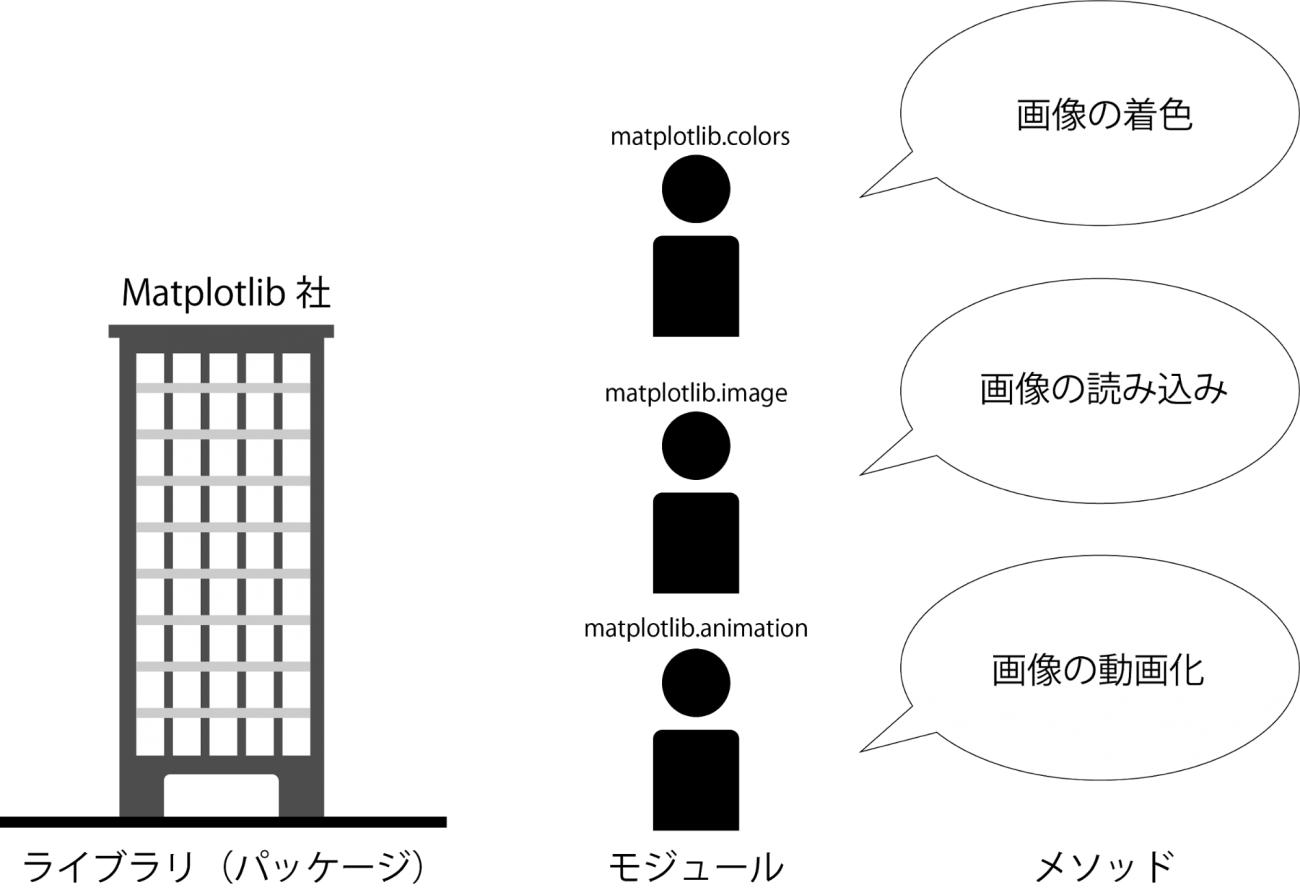
データサイエンスを行なうに当たって、一体どのようなライブラリを主として使うことになるのでしょうか。次章以降で実際のコードと合わせて紹介します。
また、本記事はかなり長い記事となっておりますので、知りたいことが明確、もしくは、コードは開発環境上で見たいという方は以下を参考に記事をご覧ください。
・データ収集
–データベースからの取得(sqlite3) ※コードをダウンロード
–APIを用いて取得(requests) ※コードをダウンロード
–Webスクレイピングを用いて取得(beautiful soup) ※コードをダウンロード
・NumpyとPandasについて ※コードをダウンロード
–Numpy
–Pandas
・EDAとデータクリーニングについて ※コードをダウンロード
–データが整っていない
–変数が意図したデータ型ではない
–表記揺れ
–誤入力
–外れ値や欠損値
・ライブラリのTips
–ライブラリのバージョン確認 ※コードをダウンロード
–ライブラリのパス確認
–ライブラリのディレクトリ確認
(2)データサイエンスで使うPythonライブラリ
データサイエンスの手順は大まかに以下のようになります。
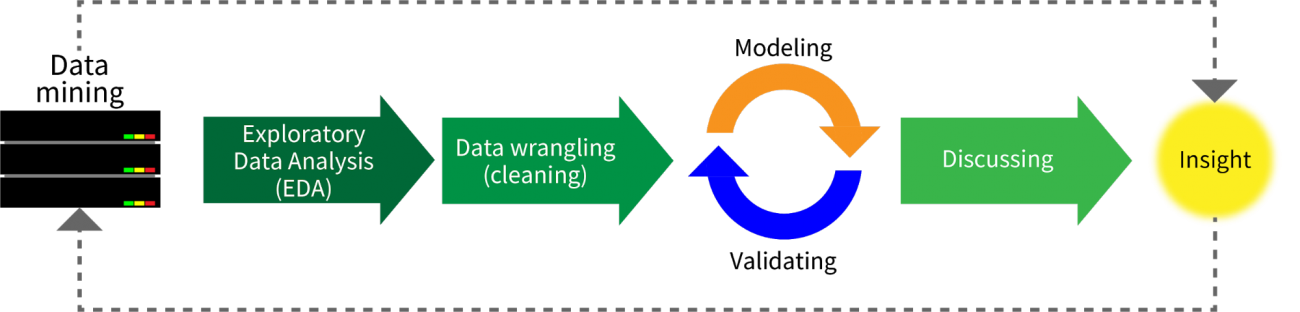
1.データ収集(Data mining)
2.記述統計や可視化(EDA:Exploratory Data Analysis)
※統計で言うところの記述統計も含み、データがどのような性質、状態であるのかを調べます。これにより外れ値や欠損値、データの分布などを捉え、モデルを組み立てる上での重要な情報を把握することになります。
3.データの掃除(Data wrangling)
4.データのモデリング+妥当性評価(Modeling+Validating)
5.考察(Discussion)
6.データから得た知見を問題解決に活かす(Insight)
これらの手順は繰り返されたり、部分的に繰り返されて、より問題に合った結果が得られるまで続くことになります。
その過程の中から、データの収集、クリーニング、EDAまでのライブラリを中心として紹介します。
本来はデータの収集の前に、どのようなことを解決したいのかを明らかにする必要があります。今回はデータサイエンスの手順を説明するものでないので省きますが、ビジネスにしろアカデミックにしろ問題設定なしには、データを集めることはできません。
2.1:データ収集
データは様々な場所から取得することができます。実験や調査を自ら行なうことによってデータを得ることは一般的なことです(例えば得られたデータをcsvに保存したり、データベースに保存したりする)。一方で、必要な情報をネットから集めることも可能です。それには大きく三つの方法があります。
・データベースから取得
・APIを用いて取得
・Webスクレイピングを通じて取得
Pythonでは、ライブラリを用いることにより、これらの方法を容易に実現することができます。
2.1:データベースからの取得(sqlite3)
データベースにも幾つかの種類がありますが、今回はSQLiteデータベースのみに言及をします。
今回のライブラリでは以下のようなモジュールとメソッドを使用します。sqlite3の詳しい説明はこちらの公式ドキュメントをご覧下さい。

※他のライブラリであっても、ライブラリのインポートから始まり、モジュール・メソッドを使うという流れは同じになります。
実際に動かしてみましょう。
まずはライブラリをインポートします。
# SQLiteのライブラリを読み込む
import sqlite3次にデータベースに接続します。test.dbが作業ディレクトリに存在しない場合にはtest.dbが新しく生成されることになります。
# データベースへの接続
connection = sqlite3.connect("test.db")
# 接続を切断する
connection.close()次はテーブルの作成です。
作成したデータベースファイルに接続した後で、クエリを実行するためのカーソルを用いて、テーブルを定義します。
カーソルを用いることにより、データをデータベースに記述することができるようになります。
その際にメタデータを指定していますが、無くてもテーブルを作成するだけならば問題はありません。
詳しくはこちらのリンクをご覧下さい。
# 接続
connection = sqlite3.connect("test.db")
# カーソルを開く
cursor = connection.cursor()
# テーブルを作るためのクエリ
create_table = """
CREATE TABLE testscore (
student_id INTEGER PRIMARY KEY,
name VARCHAR(20),
gender CHAR(1),
rika_score INTEGER,
sansuu_score INTEGER,
kokugo_score INTEGER
);"""
# SQLコマンドの実行
cursor.execute(create_table)
# 変更の追加
connection.commit()
# 接続の切断
connection.close()次はデータ挿入の流れをご説明します。
# テーブルに加えるデータ
test_data = [( 1, "山田太郎","M", 70, 64, 72),
( 2, "山田花子","F", 70, 84, 92),
( 3, "鈴木次郎","M", 80, 84, 82),
( 4, "鈴木妹子","F", 60, 54, 99)]
conn = sqlite3.connect("test.db")
cursor = conn.cursor()
# 各々の学生のデータをテーブルに加えていく
for score in test_data:
insert_statement = """INSERT INTO testscore VALUES ({0}, "{1}", "{2}", {3}, {4}, {5});""".format(score[0], score[1], score[2],score[3],score[4],score[5])
cursor.execute(insert_statement)
conn.commit()
conn.close()テーブルに加えられる行のデータは以下のようになっています。
insert_statementOutput
===
‘INSERT INTO testscore VALUES (4, “鈴木妹子”, “F”, 60, 54, 99);’
===
次は、データを新しく追加してみましょう。同様にデータベースに接続し、カーするを開きSQLコマンドを実行することにより新しい行データを加えることができます。
# 接続開始
conn = sqlite3.connect("test.db")
# カーソルを開く
cursor = conn.cursor()conn.execute('''INSERT INTO testscore VALUES ( 5, "山田隆","M", 80, 80, 80)''')conn.commit()
conn.close()次はデータの抽出です。
connection = sqlite3.connect("test.db")
cursor = connection.cursor()# クエリの実行
query = "SELECT * FROM testscore"
cursor.execute(query)
# 検索結果を全て抜き出す
result = cursor.fetchall()
# 結果を表示する
for row in result:
print(row)
# close connection
connection.close()フェッチやカーソルについての詳しい説明はこちらのリンクをご覧下さい。
2.2:APIを用いて取得(requests)
続いてAPIを用いてデータを取得します。Pythonでデータサイエンスを始めようとする人にとって、データベースはまだしも、APIはよく分かっていないということが多いかと思います。

