【2025年1月】衛星データ利活用に関する論文とニュースをピックアップ!
2025年1月に公開された衛星データの利活用に関する論文の中でも宙畑編集部が気になったものをピックアップしました。
2025年1月に公開された衛星データの利活用に関する論文の中でも宙畑編集部が気になったものをピックアップしました。
・Forest fires under the lens: needleleaf index – a novel tool for satellite image analysis
(主に北米の針葉樹林帯を対象とした、Landsatシリーズの衛星画像から新規指標「Needleleaf Index」を用いた針葉樹林を抽出・モニタリングする手法)
・A comprehensive evaluation of deep vision transformers for road extraction from very-high-resolution satellite data
(衛星データ(非常に高い空間解像度:VHR)から道路を自動抽出するタスクに対する、Vision Transforme系のアーキテクチャ11種類の体系的比較・評価)
・A changing marine lightscape: Two decades of satellite data to map the global benthic mesophotic zone and explore trends of change
(PAR: Photosynthetically Active Radiation)の海洋内部への浸透度合いに着目し、地球規模で30 m以上の水深から光合成が正味で成立しなくなる直前の「中深層帯(メソフォティックゾーン)」がどこまで広がっているかを衛星データを用いて推定する手法)
・Estimation of internal displacement in Ukraine from satellite-based car detections
(熱帯山地林の森林タイプ別の遷移段階を、多様な衛星データ(Sentinel-1/Sentinel-2、InSAR、GEDI)と機械学習を組み合わせて分類する手法)
宙畑の連載「#MonthlySatDataNews」では、前月に公開された衛星データの利活用に関する論文やニュースをピックアップして紹介します。
実は、本記事を制作するために、これは!と思った論文やニュースをTwitter上で「#MonthlySatDataNews」「#衛星論文」をつけて備忘録として宙畑編集部メンバーが投稿していました。宙畑読者のみなさまも是非ご参加いただけますと幸いです。
2025年1月の「#MonthlySatDataNews」「#衛星論文」を投稿いただいたのはこの方でした!
Landscape diversity promotes landscape functioning in North America https://t.co/hWp0VBgoUp #衛星論文
景観多様性が一次生産性や生態系の安定性などの景観全体の機能に与える影響を調査— たなこう (@octobersky_031) January 17, 2025
それではさっそく2025年1月の論文を紹介します。
Forest fires under the lens: needleleaf index - a novel tool for satellite image analysis
【どういう論文?】
本論文は、主に北米の針葉樹林帯を対象として、Landsatシリーズの衛星画像から新規指標「Needleleaf Index」を用いて針葉樹林を抽出・モニタリングする手法を提案する
