CNNを使って衛星データに雲が映っているか否か画像分類してみた
宙畑編集部による衛星データを活用していろいろ遊んでみようという連載「宇宙データ使ってみた」にて、ついに機械学習にチャレンジしてみました!
記事作成時から、Tellusからデータを検索・取得するAPIが変更になっております。該当箇所のコードについては、以下のリンクをご参照ください。
https://www.tellusxdp.com/ja/howtouse/access/traveler_api_20220310_
firstpart.html
2022年8月31日以降、Tellus OSでのデータの閲覧方法など使い方が一部変更になっております。新しいTellus OSの基本操作は以下のリンクをご参照ください。
https://www.tellusxdp.com/ja/howtouse/tellus_os/start_tellus_os.html
今やビジネスの現場で当たり前のように使われるようになってきたAI(人工知能)。
衛星データの利用においても、機械学習や深層学習(ディープラーニング)といったAI技術の存在感が年々強まっています。
我々宙畑編集部も「AIはなんだか難しそうで……」なんて言っている場合ではありません。
来たるべきAI時代に備えて今から少しでも勉強をしていかなければ業界から取り残されてしまう……。
ということで、何はともあれ大事なのは実際にやってみること。
本記事では、宙畑編集部がAI×衛星データにチャレンジする様子を(悪戦苦闘するところまで含めて)ご紹介いたします。
※本記事は宙畑メンバーが気になったヒト・モノ・コトを衛星画像から探す不定期連載「宇宙データ使ってみた-Space Data Utilization-」の第18弾です。まだまだ修行中の身のため至らない点があるかと思いますがご容赦・アドバイスいただけますと幸いです!
1)AIでやることを決める
まずはAIを使って何をするか、から考えます。車や建物の検出、閾値の推定、ノイズ除去……etc.
衛星データ利用を考える際、AIにやって欲しいことはたくさんあります。ですが最初から難しいことにチャレンジすると、初心者では扱いきれず中途半端に頓挫してしまいかねません。
考えた結果、画像の中に雲を含んでいるか否かのシンプルな2値分類に挑戦してみることにしました。
光学センサによる観測はその特性上、見たい地点が写っているシーンを見つけても雲がかかっていて肝心の地上が見えない、なんてことがよくあります。

雲が写っていると同じ地点でも別時刻のデータとの比較が難しくなってしまうため、雲の有無で画像を仕分けることができれば、解析する際にきっと役立つことでしょう、ということで、「果たしてこれは簡単なのか……!?」は分からないまま、分からないなりに進めてみます。
2)AVNIR-2のタイル画像を取得する
まずは分類する衛星画像を取得しましょう。今回はAVNIR-2という光学センサのデータで挑戦します。
Tellusで取得できるAVNIR-2のシーンからランダムに30ほどピックアップして、ズーム率12でタイルを切り出し保存します。
以降の内容はすべてTellusの開発環境(Jupyter Lab)で実行します。
Jupyter Labを使う方法は「Tellusの開発環境でAPI引っ張ってみた」をご覧ください。
import os
import requests
import math
from skimage import io
from io import BytesIO
import random
import warnings
import numpy as np
TOKEN = 'アクセストークンを貼ってください。'
DOMAIN = 'tellusxdp.com'
def search_AVNIR2_scenes(min_lon, min_lat, max_lon, max_lat):
url = 'https://gisapi.{}/api/v1/av2ori/scene'.format(DOMAIN)
headers = {
'Authorization': 'Bearer ' + TOKEN
}
payload = {'min_lat': min_lat, 'min_lon': min_lon,
'max_lat': max_lat, 'max_lon': max_lon}
r = requests.get(url, params=payload, headers=headers)
if r.status_code is not 200:
raise ValueError('status error({}).'.format(r.status_code))
return r.json()
def get_AVNIR2_scene_tile(rsp_id, product_id, zoom, xtile, ytile,
