【Kaggleコンペ解説連載】衛星データから雲を理解する! 上位入賞者の手法解説
データサイエンスコンペkaggleで実施された、衛星データの雲分類について、上位入賞者3名の解析手法について解説します。
データサイエンス、特に深層学習を含めた機械学習の技術は日進月歩で発展しています。常に最新の手法を学ぶ必要があり、どの問題に対して何の手法が効果的かを知るには、本やWebサイトで情報を得るだけは限界があります。「百聞は一見に如かず」で、どんどんデータを触ることが一番の近道。
最近ではデータサイエンスコンペティション(コンペ)が世界中で行われており、最も代表的なのは「Kaggle」でしょう。宙畑では、Kaggleの中でも衛星データをテーマに扱ったコンペを中心に上位入賞者の解説をする連載を「Kaggleコンペ解説」を更新中。本記事はその第2弾として、2019年に行われた「Understanding Clouds from Satellite Images(衛星データから雲を理解する)」を解説します。
(1)記事概要3行解説
1.衛星画像に写っている雲のラベルを予測するモデルを作成するKaggleコンペ
2.「雲」という境界が曖昧なデータに対しての検出+予測
3.空の領域(ラベルが振られていない領域)をどのように検出するかという点で、セグメンテーションモデルをどのように利用させるかが鍵
(2)「衛星データから雲を理解する」コンペの概要
あらためて、今回解説するKaggle コンペはこちら、「Understanding Cloud From Satelite Images」です。
直訳すると「衛星データから雲を理解する」なのですが、あらためて雲について知っていることが何かと問われると、思い浮かぶことが少ない……。ググってみたところ、雲は大分類で10種類あり、さらに細かく分類することもできるそう!(※1)
※1:雲の種類について
たしかに、種類によって「あーあの雲は雨が降る雲だ」とか「あの雲は雨が降らない雲だ」とか習ったなーと。
では、本題に入ります。まずは、今回解説するコンペが実施される背景から。
雲は地球の放射バランスに大きな役割を果たしていますが、気候モデルではあまり表現されていないそう。また、雲の輪郭の境界ってすごく曖昧なので、ルールベースでの分類が難しく、いざ気候モデルで雲の影響を図ろうとしても、分析に必要なデータ収集(ラベル付与)の部分でネックになってくるそう(※2)です。
※2:雲の分類について
そこで、実際の雲の画像から、その雲がどのような形か、という事を正しく分類出来るようになれば、雲が気候に対してのどのような影響が与えられているか、その雲が将来的にどのような影響を与えるのかの研究が進むかも、というのが今回のコンペの背景でした。
