Python でトレーニングした衛星画像分類モデルを Elixir で並列分散推論する(Elixir 推論編)
並列分散処理を得意とするElixirで衛星データ分析を実施してみました!後編です。
はじめに
本記事は、「Python でトレーニングした衛星画像分類モデルを Elixir で並列分散推論する(Python トレーニング編)」の後編です。
前編でも紹介した通り、Elixirは並列分散処理が得意な開発言語です。機械学習モデルを Elixir によって並列分散実行することにより、大量の衛星データを高速に処理することが可能になります。
この記事では、Pythonトレーニング編でトレーニングした機械学習モデルを使用し、 Tellus から取得した衛星画像に対して Elixir Livebook から画像分類を実行します。
Livebook とは
Livebook はブラウザ上で Elixir のコードを実行し、結果を視覚化するツールです。
Python における Jupyter のようなものなので、 Google Colaboratory と同じ感覚で操作できます。
参考サイト:
Livebook.dev
https://livebook.dev/
分散処理のイメージ
Livebook ではノートブック(実行コードを記載したもの)が一つのプロセスとして動作します。
このノートブック同士を接続し、複数のノートブックで処理することで分散処理を実現します。
今回の処理では同じスペックのローカルマシンAとローカルマシンBを用意します。
それぞれのマシン上でサーバー側ノートブックAとサーバー側ノートブックBを実行して画像を待ち受けます。
片方のマシン上でクライアント側ノートブックを実行し、二つのサーバー側ノートブックに接続します。
クライアント側ノートブックから2つのサーバー側ノートブックに画像を送信し、サーバー側ノートブックで推論(画像分類)して結果を返します。
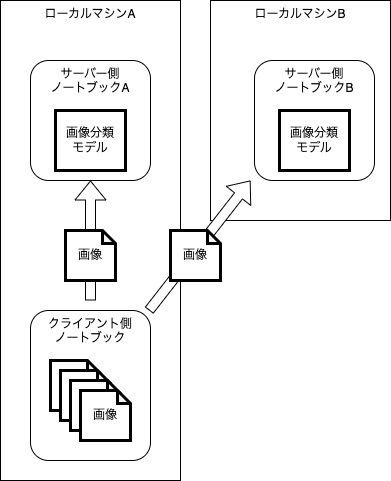
このように分散処理したとき、オーバーヘッド(分散処理することによって増える処理、通信など)にかかる時間が十分に小さければ、ローカルマシンの台数分処理が速く実行できることになります。
例えば 100 倍のスペックを持つスーパーコンピューターに対して、 100 台の低スペックマシンでほぼ同等の性能が発揮できる、ということです。
限られた資源で動く衛星間をネットワークで繋ぎ、互いに通信して分散処理すれば、大量データを高速に処理できるようになります。
また、地上と衛星間を繋いで分散処理する、という方法も考えられます。
衛星が大量に打ち上がり、通信速度がより向上した際には間違いなく有効な手段になるでしょう。
データの準備
モデルファイルとテスト用データ
Python トレーニング編で作成したモデルファイルとテスト用データを Google Drive からダウンロードします。
実行する各マシンの以下のパスにファイルを配置します。
– モデルファイル: `/tmp/sorabatake/efficientnet_v2_m.onnx`
– テスト用データ: `/tmp/sorabatake/dataset/test`
Tellus の準備
衛星データを取得するため、 Tellus の準備をします。
Tellus は無料で使い始めることができますが、アカウント登録が必要です。
まず、以下のドキュメントを参考に Tellus アカウントを作成しましょう。
アカウントを作成したら、 Tellus の API を呼び出すためのトークンを発行します。
実行環境
2 台の MAcBook Pro を使用します。
– MacBook Pro 13 inch, 2019
– CPU 2.4 GHz クアッドコアIntel Core i5
– メモリ 16 GB
– Elixir 1.15.4
– Erlang 26.0.2
– Livebook 0.10.0
– ローカルネットワークのルーター: docomo Wi-Fi STATION HW-01L
2019 年モデルの Intel CPU なので、あまり性能は高いと言えません。
実際 M2 Mac で実行するともっと速いのですが、分散処理できるほど手元に M2 Mac がないので、、、
また、 NVIDIA の GPU も使わないので、 Google Colaboratory 上で GPU を使った場合と比較すると遅いです。
今回の主眼はあくまでも Elixir による分散処理の実装と効果なので、 GPU を使った高速分散処理については別の機会に実施します(おそらく、その場合は Livebook でやるのは難しい)。
また、2台のマシンは手元にあるポケット WiFi 経由で通信します。
同じローカルネットワーク 192.168.8.0/24 に入っています。
実行環境の構築方法
Elixir の環境構築については以下の記事を参照してください。
Livebook のはじめ方 -インストール、実行、注意点- – Qiita
Elixir のインストール後、Livebook をコードからビルドして実行します。
Livebook のバージョン 0.10.0 を GitHub から取得します。
git clone https://github.com/livebook-dev/livebook.git -b v0.10.0 \
&& cd livebook
Livebook の依存モジュールをインストールします。
mix deps.get --only prod単体処理
まずは1台のマシンで衛星データの画像分類を実行します。
一つのマシン上で一つのノートブックを実行し、画像分類モデルで画像を分類していきます。
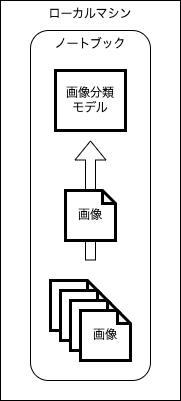
実装したノートブックはこちら。
https://github.com/sorabatake/article_33381_livebook/blob/main/notebooks/standalone.livemd
単体処理用の Livebook の起動
ローカルマシン上で Livebook を起動します。
MIX_ENV=prod mix phx.serverしばらくすると Livebook の URL が表示されるので、ブラウザで開きます。
[Livebook] Application running at http://localhost:8080/?token=xxxx
右上の “+ New notebook” をクリックすると、以下のように新しいノートブックが開きます。
単体処理のセットアップ
セットアップセル(”Notebook dependencies and setup” と書いてあるところ)に以下のコードを入力し、セル左上に表示される “Setup” をクリックします。
