Kerasを使って衛星画像内の山が独立峰か連峰かを判別するモデル作成チャレンジ
衛星画像を使って、画像内に写っている山が独立峰かそうでないかを判定するモデルの作成にチャレンジしてみました。
山の中には「独立峰」と呼ばれるものがあります。多くの山々は尾根伝いに連なっている形状(連峰)をなしているのに対して、独立峰はその名の通り、一つの山が独立して成り立っています。今回はKerasを使って、衛星画像内に写っている山が独立峰かそうでないかを判定するモデルを作成してみたいと思います。
1.独立峰とは
独立峰の多くはプリンのような円錐台の形をしています。
日本で最も有名な独立峰といえば富士山ですね。そのほかにも全国各地に様々な独立峰が存在し、例えば、北海道にある羊蹄山などは蝦夷富士とも呼ばれ親しまれています。海外ではキリマンジャロという独立峰世界最高峰の山が有名です。

今回は、タイトルにある通り、衛星画像を使って、そこに写っている山の形状からそれが独立峰であるのか、それとも連なった連峰であるのか判定してみたいと思います。
2.検出方法と使用するデータの説明
まずは独立峰と連峰のそれぞれの画像を集めます。画像の取得にはLandsat-8の衛星画像を使用することにします。その際、山の形状をよりその植生分布で際立たせるために、NDVI(正規化差植生指数)を取得するようにプリセットで指定します。
Landsat-8で取得した各画像のうち、山容(さんよう)がきれいに収まっている画像だけを抽出したのちに、Pythonの機械学習ライブラリである「Keras」を使ってシンプルなニューラルネットワークモデルを構築し、独立峰判定モデルを構築していきます。
NDVIに関しては下記の記事も参考にしてください。
【ゼロからのTellusの使い方】正規化指標で衛星データから植物、水、砂を抽出
3.コードと結果のご紹介
独立峰の画像の取得および保存
まずはじめに必要なライブラリを読み込みます。
import os, requests, json
from skimage import io
from io import BytesIO
import math
from time import sleep
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline必要な関数を定義していきます。詳細はコードを見ていただくとして、定義している関数の一覧は下記のようになります。
- TellusAPIを呼び出す汎用関数(get_api_data)
- タイル座標から緯度経度を取得する(get_tile_bbox)
- Landsat-8のシーンを取得する(get_landsat_scenes)
- シーンのパスから画像を取得する(get_landsat_image)
- タイル座標から縦横に画像を連結して取得する(get_combined_image)
TOKEN = "ここにAPIトークンを貼り付けてください"
HOST = "https://gisapi.tellusxdp.com"
def get_api_data(url, params={}):
"""
TellusAPIからデータを取得する
"""
headers = {
"content-type": "application/json",
"Authorization": "Bearer " + TOKEN
}
# APIへの負荷軽減のため、100msごとにアクセスする
sleep(0.1)
return requests.get(url, headers = headers, params = params)
def get_tile_bbox(z, x, y):
"""
タイル座標からバウンディングボックスを取得する
https://tools.ietf.org/html/rfc7946#section-5
Parameters
----------
z : int
タイルのズーム率
x : int
タイルのX座標
y : int
タイルのY座標
Returns
-------
bbox: tuple of number
タイルのバウンディングボックス
(左下経度, 左下緯度, 右上経度, 右上緯度)
"""
def num2deg(xtile, ytile, zoom):