(3)利用データについて
本コンペ「Understanding clouds from satelite Images」で参加者に提供されているデータは下記のとおりです。
・train.csv
・train_images.zip
・test_images.zip
・sample_submission.csv
⇒合計6GB
NASAの衛星データから取得をした画像を今回の学習及び検証に利用します。
また、学習や検証に利用する衛星データには少なくとも1種類は下記の形に分類される雲が写っています。
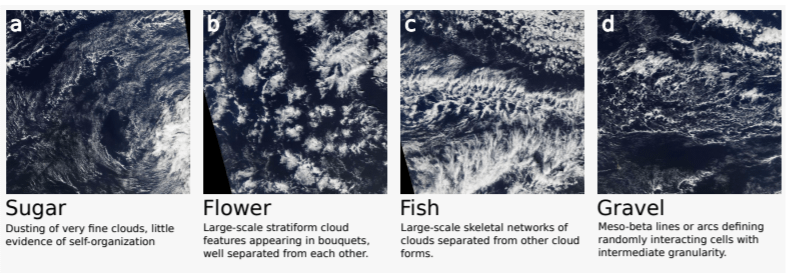
1枚の写真の中に、複数のラベルが紐付く事もあり、1種類も紐付かない事はありません
データのイメージとしては下記の通り。
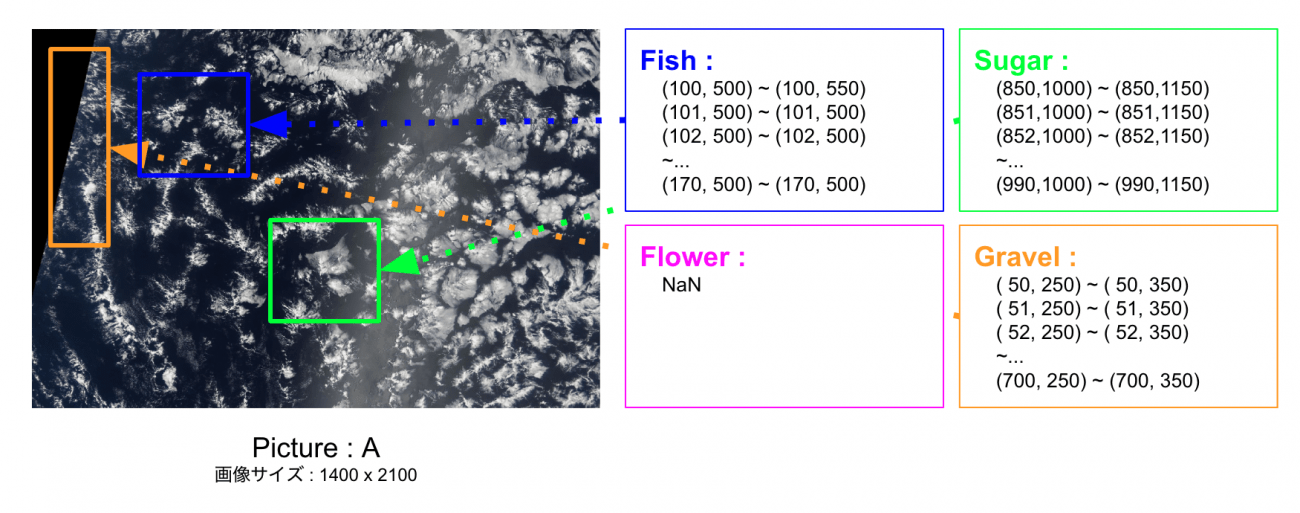
実際には、一枚の写真の中で、以下のようにラベルの領域が区切られるイメージです。

また、実際のtrain.csvに入っているラベル件数はそれぞれ以下のようになります。
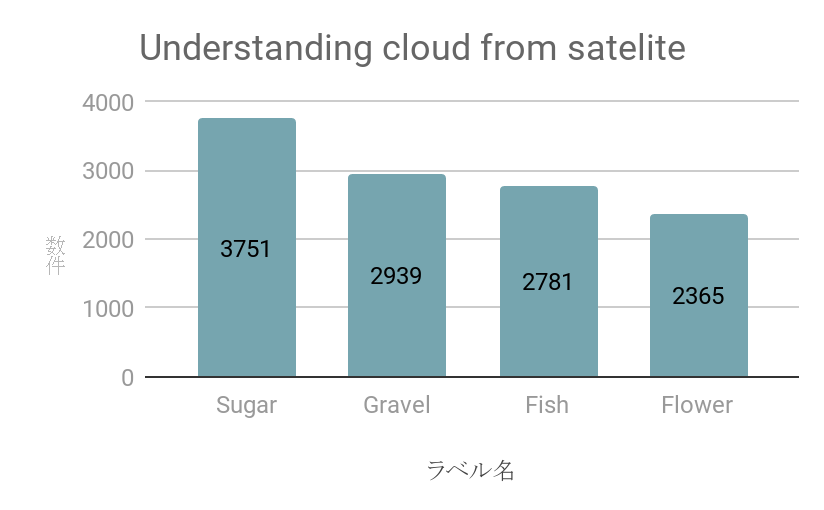
Sugarのラベルがやや多めですが、比較的突出してどれかのラベルの件数が多いというわけではないようです。
(※領域Pixel = NaN を除く)
(4)上位入賞者の手法解説
では、いよいよ本題の上位入賞者の手法解説へ。本コンペは 2019/11/19 に終了しており、本記事では、賞金を獲得できる3チーム(それぞれ1名ずつ)の手法を解説します。
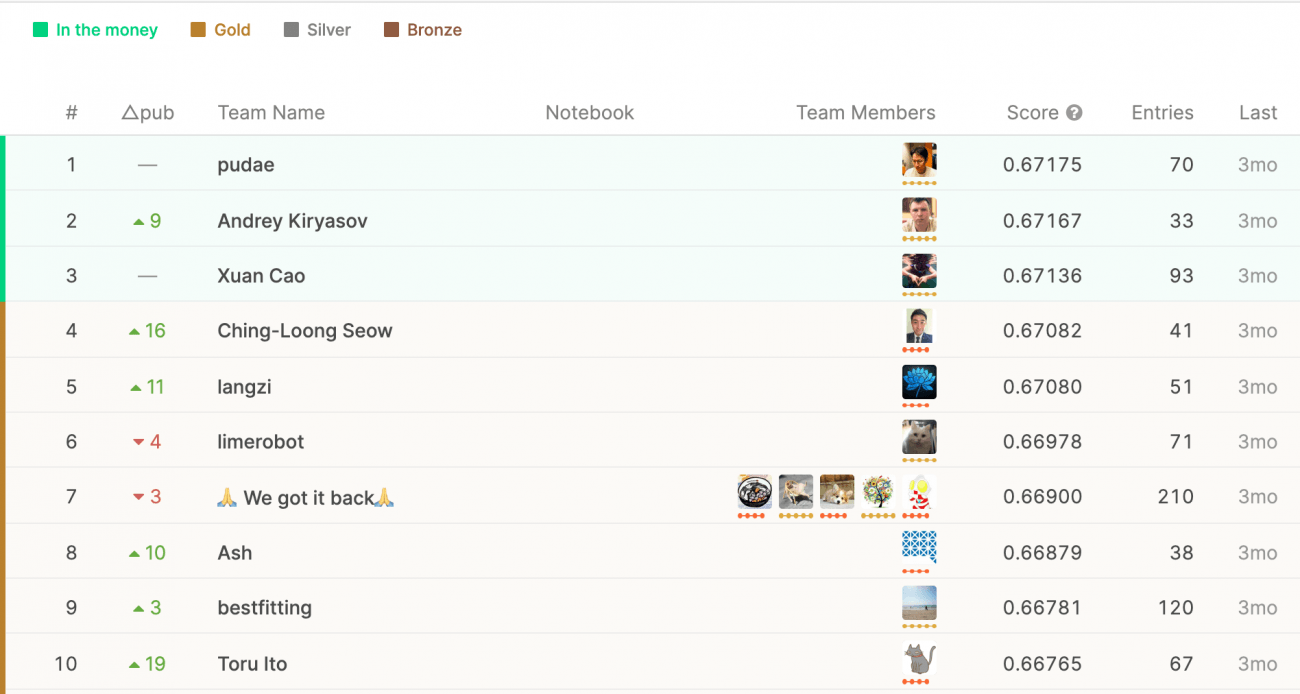
3rd : Xuan Cao : Score / 0.67136
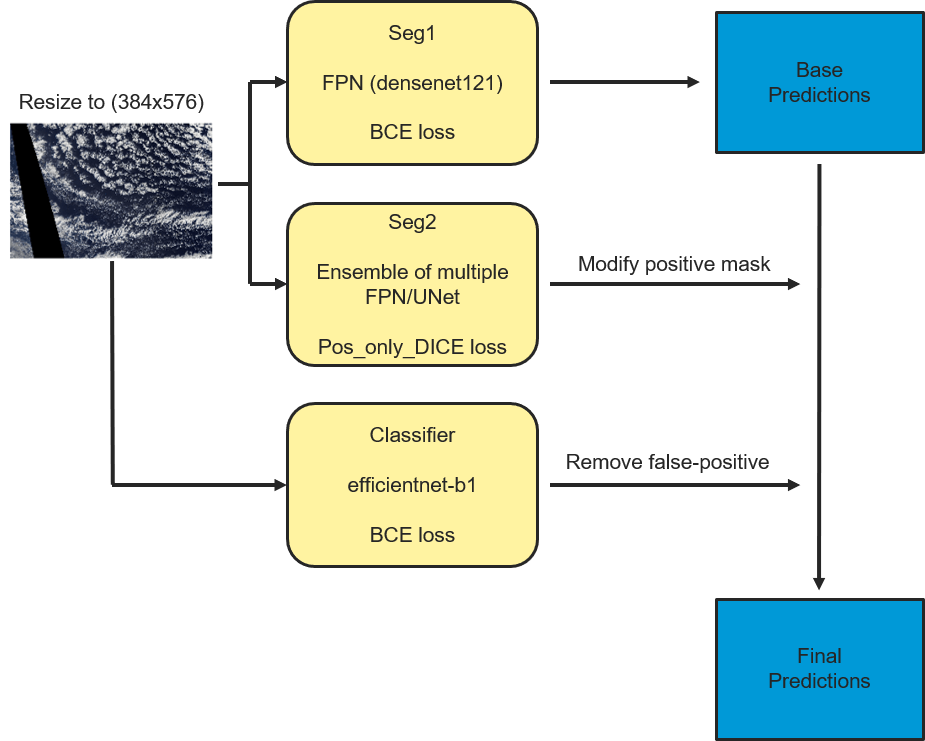
今回のコンペにおいて3位だったXuanCaoさんは、大まかに3つのモデルを利用することで見事3位のスコアを記録することが出来たようです。
Seg1 : BCE(Binary Cross Entropy)損失関数を定義した、マルチラベルセグメンテーションモデル
-Densenet121
Seg2 : SoftDice損失関数を定義し、下記の4つのモデルアンサンブル学習を行い、各画像のマルチラベルセグメンテーションを学習させているモデル
-b5-Unet | InceptionResnetV2-FPN | b7-FPN | b7-Unet
CLS : BCE(Binary Cross Entropy)損失関数を定義した、マルチクラス分類モデル(※3)
※3:EfficientNetについて