APIを簡単に説明したものとして、レストランでの注文に例えたものがよく見られます。レストランでは、客が給仕に注文(request)をします。注文をする際に使ったメニューは、どのようなAPIかを説明したリファレンス(yaml)です。給仕(API)は客の注文を厨房(server)にもって行き、その通りの食べ物を運んでくること(response)になります。
APIはクライアントの情報をサーバーに正しく伝えて、正しくクライアントに返すためのメッセンジャーです。このメッセンジャー無しの関係とは、レストランに給仕もメニューもなく、欲しいものを直接厨房まで客自身が伝えに行くことに当たります。もちろん、希望する料理を厨房で作れるのか客が事前に把握することはできませんし、厨房も部外者の立ち入りを許してしまうというセキュリティ上の問題にも繋がります。
前置きはここまでにして、APIを通じてデータを取得してみましょう。ここではrequestsライブラリを使用します。
まずはrequestsライブラリを読み込みます。
import requests今回は、以下のAPIを利用します。
https://github.com/ryo-ma/covid19-japan-web-api
APIの仕様に従い、必要なパラメーターを加えます。ここでは都道府県名が必須のパラメーターとなります。
*requestsに関しての詳細情報はこちらをご覧下さい。
place = '東京都'
base_url = "https://covid19-japan-web-api.now.sh/api/v1/positives?prefecture={}".format(place)getメソッドを用いてサーバーにrequestを送ります。
re = requests.get(base_url)サーバーからのレスポンスを確認しましょう。正しくリクエストが通れば200番が返されることになります。以下で確認しましょう。
re.status_codeデータはjsonフォーマットで格納されていますので、それを新しい変数covidに保存します。
covid = re.json()データからageの部分だけを抽出して、新しいリストを作成します。
covid_age = [row['age'] for row in covid]空の辞書型のデータを用意し、年齢ごとで集計をしてみましょう。
age_dic ={}
for age in covid_age:
if age in age_dic:
age_dic[age] += 1
else:
age_dic[age] = 1age_dic実行すると集計結果が表示されますが、Outputの順番がバラバラのため、以下のように順番を揃えます。
age_sorted = sorted(age_dic.items(), key=lambda x:x[0])
age_sortedOutput
===
[(‘-‘, 1),
(’00代’, 66),
(‘100代’, 2),
(‘100歳以上’, 1),
(’10代’, 75),
(’20代’, 837),
(’30代’, 867),
(’40代’, 781),
(’50代’, 761),
(’60代’, 502),
(’70代’, 472),
(’80代’, 313),
(’90代’, 159),
(‘不明’, 8),
(‘欠番’, 13)]
===
APIについてもっと知りたいという方は、こちらのリンクを参考にしてください。
2.3:Webスクレイピングを用いて取得(beautiful soup)
あるサイトに記載されているテーブルの情報が欲しい。しかし、APIはもちろんのこと、csvの配布もしていない。そのような状況は珍しくありません。このようなときに役立つのがスクレイピング(webスクレイピング)となります。
スクレイピングを行う場合に重要となることは、情報を抜き出したいサイトの構造を把握することです。例えば、https://en.wikipedia.org/wiki/SpaceXを見てみましょう。
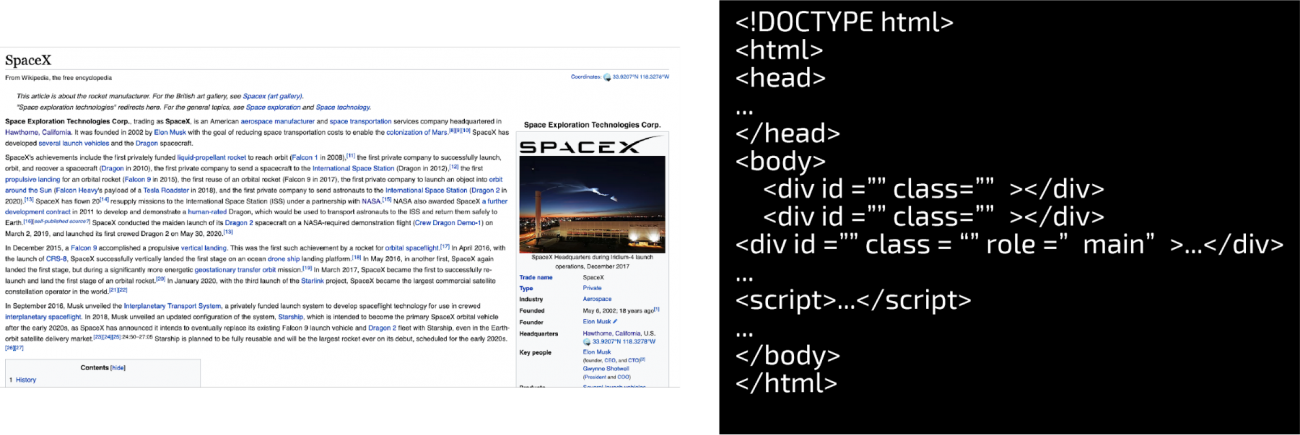
非常に簡略化したページの構造ですが、様々なタグで構成された文書がウェブサイトの骨格を表しています。スクレイピングでは、これらのタグを対象として必要な情報を抜き出していくということになります。
実際にhttps://en.wikipedia.org/wiki/List_of_Falcon_9_and_Falcon_Heavy_launchesのwikiからテーブルの情報を抜き出してみましょう。PythonではBeautifulSoupを用いてスクレイピングを行います。
まずはライブラリの読み込みを行います。
from bs4 import BeautifulSoup
import requests
import pandas as pd該当のurlを抜き出す際に、headerの情報を付け足します(今回はfirefoxにしています)。これにより、あたかもブラウザからアクセスしているように振る舞うことができます。
※最新のユーザーエージェント情報については、こちらをご覧下さい。
https://en.wikipedia.org/wiki/List_of_Falcon_9_and_Falcon_Heavy_launchesのテーブル情報に対してスクレイピングを行います。
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:77.0) Gecko/20100101 Firefox/77.0'}
url = "https://en.wikipedia.org/wiki/List_of_Falcon_9_and_Falcon_Heavy_launches"
r = requests.get(url, headers=headers)レスポンスをチェックしましょう。200番が返ってくれば正常にリクエストが通っています。
rBeatfifulSoupを用いて、取得したhtmlの構造を読み取ります。
soup = BeautifulSoup(r.content, "html.parser")中身を確かめてみましょう。上記のurlで指定したhtmlが丸ごと表示されます。
soup※上記、Outputが長いため割愛。
htmlファイルの中から特にテーブルの方法を取得します。このとき、テーブルにクラスの情報が入っていますので、それをターゲットとして探し出します。このときに使うのがfindメソッドです。find_allでは、そのページに存在する関連タグの全てを抽出します。findを用いた場合には、最初に現れた要素のみを取り出すことになります。
tab = soup.find_all("table",{"class":"wikitable plainrowheaders"})続けて、trタグの情報、テーブルの行に該当する場所を全て探し出します。
tableのクラスがwikitable plainrowheadersに該当するものは8つ存在します。
len(tab)Output
===
8
===
抜き出した情報をデータフレームにするための準備として空のリストを作成します。pandasの使い方については後述します。
row_list = list()trタグ内には、tdとして行内のデータが挿入されている場所があります。ループ処理でそれを一行一行読み取り、テキストデータに変換します。これにより無駄な情報の多くが省かれ、後々の処理を行う手間がなくなります。
for i in range(len(tab)):
rows = tab[i].find_all('tr')
for tr in rows:
td = tr.find_all('td')
row = [cell.text for cell in td]
row_list.append(row)リストをデータフレームに変換します。
※Flight Noは取得していませんので、wikiのページでは10列だったものが9列になっています。
df = pd.DataFrame(row_list,columns=['Datetime(UTC)','Ver_booster','Launch_site','Payload','Payload mass','Orbit','Customer','Launch_outcome','Booster_landing'])結果を出力してみましょう。