# https://wiki.openstreetmap.org/wiki/Slippy_map_tilenames#Python
n = 2.0 ** zoom
lon_deg = xtile / n * 360.0 - 180.0
lat_rad = math.atan(math.sinh(math.pi * (1 - 2 * ytile / n)))
lat_deg = math.degrees(lat_rad)
return (lon_deg, lat_deg)
right_top = num2deg(x + 1, y, z)
left_bottom = num2deg(x, y + 1, z)
return (left_bottom[0], left_bottom[1], right_top[0], right_top[1])
def get_landsat_scenes(min_lat, min_lon, max_lat, max_lon, cloud):
""""
緯度経度、および被雲率からLandsat-8のシーンを取得する
Parameters
----------
min_lat : number
左下経度
min_lon : number
左下緯度
max_lat : number
右上経度
max_lon : number
右上緯度
cloud : number
被雲率
Returns
-------
scene : list
シーンのリスト
"""
path = "/api/v1/landsat8/scene"
queries = "?min_lat={}&min_lon={}&max_lat={}&max_lon={}&cloud={}".format(min_lat, min_lon, max_lat, max_lon, cloud)
url = HOST + path + queries
r = get_api_data(url)
return json.loads(r.content.decode('utf-8'))
def get_landsat_image(tile_path, zoom, xtile, ytile, opacity=1, r=3, g=2, b=1, preset=None):
"""
Landsat-8のバンド別合成画像を取得する
Parameters
----------
tile_path : str
対象タイルのパス
zoom : str
ズーム率
xtile : str
座標X
ytile : number
座標Y
opacity : number
透過率
r : number
Redに割り当てるバンド
g : number
Greenに割り当てるバンド
b : number
Blueに割り当てるバンド
preset : str
使用するプリセット
Returns
-------
img_array : ndarray
バンド別合成画像タイル(PNG)
"""
path = "/blend/" + tile_path.format(z=zoom, x=xtile, y=ytile)
queries = "?opacity={}&r={}&g={}&b={}".format(opacity, r, g, b)
if preset is not None:
queries += "&preset=" + preset
url = HOST + path + queries
r = get_api_data(url)
return io.imread(BytesIO(r.content))
def get_combined_image(tile_path, get_image_func, z, topleft_x, topleft_y, size_x=1, size_y=1, preset=None):
"""
結合されたタイル画像を取得する
Parameters
----------
tile_path : string
使用するタイルのパス
get_image_func : function
タイル画像取得メソッド
引数はz, x, y, option, params
z : int
タイルのズーム率
topleft_x : int
左上のタイルのX座標
topleft_y : int
左上のタイルのY座標
size_x : int
タイルを経度方向につなぎわせる枚数
size_y : int
