SAR画像から光学画像への変換をpix2pixで実装して、作った生成器で別のSAR画像を分析してみた
画像生成アルゴリズムとして近年話題に上がることの多いGANを用いて、直感的に分かりにくいSAR画像を光学画像に変換することにチャレンジしてみました。
本記事は、人の目で見て分かりやすい光学画像と、パッと見ただけでは分かりにくいSAR画像という特徴の異なる2つの衛星データについて、画像生成アルゴリズムとして近年話題に上がることの多いGANを用いてSAR画像をより分かりやすいデータに変換することができるかチャレンジしてみたという内容です。
まずは光学画像とSAR画像の違いについて簡単にご説明します。
【光学画像】
光を用いたリモートセンシング技術で、太陽光に対する散乱光を測定して、遠距離で測定した対象物の性質を分析します(一般的に衛星画像と聞くとこちらを指すことが多いです)。ただし、雲が覆っている地域や夜間は観測できません。
【SAR画像】
電波を対象物に照射した際の反射波を観測することで、遠距離で測定した対象物の性質を分析します。光学画像とはかなり見え方が異なりますが、雲が覆っていても夜間でも観測が可能であることや、位相情報を利用して地盤変動などを観測できるため、地震などの災害時に重宝されています。

ご覧いただくと分かる通り、光学画像は、基本的には人がGoogle Earthでよく見る画像に近い物が表示されるので親しみやすいです。
※光波領域を使用して測定された物であるため、人の目には見えない近赤外などを含めた様々な波長を組み合わせた測定もされています
一方で、電波領域を使用して測定されているSAR画像は、可読しやすい光学画像と見え方や特性が全く異なります。画像を見ていただくと分かる通り、初心者の方にとってSAR画像は理解しにくく、扱いづらい画像です。
もしもSAR画像の可読性を向上させることができれば、衛星画像活用がより広まるきっかけとなるでしょう。また、それを実現するためには、SAR画像と光学画像との関係性を理解することが重要だと考えられます。
加えて、近年では衛星技術が進歩しているため複数のセンサやパラメータを用いた詳細な測定が可能になりましたが、過去に観測された分解能の乏しいorグレースケールの画像しかない光学画像やSAR画像は数多く存在し、これらの情報を元に過去の情報をより詳細な状態に復元したり重要な情報を取り出すことも重要な課題です。
上記の課題のアプローチとして、今回の解析では「SAR画像を光学画像へ変換する方法を機械学習を用いて実装」することによって、SAR画像と光学画像との関係性について解析します。
実際に使用する機械学習の手法としては、画像生成アルゴリズムとして有名なGANの一種であるpix2pixを用いてSAR画像から光学画像への変換を学習させました。また、比較対象としてグレースケールの光学画像からRGBの光学画像への変換もpix2pixで学習させました。
※これらの実装にはSAR画像と光学画像の地形が一致したデータセットが大量に必要で、個人で作成するには膨大な時間がかかるため、Tellus外部で公開されているSentinel-1(SAR)およびSentinel-2の画像(光学画像)ペアで学習を行いました。

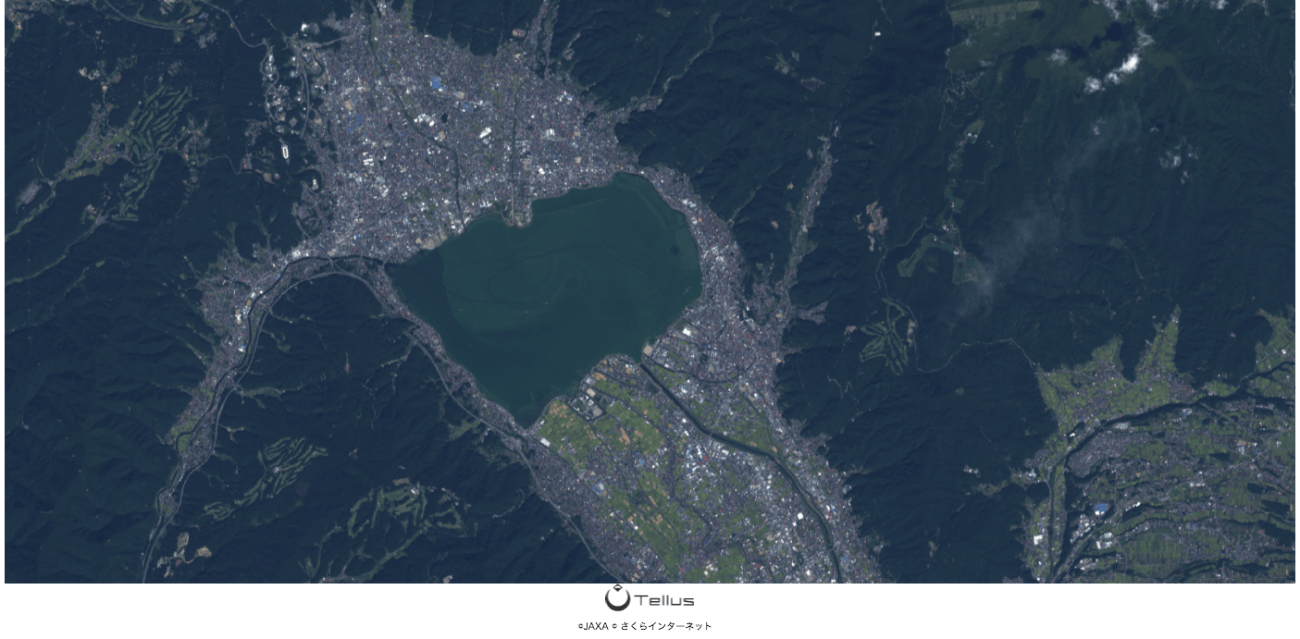
さらに、pix2pixで作成した生成器を用いて、Tellusで公開されているPALSAR2の諏訪湖(図2)周辺のSAR画像をカラーのRGB画像に変換しようと試みた場合、SAR画像(グレースケール)→光学画像(RGB)の生成器と光学画像(グレースケール)→光学画像(RGB)の生成器でどのような結果が生まれたかをご紹介したいと思います。
(1)GAN(Generative Adversarial Networks)とは?
では、実際にチャレンジを始める前に、今回の肝となるGANについてご説明します。
GANは二つのネットワーク(生成器と識別器)を互いに競わせるように学習する構造を持った手法です(今回使用するpix2pixもGANの一種です)。
生成器である入力画像から本物そっくりの偽画像を生成していく一方で、識別器では生成器から生成された偽画像と本物画像を比較してどちらが本物が判定します。生成器はなるべく本物そっくりの画像を生成しようとして、識別器では生成器が作った画像を偽物と判定するように頑張ります。この競争過程を通じて獲得された画像を本物そっくりに変換する規則性や特徴量を見出していくのがGANの大きな特徴になっています。