Mix.install(
[
{:nx, "~> 0.6"},
{:exla, "~> 0.6"},
{:axon_onnx, "~> 0.4"},
{:evision, "~> 0.1"},
{:flow, "~> 1.2"},
{:req, "~> 0.3"},
{:kino, "~> 0.10"}
],
config: [nx: [
default_backend: EXLA.Backend,
default_defn_options: [compiler: EXLA]
]]
)
このコードによって、処理の実行に必要な外部モジュールがインストールされました。
クラス名取得
テストデータのディレクトリー名からクラス名の一覧を取得します。
次のセル(黒い枠)に以下のコードを入力し、左上の “Evaluate” をクリックしてください。
classes =
"/tmp/sorabatake/dataset/test"
|> File.ls!()
|> Enum.sort()
実行後、結果が `[“clear”, “cloudy”]` と表示されます。
セルの下中央あたりにマウスカーソルを持っていくと、 “+ Elixir” というボタンが表示されるので、それをクリックすると、下に新しいセルが追加されます。
以後、新しいセルを追加、コードを入力、 Evaluate(コードの実行)を繰り返します。
モデルの読み込み
ONNX 形式のモデルファイルを読み込みます。
model_path = "/tmp/efficientnet_v2_m.onnx"
{model, params} = AxonOnnx.import(model_path)テスト用データに対する予測の実行
テスト用データ一覧の取得
テスト用データのファイル一覧を取得します。
test_files =
classes
|> Enum.flat_map(fn class ->
"/tmp/sorabatake/dataset/test/#{class}"
|> File.ls!()
|> Enum.filter(&String.ends_with?(&1, ".png"))
|> Enum.map(fn filename -> "/tmp/sorabatake/dataset/test/#{class}/#{filename}" end)
end)
|> Enum.sort()テスト用データの画像 100 件を 10 * 10 に並べて表示します
test_files
|> Enum.map(fn file_path ->
file_path
# 画像の読み込み
|> Evision.imread()
# 色空間を BGR から RGB に変換
|> Evision.cvtColor(Evision.Constant.cv_COLOR_BGR2RGB())
# 80 * 80 にリサイズ
|> Evision.resize({80, 80})
# 画像表示
|> Evision.Mat.to_nx()
|> Kino.Image.new()
end)
# 10列に並べて表示する
|> Kino.Layout.grid(columns: 10)
1 枚の画像に対する予測
先頭の1枚に対して予測を実行します。
test_files
# 先頭のファイル
|> Enum.at(0)
# OpenCV で読み込み
|> Evision.imread()
# BGR を RGB に変換
|> Evision.cvtColor(Evision.Constant.cv_COLOR_BGR2RGB())
# 224 * 224 にリサイズ
|> Evision.resize({224, 224})
# テンソルに変換
|> Evision.Mat.to_nx(EXLA.Backend)
# 0 から 255 を 0 から 1 に変換
|> Nx.divide(255)
# ImageNet の平均・分散を使って正規化
|> Nx.subtract(Nx.tensor([0.485, 0.456, 0.406]))
|> Nx.divide(Nx.tensor([0.229, 0.224, 0.225]))
# 高さ、幅、色 を 色、高さ、幅 に入れ替える
|> Nx.transpose(axes: [2, 0, 1])
|> then(fn tensor ->
model
# 予測を実行
|> Axon.predict(params, Nx.Batch.stack([tensor]))
# 値が最大のクラスを取得
|> Nx.argmax(axis: 1)
|> then(&Nx.to_number(&1[0]))
|> then(&Enum.at(classes, &1))
end)基本的に PyTorch と同じ操作を行なっています。
- `Evision.imread()`PyTorch では内部的に Pillow で読み込んでいますが、 Elixir には Pillow のラッパーがまだ存在しないので、 Evision = OpenCV で画像を読み込みます。
PyTorch 内で Pillow を使って画像をロードする際、 CYMK (シアン、イエロー、マゼンタ、キープレート) という色空間で読み込んだ後、 RGB に変換されています。
これにより、 Evision (OpenCV) で読み込んだときとピクセルの値が微妙に異なります。
- `Evision.cvtColor(Evision.Constant.cv_COLOR_BGR2RGB())`Evision では画像の色を BGR (青、緑、赤)の順で持っているため、これを RGB の順に変更します。
- `Evision.resize({224, 224})`224 * 224 のサイズに変更します。
PyTorch での `Resize(224)` に相当します。
- `Evision.Mat.to_nx(EXLA.Backend)`Nx のテンソル形式に変換します。
高速演算するため、 `EXLA.Backend` を明示的に指定しています。
- `Nx.divide(255)`
0 から 255 の範囲の整数を 0 から 1 の範囲の小数に変換します。
- `Nx.subtract(Nx.tensor([0.485, 0.456, 0.406]))`
- `Nx.divide(Nx.tensor([0.229, 0.224, 0.225]))`平均を引いてから標準偏差で割っています。
PyTorch の `Normalize(mean, std)` に相当します。
- `Nx.transpose(axes: [2, 0, 1])`高さ、幅、色 を 色、高さ、幅 に入れ替えます。
`Evision.Mat.to_nx()` と `Nx.divide(255)` と合わせて、 PyTorch の `ToTensor` に相当します。