タイルを緯度方向につなぎわせる枚数
preset : string
プリセット
Returns
-------
combined_image: ndarray
結合されたタイル画像
"""
rows = []
blank = np.zeros((256, 256, 4), dtype=np.uint8)
for y in range(size_y):
row = []
for x in range(size_x):
try:
img = get_image_func(tile_path, z, topleft_x + x, topleft_y + y, preset=preset)
except Exception as e:
img = blank
row.append(img)
rows.append(np.hstack(row))
return np.vstack(rows)まず先に、独立峰の画像を取得していきたいと思います。
取得する独立峰は下記のコードの通りです。
なるべく多くの画像を取得するためにそれぞれズームレベル:11と12の座標を指定しています。
independent_mountains_zxy = [
[11, 1805, 804], # 御嶽山
[11, 1811, 799], # 草津白根山
[11, 1824, 753], # 羊蹄山
[11, 1820, 792], # 磐梯山
[11, 1815, 798], # 武尊山
[11, 1820, 781], # 鳥海山
[11, 1820, 802], # 筑波山
[11, 1808, 797], # 妙高山
[12, 3611, 1609], # 御嶽山
[12, 3623, 1598], # 草津白根山
[12, 3649, 1507], # 羊蹄山
[12, 3641, 1585], # 磐梯山
[12, 3630, 1596], # 武尊山
[12, 3640, 1563], # 鳥海山
[12, 3641, 1604], # 筑波山
[12, 3618, 1595], # 妙高山
]座標はTellus OS上で山の名前で検索しながら、一つ一つ山容がきれいに収まる位置を探しました。
タイル座標から縦2枚、横2枚を連結した画像を返す関数を定義します。
# タイル位置から画像を取得する
def get_scene_images_from_zxy(zxy, cloud=3):
z = zxy[0]
x = zxy[1]
y = zxy[2]
bbox = get_tile_bbox(z, x, y)
min_lon = bbox[0]
min_lat = bbox[1]
max_lon = bbox[2]
max_lat = bbox[3]
scenes = get_landsat_scenes(min_lat, min_lon, max_lat, max_lon, cloud)
#print(zxy, "'s scenes_count: ", len(scenes))
size_x = 2
size_y = 2
imgs = []
for scene in scenes:
img = get_combined_image(scene['tile_path'], get_landsat_image, z, x, y, size_x=size_x, size_y=size_y, preset="natural")
# うまく画像データが取得されたものだけをimgsに追加する
if np.array(img).mean() > 0:
imgs.append(img)
return imgs
# 山岳のタイルリストから画像を取得する
def get_images_from_mountains(mountains_zxy, cloud=3):
imgs = []
for zxy in mountains_zxy:
imgs.extend(get_scene_images_from_zxy(zxy, cloud))
return imgs
それでは単独峰の画像を取得します。
imgs = []
imgs = get_images_from_mountains(independent_mountains_zxy, cloud=3)
print(len(imgs))

111枚の画像が取得できました。
これらの画像を表示して確認してみます。
col = 3
