Python でトレーニングした衛星画像分類モデルを Elixir で並列分散推論する(Python トレーニング編)
並列分散処理を得意とするElixirで衛星データ分析を実施してみました!前編です。
はじめに
先日、宙畑の記事でElixirという開発言語を紹介しました。
衛星データ分析におススメの言語は?言語別の特徴まとめとElixir紹介
Elixir は並列分散処理が得意な開発言語で、近年機械学習などの領域でも使われだしています。
今回は Python でトレーニングした機械学習モデルを Elixir で並列分散実行してみようと思います。
記事が長いのでトレーニング編と推論編の2本に分割しています。
– Python トレーニング編 (この記事)
– Elixir 推論編
Python トレーニング編では、衛星画像を分類する機械学習モデルを Google Colaboratory (以下、Colab)上でトレーニングします。
Elixir 推論編では、学習したモデルを使って、Tellus から取得した日本の衛星画像に対して画像分類を実行してみます。
Python プログラマーの方へ
Python でトレーニングしたモデルを最強 Web フレームワーク Phoenix で動かすことができます。
以下は公式サイトからの引用です。
>Build rich, interactive web applications quickly, with less code and fewer moving parts.
和訳
> 少ないコードと少ないパーツで、リッチでインタラクティブな Web アプリケーションを迅速に構築します。
Phoenix は Ruby on Rails の開発メンバーである Jose Valim が開発に携わっており、エンジニアが楽に、楽しく Web アプリケーションを開発できるように設計されています。
また、2023 年 Stack Overflow の調査結果では、 Elixir の Web フレームワークである Phoenix が最もエンジニアたちから称賛されています。
大量アクセスに対しても高効率で安定稼働できるため、様々なサービスで数億円規模のコスト削減を実現しています。
Elixir 、 Phoenix を使って安定稼動する AI Web システムを構築しましょう。
参考サイト:
Phoenix Framework
https://www.phoenixframework.org/
Stack Overflow 2023 Developer Survey
https://survey.stackoverflow.co/2023/#section-admired-and-desired-web-frameworks-and-technologies
Elixir Saves Pinterest $2 Million a Year In Server Costs
https://paraxial.io/blog/elixir-savings
衛星データを並列分散処理する目的
近い将来、次々と大量の衛星が打ち上がり、その衛星から得られるデータもどんどん増えていくでしょう。
巨大かつ膨大な衛星データを処理するためには、コンピュータにかなり高い処理能力が必要になってきます。
そこで、多数のコンピュータを繋げ、 Elixir によって高効率、堅牢な並列分散処理を実装することで、この課題を解決したい、というのが、衛星データを並列分散処理する最終的な目的です。
詳しくは北九州市立大学の山崎准教授の書いた記事をご覧ください。
Elixirと宇宙の話でもしますか〜Elixirと宇宙利用の関係
構築する画像分類モデル
以下の記事で使った衛星データを流用し、雲が映っているか否か画像分類するモデルを PyTorch で構築します。
CNNを使って衛星データに雲が映っているか否か画像分類してみた
データセットはこちらからダウンロードできます。
衛星画像は以下の2種類にクラス分けされます。

また、機械学習のため、衛星画像をトレーニング用、評価用、テスト用の3種類に振り分けます。
– トレーニング用
トレーニング時、機械学習モデルに何度も読み込ませて内部のパラメータを調整するためのデータ。
– 評価用
トレーニング時、定期的にトレーニングがうまく進んでいるか確認するためのデータ。