opacity=1, r=3, g=2, b=1, rdepth=1, gdepth=1, bdepth=1, preset=None):
# zoom = 8 - 14
url = 'https://gisapi.{}/av2ori/{}/{}/{}/{}/{}.png'.format(
DOMAIN, rsp_id, product_id, zoom, xtile, ytile)
headers = {
'Authorization': 'Bearer ' + TOKEN
}
payload = {'preset': preset, 'opacity': opacity, 'r': r, 'g': g,
'b': b, 'rdepth': rdepth, 'gdepth': gdepth, 'bdepth': bdepth}
r = requests.get(url, params=payload, headers=headers)
if not r.status_code == requests.codes.ok:
r.raise_for_status()
return io.imread(BytesIO(r.content))
def get_tile_num(lat, lon, zoom):
"""
緯度経度からタイル座標を取得する
"""
# https://wiki.openstreetmap.org/wiki/Slippy_map_tilenames#Python
lat_rad = math.radians(lat)
n = 2.0 ** zoom
xtile = int((lon + 180.0) / 360.0 * n)
ytile = int((1.0 - math.log(math.tan(lat_rad) + (1 / math.cos(lat_rad))) / math.pi) / 2.0 * n)
return (xtile, ytile)
def get_tile_bbox(z, x, y):
"""
タイル座標からバウンディングボックスを取得する
https://tools.ietf.org/html/rfc7946#section-5
"""
def num2deg(xtile, ytile, zoom):
# https://wiki.openstreetmap.org/wiki/Slippy_map_tilenames#Python
n = 2.0 ** zoom
lon_deg = xtile / n * 360.0 - 180.0
lat_rad = math.atan(math.sinh(math.pi * (1 - 2 * ytile / n)))
lat_deg = math.degrees(lat_rad)
return (lon_deg, lat_deg)
right_top = num2deg(x + 1, y, z)
left_bottom = num2deg(x, y + 1, z)
return (left_bottom[0], left_bottom[1], right_top[0], right_top[1])
# 日本周辺のシーン情報を取得し、ランダムに30シーン絞り込み
scenes = search_AVNIR2_scenes(120.0, 24.0, 155.0, 46.0)
random_scenes = random.sample(scenes, 30)
# ズーム率12でそのシーンから切り出せるタイル画像をすべて取得する
zoom = 12
for scene in random_scenes:
(xtile, ytile) = get_tile_num(scene['max_lat'], scene['min_lon'], zoom)
x_len = 0
while(True):
bbox = get_tile_bbox(zoom, xtile + x_len + 1, ytile)
tile_lon = bbox[0]
if(tile_lon > scene['max_lon']):
break
x_len += 1
y_len = 0
while(True):
bbox = get_tile_bbox(zoom, xtile, ytile + y_len + 1)
tile_lat = bbox[3]
if(tile_lat 0:
with warnings.catch_warnings():
warnings.simplefilter('ignore')
io.imsave(os.getcwd()+'/tile/{}_{}_{}.png'.format(zoom, xtile + x, ytile + y), img)
except Exception as e:
print(e)上記のサンプルコードを「tile」というディレクトリを作成してから実行してください。
取得が完了するまで数分かかるので気長に待ちます。
