80%は中国依存。漢方薬の原料、生薬の国内栽培適地の探索チャレンジ~データ解析編~
生薬の国内栽培適地を見つける方法について、宙畑が行った解析の手順を紹介しています。
はじめに
漢方薬の原料である生薬は80%を中国生産に依存している中で、直近は中国での需要増によって価格が上がっています。
本記事は、このような背景において、生薬の国内栽培最適地を衛星データから探してみようと始まった企画の後編です。
80%は中国依存。漢方薬の原料、生薬の国内栽培適地を衛星データで探索チャレンジ~ヒアリング編~
衛星データ利活用の兆しが見えた?80%は中国依存。漢方薬の原料、生薬の国内栽培適地を衛星データで探索チャレンジ~解析結果共有編~
この記事では中編で紹介したデータ分析の詳細について解説します。本データ分析では、AMeDAS(以下、アメダス)データを利用して、気象データから生薬の国内栽培の候補地を探しています。生薬のなかでも特に国内需要が高く、かつ中国での生産比率が高いものは需要が高いということになります。加えて、日本で育てることができそうなトウキとシャクヤクを今回のターゲットとしています。
この記事を読むと次のようなことがわかります。
・アメダスの1分値APIを利用して気象データを取得する方法がわかるようになる
・気象データを利用して、農作物栽培の適地を探す方法がわかるようになる
この記事では、最終的に生薬栽培候補地の予測していますが、あくまで簡易的な方法で予測をした結果です。また、実際に候補地の下見を行う場合、決して危険な場所や私有地には足を踏み入れないようにしてください。
生薬の国内栽培適地を探すための基本的な考え方
生薬を育成するためには、それぞれの生薬(今回の場合はトウキとシャクヤク)に適した気候条件と地質条件を知ることが重要になります。仮にこれらの条件が明らかになっていれば、衛星データや地質データを利用することで国内全体から栽培適地を探索することができます。
しかしながら、生薬の理想的な栽培条件というのは具体的な数値の条件というものが少なく、また理想的な地質条件もはっきりとしていません。そこで今回の記事では、日本国内においてトウキとシャクヤクの名産地と呼ばれる土地をピックアップし、その土地と似た条件を持つ土地を栽培適地として探索します。
今回は、トウキ、シャクヤクの産地として有名なもののうち、実際の生産地が絞りやすい2つの土地を理想栽培地と仮定しています。トウキは群馬県利根沼田市、シャクヤクは奈良県下市町を理想栽培地とし、これらの土地と似た条件の栽培地を探すことにします。
残念ながら、これらの市町村のなかのどこにトウキとシャクヤクの農地があるかは明らかになっていません。
また、これらのターゲット地域の地質構造は比較的複雑な構造をしています。誤った地質構造データを利用して栽培地探索をしてしまうと、誤った土地を適地と予測してしまう可能性があります。そのため、正確な農地の場所が分からない状態において、今回の記事では地質データを利用せず、気象データから栽培適地を探すこととします(つまり、同じ市町村内であれば気象データはおおきく変わらないだろうという仮定をしています)。

気象データは地域気象観測システム(アメダス)の1分値APIを利用しました。本記事ではTellusのJupyter Notebookを利用し、2016年の1年間の気象データを取得しました。取得方法についてはこちらの記事で詳しく解説されています。今回は気象データのうち、栽培可否に大きく影響すると考えられる降水量、日照時間、気温を利用しました。気象データは1分値を利用することが可能ですが、1年間という長さに対して1分値を取得すると非常に莫大な回数APIを取得する必要がでてきます。
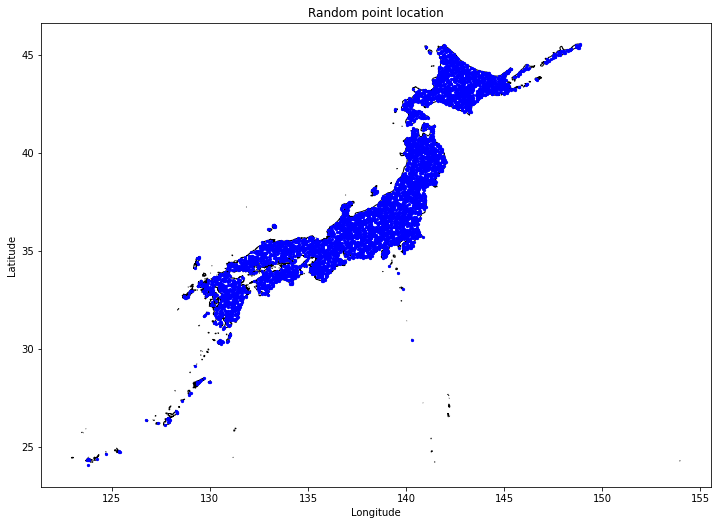
適地を探すために、まず日本全国にランダム点を配置します。今回の記事では日本全国に5742点のランダム点を配置しています。
このランダム点に対して、最寄りのアメダス観測所を探索し、アメダスの気象データをその地点に与えます。
次にターゲット農地の気象データと、ランダム点の気象データを比較し、RMS(Root Mean Square)が小さい点を適地として取得します。
解析結果の紹介
解析コードは次節以降に掲載し、ここでは解析結果を紹介します。まずはトウキについての結果です。
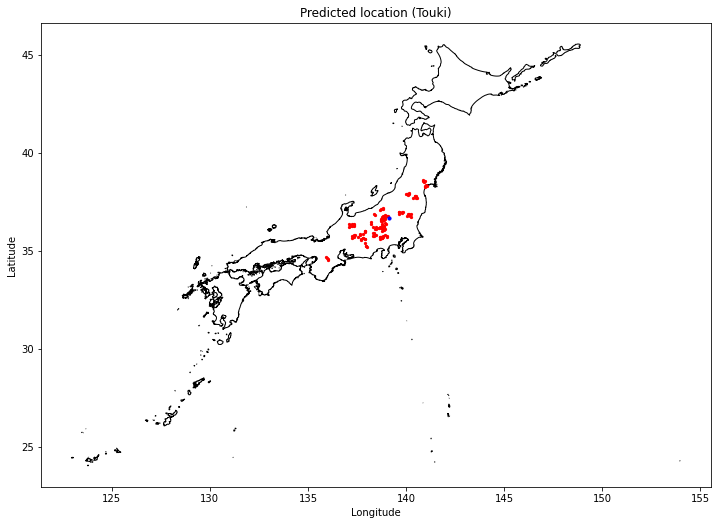
この図で青点がターゲットとした群馬県利根沼田市の農地の場所です。赤点がデータ分析により適地の可能性あり(沼田市と同様の気象条件の場所)と予測された地点になります。
この結果によると群馬県、長野県を中心とした内陸地域に多く予測されており、他にも栃木県、福島県、奈良県が適地と予測されています。
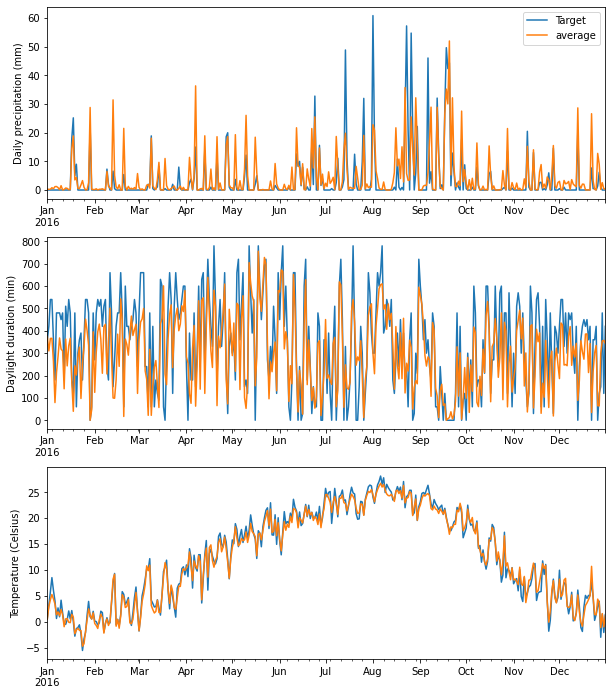
これらの赤い地点と、ターゲット農地の気象データを比較してみましょう。赤点は多数あるため、赤点の平均値と比較したものがこちらです。上から日降水量、日照時間、気温のグラフとなります。青線がターゲット農地のデータで、オレンジ線が赤点の平均値です。
これを見ると、適地と予測された点はターゲット農地の気象トレンドをうまく捉えることができていることがわかります。
次にシャクヤクについての結果です。青点はターゲットとした奈良県下市町の農地の場所です。
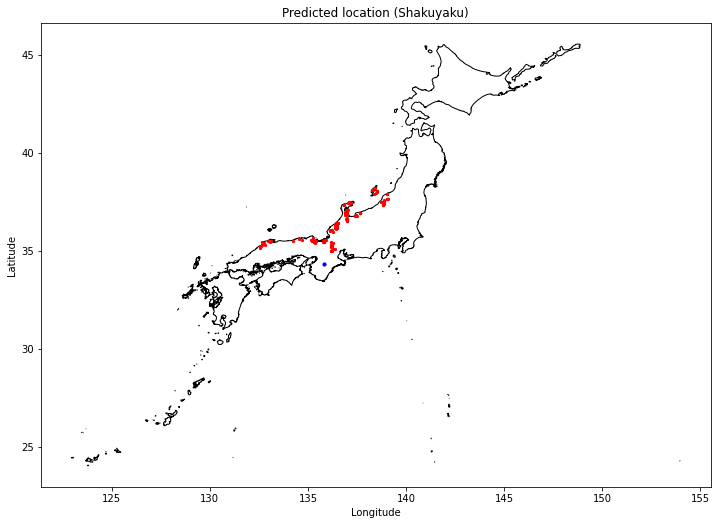
