イベント、夜の街、新施設オープン、天候……モバイル空間統計で人の動きを可視化してみた
2020年5月より一部の場所と期間において、無料で扱えるようになったモバイル空間統計®のAPIを使って、宙畑編集部が気になる人の動きに関わる事象について検証してみました。
新型コロナの影響で基本的に在宅ワークに変更になったということも多いのではないでしょうか。人の動きが変わったことで、商売は繁盛した企業もあれば、そのまた逆の企業も多いようです。
マーケティング観点で、人の動きという指標は様々な企業が喉から手が出るほど欲しいデータ。そこで、2020年5月より一部の場所と期間において、無料で扱えるようになったモバイル空間統計®のAPIを使って、宙畑編集部が気になる人の動きに関わる事象について検証してみました。
※モバイル空間統計はNTTドコモの登録商標です
※2020年6月時点でモバイル空間統計の提供データは以下になります
===
■2016/7/1~2017/9/30(東京23区、横浜市18区、大阪市24区、名古屋市16区、福岡市7区)
■2016/4/1~2016/7/31(熊本県内全域)
■2018/6/28~2018/7/8+前後1週間(岐阜県、京都府、兵庫県、岡山県、鳥取県、広島県、愛媛県、高知県、福岡県、佐賀県、長崎県)
===
本記事の内容を実践したい場合はTellusへの登録が必須になります。
★Tellusの利用登録はこちらから
(1)本記事で検証する人の動きに関する4つの事象
今回、大きく分けて4つの事象についてモバイル空間統計を用いて、気になったことを検証してみました。
【今回検証する4つの事象】
①年末年始、ハロウィン時の人の増減
②大規模な商業施設がオープンしたら特定地域の人口が増えるのか
③深夜帯まで家に帰らない人が多い街は夜間光データを見ても光が煌々と輝いているのか
④天気によってテーマパークの客数が変わるのか
また、②~④の3つの事象については衛星データも合わせて検証を行いたいと思います。
(2)モバイル空間統計情報を取得するための事前準備
それではさっそくモバイル空間統計情報を用いて、気になる事象を検証してみましょう。まずはモバイル空間統計APIを使用するための事前準備です。
必要なライブラリをインポートします。
# -*- coding:utf-8 -*-
import os, requests
import pandas as pd
import matplotlib.pyplot as plt
TOKEN = "XXXXXXXXXXXXXXXXXXXXXXX" # set your token次に、モバイル空間情報を取得するための関数を定義します。
※APIリファレンスはこちら
def mobaku(params={}, next_url=''):
if len(next_url) > 0:
url = next_url
else:
url = 'https://pflow.tellusxdp.com/api/v1/mobaku'
headers = {
'Authorization': f'Bearer {TOKEN}'
}
r = requests.get(url, params=params, headers=headers)
if not r.status_code == requests.codes.ok:
r.raise_for_status()
return r.json()
def time(i):
if (i > 24):
return i - 24
else:
return i
def add_time(data):
return [time(i) for i in range(len(data['items']))]
(3)4つの事象を検証!
事前準備が終わったところで、いよいよ検証を始めてみましょう。
①イベント時の人の増減を可視化する
まずはイベント時の人の増減を可視化します。
取得したモバイル空間情報を年齢別に分けて、pandasのdataframe形式で返す関数を定義します。
def get_age_specific_mobaku(startDate, endDate, startTime, endTime, mesh):
for i in mesh:
data = mobaku({
'after': f"{startDate[0]}-{startDate[1]}-{startDate[2]}T{startTime[0]}:{startTime[1]}:{startTime[2]}+09:00",
'before': f"{endDate[0]}-{endDate[1]}-{endDate[2]}T{endTime[0]}:{endTime[1]}:{endTime[2]}+09:00",
'mesh': i
})
