【2023年9月】衛星データ利活用に関する論文とニュースをピックアップ!
2023年9月に公開された衛星データの利活用に関する論文の中でも宙畑編集部が気になったものをピックアップしました。
宙畑の新連載「#MonthlySatDataNews」では、前月に公開された衛星データの利活用に関する論文やニュースをピックアップして紹介します。
実は、本記事を制作するために、これは!と思った論文やニュースをTwitter上で「#MonthlySatDataNews」をつけて備忘録として宙畑編集部メンバーが投稿していました。宙畑読者のみなさまも是非ご参加いただけますと幸いです。
2023年9月の「#MonthlySatDataNews」を投稿いただいたのは4人でした!
Landsat衛星画像を用いた都市のヒートアイランド(UHI)検出と解析をした論文。
UHIの検出では影響が大きい裸地の土壌の影響を考慮。
また、解析では市街化によりUHIの範囲が拡大し、高い建物が多いほど強度が増加する傾向にあることを検証。#MonthlySatDataNewshttps://t.co/Ldwi6qBKON— ぴっかりん (@ra0kley) August 30, 2023
DDPM を利用したリモセン画像の超解像#MonthlySatDataNewshttps://t.co/r4O0WIxmgX
— emmyeil (@emmyeil) September 28, 2023
LAION-5Bの衛星版データセット。
CC-BY 4.0でhuggingfaceに公開されている#MonthlySatDataNewshttps://t.co/IJG5SgPnZa
— まぬある (@lTlanual) September 28, 2023
Flood Extent and Volume Estimation Using Remote Sensing Data https://t.co/cDRHM8DJ5H #mdpiremotesensing @RemoteSens_MDPIより #MonthlySatDataNews
Sentinel-1,Sentinel-2,およびDEMを用いて洪水の浸水深を推定— たなこう (@octobersky_031) September 12, 2023
それではさっそく2023年9月の論文を紹介します。
Remote Sensing Object Detection Meets Deep Learning: A Meta-review of Challenges and Advances
【どういう論文?】
・深層学習ベースの衛星画像による物体検出手法の最近の成果を包括的にレビューした論文
【物体検出の課題】
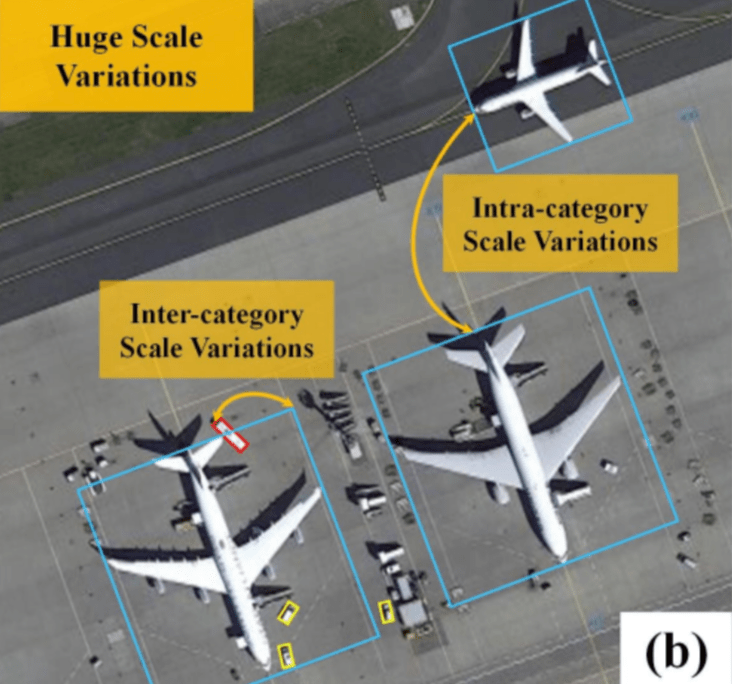
■ スケールバリエーション問題
・同じカテゴリーでも異なるオブジェクト間には非常に大きなスケールの変動がある
・例えば、車両は10ピクセルの面積ほどの小さい場合もあれば、飛行機などの車両のように200ピクセルよりも大きい場合がある
・したがって、物体検出モデルは大規模なオブジェクトと小規模なオブジェクトの両方を処理できる必要がある
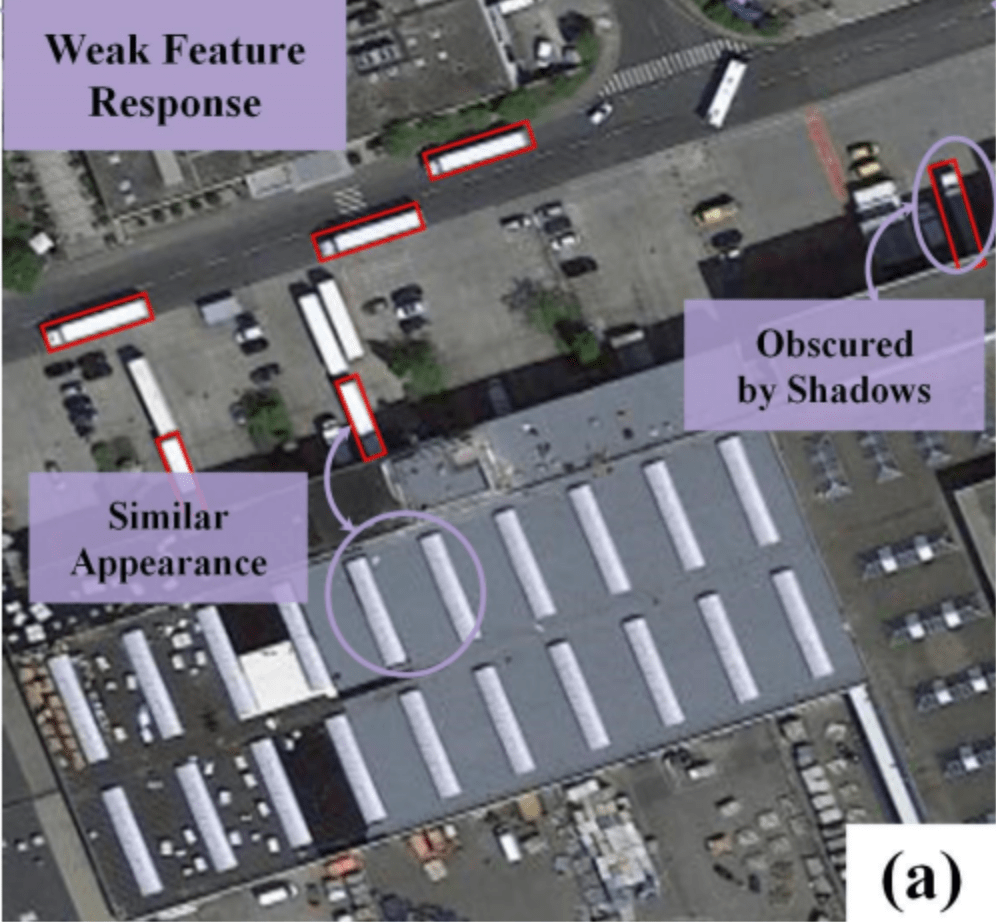
■ 微弱な特徴問題
・衛星画像には複雑なコンテキストや大量の背景ノイズが含まれている
・一部の車両は影によって隠れており、周囲の背景ノイズは車両と類似した外観を持つことがある
・この複雑な干渉(ノイズなど)は、分析対象であるオブジェクトの特徴表現を劣化させる可能性がある
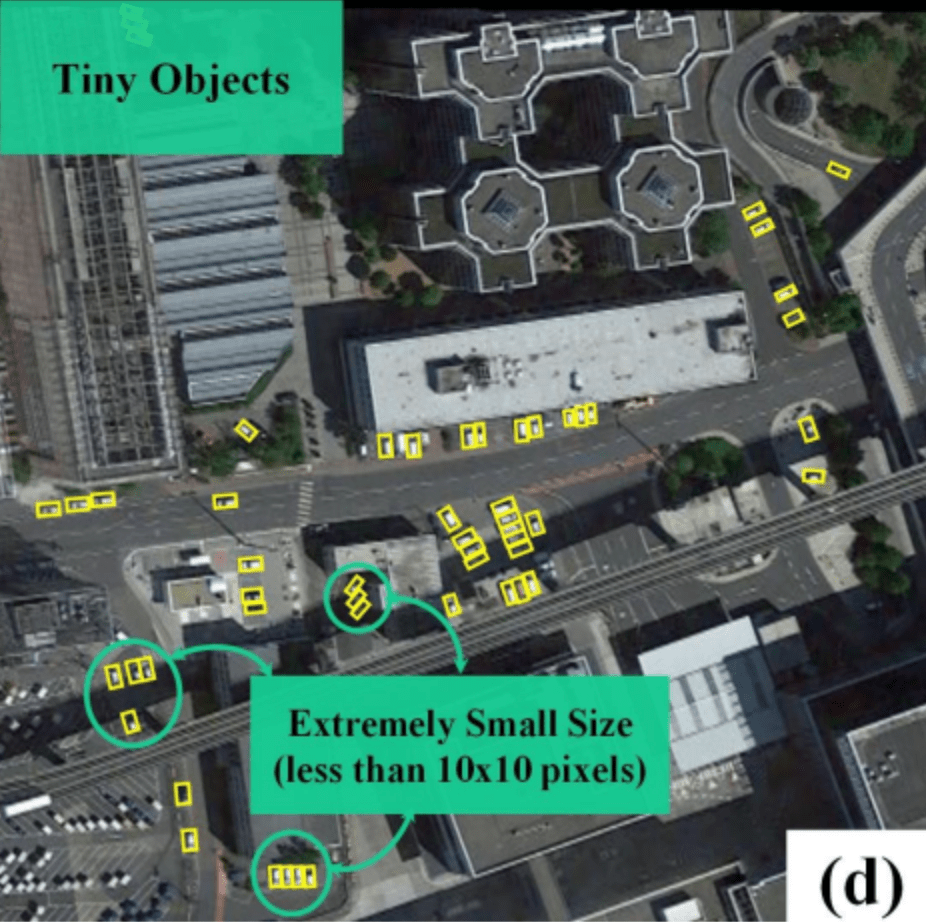
■ 小さなオブジェクト問題
・小さなオブジェクトはわずかな外観情報のみを示す傾向があり、その結果、特徴表現の品質が低くなることがある
・さらに、現在主流の検出方法は、小さなオブジェクトの表現を不適切に処理したり、(畳み込みなどの過程で)完全にその特徴を取り除いてしまうことがある
■ 高コストなアノテーション問題
・オブジェクトはスケールや角度の観点から複雑な特性を持っており、また、詳細かつ正しいアノテーション作業には専門的な知識が必要である
・現在の深層学習ベースの検出器は、性能の向上を第一優先とするために正確かつ豊富な既存のラベル付きデータに大きく依存している
【解決策の全体像】
・マルチスケールオブジェクト検出
・回転オブジェクト検出
・微弱なオブジェクト検出
・小さなオブジェクト検出
・限られた条件下でのオブジェクト検出
【マルチスケールオブジェクト検出】
主に以下の3つの分野での研究が進んでいる
1. データ拡張
・画像スケーリング