全体的に予測された適地は日本海側に集中していることがわかります。富山県などではシャクヤクの栽培が多く行われているということですが、今回の予測でも富山県などは適地として予測されています。
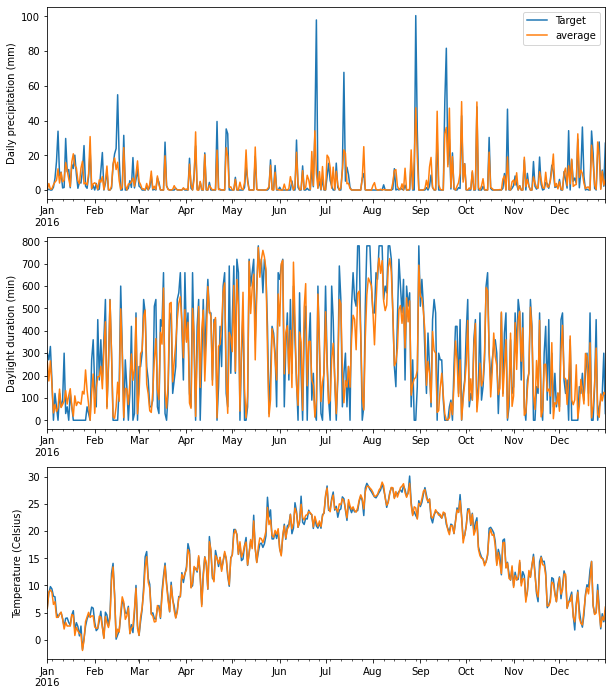
続いて気象データです。こちらも予測適地の気象データは、ターゲット農地をうまく捉えることができています。
利用するデータと解析の流れ
コードの実装
コードはアメダスの1分値APIを利用しているため、TellusのJupyter Notebookの利用を前提としています。
#必要ライブラリをインポート
import os
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import pandas as pd
import geopandas as gpd
import requests
import json
import csv
import math
import glob
import geopy.distance
from datetime import datetime, date, timedelta
import time
from shapely.geometry import Point, Polygon
from osgeo import gdal, gdalconst, gdal_array, osr
%matplotlib inline
TOKEN = 'YOUR TOKEN'
print("done")次に今回の気象データ解析で利用する日時のリストを作成します。2016年1月1日から12月31日まで1時間毎にデータを取得します。
sdate = ['2016', '01', '01', '00', '00']
edate = ['2016', '12', '31', '23', '59']
sdate = datetime(int(sdate[0]), int(sdate[1]), int(sdate[2]), int(sdate[3]), int(sdate[4]))
edate = datetime(int(edate[0]), int(edate[1]), int(edate[2]), int(edate[3]), int(edate[4]))
tdcount = math.ceil((edate-sdate)/timedelta(minutes=60))
print(tdcount)
# create datetime list
periods = [sdate + timedelta(minutes=60*x) for x in range(tdcount)]次に必要な関数を定義していきます。詳細はコードを見ていただくとして、定義している関数の一覧は下記のようになります。
・ポリゴン内のランダムな点を取得する(random_points_in_multipolygon)。
・引数のlon/latに対し、Dataframeのなかで最も距離が短い点との距離を返す(argmin_dist)
・ランダム点からのアメダスまでの最小距離点とその距離、一定の距離以下にあるかどうかをTrue/Falseで返す(search_rands_within_condition)
・引数のlon/latに対し、Dataframeのなかで最も距離が短い点との距離を返す(argmin_dist_obs)
・アメダスAPIを利用して1分値を取得(get_amedas_1min)
・アメダスデータ(JSON形式)をDataFrame形式に変換(amedas2df)
・引数の緯度経度から都道府県No.を取得(get_min_dist_prefobsno)
・RMSが最も小さいlon, latを一定数個取得(get_small_rms_sites)
・DataFrameの単位補正を行い、日毎に集計したDataFrameを返す(df_split)
def random_points_in_multipolygon(number, gdf_polys):
"""日本全国にランダムにサンプル点を取得"""
# find the bounds of your geodataframe
x_min, y_min, x_max, y_max = gdf_polys.bounds
# generate random data within the bounds
x = np.random.uniform(x_min, x_max, number)
y = np.random.uniform(y_min, y_max, number)
# convert them to a points GeoSeries
gdf_points = gpd.GeoSeries(gpd.points_from_xy(x, y))
# only keep those points within polygons
gdf_points = gdf_points[gdf_points.within(gdf_polys)==True]
return gdf_points
def argmin_dist(lon, lat, df):
"""引数のlon/latに対し、Dataframeのなかで最も距離が短い点との距離を返す"""
xy = ['lon', 'lat']
# random pointのlonlatをまとめる
lonlat = np.array([lon, lat], dtype=float)
# それぞれのdfに対して距離を計算する
distance_array = np.sum((lonlat - df[xy].values)**2, axis=1)