するとおよそ3000枚のタイル画像が保存されるはずです。
3)教師データを作ろう
素材は揃いましたが、このままでは機械学習を始めることができません。
AIに「どの画像が晴れていて、どの画像が曇っているか」を教えてあげるための教師データが必要です。
「晴れ」「曇り」「判断に困るもの」の3つのディレクトリを作りましょう。そして3000枚の画像を一つ一つ目で見て、「晴れ」「曇り」を判断し画像を選り分けていきます。

そんな面倒な作業を誰がやるのか? それは人間でやります。つまり、これをやってみたいと思われた場合は、今これを読んでいる読者の皆様の手で行う必要があります。
宙畑編集部でも2人のメンバーが協力してこの作業を行いました。
2〜3時間かけて、ただひたすら画像を選り分けていきます。もう二度とやりたくありません。
分類後の枚数は、今回のケースでは「晴れ」が約600枚、「曇り」が約1000枚となりました(海しか写っていなかったり、一部が見切れてしまっていて学習に適していない画像でした、残念)。
さらに分類した「晴れ」と「曇り」を「学習用」「訓練時検証用」「評価用」の3つに分けておきます。振り分ける枚数はエイヤで決めました。
ディレクトリ構造と枚数の内訳
dataset
┣ train (学習用)
┃ ┣ clear (200枚)
┃ ┗ cloudy (400枚)
┃
┣ validation (訓練時検証用)
┃ ┣ clear (200枚)
┃ ┗ cloudy (400枚)
┃
┗ test (評価用)
┣ clear (200枚)
┗ cloudy (200枚)
4)学習モデルを作ろう
ようやく画像の準備がすべて整ったので、AIのコードを書いていきます。
ネットに資料が豊富なことから、TensorFlow(テンサーフロー)という機械学習のフレームワークと、Keras(ケラス)というニューラルネットワークに特化したフロントエンドライブラリを利用します(どちらもTellusの開発環境にはプリインストール済みです)。
数多あるディープラーニングの手法の中で、画像処理でよく使われるのが「畳み込みニューラルネットワーク(CNN)」というアルゴリズムです。
CNNは2次元データを1次元にバラすことなく(ピクセルの位置関係をそのまま情報として)扱うことができるため画像処理に特化していると言われています。
参考
画像処理でよく使われる畳み込みニューラルネットワークとは
Deep Learning for Computer Vision – Introduction to Convolution Neural Networks
CNNのモデルを作るにあたって、フィルタの数や大きさといったパラメータを決めなければいけません。
このパラメータ設定がCNNの肝で、本来であればエンジニアの腕の見せどころなのですが、初心者にはさっぱりわかりません。
しかたがないので文献をあれこれ見ながらそれっぽい数値を設定していきます。今回はVGG16という有名なモデルを参考に、計算時間が短くなるようなるべくフィルタの数を減らしてみました。
その分精度が出るのか不安ですが、まずはこれでやってみましょう。
from keras import layers
from keras import models
from keras import optimizers
from keras.layers import GlobalAveragePooling2D
# 画像サイズ
input_width = 256
input_height = 256
# 畳み込みニューラルネットワーク
model = models.Sequential()
model.add(layers.Conv2D(64, (3, 3), activation='relu', padding='same',
input_shape=(input_width, input_height, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu', padding='same'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu', padding='same'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(GlobalAveragePooling2D())
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
model.summary()
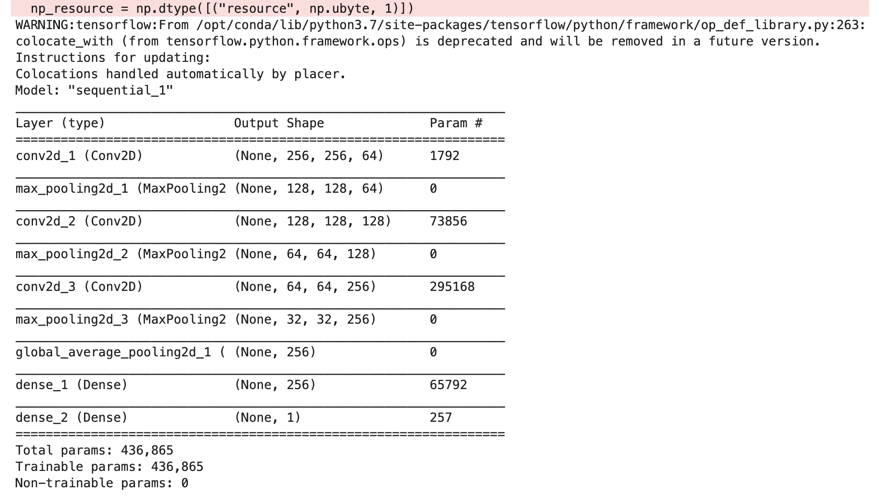
モデルのsummary(WARNINGが出ますが問題ありません)
パラメータの総数は436,865になりました。
モデル生成の次は、「学習用」「訓練時検証用」データを読み込みます。