今回使用するpix2pixと呼ばれる手法は、通常のGANと比較して以下のような特徴があります。
・通常のGANのようにランダムなノイズではなく、元の画像を入力とする
・学習とテスト時にドロップアウトを導入してノイズを付加
・生成器にU-Netと呼ばれるEncoder-DecoderのDecoderでエンコーダの情報を結合
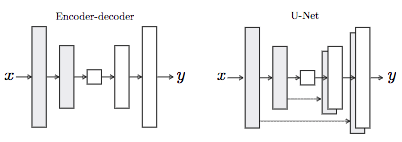
・生成器の損失関数にL1損失が導入されており、画像のボケを防ぐ効果があります。また、L1損失の比率を大きくすると元画像に近くなります
大まかに説明すると、通常のGANの生成器はノイズ→次元を拡張→次元を縮小→生成なのに対して、pix2pixの生成器では元画像→次元を拡張→次元を縮小→生成という流れで偽物が生成されていきます(pix2pixの生成過程では、ドロップアウトを導入することでノイズとしての役割を果たしています)。pix2pixは通常のGANと比較して、画像のボケを防ぐ古典的な距離(L1損失)が生成器に導入されているため、スペックルと呼ばれるゴマ状のノイズが発生しているSAR画像に対しては有力な手法であると考えられます。
今回はSAR画像を元画像として、それをRGBの光学画像に変換する学習をpix2pixで行なっていきます。また、比較対象としてグレースケールの光学画像をRGBの光学画像に変換する学習も行います。
元論文はこちら
(2)使用するデータセットと開発環境
・データセット
pix2pixで訓練するための画像セットは、さすがに自力で大量のデータセットを作成するのは無理があったため、今回は以下の論文で公開されたデータセットを使用することにしました。
・(PDF) The SEN1-2 dataset for deep learning in SAR-optical data fusion
・Medien- und Publikationsserver
このデータセットは、Sentinel-1(SAR衛星)とSentinel-2(光学衛星)から取得された画像を、Google Earth EngineとMATLABを用いて周辺の地形を一致させた画像が282384組もあるデータセットになります。
今回はこちらのデータセットから3964組のSAR画像と光学画像のペアを取り出して、pix2pixによる画像生成を試みました。
ただし、データセットのSentinel-1のSAR画像はVV偏波のみとなっていたので、本解析での結果はあくまでVV偏波のSAR画像からRGBの光学画像への変換になります。全ての画像サイズは256×256に統一されています。偏波について詳しく知りたい方は、以下の記事を参考にしていただければと思います。
SAR(合成開口レーダ)のキホン~事例、分かること、センサ、衛星、波長~
・開発環境
開発環境は、Tellusで申請すれば利用することができるGPUサーバ(高火力コンピューティング)を使用しています。スペックは以下で、また、GPUサーバで構築したjupyter notebook上でPyTorchによるpix2pix解析を行なっております。
GPU: NVIDIA Tesla V100 for PCI-Express (32GB) ×4
CPU: Xeon E5-2623 v3 4Core×2 (8C/16T 3.0GHz Max3.5GHz)
メモリ: 128GB
ディスク: SSD 480GB 2台/1組
開発環境: Jupyter Notebook
使用言語: PyTorch
TellusのGPUサーバでのPyTorchのインストールやJupyter Notebookの環境構築は以下の記事を参考にしていただければと思います。
・TellusのGPUサーバからPyTorchの環境を構築する
・GPUサーバからリモートでjupyter操作してtorchも触れるようにする
(3)SAR画像(グレースケール)→光学画像(RGB)をpix2pixで実装
まず初めにグレースケールのVV偏波のSAR画像をRGBの光学画像に変換するための処理を行いたいと思います。エポック数は100、ミニバッチのサイズは128となっていて、上記の環境で2時間かからない程度で解析が終わりました。
まず、必要なモジュールを読み込んでいきます。
import os
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optimizers