df実行すると「226 rows × 9 columns」のデータが出力されます。
to_csvのメソッドを用いることにより、上のデータフレームをcsvとして作業ディレクトリに保存することが可能です。
df.to_csv('falcon_heavy.csv')もちろん、取得したテーブルはさらにデータクリーニングを行う必要があります。
今回はスクレイピングの概要と言うことで割愛しましたが、さらにスクレイピングについて詳しく知りたいという方はこちらをご覧下さい。
また、全てのサイトの情報がBeatfifulSoupのみで取得できるわけではありません。Javascriptによりコントロールされているウェブサイトでは、マウスイベントを起さなければ適切に情報を取得できません。その場合にはSeleniumを利用しましょう。
詳しくはこちらをご覧下さい。
(3)NumPyとPandas
冒頭で説明した「EDA(Exploratory Data Analysis)+データクリーニング」に入る前に、まずはNumpyとPandasの使い方を学びましょう。
3.1:NumPy
Numpyが扱うデータはn-dimensional array(ndarray)という名前が示す通り、1からそれ以上の次元を持った配列データになります。高い次元のデータを扱えるというだけでなく、numpyではPythonのリストを用いるより高速な計算処理ができることで知られています。
その秘密の一つとしてNumpyがCPUの一サイクルで複数のデータポイントを一度に処理できるという利点(SIMD:Single Instruction Multiple Data)があります。これにより、一つ一つを計算していくリスト(SISD:Single Instruction Single Data) を用いるより、効率良く計算ができます。このような操作をベクトル演算(vectorized operations)と呼びます。
※ここには、ndarrayがlistと異なり、データ型に対して非常に厳格であるということも関係しています。詳しくは、こちらをご覧下さい。
Numpyがベクトル演算を使えるため、リストで行っていたようなループ処理を省くことが可能です。
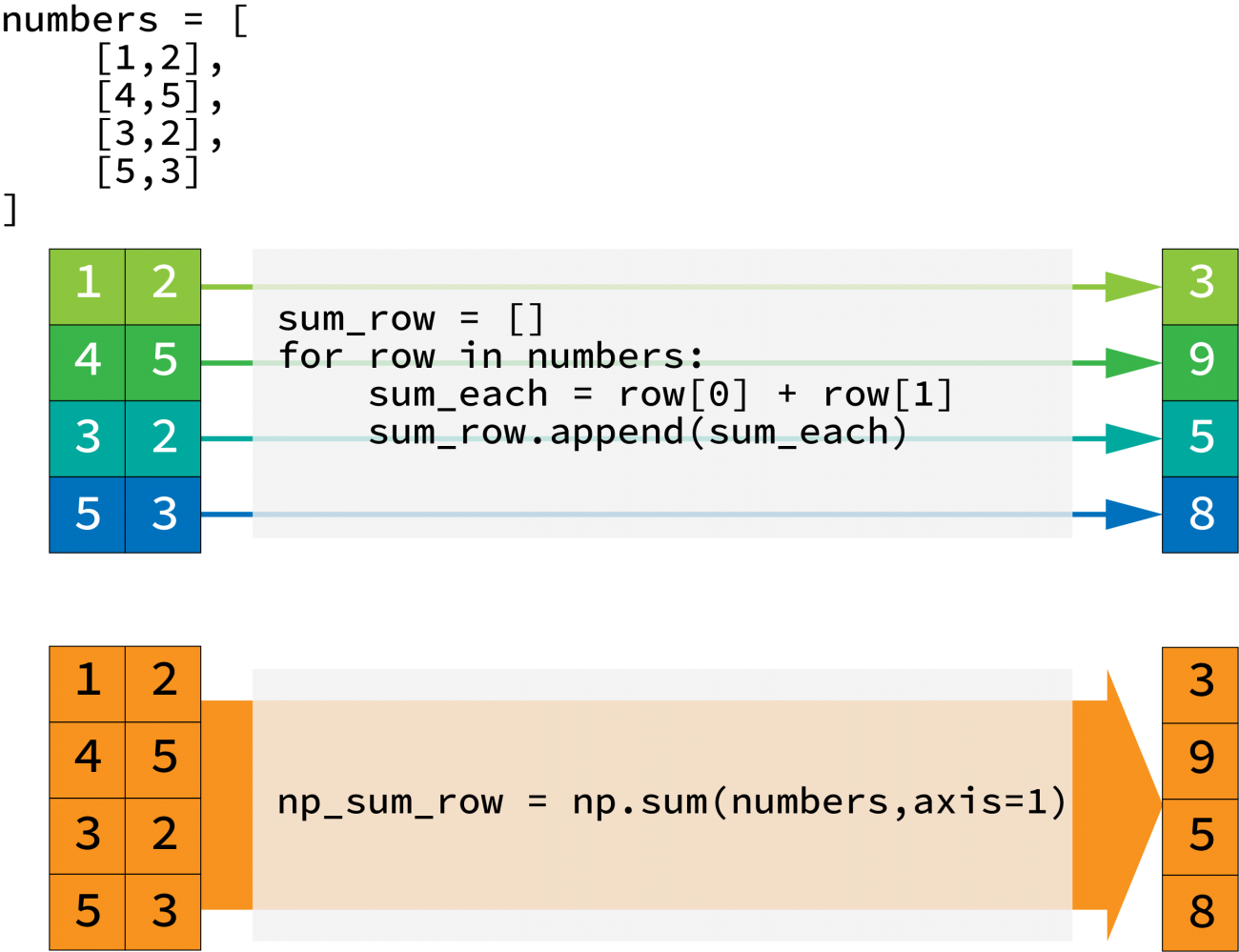
まずはライブラリをインポートします。
# ライブラリのインポート
import numpy as np
import pandas as pd4行2列のlistを作成します。
numbers = [
[1,2],
[4,5],
[3,2],
[5,3]
]上のリストに対して行ごとの和をとりましょう。この場合、ループを行って各々の行ごとに集計します。
sum_row = []
for row in numbers:
sum_each = row[0] + row[1]
sum_row.append(sum_each)
print(sum_row)Output
===
[3, 9, 5, 8]
===
次は、リストをndarrayに変換します。
np_numbers = np.array(numbers)NumPyではリストで行ったことを簡単に処理することが可能です。今回はsumの例で紹介をしていますが、平均や分散などの処理も行うことが可能です。この場合、どの方向に計算を行うのかを示す必要があります。行方向(下から上)ならばaxis=0、列方向(左から右)ならばaxis=1です。
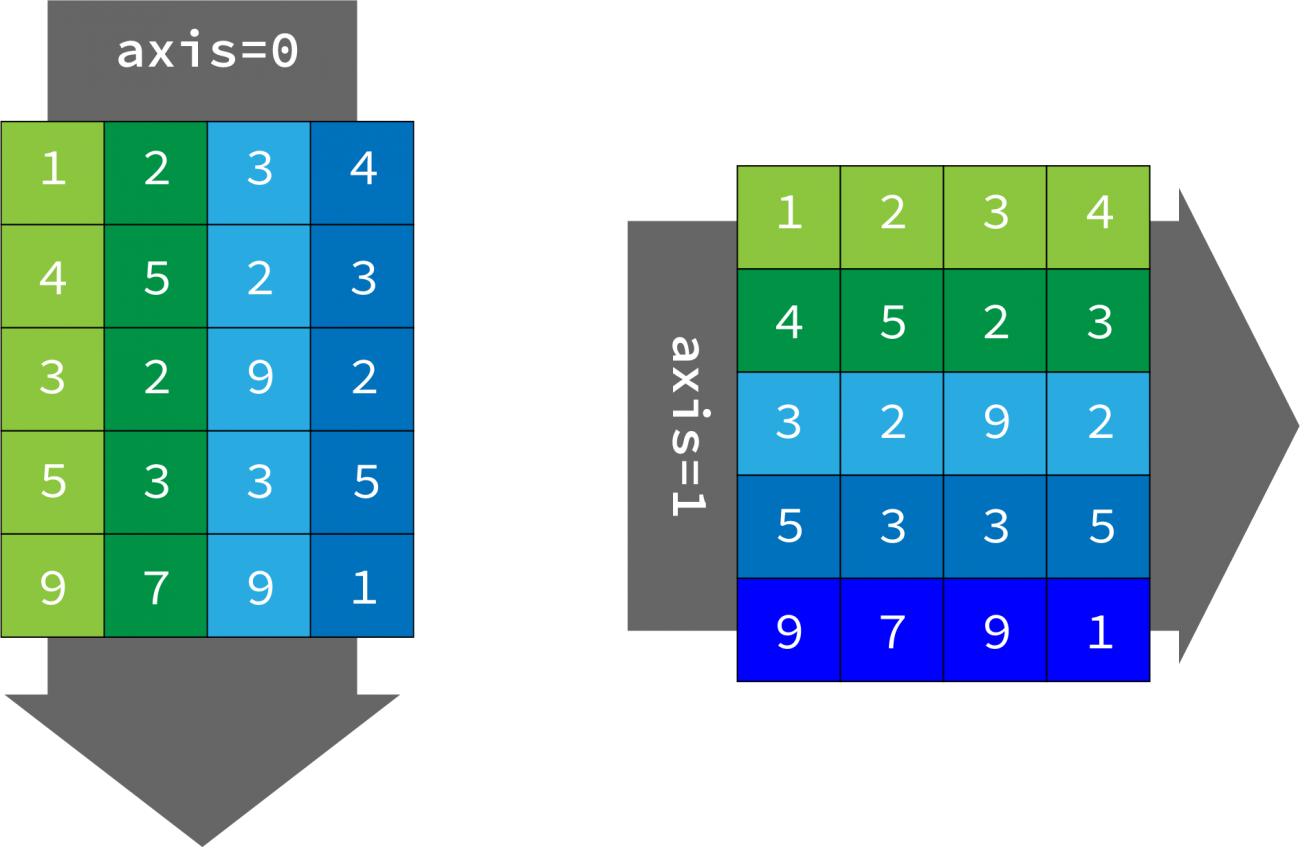
# sum関数を実行する
np_sum_row = np.sum(numbers,axis=1)print(type(sum_row))
print(type(np_sum_row))Output
===
<class ‘list’>
<class ‘numpy.ndarray’>
===
では、axisの動きを、別のデータを使って再度確認しましょう。
# 5行4列の配列
numbers = [
[1,2,3,4],
[4,5,2,3],
[3,2,9,2],
[5,3,3,5],
[9,7,9,1]
]# 行方向への演算
print(np.sum(numbers,axis=0))
# 列方向への演算
print(np.sum(numbers,axis=1))Output
===
[22 19 26 15]
[10 14 16 16 26]
===
続いて、具体的なNumPyの機能について説明をします。
ここからは、Kaggleで公開されているデータセットを利用します。リンク先からtrain.csvをダウンロードして、作業ディレクトリに移動させましょう。
※Kaggleのデータを利用するために登録をする必要があります。Kaggleへはgoogleなどの既存のサービスと紐付けて登録する、メールで新規にKaggleのアカウントを作成するなどの方法があります。
複数のデータ型を含んだcsvに対してはgenfromtxt関数を使います。
np_train = np.genfromtxt("train.csv", delimiter=",",dtype=None, encoding='utf-8')‘dtype=None’とすることで、様々なデータ型を含んだcsvを読み込めるようになります。
※’names = True’とすることによりcsvの先頭行を変数名にできます。 np_train.dtype.namesとすることで、その変数名を確認できます。
var_names = np_train[0] #変数名を抽出
np_train = np_train[1:] #変数名以外を抽出# shapeメソッドを用いて、配列の形を確認
# 1460行81列の二次元配列であると分かる
np_train.shapeOutput
===
(1460, 81)
===
NumPyは便利な関数を持っていますが、記述統計で用いるもののみを紹介します。関数とメソッドで分けていますが、機能に差はありません。ただし、関数はあってメソッドには使えないものも存在します。基本的にはメソッドと関数で揃えるのが綺麗ですが、存在しないものは割り切って使ってしまいましょう。
※代表値には平均や中央値に加え最頻値もあります。NumPyでは最頻値を簡単に取得できる方法はなく、SciPyを用いることになります。
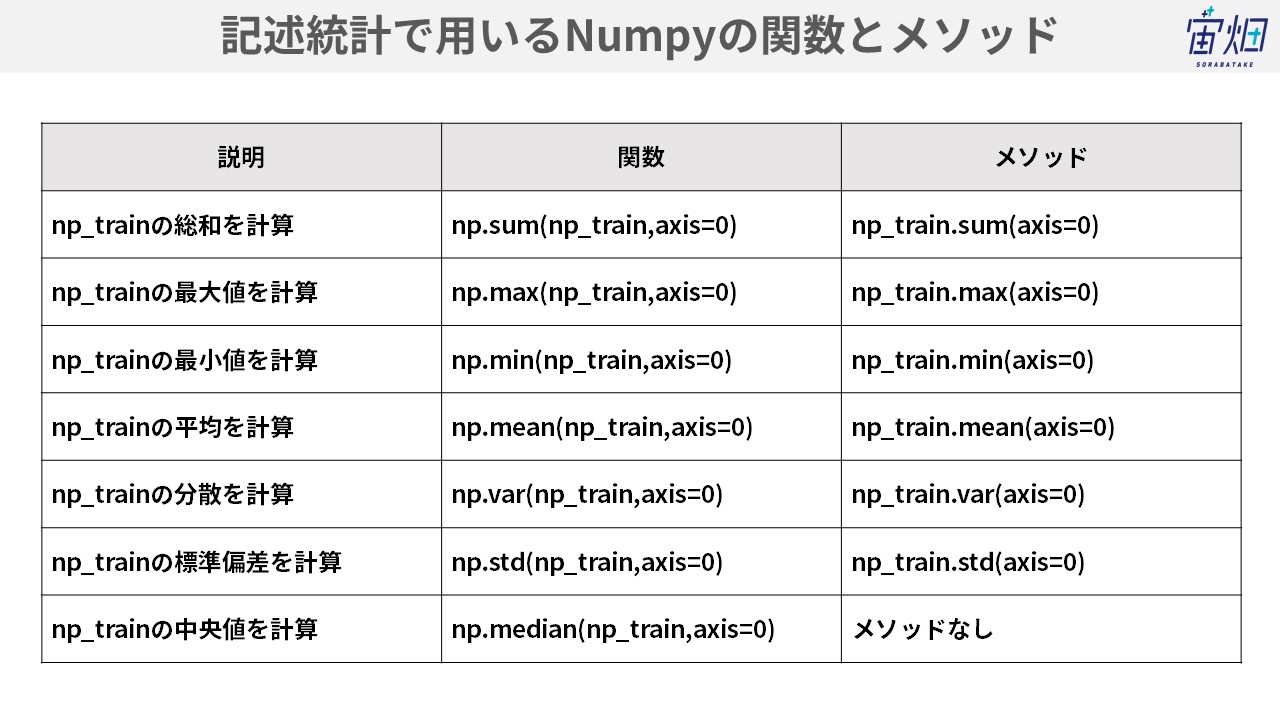
総和を求める
print(np_train[:,(17,18)].astype(np.int).sum(axis=0))
#print(np.sum(np_train[:,(17,18)].astype(np.int),axis =0))
print(np_train[:,(17,18)].astype(np.int).sum(axis=1))
#print(np.sum(np_train[:,(17,18)].astype(np.int),axis =1))行方向への最大値を求める
print(np_train[:,1].astype(np.int).max(axis=0))
# print(np.max(np_train[:,1].astype(np.int),axis =0))
行方向への最小値を求める
print(np_train[:,1].astype(np.int).min(axis=0))
# print(np.min(np_train[:,1].astype(np.int),axis =0))行方向への平均を求める
print(np_train[:,1].astype(np.int).mean(axis=0))
# print(np.mean(np_train[:,1].astype(np.int),axis =0))行方向への分散を求める
print(np_train[:,1].astype(np.int).var(axis=0))
# print(np.var(np_train[:,1].astype(np.int),axis =0))行方向への標準偏差を求める
print(np_train[:,1].astype(np.int).std(axis=0))
