山の天気が変わりやすい理由について、AMeDASと衛星データを用いて確認してみた
山の天気が変わりやすいと聞いたことはあるけれど、なぜ? 通説について、AMeDASのデータを用いて考察してみました。
2022年8月31日以降、Tellus OSでのデータの閲覧方法など使い方が一部変更になっております。新しいTellus OSの基本操作は以下のリンクをご参照ください。
https://www.tellusxdp.com/ja/howtouse/tellus_os/start_tellus_os.html
山の天気は変わりやすいとよく言われます。その理由は、山に向かって吹く風が山肌を駆け上るにつれて標高が高くなって雲を形成し、その雲が雨を降らすことが関係しているそうです。
本記事では、山の天気が変わりやすいと言われている原因について、本当にそのような傾向が見られるのかを検証するために、Tellusで扱えるAMeDASのデータから1分毎の風の強さ、風向き、雨量を取得して確かめてみました。
また、実際に変化する雲の様子を確認するために、気象衛星のひまわりの衛星画像を取得し、変化する雲の様子をGIF画像にして確認したものも掲載しておりますので合わせてご覧ください。
1.山の天気が変わりやすいときの3つの要素
筆者自身も、数年前に北アルプスの穂高三山を縦走しに行った際には現地に着いた途端に猛烈な雨に降られ、ヘロヘロになりながら必死で初日宿泊予定のテントエリアを目指したという苦い経験があります。

日本山岳救助機構合同会社のサイトによると、山の天気の変わりやすさ(=雲ができ、雨が降る原因)には、次の3つの要素が影響しているそうです。
1.風速の変化→西風が強まっていくときは天気が崩れることが多い
2.風向きの変化→西風が南寄りに変わっていくときは天気が崩れることが多い
3.水蒸気量の変化→水蒸気が多い空気(湿った空気)が入ると、天気が崩れる。
※雲から山の天気を学ぼう(第15回)
今回は上記条件の1である風向きに焦点を当て、筆者自身も思い入れの深い「北アルプス」特に穂高岳が鎮座する上高地エリアの天気の変化と、北アルプスに対して吹く偏西風の関係をAMeDASデータを元に考察してみようと思います。
条件2と条件3は今回の検証対象からは外しているため、今回検証したいポイントは「西風が強いときに本当に天気が崩れているのか」になります。
2.検出方法と使用するデータの説明
対象時期としては、山行データの記録サービスであるYAMAP(https://yamap.com/)の下記の記事の記述を参考にしたいと思います。
