宙畑温泉発見!?衛星データと地質データを利用して、機械学習で温泉地を探してみよう
衛星データと地質データを利用して、LightGBMという方法で温泉の候補地を探してみます。 結果は果たして…!
2022年8月31日以降、Tellus OSでのデータの閲覧方法など使い方が一部変更になっております。新しいTellus OSの基本操作は以下のリンクをご参照ください。
https://www.tellusxdp.com/ja/howtouse/tellus_os/start_tellus_os.html
はじめに
皆さんは温泉好きですか?最近のサウナブームもあり、温泉好きな人はなんと日本人全体の79%にもおよぶというデータがあります。
温泉地は日本全国におよそ3000箇所存在しますが、究極の温泉好きになると自分専用の温泉も欲しくなる人もいるかもしれません笑
私は地球科学で博士号を取得したという背景もあり、今回はそんなあなたのために、衛星データと地質データを利用して、新しい温泉地を探してみたいと思います。
この記事では衛星データと地質データを利用して、LightGBMという方法で温泉の候補地を探してみます。
この記事を読むと次のようなことがわかります。
・衛星データと地質データを組み合わせる方法がわかるようになる
・これらのデータを利用して機械学習モデルを作成する方法がわかるようになる
この記事では、最終的に温泉地の予測をしていますが、あくまで簡易的な方法で予測をした結果です。また、実際に探索を行う場合、決して危険な場所や私有地には足を踏み入れないようにしてください。
温泉を探すための基本的な考え方
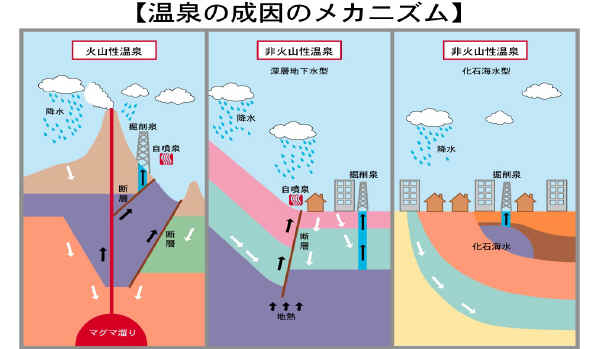
まず、温泉は火山地帯に多く存在しますが、温泉は火山性温泉と非火山性温泉に分けられます。前者は火山地帯に存在する温泉で、地下深部にあるマグマ溜まりに、地表から降った雨や雪などが温められ、地表に湧き出してきたものです。 後者の非火山性温泉は、マグマが冷えてできた高温岩体と呼ばれる高温の岩石によって地下水が温められ、それが地表に湧き出すことでできる温泉です。
つまり、温泉の場所の推定は、地下数キロから十数キロ程度の深さの地下構造を物理探査などで推定することによって、行われます。
学術的にきっちりと探すためには地下の地質構造を探る必要があるのですが、地下構造の情報というのは簡単に手に入るデータではありません。
そこで、今回の記事では、地下構造が地表の地質データに反映されていると仮定し、地表の地質データを利用します。地質データは産総研地質調査総合センターにより、20万分の1日本シームレス地質図として公開されており、今回利用するのもこの地質データです。
解析結果の紹介
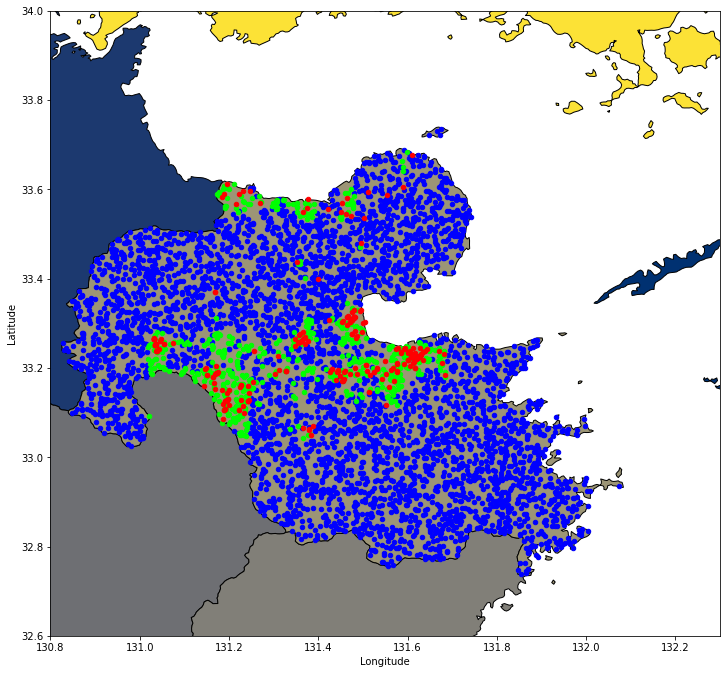
先に本記事で解析を行った結果から紹介します。今回の解析では、日本有数の温泉地である大分県に着目して解析を行いました。下図のうち、赤点が実際の温泉地の位置、緑が機械学習が予測した温泉地の位置、青が機械学習が温泉ではないだろうと予測した位置になります。
実際の温泉地とは少し離れたところに緑色のポイントがあり、実際に訪れて確かめてみたいところです。
※実際に探索を行う場合、決して危険な場所や私有地には足を踏み入れないようにしてください。
利用するデータと解析の流れ
解析に利用するデータ
まず最初に利用するデータについて説明します。
今回の解析では、インプットデータとして以下の3つのデータを利用しています。
(1) 地質データ
(2) 標高データ
(3) 緯度経度データ
標高データと緯度経度データを利用する理由は、温泉が湧出する地域というのは、既存の温泉地に近いところにあり、また標高も似たところになるであろうという考えたからです。
正解データとなる温泉の場所データは、日本原子力研究開発機構が公開している温泉地化学データベースを利用しました。このデータは論文や自治体の報告書を元にしてまとめられているため、緯度経度情報が掲載されていないものも存在しており、今回は緯度経度が掲載されているデータのみを利用しました。
また、このデータベースの緯度経度を丁寧に確認するとわかりますが、データベース上の位置と、実際の温泉地の位置が数百メートル程度ずれているものも存在します。これは温泉地化学データベースの緯度経度の単位が度分秒の整数値の精度までしか表記されていないためです。ただし、今回は地質データを利用しており、地質データの解像度から考えると、数百メートルは大きな誤差ではないと考え、データベース上の数値を利用しました。
