アメダスデータを使って気温予測や降雨状況の可視化をしてみた
今回はTellusで公開されているアメダスの1分値のデータを使って解析を行いました。具体的には、2017年7月5日から7月6日にかけて発生した平成29年7月九州北部豪雨におけるアメダス1分値データを対象にして以下の解析を行いました。
はじめに
過去の宙畑の記事として、アメダスのデータを取り出す記事があります。
【ゼロからのTellusの使い方】Jupyter Labで地域気象観測システム(アメダス)のデータを取得する
しかし、実際にアメダスのデータからどんな解析ができるかまでは紹介できていなかったため、今回は、2017年7月5日から7月6日にかけて発生した平成29年7月九州北部豪雨におけるアメダス1分値データを対象にして以下の解析を行う過程と結果を紹介します。
1. 平成29年7月九州北部豪雨における全国の降雨強度や平均風速、最大瞬間風速を特徴量として気温が予測できるかどうかを機械学習を用いて分析。実際に最も被害が大きかった大分県日田市と大分県の県庁所在地である大分市のデータを用いて予測精度を検証する
2.1分毎の降雨強度の時系列データから平成29年7月九州北部豪の降雨状況をネットワーク解析を用いて可視化→クラスタリングを行い、地域間の関係性を可視化する
今回はディープラーニングではなくscikit-learnやnetworkxを用いて解析を行なっているので、tellusで提供されている以下の仮想環境でも十分解析が可能です。もし興味のある方は、お手元に下記の仮想環境を申請して用意して頂ければ簡単に解析を進めてみてください。
☆Tellusの登録はこちらから
開発者の方へ | Tellus
https://www.tellusxdp.com/ja/developer/
・申込む環境
仮想環境
(さくらのクラウド )
CPU:4Core
メモリ:8GB
ディスク:SSD 100GB
データの取り出し
解析を行う前に、平成29年7月九州北部豪雨におけるアメダス1分値データをTellusのAPIから取得する必要があるので、アメダスの観測所データを取得します。
まずは、アメダスの観測所番号を取得する必要があるので、以下のサイトからアメダス観測所一覧のデータであるobs_station.xlsxをダウンロードします。
アメダス観測所一覧 | washitake.com
http://washitake.com/weather/amedas/obs_stations.md
取り出したデータをエクセルで開くと、obs_stationsと書かれたシートに観測所地点の地名や府県番号、観測所番号1,2などが記載されているのが確認できます。
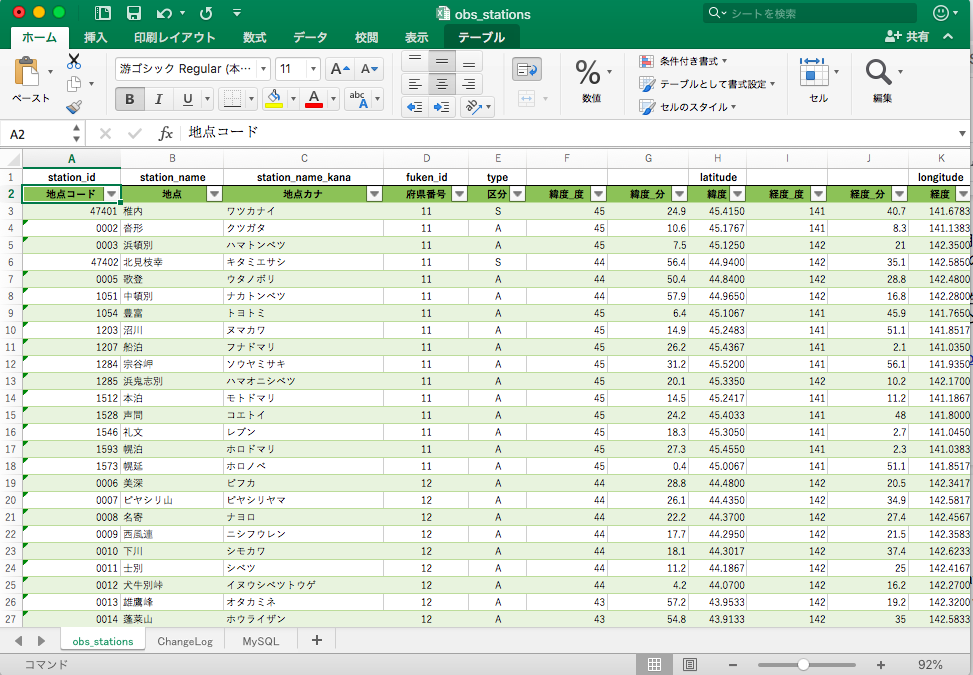
xlsxデータをpythonで取り出して分析しても良いのですが、csvの方が扱いが便利なのでこのobs_stationsと書かれたシートをcommand+A(Windowsの場合はctrl+A)で全部コピーして別のエクセルファイルに貼り付け、.csv形式で保存します(この後に書かれているソースコードは、obs_stations.csvという名前でデータを読み込んだりします)。うまく保存できていれば下記のようなcsvになっています。
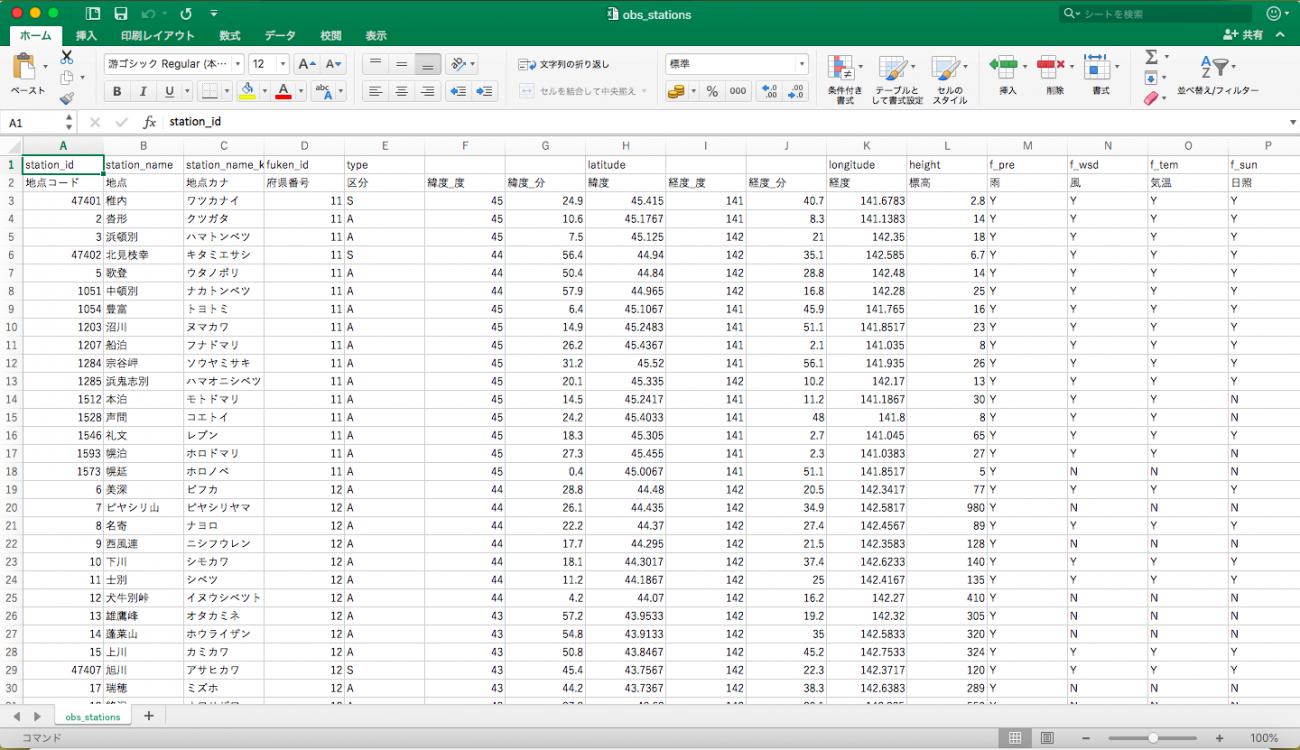
こちらのcsvファイルを、コードを実行する開発環境と同じところにおいておきます。
アメダスの観測所番号が手に入ったら、次は観測所番号を元にtellus APIを用いて平成29年7月九州北部豪雨におけるアメダス1分値データを取得します。Tellusのアメダスデータの取り出し方については、下記のURLを参考にしました。
アメダスのデータをAPIを利用して取得する | Tellus How to Use
https://www.tellusxdp.com/ja/howtouse/dev/20200221_000254.html
こちらが降雨強度のデータを取り出すソースコードになります。
Extract_rain.py (降雨強度の取得)
import pandas as pd
import requests, json
from datetime import datetime
from datetime import timedelta
from tqdm import tqdm
df = pd.read_csv('obs_stations.csv', header=1)
df1 = df[['地点','観測所番号1','区分']]
df1.columns = ['location','station_id','rank']
df2 = df[['地点','観測所番号2','区分']]
df2.columns = ['location','station_id','rank']
obs = pd.concat([df1,df2]).dropna(how='any')
obs['station_id']=obs['station_id'].astype('int')
obs = obs[obs['rank']=='S']
keys = obs['station_id']
TOKEN = "***************" # Tellusの開発環境のAPIアクセスからトークンを発行する
def get_amedas_1min(year, month, day, hour, minute, payload={}):
"""
/api/v1/amedas/1minを叩く
Parameters
----------
year : string
西暦年 (4桁の数字で指定) UTC
month : string
月 01~12 (2桁の数字で指定) UTC
day : string
日 01~31 (2桁の数字で指定) UTC
hour : string
時 00~23 (2桁の数字で指定) UTC
minute : string
分 00~59 (2桁の数字で指定) UTC
payload : dict
パラメータ(min_lat,min_lon,max_lat,max_lon)
Returns
-------
content : list
結果
"""
url = 'https://gisapi.tellusxdp.com/api/v1/amedas/1min/{}/{}/{}/{}/{}/'.format(year, month, day, hour, minute)
headers = {
'Authorization': 'Bearer ' + TOKEN