パラメータの調整には使わないが、「どこでトレーニングを終了させるか」の判断に使う。
– テスト用
トレーニング完了後、精度を検証するためのデータ。
各種衛星画像は以下のようなディレクトリー構造で配置します。
dataset
┣ train (トレーニング用)
┃ ┣ clear (36枚)
┃ ┗ cloudy (64枚)
┃
┣ validation (評価用)
┃ ┣ clear (450枚)
┃ ┗ cloudy (750枚)
┃
┗ test (テスト用)
┣ clear (114枚)
┗ cloudy (186枚)流用元の記事と合計枚数、ディレクトリー構造は同じですが、トレーニング用の画像枚数を増やすため、ディレクトリー毎の枚数を変えています。
この `dataset` ディレクトリーを圧縮し、 Colab 上で使うために自分の Google Drive 上に `space/dataset.zip` としてアップロードしたものとします。
Google Colab でのノートブック実行
右のリンクを開くと、 GitHub上のJupyter ノートブックが開きます。
ノートブックにある「Open In Colab」のボタンをクリックしてください。
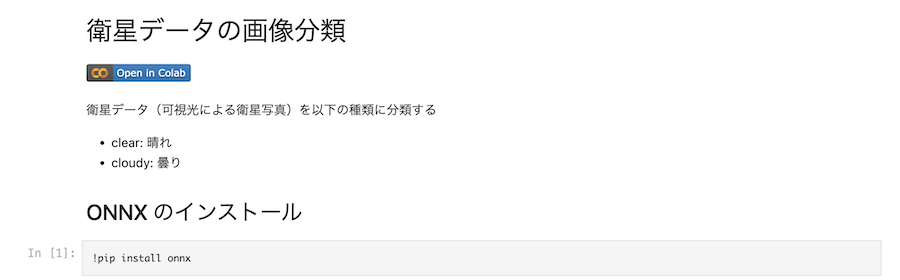
すると、Colab で当該ノートブックが開きます。
トレーニングを高速に行うため、 GPU が使えるようになっているか確認します。
上メニューから “ランタイム” |> “ランタイムタイプの変更” をクリックします。
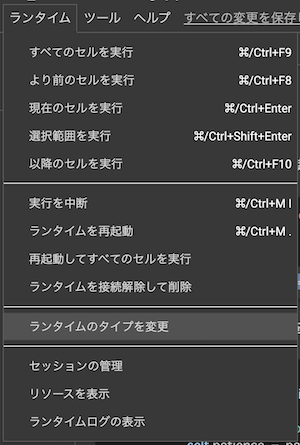
ハードウェアアクセラレータが “GPU” になっていることを確認してください。
(なっていなければ “GPU” に変更して “保存” をクリックしてください。)
以降、 Colab でノートブック上の各セルを実行していきます。
必要なモジュールのインストール
今回はトレーニングしたモデルを最終的に ONNX という形式に変換します。
Colab では PyTorch などの、機械学習でよく利用するモジュールはインストール済になっていますが ONNX はインストールされていません。
そのため、追加でインストールする必要があります。
!pip install onnx参考サイト:ONNX
https://onnx.ai/
モジュールのインポート
利用するモジュールをインポートしておきます。
import copy
import math
import os
import random
import time
import matplotlib.pyplot as plt
import numpy as np
import shutil
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from glob import glob
from google.colab import drive
from torchvision import datasets, models, transforms今回は PyTorch を使ってトレーニングするため、 `trorch` や `torchvision` をインポートしています。
また、 `google.colab` は Google Drive へのアクセスに使用します。
画像ファイルの配置
画像ファイルの展開
Google Drive に接続し、トレーニングする画像ファイルを Colab 上に配置します。
以下のコードを実行すると、 Google Drive へのアクセス許可を求めるウィンドウが開くので、許可して先に進んでください。
drive.mount("/content/drive")`Mounted at /content/drive` と結果が表示されれば接続できています。
Colab の左メニューからフォルダのアイコンをクリックすると、 Colab 上のファイルシステムを参照できます。
drive を開くとその中に MyDrive があり、その中が Google Drive の内容になっています。
次のコードで、用意しておいた ZIP ファイルを Colab 上にコピーし、展開します。
!cp /content/drive/MyDrive/space/dataset.zip .