【技術や方法のポイントはどこ?】
◾️先行研究の課題
・NDVIやEVI、SAVIなどの一般的な植生指標では、針葉樹林と他の広葉樹・草地などを明確に分離しにくい
※EVI (Enhanced Vegetation Index): NDVIを改良した指標で、土壌や大気の影響を低減する特徴がある
※SAVI (Soil Adjusted Vegetation Index): 土壌の影響を補正する目的で提案された植生指標
・針葉樹林のみを詳細に把握した高解像度のグローバル/大域データセットが十分ではない
・気候変動による極端現象(山火事など)の影響把握が難しい
◾️データセット
①衛星画像
・Landsat 5, Landsat 7, Landsat 8–9の30m分解能データを利用
・夏季(6〜9月)の雲・雪覆率が10%以下のシーンを取得し、24,877枚を分析対象とした
②参照点(Reference Point)データセットの作成
・針葉樹とそれ以外の被覆を判別するための閾値決定、および精度検証に用いる
・Google Earth Proの高解像度画像(サブメートル〜5m級)を背景に、手動でサンプル点を配置
・MODIS land coverや航空写真、専門家の知見などを参照しつつ土地被覆クラスをラベリング
・10種類のクラス(針葉樹林、広葉樹林、水域、草地等)を設定し、期間ごとに合計13,719サンプルを作成
・なお、空間的なバイアスを減らすためランダム配置し、幅広い地形・植生タイプを網羅した
③Needleleaf Index (NI) の開発と算出
[基本式]
・NI=ρ NIR +ρ SWIR1 +ρ SWIR2
・Landsat 8–9の場合: NIOLI = B5(NIR) + B6(SWIR1) + B7(SWIR2)
[波長選定の理由]
・針葉樹は可視域(0.4〜0.7 µm)の反射が低く、NIR(0.85〜0.88 µm)〜SWIR(1.57〜2.29 µm)で他の植生に比べて比較的低い反射特性を示す
・水域はこれら赤外域での反射が極めて小さいか、ほぼゼロ
・NIは針葉樹を広葉樹や草地と分離しやすい帯域を単純加算することで実装
[閾値設定]
・NI値 0.15〜0.4 を針葉樹と判定(ただし水域をNDWI等でマスクした上で0.15〜0.4を使う)
・水マスクなしの場合は 0.2〜0.4 を採用し、混在画素を排除
[決定木による分類]
・Normalized Difference Water Index (NDWI)で水域を抽出し、非水域ピクセルのみを対象
・NI値に基づく閾値判定(0.15〜0.4)
【議論の内容・結果は?】
・水域と針葉樹林の混合画素(0.15〜0.2付近)や、針葉樹林と広葉樹林の混合画素(0.4〜0.45付近)が示されており、厳密な閾値選定が必要であることがわかる
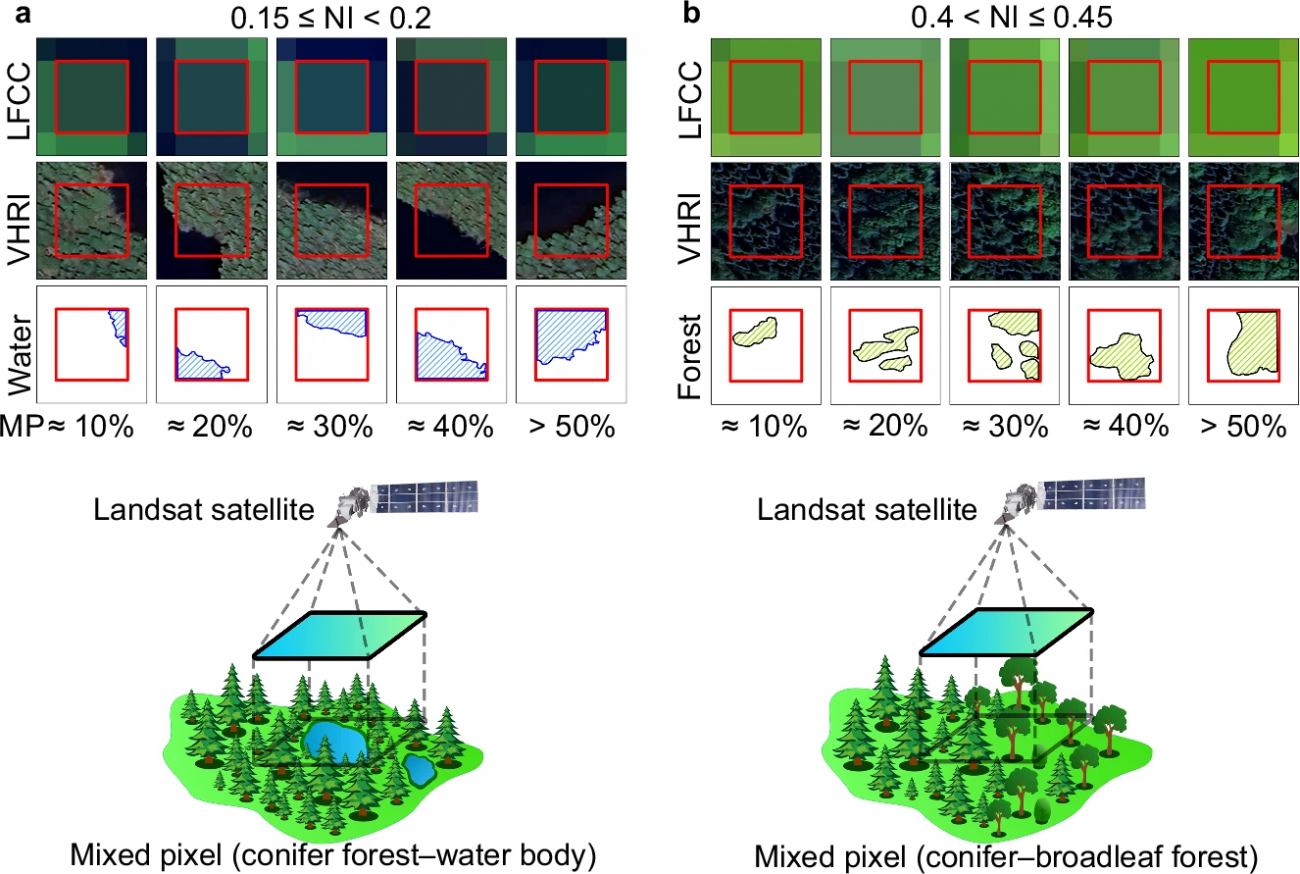
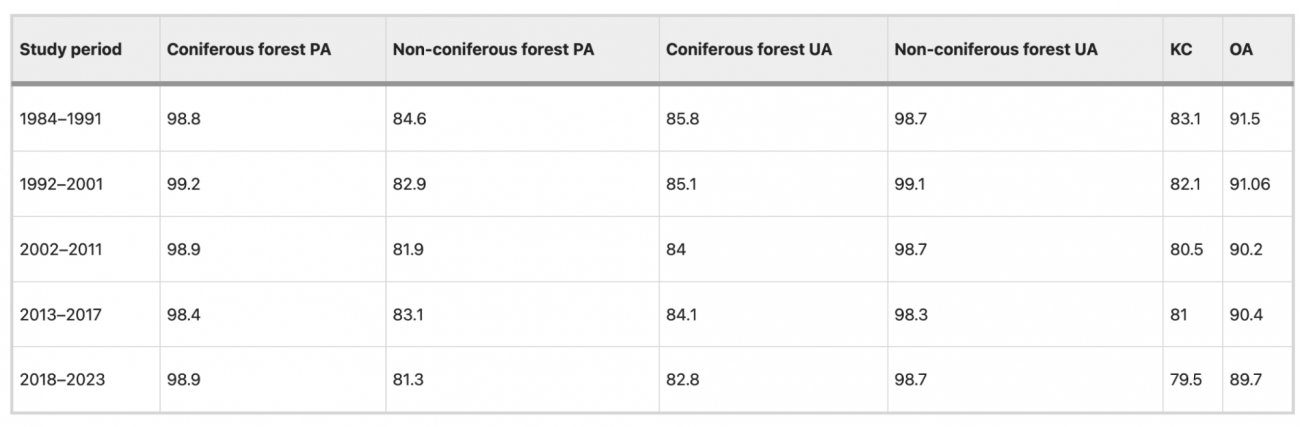
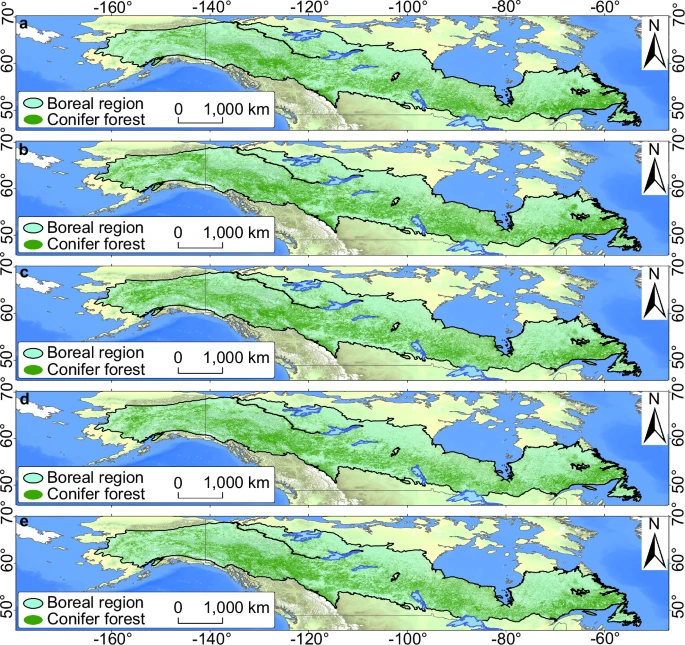
・北米域での針葉樹分布と州(道)の分布面積推移が可視化され、1984–2023年の5期間比較が行われた
・NI適用における各期間の全体精度(OA)は約89.7%〜91.5%、Kappa係数も最大83.1%を達成
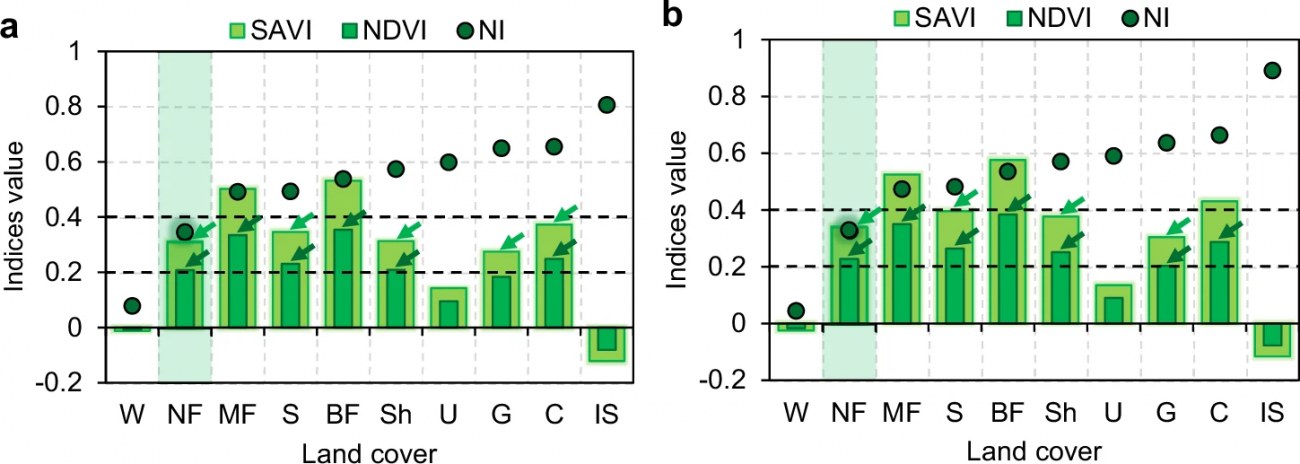
・NDVI・SAVI・NIの3つの指標を比較した