}
r = requests.get(url, headers=headers, params=payload)
if r.status_code is not 200:
print(r.content)
raise ValueError('status error({}).'.format(r.status_code))
return json.loads(r.content)
def is_valid(value_obj, flag_obj):
byte_size = {
1: 127,
2: 32767,
4: 2147483647
}
return flag_obj['value'] <= 12 and value_obj['value'] != byte_size[value_obj['size']]
dl = {}
res = pd.DataFrame()
time = datetime(2017,7,5,0,0)
times = []
times.append(time)
while time <= datetime(2017,7,6,23,59):
amedas = get_amedas_1min(str(time.year), str(time.month).zfill(2), str(time.day).zfill(2), str(time.hour).zfill(2), str(time.minute).zfill(2))
amedas_sorted = sorted(amedas, key=lambda d: d['rain']['intensity']['value'], reverse=True)
amedas_filtered = list(filter(lambda d: is_valid(d['rain']['intensity'], d['rain']['intensity_flag']), amedas_sorted))
for data in amedas_filtered:
id = str(data['station']['prefecture_no']['value']).zfill(2) + str(data['station']['observatory_no']['value']).zfill(3)
if int(id) in list(obs['station_id']):
dl.setdefault(obs[obs['station_id']==int(id)]['station_id'].values[0], []).append(data['rain']['intensity']['value']/10)
time += timedelta(minutes=1)
times.append(time)
rest = {}
for k,v in dl.items():
k = str(k)
ll = {}
if len(times)-1==len(v):
for i,value in enumerate(v):
l = {times[i].strftime('%Y-%m-%d %H:%M:%S'):value}
ll.update(l)
rest[k]=ll
with open('Rain_intensity.json', 'w') as f:
json.dump(rest, f, indent=4)
こちらのソースコードを.py形式で保存して、実際にtellusの仮想環境上でプログラムを実行すればアメダス1分値の降雨強度の時系列データが取得できます。
Windowsでは、csvファイルの文字コードでエラーとなる場合があります。csvを開く際にエンコード形式を指定して下さい(csv UTF-8で保存した場合)。
df = pd.read_csv('obs_stations.csv', header=1,encoding="utf-8")普通にプログラムを実行しても二日間くらいのデータであれば一時間半ほどで取得できますが、バックグラウンドで実行した方が楽だと思うので、そのやり方も記載したいと思います。
まず、jupyter labの仮想環境でlauncherからOther→Terminalを選択します。
そうすると、以下のようなターミナルの画面が出てくると思いますので、cd work/~という形でプログラムファイルがあるフォルダまで移動します。
指定のフォルダまで移動できたら「nohup python 保存したpythonファイル名 &」を実行すればバックグラウンドで実行でき、「ps -u」というコマンドで処理状況を確認することができます。
もしもエラーが起きてしまった場合は、実行したプログラムファイルと同じディレクトリにnohup.outというファイルが出力されているので、「cat nohup.out」と打ってあげればエラー内容の中身を確認することができます。最後までプログラムが実行されれば、「Rain_intensity.json」というjson形式のファイルが出力されています。
また、obs_stations.csvに記載されている「区分」については品質がSとAに分かれており、Sである観測所の方が品質が高い観測所です。今回はrankをS指定でデータを取得しました(約150箇所くらい)。rankの指定をしなければ1300箇所近くから膨大なデータを取得できるので、興味がある方は全体のデータを取得して解析に使っても良いでしょう。
最後に、上記の手順を真似していく形で、降雨強度だけではなく気温と平均風速、最大瞬間風速の三つを取得していきます。この手順を全て実行すれば、機械学習の解析に必要な特徴量は全て揃います(ネットワーク解析だけ行いたい方は、降雨強度の時系列データのみで可視化できるので、気温や平均風速の取得は飛ばしていただいてかまいません)。
基本的にソースコード内に記載されているモジュールのimportや関数の記載は全く同じなので、is_valid関数より下の処理部分を気温、平均風速、最大瞬間風速それぞれに関して以下のように書き換えて実行すれば問題ないです。
バックグラウンドの実行は複数のプログラムを同時に動かせるので、必要な降雨強度、気温、平均風速、最大瞬間風速の取得をnohupで一遍に実行してしまえば、数時間で取得できます。また、今回は二日間だけのアメダスデータを対象に解析しますが、一年間のデータを取得するとなると膨大に時間がかかるので、長期間のデータを取得したいときには注意してください。
Extract_temp.py (気温の取得)
dl = {}
res = pd.DataFrame()