解析の流れ
次に解析の流れについて説明します。
Trueデータ(温泉地の場所)の取得
まず、温泉地の場所を温泉地化学データベースから抽出します。日本全国の温泉地データを利用すると、大規模になりすぎるため、今回は日本で温泉がいちばん有名な大分県のデータを利用して、大分県内の温泉候補地を探すこととします。このデータベースで得た既存の温泉地の緯度経度データを利用します。
既存の温泉地の緯度経度データから、これらの位置に対応する地質データ、標高データを特徴量として取得します。
Falseデータ(温泉地でない場所)の取得
次に、温泉地でない場所のデータを取得します。
大分県内からランダムな点を選び、そのうち既存の温泉地から1km離れた点を温泉地ではない点としました。同様にこれらの点に対しても、地質データ、標高データを取得します。
モデルの作成(特徴量の学習)
既存の温泉地をTrue、温泉地ではない点をFalseとしてLightGBMで教師データとなる特徴量を学習させます。
LightGBMとは、決定木による勾配ブースティングの機械学習ライブラリです。ここでは詳細な説明は割愛しますが、例えばこちらのページで分かりやすく説明されています。
温泉地の候補地探し
作成したモデルを今度は大分県内全域(ランダムな点を抽出)に対して適用し、温泉地の候補地を探します。
なお、今回の解析ではGoogle Colaboratoryを利用して解析を行いましたが、こちらはTellusの開発環境やローカル環境でも実行可能です。適切にデータを置くファイルパスを変更してください。
コードは宙畑のGithubでも公開しています。
https://github.com/sorabatake/article_19819_Onsen
コードの実装
下準備
まずはじめにMyDriveと必要なライブラリを読み込みます。
# google driveをマウント
from google.colab import drive
drive = drive.mount('/content/drive')!pip install geopandas
!pip install pandas
!pip install matplotlib
!pip install numpy
!pip install scikit-learn
!pip install dms2dec
!pip install category_encoders
#ローカル環境で実施する場合pipではなく、condaの方が良い場合があります。#必要ライブラリをインポート
import os
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import pandas as pd
import geopandas as gpd
from shapely.geometry import Point, Polygon
import lightgbm as lgbm
import category_encoders as ce
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score, recall_score, precision_score, f1_score
from dms2dec.dms_convert import dms2dec
%matplotlib inline
print("done")必要な関数を定義していきます。詳細はコードを見ていただくとして、定義している関数の一覧は下記のようになります。
ポリゴン内のランダムな点を取得する(random_points_in_multipolygon)。
温泉地に近いかどうかをTrue/Falseで返します(close2onsen)
特定の点における地質データを返します(geology_at_point)
緯度経度から高度を取得します(get_elevation)
hgtファイルから高度を取得します(read_elevation_from_file)
緯度経度から適切なhgtファイルを取得します(get_file_name)
testデータと予測データからプロット用のGeoDataFrameを取得します(testdata2df)
def random_points_in_multipolygon(number, gdf_polys):