KerasのImageDataGeneratorという機能を使うと、学習に使う画像の枚数が足りないときはランダムに回転させたり拡大縮小をしてデータを増やしてくれます。
便利ですが、元となるデータは同じなため、あまりに水増しすぎると同じようなデータばかり学習した状態になり、学習用データに対する精度は高まりますが、それ以外のデータに対する精度が下がってしまいます(これを過学習と言います)。
バッチサイズ(1回の計算で利用する画像の数)は学習用データと訓練時検証用データともに30としました。
from keras.preprocessing.image import ImageDataGenerator
train_dir = './dataset/train'
validation_dir = './dataset/validation'
# 回転や拡大縮小によりデータ数を水増し
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=30,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,)
test_datagen = ImageDataGenerator(rescale=1./255)
# 学習用データ読込み
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(input_width, input_height),
batch_size=30,
class_mode='binary')
# 訓練時検証用データ読込み
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(input_width, input_height),
batch_size=30,
class_mode='binary')
ここで「Found {画像の枚数} images belonging to 2 classes」以外の結果が出た場合、不要なディレクトリ(.ipynb_checkpointsなどの隠れディレクトリ)が存在しているかもしれません。そのままでは正しく分類することができないので不要なディレクトリを削除してやりなおしましょう。
5)学習開始
最後に、エポック数(繰り返し回数)とステップ数を決めて学習を開始します。
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=20,
validation_data=validation_generator,
validation_steps=20)
# 処理時間が長いため途中から再開できるようできた学習モデルを保存しておく
model.save('avnir2demo')今回は学習100ステップ、検証20ステップを20回繰り返します。
いざ実行です。
ひたすら計算が終わるのを待ちます。
待ちます。
待ちます。
いつまで経っても終わりません。
待ち続けた結果、完了まで6時間かかりました。
今回計算を実行したのはTellusの一般的な開発環境(CPU4Core, メモリ8GB)です。
これまでちょっとした数値計算をするだけであればこの性能で困ったことはありませんでしたが、ディープラーニングをやるには少々厳しかったようです。
ディープラーニングといえばすぐに「GPUが必要だ」と言われる理由がよくわかりました。
では実行結果を見てみましょう。

最後の行に注目してください。学習を繰り返した20エポック目で「val_acc: 0.8517」、訓練時検証用データで約85%の正解率を達成しています。
また、履歴を見ると10回目の辺りから正解率があまり改善されていない様子が見て取れます。繰り返し回数は半分程度で十分だったかもしれません。
6)検証
できあがった学習モデルを評価用データでも試してみます。
from keras.models import load_model
from keras.preprocessing.image import ImageDataGenerator
model = load_model('avnir2demo')
test_dir = './dataset/test/'
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(input_width,input_height),
batch_size=30,
class_mode='binary')
test_loss, test_acc = model.evaluate_generator(test_generator, steps=10)
print('test loss:', test_loss)
print('test acc:', test_acc)
なんと評価用データでも約88%と非常に高い正解率を達成しました。
しかし本当に正しく画像を分類できているのでしょうか?