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import torchvision
from torchvision import transforms, datasets
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
%matplotlib inline
import statistics
from tqdm import tqdm
import pickle
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
torch.cuda.device_count()次に、必要なデータセットを読み込んでいきます。今回はConcatDatasetクラスを作成してSAR画像と光学データを訓練時に両方とも呼び出して学習ができるようにしています。
class Gray(object):
def __call__(self, img):
gray = img.convert('L')
return gray
class ConcatDataset(torch.utils.data.Dataset):
def __init__(self, *datasets):
self.datasets = datasets
def __getitem__(self, i):
return tuple(d[i] for d in self.datasets)
def __len__(self):
return min(len(d) for d in self.datasets)
def load_datasets():
SAR_transform = transforms.Compose([
Gray(),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(0.5,))
])
opt_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,0.5,0.5,), std=(0.5,0.5,0.5,))
])
# s1フォルダにはSAR画像のセット、s2フォルダには光学画像のセットが入っています。
SAR_trainsets = datasets.ImageFolder(root = './GAN_datasets/s1',transform=SAR_transform)
opt_trainsets = datasets.ImageFolder(root = './GAN_datasets/s2',transform=opt_transform)
Image_datasets = ConcatDataset(SAR_trainsets,opt_trainsets)
train_loader = torch.utils.data.DataLoader(
Image_datasets,
batch_size=128, shuffle=True,
num_workers=4, pin_memory=True)
return train_loader次に、pix2pixの生成器(Generator)と識別器(Discriminator)をそれぞれ構築していきます。
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.enc1 = self.conv_bn_relu(1, 64, kernel_size=5)
self.enc2 = self.conv_bn_relu(64, 128, kernel_size=3, pool_kernel=4)
self.enc3 = self.conv_bn_relu(128, 256, kernel_size=3, pool_kernel=2)
self.enc4 = self.conv_bn_relu(256, 512, kernel_size=3, pool_kernel=2)
self.dec1 = self.conv_bn_relu(512, 256, kernel_size=3, pool_kernel=-2,flag=True,enc=False)
self.dec2 = self.conv_bn_relu(256+256, 128, kernel_size=3, pool_kernel=-2,flag=True,enc=False)