# もっとも距離が短い点に対して、lon/latを保存
target_lon = df.lon.iloc[distance_array.argmin()]
target_lat = df.lat.iloc[distance_array.argmin()]
# longitude has to be between -90 to 90
# 距離を返す
return geopy.distance.vincenty((lon-180, lat), (target_lon-180, target_lat)).km
def search_rands_within_condition(df_rands, df_region, label, distance):
"""ランダム点からの最小距離点までの距離と、一定の距離以下にあるかどうかをTrue/Falseで返す"""
# DataFrameのcolumnの初期化
df_rands[[label, label+'_dist']] = np.nan
# それぞれのrawに対して、最短点までの距離を計算する
for i in range(len(df_rands)):
df_rands.loc[i, label+'_dist'] = argmin_dist(lon=df_rands.loc[i, 'lon'], lat=df_rands.loc[i, 'lat'], df=df_region)
# 最短点の距離が一定値以下ならTrue、そうでないならFalseを返す
df_rands[label][df_rands[label+'_dist']=distance] = False
return df_rands
def argmin_dist_obs(lon, lat, df):
"""引数のlon/latに対し、Dataframeのなかで最も距離が短い点との距離を返す"""
xy = ['lon', 'lat']
# random pointのlonlatをまとめる
lonlat = np.array([lon, lat], dtype=float)
# それぞれのdfに対して距離を計算する
distance_array = np.sum((lonlat - df[xy].values)**2, axis=1)
# もっとも距離が短い点に対して、lon/latを保存
target_lon = df.lon.iloc[distance_array.argmin()]
target_lat = df.lat.iloc[distance_array.argmin()]
# 観測所番号と距離を返す
return pd.Series([int(distance_array.argmin()), geopy.distance.geodesic((lat, lon), (target_lat, target_lon)).km])
def get_amedas_1min(year, month, day, hour, minute, payload={}):
"""
/api/v1/amedas/1minを実行
Parameters
----------
year : string
西暦年 (4桁の数字で指定) UTC
month : string
月 01~12 (2桁の数字で指定) UTC
day : string
日 01~31 (2桁の数字で指定) UTC
hour : string
時 00~23 (2桁の数字で指定) UTC
minute : string
分 00~59 (2桁の数字で指定) UTC
payload : dict
パラメータ(min_lat,min_lon,max_lat,max_lon)
Returns
-------
content : list
結果
"""
url = 'https://gisapi.tellusxdp.com/api/v1/amedas/1min/{}/{}/{}/{}/{}/'.format(year, month, day, hour, minute)
headers = {
'Authorization': 'Bearer ' + TOKEN
}
r = requests.get(url, headers=headers, params=payload)
if r.status_code is not 200:
print(r.content)
raise ValueError('status error({}).'.format(r.status_code))
return json.loads(r.content)
def amedas2df(amedas):
"""アメダスデータ(JSON形式)をDataFrame形式に変換"""
cols = ['lat', 'lon', 'prefobs_no', 'elev', 'rain_intensity', 'rain_flag', 'sunshine_duration', 'sunshine_flag', 'temperature_deg', 'temperature_flag']
df = pd.DataFrame(index=[], columns=cols)
for i in range(len(amedas)):
lat = amedas[i]['coordinates'][1]
lon = amedas[i]['coordinates'][0]
rain_intensity = amedas[i]['rain']['intensity']['value']