df = pd.DataFrame(data['items'], index=(add_time(data)))
try:
fifteen += df.loc[:, df.columns.str.endwith('15')]
twenty += df.loc[:, df.columns.str.endwith('20')]
thirty += df.loc[:, df.columns.str.endwith('30')]
forty += df.loc[:, df.columns.str.endwith('40')]
fifty += df.loc[:, df.columns.str.endwith('50')]
sixty += df.loc[:, df.columns.str.endwith('60')]
seventy += df.loc[:, df.columns.str.endwith('70')]
except:
fifteen = df.loc[:, df.columns.str.endswith('15')]
twenty = df.loc[:, df.columns.str.endswith('20')]
thirty = df.loc[:, df.columns.str.endswith('30')]
forty = df.loc[:, df.columns.str.endswith('40')]
fifty = df.loc[:, df.columns.str.endswith('50')]
sixty = df.loc[:, df.columns.str.endswith('60')]
seventy = df.loc[:, df.columns.str.endswith('70')]
sum_fifteen = fifteen.sum(axis=1)
sum_twenty = twenty.sum(axis=1)
sum_thirty = thirty.sum(axis=1)
sum_forty = forty.sum(axis=1)
sum_fifty = fifty.sum(axis=1)
sum_sixty = sixty.sum(axis=1)
sum_seventy = seventy.sum(axis=1)
df_fifteen = pd.DataFrame(sum_fifteen.values, columns=['15'])
df_twenty = pd.DataFrame(sum_twenty.values, columns=['20'])
df_thirty = pd.DataFrame(sum_thirty.values, columns=['30'])
df_fourty = pd.DataFrame(sum_forty.values, columns=['40'])
df_fifty = pd.DataFrame(sum_fifty.values, columns=['50'])
df_sixty = pd.DataFrame(sum_sixty.values, columns=['60'])
df_seventy = pd.DataFrame(sum_seventy.values, columns=['70'])
return pd.concat([df_fifteen, df_twenty, df_thirty, df_fourty, df_fifty, df_sixty, df_seventy ], axis=1)今回は、年末年始、ハロウィンのイベントそれぞれについて、年末年始は秋葉原駅周辺、渋谷(スクランブル交差点)と原宿(明治神宮)を、ハロウィンについては秋葉原駅周辺、渋谷(スクランブル交差点)、大阪(道頓堀・戎橋)の人の動きをみてみたいと思います。
メッシュコードの確認
まず、地域のメッシュコードを探します。
メッシュコードについては、こちらをご参考ください。
今回は、分割地域メッシュの一つである、4分の1地域メッシュというものを使用します。
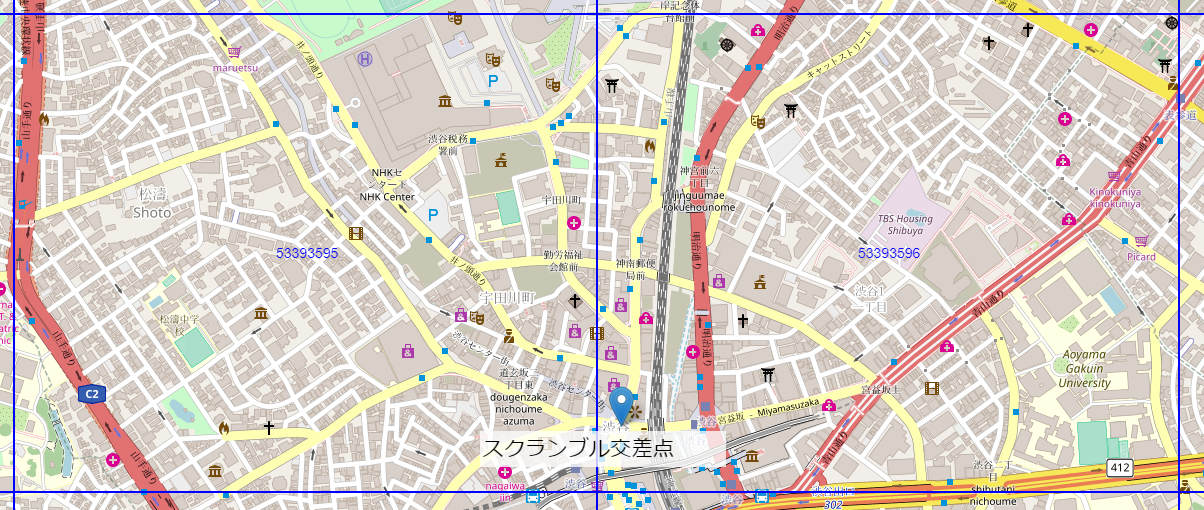
地域メッシュを確認すると、スクランブル交差点付近は 533935961 と 533935952 を組み合わせれば全体像が入ることがわかります。
実際に値を取得してみる
テストとして、渋谷のスクランブル交差点周辺の2017/01/10のデータを取得してみます。
まず、値を取得するためのパラメータ等を定義します。
startTime = ['00', '00', '00']
endTime = ['23', '59', '59']
mesh = [ 533935961, 533935952]
test_data = {
'startDate': ['2017', '01', '10'],