!unzip -q dataset.zipdataset ディレクトリーの下に train validation test があり、それぞれの配下に分類したい2クラス (clear cloudy)のディレクトリーができています。
更に各クラスのディレクトリー内には大量の画像ファイルが入っています。
クラス名の一覧を変数に格納します。
classes = [os.path.basename(directory) for directory in sorted(glob("./dataset/train/*"))]
classes実行結果は `[‘clear’, ‘cloudy’]` となります。
モデルの定義
機械学習モデルを一からトレーニングする場合、非常に大量のデータを非常に長い時間をかけてトレーニングする必要があります。
それはあまりにも大変なので、転移学習(Transfer Learning)という手法を用います。
画像分類モデルは入力層、中間層(隠れ層)、出力層の3層が繋がってできています。
– 入力層: 画像を読み込む
– 中間層: 画像の特徴を抽出する
– 出力層: 画像の特徴から、分類するもの毎に可能性の高さを算出する
転移学習とは、既存のトレーニング済モデルの出力層だけを新しいものに差し替え、そこだけ学習し直す手法です。
様々な画像を大量に学習したモデルであれば、中間層による画像の特徴抽出は学習し直す必要がない、というわけです。
今回は EfficientNet V2 というニューラルネットワークの ImageNet 画像でトレーニング済のモデルを使用します。
`torchvision.models` には様々な画像用モデルが定義されており、更に `weights` に値を指定することで、トレーニング済モデルをダウンロードしてきて使うことができます。
model = models.efficientnet_v2_m(weights=models.EfficientNet_V2_M_Weights.IMAGENET1K_V1)出力層だけトレーニング(パラメータの更新)し直すため、まず全部の層をパラメータ更新しないように設定します。
for param in model.parameters():
param.requires_grad = Falseこの時点での出力層を確認してみます。
model.classifier結果は以下のようになります。
Sequential(
(0): Dropout(p=0.3, inplace=True)
(1): Linear(in_features=1280, out_features=1000, bias=True)
)出力 `out_features` が 1,000 になっています。
これはトレーニング済のモデルが 1,000 種類のものを分類するためです。
入力の数は同じまま、出力の数を分類したいクラス数(2)のものに入れ替えます。
num_ftrs = model.classifier[1].in_features
model.classifier[1] = nn.Linear(num_ftrs, len(classes))この状態でもう一度出力層を確認してみます。
model.classifier結果は以下のように out_features が 2 になっています。
Sequential(
(0): Dropout(p=0.3, inplace=True)
(1): Linear(in_features=1280, out_features=2, bias=True)
)また、層の形を変更したことにより、出力層だけはトレーニング対象になります。
参考サイト:
EfficientNet V2
https://arxiv.org/abs/2104.00298
ImageNet
https://www.image-net.org/
データ変換
画像を機械学習モデルに読み込ませる前に、そのための形式に変換します。
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
data_transforms = {
"train": transforms.Compose([
transforms.Resize(256),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomVerticalFlip(0.5),
transforms.RandomAffine(degrees=[-5, 5], translate=(0.2, 0.2), scale=(0.9, 1.1)),