time = datetime(2017,7,5,0,0)
times = []
times.append(time)
while time <= datetime(2017,7,6,23,59):
amedas = get_amedas_1min(str(time.year), str(time.month).zfill(2), str(time.day).zfill(2), str(time.hour).zfill(2), str(time.minute).zfill(2))
amedas_sorted = sorted(amedas, key=lambda d: d['rain']['intensity']['value'], reverse=True)
amedas_filtered = list(filter(lambda d: is_valid(d['temperature']['deg'], d['temperature']['deg_flag']), amedas_sorted))
for data in amedas_filtered:
id = str(data['station']['prefecture_no']['value']).zfill(2) + str(data['station']['observatory_no']['value']).zfill(3)
if int(id) in list(obs['station_id']):
dl.setdefault(obs[obs['station_id']==int(id)]['station_id'].values[0], []).append(data['temperature']['deg']['value']/10)
time += timedelta(minutes=1)
times.append(time)
rest = {}
for k,v in dl.items():
k = str(k)
ll = {}
if len(times)-1==len(v):
for i,value in enumerate(v):
l = {times[i].strftime('%Y-%m-%d %H:%M:%S'):value}
ll.update(l)
rest[k]=ll
with open('Temp.json', 'w') as f:
json.dump(rest, f, indent=4)
Extract_wind.py (平均風速の取得)
dl = {}
res = pd.DataFrame()
time = datetime(2017,7,5,0,0)
times = []
times.append(time)
while time <= datetime(2017,7,6,23,59):
amedas = get_amedas_1min(str(time.year), str(time.month).zfill(2), str(time.day).zfill(2), str(time.hour).zfill(2), str(time.minute).zfill(2))
amedas_filtered = sorted(amedas, key=lambda d: d['rain']['intensity']['value'], reverse=True)
for data in amedas_filtered:
id = str(data['station']['prefecture_no']['value']).zfill(2) + str(data['station']['observatory_no']['value']).zfill(3)
if int(id) in list(obs['station_id']):
dl.setdefault(obs[obs['station_id']==int(id)]['station_id'].values[0], []).append(data['wind']['velocity_ave']['value']/10)
time += timedelta(minutes=1)
times.append(time)
rest = {}
for k,v in dl.items():
k = str(k)
ll = {}
if len(times)-1==len(v):
for i,value in enumerate(v):
l = {times[i].strftime('%Y-%m-%d %H:%M:%S'):value}
ll.update(l)
rest[k]=ll
with open('Wind.json', 'w') as f:
json.dump(rest, f, indent=4)
Extract_wind_max.py (最大瞬間風速の取得)
dl = {}
res = pd.DataFrame()
time = datetime(2017,7,5,0,0)
times = []
times.append(time)
while time <= datetime(2017,7,6,23,59):
amedas = get_amedas_1min(str(time.year), str(time.month).zfill(2), str(time.day).zfill(2), str(time.hour).zfill(2), str(time.minute).zfill(2))
amedas_filtered = sorted(amedas, key=lambda d: d['rain']['intensity']['value'], reverse=True)
for data in amedas_filtered:
id = str(data['station']['prefecture_no']['value']).zfill(2) + str(data['station']['observatory_no']['value']).zfill(3)
if int(id) in list(obs['station_id']):
dl.setdefault(obs[obs['station_id']==int(id)]['station_id'].values[0], []).append(data['wind']['velocity_max']['value']/10)
time += timedelta(minutes=1)
times.append(time)
rest = {}
for k,v in dl.items():
k = str(k)
ll = {}