-異なるスケールのオブジェクトを含む画像を生成するための効果的なデータ拡張手法(例えば、同じオブジェクトが異なるスケールで写っている画像を作成できる)
・画像ピラミッド
-複数のスケールでの画像を生成し、それらの画像から得られた特徴を融合してマルチスケール特徴表 現を生成する
・軽量な画像ピラミッドモジュール(LIPM)
-画像ピラミッドを使用すると検出性能は向上するが、推論時間と計算の複雑さが増加するため、軽量な画像ピラミッドモジュール(LIPM)を利用する場合がある
-LIPMは、元の画像を異なる解像度にダウンサンプリングした複数のバージョンを生成する。これらのダウンサンプリング画像は、異なるスケールの情報を保持しており、対象オブジェクトの異なるレベルの詳細な特徴を捉えるのに役立つ
・各ダウンサンプリング画像に対して、バックボーンネットワークを使用して特徴マップが生成する
-これらの特徴マップは、バックボーンネットワークの畳み込み層やプーリング層を通過して抽出され、画像内の異なるスケールでの情報を表現する(各画像の特徴マップは、それぞれ異なる解像度とスケールの情報を持つ)
・ダウンサンプリング画像から生成された各特徴マップは、対応するスケールの特徴マップと統合する
・最新のデータ拡張方法
-MosciaおよびStitcherなど(特に小さなオブジェクトに対するマルチスケール物体検出において優れた効果を示している)
2. マルチスケール特徴表現
・マルチスケール特徴統合
-特徴は深いレイヤー(車の詳細な外観情報など)と浅いレイヤー(車の一般的な外観パターンなど)で異なる性質を持っているため、これらの特徴を統合して、オブジェクトの位置情報とカテゴリ情報を含む → → マルチスケールの特徴マップを生成し、オブジェクト検出を行う
マルチスケール特徴統合は、畳み込みニューラルネットワーク(CNN)内の異なるレイヤーからの特徴を統合し、単一の特徴マップ上で検出を行う
・ピラミッド特徴階層
-小さなオブジェクトは深いレイヤーに、大きなオブジェクトは浅いレイヤーに現れやすいと考えられるため、複数のレイヤーの特徴を独立して使用して、広範なスケールのオブジェクトを検出する
-SSD(Single Shot MultiBox Detector)などが手法として挙げられる
・特徴ピラミッドネットワーク
-低レイヤーのセマンティック情報をトップダウンのパスで深いレイヤーの特徴に伝え、各レベルでリッチなセマンティック特徴を生成することで、深いレイヤーでもセマンティック分類を可能とする
・非対称特徴ピラミッドネットワーク:
-非対称特徴ピラミッドネットワーク(AFPN)は、大きなアスペクト比を持つオブジェクトに対する性能を向上させるため、非対称な畳み込みブロックを採用
・ラプラシアン特徴ピラミッドネットワーク:
-高周波情報をマルチスケールピラミッド特徴表現に統合し、正確なオブジェクト検出を可能とする
3. マルチスケールアンカー生成
・追加のアンカーの導入
-一部の研究では、通常の物体検出のアンカー設定に追加のスケールやアスペクト比のアンカーを導入し、マルチスケールオブジェクト検出を向上させている
・統計情報に基づくアンカースケールの設計
-他の研究では、トレーニングセット内のオブジェクトスケールの統計情報に基づいて、より適切なアンカースケールを設計している
・アスペクト比の柔軟な表現
-より柔軟性が高いアスペクト比を提供するために、垂直、正方形、水平のアスペクト比を組み合わせる方法も提案されている
・ダイナミックなアンカー学習:
-一部の最新の研究では、トレーニングフェーズ中にアンカーの学習を試みている
-カテゴリごとにアスペクト比を適応的に学習する方法や、アンカーの位置と形状情報を適応的に学習する軽量サブネットワークの導入などが行われている
【回転オブジェクト検出】
主に以下の2つの分野での研究が進んでいる
1. 回転したオブジェクトの表現
・五つのパラメータ表現
-最も一般的な方法は、(x、y、w、h、θ)の五つのパラメータを使用してオブジェクトを表現する方法である
・八つのパラメータ表現
-四つの頂点{(ax, ay),(bx, by),(cx, cy),(dx, dy)}を直接予測する方法となっており頂点の順序が重要である
・角度分類表現
-回転角度の(連続的な)予測に代わり、角度の予測を角度のクラス分類課題に変換する方法で、モデルトレーニングが簡素化されるというメリットがある
・ガウシアン分布表現
-ガウシアン分布を使用して回転したオブジェクトを表現する方法で、ガウシアン分布表現は、角度の境界問題を解決し、IoUの評価を改善しやすい
2. 回転に対する不変性の特徴学習
・回転に対する不変性の学習
-回転に対して不変な特徴を使用してオブジェクトを正確に認識するための最初の回転不変オブジェクト検出器を使用
・回転不変性と識別性の学習