rain_flag = int(amedas[i]['rain']['intensity_flag']['value'])
sunshine_duration = amedas[i]['sunshine']['duration']['value']
sunshine_flag = int(amedas[i]['sunshine']['duration_flag']['value'])
temp_deg = amedas[i]['temperature']['deg']['value']
temp_flag = int(amedas[i]['temperature']['deg_flag']['value'])
pref_no = amedas[i]['station']['prefecture_no']['value']
obs_no = amedas[i]['station']['observatory_no']['value']
elev = amedas[i]['station']['elevation']['value']
record = pd.Series([lat, lon, str(pref_no)+str(obs_no), elev, rain_intensity, rain_flag, sunshine_duration, sunshine_flag, temp_deg, temp_flag], index=df.columns)
df = df.append(record, ignore_index=True)
return df
def get_min_dist_prefobsno(row):
"""引数の緯度経度から都道府県No.を取得"""
lon, lat = row['lon'], row['lat']
df['dist'] = (df.lon-lon)**2 + (df.lat-lat)**2
temp = df.iloc[df.dist.idxmin()]
return int(temp['prefobs_no'])
def get_small_rms_sites(amedas_all, amedas, df_target):
"""RMSが最も小さいlon, latを一定数個取得"""
amedas_all['rms'] = 0
index = amedas_all.index
for i in range(len(amedas_all)):
tmp = amedas_all.iloc[i] - df_target.iloc[0]
rms = np.sqrt((tmp**2).sum())
amedas_all.loc[index[i], 'rms'] = rms
# rmsが最も小さいindexをnsmalls個サーチ
nsmalls = 30
min_idxs = amedas_all['rms'].nsmallest(nsmalls).index
df_nsmalls = pd.DataFrame(index=min_idxs, columns=['lon', 'lat', 'rms'])
# nsmalls個のindexのlon/latを取得
for idx in df_nsmalls.index:
df_nsmalls.loc[idx, 'lon'] = amedas[['lon']][amedas['prefobs_no']==idx].values[0, 0]
df_nsmalls.loc[idx, 'lat'] = amedas[['lat']][amedas['prefobs_no']==idx].values[0, 0]
df_nsmalls.loc[idx, 'rms'] = amedas_all.loc[idx, 'rms']
return df_nsmalls
def df_split(df_all):
"""DataFrameの単位補正を行い、日毎に集計したDataFrameを返す"""
try:
# separate df_all to each params
rain_df = df_all.drop("rms", axis=1).iloc[:, 0::3]
sun_df = df_all.drop("rms", axis=1).iloc[:, 1::3]
temp_df = df_all.drop("rms", axis=1).iloc[:, 2::3]
except:
# separate df_all to each params
rain_df = df_all.iloc[:, 0::3]
sun_df = df_all.iloc[:, 1::3]
temp_df = df_all.iloc[:, 2::3]
# indexをdatetimeに変換
index_datetime = pd.to_datetime(pd.Series(rain_df.iloc[0].index), format="rain%Y%m%d%H%M")
# データ保存用のdfを作成
df_params = pd.DataFrame(index=index_datetime, columns=['rain', 'sunshine', 'temperature'])
# combine into one df
df_params['rain'] = rain_df.iloc[0].values
df_params['sunshine'] = sun_df.iloc[0].values
df_params['temperature'] = temp_df.iloc[0].values