if len(times)-1==len(v):
for i,value in enumerate(v):
l = {times[i].strftime('%Y-%m-%d %H:%M:%S'):value}
ll.update(l)
rest[k]=ll
with open('Wind_max.json', 'w') as f:
json.dump(rest, f, indent=4)
解析その1: 機械学習を用いた気温の予測
では実際にTellus APIを用いて必要な特徴量が手に入ったので、次は降雨強度と平均風速、最大瞬間風速で構成された特徴量から気温を予測できるかの検証をしていきます。
手法:
今回は、一般的な機械学習のライブラリであるscikit-learnを用いて線形回帰モデル(stochastic gradient descent: SGD)で学習を行います。これは中身でオンライン学習してることもあり、一般的なガウス過程や多層パーセプトロンと比較すると高速で学習が終わるので時間を待つことなく学習することができます。
ソースコード(結果):
今回はjupyter labにあるノートブックでそれぞれ実行していく形でソースコードを掲載したいと思います。
まずは必要なモジュールを読み込んで、観測所のidなどを取得します。
import numpy as np
import pandas as pd
import json
from scipy import signal
# SGD:確率的勾配降下法
from sklearn import linear_model, metrics
"正規化"
from sklearn.preprocessing import StandardScaler
from sklearn import preprocessing
import matplotlib.pyplot as plt
df = pd.read_csv('obs_stations.csv', header=1)
df1 = df[['地点','観測所番号1','区分']]
df1.columns = ['location','station_id','kubun']
df2 = df[['地点','観測所番号2','区分']]
df2.columns = ['location','station_id','kubun']
obs = pd.concat([df1,df2]).dropna(how='any')
obs = obs[obs['kubun']=='S']
obs['station_id']=obs['station_id'].astype('int')
keys = obs['station_id']
次に、先ほど取り出したデータを処理して、訓練データとテストデータに分離します。テストデータは先述したように大分県の日田市と大分市の時系列データを対象にしました。
# 取り出したデータを日時のリスト、および観測所の地名:特徴量の辞書に分解する
def extract(obs,data):
output = []
label = []
for k,v in data.items():
try:
if all(int(elem) <= 1000 for elem in list(v.values())):
loc = obs[obs['station_id']==int(k)]['location'].values.tolist()
vector = list(v.values())
df = pd.Series(list(v.values()), index=v.keys())
df.index = pd.to_datetime(df.index, utc=True)
series = df.resample('1MIN').nearest()
output.append(series)
label.extend(loc)
except:
continue
datetimes = v.keys()
return datetimes, {k: v for (k, v) in zip(label, output)}
with open('Rain_intensity.json') as f:
rain = json.load(f)
with open('Wind.json') as f:
wind = json.load(f)
with open('Wind_max.json') as f:
wind_max = json.load(f)
with open('Temp.json') as f:
temp = json.load(f)
dates, rains = extract(obs,rain)
_, winds = extract(obs,wind)
_, winds_max = extract(obs,wind_max)
_, temps = extract(obs,temp)
# 先ほど取り出した辞書からデータフレームを作成し、テストデータと訓練データを取り出す。
df_rain = pd.DataFrame.from_dict(rains, orient='index')
df_wind = pd.DataFrame.from_dict(winds, orient='index')
df_wind_max = pd.DataFrame.from_dict(winds_max, orient='index')
df_temp = pd.DataFrame.from_dict(temps, orient='index')
# テストデータの作成
test_rain = df_rain.loc[['日田','大分']]
test_wind = df_wind.loc[['日田','大分']]
test_wind_max = df_wind_max.loc[['日田','大分']]
test_temp = df_temp.loc[['日田','大分']]
test_data = pd.concat([test_rain,test_wind,test_wind_max,test_temp], axis=1, sort=False)
# 訓練データの作成
df_rain = df_rain.drop(['日田','大分'], axis=0)
df_wind = df_wind.drop(['日田','大分'], axis=0)
df_wind_max = df_wind_max.drop(['日田','大分'], axis=0)
df_temp = df_temp.drop(['日田','大分'], axis=0)