- `Axon.predict()`予測を実行します。
PyTorch の `model(inputs)` に相当します。
- `Nx.argmax(axis: 1)`予測結果のうち、何番目の値が一番大きいかを取得します。
PyTorch の `torch.max(outputs, 1)` に相当します。
最終的に1枚目の画像の予測結果は “clear” で、正解でした。
100 枚の画像に対する予測
1 枚の画像に対する処理を `Flow.map` によって 100 枚分並列実行します。
`Flow.from_enumerable(stages: 4, max_demand: 4)` でどれくらい並列化するかを指定しています。
`stages` が並列処理の数で、 `max_demand` が1つの並列処理内で逐次処理する数です。

`stages: 4, max_demand: 4` の場合、 100 枚の画像を 4 枚ずつのグループに分け、 4 つのパイプラインに投げています。
`Flow.map` で処理した場合、順序はバラバラになってしまうので、最後に `Enum.sort_by` でファイルパス順に並び替えています。
predicted_classes =
test_files
# 並列処理化
|> Flow.from_enumerable(stages: 4, max_demand: 4)
|> Flow.map(fn file_path ->
predicted =
file_path
|> Evision.imread()
|> Evision.cvtColor(Evision.Constant.cv_COLOR_BGR2RGB())
|> Evision.resize({224, 224})
|> Evision.Mat.to_nx(EXLA.Backend)
|> Nx.divide(255)
|> Nx.subtract(Nx.tensor([0.485, 0.456, 0.406]))
|> Nx.divide(Nx.tensor([0.229, 0.224, 0.225]))
|> Nx.transpose(axes: [2, 0, 1])
|> then(fn tensor ->
model
|> Axon.predict(params, Nx.Batch.stack([tensor]))
|> Nx.argmax(axis: 1)
|> then(&Nx.to_number(&1[0]))
|> then(&Enum.at(classes, &1))
end)
{file_path, predicted}
end)
|> Enum.sort_by(&elem(&1, 0))実行結果から正解率を計算します。
predicted_classes
|> Enum.map(fn {file_path, predicted_class} ->
if file_path |> String.split("/") |> Enum.at(3) == predicted_class, do: 1, else: 0
end)
|> Enum.sum()正解数は 78 (正解率 78%)で、 PyTorch の時より少し落ちています。
これは Pillow と OpenCV による差異のため、入力値が変化したためだと思われます。
続いて、画像毎に正解クラス、予測クラスを表示します。
predicted_classes
|> Enum.map(fn {file_path, predicted_class} ->
[
Kino.Markdown.new(file_path |> String.split("/") |> Enum.at(3)),
Kino.Markdown.new(predicted_class),
file_path
|> Evision.imread()
|> Evision.cvtColor(Evision.Constant.cv_COLOR_BGR2RGB())
|> Evision.resize({120, 120})
|> Evision.Mat.to_nx()
|> Kino.Image.new()
]
|> Kino.Layout.grid()
end)
|> Kino.Layout.grid(columns: 5)
やはり、少しだけ雲がある画像で cloudy を clear と誤判定するケースがあるようです。
精度が高いとは言えませんが、それなりに分類できています。
Tellus の衛星データに対する予測
単体処理 Tellus 衛星データ取得モジュール
Tellus Traveler からデータセット(衛星やセンサーの種類)と、シーン(座標と日時の組み合わせ)を指定して衛星データをダウンロードするモジュールを用意します。
defmodule TellusTraveler do
@base_path "https://www.tellusxdp.com/api/traveler/v1"
@data_path "#{@base_path}/datasets"
defp get_headers(token) do
%{
"Authorization" => "Bearer #{token}",
"Content-Type" => "application/json"
}
end
def get_data_files(token, dataset_id, data_id) do
url = "#{@data_path}/#{dataset_id}/data/#{data_id}/files/"
headers = get_headers(token)
url
|> Req.get!(headers: headers)
|> then(& &1.body["results"])
end
defp get_data_file_download_url(token, dataset_id, data_id, file_id) do
url = "#{@data_path}/#{dataset_id}/data/#{data_id}/files/#{file_id}/download-url/"
headers = get_headers(token)
url
|> Req.post!(headers: headers)
|> then(& &1.body["download_url"])
end
def download(token, dataset_id, scene_id, dist \\ "/tmp/") do
[dist, scene_id]
|> Path.join()
|> File.mkdir_p()
token
|> get_data_files(dataset_id, scene_id)
|> Enum.map(fn file ->