'endDate': ['2017', '01', '10'],
'startTime': startTime,
'endTime': endTime,
'mesh':mesh,
}その次に、事前準備の際に定義した関数を使用して、実際に値を取得します。
df = get_age_specific_mobaku(test_data['startDate'], test_data['endDate'],test_data['startTime'], test_data['endTime'], test_data['mesh'])
df.plot.bar(stacked=True)これを実行すると、以下のようなグラフが出力されます。
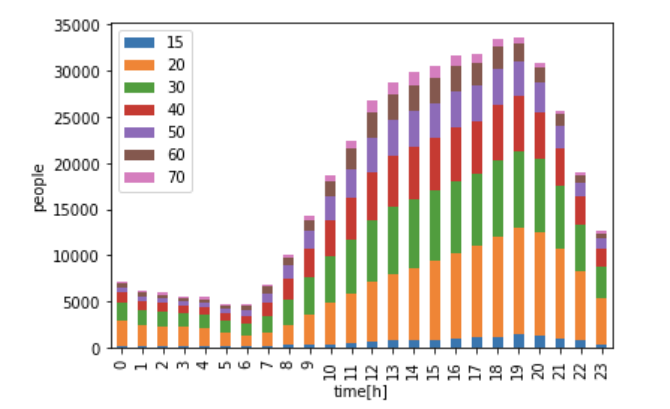
これを繰り返して、データの比較を行っていきます。
今後のこの処理を毎回使用するので、test_dataを渡せばグラフまで表示してくれる関数を先に定義しておきます。
def show_img(test_data):
df = get_age_specific_mobaku(test_data['startDate'], test_data['endDate'],test_data['startTime'], test_data['endTime'], test_data['mesh'])
ax = df.plot.bar(stacked=True)
ax.set_xlabel("time[h]")
ax.set_ylabel("people")今回使用するメッシュコードは以下の通りです。
秋葉原:mesh = [533946314]
明治神宮:mesh = [533945161, 533945152, 533945054, 533945063]
渋谷、スクランブル交差点: mesh = [533935961, 533935952]大晦日から正月にかけて、各地点の比較
まずは、大晦日から正月にかけて、各地点の比較をしてみます。
これらのメッシュコードを使用して、12/31と1/1のデータを取得すると以下のように表示されます。
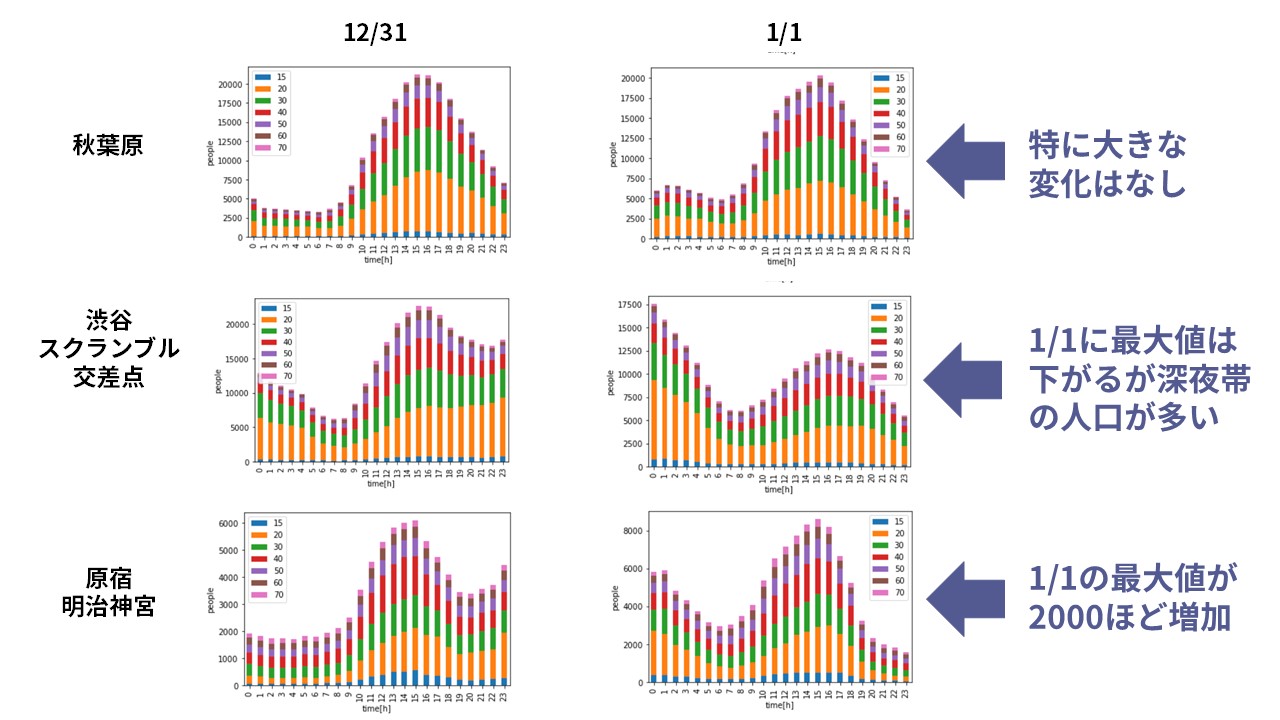
明治神宮の初詣参拝者が多いと思っていたのですが、実際にデータを見てみると、渋谷と皇居周辺の深夜の人数が多いようです。どちらも20代が夜に出歩くことが多いみたいですね。カウントダウンのまま朝まで盛り上がっているということでしょうか。
ハロウィン当日と前後の同じ曜日の人数比較
次は、ハロウィンの日の人の動きを確認します。ハロウィンと言えば渋谷のスクランブル交差点が魔界のようになっているニュースを見たことがある人も多いでしょう。いったいどれほど人が増えているのでしょうか。
モバイル空間統計のデータがある2016年のハロウィンに注目すると、10/31は月曜日です。したがって、その前の月曜日である10/24(月)の人数を各地点で比較してみましょう。
今回使用するメッシュコードは以下の通りです。
秋葉原:mesh = [533946314]
渋谷、スクランブル交差点: mesh = [533935961, 533935952]
大阪道頓堀、戎橋: mesh = [523504001, 523504002]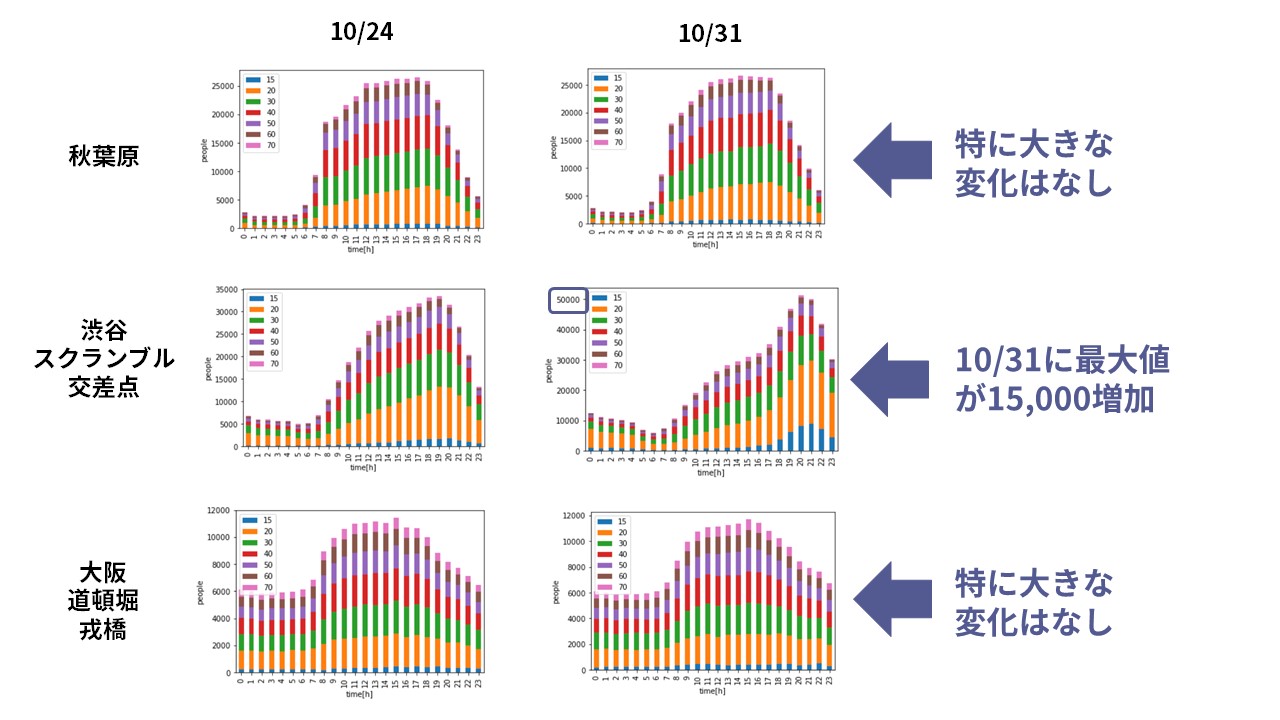
渋谷にあるスクランブル交差点では、数値で見てみると最大で15000人ほど多いと言うことがわかります。遊びに行く際は、勇気が必要です。
②大規模な商業施設がオープンしたら特定地域の人口が増えるのか
次は、大規模商業施設と人の動きの関係を検証します。モバイル空間統計のデータがある期間にできた大規模商業施設として目ぼしいものは2017年4月20日にオープンした「GINZA SIX」が該当します。
では、実際にオープンした後、人は増えたのでしょうか。見てみましょう。
メッシュコードと日付から男性と女性の人数を返す関数を定義します。
import os, requests
import pandas as pd
TOKEN = "xxx"
def mobaku(params={}, next_url=''):
if len(next_url) > 0:
url = next_url
else:
url = 'https://pflow.tellusxdp.com/api/v1/mobaku'
headers = {
'Authorization': f'Bearer {TOKEN}'
}
print(params)
r = requests.get(url, params=params, headers=headers)
if not r.status_code == requests.codes.ok:
r.raise_for_status()
return r.json()
def time(i):
if (i > 24):
return i - 24
else:
return i
def add_time(data):
return [time(i) for i in range(len(data['items']))]
def get_total_mobile_data_by_pandas(startDate, endDate, startTime, endTime, mesh):
male = 0
female = 0
for i in mesh:
data = mobaku({
'after': f"{startDate[0]}-{startDate[1]}-{startDate[2]}T{startTime[0]}:{startTime[1]}:{startTime[2]}+09:00",
'before': f"{endDate[0]}-{endDate[1]}-{endDate[2]}T{endTime[0]}:{endTime[1]}:{endTime[2]}+09:00",
'mesh': i
})
df = pd.DataFrame(data['items'], index=(add_time(data)))
df_female = df.loc[:, (df.columns.str.startswith('female'))]
df_male = df.loc[:, (df.columns.str.startswith('male'))]
female += df_female.sum(axis=1)
male += df_male.sum(axis=1)
df_female = pd.DataFrame(female.values, columns=['female'])
df_male = pd.DataFrame(male.values, columns=['male'])
return pd.concat([df_female, df_male], axis=1)値を取得します。
startTime = ['00', '00', '00']
endTime = ['23', '59', '59']
mesh = [533946011] # GINZA SIX
test_data = [
{
'startDate': ['2017', '04', '13'],
"endDate": ['2017', '04', '13'],
'startTime': startTime,
'endTime': endTime,
'mesh': mesh,
},
{
'startDate': ['2017', '04', '19'],
"endDate": ['2017', '04', '19'],
'startTime': startTime,
'endTime': endTime,
'mesh': mesh,
},
{
'startDate': ['2017', '04', '20'],
"endDate": ['2017', '04', '20'],
'startTime': startTime,
'endTime': endTime,
'mesh': mesh,
},
{
'startDate': ['2017', '04', '27'],
"endDate": ['2017', '04', '27'],
'startTime': startTime,
'endTime': endTime,
'mesh': mesh,
}
]
array = []
for i in test_data:
array.append(get_total_mobile_data_by_pandas(i['startDate'], i['endDate'],i['startTime'], i['endTime'], i['mesh']))
for i in array:
i.plot.bar(stacked=True)実行すると以下のグラフが出力されます。
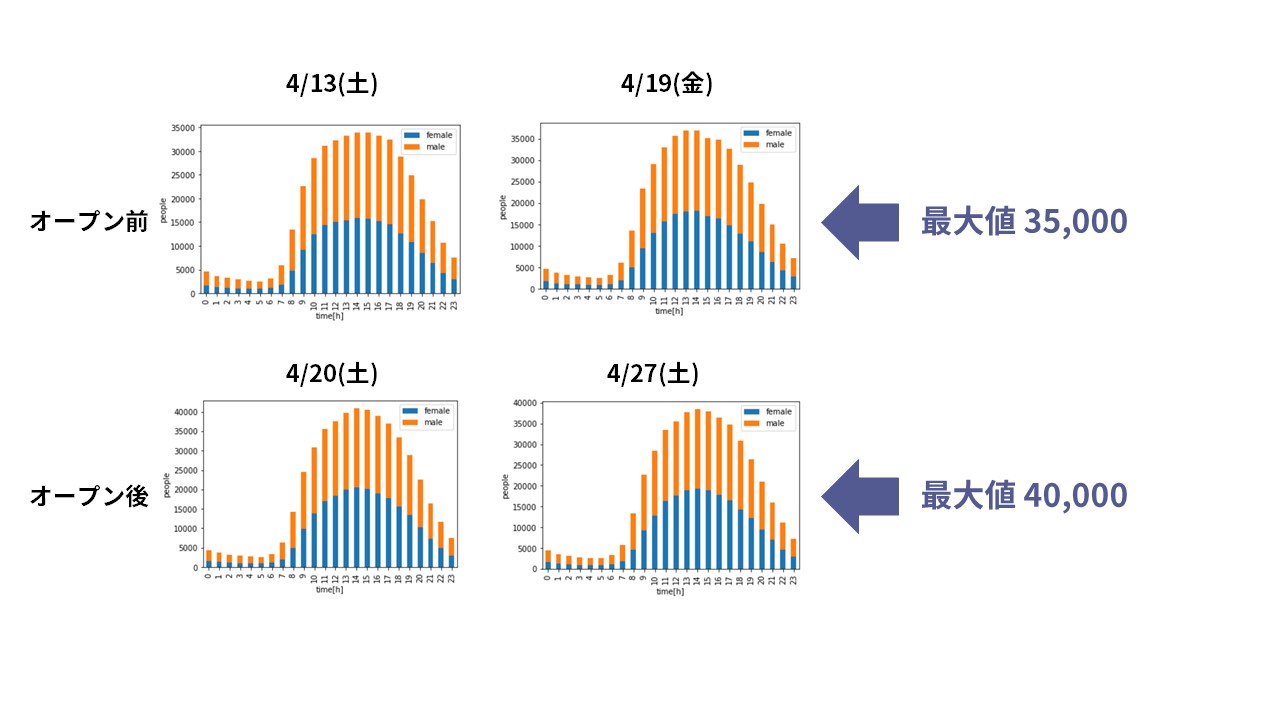
開店の前の週と開店してからを比較すると、地域メッシュに対する人の数が増えたことがわかります。
わかりやすくするために、4/13と4/20のデータを比較してみましょう。
前の週と開店当日の差をグラフに出してみます。
(array[2] - array[0]).plot.bar(stacked=True)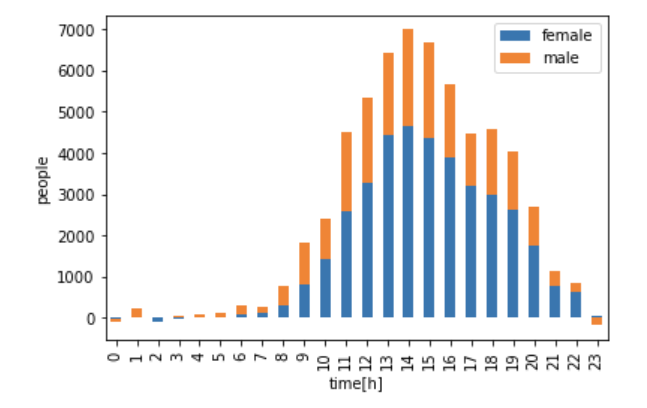
グラフを見ると分かる通り、GINZA SIXがオープンした週は、1日のお昼に7,000人超が増え、女性の比率が多いことがわかりました。
③深夜帯まで家に帰らない人が多い街は夜間光データを見ても光が煌々と輝いているのか