# print(np.std(np_train[:,1].astype(np.int),axis =0))行方向への中央値を求める
print(np.median(np_train[:,1].astype(np.int),axis =0))NumPyは他にも様々な関数を持っています。詳しくはこちらをご覧下さい。
高機能で便利なNumPyですが、幾つかの欠点も持っています。
変数名が利用できない
ndarrayの性質上、様々なデータ型を扱うのに不適
などです。
次に紹介するPandas(Pandas.DataFrameやPandas.Series)では、ndarrayが持つこれらの弱点が補われ、より簡単にデータを操作することができます。
3.2:Pandas
csvファイルを、read_csv関数により読み込みます。データフレームのインデックスとしてIdを利用します。
house_price = pd.read_csv("train.csv",index_col='Id')NumPyと同様にshapeメソッドを使ってデータの次元を確認することが出来ます。
house_price.shapeOutput
===
(1460, 80)
===
変数名を調べたい場合にはcolumnsメソッドを使うことになります。
print(house_price.columns)上記を実行すると変数名がOutputされます
次に、データフレームの情報を網羅的に調べたい場合には、infoメソッドを用いることになります。
info()で確認できる情報はデータが自分の意図したものであるかを確認する最も簡単な方法でもあります。
house_price.info()次に、describeを用いてデータの要約統計量を簡単に表示することが出来ます。デフォルトでは数値データのみを示します。
objectやboolでもdescribe()を用いて、データの概要を把握することが可能です。この場合にはincludeオプションを使います。
house_price.describe()実行すると、「8 rows × 37 columns」のデータが出力されます。
infoで示されている統計量を個別に求めてみましょう。具体的にLotArea(Lot size in square feet)の変数に対して計算を行います。
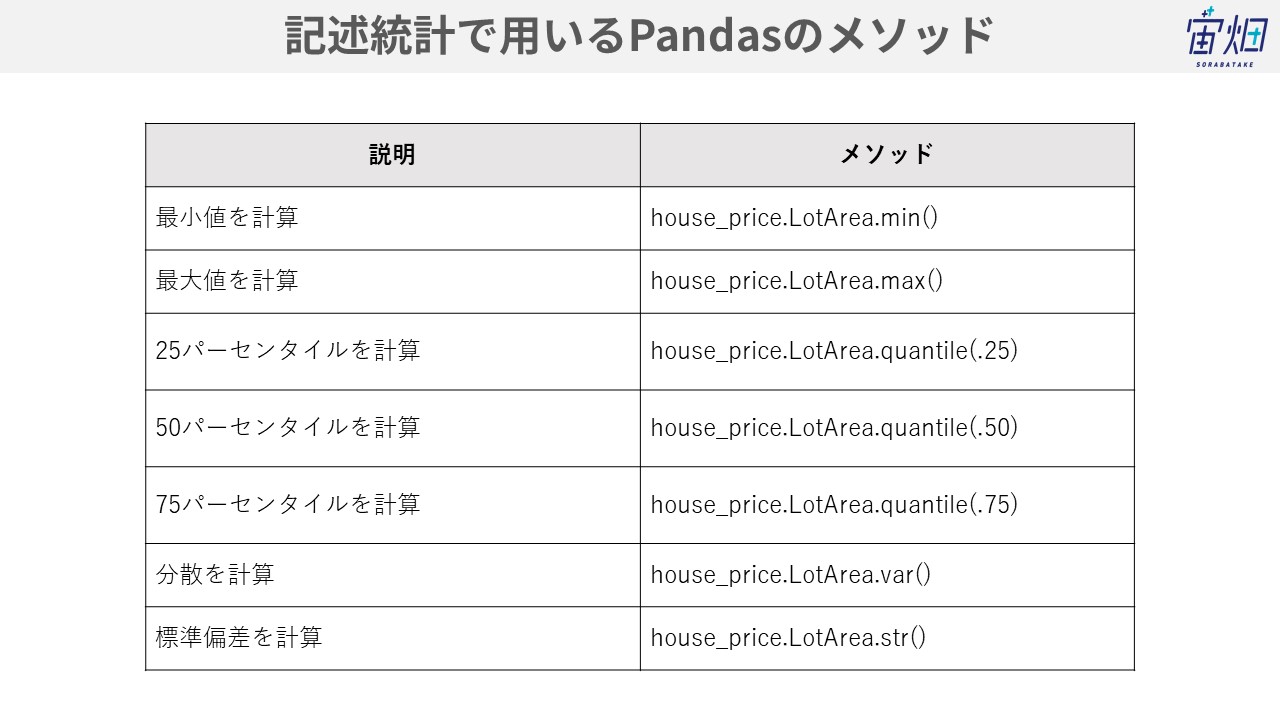
print('Min LotArea : {0}'.format(house_price.LotArea.min()))
print('Max LotArea : {0}'.format(house_price.LotArea.max()))
print('25 percentile : {0}'.format(house_price.LotArea.quantile(.25)))
print('50 percentile : {0}'.format(house_price.LotArea.quantile(.5)))
print('75 percentile : {0}'.format(house_price.LotArea.quantile(.75)))
print('Variance LotArea : {0}'.format(house_price.LotArea.var()))
print('Standard deviation LotArea : {0}'.format(house_price.LotArea.std()))Output
===
Min LotArea : 1300
Max LotArea : 215245
25 percentile : 7553.5
50 percentile : 9478.5
75 percentile : 11601.5
Variance LotArea : 99625649.65034176
Standard deviation LotArea : 9981.26493237915
===
カテゴリ変数では、重複を除いた値の数が幾つか(uniuqe)、最頻値は何か(top)、そして最頻値に対する頻度(freq)がでます。
house_price.describe(include=['object','bool'])
# iclude = allで全ての変数の情報を示すことも可能
# house_price.describe(include='all')上記を実行すると「4 rows × 43 columns」のデータが出力されます。
似た集計方法として、value_counts()のメソッドを使う方法もあります。uniqueやtopは明示されませんが、各々の値に対する頻度が分かるので、データの分布をイメージしやすくなります。
house_price["MSZoning"].value_counts()
# 比率を求める場合はnormalizeオプションを用いる
# house_price["MSZoning"].value_counts(normalize = True)■データフレームの一部だけを表示したい場合
データフレームの一部を表示するためには、headメソッドを使います。headメソッドではデフォルトで先頭からの5行分のデータを抜き出します。反対に最終行から取得する場合にはtail()を利用します。
house_price.head()
# 先頭から10行とる場合
# house_price.head(10)house_price.tail()
# 最終行から10行とる場合
# house_price.tail(10)■特定の変数を基準にデータを並べ替えたい場合
また、データフレームでは並べ替えも簡単に実行することが出来ます。
# 昇順で並べ替える場合にはascending=True。降順であればascending=False
house_price.sort_values(by='MSSubClass', ascending=True).head()■複数の変数を基準に並び替えたい場合
複数の変数を基準に並べ替えることも可能です。カテゴリ変数であっても同様に処理ができます。
house_price.sort_values(by=['MSSubClass', 'Utilities'], ascending=[False, True]).head()■特定の値だけを抽出したい場合
場合によっては、特定の値だけを抽出したい場合があります。例えば、MSZoningからRL(人口密度が低い居住地)に該当する値だけをデータフレームから抜き出してみましょう。このようなデータ抽出をfilterと呼びます。
andやorを用いれば、複数の条件を下にして、該当する行を抜き出すこともできます。試してみてください。
house_price[house_price['MSZoning'] == 'RL']
# house_price[(house_price['MSZoning'] == 'RL') & (house_price['BldgType'] == '1Fam')][['MSSubClass','MSZoning','BldgType']]データフレームが保持されていますので、同様にメソッドと組み合わせて使うことができます。
house_price[house_price['MSZoning'] == 'RL'].mean()
# house_price[(house_price['MSZoning'] == 'RL') & (house_price['BldgType'] == '1Fam')][['MSSubClass','MSZoning','BldgType']].mean()pandasにはデータフレームの変数名に基づいたデータ選択が可能なloc、インデックスに基づいてデータ選択を行うilocの二つのメソッドが備わっています。
※厳密にはTrueやFalseを使った抽出もできます。
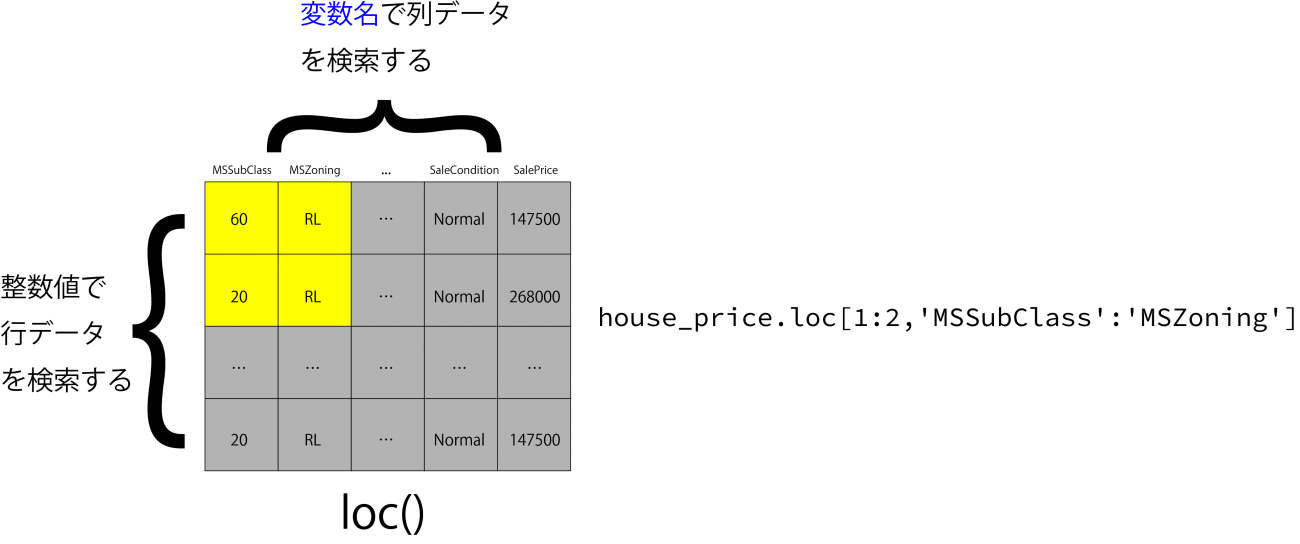
# MSSubClassからBldgTypeまでの列を選択
house_price.loc[:,'MSSubClass':'BldgType']
# house_price.loc[2:5,'MSSubClass':'BldgType']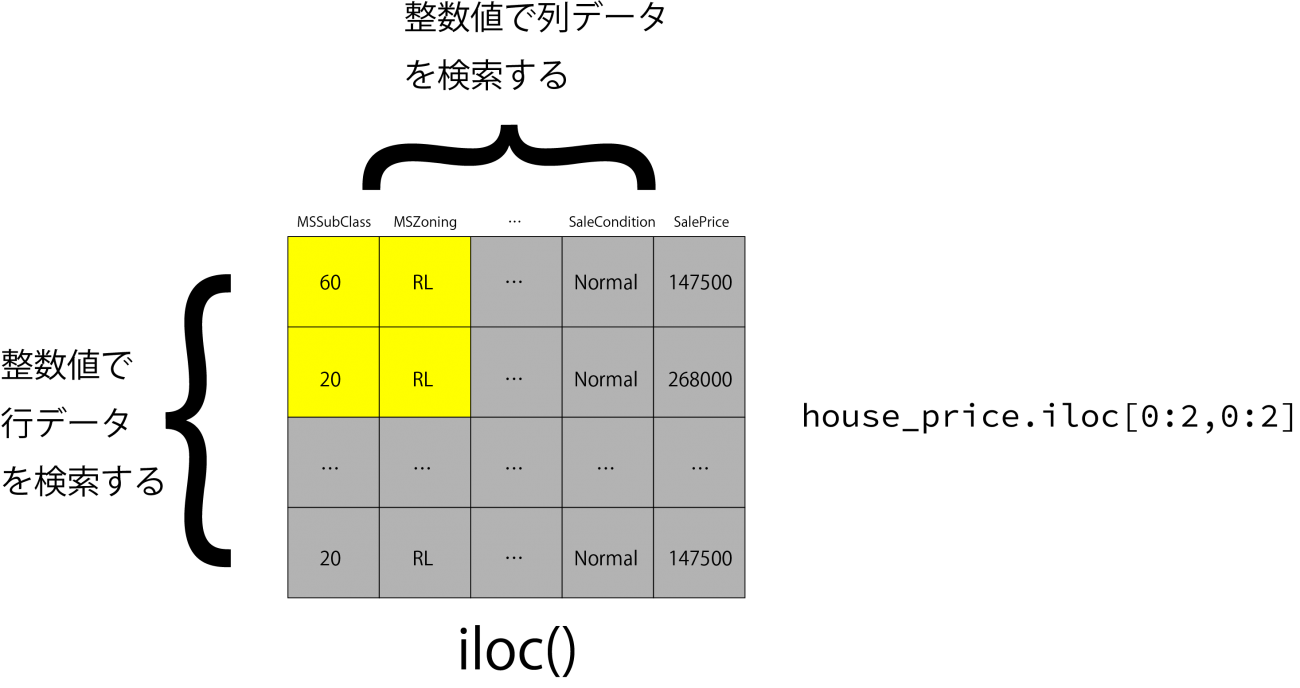
# 1行目から10行目までを選択
house_price.iloc[0:10,]