self.dec3 = self.conv_bn_relu(128+128, 64, kernel_size=3, pool_kernel=-4,enc=False)
self.dec4 = nn.Sequential(
nn.Conv2d(64 + 64, 3, kernel_size=5, padding=2), # padding=2にしているのは、サイズを96のままにするため
nn.Tanh()
)
def conv_bn_relu(self, in_ch, out_ch, kernel_size=3, pool_kernel=None, flag=None, enc=True):
layers = []
if pool_kernel is not None:
if pool_kernel > 0:
layers.append(nn.AvgPool2d(pool_kernel))
elif pool_kernel < 0:
layers.append(nn.UpsamplingNearest2d(scale_factor=-pool_kernel))
layers.append(nn.Conv2d(in_ch, out_ch, kernel_size, padding=(kernel_size - 1) // 2))
layers.append(nn.BatchNorm2d(out_ch))
# Dropout
if flag is not None:
layers.append(nn.Dropout2d(0.5))
# LeakyReLU or ReLU
if enc is True:
layers.append(nn.LeakyReLU(0.2, inplace=True))
elif enc is False:
layers.append(nn.ReLU(inplace=True))
return nn.Sequential(*layers)
def forward(self, x):
x1 = self.enc1(x)
x2 = self.enc2(x1)
x3 = self.enc3(x2)
x4 = self.enc4(x3)
out = self.dec1(x4)
out = self.dec2(torch.cat([out, x3], dim=1))
out = self.dec3(torch.cat([out, x2], dim=1))
out = self.dec4(torch.cat([out, x1], dim=1))
return out
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = self.conv_bn_relu(4, 16, kernel_size=5, reps=1) # fake/true opt+sar
self.conv2 = self.conv_bn_relu(16, 32, pool_kernel=4)
self.conv3 = self.conv_bn_relu(32, 64, pool_kernel=2)
self.out_patch = nn.Conv2d(64, 1, kernel_size=1)
def conv_bn_relu(self, in_ch, out_ch, kernel_size=3, pool_kernel=None, reps=2):
layers = []
for i in range(reps):
if i == 0 and pool_kernel is not None:
layers.append(nn.AvgPool2d(pool_kernel))
layers.append(nn.Conv2d(in_ch if i == 0 else out_ch,
out_ch, kernel_size, padding=(kernel_size - 1) // 2))
layers.append(nn.BatchNorm2d(out_ch))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv3(self.conv2(self.conv1(x)))
return self.out_patch(out)次に、読み込んだデータセットや構築した生成器および識別器を用いて訓練を行なっていきます。
def train():
torch.backends.cudnn.benchmark = True
model_G, model_D = Generator(), Discriminator()