# find the bounds of your geodataframe
x_min, y_min, x_max, y_max = gdf_polys.bounds
# generate random data within the bounds
x = np.random.uniform(x_min, x_max, number)
y = np.random.uniform(y_min, y_max, number)
# convert them to a points GeoSeries
gdf_points = gpd.GeoSeries(gpd.points_from_xy(x, y))
# only keep those points within polygons
gdf_points = gdf_points[gdf_points.within(gdf_polys)==True]
return gdf_points
def close2onsen(point, target_df):
min_dist = 99999.0
for p in target_df.geometry:
dist = point.distance(p)
if min_dist > dist:
min_dist = dist
# 温泉地の緯度経度との距離差が0.01(=約1km)より小さい場合、True
if min_dist 1:
raise ValueError('specified lon/lat has more than two polygons.')
geology = included_symbol.values[0]
return pd.Series(geology)
def get_elevation(lon, lat):
hgt_file = get_file_name(lon, lat)
if hgt_file:
return read_elevation_from_file(hgt_file, lon, lat)
# Treat it as data void as in SRTM documentation
# if file is absent
return -32768
def read_elevation_from_file(hgt_file, lon, lat):
with open(hgt_file, 'rb') as hgt_data:
# HGT is 16bit signed integer(i2) - big endian(>)
elevations = np.fromfile(hgt_data, np.dtype('>i2'), SAMPLES*SAMPLES)\
.reshape((SAMPLES, SAMPLES))
lat_row = int(round((lat - int(lat)) * (SAMPLES - 1), 0))
lon_row = int(round((lon - int(lon)) * (SAMPLES - 1), 0))
return elevations[SAMPLES - 1 - lat_row, lon_row].astype(int)
def get_file_name(lon, lat):
"""
Returns filename such as N27E086.hgt, concatenated
with HGTDIR where these 'hgt' files are kept
"""
if lat >= 0:
ns = 'N'
elif lat = 0:
ew = 'E'
elif lon < 0:
ew = 'W'
hgt_file = "%(ns)s%(lat)02d%(ew)s%(lon)03d.hgt" % {'lat': abs(lat), 'lon': abs(lon), 'ns': ns, 'ew': ew}
hgt_file_path = os.path.join(HGTDIR, hgt_file)
if os.path.isfile(hgt_file_path):
return hgt_file_path
else:
return None
def testdata2df(X_test, y_pred):
gdf = gpd.GeoDataFrame(X_test, geometry=gpd.points_from_xy(X_test.lon, X_test.lat))