file_path = Path.join([dist, scene_id, file["name"]])
unless File.exists?(file_path) do
token
|> get_data_file_download_url(dataset_id, scene_id, file["id"])
|> Req.get!(output: file_path)
end
file_path
end)
end
endTellus からの衛星データ取得
今回は大分県と山口県の間辺りのデータを使います。
提供:だいち(ALOS) AVNIR-2 データ(JAXA)
# 【Tellus公式】AVNIR-2_1B1
dataset_id = "ea71ef6e-9569-49fc-be16-ba98d876fb73"
# 2007年7月25日 瀬戸内海
scene_id = "bbf4a49f-2440-4b0f-a964-b64b7c7deacc"テキスト入力を作成します。
# Tellus のトークンを入力する
token_input = Kino.Input.password("Token")表示されたテキスト入力に事前に用意していた Tellus の API トークンを入力します。
Tellus から衛星データをダウンロードします。
file_path_list =
token_input
|> Kino.Input.read()
|> TellusTraveler.download(dataset_id, scene_id)実行結果として、ダウンロードしたファイルの一覧が表示されます。
["/tmp/bbf4a49f-2440-4b0f-a964-b64b7c7deacc/IMG-03-ALAV2A079792920-OORIRFU-D082P3-20070725-000.tif",
"/tmp/bbf4a49f-2440-4b0f-a964-b64b7c7deacc/IMG-04-ALAV2A079792920-OORIRFU-D082P3-20070725-000.tif",
"/tmp/bbf4a49f-2440-4b0f-a964-b64b7c7deacc/IMG-02-ALAV2A079792920-OORIRFU-D082P3-20070725-000.tif",
"/tmp/bbf4a49f-2440-4b0f-a964-b64b7c7deacc/ALAV2A079792920_webcog.tif",
"/tmp/bbf4a49f-2440-4b0f-a964-b64b7c7deacc/IMG-01-ALAV2A079792920-OORIRFU-D082P3-20070725-000.tif",
"/tmp/bbf4a49f-2440-4b0f-a964-b64b7c7deacc/HDR-ALAV2A079792920-OORIRFU-D082P3-20070725-000.txt",
"/tmp/bbf4a49f-2440-4b0f-a964-b64b7c7deacc/ALAV2A079792920-OORIRFU-D082P3-20070725-000_thumb.png"]衛星データはバンド(センサーが受信した光の周波数)毎に tif ファイルに分かれています。
– IMG-01-…-000.tif: 青色可視光
– IMG-02-…-000.tif: 緑色可視光
– IMG-03-…-000.tif: 赤色可視光
– IMG-04-…-000.tif: 近赤外線
各バンドのデータを取得するための関数を用意します。
get_band_tensor = fn file_path_list, prefix ->
file_path_list
|> Enum.find(fn file ->
file
|> Path.basename()
|> String.starts_with?(prefix)
end)
|> Evision.imread(flags: Evision.Constant.cv_IMREAD_GRAYSCALE())
|> Evision.Mat.to_nx(EXLA.Backend)
end青、緑、赤バンドのデータを取得し、 RGB の順で結合することで、通常のカラー画像として扱うことができます。
blue_tensor = get_band_tensor.(file_path_list, "IMG-01")
green_tensor = get_band_tensor.(file_path_list, "IMG-02")
red_tensor = get_band_tensor.(file_path_list, "IMG-03")
rgb_tensor = Nx.stack([red_tensor, green_tensor, blue_tensor], axis: 2)衛星データを小さくしてから表示します。
rgb_tensor
|> Evision.Mat.from_nx_2d()
|> Evision.resize({640, 640})
|> Evision.Mat.to_nx()
|> Kino.Image.new()
大分県民であれば左下にあるのが国東半島だと分かるでしょう。
右上の方が山口県宇部市です。
衛星データの分割
衛星データを 16 * 16 = 256 枚に分割します。
tiled_tensors =
rgb_tensor[[0..-1//1, 0..7199//1, 0..-1//1]]
# 水平に分割
|> Nx.to_batched(500)
# 垂直に分割
|> Enum.map(&Nx.transpose(&1, axes: [1, 0, 2]))
|> Enum.flat_map(&Nx.to_batched(&1, 450))
|> Enum.map(&Nx.transpose(&1, axes: [1, 0, 2]))
|> Enum.map(fn tensor ->
tensor
|> Evision.Mat.from_nx_2d()
|> Evision.resize({224, 224})
|> Evision.Mat.to_nx(EXLA.Backend)
end)分割した画像を表示します。
tiled_tensors
|> Enum.map(fn tensor ->
tensor
|> Evision.Mat.from_nx_2d()
|> Evision.resize({40, 40})
|> Evision.Mat.to_nx()
|> Kino.Image.new()
end)
|> Kino.Layout.grid(columns: 16)
単体処理画像分類モジュールの定義
1 ノードによる並列画像分類処理を定義します。
バッチサイズ(1回の画像分類で処理する画像の枚数)は 4 を指定します。