transforms.RandomPerspective(distortion_scale=0.05, p=0.95),
transforms.ColorJitter(brightness=0.3, contrast=0.2, saturation=0.2),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean, std)
]),
"validation": transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize(mean, std)
]),
"test": transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize(mean, std)
]),
}データ変換はトレーニング用(”train”)と評価用(”validation”)、テスト用(”test”)の3種類を定義しています。
それぞれの変換内容を説明します。
評価用データとテスト用データ
データ(画像)を読み込むとき、評価用とテスト用に関してはモデルに入力するための変換だけを行います。
- `Resize(224)`モデルの入力層(データを読み込む部分)はサイズが決まっているため、画像を一定のサイズ 224 * 224 に変更します。
- `ToTensor`画像は Pillow というパッケージで読み込んでいるため、形式も Pillow 用のものになっています。
画像データを Pillow 形式から PyTorch 内で扱うテンソル形式に変換します。
また、画像は各ピクセルの RGB について 0 から 255 の範囲の整数値を持っていますが、これを 0 から 1 の小数の範囲に変換します。
さらに、画像データは (高さ、幅、色) の順番でデータを持っていますが、これを (色、高さ、幅) の順番に入れ替えます。
- `Normalize(mean, std)`「正規化」という操作です。
入力項目毎の値の大小、バラツキの大小の差異を同程度に統一します。
今回はトレーニング済モデルに ImageNet を使っているため、 ImageNet 画像の平均と標準偏差を指定します。
トレーニング用データ
トレーニング用の場合、より良くトレーニングするため、画像にランダムな変化を加えます。
何度も同じデータばかりをトレーニングすると、トレーニングデータに対してはよく正解するが、未知のデータに対してはあまり正解しない、過学習と呼ばれる状態に陥ります。
過学習を回避するためには、できるだけバリエーションの多い様々な画像を使う必要がありますが、それを用意するのは大変です。
そこで、既にある画像をランダムに回転したり拡大縮小したり色を変えたりして、自動的にバリエーションを増やします。
- `Resize(256)`画像を 256 * 256 の大きさにします。
- `RandomHorizontalFlip(0.5)`50%の確率で画像を左右反転します。
- `RandomVerticalFlip(0.5)`50%の確率で画像を上下反転します。
- `transforms.RandomAffine(degrees=[-5, 5], translate=(0.2, 0.2), scale=(0.9, 1.1))`指定した範囲でランダムに回転、水平移動、拡大縮小します。
- `transforms.RandomPerspective(distortion_scale=0.05, p=0.95)`指定した範囲で台形補正のように画像をランダムに歪ませます。
- `transforms.ColorJitter(brightness=0.3, contrast=0.2, saturation=0.2)`指定した範囲で色(明るさ、コントラスト、彩度)をランダムに変更します。
- `CenterCrop(224)`中心の 224 * 224 を切り抜きます。
これによって入力層の形と同じになります。
データローダー
データを順次読み込みながら変換し、機械学習モデルへ渡すためのデータローダーを用意します。
データローダーは `batch_size` に指定した枚数ずつ、 `num_workers` に指定した並列数で画像を読み込みます。
data_kind = ["train", "validation", "test"]
image_datasets = {x: datasets.ImageFolder(f"dataset/{x}", data_transforms[x])