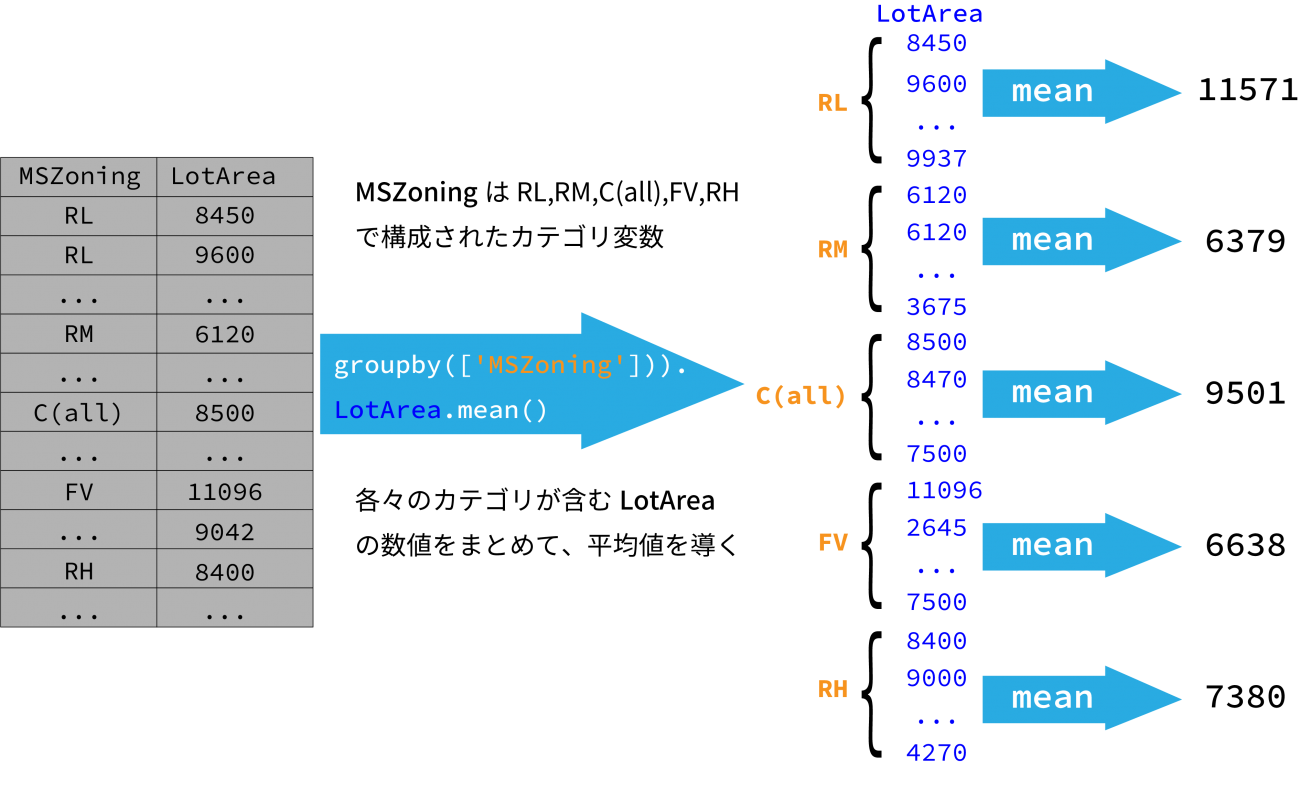
# house_price.iloc[0:10,1:3]データを触っていると、あるカテゴリ変数の値を基準にして、処理を行いたい場合があります。
具体的には、MSZoningの各々の値に対応する、LotArea(Lot size in square feet)の平均値を求めたい場合には何をすればよいのでしょうか。
このときに役立つのがgroupbyメソッドです。
house_price.MSZoning.unique()
# MSZoningはRL,RM,C(all),FV,RHの値で構成されている# MSZoning
house_price.groupby(['MSZoning']).LotArea.mean()また、複数の項目でグルーピングを行うことも可能です。
複数項目でgroupby()を行う場合には、列名をリストに格納すると便利です。下の例では、var_names = [‘MSZoning’,’LotShape’]とする使い方ができます。
house_price.groupby(['MSZoning','LotShape']).LotArea.mean()# MSZoningのカテゴリに対して、1stFlrSF(First Floor square feet)と2ndFlrSF(Second Floor square feet)の要約統計量を見る
house_price.groupby(['MSZoning'])[['1stFlrSF','2ndFlrSF']].describe()agg()を使うことにより、複数の変数に複数の処理を実行できます。
# house_price.groupby(['MSZoning']).agg({'1stFlrSF' : 'mean', '2ndFlrSF' : 'median'})
house_price.groupby(['MSZoning'])[['1stFlrSF','2ndFlrSF']].agg([np.mean,np.var])apply()では、行と列のどちらかに対して特定の処理を行うことが出来ます。
applyでは行方向に対してはaxis=0、列方向に対してはaxis=1で処理を実行します。このaxis=0というのは、行番号が増加する方向と考えてください。axis=1であれば、列番号が増える方向へ向かうということです。NumPyで指定したものと同じように考えれば問題ありません。
# デフォルトではaxis=0、行方向(左から右)への処理
house_price[['LotArea','SalePrice']].apply(np.mean)agg()やapply()は、特定の処理を行う関数を自分で作成し実行することも可能です。下では平均を求める無名関数(ラムダ式)を実行しています。
実行をすると、上の結果と同じものが返ってきます。
house_price[['LotArea','SalePrice']].apply(lambda x: sum(x)/len(x))Pandasを使えば分割表も簡単に作成することができます。分割表とは、二つの変数を行と列に配置して、その間の関係を見るものです。
詳しくは、名義尺度(カテゴリ変数のように数量の変数でない)や順序尺度(数字に順序がある。アンケートにあるような、大変よい:5〜大変悪い:1、のようなもの)である変数の関係性を見るために頻繁に用いられるものです。
# StreetとLandSlopeに対する分割表を作成する
# margins=Trueとすると周辺度数も示すことができる
pd.crosstab(house_price.Street, house_price.LandSlope)
# 比率を見たければnormalize=Trueを加える
# pd.crosstab(house_price.Street, house_price.LandSlope, normalize=True)Pandasは他にも便利なメソッドが沢山あります。公式のドキュメントであればこちら、チートシートで機能一覧が見たいという方はこちらをご覧下さい。
(4)EDA(Exploratory Data Analysis)+データクリーニング
自分で計画を立てて集めたデータで無い限りは、データに対して何らかの前処理(preprocessing)をする必要が生じることがあります。EDAはデータ構造を探索するもので、取得したデータにどのような特徴があるのかを確認し、同時に異常値を見つけるために必要な作業となります。
EDAとは統計で言うところの記述統計を行うことに当たり、数値でデータを精査していくだけでなく、データの分布を視覚的に表現したり、データ同士の関係性を描画したりと様々な方法でデータの持つ特性を洗い出していきます。
EDAを行うことにより、大きく以下のことがわかります。
1.データが整っていない
2.変数が意図したデータ型ではない
3.表記揺れ
4.誤入力
5.外れ値や欠損値
4.1データが整っていない
まず、1のデータが整っていないについてですが、一般的に整ったデータ(tidy data)というものには、いくつかの条件があります。
「値が変数名になっていない」「行データが一つの観測のまとまりになっている」などです。
例えば、国立ガン研究センターでは、ガンに関する様々なデータを公開しています。下は全国ガン罹患データの抜粋です。表のように、公開されているデータは部位にICDコード、性別、診断年、全年齢、そして複数の年齢区分という変数で構成されています。整ったデータとしてふさわしくないのは、年齢幅という値が変数になっているところです。
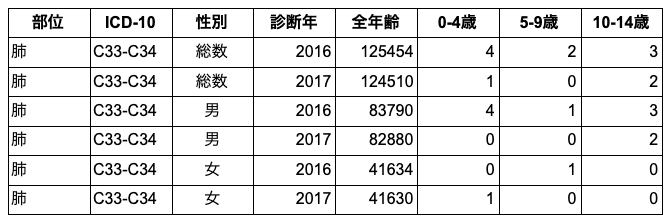
整ったデータとしては、変数としての年齢幅は年齢区分という一つの変数として扱われるのが適当となります。下の表をご覧下さい。
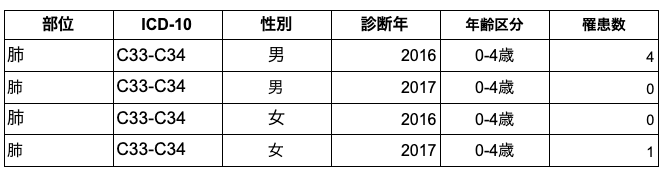
性別に総数という値が入っていることも望ましくありません。集計値は別のテーブルで示されるのが良いでしょう。
※機械学習ではカテゴリ変数を扱うことが苦手なために、one-hot encodingという手法を用いてカテゴリ変数を0と1のダミー変数に変換することがあります。そのため上で示したような値が変数として用いられることがあります。つまり、データの「整った形」とは、どのような解析をするのかで変化することがあります。重要なことは、自分の解析に合わせて、データの構造を自由自在に変化させていくことです。
上の表では、年齢区分が変数になったため表が下に伸びます。人の目には値が変数になっていた場合が見通しが良い場合も存在します。ただ、記述統計のしやすさ、描画の容易さ、そして統計モデルの作りやすさの観点から、tidy dataのルールに従うことは有用であると言えます。
4.2:変数が意図したデータ型ではない
これも誤入力の一種になりますが、後述する誤入力は、ここで説明するものより明確に分かるタイプでない誤入力になります。
再び、House Prices: Advanced Regression Techniquesにあるtrain.csvを例にとって考えてみましょう。
必要なライブラリをインポートします。
import numpy as np
import pandas as pd
import oshouse_price = pd.read_csv("train.csv",index_col='Id')info()は、最初に見るべきもの。これにより、データフレームが期待通りの形であるのかを俯瞰できるだけでなく、欠損値がどのくらい含まれているのかについても把握することができるからです。
本来、数値データであるべき変数が文字扱いになっていれば、この要約情報で知ることが可能です。
house_price.info()house_price.isnull().sum()
# house_price.apply(lambda x: sum(pd.isnull(x)),axis=0)意図したデータ型ではない、という状態を作成するため、house_priceから最初の行を抜き取り、意図的に一部の値を変換してみましょう。今回はMSSubClassを対象とします。
MSSubClassはどちらもint64のデータ型をとっています。