row = 7
plt.figure(figsize=(30, 60))
num = 0
# 先頭20枚までを表示してみる
while num < 20:
plt.subplot(row, col, num + 1)
plt.imshow(imgs[num])
plt.title(num)
plt.axis('off')
num += 1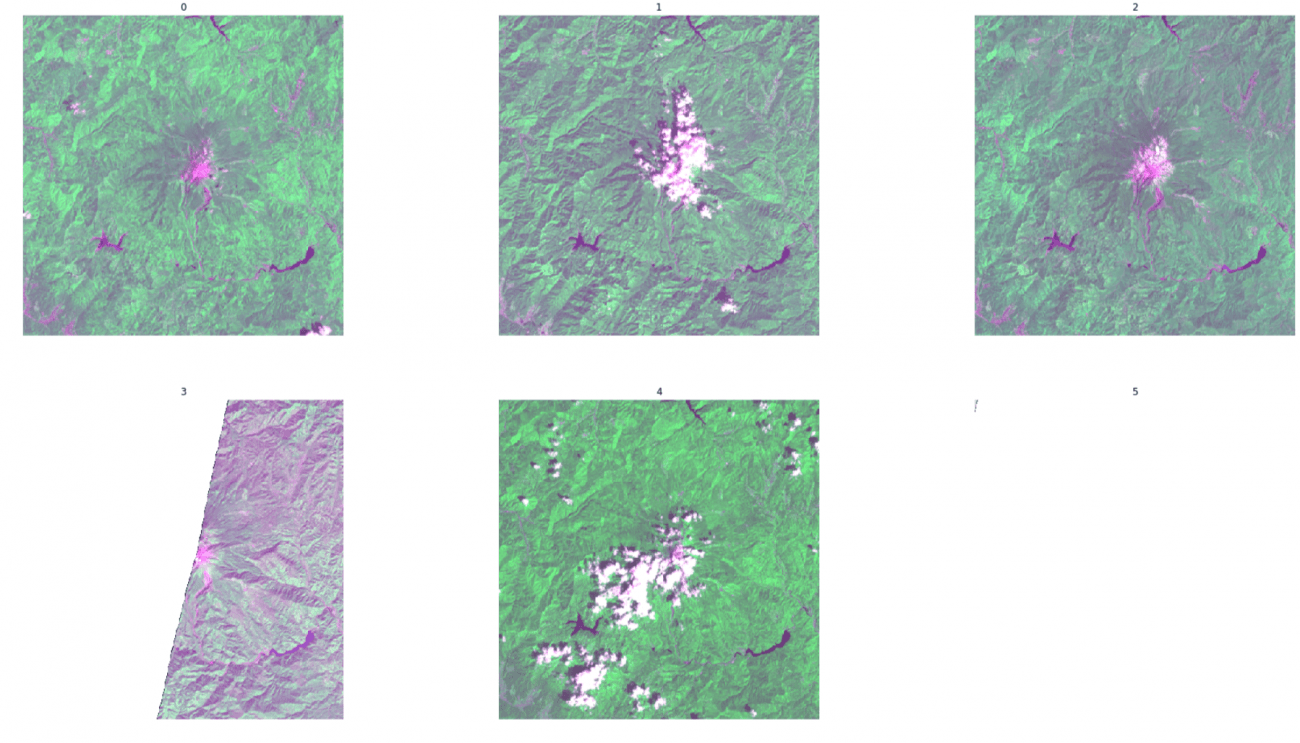
取得した画像の中には、左下の画像のように、撮影されたシーンのちょうど境界に位置していたことでかけてしまっている画像があるようです。このまま進めてしまうと作成するモデルの精度に影響が出てしまうので、かけていない画像だけを抽出するようにします。
# 画像がかけている割合を計算する
def get_correct_ratio(img):
# 画像の大きさを取得
height, width, channels = img.shape[:3]
# 画像内のピクセルを一列に並べる
flattened = img.reshape(height * width, 4)
# ピクセルの値が[0,0,0,0]、つまり完全に欠損している箇所を省く
filtered = list(filter(lambda px: np.any(px > 0), flattened))
# ピクセル値が存在する割合を計算
return len(filtered) / len(flattened)9割以上が撮影されている画像だけを抽出します。
filtered_imgs = list(filter(lambda img: get_correct_ratio(img) > 0.9, imgs))
len(filtered_imgs)
75枚ほどの画像が抽出できました。それでは再度画像を確認してみます。
col = 3
row = 7
plt.figure(figsize=(30, 60))
num = 0
while num < 20:
plt.subplot(row, col, num + 1)
plt.imshow(filtered_imgs[num])
plt.title(num)
plt.axis('off')
num += 1
うまく全体が撮影されている画像だけが抽出できたようです。
最後にimgフォルダを作成し、取得した画像を保存していきます。
for i in range(len(filtered_imgs)):
filename = "img/independent" + str(i).zfill(3) + ".png"
# 画像を保存
plt.imsave(filename, filtered_imgs[i])
連峰の画像の取得および保存
次に、連峰の画像を取得していきたいと思います。独立峰の場合とほぼ同じ流れですので、ここではコードのみ掲載させていただきます。
serial_mountains_zxy = [
[11, 1836, 746], # 大雪山旭岳 (旭岳連峰)
[11, 1825, 775], # 岩手山 (奥羽山脈)
[11, 1806, 801], # 穂高岳 (穂高連峰)
[11, 1806, 799], # 剣岳 (立山連峰)
[11, 1812, 804], # 金峰山 (秩父山地)
[11, 1814, 807], # 蛭ヶ岳 (丹沢山地)
[11, 1796, 816], # 八経ヶ岳 (紀伊山地)
[11, 1788, 808], # 氷ノ山 (中国山地)
[12, 3672, 1494], # 大雪山旭岳 (旭岳連峰)
[12, 3651, 1552], # 岩手山 (奥羽山脈)
[12, 3613, 1604], # 穂高岳 (穂高連峰)
[12, 3613, 1599], # 剣岳 (立山連峰)
[12, 3624, 1609], # 金峰山 (秩父山地)
[12, 3630, 1615], # 蛭ヶ岳 (丹沢山地)
[12, 3593, 1633], # 八経ヶ岳 (紀伊山地)
[12, 3578, 1616], # 氷ノ山 (中国山地)
]
imgs2 = []
imgs2 = get_images_from_mountains(serial_mountains_zxy, cloud=3)
filtered_imgs2 = list(filter(lambda img: get_correct_ratio(img) > 0.9, imgs2))