# 単位の補正
# https://www.data.jma.go.jp/add/suishin/jyouhou/pdf/305.pdf
df_params['rain'] = df_params['rain']/10 # (mm)
df_params['sunshine'] = df_params['sunshine'] # (min)
df_params['temperature'] = df_params['temperature']/10 # (celsius)
# 日ごとに集計
df_params_daily = df_params.resample("D").agg(['sum', 'mean'])
return df_params_daily次に日本の形状をshapefileから読み込みます。
# 日本全体のshapefileデータを読み込み
# 下記URLよりjpn_adm_2019_SHP.zipをダウンロードしました。
# https://data.humdata.org/dataset/japan-administrative-level-0-2-boundaries?
pref_file = '/home/ubuntu/jupyter/data/japan_pref/jpn_admbnda_adm0_2019.shp'
df_ja_shp = gpd.read_file(pref_file, encoding="UTF-8")
df_ja_shp.head()このshapefileから日本全体にランダム点を振り分けます。本記事では範囲内に100,000点のランダム点を振り分け、そのうち日本のshapefileに含まれているものを抽出しています。100,000点の場合非常に時間がかかるため、テスト実行される場合はランダム点の点数を大きく減らしてみても良いでしょう。
# ランダム点を何点プロットするかを選択。100000点だと実行に数時間かかるので注意
points = random_points_in_multipolygon(100000, df_ja_shp.iloc[0].geometry)
df_rands = gpd.GeoDataFrame({'geometry':points}).reset_index(drop=True)
# lon, latを別カラムで保存
df_rands['lon'] = df_rands.geometry.x
df_rands['lat'] = df_rands.geometry.y
print(len(df_rands))
df_rands.head()ここで一旦、ランダム点をプロットしてみましょう。
# 日本地図とランダム点の位置をプロット
fig, ax = plt.subplots(figsize=(12,12))
df_ja_shp.plot(ax=ax, facecolor='w', edgecolor='k',alpha=1)
# df_rands.plot(ax=ax, color='red', markersize=5)
gpd.GeoDataFrame(df_rands[['geometry']]).plot(ax=ax, color='blue', markersize=5)
ax.set_xlabel('Longitude', fontsize=10)
ax.set_ylabel('Latitude', fontsize='medium')
ax.set_title('Random point location')
df_rands.to_csv('./rands_location.csv')次に、トウキとシャクヤクのターゲット農地を指定します。ターゲット地点をコード内に緯度経度で記載しています。
# ターゲット農地の読み込み(トウキ・群馬県利根沼田地域)
# 細かい地域が絞れないので、地質データは今回利用しない
#(地質データはたかだか100mでおおきく変わる可能性があるため)
# 群馬県利根沼田地域の農地をサンプルにした。今回は北部の農地を選んだが、特に根拠はない
touki_lon = 139.110763
touki_lat = 36.684541
touki_loc = pd.DataFrame({'target':['touki'],
"Latitude": [touki_lat],
"Longitude": [touki_lon]})
gdf_touki = gpd.GeoDataFrame(
touki_loc, geometry=gpd.points_from_xy(touki_loc.Longitude, touki_loc.Latitude))
# ターゲット農地の読み込み(シャクヤク・奈良県下市町)
# 今回は南部の農地を選んだが、特に根拠はない
syaku_lon = 135.812809
syaku_lat = 34.353150
syaku_loc = pd.DataFrame({'target':['syaku'],
"Latitude": [syaku_lat],
"Longitude": [syaku_lon]})
gdf_syaku = gpd.GeoDataFrame(
syaku_loc, geometry=gpd.points_from_xy(syaku_loc.Longitude, syaku_loc.Latitude))アメダスデータを取得する前準備として、カラム名とDataFrameを作成しておきましょう。