train_data = pd.concat([df_rain,df_wind,df_wind_max,df_temp], axis=1, sort=False).dropna(how='any')
そして、作成した訓練データとテストデータをそれぞれ特徴量と教師ラベルに分解して、データを正規化した後に特徴量を予測する関数を作成しています。
# 訓練データから特徴量とラベルに分解する
Train_data = np.zeros([len(np.array(np.hsplit(train_data, 4)[0]).flatten()),3])
for i,t in enumerate(np.hsplit(train_data, 4)):
# 気温をラベル(教師データ)にする。※i==0なら降雨強度が教師になるので、ここを弄れば好きな値を教師データにできます。
if i == 3:
Train_label = np.array(t).reshape(-1)
else:
Train_data[:,i-1] = np.array(t).reshape(-1)
# テストデータから特徴量とラベルに分解する
Test_data = np.zeros([len(np.array(np.hsplit(test_data, 4)[0]).flatten()),3])
for i,t in enumerate(np.hsplit(test_data, 4)):
if i == 3:
Test_label = np.array(t).reshape(-1)
else:
Test_data[:,i-1] = np.array(t).reshape(-1)
# 訓練データとテストデータの正規化を行う。
# 特徴量の正規化
sc=StandardScaler()
stdscale=sc.fit(Train_data)
Train_data = stdscale.transform(Train_data)
Test_data = stdscale.transform(Test_data)
# ラベルの正規化
mm = preprocessing.StandardScaler()
Train_labels = mm.fit_transform(Train_label.reshape(1,-1)).flatten()
Test_labels = mm.fit_transform(Test_label.reshape(1,-1)).flatten()
# 特徴量(降雨強度、平均風速、最大瞬間風速)からラベル(気温)を予測する関数を作成
def Predict(Train_d,Train_l,Test_d,Test_l,algori,dates):
predictresult=algori.fit(Train_d,Train_l).predict(Test_d)
return {k: v for (k, v) in zip(dates, predictresult)}
SGD_ls = linear_model.SGDRegressor(loss="squared_loss")
最後に、予測した関数を呼び出して気温の予測を日田市と大分市それぞれで行い結果をグラフにします。
日田市の場合:
# 気温の予測(np.vsplit(Test_data, 2)[0],np.hsplit(Test_label, 2)[0]の要素で、0は日田市、1は大分市に対応しています)
result = Predict(Train_data,Train_label,np.array(np.vsplit(Test_data, 2)[0])
,np.array(np.hsplit(Test_label, 2)[0]),SGD_ls,dates)
df_res = pd.DataFrame.from_dict(result, orient='index')
df_res.index = pd.to_datetime(df_res.index, utc=True)
df_res = df_res.resample('15MIN').nearest()
valid = pd.DataFrame.from_dict({k: v for (k, v) in zip(dates, temp['83137'].values())}, orient='index')
valid.index = pd.to_datetime(valid.index, utc=True)
valid = valid.resample('15MIN').nearest()
visual = pd.concat([df_res, valid], axis=1)
visual.columns = ['predict','true']
visual.plot()
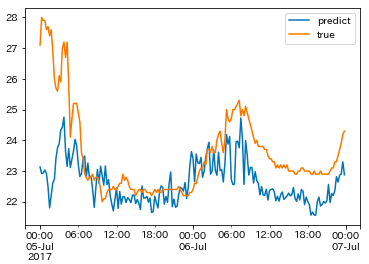
平成29年7月九州北部豪雨における日田市の気温の予測結果は上図のようになりました。この結果は1分毎の結果を15分毎に平均して出力した結果ではありますが、全体的に本来の気温よりも低い温度が予測されている結果になってしまい、特に最初の7月5日の深夜時間における気温の変化が予測できていない状態になっていました。
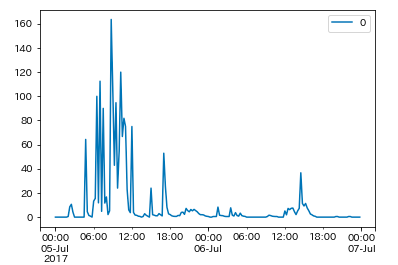
下記は実際の日田市の降雨強度ですが、本来降雨強度が強まると気温が急激に低下してることが確認できます。しかしながら、今回は訓練データに日田市のような降雨強度が異常に強まったデータが混入されていないため、正確な予測が困難になったのではないかと考えられました。
valid = pd.DataFrame.from_dict({k: v for (k, v) in zip(dates, rain['83137'].values())}, orient='index')
valid.index = pd.to_datetime(valid.index, utc=True)
valid = valid.resample('15MIN').nearest()
valid.plot()
大分市の場合:
result = Predict(Train_data,Train_label,np.array(np.vsplit(Test_data, 2)[1])
,np.array(np.hsplit(Test_label, 2)[1]),SGD_ls,dates)
df_res = pd.DataFrame.from_dict(result, orient='index')