-回転不変性と識別性(物体を他の物体と区別できる性質)の両方を学習するた←「め」の脱字?
・Fourier領域での極座標に基づく分析
-Fourier領域(信号や画像を異なる周波数成分に分解する数学的手法で)でオブジェクトの回転不変性を分析するための空間周波数(画像内のパターンや変化が空間内でどのくらい頻繁に現れるかを表す)のチャンネル特徴抽出モジュールを設計
・オブジェクトの向き情報を学習
-回転したオブジェクトと畳み込み特徴との不一致に対応するため、向き情報を学習するための新しいアラインメント畳み込み操作を採用した向き検出モジュールを使用
・回転等価性と不変性を明示的にエンコード
-回転等価性(オブジェクトをある角度だけ回転させた場合でも、その性質や特性が変わらないこと)と不変性を明示的にエンコードする回転等価検出器を使用
・事前定義された回転アンカー
-オブジェクトの任意の向き特性に対処するために、事前定義された回転アンカーの一連を使用
【微弱なオブジェクト検出】
主に以下の2つの分野で研究が進んでいる
1. 背景ノイズの抑制
・暗黙の学習
-モジュールを設計して、トレーニング中に重要な特徴を適応的に学習し、冗長な特徴を抑制することで、背景ノイズの干渉を減少させることを目指す
-次元削減やアテンションメカニズムなどが手法として挙げられる
-この方法では対象物体の特徴を強調することで背景情報を弱めることができる
・明示的な学習
-画像内のどの部分が視覚的に注目に値するかを示す特別なマップを作成する
-または、対象物体に関する情報を別途取得して特別にデータを作成し、アノテーション情報をより詳細な情報に変換する
-この方法では対象物体を特徴マップ上でより強調することで、背景に埋もれないようにすることができる
2. コンテキストの利用
・ローカルコンテキスト情報の利用
-オブジェクト周囲の複数のローカルコンテキスト領域を生成し、これらのローカルコンテキスト特徴をオブジェクト特徴と結合するなど、さまざまな手法が存在する
-具体的な手法には、コンテキスト関連の再帰ユニット(GRUs)を使用してオブジェクト特徴とローカルコンテキスト情報を統合する方法、およびオブジェクト間の関係をモデル化し学習するためにグラフ畳み込みネットワーク(GCN)を使用する方法などがある
・グローバルコンテキスト情報の利用
-オブジェクトとシーンとの間の関連性を探索する(たとえば、車両は一般的に道路にあり、船は通常海上に存在する、など)
【小さなオブジェクト検出】
主に以下の3つの分野で研究が進んでいる
1. 識別的特徴学習
・一部の文献ではセマンティック情報を深いレイヤーの特徴に組み込み、小さなオブジェクトのセマンティック情報を強化するためのトップダウン構造を導入している
・また、外観情報が限られていることを考慮して、いくつかの研究は小さなオブジェクトと周囲のコンテクスト情報との関連性を確立し、セルフアテンションメカニズムや拡張畳み込みを介して特徴の識別能力を高めている
2. 超解像度ベース手法
・エッジを強調した超解像度生成対抗ネットワーク(GAN)を利用し、詳細なエッジ情報を持つ高解像度のリモートセンシング画像を生成
・Point-to-Regionフレームワークの利用
-キーポイント予測
画像内の重要なポイントや位置を予測。これらのキーポイントは、オブジェクトが存在する可能性が高い場所を示す
-提案領域の取得
キーポイント情報を使用して、画像内の提案領域を特定。提案領域は、オブジェクトが存在する可能性が高い場所で、検出対象として考えられる。
-超解像度処理
提案領域内の画像を高解像度に変換するために、超解像度技術を適用
-マルチタスクGANの使用
高解像度への画像変換後、提案領域内の小さなオブジェクトを検出するために、マルチタスクGANを使用。GANは、オブジェクトの存在と位置を特定するために学習され、超解像度画像から情報を抽出する。
3.「ズームアウト」と「ズームイン」構造
・ラベル割り当てにおけるIoUの閾値をより細かく調整し、小さなオブジェクトのために対する正のアンカーを増やすことで、オブジェクトの学習を容易にする
・一方で、IoUはわずかな位置のずれに非常に敏感であり、また、IoUを使用したラベル割り当てにおいて、小さなオブジェクトに対して正確な割り当てが難しいというスケール問題があるため、「正規化ワッサーシュタイン距離(NWD)」という新しい評価指標が提案されている(小さなオブジェクトを2Dのガウス分布としてモデル化し、そのガウス分布間の正規化ワッサーシュタイン距離を使用して、微小なオブジェクト間の位置関係をより適切に表現する)
【アノテーションコストの低減】
主に以下の3つの分野で研究が進んでいる
1. ウィークラベル学習を用いた物体検出