人流データを用いて、昼と夜の人数の変化が少ない場所を探してみます。変化が少ないということは,夜遅くまでお仕事をしている、もしくは、その街で飲んでいる人がが多いといえるのではないでしょうか。
必要なライブラリをインポートすると同時に,日本語を使用できる設定をします。
import os, requests
import pandas as pd
import matplotlib
from matplotlib import rcParams
TOKEN = "XXX"
matplotlib.font_manager._rebuild()
rcParams['font.family'] = 'IPAMincho'
import matplotlib.font_manager as fm
fm.findSystemFonts()これまでに用いた関数を応用して、夜と昼の人数を比較した割合を計算する関数を定義します。
計算式は、朝3時はさすがに帰っている人が多いだろうという推測と、ピーク時間は日中に来ることが多いだろうという推測をベースにして、
(夜間に出歩いている人口)=
(21時の人流+22時の人流+23時の人流)/3 ー(朝3時の人流)
(日中に出歩いている人口)=
(1日の中でピークとなる時間帯の人流)ー(朝3時の人流)
(昼と夜の人口の比率)=
(夜間に出歩いている人口)÷(日中に出歩いている人口)
(21時、22時、23時の人流の和-朝3時の人流x3)/(ピークの時間帯の人流-朝3時の人流)
としてみました。
def mobaku(params={}, next_url=''):
if len(next_url) > 0:
url = next_url
else:
url = 'https://pflow.tellusxdp.com/api/v1/mobaku'
headers = {
'Authorization': f'Bearer {TOKEN}'
}
# print(params)
r = requests.get(url, params=params, headers=headers)
if not r.status_code == requests.codes.ok:
r.raise_for_status()
return r.json()
def time(i):
if (i > 24):
return i - 24
else:
return i
def add_time(data):
return [time(i) for i in range(len(data['items']))]
def get_total_mobile_data_by_pandas(startDate, endDate, startTime, endTime, mesh):
a = 0
for i in mesh:
data = mobaku({
'after': f"{startDate[0]}-{startDate[1]}-{startDate[2]}T{startTime[0]}:{startTime[1]}:{startTime[2]}+09:00",
'before': f"{endDate[0]}-{endDate[1]}-{endDate[2]}T{endTime[0]}:{endTime[1]}:{endTime[2]}+09:00",
'mesh': i
})
df = pd.DataFrame(data['items'], index=(add_time(data)))
df = df.loc[:, df.columns.str.startswith('total')]
a += df
return a
def get_dont_backhome_rate(startDate, endDate, startTime, endTime, mesh):
data = get_total_mobile_data_by_pandas(startDate, endDate, startTime, endTime, mesh)
twentyOne = data.loc[21]
twentyTwo = data.loc[22]
twentyThree = data.loc[23]
three = data.loc[3]
peek = data.loc[data['total'].idxmax()]
return (twentyOne + twentyTwo + twentyThree - three / 3) / (peek - three)定義した関数を用いて、人流データを取得します。今回は例として、2016年10月05日のデータを取得してみます。
test = {
'startDate': ['2016', '10', '05'],