df_res.index = pd.to_datetime(df_res.index, utc=True)
df_res = df_res.resample('15MIN').nearest()
valid = pd.DataFrame.from_dict({k: v for (k, v) in zip(dates, temp['83216'].values())}, orient='index')
valid.index = pd.to_datetime(valid.index, utc=True)
valid = valid.resample('15MIN').nearest()
visual = pd.concat([df_res, valid], axis=1)
visual.columns = ['predict','true']
visual.plot()
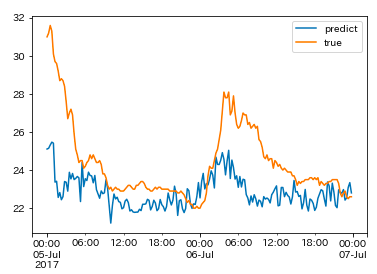
また、平成29年7月九州北部豪雨における大分市の気温の予測結果は上図のようになりました。この結果も1分毎の結果を15分毎に平均して出力した結果です。こちらの方は日田市の予測結果と比べると最初の時系列変化が多少追従できている印象がありますが、真の気温を予測できるほどまでには精度は上がりませんでした。観測所地点を地方単位で限定することによって精度が上がると思いますが、長い時系列情報を細かい間隔で取得しなければならないので、今後の課題になりそうです。
ところで、先ほどは全てのデータを使って解析してしまったので、次に交差検証してモデルの汎化性能を評価してみます。5分割の交差検証を行い、それぞれのモデルの予測結果を日田市のテストデータで可視化するコードが以下になります。今回はモデルの性能評価のみの結果を表示したいと思います。また、回帰モデルを用いているので、決定係数と呼ばれるモデルの当てはまりの良さを示す指標を算出しました(当てはまりが悪いとマイナスになり、最も当てはまりが良いと1.0になります)。
from sklearn.model_selection import KFold
from sklearn.metrics import r2_score
kf = KFold(n_splits=5)
for train_index, test_index in kf.split(Train_data, Train_label):
X_train, X_test = Train_data[train_index], Train_label[train_index]
y_train, y_test = Train_data[test_index], Train_label[test_index]
y_pred = SGD_ls.fit(X_train, X_test).predict(y_train)
y_pred = y_pred.flatten()
# 決定係数の算出
r2 = r2_score(y_pred,y_test)
print(r2)
result = SGD_ls.predict(np.array(np.vsplit(Test_data, 2)[0]))
result = {k: v for (k, v) in zip(dates, result)}
df_res = pd.DataFrame.from_dict(result, orient='index')
df_res.index = pd.to_datetime(df_res.index, utc=True)
df_res = df_res.resample('15MIN').nearest()
valid = pd.DataFrame.from_dict({k: v for (k, v) in zip(dates, temp['83137'].values())}, orient='index')
valid.index = pd.to_datetime(valid.index, utc=True)
valid = valid.resample('15MIN').nearest()
visual = pd.concat([df_res, valid], axis=1)
visual.columns = ['predict','true']
ax = visual.plot()交差検証した時のモデルの評価は以下のようになり、値はマイナスになってしまったのでモデルの予測性能がかなり悪いことが分かります。したがって、時系列情報がない状態における一地点の降雨強度や風速のみから気温を予測するのは困難であることがモデルの性能結果から分かりました。
-2.6458484868976395
-6.184890634543109
-2.883327231155094
-5.056130188249698
-3.89002396825747追加解析と課題
先ほどの結果は正確な気温の値を予測できないと結論づけていましたが、全体の挙動としては変化が追従できているのか検証するためにウェーブレット解析を行ってみました。
ソースコード:
# 真の気温結果で検証したい場合は、df_resをvalidに変えれば検証できます。
# y = np.array(valid.values.flatten())
y = np.array(df_res.values.flatten())
from scipy import signal
widths = np.arange(1, 31)
cwtmatr = signal.cwt(y, signal.ricker, widths)
plt.imshow(cwtmatr, extent=[0, 31, 1, 31], cmap='PRGn', aspect='auto',
vmax=abs(cwtmatr).max(), vmin=-abs(cwtmatr).max())
実際に日田市の先ほどの気温の予測結果と真の気温に対して適応したところ、下図のように周波数の特性はかなり類似していることがわかりました。したがって、今回の解析では正確な気温の値を予測することができませんでしたが、全体的な気温変化の挙動はある程度追従できたのではないかと考えられました。
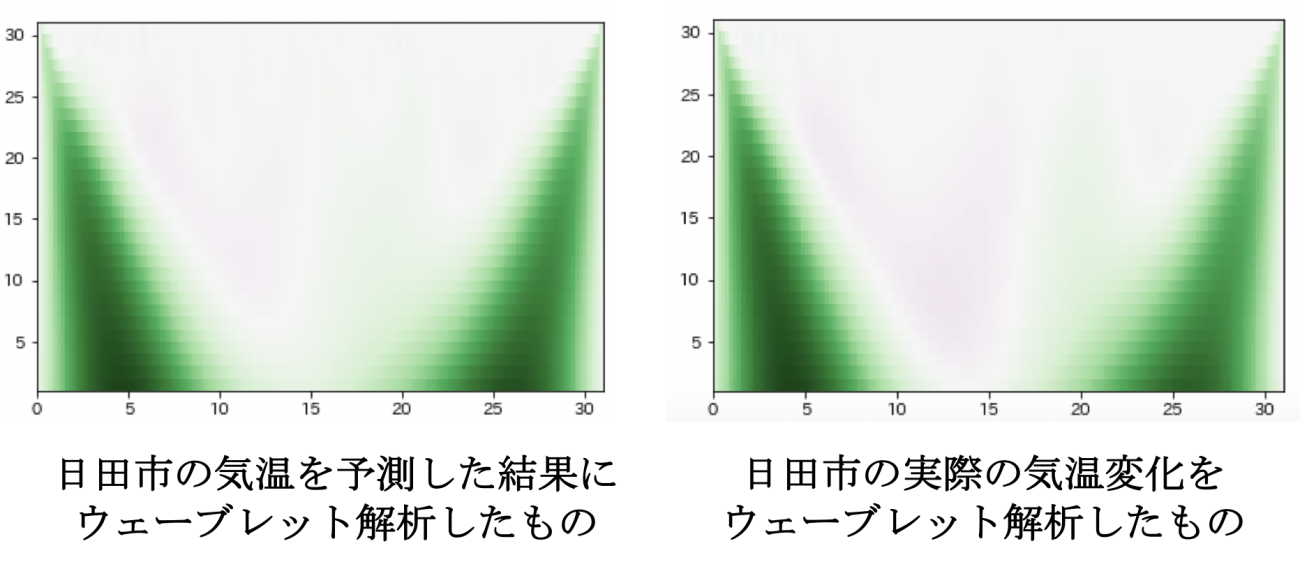
また、今後の課題としては以下のような項目が考えられました。
・もっと対象地域を限定して気温などの予測を行う必要がある。
・降雨強度や風速は、被害状況が酷かった地域は変化が激しすぎて正確な予測ができなかったので、ある程度被害状況に応じてアメダスデータのバリデーションを行う必要性があるかもしれない