・簡易的なアノテーションを用いた物体検出(WSOD)は、正確なオブジェクトの位置情報ではなく、画像全体のラベル(画像内に何らかのオブジェクトがあるかどうか)やポイントレベルのラベル(特定の位置にオブジェクトが存在するかどうか)を提供する
・WSODは、正確なラベル情報が限られている場合や、大規模なデータセットに正確なバウンディングボックスをアノテーションするのが難しい場合に役立つ
2. 半教師あり学習物体検出
・SAR船舶検出向けのSCLANet手法
-SCLANetは、ラベルの付いたサンプルとラベルのないサンプルとの間で敵対的な学習を行い、ラベルのないサンプル情報を活用してロバスト性を高めるというラベルのないサンプルに対する一貫的な学習を採用している
・疑似ラベル生成
-最初に、限られたラベルの付いたサンプルから学習された事前トレーニングされた検出器を使用して、ラベルのないサンプルを予測
-次に、信頼性の高い疑似ラベルが選択され、最終的にラベル付きと疑似ラベル付きのサンプルを用いてモデルを再トレーニングする
3.Few-shot Object Detection
・メタラーニングベースの手法
-少数のショット学習タスクをシミュレートして知識を獲得し、この知識を新しいクラスの少数のショット学習に応用する
・転移学習ベースの方法
-豊富に注釈のついたデータから学習した一般的な知識を、少数の新しいデータに対して微調整する
-メタラーニングベースの方法と比較して、転移学習ベースの方法はより単純でメモリ効率が良い
Estimation of Forest Height Using Google Earth Engine Machine Learning Combined with Single-Baseline TerraSAR-X/TanDEM-X and LiDAR
【どういう論文?】
・合成開口レーダー(SAR)データ、特にTerraSAR-X/TanDEM-Xデータを用いた森林の高さ推定に焦点を当てた研究
・森林の高さを推定するために、CART、GBDT、RF、SVMなどの様々な機械学習アルゴリズムを採用
・上記手法をDSM-DEM差分法やSINC関数モデリング法などの従来の手法と比較
【技術や方法のポイントはどこ?】
・実験の全体像
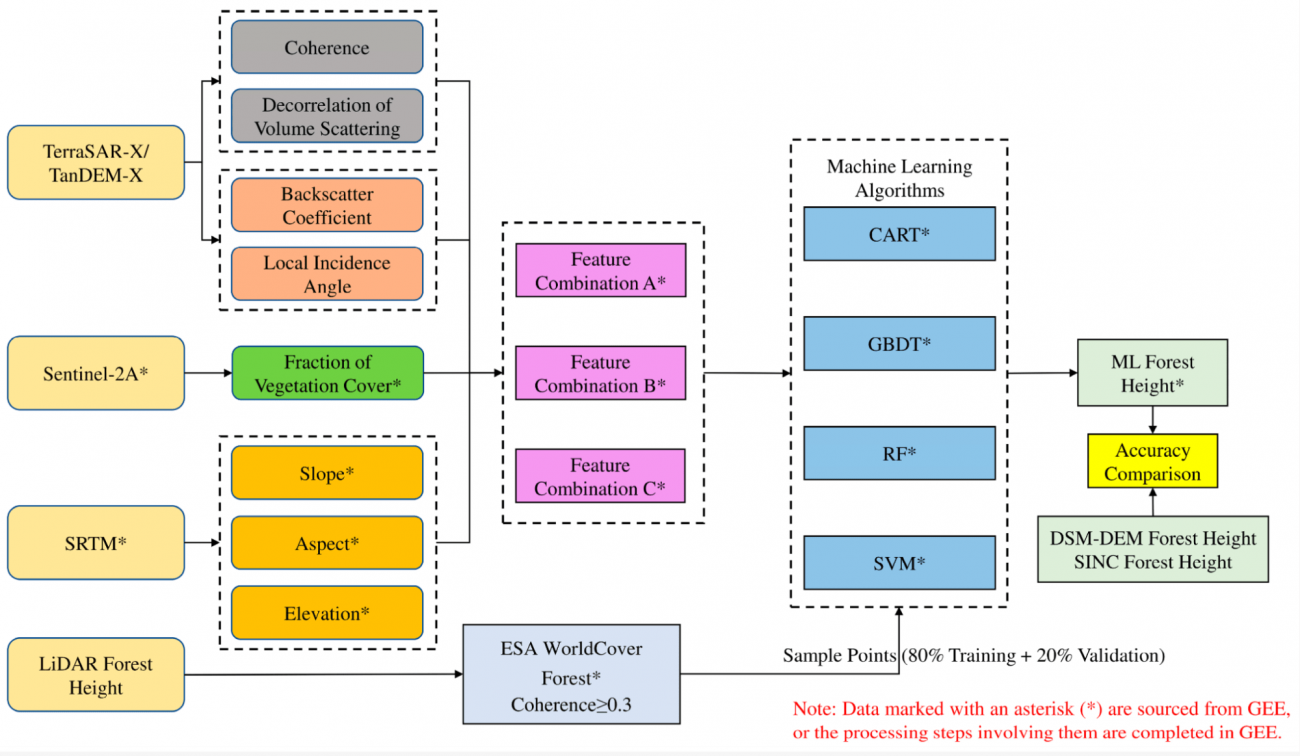
■ 利用データ元とデータ内容
・TerraSAR-X/TanDEM-X
-コヒーレンス:干渉SAR画像の相関度を示し、相関が高いほど精度の高い解析が可能
-体積散乱の非相関性:森林の内部構造や密度を推定するのに役立つ。例えば、森林の密度が高い場合、SAR信号の相関が比較的高いまま保たれ、森林の構造を評価するのに有用。逆に、森林の密度が低い場合、相関が速く低下し、森林の構造評価が難しくなる
-後方散乱係数:SAR信号が物体から反射される強度を示し、森林のバックスキャッタリング特性を把握できる
-局所入射角:入射角による歪みを補正し、正確な高度情報を取得できるようにする
・Sentinel-2A
-植生被覆率:森林高さの推定には、植生被覆率が重要なパラメータである。特定の地域や領域内で森林や植生の密度や範囲を示す指標であり、森林の高さと関連がある。高い植生被覆率の領域では、通常、より高い森林高さが期待される
-Shuttle Radar Topography Mission(標高モデル):SRTMデータは、地表の高度情報を提供するデジタル標高モデル(DEM)である。地表の標高を詳細に把握でき、地形や地勢の解析を可能とする
-ESA WorldCover 10m 2020:森林高さを推定するために土地被覆情報の取得を可能とする
-Airborne LiDAR:実際の森林高さの基準データとして使用
■ 分析手法と詳細
・DSM-DEM Differencing Method (DSM-DEM差分法)
-DSMの抽出(InSARデータからDSM(デジタルサーフェスモデル)を抽出する。このDSMには植生の高さ情報が含まれている。
-高精度DEMの取得(LiDARデータから高精度のDEM(デジタル標高モデル)を取得)
-InSAR DSMとLiDAR DEMの共通座標系へのコレジストレーション(InSAR DSMとLiDAR DEMを同じ座標系にコレジストレーション(位置合わせ)する)
-LiDAR DEMをInSAR DSMから差し引くことにより、森林高さを取得
・SINC Function Modeling Method (SINC関数モデリング法)
-InSAR観測と森林の生物物理パラメータ間の有効な相関を確立するRandom Volume over Ground(RVoG)モデルに基づいて計算する