"endDate": ['2016', '10', '05'],
'startTime': ['00', '00', '00'],
'endTime': ['23', '59', '59'],
}
meshDatas = [
[[533945192, 533945094, 533946003, 533946201], "霞ヶ関"],
[[533945251, 533945252, 533945253, 533945254], "新宿"],
[[533936902, 533946001], "新橋"],
[[533946111, 533946112, 533946114, 533946122], "丸の内(東京)"],
[[523657921, 523657922, 523657923, 523657924], "栄"],
[[523667021, 523667022, 523667023, 523667024, 523667121, 523667122, 523667012, 523667014], "伏見"],
[[523667121, 523667023, 523667014, 523667112], "丸の内(名古屋)"],
[[523504101, 523504102, 523504103, 523504104, 523504201, 523504202, 523504203, 523504204, 523503292, 523503294, 523503192, 523503194], "船場"],
[[523503491, 523503492, 523503493, 523503494, 523504401, 523504402, 523504403, 523504404, 523503394, 523504302], "梅田"],
[[523503291, 523503292, 523503293, 523503294, 523503392, 523503393, 523503394, 523503382, 523503282, 523503284], "中之島"],
[[503033031, 503033032, 503033033, 503033034, 503033131, 503033132], "博多駅"],
[[503033021, 503033023, 503033024, 503033121, 503033111, 503033112, 503033114, 503033011, 503033012, 503033013, 503033014], "天神"]
]
for index, meshData in enumerate(meshDatas):
_temp = get_dont_backhome_rate(test['startDate'], test['endDate'], test['startTime'], test['endTime'], meshData[0])['total']
a = {'rate': _temp, 'place': meshData[1]}
if (index == 0):
ar = [a]
else:
ar.append(a)
df = pd.DataFrame(ar).sort_values('rate')
df.plot.barh(x='place', stacked=True)これを実行すると、以下のような出力が得られます。
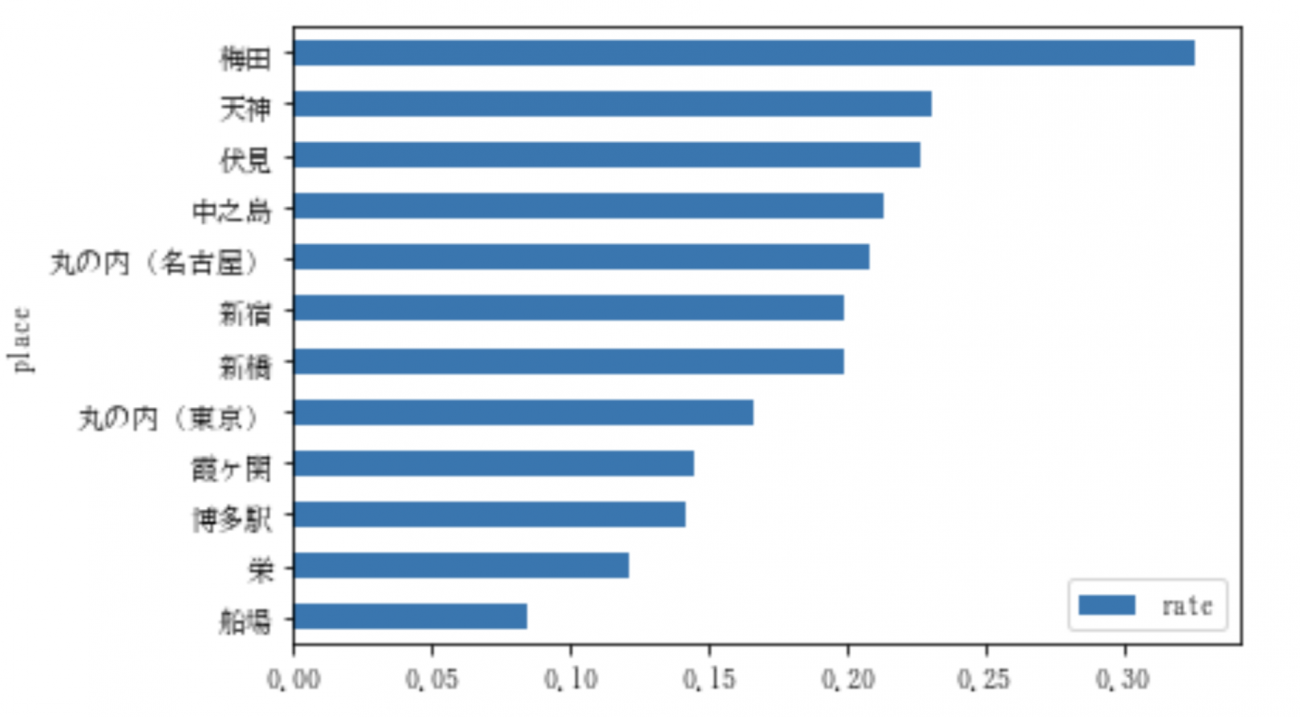
グラフを見ると、梅田が一番家に帰っていないことがわかります。それにしても、梅田の人たち、もう少し家に帰った方が良いと思う。
さて、このデータが正しいかどうか、夜間光を用いて確かめてみましょう.今回は、ブラウザで確認できるLight population mapというものを使用します。他にも夜間光を調べられるアプリケーションがあるので、興味のある方はこちらをご覧ください。
Light population mapにアクセスし、左上にある検索ボックスで「Umeda, japan」と打ち込み、Enterを押します。すると、自動的に梅田周辺の夜間光が表示されます。
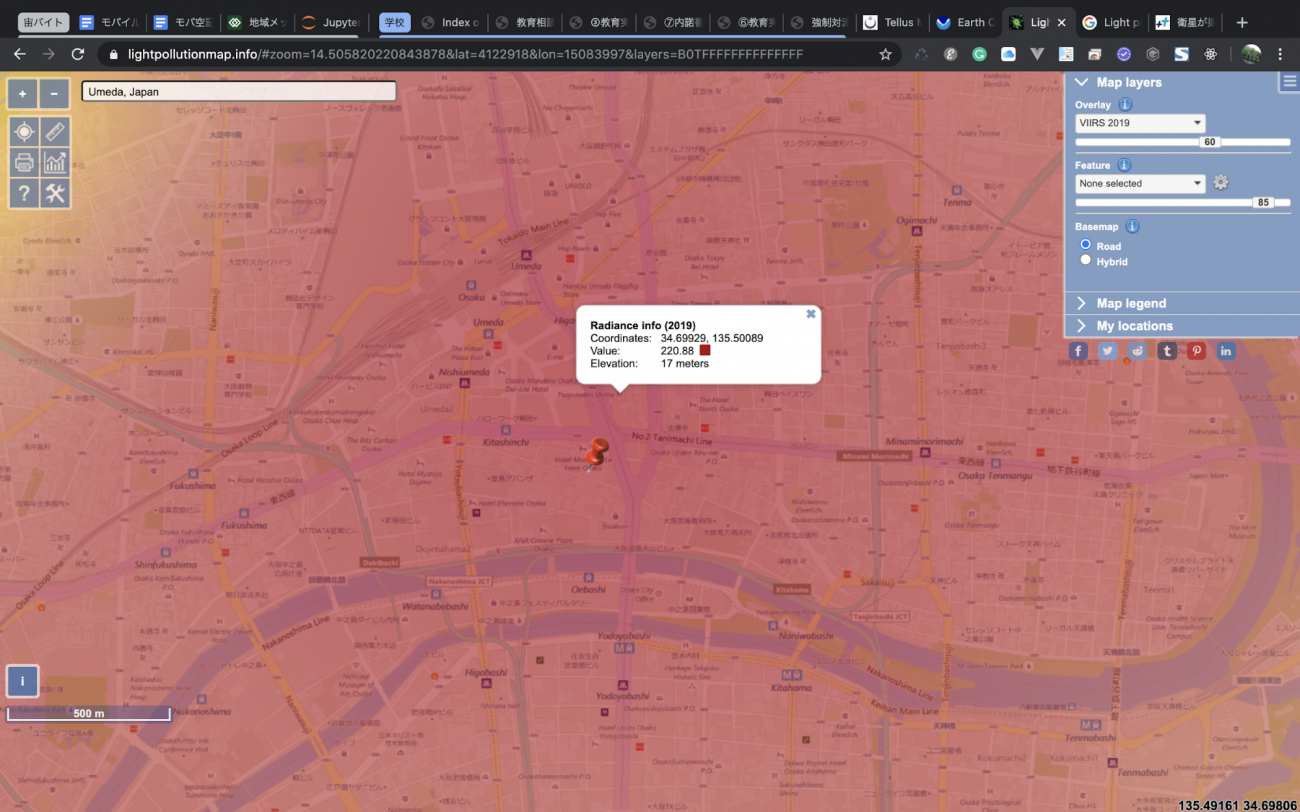
ピンの周辺の適当なところをクリックすると、Valueなどが書かれているデータが表示されます、このValueが大きければ大きいほど、明るいということになります。
これだけではわかりにくいので、二位の天神も調べてみましょう。
天神は、「Tenjin, japan」では出てこないので、まずは「Fukuoka, japan」で調べましょう。少し右側に移動すると、天神が見つかります。
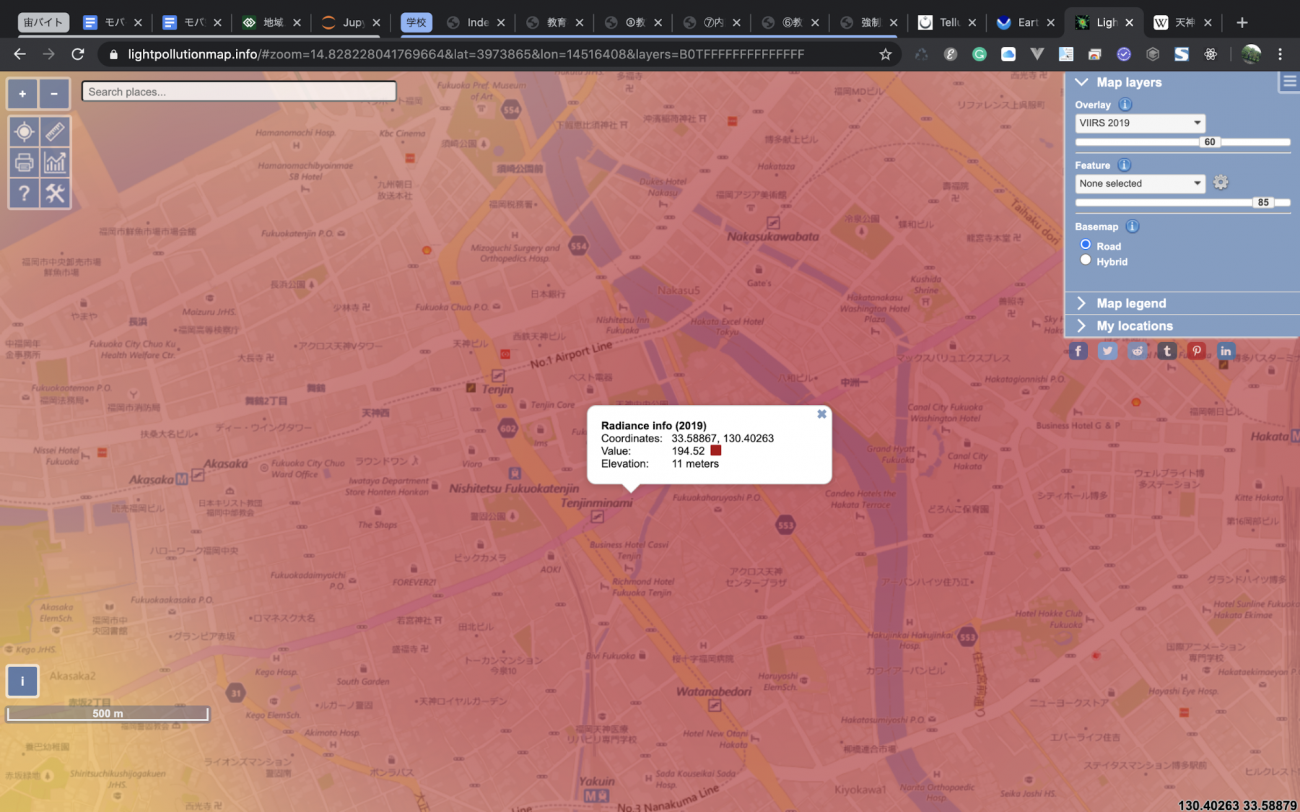