gdf['onsen'] = np.round(y_pred).astype(bool)
return gdf.reset_index(drop=True)
データの取得
さて、ここから必要なデータを取得していきます。まずは、地質データを取得します。地質データは上述したようにこちらからダウンロードしました。
今回はダウンロードして、使用しましたが地質図はWEB APIも公開されていますので、こちらを利用しても良いかもしれません。
https://gbank.gsj.jp/seamless/v2/api/1.2.1/
# seamlessV2の読み込み
geology_file = '/content/drive/MyDrive/Sorabatake/seamlessV2/seamlessV2_poly.shp'
df_shp = gpd.read_file(geology_file, encoding="UTF-8")
df_shp.head()次に都道府県のshapefileを取得します。都道府県データはこちらからjpn_adm_2019_SHP.zipをダウンロードしました。
# 日本の都道府県データを読み込み
pref_file = '/content/drive/MyDrive/Sorabatake/japan_pref/jpn_admbnda_adm1_2019.shp'
df_ja_pref = gpd.read_file(pref_file, encoding="UTF-8")
df_ja_pref.head()温泉データを取得します。温泉データはこちらからダウンロードしました。
温泉データは緯度経度情報が含まれていないデータもあるので、これらは削除します。そして緯度経度が度分秒になっているので、これを小数点付きの度に変換し、pointデータに変換します。本データベースの大分県データにはなぜか大分県以外のデータも含まれていました。そのため、これらもついでに削除しておきます。
# 温泉データをDataFrameで保存
onsen_file = '/content/drive/MyDrive/Sorabatake/dbghs/九州/大分.xls'
df_onsen = pd.read_excel(onsen_file)
# 緯度経度データがNaNのものは削除
df_onsen = df_onsen[df_onsen['東経(゜)'].notna()]
# 緯度経度データを度分秒から度に変換
df_onsen['deg E'] = df_onsen['東経(゜)'].map(int).map(str) + '°'+df_onsen['東経(′)'].map(int).map(str) + "'" + df_onsen['東経(″)'].map(int).map(str) + '"'
df_onsen['deg N'] = df_onsen['北緯(゜)'].map(int).map(str) + '°'+df_onsen['北緯(′)'].map(int).map(str) + "'" + df_onsen['東経(″)'].map(int).map(str) + '"'
df_onsen['deg E'] = df_onsen['deg E'].apply(dms2dec)
df_onsen['deg N'] = df_onsen['deg N'].apply(dms2dec)
# 度をpointデータに変換
df_onsen = gpd.GeoDataFrame(df_onsen, geometry=gpd.points_from_xy(df_onsen['deg E'], df_onsen['deg N']))
# 大分県外のデータも含まれているのでそれらを削除
df_onsen = df_onsen['geometry'][df_onsen['geometry'].within(df_ja_pref.iloc[29].geometry)==True]
df_onsen = gpd.GeoDataFrame({'geometry':df_onsen, 'onsen':True}).reset_index(drop=True)
df_onsen.head()
ここで一旦、温泉地データと都道府県データをプロットしてみましょう。赤点が温泉地の場所になります。
fig, ax = plt.subplots(figsize=(12,12))