for i in range(len(filtered_imgs2)):
filename = "img/serial" + str(i).zfill(3) + ".png"
# 画像を保存
plt.imsave(filename, filtered_imgs2[i])
独立峰判別モデルの作成
機械学習モデルのKerasを使って独立峰か否かを判別するモデルを作成していきます。
ここではシンプルなニューラルネットワークを使ってモデルを構築します。
Kerasの使い方やモデルの構築方法については下記の記事などを参考にしてみてください。
TensorFlow, Kerasの基本的な使い方(モデル構築・訓練・評価・予測)
from keras.datasets import mnist
from keras.utils import to_categorical
from keras.layers import Conv2D, MaxPool2D, Flatten, Dense
from keras.models import Sequential
from keras.models import load_model
import matplotlib.pyplot as plt
from PIL import Image
import os
import numpy as np
from sklearn.model_selection import train_test_split
保存していた画像を読み込んで、モデルに学習させるためのデータの加工を施していきます。
folder_path = "./img/"
file_list = os.listdir(folder_path)
X = []
Y = []
image_size = 30
for file in file_list:
if ('serial' in file) or ('independent' in file):
try:
image = Image.open(folder_path + file)
except:
print('error', folder_path + file)
continue
image = image.convert("RGB")
image = image.resize((image_size, image_size))
data = np.asarray(image)
X.append(data)
if 'serial' in file:
Y.append(0)
else:
Y.append(1)
X = np.array(X)
Y = np.array(Y)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.25)
X_train = X_train.reshape(-1, image_size * image_size * 3)
X_test = X_test.reshape(-1, image_size * image_size * 3)
# 0-1 に入るように正規化する
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
# one hot encoding
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)それでは加工した学習用のデータを使って、モデルを構築していきます。
model = Sequential()
model.add(Dense(64, activation='relu', input_dim=(image_size * image_size * 3)))
model.add(Dense(2, activation='softmax'))
model.compile(optimizer='Adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=20, batch_size=20)
検証用のデータを使って、どの程度正しく独立峰を判別できたか正解率を算出してみます。
model.evaluate(X_test, y_test)
出力された配列の後者が正解率になります。結果としては70%弱の正解率と、それほど精度はよくないようです。