# 時刻ごとにrain, sunshine, tempの名前を作成
cols = []
for i in range(len(periods)):
cols_default = ['rain', 'sunshine', 'temp']
period = periods[i]
dt = str(period.year).zfill(4) + str(period.month).zfill(2) + str(period.day).zfill(2) + str(period.hour).zfill(2) + str(period.minute).zfill(2)
col = [s + dt for s in cols_default]
cols.extend(col)
# colsを利用してDataFrameの初期値を作成
amedas_df_all = pd.DataFrame(index=[], columns=cols)
amedas_df_all.head()
df_touki_all = pd.DataFrame(index=[0], columns=cols)
df_syaku_all = pd.DataFrame(index=[0], columns=cols)ここでアメダスデータを取得します。今回の取得期間の長さの場合、データ取得だけで数日かかります。必要に応じて取得期間の長さを変更しましょう。ここでダウンロードしたアメダスデータは後ほどcsvファイルとして保存するため、一旦データをダウンロードすれば次回以降の解析の際は再ダウンロードは必要ありません。
for i in range(len(periods)):
if i%10==0:
print(i)
# アメダスデータの取得
period = periods[i]
year = period.year
month = period.month
day = period.day
hour = period.hour
minute = period.minute
amedas1 = get_amedas_1min(year, month, day, hour, minute)
# アメダスデータをDataFrameに変換
df = amedas2df(amedas1)
# 対象年月日のheaderの取得
cols_default = ['rain', 'sunshine', 'temp']
dt = str(year).zfill(4) + str(month).zfill(2) + str(day).zfill(2) + str(hour).zfill(2) + str(minute).zfill(2)
# headerの定義
col = [s + dt for s in cols_default]
# トウキ/シャクヤクの最寄りのアメダスindex取得
touki_index, dist = argmin_dist_obs(touki_lon, touki_lat, df)
syaku_index, dist = argmin_dist_obs(syaku_lon, touki_lat, df)
# アメダスindexからトウキ/シャクヤクの点のデータを取得
touki_data = df.iloc[int(touki_index)]
syaku_data = df.iloc[int(syaku_index)]
# df_touki_all, df_syaku_allに全データを保存
df_touki_all.at[0, col] = touki_data[['rain_intensity', 'sunshine_duration', 'temperature_deg']].values
df_syaku_all.at[0, col] = syaku_data[['rain_intensity', 'sunshine_duration', 'temperature_deg']].values
# amedas_df_allに全アメダスデータを保存
for j in range(len(df)):
if not int(df.iloc[j]['prefobs_no']) in df_all.index:
series_obj = pd.Series([np.nan, np.nan, np.nan], index=col, name=int(df.iloc[j]['prefobs_no']))
amedas_df_all = df_all.append(series_obj)
amedas_df_all.at[int(df.iloc[j]['prefobs_no']), col] = df[['rain_intensity', 'sunshine_duration', 'temperature_deg']].iloc[j].values
df.head()上記でダウンロードしたデータのうち、2147483647という値はNaNに置き換えます。
# nan値の置き換え
amedas_df_all = amedas_df_all.replace(2147483647, np.nan)
df_touki_all = df_touki_all.replace(2147483647, np.nan)
df_syaku_all = df_syaku_all.replace(2147483647, np.nan)
# nan値を含むデータを削除
amedas_df_all = amedas_df_all.dropna()データを保存します。
df.to_csv('./df.csv')