・NDVIやSAVIは針葉樹林の判別において他の植生と被りやすく、0.2〜0.4区間に草地・サバンナなどが入り込みがちである
・NIは水域や雪氷を除いて0.2〜0.4に針葉樹林が集約されやすく、より明確に分離できる
・NIのほうが針葉樹林検出には適性が高いが、一方で水域(NI<0.2)や山陰などの誤判定には注意が必要
#EVI #Landsat #MODIS #水域 #針葉樹 #広葉樹 #NDVI #SAVI #NI
A comprehensive evaluation of deep vision transformers for road extraction from very-high-resolution satellite data
【どういう論文?】
本論文は、衛星データ(非常に高い空間解像度:VHR)から道路を自動抽出するタスクに対し、Vision Transforme系のアーキテクチャ11種類を体系的に比較・評価する
【技術や方法のポイントはどこ?】
◾️先行研究の課題
・従来、道路抽出にはCNN系の手法が主流だったが、CNNは受容野のサイズの制限などから道路のように長大で多様な形状をもつ対象に対して、全体文脈を把握しづらいという難点があった
・Transformerベースのモデルも個別には研究されていたが、それらを包括的に評価し、どのモデルがどの程度の性能を発揮するか、複数都市・複数衛星による多様な条件下で比較した報告は限られていた
◾️本研究のアプローチ
・11種類のVision Transformerベースのセマンティックセグメンテーションモデルを以下の観点から一括比較する
– 各データセットでの精度 (mIoU, F-score)
– モデルのパラメータ数や推論速度
– モデルの深さ・構造と性能の関係
– 各種ハイパーパラメータ(学習率設定・最適化手法など)による影響
・街路・農村部・樹木影・建物影などが混在する複雑な環境に強いモデルを見極めるため、多様なデータセット条件下(都市・郊外・異なるセンサー)でテストを行う
◾️モデル
①Vision Transformer
・もともとは言語処理で使われていた「Transformer」の仕組みを画像に適用した手法
・画像を「パッチ(小さなブロック)」に切り分け、パッチ同士がお互いに情報をやり取りしながら特徴を学習する
・CNNはスポットライトを近くに当ててローカル(局所)をよく見るが、Vision Transformerは“俯瞰で広範囲を見る鳥のような目”を持ち、遠く離れた場所どうしの関連も捉えやすい
・道路は遠くまで連続していて、しかも途中で遮蔽物(建物、樹木など)に隠れることも多いが、Transformerベースなら「周囲の文脈情報」を遠方までつなぎ合わせ、道路同士を辿るように把握できる
②UperNet (Swin / Twins / MpViTの3つのバックボーン組み合わせバージョン)
・UperNet自体のイメージとしては、「地図を解像度の異なるレイヤーに分け、それぞれのレイヤーで特徴を取り出してから、最終的に重ね合わせてより正確な地図を描く」ようなアプローチ
・Swin Transformerは、ウィンドウを少しずつ動かしながら(Shifted Window)全域をカバーしていく仕組み
・Twins Transformerは、局所的注意と大域的注意を2種類のモジュールに分けて同時に処理する(「近くをくまなく見るカメラ」と「遠くを俯瞰するカメラ」でそれぞれ撮影して情報を合成するイメージ)
・MpViTは、複数の経路(パス)で特徴を捉え、畳み込み的な局所パターンとTransformer的な遠方パターンを合わせもつ(「小さな道と大きな道、両方から目標地点に向かうルートを探し出す」ような構造)