df_ja_pref.plot(ax=ax, facecolor='Grey', edgecolor='k',alpha=1,linewidth=1,cmap="cividis")
df_onsen.plot(ax=ax, color='red', markersize=5);
ax.set_xlabel('Longitude', fontsize=10)
ax.set_ylabel('Latitude', fontsize='medium')
ax.set_xlim([130.8, 132.3])
ax.set_ylim([32.7, 33.9])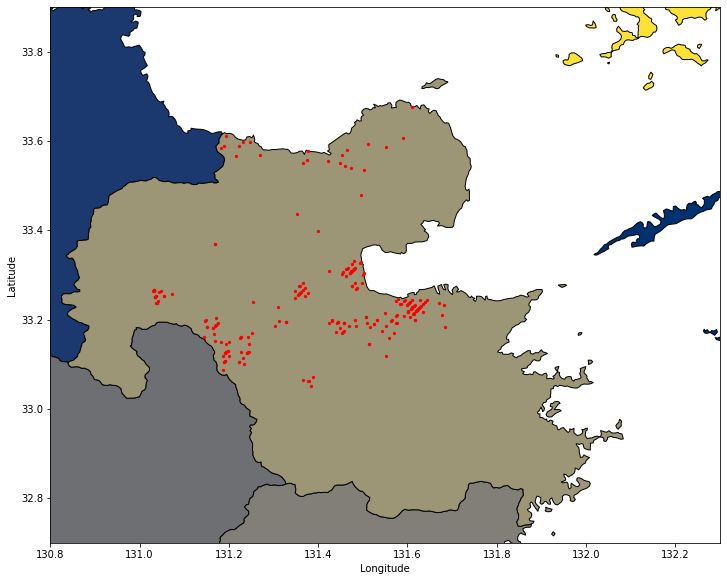
地質データについてもプロットしてみましょう。地質データはかなり分類分けが多いので、地質境界のみを黒線で描きます。同様に、赤点が温泉地の位置になります。
fig, ax = plt.subplots(figsize=(12,12))
df_ja_pref.plot(ax=ax, facecolor='Grey', edgecolor='k', alpha=1, linewidth=1, cmap="cividis")
df_shp.plot(ax=ax, facecolor='w', edgecolor='k', alpha=0.5, linewidth=1)
df_onsen.plot(ax=ax, color='red', markersize=5)
# df_rands.plot(ax=ax, color='blue', markersize=5)
ax.set_xlabel('Longitude', fontsize=10)
ax.set_ylabel('Latitude', fontsize='medium')
ax.set_xlim([130.8, 132.3])
ax.set_ylim([32.7, 33.9])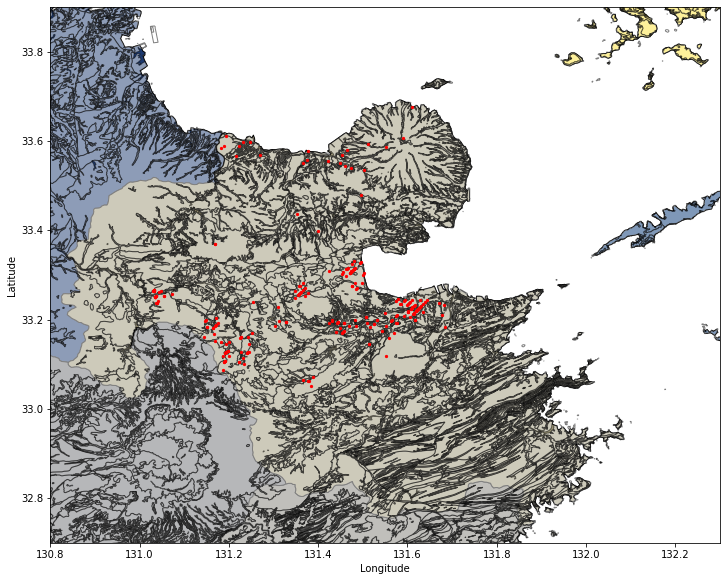
次に、大分県内にランダムな点をセットします。温泉地から1km以上より遠いものに「温泉地でない」というフラッグをつけ、特徴量として利用します。温泉地から1kmより近いものは今回の分析では利用しません。
points = random_points_in_multipolygon(1000, df_ja_pref.iloc[29].geometry)
df_rands = gpd.GeoDataFrame({'geometry':points, 'onsen':False}).reset_index(drop=True)
# 温泉地と距離が近い場合、FlagをTrueにする
df_rands['onsen'] = df_rands.geometry.apply(close2onsen, target_df=df_onsen)
このランダム点をプロットしてみましょう。赤点が温泉地の位置、青がランダムにセットされた点の位置になります。
fig, ax = plt.subplots(figsize=(12,12))
df_ja_pref.plot(ax=ax, facecolor='Grey', edgecolor='k',alpha=1,linewidth=1,cmap="cividis")
df_onsen.plot(ax=ax, color='red', markersize=5)
gpd.GeoDataFrame(df_rands[df_rands.onsen==False][['geometry', 'onsen']]).plot(ax=ax, color='blue', markersize=5)
ax.set_xlabel('Longitude', fontsize=10)
ax.set_ylabel('Latitude', fontsize='medium')
ax.set_xlim([130.8, 132.3])
ax.set_ylim([32.7, 33.9])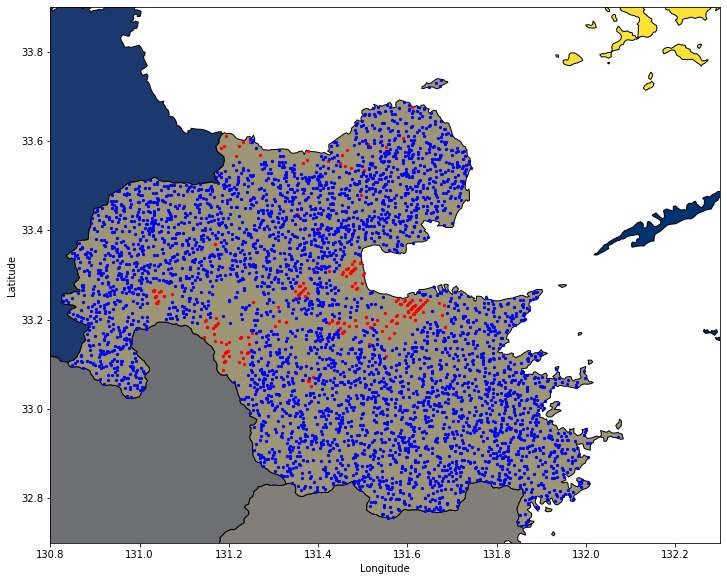
次に、温泉地データとランダム点データを教師データとして取り扱うためにGeoDataFrame形式で結合します。結合後、緯度経度情報から地質データと標高データを検索し、GeoDataFrameに特徴量として保存します。
標高データはEarthDataからNASA Shuttle Radar Topography Mission Global 3 arc second V003(SRTM3)データをダウンロードしました。
