【ゼロからのTellusの使い方】Jupyter Labで地域経済分析システム(RESAS)の統計データを取得する
地域経済分析システム(RESAS)とは、経済産業省と内閣官房が提供する、官民ビッグデータを集約し可視化するシステムです。今回はそんなRESASの統計データをTellus上で取得する方法をご紹介します。
記事作成時から、Tellusからデータを検索・取得するAPIが変更になっております。該当箇所のコードについては、以下のリンクをご参照ください。
https://www.tellusxdp.com/ja/howtouse/access/traveler_api_20220310_
firstpart.html
2022年8月31日以降、Tellus OSでのデータの閲覧方法など使い方が一部変更になっております。新しいTellus OSの基本操作は以下のリンクをご参照ください。
https://www.tellusxdp.com/ja/howtouse/tellus_os/start_tellus_os.html
本記事ではTellusのJupyter Labを使って地域経済分析システム(RESAS)の統計データを取得する方法を紹介します。
TellusでJupyter Lab(Jupyter Notebook)を使う方法は、「Tellusの開発環境でAPI引っ張ってみた」をご覧ください。
また、すでに開発環境の払い出しをJupyter Notebookで受けている方がTellus内でRESASのデータを利用するにはJupyter Labへのアップデートが必要となります。
アップデートは順次行っていく予定ですが、お急ぎの方はお問い合わせください。
※現在、本記事に記載の手法でRESASのAPIを利用することができなくなっております。ご利用の際はご注意ください。
1. 地域経済分析システム(RESAS)の統計データを取得するには
地域経済分析システム(RESAS)とは、経済産業省と内閣官房(まち・ひと・しごと創生本部事務局)が提供する、官民ビッグデータを集約し可視化するシステムです。
TellusではRESASが整備する統計データをデータベースとして保持しており、開発環境からアクセスすることができます。
データリファレンス
※2019年7月12日時点では農業系データのみ。他のデータも順次追加していく予定です。
それでは実際に、Tellus IDE(開発環境)からSQLクエリを用いてデータを取得してみましょう。
TellusのJupyter Labを開き、「work」ディレクトリに移動してから「Python3」を選択し、以下のコードを貼り付けます。
import psycopg2
def connect():
return psycopg2.connect('postgresql://jovyan:password@postgres:5432/resas')
with connect() as conn:
with conn.cursor() as cur:
cur.execute('SELECT year, worker_total_15_24, worker_total_25_34, worker_total_35_44, worker_total_45_54, worker_total_55_64, worker_total_65_74, worker_total_over_74 FROM agriculture_related_country')
print('年齢別従事者数')
print('集計年 | 15~24歳 | 25~34歳 | 35~44歳 | 45~54歳 | 55~64歳 | 65~74歳 | 74歳以上')
for row in cur:
print(row)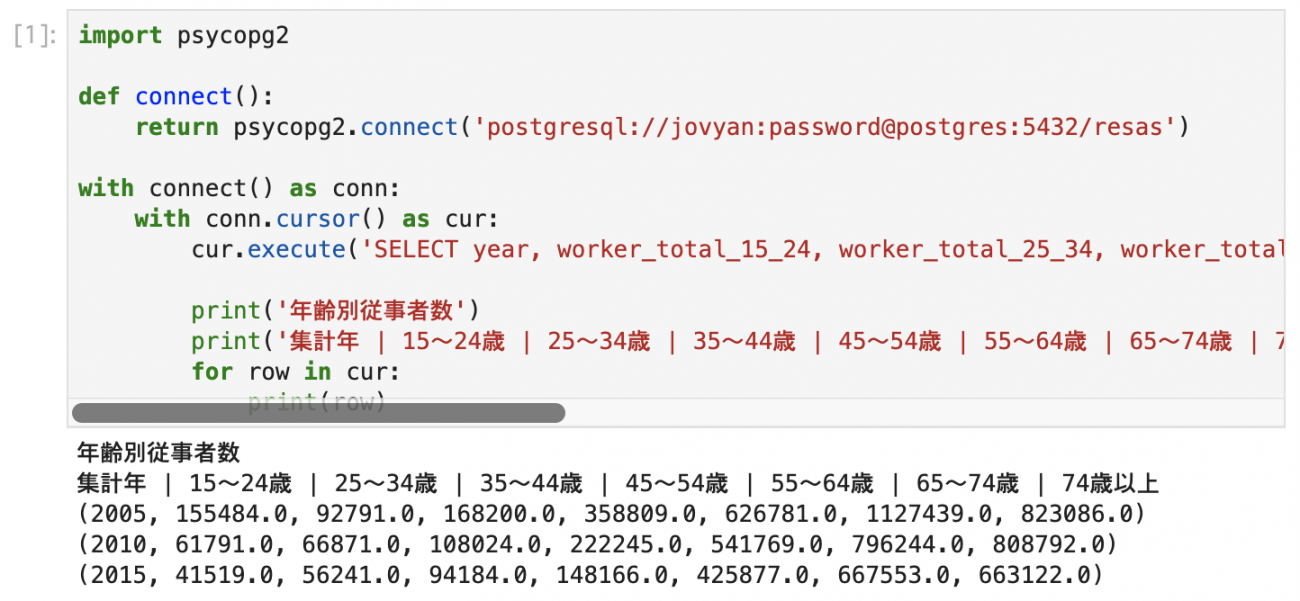
データベースに接続するのに必要な情報は、データリファレンスの「データベース接続情報」を参照してください。
サンプルでは、agriculture_related_country(全国農業関連事業)テーブルから、年齢別従事者数_男女計を取得しています。
全国農業関連事業のデータは5年毎に調査・集計されており、RESASでは2005年からのデータを参照することができます。
参考:農林業センサス
クエリの書き方次第で、条件を絞った検索も可能です。
with connect() as conn:
with conn.cursor() as cur:
cur.execute('SELECT year,city_name,agriculture_land_total,agriculture_land_ricefield,agriculture_land_field,agriculture_land_treefield FROM agriculture_land_city WHERE city_code=02201')
print('集計年 | 市町村名 | 耕作面積合計 | 田 | 畑 | 樹園地')
for row in cur:
print(row)
print('単位はアール')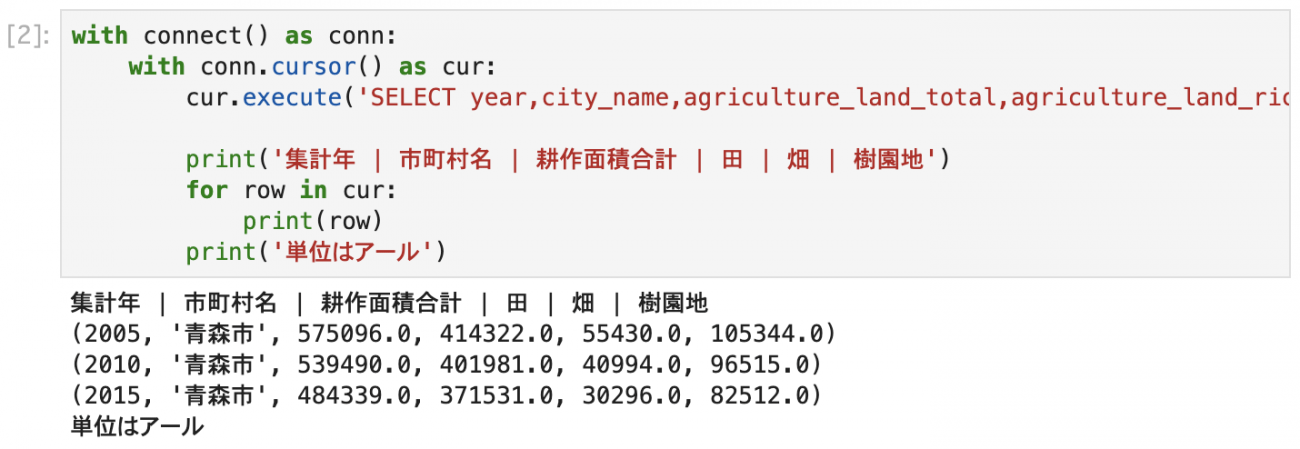
サンプルでは、agriculture_land_city(市町村別耕作地)テーブルから、経営耕作面積(総面積、田、畑、樹園地)を青森市の市町村コードで絞り込んで取得しています。
クエリは慣れてない人には書くのが難しいかもしれませんが、データベースを扱う上で必要なスキルなので少しずつでも覚えていきましょう。
2. RESASのデータからグラフを作る
さきほど確認した年齢別従事者数を棒グラフにまとめてみましょう。
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
with connect() as conn:
with conn.cursor() as cur:
cur.execute('SELECT year, worker_total_15_24, worker_total_25_34, worker_total_35_44, worker_total_45_54, worker_total_55_64, worker_total_65_74, worker_total_over_74 FROM agriculture_related_country')
years = []
data = []
for row in cur:
years.append(row[0])
data.append(row[1:])
data = np.array(data)
bar_width = 0.3
bar_gutter = 0.1
set_width = bar_width * data.shape[0] + bar_gutter
x_points = np.arange(data.shape[1]) * set_width
xlabels = ['15-24', '25-34', '35-44', '45-54', '55-64', '65-74', 'over74']
xlocations = x_points + bar_width*(-1 + data.shape[0]) / 2
fig, ax= plt.subplots(figsize=(8, 4))
for i in range(len(data)):
plt.bar(x_points + bar_width*i, data[i], bar_width,label=years[i], align='center')
plt.xticks(xlocations, xlabels )
plt.xlim(-3*bar_gutter, x_points[-1] + set_width - bar_gutter)
ax.yaxis.set_major_formatter(plt.FuncFormatter(lambda y, pos: "{:,}".format(int(y))))
ax.set_xlabel('age')
ax.set_ylabel('num')
plt.legend()
plt.show()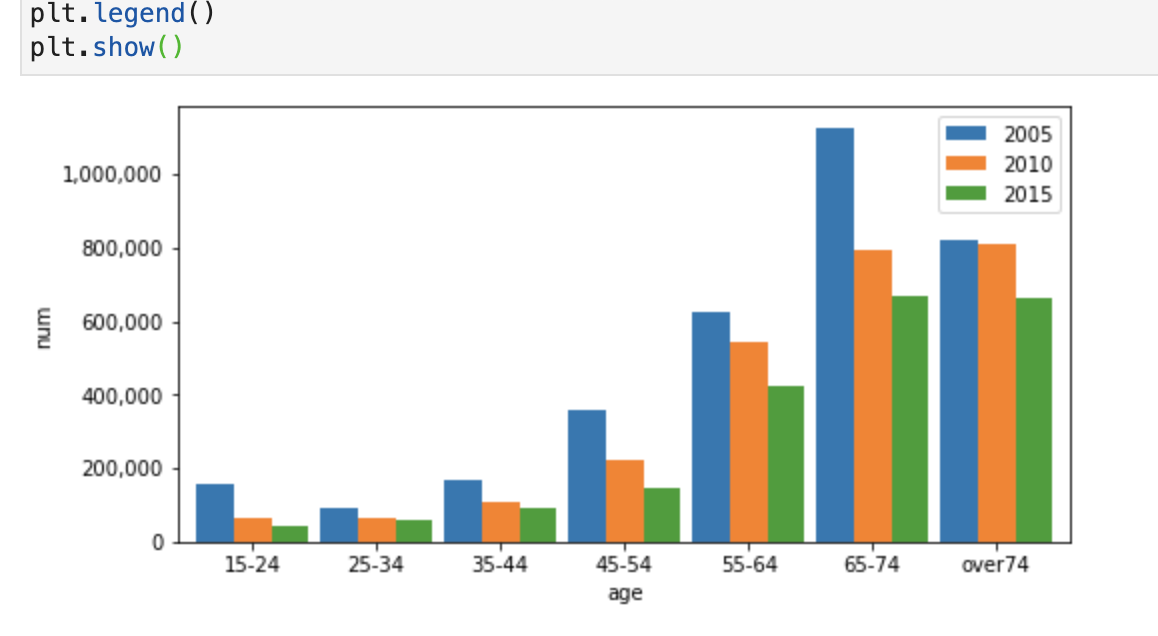
2005年をピークとして、65-74の世代では100万人を超えているのがわかります。しかしその5年後、10年後を表すグラフから、農業従事者が徐々に減ってきており、日本の高齢化が進んでいることがわかるグラフとなっています。
次に、青森の2016年の農業販売額を、市町村別にグラフ化してみます。
青森の市町村別農業販売額(2016年)は以下のクエリで取得可能です。
with connect() as conn:
with conn.cursor() as cur:
cur.execute('SELECT city_code,agri_output_total FROM agriculture_sale_city WHERE prefecture_code=2 AND year=2016')