・強みとしては、UperNet自体がマルチスケールで情報を融合するため、広域的(遠く離れた道路区間)から局所的(道路の細部形状)までバランスよく捉えやすく、バックボーンの種類によって性能・計算コストを調整できる柔軟性がある
③Segmenter
・バックボーンとしてViTを使い、Encoder-Decoder型でセグメンテーションマスクを予測する
・イメージとしては、画像をパッチに分解(Encoder)、各パッチをまとめてクラス別の切り絵型テンプレート(Decoder)を用いて、“道路”というテンプレを当てはめる形である
・強みとしては、シンプルなViTモデルにマスク生成器をつなげただけなので構造がわかりやすい
・ただし、他モデルに比べると、細かい部分の再現が難しい場面もある
④DPT (Dense Prediction Transformer)
・「複数の解像度(スケール)」から得られた特徴を少しずつアップサンプリング(大きく)しながら最終的に高精細な予測を作る
・“密な予測”(Dense Prediction)という名前通り、ピクセルごとの情報を丁寧に再構築する
・強みとしては、スケールの異なる特徴を滑らかにつなぐため、複雑な地形や広域の道路が混ざっていても比較的表現しやすい
⑤SegFormer
・Mix Transformer (MiT)というバックボーンで効率的にマルチスケール特徴を取得する
・Decoder部は比較的軽量かつ単純構造で、推論速度が速い
・イメージとしては、大きな地図を4段階の拡大率で同時に見て、そこから合成して最終セグメントマップを作るという形である
・強みとしては、シンプルかつ軽量ながら、性能とスピードのバランスがよい(特に道路抽出でも高い評価)
⑥K-Net
・セグメンテーション対象のカーネル(フィルタ)が、入力画像を見ながら自分専用に成長していくイメージのモデルである
・強みとしては、物体(道路など)ごとに応じた特徴量フィルタが柔軟に学習されるので、複雑な形状にも対応しやすい
⑦Mask2Former
・バックボーンにSwinを採用し、Pixel Decoder + Transformer Decoderを連結した汎用型モデル
・画素レベルの下絵をまず用意し(ピクセルデコーダ)、そこに最終仕上げの色塗り(Transformerデコーダ)を施して完成図を作るイメージである
・強みとしては、一度に複数のセグメンテーション方式(オブジェクト単位やクラス単位)に展開でき、特に道路抽出など細かい分割にも比較的強い
⑧TopFormer
・Token Pyramidという仕組みを使い、少ないパラメータでマルチスケール特徴を取りにいくモデルであり、とても軽量で推論も速い
・細かいピースの集まりを、階層的にまとめてピラミッド状に管理し、少ない情報量で全体像を把握するようなイメージである
・モバイルや省リソース環境でも動かしやすいものの、その分細部の精度に問題がある
⑨UniFormer
・CNNのローカルな特徴抽出とTransformerのグローバルな文脈把握を同時に行うハイブリッドモデル
・拡大鏡(CNN)で近くを精密に見つつ、双眼鏡(Transformer)で遠方まで視野を広げる。2つの視点を合わせて最適な絵を描くイメージである
・強みとしては、ローカル部分(小さな道路の枝分かれや細部)と、大域部分(広範囲に連なった道路網)の両方を捉えられるところにある
・ただしモデルサイズ次第では、思ったより精度が伸びないケースも報告されている
⑩PoolFormer