このファイルは緯度経度ごとに分割されています。大分県の場合、N32E130, N32E131, N32E132, N33E130, N33E131, N33E132の計6ファイルが必要です。
# onsenとrandomポイントを結合
df_all = gpd.GeoDataFrame( pd.concat([pd.DataFrame(df_onsen), pd.DataFrame(df_rands[df_rands.onsen==False])], ignore_index=True) )
df_all[['symbol', 'formatio_1', 'group_ja']] = pd.DataFrame(df_all)['geometry'].apply(geology_at_point, df=df_shp)
# 標高データの読み込み
SAMPLES = 1201 # Change this to 3601 for SRTM1
HGTDIR = '/content/drive/MyDrive/Sorabatake/srtm/' # All 'hgt' files will be kept here uncompressed
df_all['elev'] = df_all.apply(lambda x: get_elevation(x.geometry.x, x.geometry.y), axis=1)
LightGBMに利用するためにGeoDataFrameの形式を整えて、TrainとTestデータに分割したあとトレーニングを行います。
# Pointsをfloatに変換
df_all['lon'] = df_all.geometry.x
df_all['lat'] = df_all.geometry.y
# geometryは不要なので削除
df_all = df_all.drop(['geometry'], axis=1)
# object型をカテゴリ変数に変換
df_all[['symbol', 'formatio_1', 'group_ja']] = df_all[['symbol', 'formatio_1', 'group_ja']].astype('category')
# labelを分離
y = df_all.pop('onsen')
# trainとtestに分割
X_train, X_test, y_train, y_test = train_test_split(df_all, y, test_size=0.2, random_state=42)
# training用のデータ作成
categorical_features = ['symbol', 'formatio_1', 'group_ja']
lgb_train = lgbm.Dataset(data=X_train, label=y_train, categorical_feature=categorical_features)
lgb_eval = lgbm.Dataset(data=X_test, label=y_test, categorical_feature=categorical_features, reference=lgb_train)
# LightGBM のハイパーパラメータ
lgbm_params = {
# 多値分類問題
'objective': 'binary',
'metrics': 'binary_logloss',
}
# 上記のパラメータでモデルを学習する
model = lgbm.train(lgbm_params, lgb_train, valid_sets=lgb_eval)
得られたモデルを利用して、testデータの正解率、精度、検出率、F1スコアを計算してみましょう。正解率が96.4%となり高い正解率が得られていますね。
# テストデータを予測する
y_pred = model.predict(X_test, num_iteration=model.best_iteration)
print('Accuracy score = \t {}'.format(accuracy_score(y_test, np.round(y_pred))))
print('Precision score = \t {}'.format(precision_score(y_test, np.round(y_pred))))