2017.10.07(土) 3 DAYS テント泊 2泊3日 涸沢〜奥穂高〜北穂高
初日は雨。
日中は雲がかかるも日が差し思ったより崩れなかった。と思いきや、涸沢手前で降り出した。雨の中テントを張ったのは初でした。
(中略)
2日目は天気良好。
(中略)
3日目は紅葉を楽しみながら涸沢まで下山。
この方の記述に従うと、2017年10月07日は12:00ごろから雨が降り出し、その日1日はずっと降り続いていたようです。翌日以降の10月08日、10月09日は天候に恵まれたようですね。
こちらの記事を参考に、AMeDASのデータから前日の10月06日も含めた4日間の風量と風向き、雨量を抽出し、その関係を考察してみたいと思います。
そして最後に、この4日間における雲の動きを気象衛星ひまわり8号の衛星画像を利用して、北アルプス上空から広域で確認してみたいと思います。
3.上高地周辺の位置と標高を確認する
上高地観測所の位置をTellus上で確認すると以下になります。
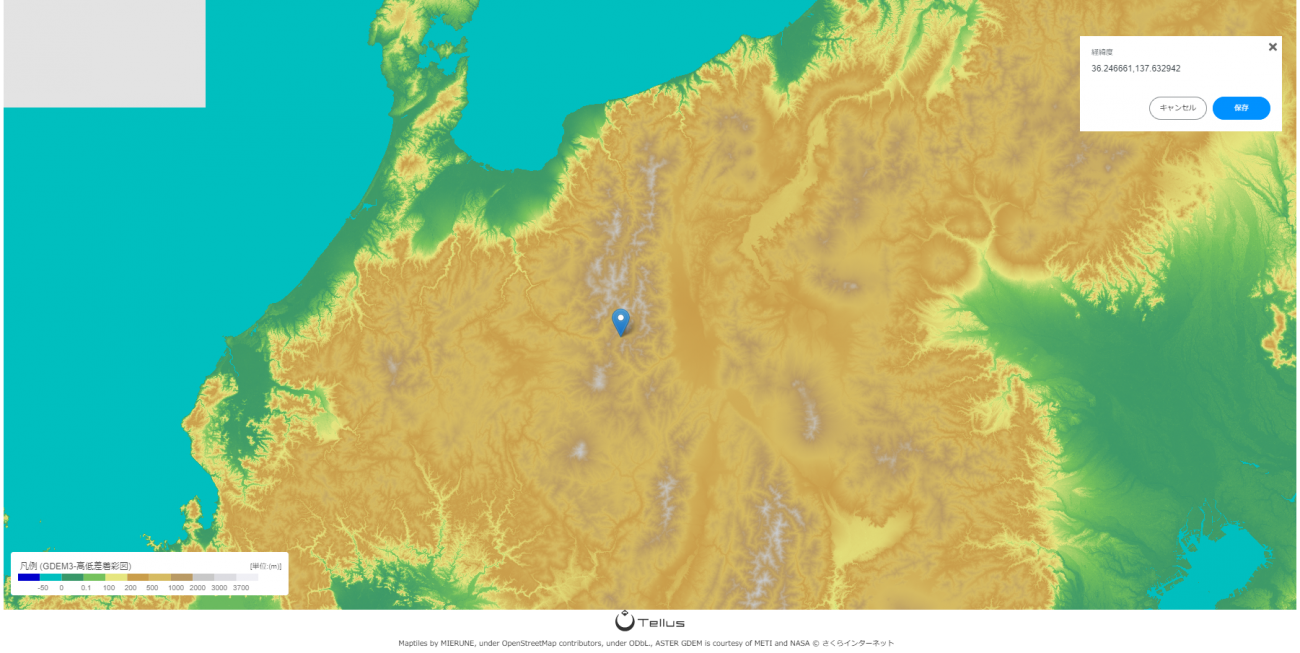
西側に観測地点よりも標高の高い場所があるようです。では実際にどの程度の標高差があるのでしょうか。
ASTER GDEMの衛星画像を使うと、標高を確認することができます。上高地から西方にかけての標高をプロットしてみることで、西方からの風がどのようにアルプス山脈に対して吹いているのか視覚的にも把握してみたいと思います。
まずASTER GDEMから標高データを取得する関数を定義します。
import os, requests, json
from skimage import io
from io import BytesIO
import math
def get_astergdem2_dsm(zoom, xtile, ytile, option = {}, params = {}):
"""
ASTER GDEM2 の標高タイルを取得
Parameters
----------
zoom : str
ズーム率
xtile : str
座標X
ytile : number
座標Y
Returns
-------
img_array : ndarray
標高タイル(PNG)
"""
path = "/astergdem2/dsm/{}/{}/{}.png".format(zoom, xtile, ytile)
url = HOST + path
r = get_api_data(url)
return io.imread(BytesIO(r.content))プロットするタイル座標をTellusOS上で確認します。