-その際、観測したコヒーレンスは体積散乱のデコレレーション(信号の相関が失われる現象)を表すと仮定し、消滅係数(電磁波が物質によって吸収および散乱される速さを示すパラメータ)は森林領域においてはゼロに近いと仮定して導く(自然の物体の消滅係数は非常に小さいことが一般的)
・機械学習手法
-CART (Classification and Regression Trees):個々の決定木を単独で使用する。アンサンブル学習ではない。
-GBDT (Gradient Boosting Decision Trees):弱学習器を順次トレーニングし、それらを組み合わせて強力なモデルを構築する。アンサンブル学習の一形態。
-RF (Random Forest):多数の決定木から成るアンサンブル学習モデル。各ツリーはデータのランダムサブセットでトレーニングされ、結果を組み合わせて最終的な予測を行う。
-SVM (Support Vector Machine):小規模な非線形問題に広く使用されており、データを多次元空間に拡張できる(元のデータを複数の線形に分離する)。ただし、高次元データは解釈が複雑になることがある。
【議論の内容・結果は?】
■ 結果
・DSM-DEM差分法
-森林高の推定において、ある程度の過小評価を示した。これは、LiDARデータに比べて詳細な部分に対する精度が高いためである。
-R2値は0.38で、RMSEは4.34 m
・SINC関数モデリング法
-明らかな過大評価を示した。特に低い森林高の場合に過大評価が顕著であった。
-R2値は0.23で、RMSEは11.43 m
・①機械学習アルゴリズム(インターフェロメトリック情報を主に使用)
-CART、GBDT、RF、SVMアルゴリズムを使用して森林高を推定
-GBDTとRFアルゴリズムが最も高い評価を示し、R2値はそれぞれ0.67、0.67で、RMSEは2.89 m、2.89 mであった。全体的に、高い木と中程度から高い木の高さを推定する際に精度が向上した。
・②機械学習アルゴリズム(インターフェロメトリック情報+後方散乱係数)
-同じく、CART、GBDT、RF、SVMアルゴリズムを使用して森林高を推定
-①に比べて精度が低下。特に、CARTとSVMアルゴリズムは精度が低下し、R2値が0.11と0.08減少し、RMSEがそれぞれ0.48 mと0.26 m増加した。
・③機械学習アルゴリズム(インターフェロメトリック情報+後方散乱係数+局所入射角)
-同じく、CART、GBDT、RF、SVMアルゴリズムを使用して森林高を推定
-②に比べて精度が向上し、GBDTとRFアルゴリズムは最も高い精度を示した
・DSM-DEM差分法およびSINC関数モデル法に比べて、機械学習アルゴリズムを使用した森林高の推定精度が優れていた。
・インターフェロメトリック情報のみに基づくモデリングは、後方散乱係数、局所入射角、またはこれらの情報を組み合わせたモデリングに比べて、精度が高いことを示した
・植生被覆率は、森林の高さ推定に影響する最も重要な特徴として特定できた
・異なる特徴の組み合わせやアルゴリズムによって精度にばらつきがあったが、GBDTは一貫して良好な結果を示した。
Flood Extent and Volume Estimation Using Remote Sensing Data
【どういう論文?】
・洪水発生時の衛星データの利用可能性や雲量などの制約を考慮しつつ、DEMと洪水予測範囲を利用して、洪水の拡大だけでなく体積や深さを正確に推定するための研究
【技術や方法のポイントはどこ?】
・データセット
-Sen1Floods11データセット
-2016年から2019年までの世界中で発生した11の洪水が含まれており、水域・非水域・雲という3つのラベリングが施されている
・前処理(水域の検出と洪水モニタリングの精度向上のため、以下の水域指標を算出)
-NDWI:水域と植物の水含有量を強調する指標
-MNDWI:NDWIに似ているが、密生植生に対する感度を低減し、水域のみの検出により効果的な指標
-SWI:土壌の湿度指標
-AWEIsh:短波赤外線を使用して水域を検出するための指標
-AWEInsh: 短波赤外線が利用できない場合の代替指標
・洪水の境界(水域)特定
-データセット
→スペクトルデータのみ
→SARデータのみ
→上記2つのデータの組み合わせ
→ モデル
→U-Netアーキテクチャ
エンコーダーとデコーダーから構成されるニューラルネットワークアーキテクチャで、セグメンテーションタスクに適している。エンコーダーは入力画像から特徴を抽出し、デコーダーは特徴を使用してセグメンテーションマップを生成する。U-Netは詳細な空間特性を捉え、地表の詳細情報を保持する能力が高い
→MA-Netアーキテクチャ