モデル2で利用されている Dice損失 は、一般的な画像認識モデルにおいて一般的に利用されている損失関数です。
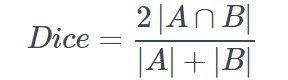
[ピクセル毎に出力した推測値と実ラベルとの一致度]と[実際にはラベルが振られていない領域をちゃんと0と推測しているか]を計算しています。
また、今回出てきているのはSoftDice損失になっており、 上記の式に -1 を付け加えてあげると SoftDice損失になります。
一般的に画像解析に利用される手法として大まかに分類すると「画像分類」「画像検出」「画像セグメンテーション」に分ける事が出来ます。
今回利用されているセグメンテーションモデルとは、画像全体や画像の一部の検出ではなくピクセル1つ1つに対して、そのピクセルが示す意味をラベル付けしていく手法になります。
Xuan Caoさんが下記のようにコメント欄で記載をされていますが、評価関数である DICE損失の特性である、「ラベルが振られていない領域の検出」「ラベルが振られている領域を精度良く予測する」を上手く表現したモデルを作成されたように感じます。
===
The key in my solution is training two segmentation models.
seg1 trained on all data with BCE loss, and seg2 trained on non-empty images only with soft DICE loss.
I think it works because this competition basically has two tasks
1) detect the empty images
2) predict accurate masks for the non-empty images.
The two segmentation models address these two tasks respectively.
【和訳】
私のソリューションの鍵は、2つのセグメンテーションモデルをトレーニングすることです。
seg1はBCE損失のあるすべてのデータでトレーニングされ、seg2はソフトDICE損失のある空でないイメージでトレーニングされます。
このコンテストには基本的に2つのタスクがあるため、うまくいくと思います。
1)空の画像を検出する。
2)空でない画像の正確なマスクを予測します。
2つのセグメンテーションモデルは、これらの2つのタスクにそれぞれ対処します。
===