・Self-Attentionの代わりにプーリング(Pooling)をトークン同士の結合(ミキシング)に使うという大胆な簡略化をしたモデルある
・重い計算を省略し、プーリングでざっくり情報を集約している
・強みとしては、Attentionを使わずに済むぶん計算が軽い・設計がシンプル、大規模データに対しても扱いやすい可能性がある
◾️データセット一覧
①DeepGlobe Road Extraction Dataset
・50 cm解像度のRGB画像、合計約6626枚の学習用画像
・建物影や多様な道路形態が含まれ、都市・郊外ともにカバー
②Massachusetts Road Dataset
・1m解像度の航空写真(RGB)で1500×1500ピクセル
③SpaceNet-3 Road Network Detection
・30 cm解像度の16-bit PS-RGB衛星画像で1500×1500ピクセル
・ラスベガス(980枚), 上海(1028枚), パリ(257枚), ハルツーム(283枚) の4都市を含む
【議論の内容・結果は?】
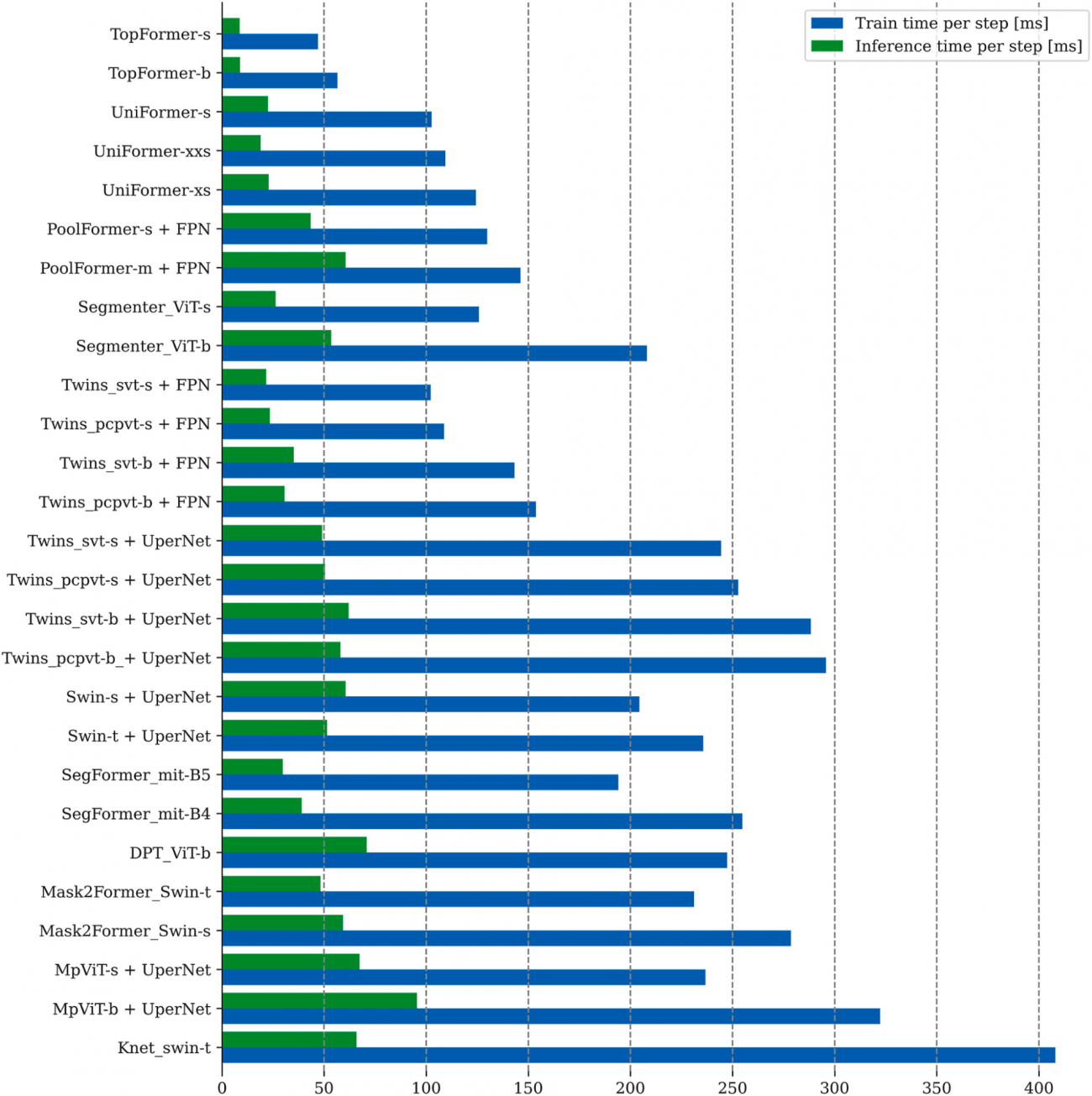
◾️学習時間・推論時間
・TopFormer, UniFormerは1ステップあたりの学習が47.03 ms (TopFormer), 56.50 ms (UniFormer)と高速、推論も8.7 ms / 8.8 msと非常に軽量
・K-Net (Swin-t), UperNet-Swin-t, UperNet-MpViT-bなどは200~400 ms/ステップ程度で訓練に時間がかかる
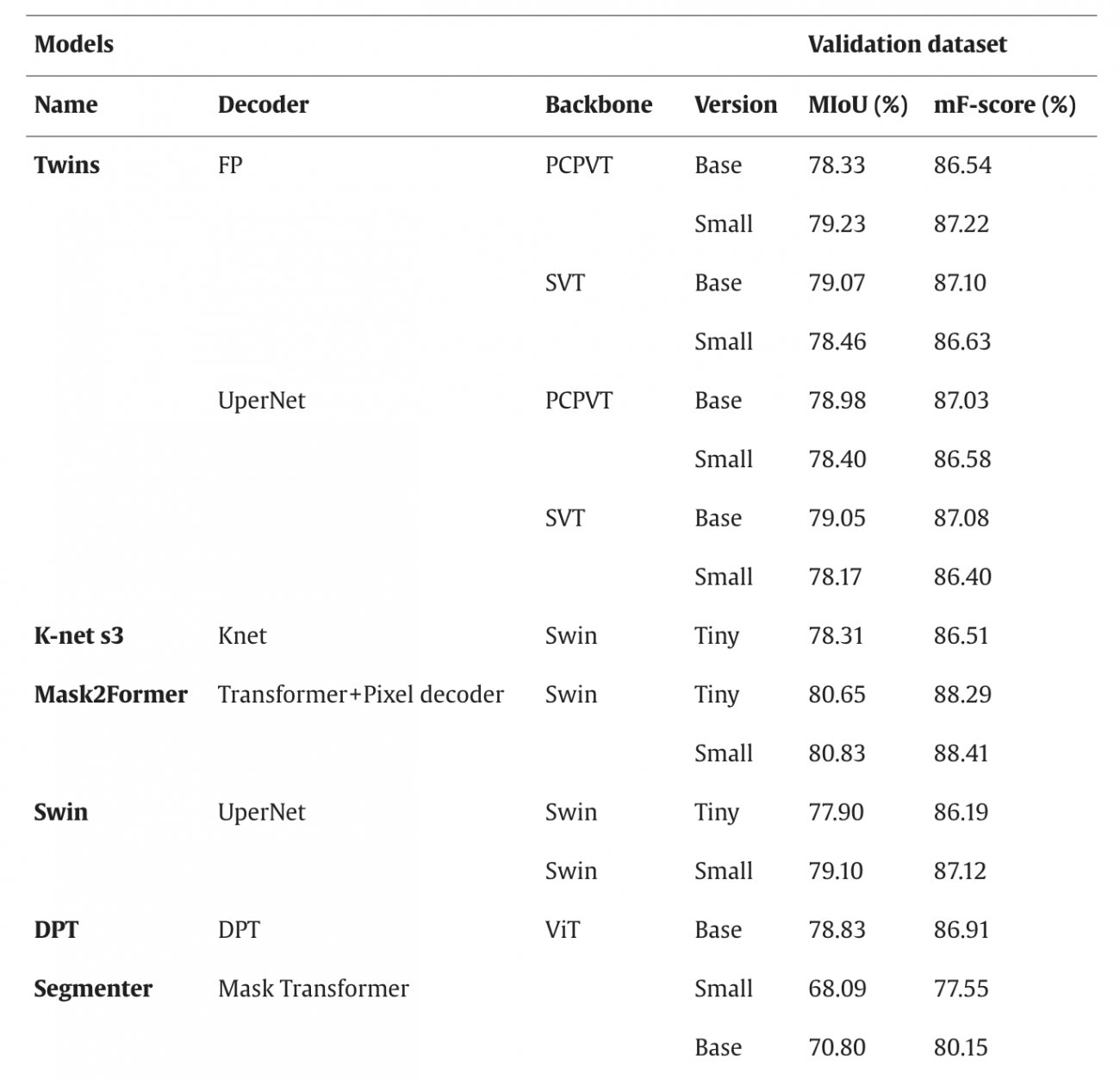
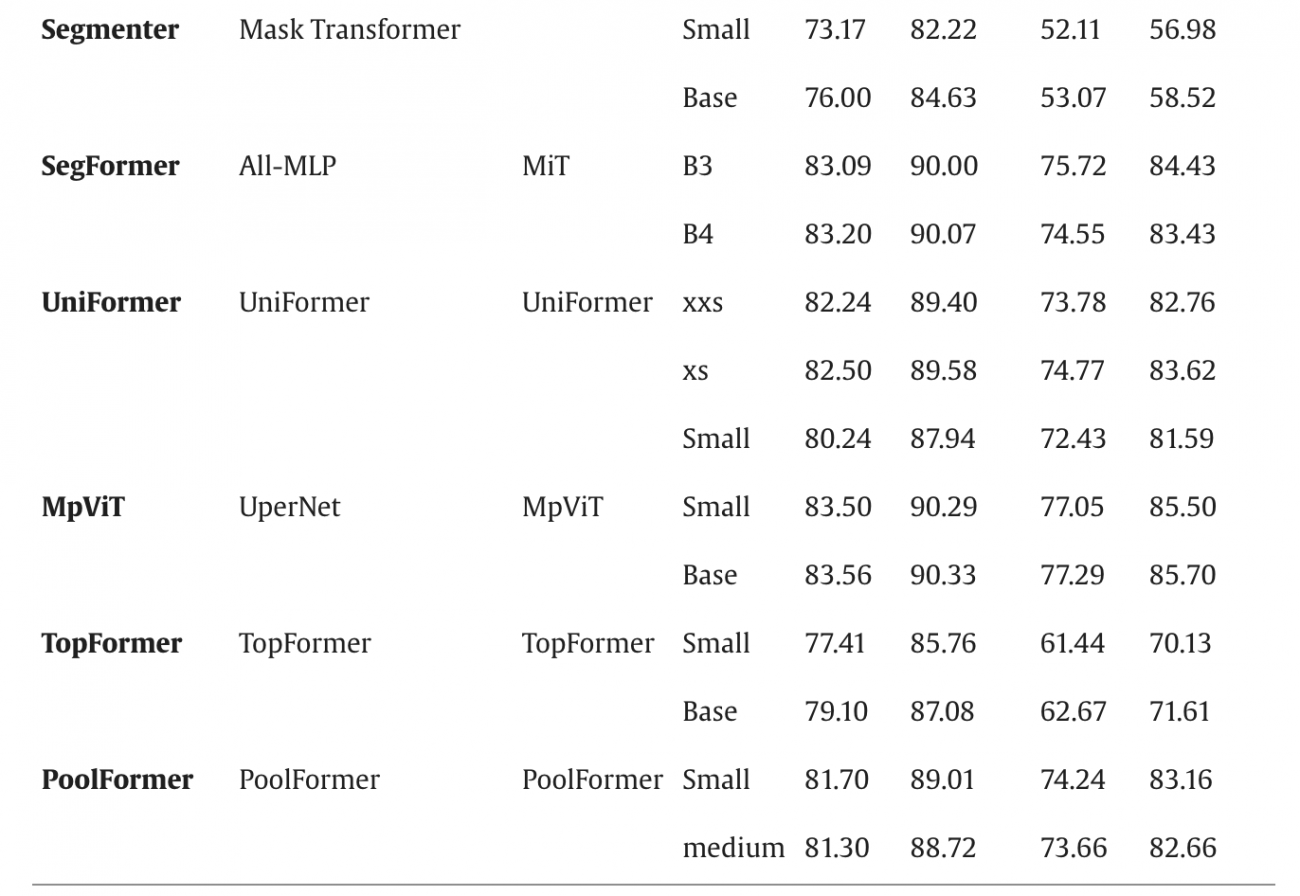
◾️評価データセットでの検証結果
・総合的にmIoUが68.09%~80.83%、mF-scoreが77.55%~88.41%まで分布
・トップ5 (mF-score基準)は以下の通り
– Mask2Former (Swin-small): 88.41%
– UperNet-MpViT-base : 87.89%
– Twins: 最高87.22%
– SegFormer-B4 : 87.33%
– UperNet-Swin-small: 87.12%
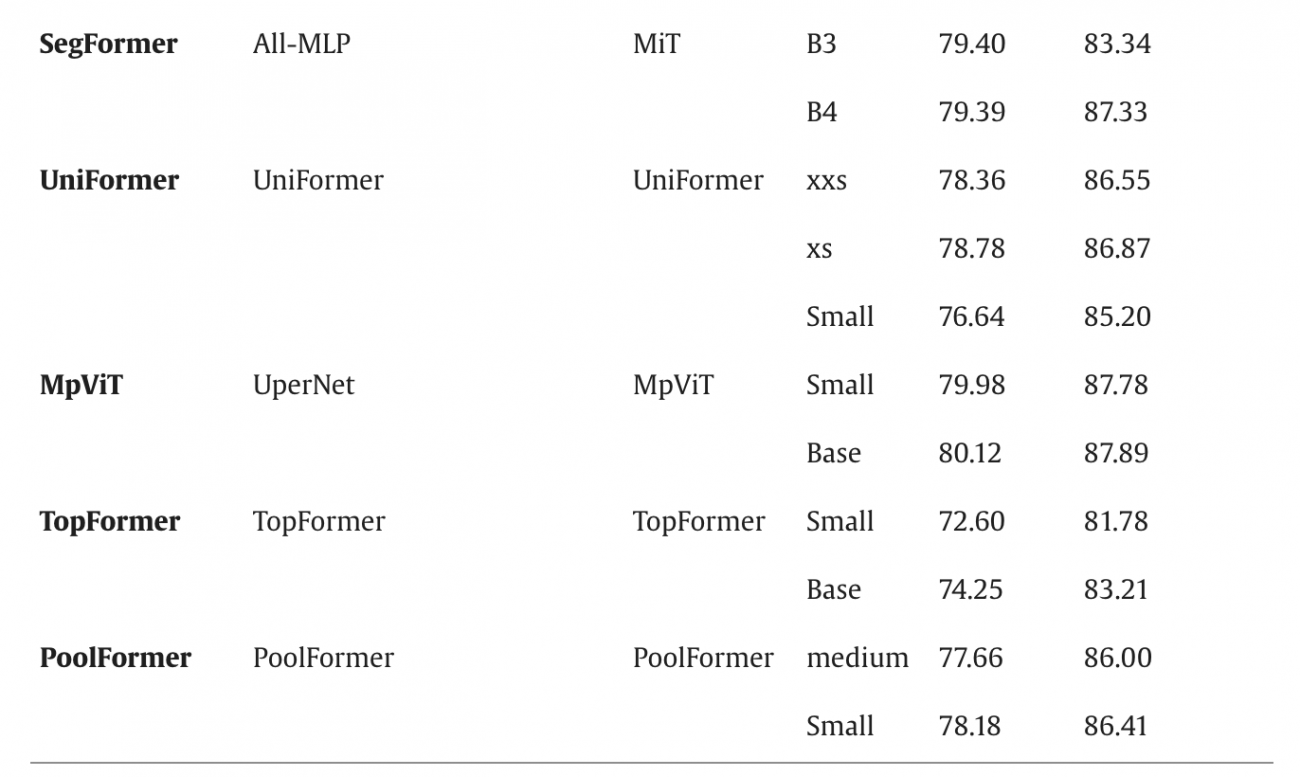
◾️推論時間と精度の関係性
・(a)(b)では「学習ステップ数に対するmIoU, mF-score」をバブルチャートで可視化
・バブルの大きさは学習所要時間(時間がかかるほど大きな点)となる
・学習時間が短いモデルはmIoU/mF-scoreがやや低めに収束する傾向がある
・一方、Mask2Former, MpViTなど学習時間は長めだが高精度だった
・(c)(d)では推論時間に対して同じ指標を比較したが、やはりTopFormer・UniFormerは推論が高速で、精度もある程度確保できる点がわかる
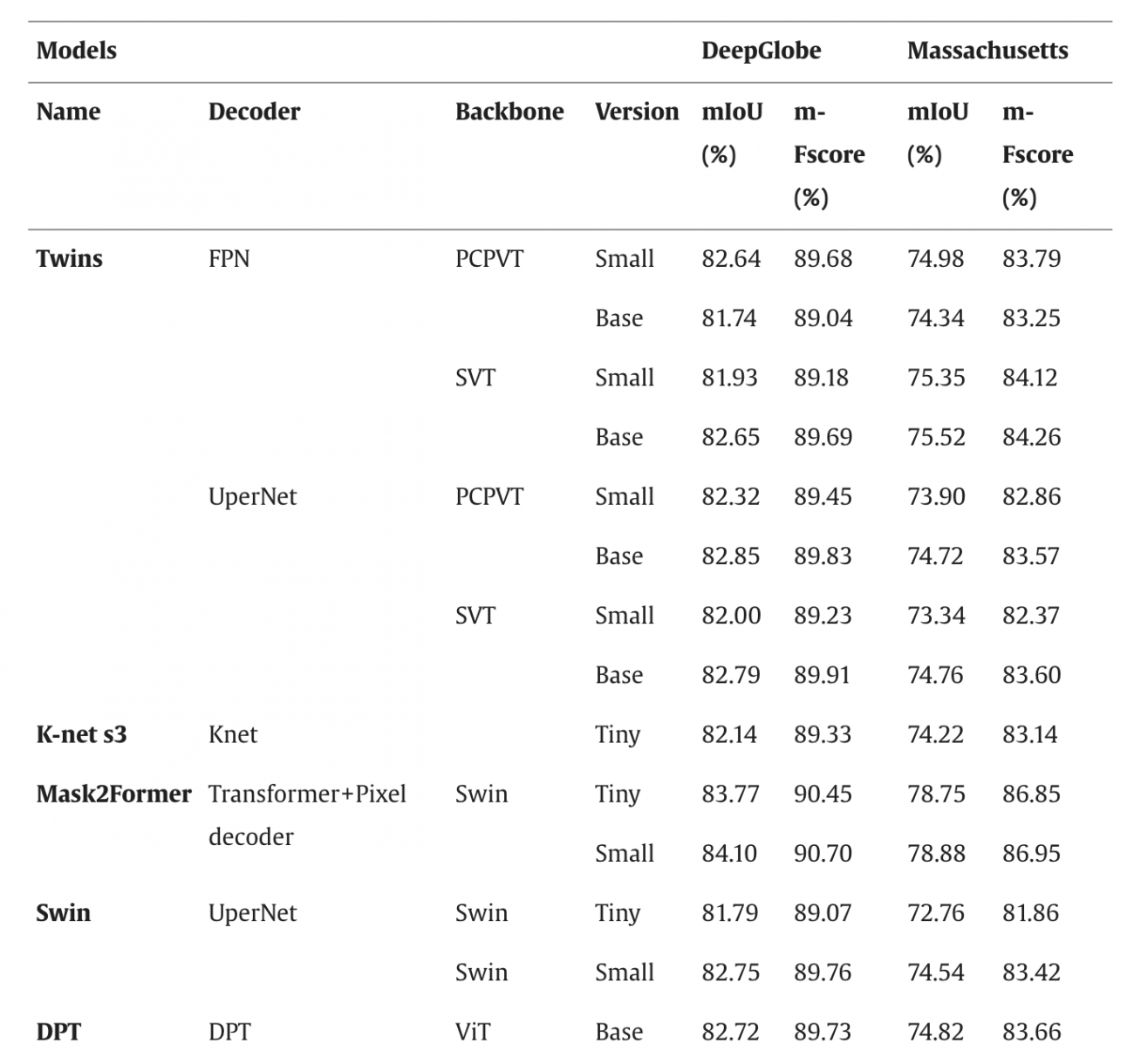
◾️テストデータセットでの検証
①DeepGlobe
・mIoUが73.17%~84.10%、mF-scoreが82.22%~90.70%の範囲
・最良モデルは、Mask2Former-Swin-smallの90.70%、UperNet-MpViT-baseの90.33%、SegFormer-B4の90.07%などとなる
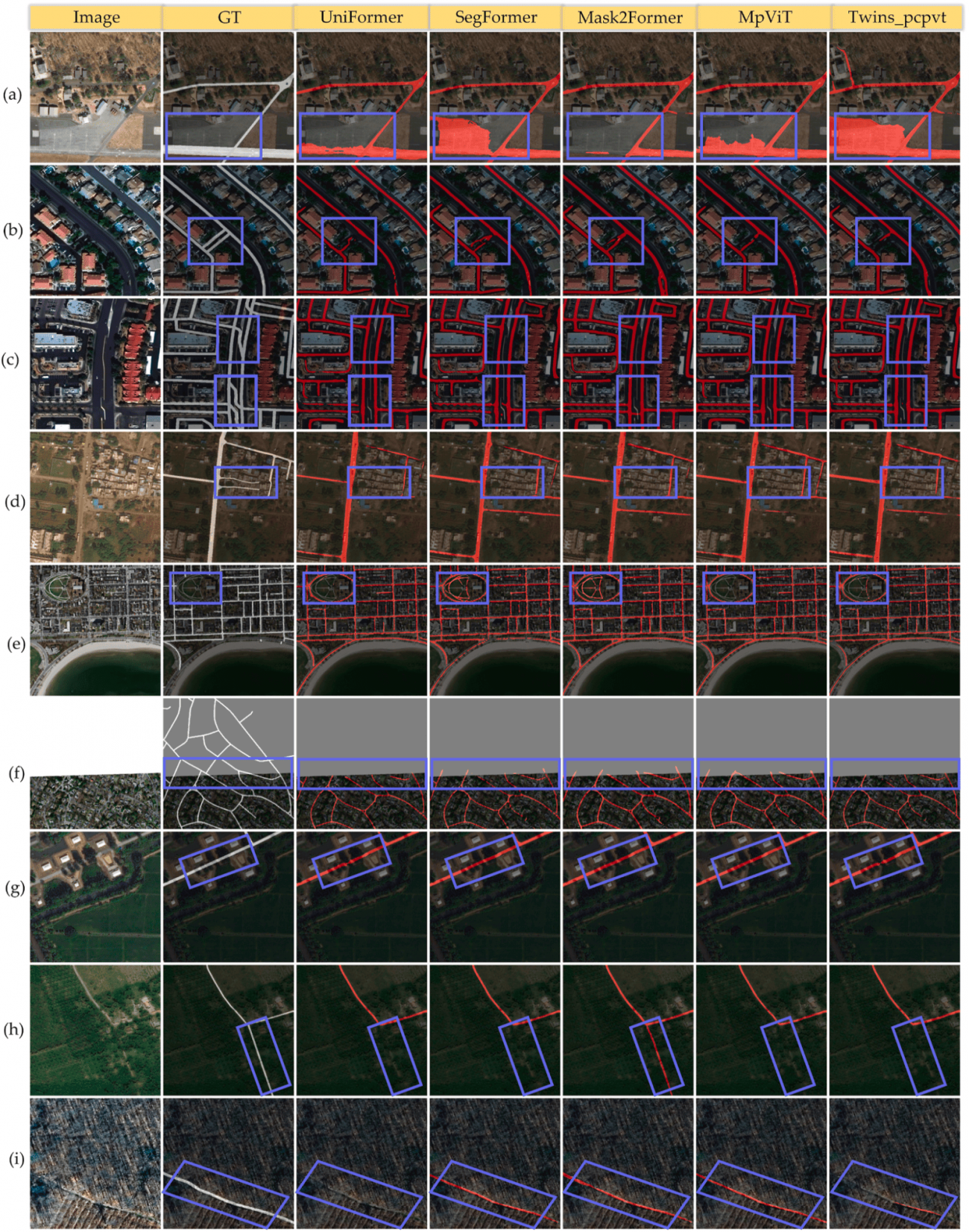
・図からわかるように、上位モデルほど道路の途切れなどを補完しやすく、ノイズが少ない推定マスクを生成している