例えば画像分類を `stages: 4, max_demand: 2` で並列実行する場合、 4 * 2 (max_demand) = 8 枚ずつ、 4 並列で処理することになります。
batch_size = 4画像分類用のモジュールを作成します。
この中では正規化などの前処理や、画像分類結果を文字列にするための後処理を定義しています。
defmodule EfficientNetV2 do
import Nx.Defn
defn normalize(tensor) do
(tensor - Nx.tensor([0.485, 0.456, 0.406])) / Nx.tensor([0.229, 0.224, 0.225])
end
defn transform_for_input(img_tensor) do
(img_tensor / 255)
|> normalize()
|> Nx.transpose(axes: [2, 0, 1])
end
defn get_top_class_index(outputs) do
Nx.argmax(outputs, axis: 1)
end
defn softmax(tensor) do
Nx.exp(tensor) / Nx.sum(Nx.exp(tensor), axes: [-1], keep_axes: true)
end
defn get_top_class_score(outputs) do
outputs
|> softmax()
|> Nx.reduce_max(axes: [-1])
end
def preprocess(tensor_list, batch_size) do
tensor_list
|> Enum.map(fn tensor ->
transform_for_input(tensor)
end)
|> Nx.Batch.stack()
|> Nx.Batch.pad(batch_size - Enum.count(tensor_list))
end
def postprocess(outputs, classes) do
predicted_classes = get_top_class_index(outputs)
predicted_scores = get_top_class_score(outputs)
output_size =
outputs
|> Nx.shape()
|> elem(0)
0..(output_size - 1)
|> Enum.to_list()
|> Enum.map(fn index ->
predicted_class =
predicted_classes[index]
|> Nx.to_number()
|> then(&Enum.at(classes, &1))
predicted_score = Nx.to_number(predicted_scores[index])
%{
predicted_class: predicted_class,
predicted_score: predicted_score
}
end)
end
def predict(input_batch, model, params) do
Axon.predict(model, params, input_batch)
end
end衛星データの並列画像分類
`stages: 4, max_demand: 4` で並列実行します。
predictions =
tiled_tensors
|> Enum.with_index()
|> Enum.chunk_every(batch_size)
|> Flow.from_enumerable(stages: 4, max_demand: 4)
|> Flow.map(fn batch ->
tensor_list = Enum.map(batch, &elem(&1, 0))
index_list = Enum.map(batch, &elem(&1, 1))
index_list
|> Enum.at(0)
|> IO.inspect()
tensor_list
|> EfficientNetV2.preprocess(batch_size)
|> EfficientNetV2.predict(model, params)
|> EfficientNetV2.postprocess(classes)
|> Enum.zip(index_list)
|> Enum.map(fn {prediction, index} ->
Map.put_new(prediction, :index, index)
end)
end)
|> Enum.to_list()
|> List.flatten()
|> Enum.sort(&(&1.index < &2.index))Livebook では実行したセルの右下 “Evaluated” にマウスカーソルを合わせると、実行時間が確認できます。
実行時間は 212.6 sec でした。
もう1台の同じマシンでは 202.6 sec だったので、おおよそ 207 sec 程度で実行できています。
結果を直観的に見やすくするため、クラス毎に色を割り当てます。
color_map = %{
"clear" => [0, 0, 255],
"cloudy" => [255, 255, 255]
}予測結果が “clear” の場合、そのタイルの場所に青い四角形を表示します。
color_map
|> Map.get("clear")
|> Nx.tensor(type: :u8)
|> Nx.broadcast({40, 40, 3})
|> Kino.Image.new()
元画像と各タイル毎に予測結果を表示したものを並べて表示します。
[
rgb_tensor
|> Evision.Mat.from_nx_2d()
|> Evision.resize({640, 640})
|> Evision.Mat.to_nx()
|> Kino.Image.new(),
predictions
|> Enum.map(fn prediction ->
color_map
|> Map.get(prediction.predicted_class)
|> Nx.tensor(type: :u8)
|> Nx.broadcast({40, 40, 3})
|> Kino.Image.new()
end)
|> Kino.Layout.grid(columns: 16)
]
|> Kino.Layout.grid(columns: 2)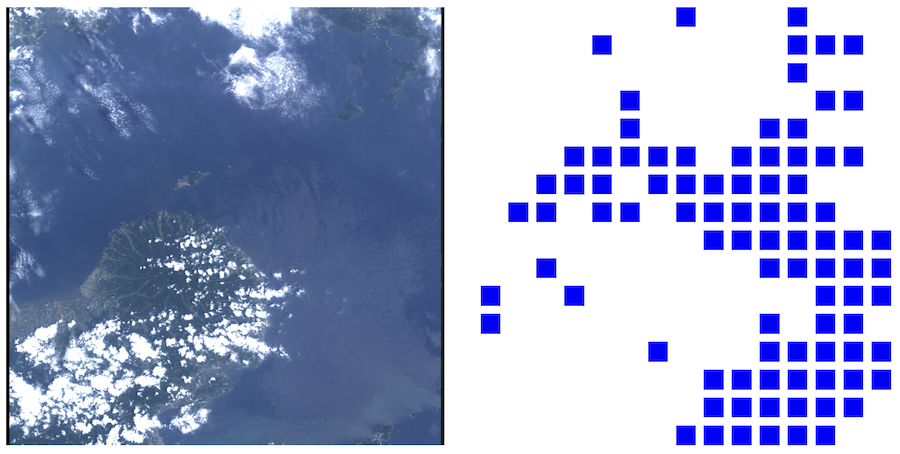
ざっくり、雲のあるところが白いタイル、雲のないところが青いタイルになっていると思います
並列分散処理