コンペにおける評価値(DICE関数)をきちんとくみ取り、「ラベルの振られていない部分の識別」と「ラベルが振られている部分の正確な予測」をそれぞれのタスクに分割し、それらに適応するモデルを構築出来た末の結果になったように思います。
2nd : Andrey Kiryasov : Score / 0.67167
・LeaderBoard
・Github(セグメンテーションモデルの構築に利用したモジュール)
Andrey Kiryasovさんは、今回のコンペに参加する以前に
・SIIM-ACR Pneumothorax Segmentation
・Severstal: Steel Defect Detection
の2つに参加しており、事前にこれらの問題に対しての知見を持っていたとの事です。
今回のコンペでは8モデル によるアンサンブル学習を施していました。
これらのモデルパラメータの組み合わせは、予測間の相関が可能な限り最小になるモデルを利用しています。
予測間の相関が最小のモデル同士をアンサンブル学習に利用することで、各モデルの出力した予測値を補完しあう事を期待しているのだと推測されます。
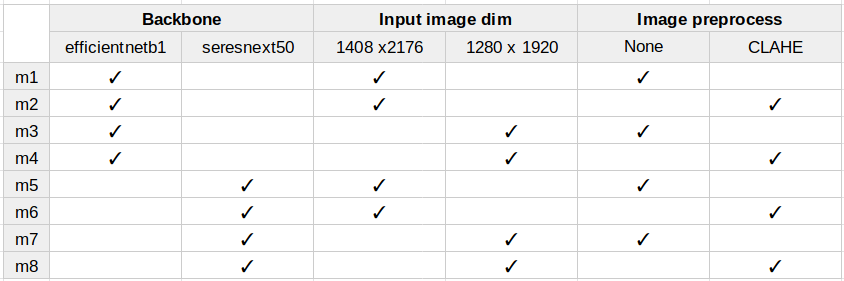
また、こちらのモデルでは与えられた画像サイズ(1400 x 2176 x 3)をそのままモデルに投入する事は良い方法では無いと考え、安易に画像のリサイズをするのではなく、下記の通り、BackBoneへの投入前に上記のConv2D層を挟む事で、入力された画像を畳み込みによる特徴抽出をしつつ画像サイズの変更をしているようです。

BackBornに投入される頃には 1400 x 2176 x 3 から 352 x 544 x 3 にリサイズされた情報に圧縮されています。
ここで出てきたBackBoneとはセグメンテーションモデル内部でエンコーダーとして利用されるモデルを指します。
さらに、上記以外でも様々な手法を試したようですが、良い結果を得る事が出来なかったようです。
良い結果を得られなかった事に対しての考察ですが、今回のコンペにおいては、ラベルが振られていない箇所への予測精度がスコアに差が付いた要因なのではないかと考えております。
また、Andrey Kiryasovさんも Leader Board の中で下記のように発言をされていました。
===
All tasks for segmenting objects with a DICE metric are very sensitive to FalsePositive errors. In some cases, training a separate classifier model for detect of a mask in the image very helps.