②Massachusetts
・解像度が1mと粗めで細い道路の識別が難しいため、他データセットより精度が下がる傾向
・建物や樹木影、道路端の欠損などが可視化されている

③SpaceNet-3
・Mask2FormerやMpViT系が安定して上位
・上海やハルツーム(Khartoum)は雑多な地形・道路が混在し、精度が相対的に低めとなっている
・都市による特徴の違いとモデル推定マスクの比較が示され、高密度建築物や未舗装道路の表現にモデル間差がある

◾️難易度の高いケース
・駐車場やUターンを道路と誤認
・高層建築の影や樹木影により、道路の一部が誤検出
・歩道(公園内の遊歩道など) と車道を混同するケース
・マスク途切れ時の補完能力はMask2FormerやSegFormer, MpViTが強く、TwinsやUniFormerは影響を受けやすい場面もみられた
#道路抽出 #Vision Transformer #UperNet #Segmenter #DPT #SegFormer #K-Net #Mask2Former #TopFormer #UniFormer #PoolFormer #DeepGlobeRoadExtractionDataset #MassachusettsRoadDataset #SpaceNet-3RoadNetworkDetection
A changing marine lightscape: Two decades of satellite data to map the global benthic mesophotic zone and explore trends of change
【どういう論文?】
本論文は、太陽光(PAR: Photosynthetically Active Radiation)の海洋内部への浸透度合いに着目し、地球規模で30 m以上の水深から光合成が正味で成立しなくなる直前の「中深層帯(メソフォティックゾーン)」がどこまで広がっているかを衛星データを用いて推定する手法を提案する
【技術や方法のポイントはどこ?】
◾️先行研究の課題
・特定地域のみ、あるいは固定された水深帯(たとえば0~200 mなど)を一律に“光が届く範囲”と仮定してしまい、地域的に異なる水質や光減衰特性を考慮しきれていない
・長期的・時系列的に海底に到達する実際の光量(PAR)を推定した例は限られていた
・気候変動に伴い水温上昇や海洋酸性化だけでなく、光環境(海氷の融解や濁度の変化など)も大きく変動しているが、そのインパクトを定量的に把握した研究は不十分だった
◾️本研究のアプローチ
・衛星観測(MODIS)の月次PARデータとKd(490)(490 nmにおける拡散減衰係数)から実際に海底に到達するPARを19年間にわたり全球で推定
◾️技術的特徴
・光が水中を透過するときの減衰を単純化したビア・ランベルトの法則(Beer’s Law)を用いて計算
・Kd(PAR)は、主にKd(490)(490 nmにおける拡散減衰係数)からパラメータ変換(Morelらの手法)を用いて近似
・1年を北半球/南半球で季節をずらして4期に区切り(例:北半球の12~2月を冬、3~5月を春、など)、合計19年×4期(=76期)分のPARを推定することで季節性を考慮
【議論の内容・結果は?】
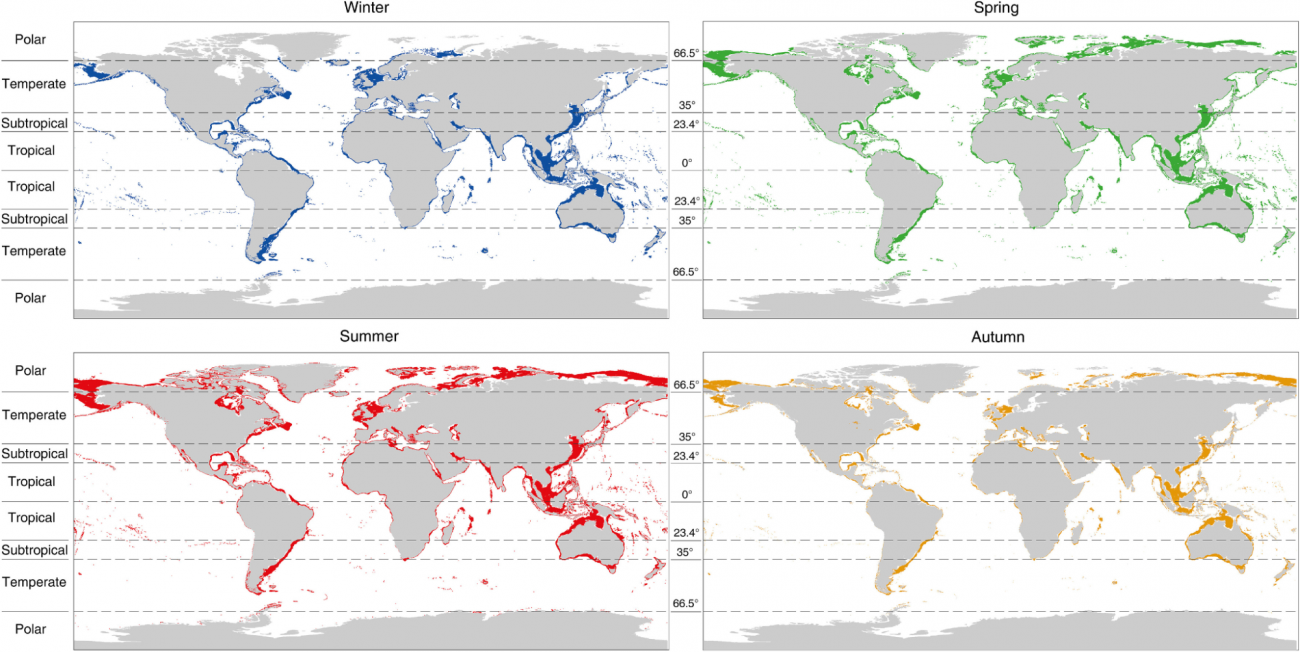
◾️メソフォティックゾーン面積の変化
・夏(北半球の6~8月、南半球nの12~2月)にメソフォティック領域が最も広がり、冬に最小