2台のマシンで衛星データの画像分類を並列分散実行します。
単体処理用 Livebook 停止
単体処理用に起動していた Livebook を `control + C` で中断します。
以下のようなメッセージが表示されるので、 `a` を入力して Livebook を終了します。
BREAK: (a)bort (A)bort with dump (c)ontinue (p)roc info (i)nfo
(l)oaded (v)ersion (k)ill (D)b-tables (d)istribution分散処理用 Livebook 起動
分散処理用に Livebook を起動します。
まず使用するローカルマシン2台が同じネットワーク内にあることを確認した上で現在の IP アドレスを確認します。
macOS の場合は以下のコマンドで確認可能です。
ipconfig getifaddr en0`192.168.8.157` というように結果が返ってくるので、この IP アドレスを Livebook 起動時に使用します。
LIVEBOOK_DISTRIBUTION=name \
LIVEBOOK_NODE="livebook-server@" \
LIVEBOOK_IP=0.0.0.0 \
MIX_ENV=prod mix phx.serverローカルマシン2台の両方で Livebook を起動してください。
サーバー側ノートブック
両方のマシンにモデルファイル `/tmp/sorabatake/efficientnet_v2_m.onnx` が配置されていることを確認してください。
ローカルマシン2台でサーバー用のノートブックを実行します。
実装したノートブックはこちら。
https://github.com/sorabatake/article_33381_livebook/blob/main/notebooks/server.livemd
サーバー側セットアップ
サーバー側で使用する外部モジュールをインストールします。
Mix.install(
[
{:nx, "~> 0.6"},
{:exla, "~> 0.6"},
{:axon_onnx, "~> 0.4"},
{:kino, "~> 0.10"}
],
config: [
nx: [
default_backend: EXLA.Backend,
default_defn_options: [compiler: EXLA]
]
]
)サーバー側モデル読み込み
クラスを指定します。
classes = ["clear", "cloudy"]モデルファイルをロードします。
model_path = "/tmp/sorabatake/efficientnet_v2_m.onnx"
{model, params} = AxonOnnx.import(model_path)画像分類モジュールの定義
単体処理のときと同じ[画像分類用のモジュール](#単体処理画像分類モジュールの定義)を作成します。
defmodule EfficientNetV2 doクライアント側から呼び出される処理の定義
処理した画像の分類結果を表示するフレームを準備します。
frame = Kino.Frame.new()バッチサイズに 4 を指定します。
batch_size = 4前処理、後処理、推論を実行するための `Nx.Serving` を作成します。
serving =
Nx.Serving.new(
fn _ ->
# 画像分類の実行
fn input_batch ->
EfficientNetV2.predict(input_batch, model, params)
end
end,
compiler: EXLA
)
# バッチサイズの指定
|> Nx.Serving.process_options(batch_size: batch_size)
# 前処理
|> Nx.Serving.client_preprocessing(fn tensor_list ->
input_batch = EfficientNetV2.preprocess(tensor_list, batch_size)
{input_batch, :client_info}
end)
# 後処理
|> Nx.Serving.client_postprocessing(fn {outputs, _metadata}, _multi? ->
predictions =
EfficientNetV2.postprocess(outputs, classes)
predictions
|> Enum.map(fn prediction ->
prediction.predicted_class
end)
|> Enum.join(", ")
|> then(&Kino.Frame.render(frame, &1))
predictions
end)ダミーデータ(真っ黒の画像)で直接実行してみます。
dummy_tensor =
0
|> Nx.broadcast({224, 224, 3})
|> Nx.as_type(:u8)`Nx.Serving.run` で直接処理を実行します。
Nx.Serving.run(serving, [dummy_tensor])実行結果は `[%{predicted_class: “cloudy”, predicted_score: 0.6431663036346436}]` になりました。
真っ黒な画像は曇りに分類したようです。
分散処理の待ち受け
クライアントからの呼び出しを待ち受けるため、画像分類処理を子プロセスとして起動します。
子プロセスは `ImageClassification` の名前で呼び出せるようになります。
Kino.start_child({Nx.Serving, serving: serving, name: ImageClassification})ダミーデータ(真っ黒の画像)で呼び出してみます。
`Nx.Serving.batched_run` で子プロセスの処理を実行します。
Nx.Serving.batched_run({:distributed, ImageClassification}, [dummy_tensor])
直接実行したときと同じ結果になりました。
別ノードから接続するための接続情報(ノード名、クッキー)を表示します。
{node(), Node.get_cookie()}実行結果は以下のようになります。
{:"zra7h4hl-livebook-server@192.168.8.157", :c_V2Un_3Pyz5xtLEmp7u46c2c2iXlDv6EPbjcLl_DAHNXxUErWFc9t}クライアント側から接続する際に使用するので、ノートブックは開いたままにします。
サーバー側を2台両方実行した後、クライアント側を実行していきます。