【和訳】
DICEメトリックでオブジェクトをセグメント化するすべてのタスクは、FalsePositiveエラーに非常に敏感です。 場合によっては、画像内のマスクを検出するために別の分類子モデルをトレーニングすると非常に役立ちます。
===
手法ももちろん大事ですが、いかに正しい目的や役割を持たせたモデルを構築できるかが鍵になったようです。
1st : pudae : Score / 0.67175
最後に 1st prize を取得された手法です。
こちらも 2つのモデルの アンサンブル学習になっております。
・Model A: UNet を利用した クラス分類 モデル
-BCE(Binary Cross Entropy) を定義
・Model B: FPN または UNet を利用した セグメンテーションモデル
-BCE(Binary Cross Entropy) * 0.75 + DICE * 0.25 の損失を定義
Githubを覗いてみるとModel Aは3つのモデル、Model Bは9つのモデルのアンサンブル学習をしているようです。
AとBのそれぞれの学習されたモデルについて、全部のパラメーターではなく、いくつかのパラメータをかいつまんで紹介したいと思います。
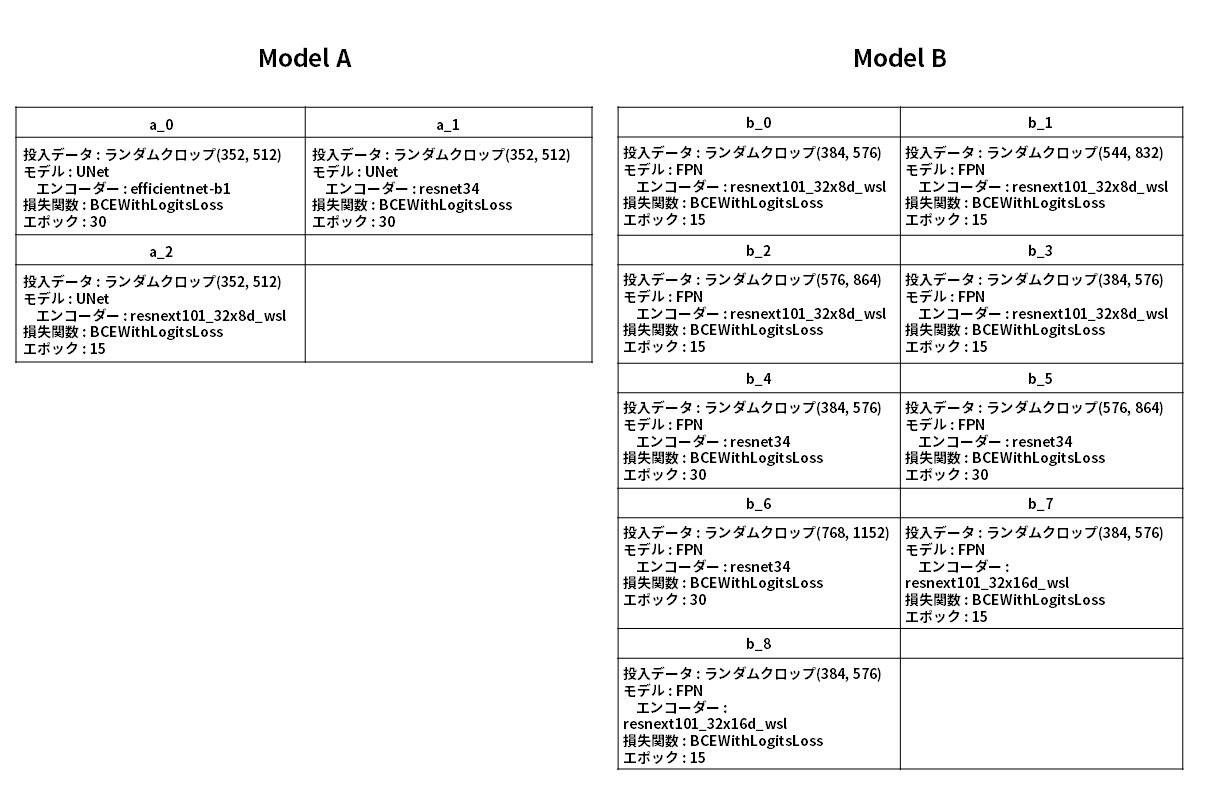
凄い……なんというか……凄い…..。.