富士山の画像を使ってモデルの検証
次に、学習させたモデルを使って、単独峰の画像を読み込ませて正しく判定できるか検証してみます。これまでと同様にLandsat-8の衛星画像を取得し、欠けていない画像を抽出したのちに保存します。
# 富士山のタイル
fuji_zxy = [12, 3626, 1617]
fuji_images = get_scene_images_from_zxy(fuji_zxy, cloud=3)
fuji_filtered_imgs = list(filter(lambda img: get_correct_ratio(img) > 0.9, fuji_images))
for i in range(len(fuji_filtered_imgs)):
filename = "img/fuji" + str(i).zfill(3) + ".png"
# 画像を保存
plt.imsave(filename, fuji_filtered_imgs[i])
保存した富士山の画像を加工した後に、学習済みモデルのpredict関数を呼び出すことで画像の判別を行います。
folder_path = "./img/"
file_list = os.listdir(folder_path)
X_fuji = []
image_size = 30
for file in file_list:
try:
image = Image.open(folder_path + file)
except:
print('error', folder_path + file)
continue
if 'fuji' in file:
image = image.convert("RGB")
image = image.resize((image_size, image_size))
data = np.asarray(image)
X_fuji.append(data)
X_fuji = np.array(X_fuji)
X_fuji = np.array(X_fuji)
X_fuji = X_fuji.reshape(-1, image_size * image_size * 3)
# 0-1 に入るように正規化する
X_fuji = X_fuji.astype('float32') / 255
predict_classes = model.predict_classes(X_fuji)
predict_classes

9枚の富士山の画像を読み込ませましたが、結果はどれも0(連峰)と判定されてしまいました…どうやら今回の独立峰判別モデルは精度としては失敗だったようです。
4.考察と今後の改善点
なぜうまくいかなかったのかの仮説を立て、今後モデルの精度のどのように向上させていくことができるか考察してみたいと思います。
①取得した画像自体に問題があった
今回取得した画像を見ると、取得する衛星画像の被雲率が3%以下と設定していたのものの、いくつか雲が目立つ形で写り込んでしまっているものがありました。画像内に雲があると、その部分がノイズとして影響し、単独峰の形状をうまく学習できなかったという可能性が考えられそうです。パラメーターに被雲率(cloudcover)があるので、それをよりうまく活用できれば結果は変わったかもしれません。
こうしたノイズとなりうる要素が写り込んでしまっている画像を取得した画像の中からノイズとなってしまいそうな画像を取り除いて学習し直すことによって精度を向上させられるのではないかと思います。また、今回は正規化指数としてNDVIを利用しましたが、その他のプリセットに変えて学習させてみることによって、正解率が変化するかもしれません。こちらも検証の余地はありそうです。
②取得した画像の枚数が少なかった
今回は単独峰の画像を74枚、連峰の画像を96枚使用して学習を行いました。一般に機械学習モデルを構築する際には、データ量が多いほどモデルの精度も高くなると言われています。取得する画像の枚数を増やすことで精度の向上が見込めます。
しかし、Landsat-8のシーンから取得できる枚数にも限りがありそうです。その場合はAVNIR-2など他の衛星の画像も使って枚数を確保するといった手段が必要となりそうです。
③ズームレベルの取り扱いに問題があった