model_G, model_D = nn.DataParallel(model_G), nn.DataParallel(model_D)
model_G, model_D = model_G.to(device), model_D.to(device)
params_G = torch.optim.Adam(model_G.parameters(),lr=0.0002, betas=(0.5, 0.999))
params_D = torch.optim.Adam(model_D.parameters(),lr=0.0002, betas=(0.5, 0.999))
# ラベル変数 (PatchGAN),損失関数
ones = torch.ones(128, 1, 32, 32).to(device)
zeros = torch.zeros(128, 1, 32, 32).to(device)
bce_loss = nn.BCEWithLogitsLoss()
mae_loss = nn.L1Loss()
# 損失を表示するための辞書
result = {}
result["log_loss_G_sum"] = []
result["log_loss_G_bce"] = []
result["log_loss_G_mae"] = []
result["log_loss_D"] = []
output_Gsum = []
output_Gbce = []
output_Gmae = []
output_D = []
# 訓練
dataset = load_datasets()
for i in range(100):
log_loss_G_sum, log_loss_G_bce, log_loss_G_mae, log_loss_D = [], [], [], []
for (input_gray, real_color) in dataset:
# input_gray[0] がSAR画像、input_gray[1]がラベル(今回は必要ない)
# real_color[0]が光学画像、input_gray[1]がラベル
batch_len = len(real_color[0])
real_color, input_gray = real_color[0].to(device), input_gray[0].to(device)
### Gの訓練
# 偽のカラー画像を作成
fake_color = model_G(input_gray)
# 識別器の学習の際に生成器に影響が出ないようにするため、偽画像を一時保存
fake_color_tensor = fake_color.detach()
# 偽画像を本物と騙せるようにロスを計算
LAMBD = 100.0 # L1損失と交差エントロピー損失の比率を決める超パラメータ
out = model_D(torch.cat([fake_color, input_gray], dim=1))
loss_G_bce = bce_loss(out, ones[:batch_len])
loss_G_mae = LAMBD * mae_loss(fake_color, real_color)
loss_G_sum = loss_G_bce + loss_G_mae
log_loss_G_bce.append(loss_G_bce.item())
log_loss_G_mae.append(loss_G_mae.item())
log_loss_G_sum.append(loss_G_sum.item())
# 微分計算・重み更新
params_D.zero_grad()
params_G.zero_grad()
loss_G_sum.backward()
params_G.step()
### Discriminatorの訓練
# 本物のカラー画像を本物と識別できるようにロスを計算
real_out = model_D(torch.cat([real_color, input_gray], dim=1))
loss_D_real = bce_loss(real_out, ones[:batch_len])
# 偽の画像の偽と識別できるようにロスを計算
fake_out = model_D(torch.cat([fake_color_tensor, input_gray], dim=1))
loss_D_fake = bce_loss(fake_out, zeros[:batch_len])