amedas_df_all.to_csv('./amedas_df_all.csv')
df_touki_all.to_csv('./df_touki.csv')
df_syaku_all.to_csv('./df_syaku.csv')一旦、データを保存すると次のコマンドでDataFrameを読み込み可能です。この場合、データを再ダウンロードする必要はありません。
df = pd.read_csv('./df.csv', index_col=0)
amedas_df_all = pd.read_csv('./amedas_df_all.csv', index_col=0)
df_touki_all = pd.read_csv('./df_touki.csv', index_col=0)
df_syaku_all = pd.read_csv('./df_syaku.csv', index_col=0)次に、ダウンロードしたアメダスデータとランダム点の紐付けを行います。
# ランダム点の最寄りのアメダスデータ番号を紐付け
df_rands['prefobs_no'] = df_rands.apply(get_min_dist_prefobsno, axis=1)
df_rands.head()ターゲット農地とアメダスデータを比較し、RMSの計算を行います。また、RMSが小さいものを取得します。
df_nsmalls_touki = get_small_rms_sites(amedas_df_all, df, df_touki_all)
df_nsmalls_syaku = get_small_rms_sites(amedas_df_all, df, df_syaku_all)
df_rands_touki_selected = df_rands[df_rands['prefobs_no'].isin(df_nsmalls_touki.index.tolist())]
df_rands_syaku_selected = df_rands[df_rands['prefobs_no'].isin(df_nsmalls_syaku.index.tolist())]上記の結果、RMSが小さいと判断されたランダム点を表示します。まずトウキの結果です。
# 日本地図とランダム点の位置をプロット
fig, ax = plt.subplots(figsize=(12,12))
df_ja_shp.plot(ax=ax, facecolor='w', edgecolor='k',alpha=1)
gpd.GeoDataFrame(df_rands_touki_selected[['geometry']]).plot(ax=ax, color='red', markersize=5)
gpd.GeoDataFrame(gdf_touki[['geometry']]).plot(ax=ax, color='blue', markersize=10)
ax.set_xlabel('Longitude', fontsize=10)
ax.set_ylabel('Latitude', fontsize='medium')
ax.set_title('Predicted location (Touki)')次に、シャクヤクの結果です。
# 日本地図とランダム点の位置をプロット
fig, ax = plt.subplots(figsize=(12,12))
df_ja_shp.plot(ax=ax, facecolor='w', edgecolor='k',alpha=1)
gpd.GeoDataFrame(df_rands_syaku_selected[['geometry']]).plot(ax=ax, color='red', markersize=5)
gpd.GeoDataFrame(gdf_syaku[['geometry']]).plot(ax=ax, color='blue', markersize=10)
ax.set_xlabel('Longitude', fontsize=10)
ax.set_ylabel('Latitude', fontsize='medium')
ax.set_title('Predicted location (Shakuyaku)')次に、気象データをプロットするために、1時間ごとに取得したデータをDailyデータに落とし込みます。
# daily データに落とし込み
df_touki_params_daily = df_split(df_touki_all)
df_syaku_params_daily = df_split(df_syaku_all)赤点(RMSが小さい点)の気象データの平均値を計算します。
def get_average_df(df_params_daily, df_nsmalls, amedas_df_all):
df_sum = df_params_daily.copy()
for col in df_sum.columns:
df_sum[col].values[:] = 0
for i in range(len(df_nsmalls)):
idx = df_nsmalls.index[i]
df_tmp = df_split(amedas_df_all[amedas_df_all.index==idx])
df_sum += df_tmp
df_sum = df_sum/len(df_nsmalls)
return df_sum