print('Recall score = \t {}'.format(recall_score(y_test, np.round(y_pred))))
print('F1 score = \t {}'.format(f1_score(y_test, np.round(y_pred))))
次に、作成したモデルを利用して大分県全体の推定をします。まず、大分県全体からランダムな点を1万点取得します。1万点取得すると計算時間がかなりかかるので、急いでいる方は1000点ぐらいに変更してみても良いでしょう。
# 作成したモデルを用いて、大分県全体の予測をする
points = random_points_in_multipolygon(10000, df_ja_pref.iloc[29].geometry)
df_rands = gpd.GeoDataFrame({'geometry':points, 'lon':points.x, 'lat':points.y}).reset_index(drop=True)温泉地と取得したランダム点の位置をプロットします。
fig, ax = plt.subplots(figsize=(12,12))
df_ja_pref.plot(ax=ax, facecolor='Grey', edgecolor='k',alpha=1,linewidth=1,cmap="cividis")
df_rands.plot(ax=ax, color='blue', markersize=5)
df_onsen.plot(ax=ax, color='red', markersize=5)
ax.set_xlabel('Longitude', fontsize=10)
ax.set_ylabel('Latitude', fontsize='medium')
ax.set_xlim([130.8, 131.9])
ax.set_ylim([32.8, 34.0])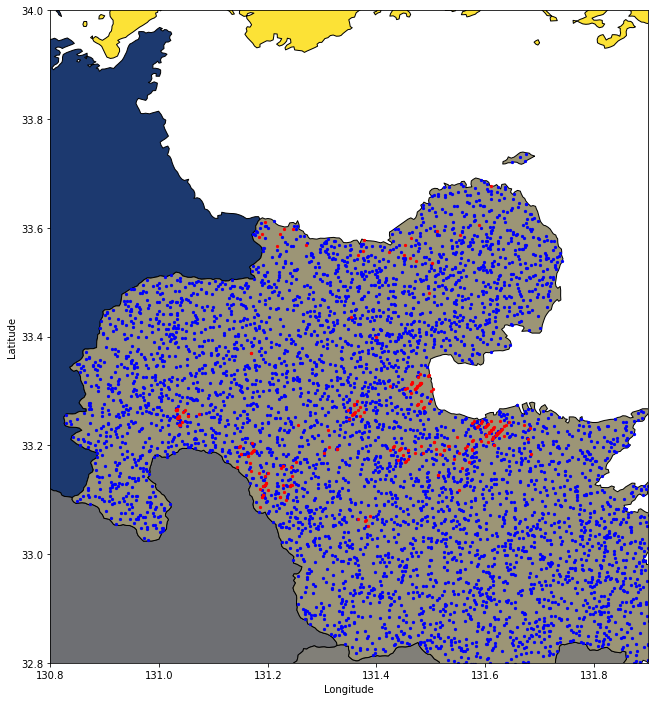
ランダム点の緯度経度情報から特徴量を取得し、モデルにインプットするために形式を整えます。モデルで温泉の有無の予測をします。
df_rands['elev'] = df_rands.apply(lambda x: get_elevation(x.lon, x.lat), axis=1)
df_rands[['symbol', 'formatio_1', 'group_ja']] = pd.DataFrame(df_rands)['geometry'].apply(geology_at_point, df=df_shp)
# columnの順番を変更
df_rands = df_rands[['symbol', 'formatio_1', 'group_ja', 'elev', 'lon', 'lat']]
# object型をカテゴリ変数に変換
df_rands[['symbol', 'formatio_1', 'group_ja']] = df_rands[['symbol', 'formatio_1', 'group_ja']].astype('category')
# df_rands.head()
# テストデータを予測する
y_pred_all_region = model.predict(df_rands, num_iteration=model.best_iteration)
df_pred_all_region = testdata2df(df_rands, y_pred_all_region)
df_pred_all_region = df_pred_all_region.drop(['symbol', 'formatio_1', 'group_ja', 'elev', 'lon', 'lat'], axis=1)
df_pred_all_region.head()最終的に予測された温泉の有無についてプロットします。赤点が実際の温泉地の位置、緑が機械学習が予測した温泉地の位置、青が機械学習が温泉ではないだろうと予測した位置になります。
fig, ax = plt.subplots(figsize=(12,12))
df_ja_pref.plot(ax=ax, facecolor='Grey', edgecolor='k',alpha=1,linewidth=1,cmap="cividis")