それぞれエポック数にも違いがあるのが面白いですよね。ランダムクロップのサイズを変えてあげるであったり、モデルの複雑性を上げる、下げる等は想像が付くのですが…
比較的複雑なモデルに対しては 15エポック で、比較的単純なモデルに対しては 30エポック での学習を行っているようです。
LeaderBoardで議論がされていますが、その中でpudaeさんは下記の用に説明をされていました。
===
私の場合、15を超えるエポックをトレーニングすると、より深いモデルが簡単にオーバーフィットしました。そこで、約15エポック以内でモデルを訓練するために学習率をスケジュールしました。
===
また、最初から Model A 3 モデル と Model B 9 モデル によるアンサンブル学習をやっていたのではなく、今回のコンペが始まって約2週間ほどは、クラス分類モデルのみによる精度の改善を試行していたようです。
しかし、精度の改善があまり見られず、原因を考察した所、セグメンテーションのパフォーマンスが低いためだと考え、より強力なセグメンテーションモデルを用意し、BackBoneを変えたり、画像のサイズを変えたりしながら、様々な事を試行錯誤し今回の結果に繋がったとの事です。
また、アンサンブル学習においての工夫だけでなく、Model A ではセグメンテーションモデルの精度を利用して、エンコーダーからの出力をデコーダーに渡さず、Global Pooling層を介して シグモイド変換 を行い、出力された値から上位Kピクセルの平均を利用しているようです。
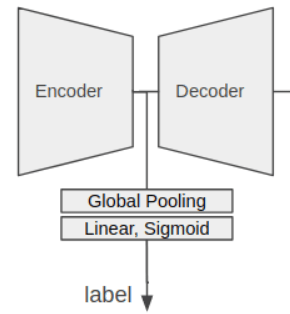
完璧に理解には出来ていませんが、GitHubのコードを見た限りだと、対象のラベルに対しての Model B によるセグメンテーションモデルの推測領域の確からしさを Model A による確率推測で行っているのではないかと思います。
またセグメンテーションモデルの性能を利用した分類モデルへの適用についてはコメント欄でこのように議論がされておりました。
===
Using segmentation models as classifiers is smart. In my experiments, I found that segmentation models could predict empty masks more accurately than a classification model trained on labels only. Doing “use max probability as a positive prediction” is a great trick
【和訳】
セグメンテーションモデルを分類子として使用するのは賢明です。 私の実験では、ラベルのみでトレーニングされた分類モデルよりも、セグメンテーションモデルが空のマスクをより正確に予測できることがわかりました。 「正の予測として最大確率を使用する」ことは、素晴らしいトリックです。
===
(5)まとめ
以上、Kaggleコンペ「Understanding clouds from satelite Images」の解説でした。
様々な手法を利用し、得られた結果から上手くいっていない原因を推測し、それらを解決するために真摯にデータに向き合った軌跡がより明らかになり、筆者個人として負けたく無いなと切に思った次第です。
(あとマシンパワー凄そう……とか、計算にかかった時間……など、凄く気になることも)
また、詳細な部分を上手くまとめる事が出来ておらず、本当の魅力(あーそんな方法があったのか……などの気付き)を伝え切れたのか不安ではありますが、ぜひご興味を持っていただけた方は、記載させて頂いたLeaderBoardの方まで是非見に行って頂けますと幸いです。