・汎化性の高い予測を行うときには、平成29年7月九州北部豪雨のデータに限らず、長期間の時系列データを利用する必要性がある
・今回は気温変化の周期性などを考慮に入れていなかったため、周期性(トレンド)を除外した特徴量を利用する必要が出てくるかもしれない
解析その2: 降雨状況の可視化
では次に、取り出した降雨強度の時系列データを使用してネットワーク分析を行ってクラスタリングを行うことによって、平成29年7月九州北部豪雨における全国の降雨状況を把握してみたいと思います。
手法:
今回は、純粋に降雨強度の時系列データの相関係数を観測所地点ごとに計算して相関行列を作成します。そして、計算した相関行列を用いてネットワーク分析用のpythonライブラリであるnetworkxを使ってネットワークを可視化し、コミュニティ抽出などでよく使用されているlouvainという手法を使ってクラスタリングを行います(pipで簡単にインストールすることが可能です)。
手法:
今回は、純粋に降雨強度の時系列データの相関係数を観測所地点ごとに計算して相関行列を作成します。そして、計算した相関行列を用いてネットワーク分析用のpythonライブラリであるnetworkxを使ってネットワークを可視化し、コミュニティ抽出などでよく使用されているlouvainという手法を使ってクラスタリングを行います(pipで簡単にインストールすることが可能です)。
ソースコード(結果):
まずは、取り出した降雨強度のデータを基にして相関行列を作成して、ネットワーク化します。tellusの仮想環境だとネットワーク分析をした際に日本語の文字化けに対応できなかったため、こちらの解析はローカル環境で行っております。
import numpy as np
import pandas as pd
import json
from scipy import signal
import networkx as nx
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('seaborn')
plt.rcParams['font.family'] = 'IPAexGothic'
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv('obs_stations.csv', header=1)
df1 = df[['地点','観測所番号1','区分']]
df1.columns = ['location','station_id','kubun']
df2 = df[['地点','観測所番号2','区分']]
df2.columns = ['location','station_id','kubun']
obs = pd.concat([df1,df2]).dropna(how='any')
obs = obs[obs['kubun']=='S']
obs['station_id']=obs['station_id'].astype('int')
keys = obs['station_id']
with open('Rain_intensity.json') as f:
data = json.load(f)
output = []
label = []
for k,v in data.items():
if int(k) in list(keys):
loc = obs[obs['station_id']==int(k)]['location'].values.tolist()
df = pd.Series(list(v.values()), index=v.keys())
df.index = pd.to_datetime(df.index, utc=True)
series = df.resample('3H').nearest()
output.append(series)
label.extend(loc)
res = np.nan_to_num(np.corrcoef(output))
datetimes = v.keys()
# ネットワークによる可視化
# networkxに引き渡すエッジリストを準備
edge_lists = []
df = pd.DataFrame(res)
edge_name = label
df.index = df.columns = edge_name
# 相関係数DFより右上の三角行列およびに 0.6以下のデータをマスク
tmp_df = df.mask(np.triu(np.ones(df.shape)).astype(bool) | (df < 0.6))
# エッジリストを生成
edge_lists = tmp_df.stack().reset_index().apply(tuple, axis=1).values
G = nx.Graph()
G.add_weighted_edges_from(edge_lists)
# 描画の準備
plt.figure(figsize=(8,8)) #描画対象に合わせて設定する
pos = nx.circular_layout(G)
line_width = [d['weight']*1 for u,v,d in G.edges(data=True)]
nx.draw_networkx(G, pos=pos, font_size=10, node_color='gray', width=line_width, font_family='IPAexGothic')
plt.savefig('network.png')
実際にネットワーク化した結果は下図のようになっており、主に関西や中国四国、九州地方を中心にネットワークが形成されていることが確認できました。今回は観測所地点における降雨強度の時系列データ同士で相関係数が0.6以下であるものはフィルタリングしていますが、この閾値を変えることで、少しでも相関があった観測所地点同士の繋がりを可視化できます。
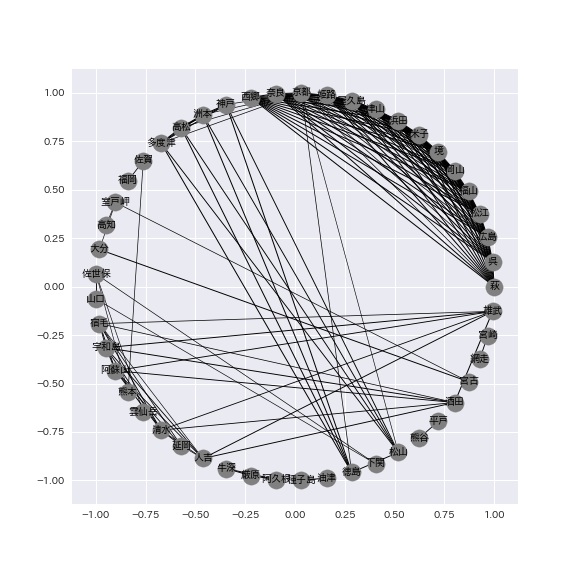
最後に、上記のネットワークを基にしてlouvainによるクラスタリングを行います。実際のソースコードは以下のようになります。
# クラスタリングの結果を表示
import community
partition = community.best_partition(G)
size = float(len(set(partition.values())))
pos = nx.spring_layout(G)
count = 0.