クライアント側ノートブック
2台のローカルマシンの片方で新しいノートブックを開き、クライアント側のノートブックを実行していきます。
クライアント側のノートブックで Tellus から画像を取得し、分割して2台のサーバー側に送信します。
実装したノートブックはこちら。
https://github.com/sorabatake/article_33381_livebook/blob/main/notebooks/client.livemd
クライアント側セットアップ
セットアップセルに以下のコードを入力し、実行します。
Mix.install(
[
{:nx, "~> 0.6"},
{:exla, "~> 0.6"},
{:axon_onnx, "~> 0.4"},
{:evision, "~> 0.1"},
{:flow, "~> 1.2"},
{:req, "~> 0.3"},
{:kino, "~> 0.10"}
],
config: [nx: [default_backend: EXLA.Backend]]
)クライアント側データ取得
単体処理のときと同じTellus衛星データ取得モジュールを定義します。
defmodule TellusTraveler do単体処理のときと同じデータセットID、シーンIDを指定します。
dataset_id = "ea71ef6e-9569-49fc-be16-ba98d876fb73"
scene_id = "bbf4a49f-2440-4b0f-a964-b64b7c7deacc"Tellus のトークンを入力します。
# Tellus のトークンを入力する
token_input = Kino.Input.password("Token")
Tellus から衛星データをダウンロードします。
file_path_list =
token_input
|> Kino.Input.read()
|> TellusTraveler.download(dataset_id, scene_id)
get_band_tensor = fn file_path_list, prefix ->
file_path_list
|> Enum.find(fn file ->
file
|> Path.basename()
|> String.starts_with?(prefix)
end)
|> Evision.imread(flags: Evision.Constant.cv_IMREAD_GRAYSCALE())
|> Evision.Mat.to_nx(EXLA.Backend)
end
blue_tensor = get_band_tensor.(file_path_list, "IMG-01")
green_tensor = get_band_tensor.(file_path_list, "IMG-02")
red_tensor = get_band_tensor.(file_path_list, "IMG-03")
rgb_tensor = Nx.stack([red_tensor, green_tensor, blue_tensor], axis: 2)
rgb_tensor
|> Evision.Mat.from_nx_2d()
|> Evision.resize({640, 640})
|> Evision.cvtColor(Evision.Constant.cv_COLOR_RGB2BGR())単体処理のときと同じように衛星画像を 256 分割します。
tiled_tensors =
rgb_tensor[[0..-1//1, 0..7199//1, 0..-1//1]]
# 水平に分割
|> Nx.to_batched(500)
# 垂直に分割
|> Enum.map(&Nx.transpose(&1, axes: [1, 0, 2]))
|> Enum.flat_map(&Nx.to_batched(&1, 450))
|> Enum.map(&Nx.transpose(&1, axes: [1, 0, 2]))
|> Enum.map(fn tensor ->
tensor
|> Evision.Mat.from_nx_2d()
|> Evision.resize({224, 224})
|> Evision.Mat.to_nx(EXLA.Backend)
end)
tiled_tensors
|> Enum.map(fn tensor ->
tensor
|> Evision.Mat.from_nx_2d()
|> Evision.resize({40, 40})
|> Evision.Mat.to_nx()
|> Kino.Image.new()
end)
|> Kino.Layout.grid(columns: 16)サーバー側との接続
2つのサーバー側ノートブックに接続するため、接続情報を入力します。
server_node_inputs =
["A", "B"]
|> Enum.into(%{}, fn node_id ->
{
node_id,
%{
node: Kino.Input.text("SERVER_#{node_id}_NODE_NAME"),
cookie: Kino.Input.text("SERVER_#{node_id}_COOKIE")
}
}
end)
server_node_inputs
|> Enum.map(fn {_, inputs} ->
[inputs.node, inputs.cookie]
end)
|> List.flatten()
|> Kino.Layout.grid(columns: 2)サーバー A と B に対して、それぞれノード名、クッキーを入力してください。

サーバー側ノートブックに接続します。
server_node_inputs
|> Enum.map(fn {_, inputs} ->
node_name =
inputs.node
|> Kino.Input.read()
|> String.to_atom()
cookie =
inputs.cookie
|> Kino.Input.read()
|> String.to_atom()
Node.set_cookie(node_name, cookie)
Node.connect(node_name)
end)実行結果が `[true, true]` になれば接続成功です。
分散逐次実行
バッチサイズに 4 を指定します。
batch_size = 4まず、 `Enum.map` で先頭 16 件を逐次処理してみます。
`Nx.Serving.batched_run` により、画像分類処理は呼び出されるたび、サーバーAかサーバーBのどちらかで実行されます。
predictions =
tiled_tensors