さて、梅田と天神を比較すると、梅田は220近くあるのに対して、天神は190程度ですね。これで、確かに梅田の方が夜遅くまで起きている人が多そうということがある程度信じられるようになってきました。
このように、人流データだけではなく、他の衛星データも使用すると、より正確な求めているデータを取得することができるようになります。ぜひ、みなさんも挑戦してみてください。
④雨天時と晴天時でテーマパーク周辺の人流に差はあるのか!?
今回は、ユニバーサルスタジオジャパン(USJ)を調査します。
2016年8月の天気を調べたところ、8月29日が雨で、その前後が晴れということがわかりました。したがって、今回のテストは以下の日時を採用します。
雨天時:2016年8月29日(月)
晴天時:2016年8月30日(火)
def mobaku(params={}, next_url=''):
if len(next_url) > 0:
url = next_url
else:
url = 'https://pflow.tellusxdp.com/api/v1/mobaku'
headers = {
'Authorization': f'Bearer {TOKEN}'
}
print(params)
r = requests.get(url, params=params, headers=headers)
if not r.status_code == requests.codes.ok:
r.raise_for_status()
return r.json()
def time(i):
if (i > 24):
return i - 24
else:
return i
def add_time(data):
return [time(i) for i in range(len(data['items']))]
def get_total_mobile_data_by_pandas(startDate, endDate, startTime, endTime, mesh):
for i in mesh:
data = mobaku({
'after': f"{startDate[0]}-{startDate[1]}-{startDate[2]}T{startTime[0]}:{startTime[1]}:{startTime[2]}+09:00",
'before': f"{endDate[0]}-{endDate[1]}-{endDate[2]}T{endTime[0]}:{endTime[1]}:{endTime[2]}+09:00",
'mesh': i
})
df = pd.DataFrame(data['items'], index=(add_time(data)))
df = df.loc[:, df.columns.str.startswith('total')]
try:
a += df
except:
a = df
return a
def get_amedas_1min(year, month, day, hour, minute, payload={}):
url = f"https://gisapi.tellusxdp.com/api/v1/amedas/1min/{year}/{month}/{day}/{hour}/{minute}/"
headers = {
'Authorization': 'Bearer ' + TOKEN
}
r = requests.get(url, headers=headers, params=payload)
if r.status_code is not 200:
print(r.content)
raise ValueError('status error({}).'.format(r.status_code))
return json.loads(r.content)
def getRainVal(year, month, day, payload):
def toStr(num):
a = str(num)
if (len(a) == 1):
return "0" + a
else:
return a
ar = []
for i in range(24):
amedas2 = get_amedas_1min(year, month, day, toStr(i), '00', payload)
ar.append(amedas2[0]['rain']['intensity']['value'])
return pd.DataFrame(ar, columns = ['rain-value'])雨天と晴天の降雨量を調べるため、アメダスのデータを使用します。
USJに一番近い観測所は「大阪市中央区大手前 大阪管区気象台」なので、この観測所のデータを目安とし、雨かどうかを判断します。(観測所を調べる)