df_average_touki = get_average_df(df_touki_params_daily, df_nsmalls_touki, amedas_df_all)
df_average_syaku = get_average_df(df_syaku_params_daily, df_nsmalls_syaku, amedas_df_all)気象データをプロットします。まずトウキについてです。
fig = plt.figure(figsize=(10, 12))
plt.subplot(3,1,1)
df_touki_params_daily['rain']['sum'].plot(label='Target')
df_average_touki['rain']['sum'].plot(label='average')
plt.legend()
plt.ylabel("Daily precipitation (mm)")
plt.subplot(3,1,2)
df_touki_params_daily['sunshine']['sum'].plot()
df_average_touki['sunshine']['sum'].plot()
plt.ylabel("Daylight duration (min)")
plt.subplot(3,1,3)
df_touki_params_daily['temperature']['mean'].plot()
df_average_touki['temperature']['mean'].plot()
plt.ylabel("Temperature (Celsius)")次に、シャクヤクについてです。
fig = plt.figure(figsize=(10, 12))
plt.subplot(3,1,1)
df_syaku_params_daily['rain']['sum'].plot(label='Target')
df_average_syaku['rain']['sum'].plot(label='average')
plt.legend()
plt.ylabel("Daily precipitation (mm)")
plt.subplot(3,1,2)
df_syaku_params_daily['sunshine']['sum'].plot()
df_average_syaku['sunshine']['sum'].plot()
plt.ylabel("Daylight duration (min)")
plt.subplot(3,1,3)
df_syaku_params_daily['temperature']['mean'].plot()
df_average_syaku['temperature']['mean'].plot()
plt.ylabel("Temperature (Celsius)")考察
予測された候補地と実際の産地の関係
今回は群馬県(トウキ)と奈良県(シャクヤク)の気候に似た土地をアメダスデータを利用して探索しました。では、予測した候補地と実際にトウキとシャクヤクが栽培されている産地を比較してみましょう。ただし、農地の細かい場所まではわからないため、産地は市町村の粒度での情報となります。
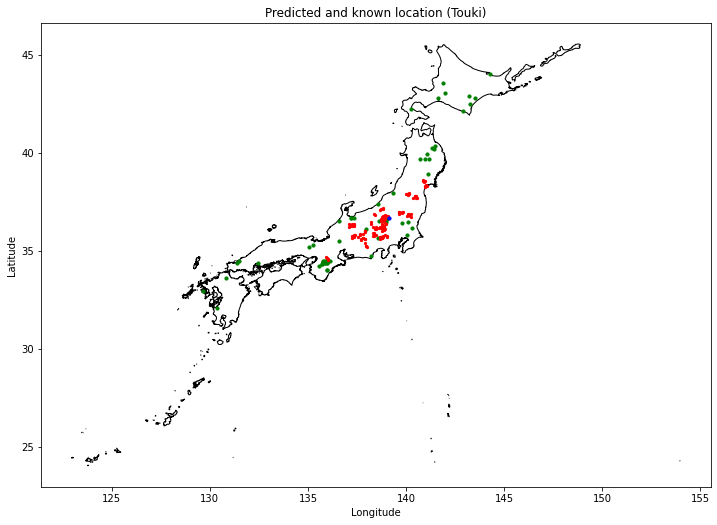
こちらはトウキの結果です。赤点が予測した候補地、緑点が実際にトウキが栽培されている産地、青点は今回ターゲット農地として利用した農地です。
こちらはシャクヤクの結果です。
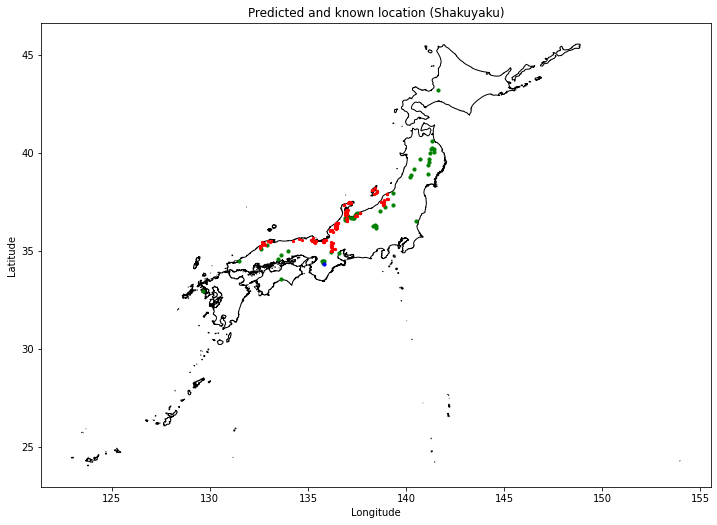
これらの結果を見ると、候補地のうち一部は実際に産地として有名なところと一致していました。特にトウキは中日本地域、シャクヤクは北陸地域を中心に実際の産地とよく一致していることがわかりました。これらの情報はデータに含めていないため、うまく予測ができているということが明らかになりました。
予測モデルを向上させるためには
一方で、中編記事でも議論されているように、北海道や東北などの産地が候補地に含められていません。今回、トウキやシャクヤクを育てるのに適切な気候条件を探しているのではなく、ターゲット農地と同じ気候条件を探していることが原因だと考えられます。北海道や東北の地域を予測として得られるようにするためには、今回のように単一のターゲット農地だけでなく、複数の農地情報を利用することが重要だと考えられます。また、「(2本目タイトル)」であったように、土壌情報、農家戸数情報などを含めることも重要になるでしょう。
今回はトウキとシャクヤクの名産地から近傍の農地をランダムに選び、ターゲット農地としています。土地情報を含めるためには、理想的なトウキとシャクヤクの緯度経度情報が必要となります。残念ながら今回はこのような情報を得ることができなかったのですが、もしも協力いただける農家の方がいればこういったことも可能になるかもしれません。
まとめ
今回の記事では、アメダスデータを利用してトウキとシャクヤクの産地情報から、ターゲット農地と似た気象条件を持つ候補地を探してみました。予測した候補地を検証したところ、実際の産地の一部と良く似た場所を示していました。そのため、今回の予測モデルはある程度うまく動作していることがわかりました。
ただし、現在のモデルには限界もあり、北海道や東北の一部はまだうまく予測できていません。今後、実際にトウキやシャクヤクを育成している農地情報が集まれば、もっと予測精度の高いモデルが作成できるようになるでしょう。
この記事がアメダスデータを利用した予測モデル構築の参考になりましたら幸いです。