判定結果を一つずつ確かめてみましょう。
以下はそのサンプルですが、ファイル名は自分の環境に合わせて適宜変更してください。
from skimage import io
import numpy as np
from skimage.transform import resize
%matplotlib inline
img = io.imread('./dataset/test/{clear or cloudy}/{z_x_y}.png')
io.imshow(img)
pred = model.predict(np.expand_dims(img[:,:,0:3]/255, axis=0))
print(pred)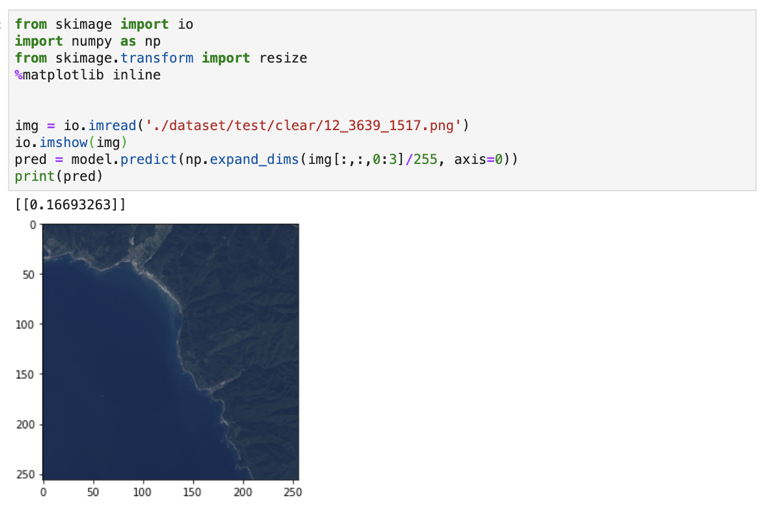
くっきりと晴れた画像を学習モデルに判定させたところ、きちんと晴れ(0.5未満)と出力されました。
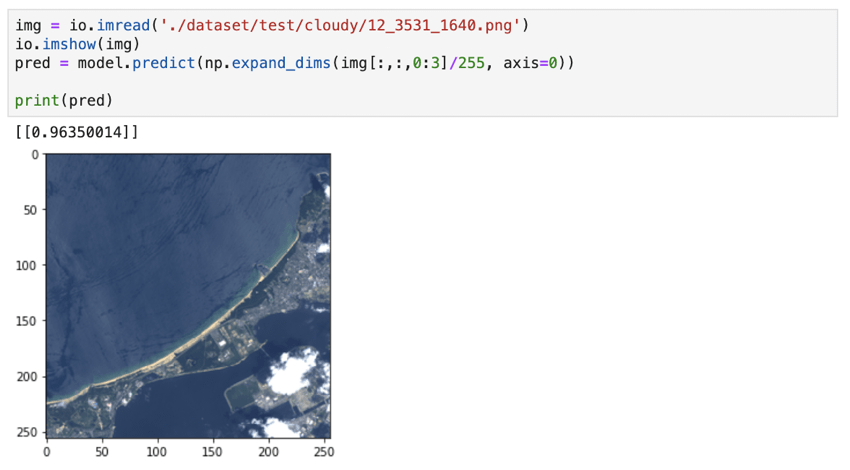
続いて右下に雲のかかった画像を学習モデルに判定させたところ、曇り(0.5以上)と正しく判定することができています。
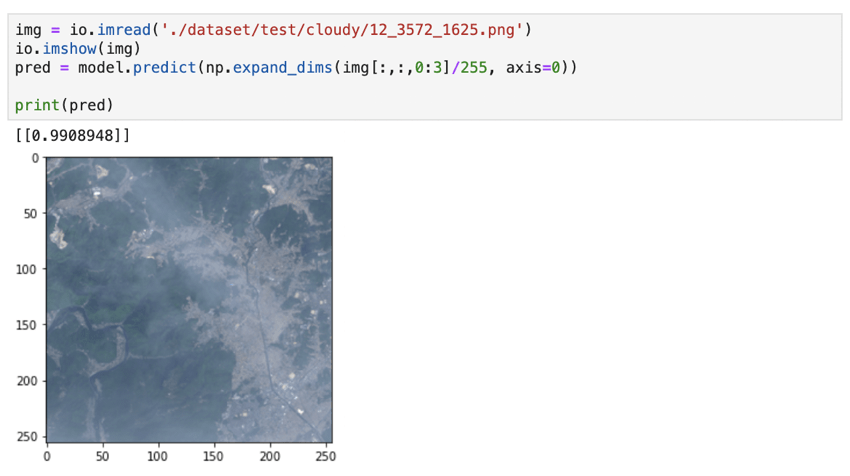
やや難しい薄曇りの画像で試しましたが、こちらも曇りと判定できています。