・とくに北極圏・南極圏で季節変動が顕著で、北極圏では冬0.84% → 夏14.70%と大幅に変化
・南極圏はそもそも年間平均が0.02 ± 0.01%と少なく、夏でも0.05%程度で極端に小さい
・温帯域や亜熱帯でも季節差はあるが、熱帯は通年で変動が小さい
・2003年~2021年の19年間に、北極・南極ともにメソフォティック域が有意に増加している
・ただし北極圏の春季のみ、逆にメソフォティック域が減少している
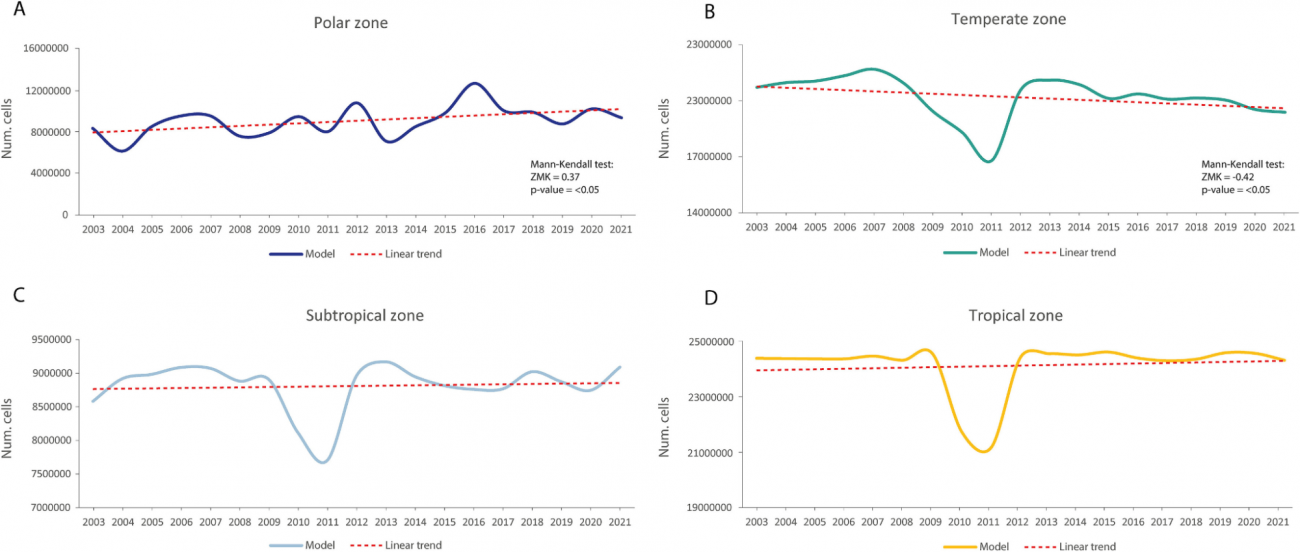
◾️海底に到達する光量(PAR)の長期変化
・北極圏は冬季に海底PARが減少(ZMK0)という複合的パターン
温帯域も全体としては有意な減少傾向(特に北半球)を示すが、春だけは増加という季節依存がみられる
・亜熱帯/熱帯は年間平均では有意な増減は見られない
・2010~2011年:極・温帯・亜熱帯・熱帯すべてで、メソフォティック域が縮小したりPAR値が急変したりする異常が見られる
◾️示唆
・北極・南極のメソフォティック域は面積自体は拡大するが、光量は減少する季節もある
・海氷減少などで海底まで光が届きやすくなる一方、雲量増や濁度変化によるPAR減少が考えられる(季節や年次の組み合わせで複雑に変化)

・温帯域では海底光の減衰が強まり、メソフォティック範囲が縮小する
・特に北半球温帯は春・秋の域が狭まり、PAR自体も冬は顕著に減少する
・近年の豪雨増加や表層の混合層深度変動などにより、濁度や吸収係数が高まっている可能性がある
#太陽光 #海洋内部 #メソフォティックゾーン #亜熱帯 #熱帯 #北極 #南極 #PAR #豪雨
Estimation of internal displacement in Ukraine from satellite-based car detections
【どういう論文?】
本論文は、熱帯山地林の森林タイプ別の遷移段階を、多様な衛星データ(Sentinel-1/Sentinel-2、InSAR、GEDI)と機械学習を組み合わせて分類する手法を提案する
【技術や方法のポイントはどこ?】
◾️先行研究の課題
①山地森林の複雑性
・熱帯山地林は標高勾配や急峻な地形のため、生態系の構造や種組成の変動が大きい
・低地林に比べ詳細な評価が困難
②林冠高計測の難しさ
・既存のLiDARやInSARは活用例は増えてきたが、山岳地帯ではデコリレーションやジオロケーションの誤差が大きく、精度低下が指摘される
※デコリレーションや・・・InSAR(干渉合成開口レーダ)の処理で、同じ場所を観測したはずの2つのSAR画像が互いに「似ていない」状態になることを指す
・ジオロケーション・・・衛星画像やLiDARなどで得られた画素や点群(3D座標など)に、正しい地理座標(緯度経度・標高など)を対応付けることであり、ジオロケーション誤差は、「衛星が捉えた画像や3次元データ(座標)と、実際の地表上の位置がずれてしまう」ことである
③多彩なデータの融合不足
・マルチスペクトラル・多種センサー(光学×レーダ×LiDARなど)の統合事例が限られている
◾️本研究のアプローチ
①マルチ衛星データと機械学習の統合
・Sentinel-1(レーダ)・Sentinel-2(光学)・GEDI(準LiDAR)・InSAR(干渉SAR)の複合入力を、ランダムフォレストモデルで解析
②新規データ活用
・NASAのGEDI計測データやInSARによる林冠高推定、またテクスチャ情報(GLCM)や標高・植生指数・LAIなど多様な指標を組み合わせる
※GEDI(Global Ecosystem Dynamics Investigation)・・・国際宇宙ステーション(ISS)に搭載されたLiDAR(レーザー光による高度計測)システム