for x in data_kind}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,shuffle=(x != "test"), num_workers=2)
for x in data_kind}それぞれのデータ数(画像の枚数)を確認します。
dataset_sizes = {x: len(image_datasets[x]) for x in data_kind}
dataset_sizes結果は `{‘train’: 1200, ‘validation’: 300, ‘test’: 100}` となります。
この後使うため、画像表示用関数を準備します。
データローダーから読み込んだ画像は正規化等の処理で変換されているため、画像として表示するために正規化の逆を適用しています。
inv_normalize = transforms.Normalize(
mean= -1 * np.divide(mean, std),
std= 1 / std
)
def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inv_normalize(inp)
inp = inp.numpy().transpose((1, 2, 0))
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001)トレーニング用データを1回分( `batch_size=4` なので画像4枚)を読み込み、ランダムに変更された結果を確認してみます。
inputs, classes = next(iter(dataloaders['train']))
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])
ランダムに回転させたりした結果、黒い部分ができていることが分かります。
トレーニング定義
どうトレーニングするか、を定義していきます。
デバイス
まず、トレーニングに使うデバイスを取得します。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")GPU が使えれば GPU 、使えなければ CPU を使います。
Colab の設定で GPU を設定できるようにしたため、 結果は `device(type=’cuda’, index=0)` となるはずです。
早期終了
トレーニングでは何度も画像を読み込みながらモデル内のパラメータを調整していきます。
トレーニングデータに対しては基本的に繰り返せば繰り返すほど精度が上がって誤差が下がっていきますが、トレーニングしていない評価用データに対しては頭打ちになります。
そして、頭打ちになった後にさらにトレーニングを続けていくと、画像にランダムな変化を加えていたとしても、やはりある程度同じ画像をトレーニングしているため、過学習が発生し、評価用データに対する精度が下がって誤差が上がっていくようになります。
そこで、データを1巡(1 epoch)トレーニングする度に評価用データに対する誤差を算出し、以前よりも良くなったか、悪くなったかをチェックします。
指定した回数、評価用データに対する誤差が小さくならなかった = 改善されなかった場合、過学習が起きているものと判断してトレーニングを中断します。
これを早期終了(Early Stopping)と呼び、余計なトレーニングをせず、指定した上限回数より早めにトレーニングを終えることができます。
class EarlyStopping:
def __init__(self, patience=5, verbose=0):
self.epoch = 0
self.pre_loss = float('inf')
self.patience = patience
self.verbose = verbose
def __call__(self, current_loss):
if self.pre_loss self.patience:
if self.verbose:
print('early stopping')
return True
else:
self.epoch = 0
self.pre_loss = current_loss
return False精度と誤差のグラフ表示
トレーニングがうまくいったのかどうかを確認するため、精度と誤差をグラフ表示し、画像として保存します。
トレーニングデータに対する精度・誤差を青の線、評価用データに対する精度・誤差をオレンジの線で表示します。