今回は一律にズームレベル11および12の画像を取得しました。しかし独立峰といってもその山容の広さは様々。各独立峰の山容がちょうど良いサイズで収まるズームレベルで画像を取得することでより独立峰の形状を反映した学習が可能となるかもしれません。
そのほかにも異なる学習モデルを使用するなどの改善方法が考えられますが、今回は衛星画像の取り扱いにフォーカスして、精度向上の方法を考えて見ました。
5. SAR画像で再度試してみた
上記の考察で雲の影響があったのではないかと推測しました。そこで、雲の影響を受けないSAR画像を使って、再度判別モデルを構築してみました。取得する画像はPALSAR-2という衛星の物を使います。
流れはほとんど同じですので、ここではPALSAR-2から画像を取得するコードだけ記載させていただきます。
def get_palsar2_scenes(min_lat, min_lon, max_lat, max_lon):
""""
緯度経度、および被雲率からPALSAR-2のシーンを取得する
Parameters
----------
min_lat : number
左下経度
min_lon : number
左下緯度
max_lat : number
右上経度
max_lon : number
右上緯度
Returns
-------
scene : list
シーンのリスト
"""
path = "/api/v1/palsar2/scene"
queries = "?min_lat={}&min_lon={}&max_lat={}&max_lon={}".format(min_lat, min_lon, max_lat, max_lon)
url = HOST + path + queries
r = get_api_data(url)
return json.loads(r.content.decode('utf-8'))
def get_palsar2_image(sceneId, zoom, xtile, ytile):
"""
PALSAR-2のバンド別合成画像を取得する
Parameters
----------
sceneId : str
シーンID
zoom : str
ズーム率
xtile : str
座標X
ytile : number
座標Y
Returns
-------
img_array : ndarray
バンド別合成画像タイル(PNG)
"""
path = "/PALSAR-2/{}/{}/{}/{}.png".format(sceneId, zoom, xtile, ytile)
url = HOST + path
r = get_api_data(url)
return io.imread(BytesIO(r.content))
さて、その結果は…
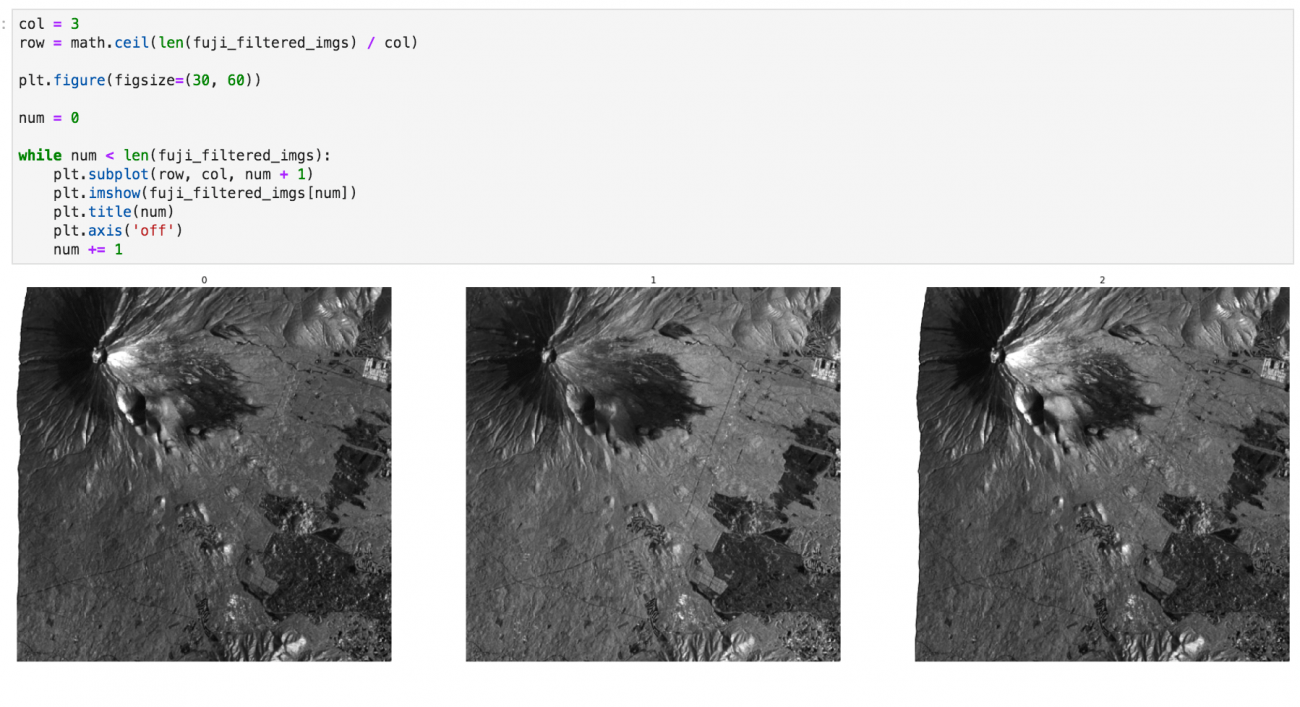

残念ながらSAR画像を用いてもうまく判別することはできませんでした…単純な雲の有無だけでなく、より複雑な要因が影響していそうだと分かりました。
6.まとめ
Landsat-8の衛星画像とSAR画像を使って、独立峰と連峰の判別モデルの構築にチャレンジしてみました。Tellusの開発環境を用いると、APIを使って簡単に衛星画像を取得・保存することができ、そのまま機械学習ライブラリを使って学習モデルを構築することができました。
しかし、結果としては、うまく判別するモデルを構築するには至りませんでした。学習に使用する画像の取得方法を工夫することで、モデルの精度を向上させる余地はまだありそうです。
Tellusの開発環境を利用することで簡単に機械学習モデルを構築できることがわかりました。日々撮影されている衛星画像には、様々な地形や地物が写っています。山以外にも、写り込んでいる物を判別するモデルを色々と構築してみるのも面白いと思います。
また、今回は「画像内に独立峰が写っているか(=画像分類)」という問題に取り組みましたが、「画像内のどこに写っているか(=物体検出)」というモデルを構築することにも取り組んでみたいなとも思いました。
この記事が衛星画像を使った機械学習モデル構築の参考になれば幸いです。
「Tellus」で衛星データを触ってみよう!
日本発のオープン&フリーなデータプラットフォーム「Tellus」で、まずは衛星データを見て、触ってみませんか?
★Tellusの利用登録はこちらから