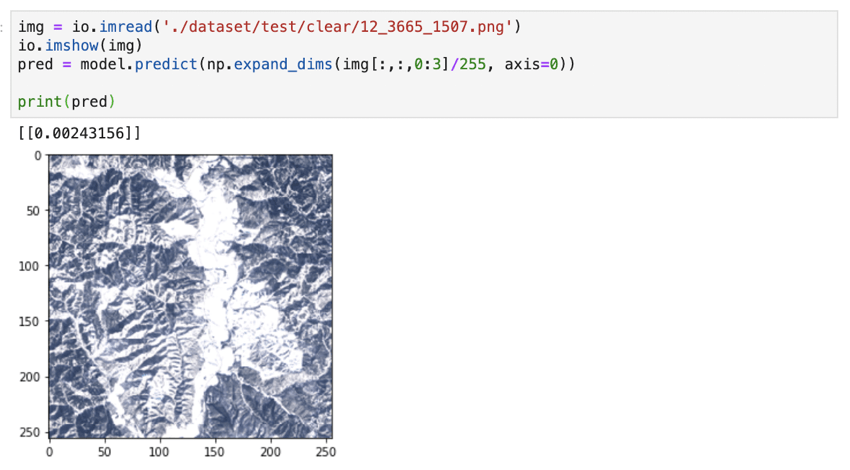
晴れている雪山の画像を曇りと誤判定しないか調べてみましたが、無事に晴れと判定できています。
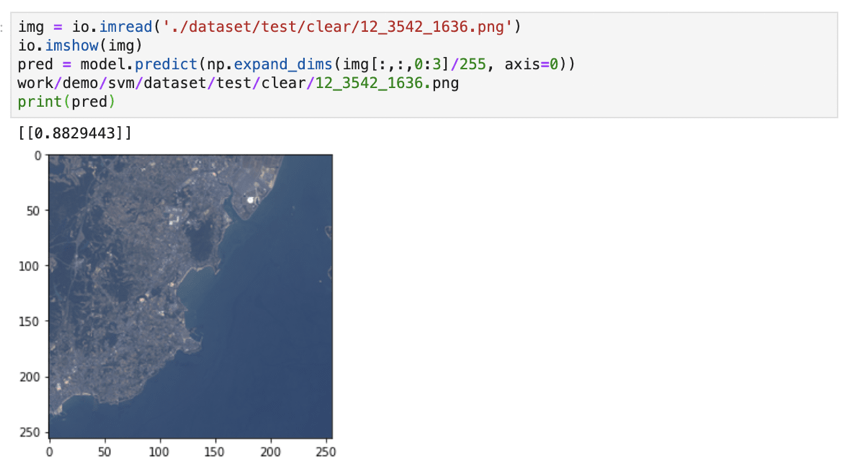
たまに晴れなのに曇りと誤判定しています。地上の白い建物を雲と間違えてしまっているのかも?
7)まとめ
このように初心者が見様見真似でやったにも関わらず、9割に近い精度で雲の有無を判定することができてしまいました。
パラメータをチューニングしたり、教師データの数を増やすことでさらに精度を上げることもできそうです。
本記事を読んで「自分でもAI×衛星データで何かできそう」と感じてもらえたでしょうか?
ディープラーニングのより詳しい解説は専門家の方々に譲りますが、宙畑編集部では今後もAI×衛星データの事例を紹介するだけでなく、実際に自分たちでチャレンジしていきます。
皆さんも手軽にできるAI×衛星データの使い方を思いついた際はぜひ実際に挑戦してみてください。宙畑への寄稿も大歓迎です!
「Tellus」で衛星データを触ってみよう!
日本発のオープン&フリーなデータプラットフォーム「Tellus」で、まずは衛星データを見て、触ってみませんか?
★Tellusの利用登録はこちらから