③フィールドデータとGoogle Earthの併用
・実地調査172点+Google Earth由来182点の合計359点を学習用に利用
④カテゴリー分類
・森林の遷移段階を6区分(例:成熟段階のマツ林(MPF)、若齢段階のマツ林(YPF)、成熟段階の苔林(MMF)、若齢段階の苔林(YMF)、草地のマツ帯(GRP)、山頂草原(GRM))、および非森林(NFO)などに分類する
◾️分類モデル
・ランダムフォレスト分類器により、森林の遷移段階(6段階+非森林+欠損域)を推定する
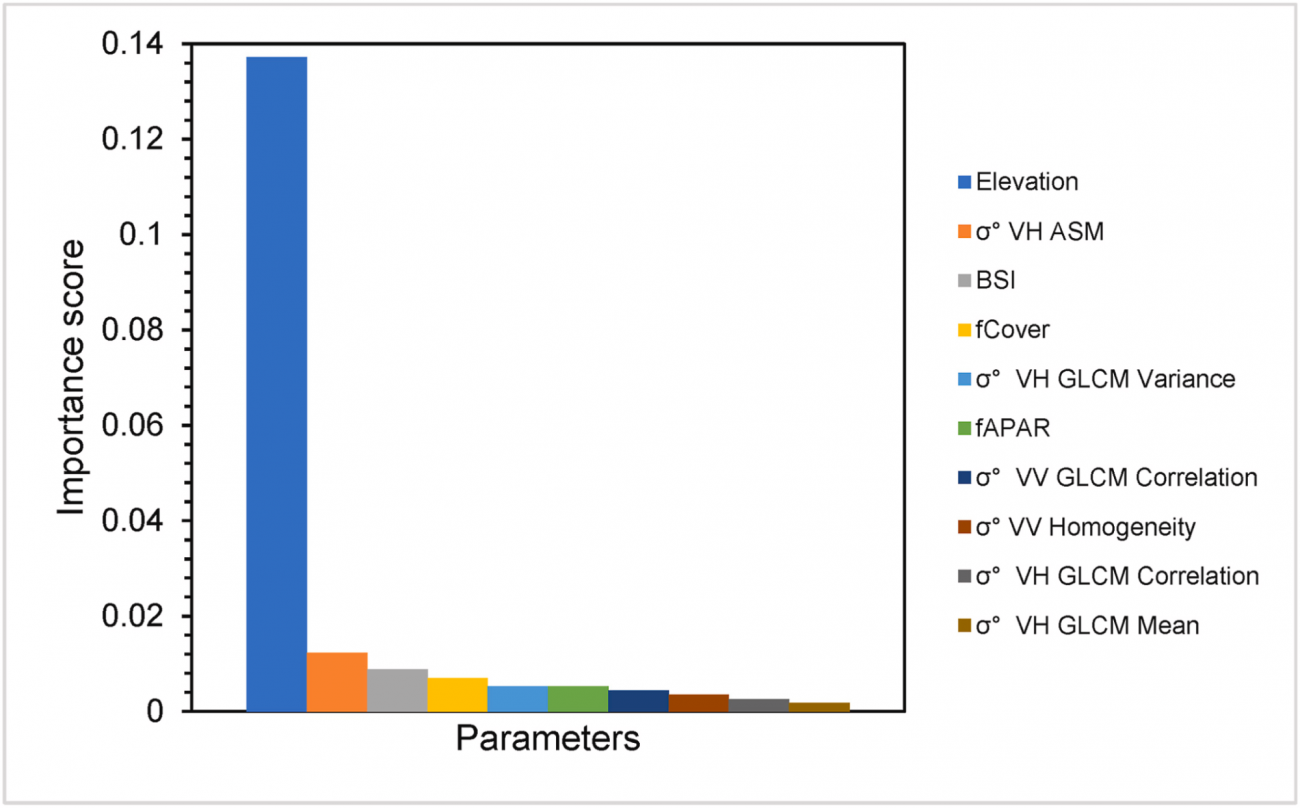
・特徴量として、 Sentinel-1(σ°VV/VH + GLCMテクスチャ9種類)、Sentinel-2のバンド&植生指数(NDVI/EVI/NDMI/BSI/NBR/OSAVI)、生物物理量(LAI/fAPAR/fCover/推定林冠高/標高)など計40以上を利用する
・GLCMテクスチャを、コントラスト、相互相関(correlation)、ASM、エネルギーなど多様な統計量を用いて計算する
※テクスチャ・・・画像を“質感”として見る際の数値的な特徴量で、グレーレベル共起行列(GLCM, Gray-Level Co-occurrence Matrix)という手法を用いて計算できる
【議論の内容・結果は?】
◾️分類モデルの精度
・Sentinel-1関連のみ → OA=53.79%, κ=44.61%
・Sentinel-2関連のみ → OA=67.64%, κ=61.59%
・Biophysical(標高やLAI, fAPAR, fCover, 林冠高)だけ → OA=65.78%, κ=56.03%
・全部組み合わせ → OA=79.56%, κ=75.74%

・トップ10の中で特に重要度が高いのは標高(72%)で、その次にSARテクスチャや土壌指標(BSI)、被度(fCover)、fAPARなどが続いた
・衛星画像の「表面のザラザラ感」や「粗度」を捉える指標が、若い森林か成熟林かの違いをある程度反映していると考えられる
・森林の垂直構造を直接見る(林冠高)よりも、山地林では標高・レーダテクスチャ・地表被度などのほうが区分精度に寄与する場合がある
◾️各ステージの推定結果
・MPF(成熟マツ林)が面積の40.38%で最大
・YMF/MMF(若齢/成熟苔林)やGRM(草地山頂)は合計でも10%未満

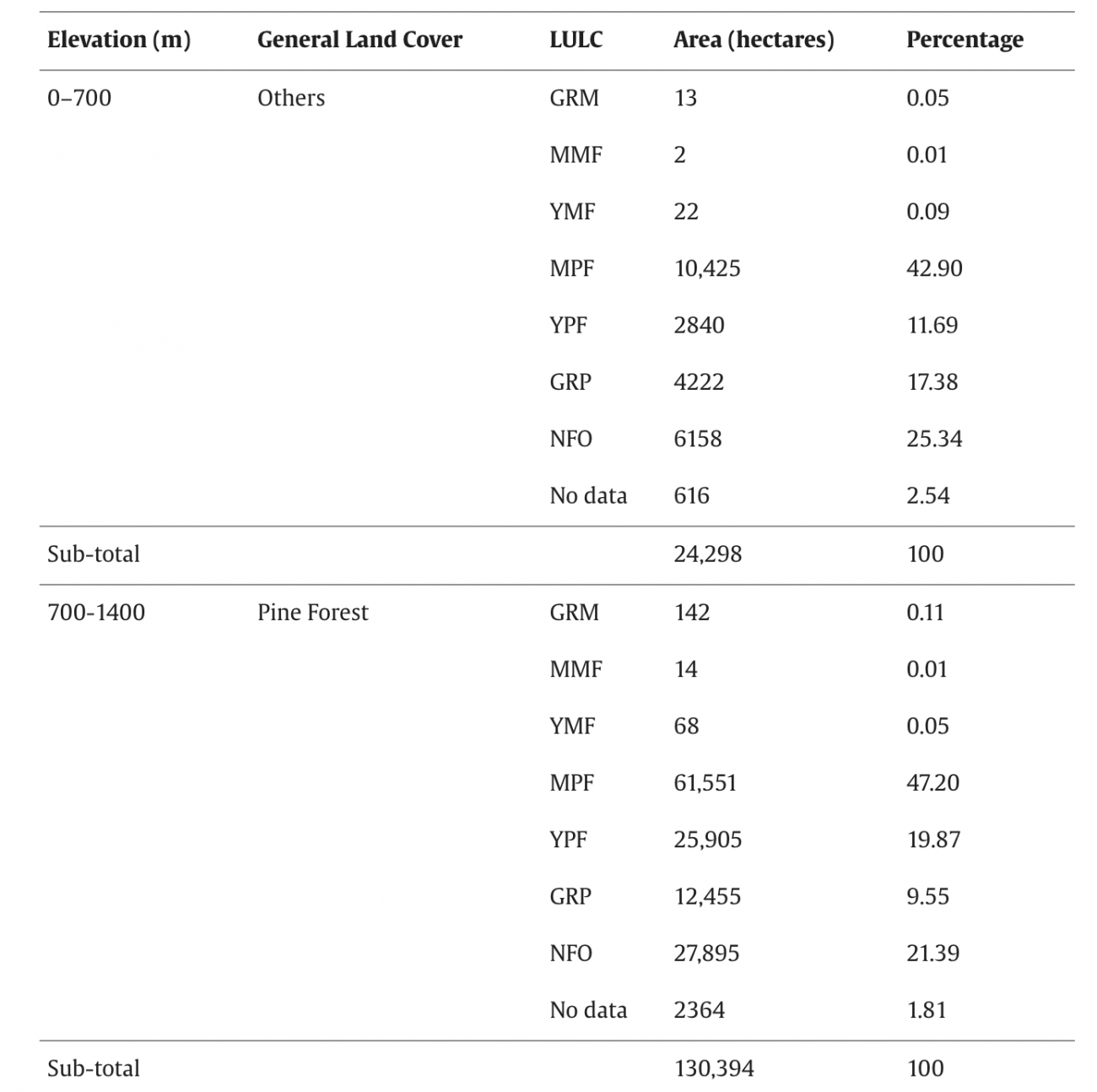
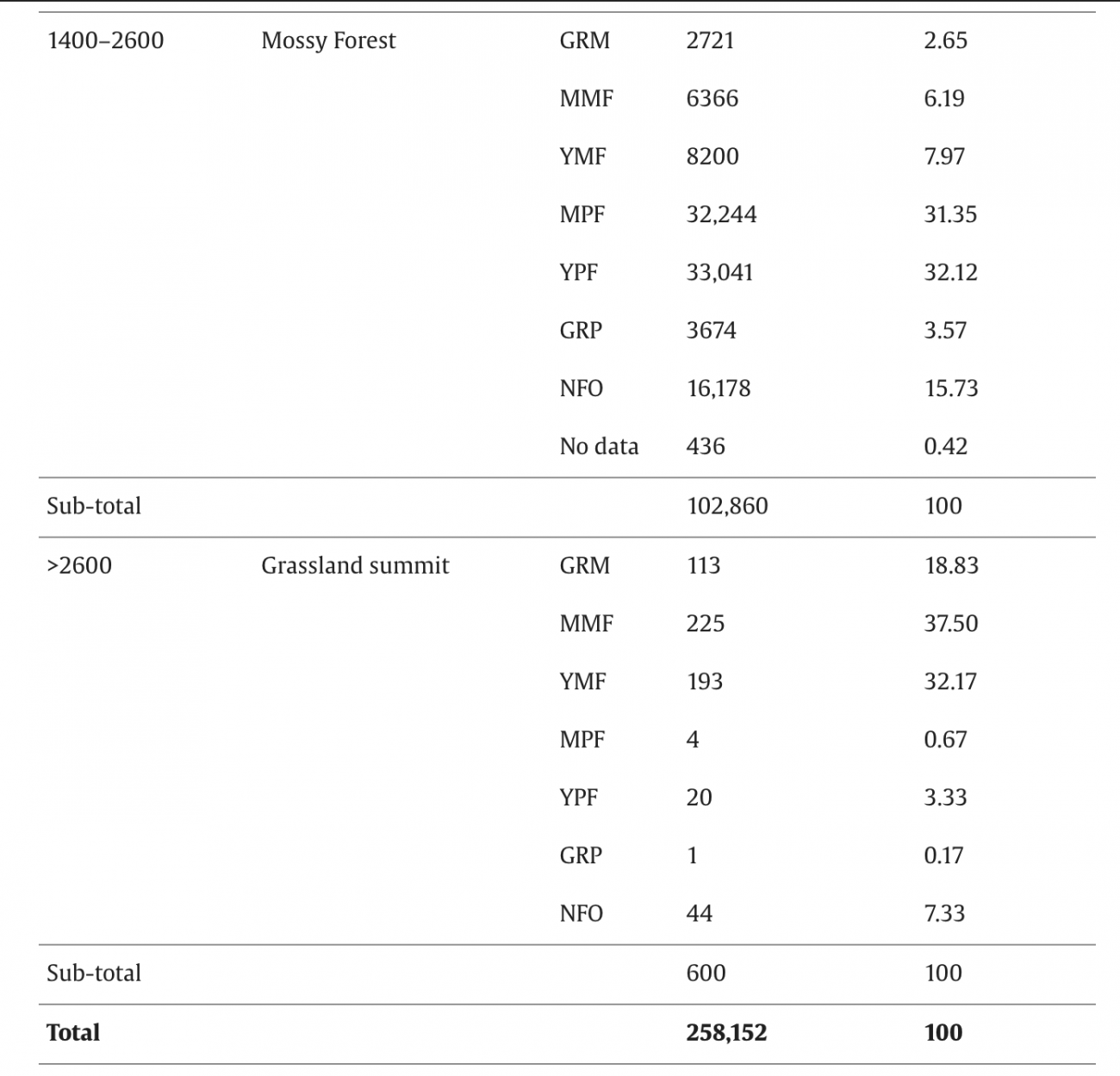
◾️標高ごとの各クラスのエリア面積
・0〜700m: MPF(42.90%)、GRP(17.38%)、NFO(25.34%) 、農業地や都市近接地が多い
・700〜1400m: MPF + YPF(約67%) 、中心的にマツ林帯
・1400〜2600m: MMF + YMF + GRM(合計17%)、MPFやYPFも約63%カバー、苔林とマツ林が混在
・標高が上がるにつれて苔林・草地が優勢という熱帯山地林特有の垂直分布パターンがマップに明確に示された
#森林タイプ #InSAR #GEDI #ランダムフォレス #NDVI #EVI #NDMI #BSI #NBR #OSAVI #LAI #fAPAR #fCover #推定林冠高 #Sentinel #土壌指標 #fAPAR #森林 #苔林 #草地 #熱帯山地林
来月以降も「#MonthlySatDataNews」「#衛星論文」を続けていきますので、お楽しみに!