# 実画像と偽画像のロスを合計
loss_D = loss_D_real + loss_D_fake
log_loss_D.append(loss_D.item())
# 微分計算・重み更新
params_D.zero_grad()
params_G.zero_grad()
loss_D.backward()
params_D.step()
result["log_loss_G_sum"].append(statistics.mean(log_loss_G_sum))
result["log_loss_G_bce"].append(statistics.mean(log_loss_G_bce))
result["log_loss_G_mae"].append(statistics.mean(log_loss_G_mae))
result["log_loss_D"].append(statistics.mean(log_loss_D))
print(f"eposh:{i+1}=>" + f"log_loss_G_sum = {result['log_loss_G_sum'][-1]} " +
f"({result['log_loss_G_bce'][-1]}, {result['log_loss_G_mae'][-1]}) " +
f"log_loss_D = {result['log_loss_D'][-1]}")
output_Gsum.append(result['log_loss_G_sum'][-1])
output_Gbce.append(result['log_loss_G_bce'][-1])
output_Gmae.append(result['log_loss_G_mae'][-1])
output_D.append(result['log_loss_D'][-1])
# 画像を保存
if not os.path.exists("SARtoOpt"):
os.mkdir("SARtoOpt")
# 生成画像を保存
torchvision.utils.save_image(input_gray[:min(batch_len, 100)],
f"SARtoOpt/gray_epoch_{i:03}.png",
range=(-1.0,1.0), normalize=True)
torchvision.utils.save_image(fake_color_tensor[:min(batch_len, 100)],
f"SARtoOpt/fake_epoch_{i:03}.png",
range=(-1.0,1.0), normalize=True)
torchvision.utils.save_image(real_color[:min(batch_len, 100)],
f"SARtoOpt/real_epoch_{i:03}.png",
range=(-1.0, 1.0), normalize=True)
# 生成器と識別器の学習モデルをそれぞれ保存
if not os.path.exists("SARtoOpt/models"):
os.mkdir("SARtoOpt/models")
if i % 10 == 0 or i == 99:
torch.save(model_G.state_dict(), f"SARtoOpt/models/gen_{i:03}.pt")
torch.save(model_D.state_dict(), f"SARtoOpt/models/dis_{i:03}.pt")
# ログ
with open("SARtoOpt/logs.pkl", "wb") as fp:
pickle.dump(result, fp)
plt.plot(output_Gsum, color = "red")
plt.plot(output_Gbce, color = "blue")
plt.plot(output_Gmae, color = "green")
plt.plot(output_D, color = "black")
plt.show()
if __name__ == "__main__":
train()訓練結果
以下が、100回訓練した時の生成器モデルを使ってSAR画像を光学画像のRGB形式に変換した結果になります。
図4は変換の一例になります。大まかな色付けはうまくいってますし、川などもしっかり識別されていますが、細かい建物の構造までは取得できず、一部の建物群がぼやけて見える形になりました。