df_pred_all_region[df_pred_all_region.onsen==False].plot(ax=ax, color='blue', markersize=20)
df_pred_all_region[df_pred_all_region.onsen==True].plot(ax=ax, color='lime', markersize=20)
df_onsen.plot(ax=ax, color='red', markersize=20)
ax.set_xlabel('Longitude', fontsize=10)
ax.set_ylabel('Latitude', fontsize='medium')
ax.set_xlim([130.8, 132.3])
ax.set_ylim([32.6, 34.0])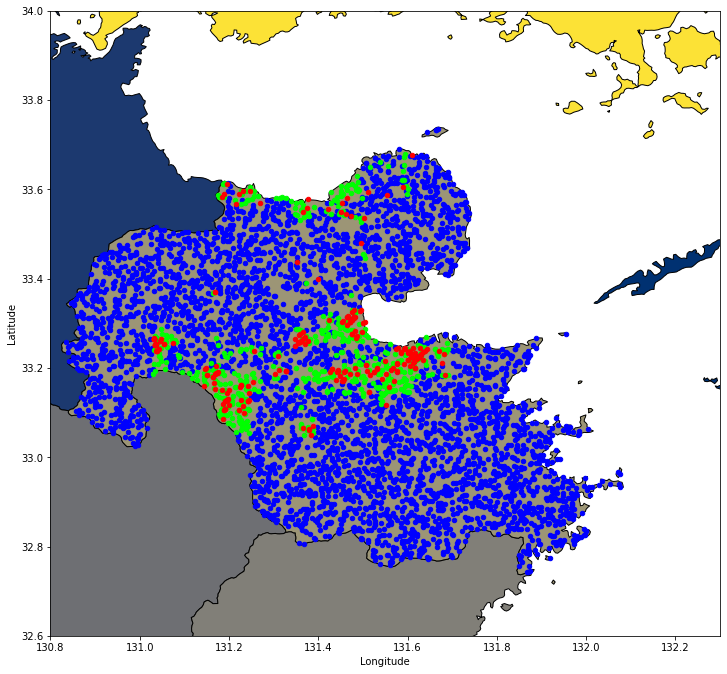
考察
ここまで解析していた内容を考察していきます。
予測された温泉地と地質データの関係
ここで予測された温泉地は、地質データを反映しているのでしょうか。
地質データと実際の温泉地の位置、予測された温泉地の位置をプロットしてみましょう。地質データのカテゴリを数値データに変換することで、色分けしてプロットします。
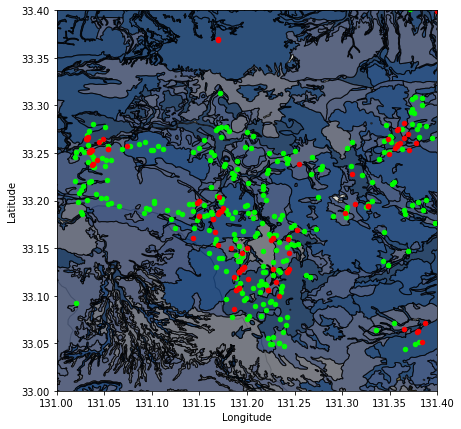
この図を見ると、地質データと予測された温泉地の位置はあまり相関がないように見えます。
特徴量の重要度
では、最後にLightGBMの特徴量の重要度を出力してみましょう。LightGBMを利用している場合、feature_importance関数で簡単に取得することができます。
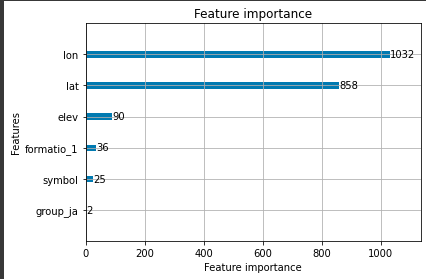
これを見ると、緯度経度(lon, lat)の重要度が高く、地質データ(formatiio_1, symbol, group_ja)の重要度は低いことがわかります。
これについて簡単に考察をします。
地質データの重要度が低い理由
「はじめに」で説明しましたが、温泉地は地表の地質ではなく、地下数キロから十数キロの構造の影響を受けています。地表の地質そのものが温泉地の位置を表しているわけではないので、重要度が低くなったと考えられます。
緯度経度の重要度が高かった理由
逆に、緯度経度が効く理由は、1)マクロスケールで見たときには、温泉が湧出する位置は地下構造(マグマまたは高温岩体)で決まるので、マグマまたは高温岩体がある緯度経度に予測する傾向があると思われる、2)ミクロスケールで見ても、湧出する位置は表層付近のプレート境界づたいに湧出する傾向があるので、同様に緯度経度が効いてくる、の2種類の理由が考えられます。
予測モデルを向上させるためには
では、今回の結果から、温泉地予測モデルを向上させるためにはどのようにすればよいでしょうか。
①地下構造の情報を取り入れる
今回利用した地質データはあくまで地表の地質情報となります。実際には温泉地は地下数キロから十数キロの地下構造に影響を受けています。
そのため、地下構造の情報を取り入れることができればより精度の高いモデルを作成することができるかもしれません。マグマや高温岩体の存在は地下比抵抗構造に影響を与えるので、例えば地下比抵抗構造の情報を取り入れるというのは面白いかも知れません。
②放射能情報を利用する
地表には岩石鉱物中から放出される微小なガンマー線が存在します。ガンマー線強度は岩石鉱物によって変化するのですが、特に断層・破砕帯周辺で高い強度を示します。
温泉はこのような地域で湧出することが多いため、ある程度地表の放射能情報と関連があるとされています。このような情報を特徴量に含めることでより良いモデルが作成できるかもしれません。
まとめ
衛星データと地質データを利用して、機械学習モデルを作成し温泉地を探してみました。テストデータで試してみたところ96.4%の正解率と非常に高い正解率を示すことができました。
今回は地質データを取り入れてみましたが、機械学習モデルによると地質データはあまり重要ではなく、緯度経度が重要であるということになりました。この理由は、地質データはあくまで地表数メートル程度の情報を表しており、本質的に温泉の成因となるマグマや高温岩体などを捉えることができていないからだと考えられます。
今後、地下構造情報や地表の放射能データを利用することでよりよいモデルを作成することができるかもしれません。
この記事が衛星データと地質データを使った機械学習モデル構築の参考になれば幸いです。