agri_output_total = {}
for row in cur:
agri_output_total[str(row[0]).zfill(5)] = row[1]
print(agri_output_total)
サンプルコードでは、取得した値を市区町村コードをキーとする辞書オブジェクトにまとめなおしています。
グラフは市区町村のポリゴンの色で値を表現します。
市区町村の形状はgeojsonとして「国土数値情報 ダウンロードサービス」から入手できます。
※詳しいダウンロード方法はこちらの記事をご覧ください。
ダウンロードした青森県の行政区域データをJupyter Lab上にアップロードします。
ファイルは「work」ディレクトリの配下であればどこにアップロードしてもいいのですが、筆者の場合は「data」ディレクトリを作成し、そこにファイルをドラッグ・アンド・ドロップしました。
そして、アップロードしたファイルをgeopandasを使って呼び出します。
geopandasはpandasを地理情報を扱いやすいよう拡張したライブラリです。
import os
import geopandas as gpd
DIR_PATH = os.path.expanduser("~/work/data/") #ファイルを置いた場所に各自修正する
df = gpd.read_file(DIR_PATH + "N03-19_02_190101.geojson") #保存したファイル名に各自修正する
df[:3]
この2つのデータからグラフを作りましょう。
data = []
for code in df['N03_007']:
data.append(agri_output_total[code])
df['v'] = data
fig, ax = plt.subplots(figsize = (12, 6))
df.plot(column="v", edgecolor='black', figsize=(12, 8), cmap='Wistia', legend=True, ax=ax)
ax.set_xlabel('longitude')
ax.set_ylabel('latitude')
ax.set_title('Aomori\'s total output amount of 2016', fontsize='small')
plt.show()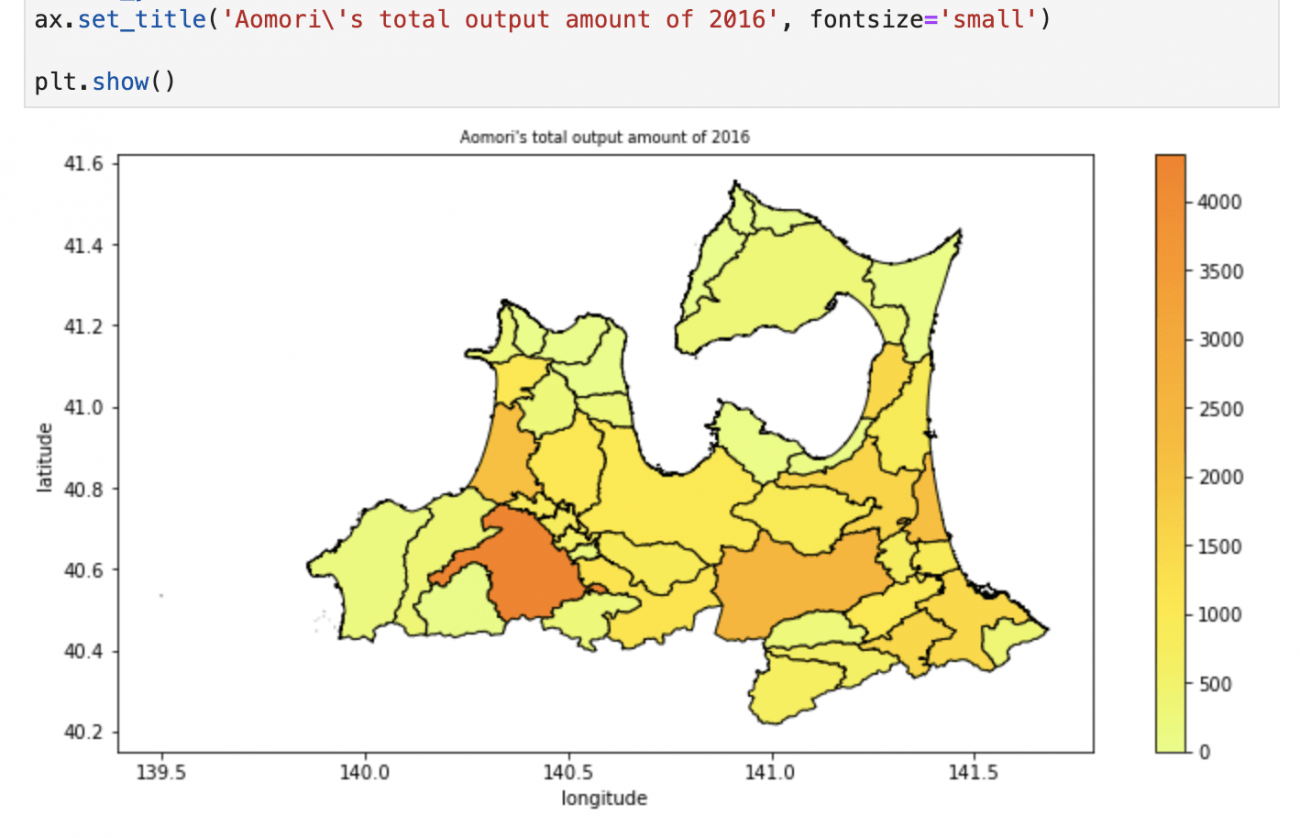
青森県の各市区町村が、農業販売額が大きいほどオレンジに、小さいほど黄色に塗られたグラフを作ることができました。
以上が、TellusのJupyter Labを使って地域経済分析システム(RESAS)の統計データを取得する方法でした。
RESASのデータは貴重なファクトデータ(事実)です。
それ単体で分析するもよし、他のデータの補正に利用したり組み合わせて統計処理するもよし。様々な分析シーンで活用してください。