トレーニングが上手くいっていれば、 epoch が進むにつれ精度は上昇し、誤差は下降するはずです。
また、トレーニングデータの誤差が下がっているのに評価用データの誤差が上がっていれば、過学習が発生した = 現在の定義ではこれ以上精度は向上しない、と判断できます。
逆にトレーニングが上限回数まで達したのにまだまだ評価用データの誤差が下がっているようであれば、トレーニング回数が足りていないと判断できます。
def save_plots(value_dict, label):
plt.figure(figsize=(10, 7))
plt.plot(
value_dict['train'], color='blue', linestyle='-',
label=f"train {label}"
)
plt.plot(
value_dict['validation'], color='orange', linestyle='-',
label=f"validation {label}"
)
plt.xlabel('Epochs')
plt.ylabel(label.capitalize())
plt.legend()
plt.savefig(f"./{label}.png")トレーニング処理
トレーニングの本体です。
def train_model(model, criterion, optimizer, early_stopping, num_epochs=25):
since = time.time()
loss_dict = {'train': [], 'validation': []}
acc_dict = {'train': [], 'validation': []}
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
stop = False
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
for phase in ['train', 'validation']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
# トレーニング用データの場合、パラメータを最適化する
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
loss_dict[phase].append(epoch_loss)
acc_dict[phase].append(epoch_acc.to('cpu').detach().numpy().copy())
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
if phase == 'validation':
# 早期終了の判定
if early_stopping(epoch_loss):
stop = True
# 最善の状態を保持する
if epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
if stop:
break
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
model.load_state_dict(best_model_wts)
return model, loss_dict, acc_dictトレーニング用データと評価用データについて、各 epoch で全画像を読み込んでいます。トレーニング用データの場合のみ、 `loss.backward()` でパラメータ更新を行います。
どちらの場合も精度、誤差を計算します。評価用データの場合、早期終了の判定を行います。
また、評価用データの精度が最善の状態を変数 `best_model_wts` に保持しておきます。
トレーニング実行
これまで定義してきたものを使ってトレーニングを実行します。
model = model.to(device)
# 損失関数
criterion = nn.CrossEntropyLoss()
# 最適化関数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
# 早期終了
early_stopping = EarlyStopping(patience=5, verbose=1)