a = getRainVal('2016', '08', '29', payload)
b = getRainVal('2016', '08', '30', payload)
a.plot()
b.plot()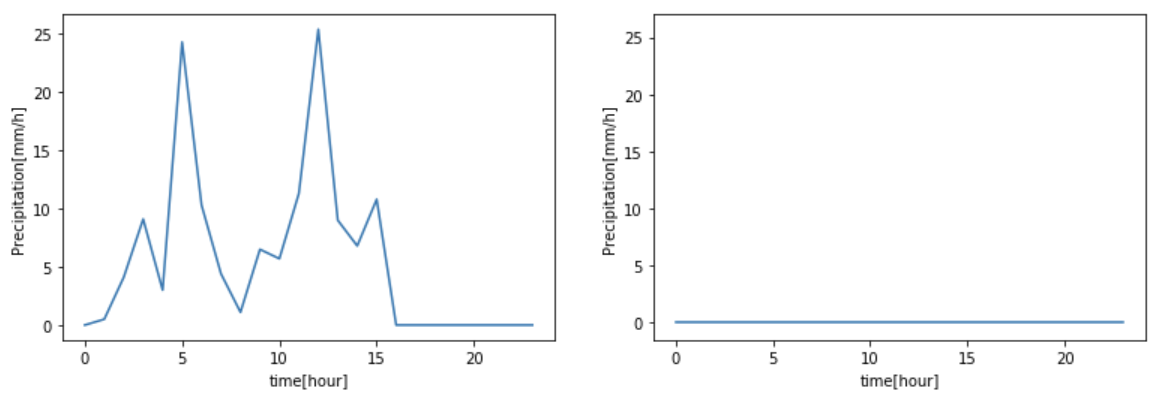
たしかに、雨が降っていることがデータでも確認できました。
次に、同じ日の人流データを取得します。
startTime = ['00', '00', '00']
endTime = ['23', '59', '59']
mesh = [513573941, 513573942, 513573943, 523503041, 523503042, 523503043, 523503044]
test_data = [
{
'startDate': [2016, '08', '31'],
"endDate": [2016, '08', '31'],
'startTime': startTime,
'endTime': endTime,
'mesh':mesh,
},
{
'startDate': [2016, '08', '29'],
"endDate": [2016, '08', '29'],
'startTime': startTime,
'endTime': endTime,
'mesh':mesh,
},
]
array = []
for i in test_data:
array.append(get_total_mobile_data_by_pandas(i['startDate'], i['endDate'],i['startTime'], i['endTime'], i['mesh']))
df = array[1]
ax = df.plot.bar(stacked=True)
ax.set_xlabel("time[h]")
ax.set_ylabel("people")
ax.set_ylim([0, 26000])
df = array[2]
ax = df.plot.bar(stacked=True)
ax.set_xlabel("time[h]")
ax.set_ylabel("people")
ax.set_ylim([0, 26000])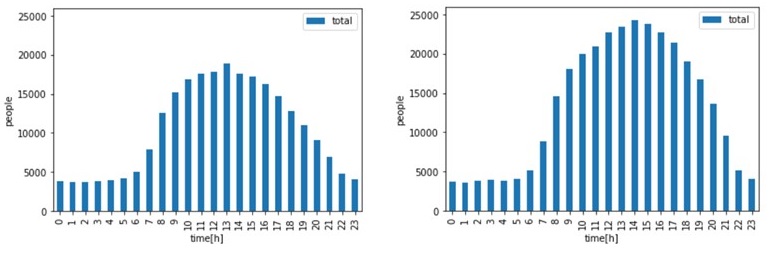
これだけでは少しわかりにくいので、(晴天時の人流 – 雨天時の人流)のデータを表示させてみましょう。
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
labels = [time(i) for i in range(24)]
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots()
rects1 = ax.bar(x - width/2, ar1, width, label='08/29')
rects2 = ax.bar(x + width/2, ar2, width, label='08/30')
ax.set_ylabel('people')
ax.set_xlabel('time[h]')
ax.set_xticks(x)
ax.set_xticklabels(labels)
ax.legend()
fig.tight_layout()
plt.show()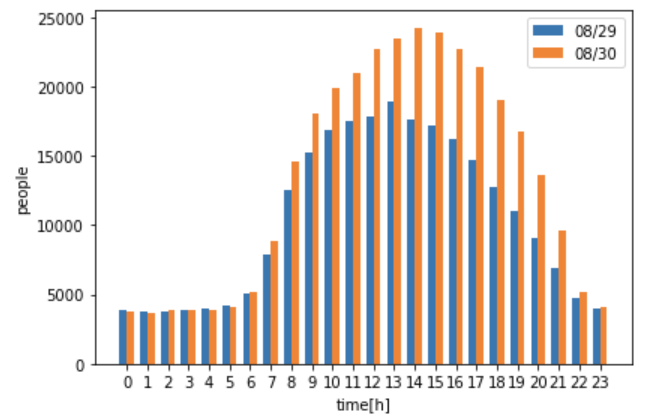
このグラフを見ると、一目瞭然ですね。晴天時の方が、雨天時よりも最大8,000人近く多いということがわかりました。
(4)まとめ
本記事では、4つの事象について、このような時に人はこのように動くのではないかと漠然と思っていたものを検証し、実際にデータとしてその確からしさを知ることができました。
漠然と仮説として考えていたことはほとんどデータで可視化できましたが、仮説の設定によっては思っていたのと違うということも出てくるのではないかと思います。
実際に気象データxモバイル空間統計データの事例としては「AIによるビッグデータ活用で30分後のタクシーの需要が予測できる!」でも紹介しているように、タクシーの配車予測にも使われており、タクシー会社の売上アップとお客さんの利便性工場を両立する素晴らしいサービスに発展しています。
アイデア次第でまだまだ利用の幅が拡がりそうなモバイル空間統計データをまずは触ってみるところからぜひ試していただければと思います。
「Tellus」で衛星データを触ってみよう!
日本発のオープン&フリーなデータプラットフォーム「Tellus」で、まずは衛星データを見て、触ってみませんか?
★Tellusの利用登録はこちらから