# 一行目を抽出
new_row = house_price[0:1]
print(new_row)MSSubClassを60から’FOO’という文字列に変換
new_row = new_row.replace({'MSSubClass': {60 : 'FOO'}})MSSubClassのデータ型をチェックしておきます。
house_price.MSSubClass.dtype元のデータフレームではMSSubClassは整数型であることが確認できます。
# 作成した行を既存のデータフレームに追加。新しいデータフレーム名をnew_hosuse_priceとする
new_house_price = house_price.append(new_row, ignore_index=True)追加した行を確認するためtailメソッドを利用します。
# 最後の行から5つの行データを取得する
new_house_price.tail()new_house_price.info()
# new_house_price.MSSubClass.dtypeご覧のように新しく生成したデータフレームでは、MSSubClassのデータ型がint64からobjectに変化したのが分かります。このようにinfoでデータを眺めることにより、変数が自分の期待したデータであるのかを理解することができます。
Pandasのデータ型について詳しくはこちらをご覧下さい。
4.3:表記揺れ
表記揺れも解析上は問題となります。1行目のMSZoningの値をRLから小文字のrlに変えてみましょう。
house_price.loc[1,'MSZoning'] = 'rl'house_price.MSZoninghouse_price.MSZoning.value_counts()Output
===
RL 1150
RM 218
FV 65
RH 16
C (all) 10
rl 1
Name: MSZoning, dtype: int64
===
ご覧のように大文字のRLと小文字のrlは別の値として集計されています。これ以外のケースとしては、先頭のみが大文字の場合もあります。いずれの場合にも、このような表記揺れは、同じ価値を持つ値でありながら、別のものとして区別されてしまうことがあるので注意をして要約データを眺める必要があります。
表記揺れに対しては、全ての文字列を大文字にするか小文字にするかで対応することができます。
house_price.MSZoning = house_price.MSZoning.str.upper()全ての文字列を大文字に変換しました。
house_price.MSZoning.value_counts()Output
===
RL 1151
RM 218
FV 65
RH 16
C (ALL) 10
Name: MSZoning, dtype: int64
===
これにより、小文字と大文字が混在した表記揺れを修正することができました。
4.4:誤入力
誤入力は間違いですので、全体として見れば出現頻度は限られます。一般的に言えば正しい言葉を知っていれば判断が難しいということはないでしょう。
しかし、カテゴリ変数の値が増え、集計しても全体の見通しが悪くなったような場合には面倒になる場合が多いです。例えば、筆者の例ですと、300種程度の細菌データを扱ったことがありますが、ラテン名から正しいものを選ぶのは、なかなかに面倒です。
さらに誤入力では、単に文字を大きくするか小さくするかの問題でなく、間違った言葉を正しい言葉に変換する必要があります。
# object型のみを抜き出して新しいデータフレームにする
house_price_obj = house_price.loc[:,(house_price.dtypes == 'object')]
# カテゴリ数を求める
uq_cat_num = house_price_obj.apply(lambda x: len(pd.unique(x)))
# 最もカテゴリの数が多い変数を見つける
# print(int(np.where(uq_cat_num == max(uq_cat_num))[0]))
print(house_price_obj.iloc[:,8].name,'is the biggest value:',len(house_price_obj.iloc[:,8].unique()))Output
===
Neighborhood is the biggest value: 25
===
house_price_objでは最大でも25のカテゴリを持つ変数(Neighborhood)があるだけです。
unique_characters = house_price_obj.Neighborhood.unique()
print(unique_characters)Output
===
[‘CollgCr’ ‘Veenker’ ‘Crawfor’ ‘NoRidge’ ‘Mitchel’ ‘Somerst’ ‘NWAmes’
‘OldTown’ ‘BrkSide’ ‘Sawyer’ ‘NridgHt’ ‘NAmes’ ‘SawyerW’ ‘IDOTRR’
‘MeadowV’ ‘Edwards’ ‘Timber’ ‘Gilbert’ ‘StoneBr’ ‘ClearCr’ ‘NPkVill’
‘Blmngtn’ ‘BrDale’ ‘SWISU’ ‘Blueste’]
===
意図的に誤入力を挿入します。
CollgCr=>CollgCrr
NoRidge=>NoRiddge
Somerst=>Somorst
左が正しいもので右が誤入力とします。
上の単語が含まれている部分を探索します。条件に含まれる中で、各々一番若い番号を表示します。
print(list(house_price_obj.loc[(house_price_obj.Neighborhood == 'CollgCr'),'Neighborhood'].index)[0])
print(list(house_price_obj.loc[(house_price_obj.Neighborhood == 'NoRidge'),'Neighborhood'].index)[0])
print(list(house_price_obj.loc[(house_price_obj.Neighborhood == 'Somerst'),'Neighborhood'].index)[0])Output
===
3
5
7
===
print(house_price_obj.loc[3,"Neighborhood"])
print(house_price_obj.loc[5,"Neighborhood"])
print(house_price_obj.loc[7,"Neighborhood"])Output
===
CollgCr
NoRidge
Somerst
===
誤入力の値を挿入します。
house_price_obj.at[3,"Neighborhood"] = "CollgCrr"
house_price_obj.at[5,"Neighborhood"] = "NoRiddge"
house_price_obj.at[7,"Neighborhood"] = "Somorst"変更できたかを確認しましょう。
print(house_price_obj.loc[3,"Neighborhood"])
print(house_price_obj.loc[5,"Neighborhood"])
print(house_price_obj.loc[7,"Neighborhood"])Output
===
CollgCrr
NoRiddge
Somorst
===
unique_characters = house_price_obj.Neighborhood.unique()
print(len(unique_characters))Output
===
28
===
誤入力の3つ分だけカテゴリが増えたことがわかります。誤入力を直す一般的な方法は正しい値へと置換することです。
辞書型のデータを用意し、キーに、現在データフレームに含まれている値、ハッシュを置換後の値として定義してあります。
※{古い値: 新しい値}と考えることもできます。