# トレーニング実行
model, loss_dict, acc_dict = train_model(model, criterion, optimizer, early_stopping, num_epochs=25)損失関数は「誤差はどういう値か」を定義し、最適化関数は「どういうふうにパラメータを更新するか」を定義します。
(この記事ではここに踏み入りません。)
また、早期終了を使い、最大 epoch 数を 25 に指定してトレーニングを実行します。
トレーニングを開始すると、以下のように途中経過が表示されていきます。
Epoch 0/24
----------
train Loss: 0.5219 Acc: 0.7492
validation Loss: 0.4345 Acc: 0.8033
Epoch 1/24
----------
train Loss: 0.4497 Acc: 0.8050
validation Loss: 0.4320 Acc: 0.8133
Epoch 2/24
----------各 epoch について、トレーニング用データ(train)と評価用データ(validation)に対する Loss = 誤差と、 Acc = 精度が表示されています。
評価用データの Loss が下がっているようであれば順調です。数十分トレーニングにかかりますが、時々状況を確認してください。
90分間操作しないと、環境がリセットされてしまいます(今回のトレーニング時間であれば大丈夫だとは思いますが。)
最終的に、以下のように “Training complete” が表示されればトレーニング終了です。
----------
train Loss: 0.4131 Acc: 0.8200
validation Loss: 0.4185 Acc: 0.8167
Epoch 10/24
----------
train Loss: 0.4248 Acc: 0.8050
validation Loss: 0.3966 Acc: 0.8200
early stopping
Training complete in 4m 27s
Best val Acc: 0.856667最善のトレーニング結果をファイルとして保存します。
torch.save(model.state_dict(), "./efficientnet_v2_m.pth")トレーニング結果のグラフ化
誤差の推移をグラフ化します。
save_plots(loss_dict, "loss")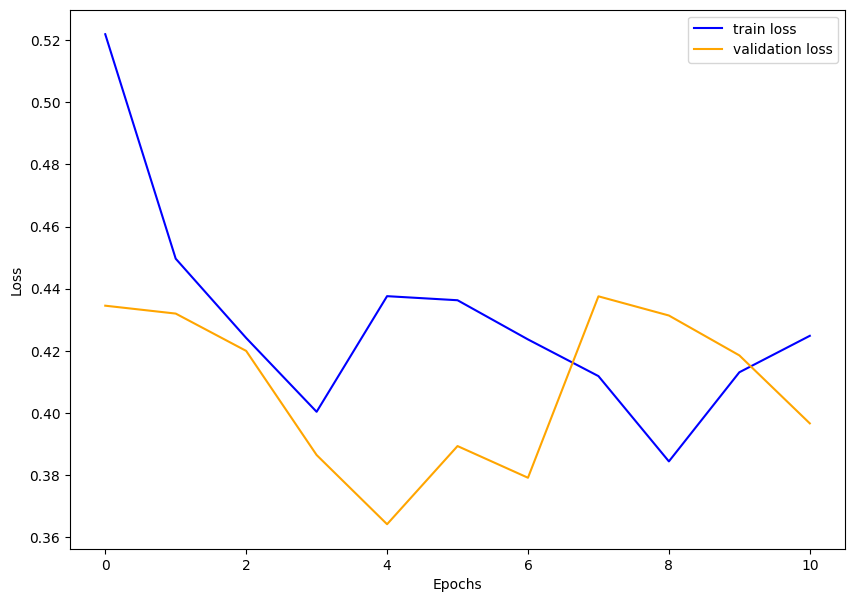
第 4 epoch で評価用データの誤差が最小になっていて、その後改善しなかったため早期終了したことが分かります。
精度の推移をグラフ化します。
save_plots(acc_dict, "accuracy")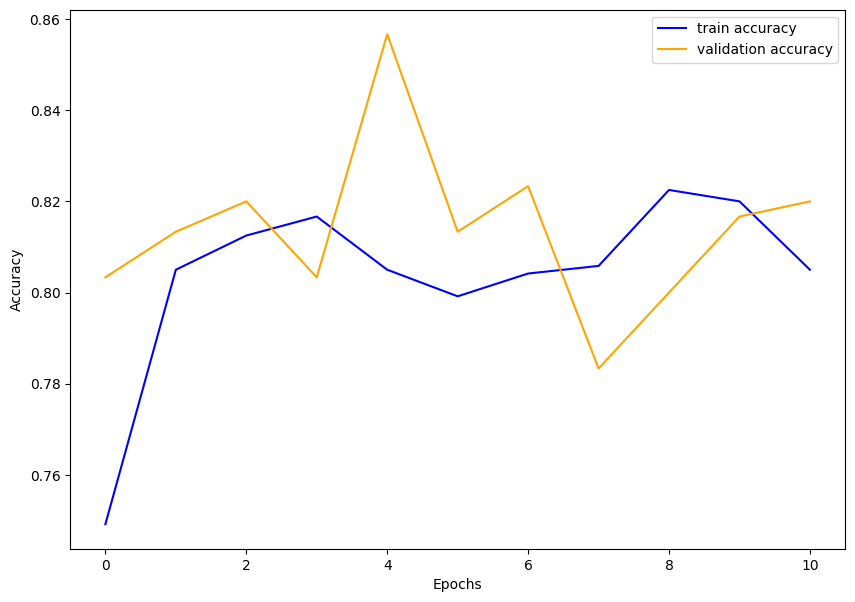
ある程度高い数値で推移しています。
Google Drive へのトレーニング結果の保存
Colab の環境は使い終わったら消えてしまいます。
Colab のファイルシステム上に保存したファイルも消えてしまうため、残しておきたいファイルは外部にコピーする必要があります。
トレーニング結果のモデルファイル、グラフの画像ファイルを Google Drive 上にコピーします。
!mkdir "./drive/MyDrive/space/model"
!cp "./efficientnet_v2_m.pth" "./drive/MyDrive/space/model/"
!cp "./loss.png" "./drive/MyDrive/space/model/"
!cp "./accuracy.png" "./drive/MyDrive/space/model/"精度検証
トレーニングしたモデルの精度を確認します。
検証用関数の定義
精度検証用の関数を定義します。
def visualize_model(model, dataset, num_images=12):
model.eval()
images_so_far = 0
correct = 0
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders[dataset]):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for j in range(inputs.size()[0]):
if labels[j] == preds[j]:
correct += 1
images_so_far += 1
print(f"correct: {class_names[labels[j]]}")