for com in set(partition.values()):
count += 1.
list_nodes = [nodes for nodes in partition.keys() if partition[nodes] == com]
nx.draw_networkx_nodes(G, pos, list_nodes, node_size=20, node_color = str(count/size))
plt.show()
# クラスタリングの結果を保存
partition = community.best_partition(G)
labels = dict([(i, str(i)) for i in range(nx.number_of_nodes(G))])
nx.set_node_attributes(G, labels,'label')
nx.set_node_attributes(G, partition, 'community')
nx.write_graphml(G, "fourpath.graphml", encoding='utf-8')
最終的に出力された結果をcytoscapeと呼ばれるソフトで開いて綺麗に整形した時の結果が下図になります(cytoscapeの可視化などは、こちらなどを参考にして頂ければと思います:https://qiita.com/bamboo-nova/items/ff26593380147ba48ee9)。その場で結果を確認したいだけの場合は、辞書形式になってるpartitionの中身を見れば大丈夫です。
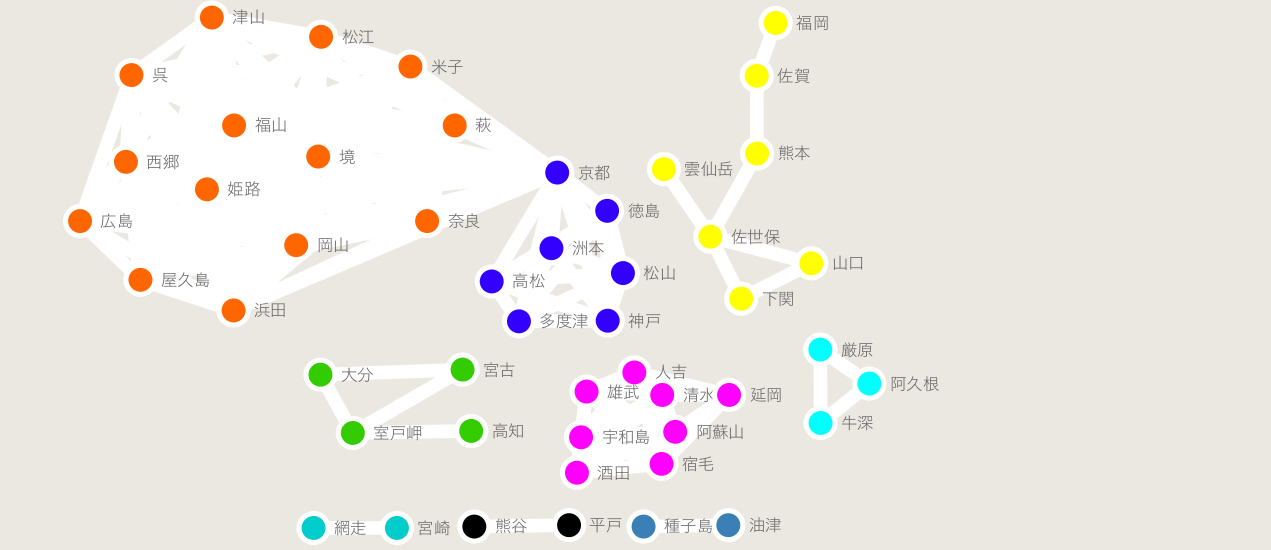
よく見ると、主に2017年7月5日から6日にかけては西日本を中心に雨が降っていたことが確認できました。
例えば、京都を状況を中心として、主に関西と中国・四国地方の中で大きく二つの異なる降雨強度の変化をしている地域があることが推測できました。
また、一番被害が酷かった九州地方では、一部ノイズは入っていますが大分県が他の隣の福岡県や熊本県と同じクラスタに所属しなかったことから、同じ九州地方でも大分県などは他の隣県と比べて降雨強度の変化が異なることも推測できました。
さらに、熊本県に至っては市街地と山間部で異なるクラスタに所属している(降雨強度の変化が異なる)ことも結果から伺うことができました。このように、たった二日間の降雨強度の時系列変化を利用するだけで、大まかな降雨強度変化を地域ごとに可視化することができました。
今後は他の時期の時系列情報を加味した解析などを適用することによって、より精度の高い災害状況の把握、予測が可能になるかもしれません。
まとめ
今回は2017年7月5日から7月6日に書けて発生した平成29年7月九州北部豪雨における1分値アメダスデータを用いて、降雨強度や風速から気温の予測ができるか検証を行ました。また、その時の降雨強度の時系列変化をネットワークとして可視化し、地域間のコミュニティ抽出を行いました。今回は平成29年7月九州北部豪雨におけるデータで限定して解析を行う形になりましたが、より長期間の時系列情報を地域を限定するなどして解析を行うことによって、より精度の高い気象予測や災害状況の把握が可能になることが期待できます。
今回のデータはGPU環境を用いずに誰でもTellusの仮想環境があれば解析することができるので、もし良かったら今回掲載したソースコードをベースにして、新しく他の地域や期間で解析して気象予測、災害状況の把握をしてみてはどうでしょうか。
ライター名:新星 竹(あらほし たけ)
プロフィール:主にバックエンドや機械学習に関連した分析&実装で生計を立てているフリーランスの大学院生(博士後期課程)です。様々な衛星データを扱えるTellusに興味を持ち、主にSAR画像に関連した解析などを研究や仕事の合間に行なっています。