error_dict = {
'CollgCrr':'CollgCr',
'NoRiddge': 'NoRidge',
'Somorst': 'Somerst',
}データフレームの値が辞書のキーに相当する値を含む場合には、正しい値で置換します。置換をするためにはreplaceを使うことになります。置換済みのデータフレームをhouse_price_fixとしましょう。
house_price_fix = house_price_obj.replace(error_dict)unique_characters = house_price_fix.Neighborhood.unique()
print(len(unique_characters))Output
===
25
===
置換することにより、誤った入力を正しい値に修正することができました。
この文字列修正は、値が誤っている場合だけでなく、無駄な情報を含んでいる場合にも使います。例えばWebスクレイピングした情報は、不要な改行やスペース、特殊文字を含み、綺麗なデータで取得することができない場合があります。そのような場合にもreplaceを用いて値を整えることが可能です。
replaceの詳しい使い方についてはこちらをご覧下さい。
4.5欠損値や外れ値
欠損値とは、簡単に言えば変数内で値が存在しないこと。
厳密に言えば、値が存在しないだけでなく、その変数が本来もつべき値でない値を持つ場合にも欠損値となります。例えば、気象観測システムが何らかの原因で、風速を正しく計測できなかった場合には-999のような異常値をデータとして残す場合があります。データの要約情報を眺めたとき、このようなあり得ない異常値は基本的に欠損値として扱えます。
しかし、不慣れな領域のデータを扱う場合には、それが本当に欠損値かどうかは公式文献に基づいて判断を下す必要があります。
例えば、MODISは衛星に搭載されている光学センサです。そこでの欠損値はデータの種類によって指定された数値が異なります。このような場合には、衛星データに詳しくない限り、何が正しい値なのか判断するのが困難です。このような場合には、公式の説明書を利用することを忘れてはなりません。
以下では簡便にするため、NaNやNullのような値だけを欠損値として考えています。
異常な値を見るにはdescribe()、欠損値の数についてはinfo()により眺めることができます。加えて、欠損値であれば、isnull()を使うことにより、指定した変数が欠損値を含むのかを判断することが可能です。
# 表示する最大列数を13にする
pd.options.display.max_columns = 13house_price[house_price.MasVnrType.isnull()]欠損値を含む行を削除する場合にはdropna()を使うことになります。
subsetオプションで変数名を指定すれば、その変数内で欠損値を含む行のみを削除することになります。変数名は複数選択することができます。変数を複数選択すると、どちらかの変数が欠損値を含めば、その行がデータから削除されることになります。
house_price.dropna(subset=[‘MasVnrType’])
欠損値はヒートマップで視覚的に示すことも可能です。欠損のパターンを掴むにはこちらの方が向いています。
# 描画に必要なライブラリをインポートします。
import seaborn as sns
import matplotlib.pyplot as plt # 図の黄色部分が欠損値がある場所
plt.figure(figsize=(18,8))
sns.heatmap(house_price.isnull(),cbar=False,yticklabels=False,cmap = 'viridis');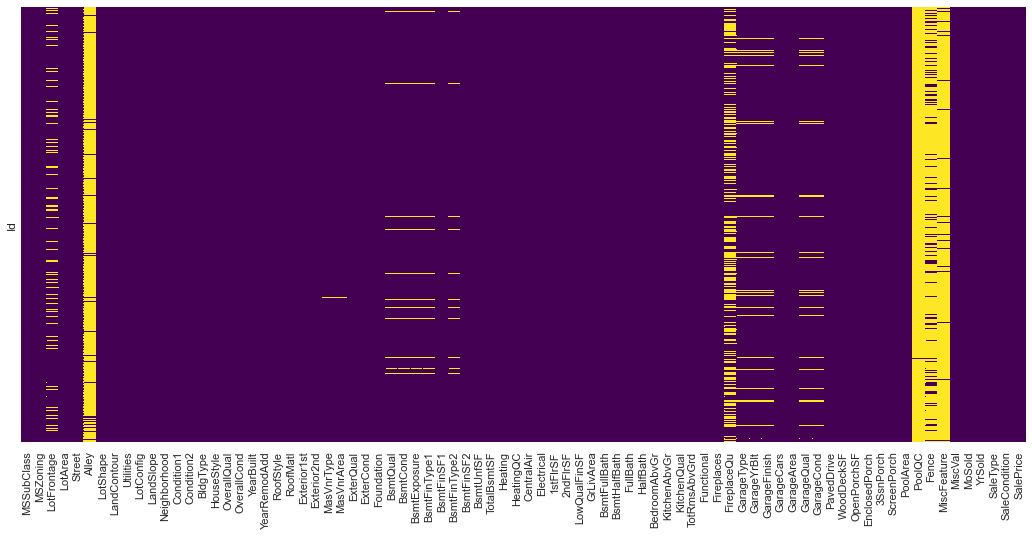
実際のデータ解析において、欠損値を省くかどうかは難しい問題となります。全体のデータから見て欠損値が数パーセントであり、データの補完が難しいということであれば解析に含めないという判断にはなりやすいです。
しかし、欠損値が10%を超えてくるとこれを解析に含めないかどうかは悩ましくなり、何とかしてデータの補完をしなければならない、という気持ちが強くなります。
データが簡単に補完できるものかは、欠損値の数と、それがどのようなパターンで出現するかに依存しています。欠損値が多過ぎる場合、直感的に補完が難しくなると想像できますが、後者の欠損のパターンについてはさらに考える必要があります。
基本的に欠損値の出現がランダムであれば、補完は難しくはありませんが、ランダムでない、一定のパターンで出ると補完は難しくなります。簡単に言ってしまえば、欠損値の数が全体の中でそれほど多くなく、出現がランダムであれば、その前後のデータから空いた部分を埋めることができます。
しかし、データの欠損が一週間以上連続で出てくるなどど言う場合には、前後の値がなくなるため、そこからデータを推測することは難しくなります。非常に有名なデータ補完方法としてMICEがありますが、これもランダムでない欠損値を扱うことはできません。
MICEについて詳しくはこちらの文献をご覧下さい。
別の方法としては、データの補完を行うために推測モデルを用意することも考えられます。今回は欠損値をどのように埋めるのかに対しては概要を説明するだけに留めますが、非常に面白い分野なので興味のある方は、是非興味を持って文献を漁ってみてください。
※欠損値取り扱い専門家の方がいらっしゃいましたら宙畑で記事を執筆いただけますととてもありがたいです
続いて、外れ値について調べて見ましょう。

異常な値は欠損値の場合もあれば、外れ値の場合もあります。大きな違いは、値が正常な範囲の中での変動であるが(例えば、日本の気象データを扱った場合、気温が-100度であれば欠損値として考慮できますが、-30度であれば想定される範囲内)、データ全体として考えた時、明らかにおかしいという値になります。
外れ値はdescribe()などを利用して観察する場合と、モデルを通して観察する場合があります。今回は箱ヒゲ図を用いて簡単に外れ値を確認します。
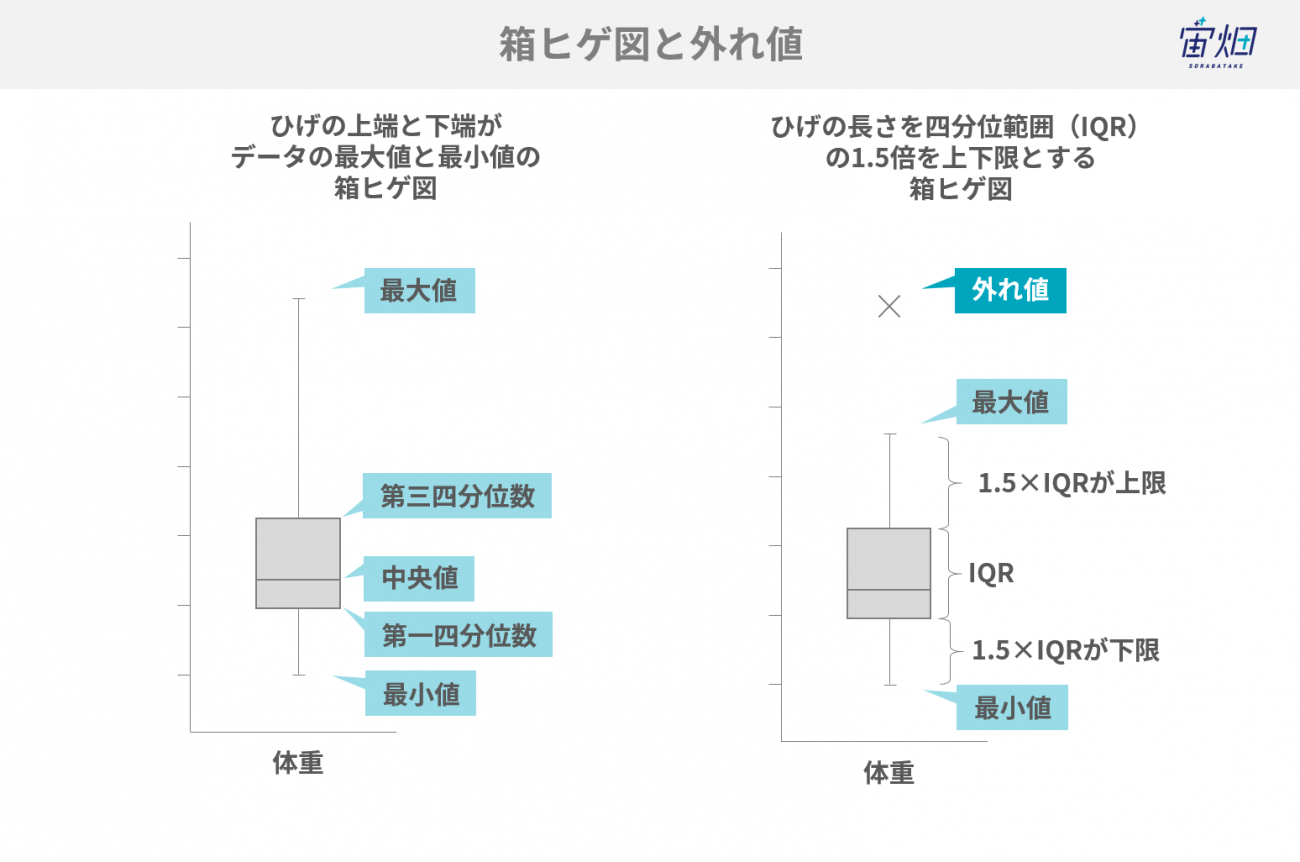
箱ヒゲ図はある変数に対するデータの分布を捉えるもので、ヒストグラムや棒グラフ(バープロット)のようにEDAの過程でよく用いられます。上の例では体重の分布を見ています。箱から伸びる線分(ヒゲ)内であればデータは外れ値でないと判断されますが、ここから外れた場合は外れ値と考えることになります。
上記の図の通り、箱ヒゲ図は五つの要素で成り立っています。
1.最小値
2.第一四分位数(25パーセンタイル)
3.中央値(50%)
4.第三四分位数(75パーセンタイル)
5.最大値
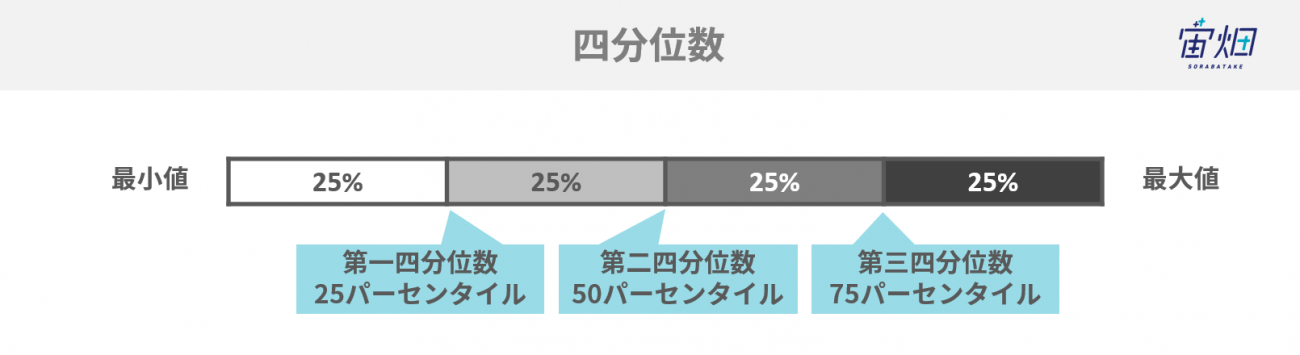
ヒゲの最小値と最大値は図の通りの式で求められます。IQRは四分位範囲と呼ばれるもので,
「75パーセンタイル(第三四分位数)-25パーセンタイル(第一四分位数)」
を意味します。箱ヒゲ図から、データの大体の分布がイメージできます。中央値が下側に偏れば、データは左側に山があり、ヒゲが右に長く伸びれば、データは裾が右側に長く伸びているということです。
一つ目にはpandas+matplotlibで箱ヒゲ図を描画します。
house_price.boxplot(column = 'SalePrice', by='MSZoning',figsize=(10,5))
title_boxplot = 'MSZoning vs. Sale Price'
plt.title(title_boxplot)
plt.suptitle('')
plt.show();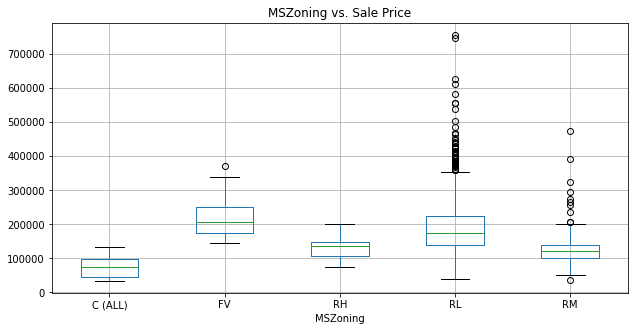
二つ目はseaborn+matplotlibです。
plt.figure(figsize=(10,5))
sns.boxplot(house_price['MSZoning'],house_price['SalePrice']).set_title('MSZoning vs. Sale Price');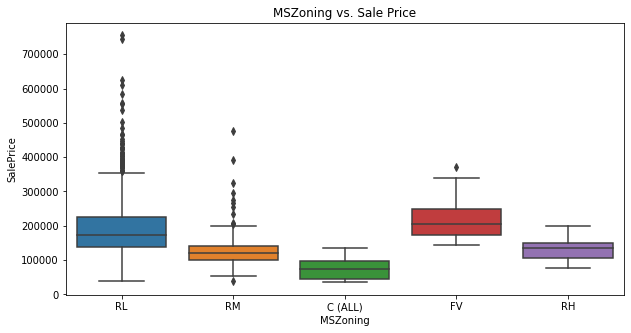