また、図5も実際の生成例になりますが、元のSAR画像の輪郭や地形などが一部欠損していることもあり、完璧な光学画像の変換はできませんでした。

画像によっては真ん中の画像のように一部の情報(左下部分の道路の情報)が上手く生成できなかったり畑の細かい色合いなどを抽出できなかったりする生成例が見受けられました。しかしながら、光学画像と全く見え方も性質の異なるSAR画像からRGBの光学画像と類似した大まかな土地状況の把握と色付けができたのは驚きでした。
(4)光学画像(グレースケール)→光学画像(RGB)をpix2pixで実装
この場合は、RGBからグレースケールに変換した時に両者を同時にデータセットとして読み込む必要性があったので、dataloaderにグレースケール変換したものを一緒にして訓練時に呼び出す必要性があります(下記のコード部分以外はほとんど同じです)。
class ColorAndGray(object):
def __call__(self, img):
gray = img.convert('L')
return img, gray
class MultiInputWrapper(object):
def __init__(self, base_func):
self.base_func = base_func
def __call__(self, xs):
if isinstance(self.base_func, list):
return [f(x) for f,x in zip(self.base_func, xs)]
else:
return [self.base_func(x) for x in xs]
def load_datasets():
transform = transforms.Compose([
ColorAndGray(),
MultiInputWrapper(transforms.ToTensor()),
MultiInputWrapper([
transforms.Normalize(mean=(0.5,0.5,0.5,), std=(0.5,0.5,0.5,)),
transforms.Normalize(mean=(0.5,), std=(0.5,))
])
])
trainsets = datasets.ImageFolder(root = './GAN_datasets2',transform=transform)
train_loader = torch.utils.data.DataLoader(trainsets, batch_size=128, num_workers=4, pin_memory=True)
return train_loader訓練結果
以下の訓練結果では、一番上手く生成できたエポック数20回の時の生成器モデル(図6)と100回目の時の生成器モデルの結果(図7)を提示します。結果をよく見ると、エポック数が20の時の生成器から変換されたRGB画像は、多少の色合いの問題はありますが、概ね期待通りの着色がされており、実際の光学画像の森林や湖、道路などの情報をしっかりと反映できていることが分かります。

しかしながら、図7の方では図6の時と比べて多くの訓練を行ったにも関わらず、湖の一部や道路の一部にありもしない斑点や光沢が浮き出ており、上手く着色ができなくなっていました。

この原因を探るために、エポック数毎の生成器や識別器の損失をプロットしたのが図8になります。
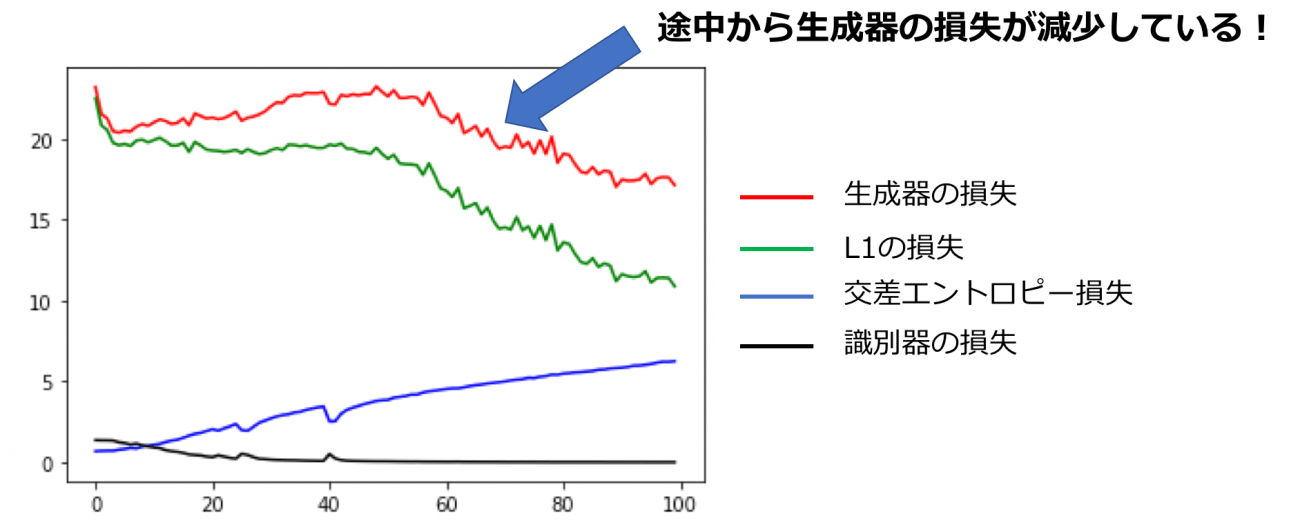
GANの訓練時は識別器の損失がエポック数ごとに減少して生成器の損失が小さな分散で増加していくのが理想なのですが、上図を見ると生成器の損失がエポック数40くらいを境に損失が減少しています。これは端的に言うと「エポック数40以降は意味のない画像を生成している可能性がある」と解釈することができ、実際にそれが反映された着色結果になってしまいました。しかしながら、生成器の損失が徐々に上昇している過程では安定した着色が行われており、かなり精度の高い着色が行われていました。
(5)実際に訓練した生成器を用いてPALSAR2のSAR画像で検証!
それでは、SAR画像(グレースケール)→光学画像(RGB)の生成器と光学画像(グレースケール)→光学画像(RGB)の生成器を作ることができたので、いよいよTellusで公開されているPALSAR2のグレースケール画像を用いてRGB変換したいと思います!