様々なスケール(対象物や特徴のサイズなど)の特徴を明示的にモデリング・統合し、衛星画像内のスケールの特徴を捉える
→DeepLabV3アーキテクチャ
通常の畳み込み演算とは異なり、受容野(フィルターが適用される領域)を効果的に拡大できる特徴を持つアトラウス畳み込み(Atrous Convolution)を行う。これにより、画像内の広範なコンテキスト(土地区分など)を捉えることができる
・洪水の流量/体積計算
-洪水領域のセグメンテーション:衛星データと地形情報(DEM)を使用して、洪水で影響を受けた地域を特定する
-洪水の水深データの推定:地形情報(DEMなど)と実際(洪水時)の水深を関連付ける方法を使用する(洪水境界部分のピクセルのAWLS値を計算する。基準地形の高度と洪水境界の高度を比較して計算可能)
-水深と洪水領域の組み合わせ:各地点での水深データと洪水領域データを組み合わせて、各地点の洪水量を計算する
-総水量の計算: 各地点で計算された洪水量を合計して、全体の洪水量を算出する
【議論の内容・結果は?】
・最も優れた結果は、Sentinel-2のマルチスペクトルチャンネルとSentinel-1のレーダーチャンネルのすべてを組み合わせたモデルで得られた(F1スコア – 0.92、IoU-0.851)
・ただし、マルチスペクトラルデータのみの場合でも高い結果を得ることができた(F1スコア-0.917)
・SARデータのみの場合はかなり低い結果となった(F1スコア-0.793、IoU-0.657)
・洪水前(BF)と洪水中(DF)の領域の予測に関しては、F1スコアがそれぞれ0.705と0.99なった。水域の境界が明確でない場合(氾濫後も川が通常の水位である場合など)、モデルが一部のピクセルを区別しにくいことがわかった
Adapting Segment Anything Model for Change Detection in HR Remote Sensing Images
【どういう論文?】
・VFMという視覚的な情報を分類するモデルカテゴリー(例:Segment Anything Modelというゼロショットセグメンテーションができるモデルなど)に関して、衛星画像の特殊な性質により直接使用することは難しい
・本研究は、VFMの優れた視覚認識能力を活用して高解像度の衛星画像での変更検出を向上させることを目標とする
【技術や方法のポイントはどこ?】
・FastSAM アダプターの利用
-利用目的
→自然言語処理においては、一般的なモデルをより具体的に適応させるという手法がある
→上記モデルの一種であるFastSAMは、CNNを用いて、画像から得た情報を洗練させるために「畳み込みアダプター」を使用する
-技術内容
→画像から特徴(固有のパターン等)を様々なスケールで収集する
→上記の特徴を、1×1畳み込みレイヤー、バッチ正規化、RELU関数などを含むアダプターによって処理する
→衛星画像の変化検出タスクでは、低レベルの詳細が非常に重要なため、unet-likeデコーダー と呼ばれるアーキテクチャを用いて、異なるスケールからの特徴を組み合わせ、より良いピンポイントでの変化検出を補助する
・意味学習
-利用目的
→研究により、システムが関連する複数のタスクを一緒に学習すると、それぞれのタスクでより良いパフォーマンスを発揮することが示されている
→変化検出タスクにおいても、異なるタイムスタンプ(日付)の画像を最初に分類し、次に変化を検出するという従来の方法を取っているが、今回のモデルは両方のタスクを一度に学習する
-技術内容
→FastSAMアダプターから特徴{d1, d2, d3}のセットを取得する
→これらの特徴量はさらに処理され、衛星画像内の主要なオブジェクトの潜在表現)のようなものを導き出す
→あるタスクでは、この潜在を変化ラベルで直接監視する(どのような変化を探すかをシステムに直接指定する)のだが、ここでは異なる方法で行われる
→ソフトマックス関数を用いて、2つの画像間で変化しない領域が、類似した表現を持つようにする
→その後、アテンション操作(特定の部分に焦点を当てる技術的手法)を使って、上記の情報を変化特徴に埋め込む
→その結果、画像に何が写っているかというモデルの理解によって、詳細な変化を示すマップが出来る
・実装の詳細
-設計とセットアップ
→FastSAMは、yolo-v8アーキテクチャを使用して構築する
→FastSAMの視覚エンコーダーのみを使用し、プロンプトデコーダー(他の処理部分)はスキップする
→学習の1つの分岐では、単一の1×1畳み込み層(以前からある、画像処理ユニット)が使用される。変化検出のための別の分岐では、6層の処理ユニットを持つより複雑な構造が使用される。
-トレーニング
→50エポックで学習をトレーニングを行う(詳細はオンラインで公開されているソースコードを参照)