数値データだけを抽出して全ての箱ヒゲ図を描画して見ましょう。変数が多いとやや見通しが悪くなりますが、全体の分布を眺めるには便利です。
# object型のみを除外したデータフレームを作成する。
house_price_num = house_price.loc[:,(house_price.dtypes != 'object')]整数値の中にも単に文字情報の代替として用いられているものがあります。そのためこれらを除いたものを再びhouse_price_numとして作成します。
num_vars = list(house_price_num.columns.values[[1,2,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,25,26,27,28,29,30,31,32,33,36]])
house_price_num = house_price_num[num_vars]var_names = house_price_num.columns.values
number_of_columns=int(len(var_names)/2)
number_of_rows = len(var_names)-1/number_of_columns
plt.figure(figsize=(number_of_columns,5*number_of_rows))
for i in range(len(var_names)):
plt.subplot(number_of_rows + 1,number_of_columns,i+1)
sns.set_style('whitegrid')
sns.boxplot(house_price_num[var_names[i]],orient='v',palette="Set3")
plt.tight_layout(pad=0, w_pad=0, h_pad=1.0)
続いてヒストグラムを使ってデータの分布をとらえてみましょう。ヒストグラムとよく似たものとして棒グラフがありますが、ヒストグラムと棒グラフはやや異なる使い方をされます。ヒストグラムは数量データに使われるのに対して、棒グラフはカテゴリデータに使われます。
house_price_num.SalePrice.plot(kind='hist', bins=20, color='c');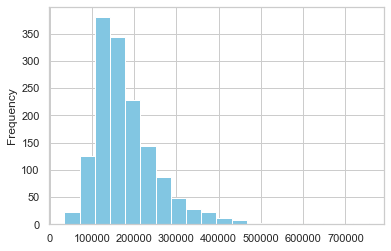
同様に全ての数量データを描画します。
plt.figure(figsize=(2*number_of_columns,10*number_of_rows))
for i in range(len(var_names)):
plt.subplot(number_of_rows + 1,number_of_columns,i+1)
sns.distplot(house_price_num[var_names[i]],hist=True,kde=False,color="green")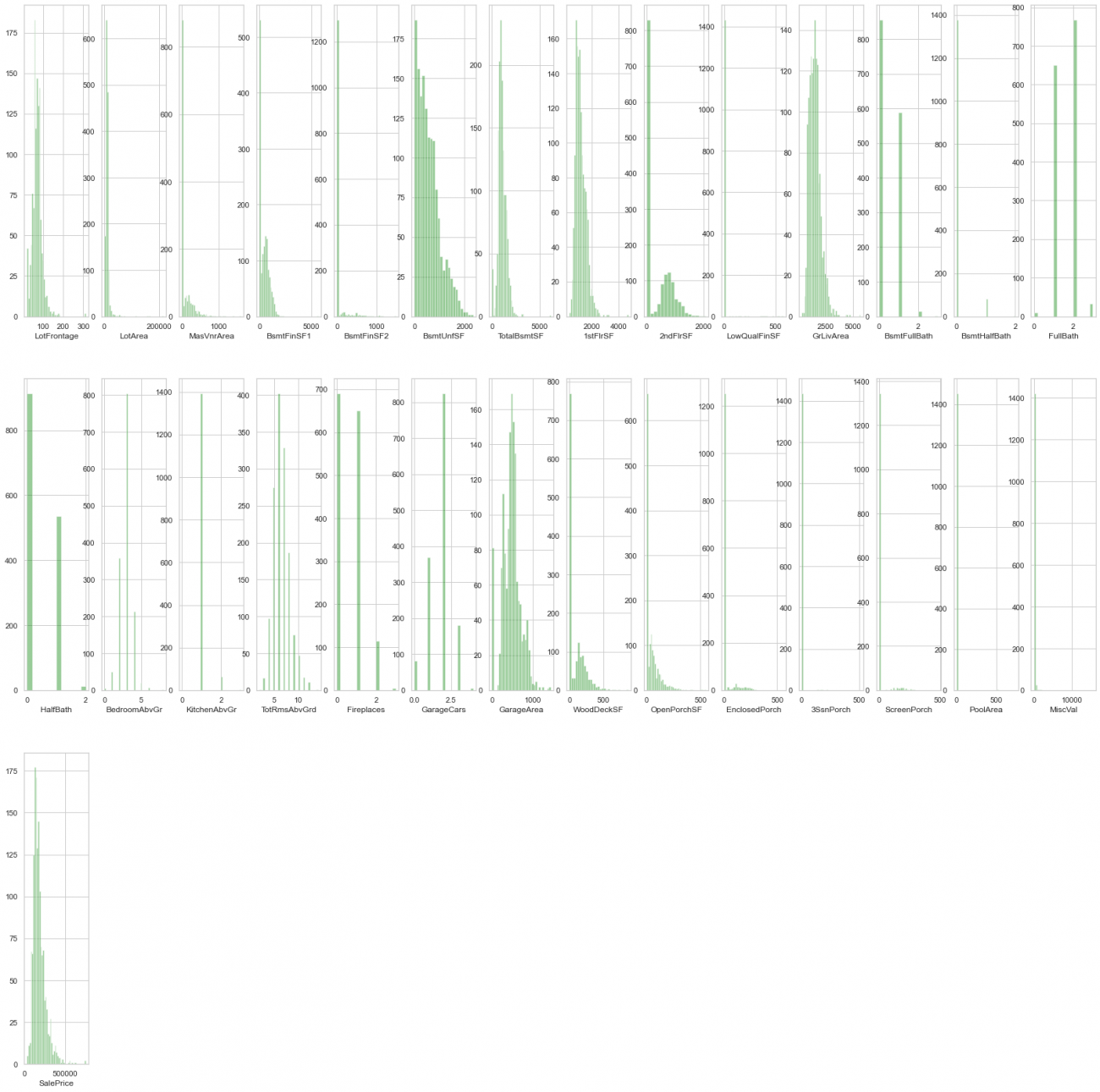
棒グラフの例を示します。
家の屋外に使われている材質が高いか低いかを、家に空調を備わっているかについての関係についてまとめたデータフレームを作成します。size()を使うことにより、組み合わせで生じた数を返し、unstack()でその結果をデータフレームとして表示します。
house_air = house_price.groupby(['ExterQual','CentralAir']).size().unstack()
print(house_air)Output
===
CentralAir N Y
ExterQual
Ex NaN 52.0
Fa 9.0 5.0
Gd 4.0 484.0
TA 82.0 824.0
===
# 変数名の変更
house_air.columns = ['No', 'Yes']# 棒グラフの描画
f, axe = plt.subplots(figsize=(10,6))
axe.set_title('The quality of the exterior material impacts on Central air conditioning')
house_air.plot(kind='bar', stacked=False, color=['r','c'], ax=axe, rot=0)
plt.legend(bbox_to_anchor=(0.2,0.8))# 凡例の位置を変更
plt.show();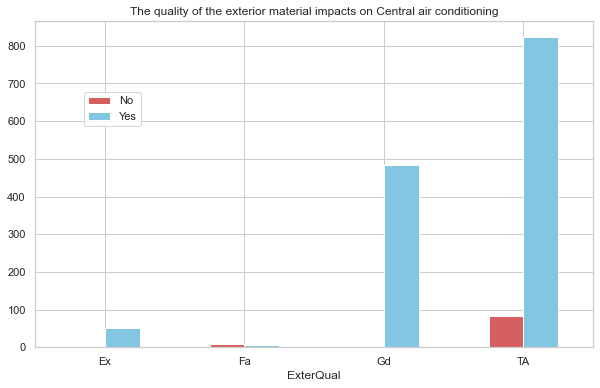
ヒストグラムも棒グラフも扱うデータが数量かカテゴリという差があるだけで、データの散らばりを見るという点では全く同じ働きをしています。
外れ値や欠損値の中にデータの可視化も含めて説明しましたが、このような描画は単に外れ値や欠損値を見つけるだけでなく、それぞれの変数がどのような特徴を持っているのかを把握する場合に非常に重要です。例えば、データの正規性(normality)が仮定されているような解析において、データが偏った分布をとっていれば、なんとかして正規性を持ったデータに近づけるか(データの対数変換など)、別の方法で対処するかなど(例えばノンパラメトリック)を判断することができます。
ここではEDAについて網羅しているわけではありません。しかし、機械学習や統計解析を行うにあたり、データ収集からEDAまでの流れは極めて重要な部分になります。そもそも解析に不適切なデータを集めてしまいえば、得られる結果は意味のないものになりますし、データが目的に合っていても、その中身を精査しなければ期待通りのモデルを作成することはできません。
整えられたデータが手に入り易くなった一方で、まだまだデータの整理が甘い分野や国もあります。データを集めて観察する力は、まだまだ大事な部分であると言えるでしょう。
(5)ライブラリのTips
本章では3つのライブラリTipsをご紹介します。
6.1:ライブラリのバージョン確認
ライブラリのバージョン確認は以下のように行います。
import pandas as pdprint(pd.__version__)Output
===
1.0.3
===
6.2:ライブラリのパス確認
ライブラリのパスの確認は以下のように行います。
確認方法①
print(pd.__file__)Output
===
/usr/local/lib/python3.7/site-packages/pandas/__init__.py
===
確認方法②
import os
path = os.path.abspath(pd.__file__)pathOutput
===
‘/usr/local/lib/python3.7/site-packages/pandas/__init__.py’
===
ライブラリのディレクトリ確認
ライブラリのディレクトリの確認は以下のように行います。
path = os.path.dirname(pd.__file__)pathOutput
===
‘/usr/local/lib/python3.7/site-packages/pandas’
===
以上、3つのライブラリに関するTipsをご紹介しました。
(6)まとめ
かなり長くなってしまいましたが、これでデータサイエンスで用いる基本ライブラリの説明を終わります。
データを実際に解析する場合には、他にも様々なライブラリを利用する必要がありますので、それらはまた別の記事で紹介します。
宙畑の機械学習関連記事
【保存版】課題から探すAI・機械学習の最新事例57選
Kaggle上位ランカーの5人に聞いた、2019年面白かったコンペ12選と論文7選
【Kaggleコンペ解説連載】衛星データから雲を理解する! 上位入賞者の手法解説
【Kaggleコンペ解説連載】衛星画像による海氷と船舶の識別
世界的な機械学習プラットフォーム「Kaggle」の概要と衛星データコンペ事例まとめ
「Tellus」で衛星データを触ってみよう!
日本発のオープン&フリーなデータプラットフォーム「Tellus」で、まずは衛星データを見て、触ってみませんか?
★Tellusの利用登録はこちらから