print(f"predicted: {class_names[preds[j]]}")
imshow(inputs.cpu().data[j])
if images_so_far == num_images:
return correct / num_images各画像について、正解と予測のクラス名と画像を表示し、最後に正解率=精度を表示します。
評価データに対する検証
まず、評価データに対する精度を確認します。
全部の評価データを使うと表示が大変なので、先頭 12 件だけで実行してみます。
visualize_model(model, "validation")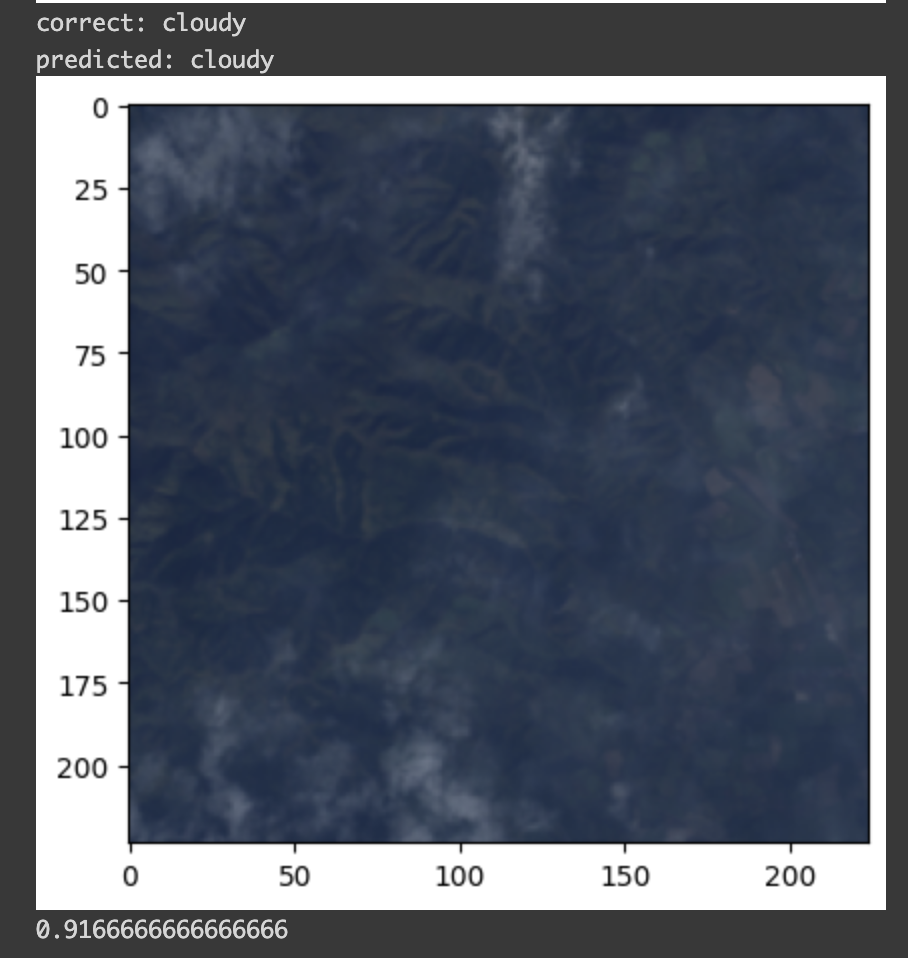
12枚の画像に対して予測が実行され、最後に 0.91666.. と精度が表示されました。
91.66 % なので、 12 枚中 1 枚が不正解になっています。
間違ったのは以下の1枚ですが、右下にうっすら雲があることを認識できず clear と分類してしまったようです。
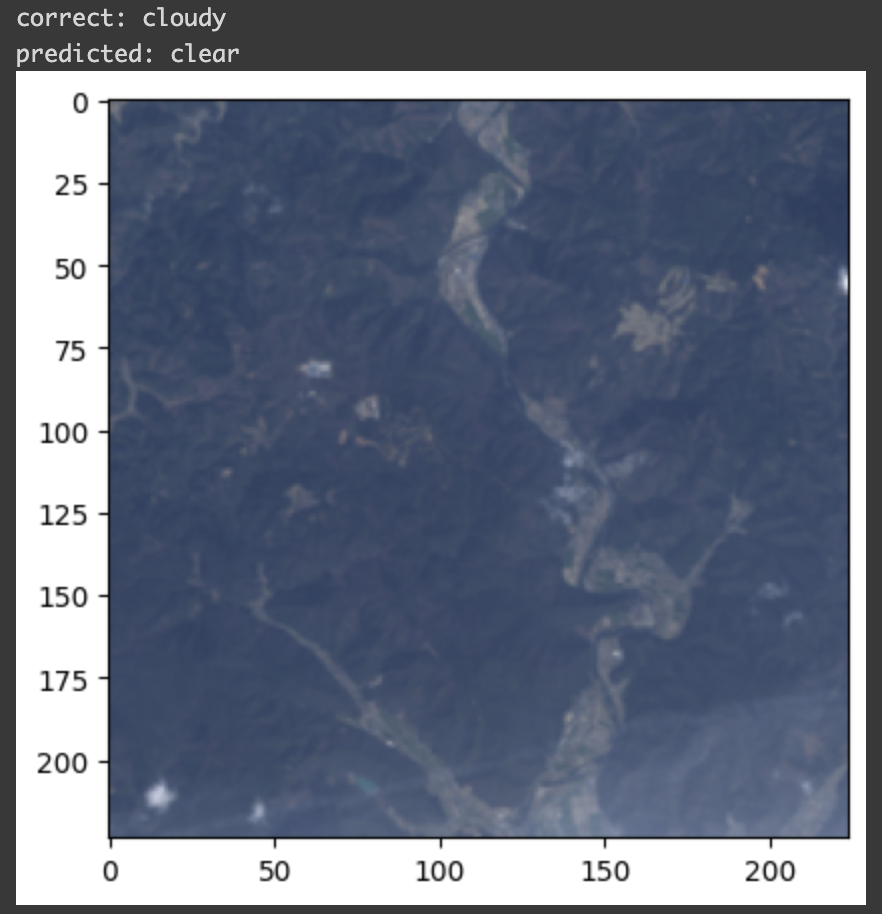
ちゃんと精度検証できていることが確認できました。
テスト用データに対する検証
テスト用データに対する検証をする前に、改めて保存したモデルファイルから精度を読み込んでみます。
まず、ニューラルネットワークの定義を `torch.models` から取得します(weights は指定しません)。
saved_model = models.efficientnet_v2_m()最初にやったのと同じように、出力層の形を4クラス分類用に変更します。
num_ftrs = saved_model.classifier[1].in_features
saved_model.classifier[1] = nn.Linear(num_ftrs, len(classes))保存したファイルからパラメータを読み込みます。
saved_model.load_state_dict(torch.load('efficientnet_v2_m.pth'))GPU を使うように設定します。
saved_model = saved_model.to(device)読み込んだモデルを使って、テスト用データ 100 枚に対して予測を実行します。
visualize_model(saved_model, "test", 100)100 枚中 79 枚正解で、精度は 79% でした。
ONNX 形式への変換
Elixir で画像分類を実行するため、モデルを ONNX 形式に変換します。
onnx_file = "efficientnet_v2_m.onnx"
dummy_img = torch.zeros(1, 3, 224, 224)
cpu_device = torch.device("cpu")
cpu_model = saved_model.to(cpu_device)
dummy_img.to(cpu_device)
torch.onnx.export(cpu_model, dummy_img, onnx_file, verbose=False, opset_version=12, input_names=['images'],
output_names=['predictions'],
dynamic_axes={'images': {0: 'batch_size'},})
onnx_model = onnx.load(onnx_file)
onnx.checker.check_model(onnx_model)以下のように結果が表示されます。
============= Diagnostic Run torch.onnx.export version 2.0.1+cu118 =============
verbose: False, log level: Level.ERROR
======================= 0 NONE 0 NOTE 0 WARNING 0 ERROR ========================変換結果も Google Drive にコピーしておきます。
!cp "./efficientnet_v2_m.onnx" "./drive/MyDrive/space/model/"これで Colab での操作は完了です。
まとめ
Kaggle のデータを使用して衛星画像分類モデルのトレーニングができました。
次はこのトレーニングしたモデルを使って、Elixirで並列分散推論します。