使用した画像はPALSAR2のL2.1の画像で諏訪湖周辺から切り出しました。PALSAR2のL2.1プロダクトの取り出し方法は以下を参考にしていただければと思います。
TellusでPALSAR-2のL2.1標準処理データを使って 土地被覆の抽出にチャレンジ
図9のD.が実際に生成器に入力する画像になりますが、元のC.などの画像と比較すると、生成器に通すために256×256の画像に圧縮しているため、一部の建物や道路などの細かい情報が欠損している形になっています。このように、一部の情報が失われた状態のSAR画像に対して、生成器はどのような振る舞いをするのか検証していきます。

生成結果
図9のD.のHH偏波の画像を生成器に入れた時の結果が図10になります。

どちらも綺麗なRGB画像にすることができませんでした。少しだけ光学画像(グレースケール)→光学画像(RGB)の生成器の方が見た目がスッキリしてますが、SAR画像→光学画像の生成器の方が諏訪湖と市街地の分け目がくっきりしているように感じました。
当初の期待通り、SAR画像からRGBの綺麗な光学画像に変換することはできませんでしたが、さらにチャレンジを続けます。
次は、以下の手順でHH偏波とHV偏波それぞれのSAR画像に対して二つの生成器を用いてRGB画像を生成し、それらを組み合わせて擬似カラー画像を作成した時にどのような結果になるのか検証しました。
1.256×256に縮小したSAR画像に対して、先ほど作成した二つの生成器を用いてRGBに変換する処理をHH&HV偏波それぞれのSAR画像に適用して変換する
2.それぞれ生成した画像を組み合わせて擬似カラー画像にする(赤:HH偏波、緑:HV偏波、青:HH偏波とHV偏波の差分)
3.手順2.で作成した擬似カラー画像と実際に縮小前のHH&HV偏波の画像を組み合わせた本来の擬似カラー画像を比較する
これにより、先ほど作成した二つの生成器のノイズに対する頑健性や画像のどの特徴を保存しているかを比較することができます。
実証結果
先ほどの手順で解析を行なった結果、図11のような結果になりました。

結果として、もちろんSAR画像を圧縮する前の擬似カラー画像の方が一番綺麗なのですが、pix2pixの生成器に入れるために縮小させたSAR画像に関しては、SAR画像→光学画像の生成器の方が本来のSAR画像としての情報が綺麗に保持されているのに対して、光学画像(グレースケール)→光学画像(RGB)を通じて作成された生成器では、SAR画像特有の情報をあまり保持できずノイズで埋もれてボヤけた結果になりました。
以上のことから、SAR画像→光学画像で訓練させた生成器の方が、光学画像(グレースケール)→光学画像(RGB)の生成器と比べてSAR特有の情報を保存されたまま画像を生成することができることがわかりました。
(6)今後の課題
今回はConditional-GANの一種であるpix2pixを用いてSAR画像(グレースケール)→光学画像(RGB)の生成器と光学画像(グレースケール)→光学画像(RGB)の生成器をそれぞれ訓練して作成しました。また、両者の生成器をTellusで公開されているPALSAR2の画像を生成器に入れて画像を生成し、両者の生成器の特定の違いを比較してみましたが、以下のような課題が考えられました。
・訓練に用いたデータセットのペアが約4000枚だったため、本格的に実証するにはさらに多くの画像を用いて学習する必要がある
・(使用したデータセットの都合上、)訓練に使用した画像がVV偏波のみであるのに対して、実際のテスト画像がPALSAR2のHHとHV偏波であったことから、偏波画像の種類が一致していないため、VV偏波の強度画像がTellus上で公開され次第検証する必要がある
・訓練に使用した画像がSentinel-1から撮像されたSAR画像だが、このSAR画像はC-bandの周波数帯で撮像されているのに対して、PALSAR2はL-bandの周波数帯を用いて撮像しているため、周波数帯の違いを考慮した画像情報が学習されていない可能性が高いと推測できます。また、PALSAR2とSentinel-1の画像分解能の違いもあるため、本格的に検証するためには、PALSAR2の画像データセットを大量に作る必要性がある
(7)まとめ
さすがにSAR画像から光学画像のRGB画像に綺麗に変換することはSAR衛星の周波数帯や偏波成分の違いなどもあり、できませんでした。
しかしながら、SAR画像から光学画像へ変換するための訓練をした生成器の方がSAR画像のノイズに影響されることなく、各偏波成分から生成された画像を擬似カラーにしても都市部などの情報が保存されやすい傾向にあることが確認できました。
このような技術の発展により、例えば昔のSAR画像からRGB画像を作ったり光学画像からSAR画像に変換するなどという試みが、違いや衛星の特徴を考慮したデータセットを作成して解析することによって可能になる日もくるかもしれません。