【議論の内容・結果は?】
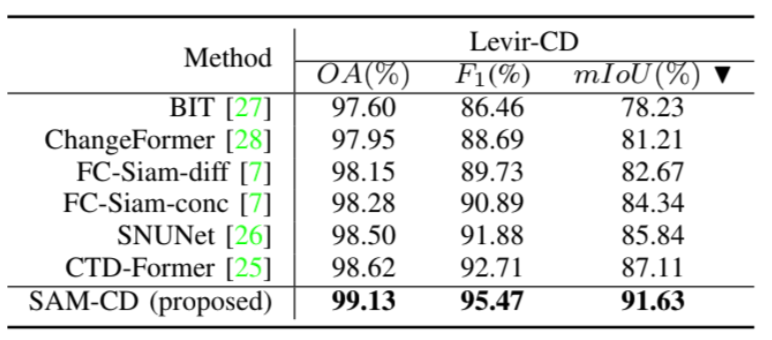
・本手法(SAM-CD)の性能を最新の手法と比較したところ、最新の手法のほとんどを上回り、そのロバスト性と有効性が示された。
RSDiff: Remote Sensing Image Generation from Text Using Diffusion Model
【どういう論文?】
・テキスト入力に基づいて高解像度の衛星画像を生成するために、2段階の拡散モデルを利用する革新的なアプローチの研究
・低解像度生成拡散モデル(LR-GDM)とテキストから低解像度画像を生成し、その後、高解像度画像を生成するためのスーパーリゾリューション拡散モデル(SRDM)を採用
【技術や方法のポイントはどこ?】
・データセットには10,921枚の高解像度の衛星画像を利用
・各画像は224×224ピクセルの寸法を持ち、5つのテキスト説明がアテンションされている
・実験用のトレーニングセットには8734枚のテキスト-画像の組み合わせを利用し、テストセットは残りの2187枚を利用
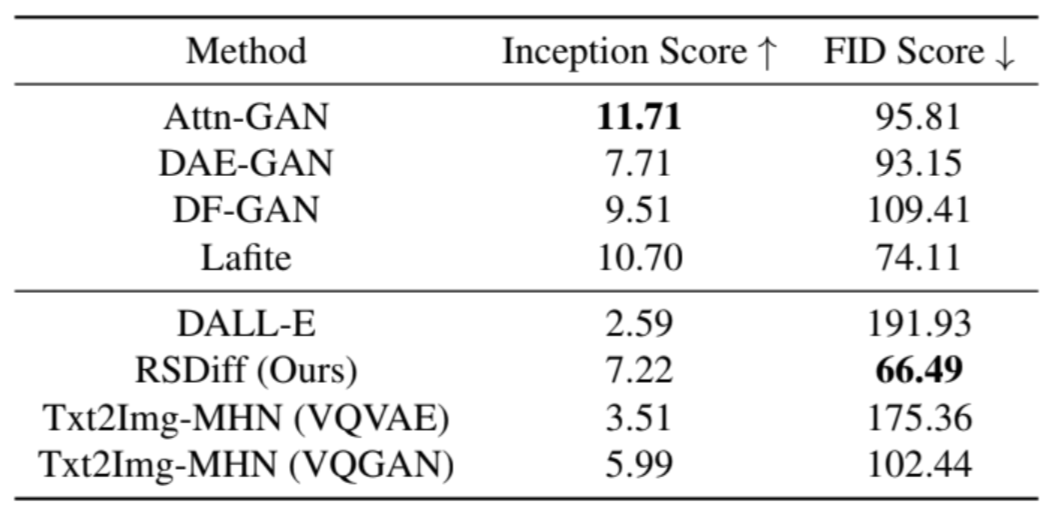
・以下の指標を利用
1.Inception Score
・概要
-生成された画像がどれだけ多様であり、それらの画像がどれだけリアルに見えるかを評価するための指標
・計算方法
-生成された各画像に対して、Inceptionモデル(通常、画像分類のためのもの)を使用してクラス確率分布を取得
-画像が多様であることを示すためのエントロピーを計算
-画像がリアルであるかどうかを示すためのKLダイバージェンスを計算
-上記の2つの値の積を取り、その期待値の指数をとる
・解釈
-高いInceptionScoreは、生成された画像が多様でリアルであることを示す2.FID
・概要
-生成された画像の分布と実際の画像の分布の間の距離を評価するための指標
・計算方法
-生成された画像と実際の画像の両方をInceptionモデルを用いて特徴空間にエンコード
-それぞれの画像セットの特徴の平均と共分散を計算
-平均の差の二乗と共分散行列のフロベニウスノルムの差を取り、それらの和を計算
・解釈
-低いFID値は、生成された画像の分布が実際の画像の分布に近いことを示す
【議論の内容・結果は?】

Incorporating Attention Mechanism, Dense Connection Blocks, and Multi-Scale Reconstruction Networks for Open-Set Hyperspectral Image Classification
【どういう論文?】
・本論文はハイパースペクトル画像の分類プロセスにおける未知のクラスの取り扱いに関する研究
・IADMRN(Intelligent Attention-Based Deep Multibranch Residual Network)と呼ばれる新しいフレームワークを紹介している
【技術や方法のポイントはどこ?】
・特徴抽出サブネットワーク
-densely connected blocksを用いて、各層の出力をすべての前の層の出力と結合する
-Depthwise Separable Convolutionのアテンションを強化し、ハイパースペクトル画像のスペクトルおよび空間次元に対するアテンションの配分を効率化する
STEP1. Depthwise Convolution
・各入力チャネルに対して畳み込みを個別に行う
・入力チャネルごとに畳み込みの結果が得られるため、出力のチャネル数は入力のチャネル数と同じになる
・本ステップでは空間的な特徴(エッジ・テクスチャ・パターン等)が処理されるSTEP2. Pointwise Convolution
・1×1の畳み込みカーネルを使用(同じ位置にある異なるチャネルの特徴マップの値を統合)して、上記の Depthwise Convolutionの結果を処理する
・本ステップではチャネル間の情報統合が行われる
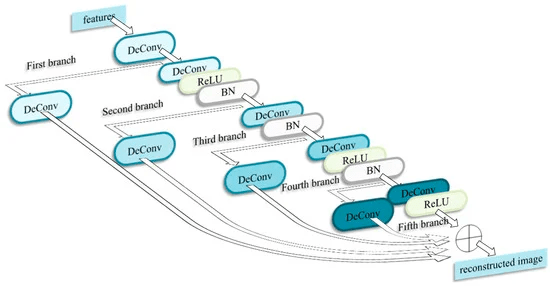
・画像再構築サブネットワーク
-本ネットワークは5つのブランチから構成されており、それぞれのブランチから得られたハイパースペクトラル画像の特徴マップを要素ごとに合算することで、集約された情報を利用した再構築画像を取得する
-つまり、特徴抽出サブネットワークで処理された低次元(重要な特徴だけをキャプチャした)画像を逆畳み込みを用いて元の空間解像度に逆写像する
-これを行うことで、ノイズや他の干渉を受けやすいハイパースペクトラル画像に対する分類器の精度を上げたりできる
・分類サブネットワーク