# 先頭16件
|> Enum.slice(0..15)
|> Enum.with_index()
# バッチサイズ毎に分割
|> Enum.chunk_every(batch_size)
# 逐次実行
|> Enum.map(fn batch ->
tensor_list = Enum.map(batch, &elem(&1, 0))
index_list = Enum.map(batch, &elem(&1, 1))
# 画像分類処理を呼び出す
ImageClassification
|> Nx.Serving.batched_run(tensor_list)
|> Enum.zip(index_list)
|> Enum.map(fn {prediction, index} ->
Map.put_new(prediction, :index, index)
end)
end)
|> List.flatten()16件分の結果を表示してみます。
tiled_tensors
|> Enum.zip(predictions)
|> Enum.map(fn {tensor, prediction} ->
[
Kino.Markdown.new(prediction.predicted_class),
tensor
|> Evision.Mat.from_nx_2d()
|> Evision.resize({100, 100})
|> Evision.Mat.to_nx()
|> Kino.Image.new()
]
|> Kino.Layout.grid()
end)
|> Kino.Layout.grid(columns: 8)正解かどうかはともかく、分割されたそれぞれの画像に対して結果が表示されました。

並列分散実行
`Enum.map` を `Flow.map` に変更して並列分散実行します。
predictions =
tiled_tensors
|> Enum.with_index()
|> Enum.chunk_every(batch_size)
|> Flow.from_enumerable(stages: 4, max_demand: 4)
|> Flow.map(fn batch ->
tensor_list = Enum.map(batch, &elem(&1, 0))
index_list = Enum.map(batch, &elem(&1, 1))
index_list
|> Enum.at(0)
|> IO.inspect()
ImageClassification
|> Nx.Serving.batched_run(tensor_list)
|> Enum.zip(index_list)
|> Enum.map(fn {prediction, index} ->
Map.put_new(prediction, :index, index)
end)
end)
|> Enum.to_list()
|> List.flatten()
|> Enum.sort(&(&1.index < &2.index))`stages: 4, max_demand: 4` のとき、実行時間は 116.2 sec でした。
単体処理のときが約 207 sec だったので、 約 56 % まで時間が短縮できました。
実行結果を色のタイルで視覚化します。
color_map = %{
"clear" => [0, 0, 255],
"cloudy" => [255, 255, 255]
}
[
rgb_tensor
|> Evision.Mat.from_nx_2d()
|> Evision.resize({640, 640})
|> Evision.Mat.to_nx()
|> Kino.Image.new(),
predictions
|> Enum.map(fn prediction ->
color_map
|> Map.get(prediction.predicted_class)
|> Nx.tensor(type: :u8)
|> Nx.broadcast({40, 40, 3})
|> Kino.Image.new()
end)
|> Kino.Layout.grid(columns: 16)
]
|> Kino.Layout.grid(columns: 2)単体処理のときと全く同じ結果になりました。
並列分散数の変更
stages と max_demand を変えて、その影響を確認してみましょう。
| stages \ max_demand | 1 | 2 | 4 | 8 | 16 |
|---|---|---|---|---|---|
| 1 | 241.3 | 223.7 | 216.6 | 219.1 | 219.7 |
| 2 | 157.4 | 149.3 | 151.2 | 161.2 | 140.5 |
| 4 | 120.1 | 143.3 | 116.2 | 135.0 | 139.1 |
| 8 | 131.2 | 117.1 | 118.5 | 129.5 | 120.8 |
| 16 | 140.8 | 112.2 | 112.7 | 127.3 | 130.4 |
stages が 1 のときは分散処理のオーバーヘッド(通信時間など)が単純に増え、単体処理よりも遅くなっています。
stages が 2 以上では複数台で並列処理する分、単体処理よりも速くなっています。
最も速度の速かった `stages: 16, max_demand: 2` の場合、単体処理の 54 % の時間で処理できており、ほぼ2倍の性能になっています。
つまり、単純に2台で画像を分けて実行した場合とあまり変わらず、ほとんどオーバーヘッドなしで分散処理できていることが分かります。
また、 `stages: 8` と `stages: 16` ではあまり差がありません。
むしろ `stages: 16` の方が遅くなっているケースもあります。
これは使用した MacBook が CPU コア数 4 であり、2台だと 8 までしか並列処理の効果がないためです。
stages は CPU のコア数に応じた値を指定することになります。
max_demand は 1 や 16 ではなく、中間の 4 あたりで速度が上がっています。
これはある程度のカタマリで処理したほうがオーバーヘッドが小さくなるためだと思われます。
今回バッチサイズは変更していませんが、バッチサイズと max_demand によって一度に送信するデータ量が変わるため、この2つを調整することで、性能を改善できるケースがありそうです。
まとめ
Elixir によってオーバーヘッドを極力抑えた並列分散推論が実装できました。
実用では GPU を使うことになるので、いずれ GPU を積んだ複数台のマシンによる並列分散処理を実行してみます。