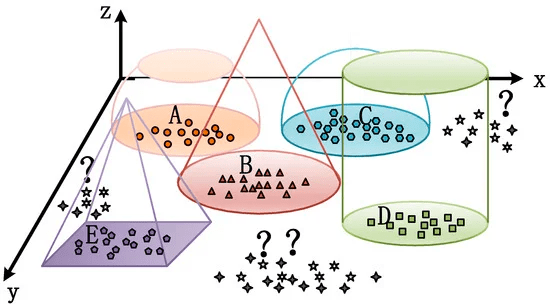
-未知のクラスを識別するために、EVT(極値理論)を用いたモデリングを利用する
-EVTは、極端な条件下で発生する可能性のある事象を予測するために使用される統計的手法
-訓練セットのサポートの範囲外にある「?」入力を「未知」として拒否し、A、B、C、D、Eの5つのカテゴリーを識別できるEVTモデルがある
また、再構築損失の計算を行う。これは、元のハイパースペクトル画像と再構築された画像との間の差を測定するものである(平均二乗誤差がこの差を定量化するための損失関数として使用される)
【議論の内容・結果は?】
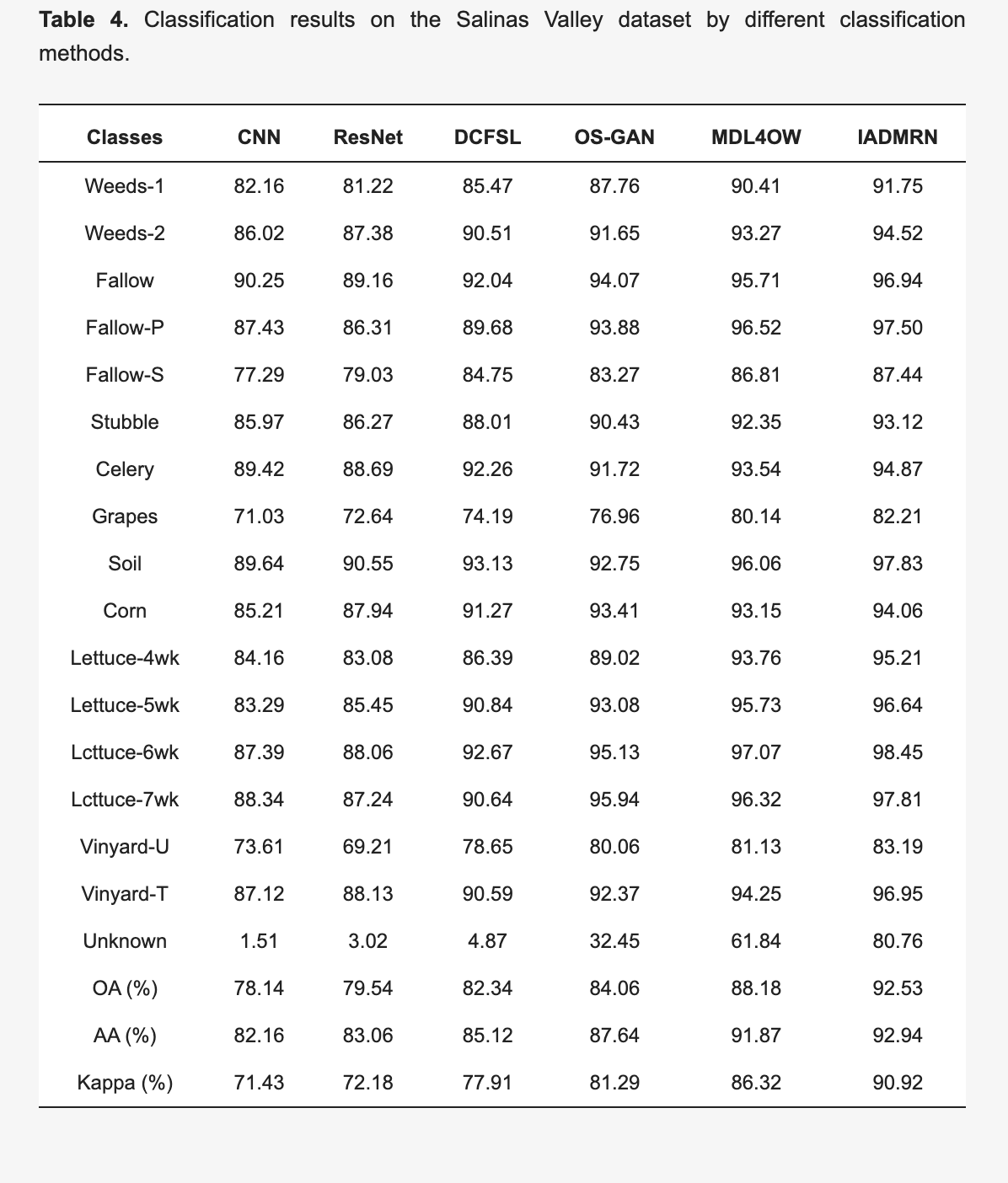
・提案アルゴリズムであるIADMRNと他の既存の手法(CNN、ResNet、DCFSL、MDL4OW、OS-GAN)との間の分類パフォーマンスの比較を行った
・データセットA
-IADMRNはOA(Overall Accuracy), AA(Average Accuracy), およびKappaのすべての指標で最も高いパフォーマンスを達成(OA: 92.53%、AA: 92.94%、Kappa: 90.92%)
-CNN、ResNet、およびDCFSLの方法では未知のクラスをよく識別できないことがわかった。未知のクラスの分類精度は5%未満
-MDL4OWおよびOS-GANに比べて、IADMRNのOAの認識精度はそれぞれ4.35%および8.47%増加した
・データセットB
-IADMRNのOAは、CNN, ResNet, DCFSL, OS-GAN, およびMDL4OWに比べて、それぞれ20.06%, 13.43%, 9.6%, 6.57%, および4.08%増加した
・データセットC
-IADMRNのOAは86.79%で最も高い
-IADMRNは、OA, AA, およびKappaで他の全ての方法に比べて精度が高かった
以上、2023年9月に公開された論文をピックアップして紹介しました。
皆様の業務や趣味を考えた時に、ピンとくる衛星データ利活用に関する話題はありましたか?
最後に、#MonthlySatDataNewsのタグをつけてTwitterに投稿された全ての論文をご紹介します。
• Landslide Segmentation with Deep Learning: Evaluating Model Generalization in Rainfall-Induced Landslides in Brazil
• Estimation of Forest Height Using Google Earth Engine Machine Learning Combined with Single-Baseline TerraSAR-X/TanDEM-X and LiDAR
• Recognition of Severe Convective Cloud Based on the Cloud Image Prediction Sequence from FY-4A
• Remote Sensing Object Detection Meets Deep Learning: A Meta-review of Challenges and Advances
• Flood Extent and Volume Estimation Using Remote Sensing Data
• RSDiff: Remote Sensing Image Generation from Text Using Diffusion Model
• Adapting Segment Anything Model for Change Detection in HR Remote Sensing Images
• Two-Level Feature-Fusion Ship Recognition Strategy Combining HOG Features with Dual-Polarized Data in SAR Images
• Two-Level Feature-Fusion Ship Recognition Strategy Combining HOG Features with Dual-Polarized Data in SAR Images
• Whale Detection Enhancement through Synthetic Satellite Images
• Generate Your Own Scotland: Satellite Image Generation Conditioned on Maps
来月以降も「#MonthlySatDataNews」を続けていきますので、お楽しみに!