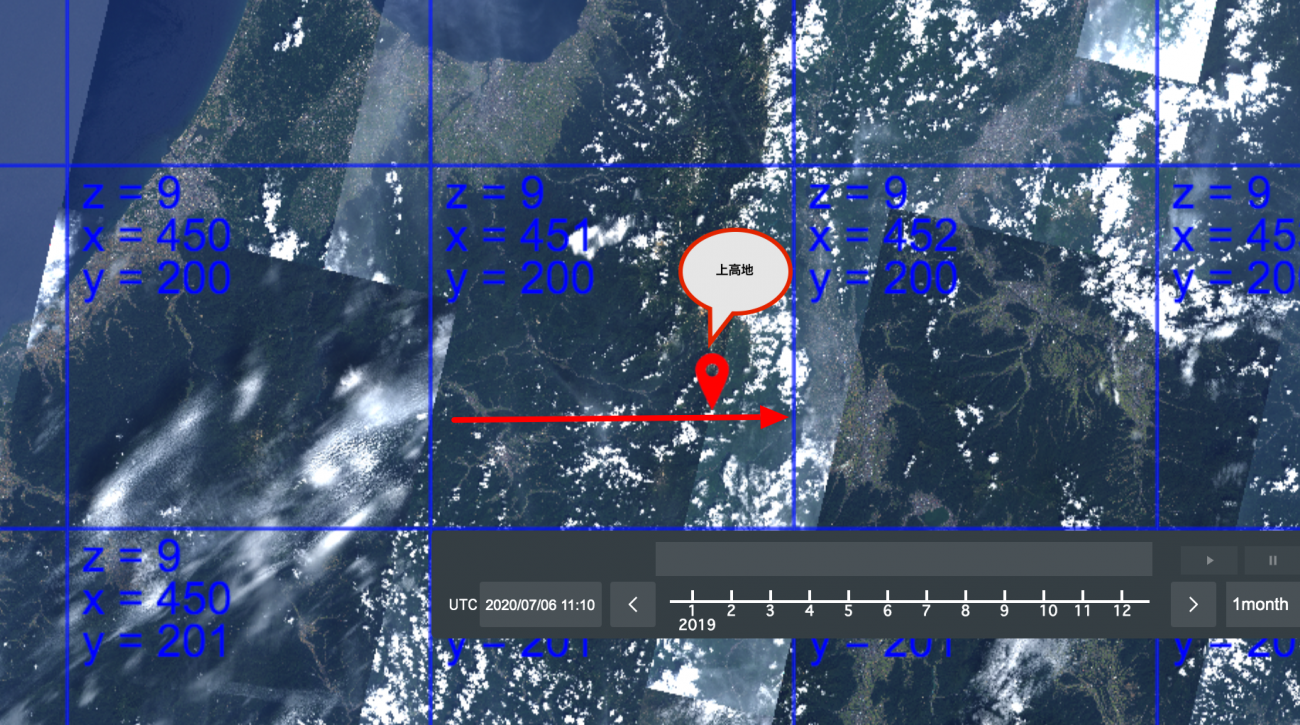
赤い矢印を引いたあたりの標高データをASTER GDEMから取得します。
z=9
x=451
y=200
gdem_img = get_astergdem2_dsm(z, x, y)
io.imshow(gdem_img)
プロットするための関数を定義します。
def get_tile_bbox(zoom, topleft_x, topleft_y, size_x=1, size_y=1):
"""
タイル座標からバウンダリボックスを取得
https://tools.ietf.org/html/rfc7946#section-5
"""
def num2deg(xtile, ytile, zoom):
# https://wiki.openstreetmap.org/wiki/Slippy_map_tilenames#Python
n = 2.0 ** zoom
lon_deg = xtile / n * 360.0 - 180.0
lat_rad = math.atan(math.sinh(math.pi * (1 - 2 * ytile / n)))
lat_deg = math.degrees(lat_rad)
return (lon_deg, lat_deg)
right_top = num2deg(topleft_x + size_x , topleft_y, zoom)
left_bottom = num2deg(topleft_x, topleft_y + size_y, zoom)
return (left_bottom[0], left_bottom[1], right_top[0], right_top[1])
def calc_height_chiriin_style(R, G, B, u=100):
"""
標高タイルのRGB値から標高を計算する
"""
hyoko = int(R*256*256 + G * 256 + B)
if hyoko == 8388608:
raise ValueError('N/A')
if hyoko > 8388608:
hyoko = (hyoko - 16777216)/u
if hyoko < 8388608:
hyoko = hyoko/u
return hyoko
def plot_height(tile, index, direction, z, x, y, xtile_size=1, ytile_size=1, u=1):
"""
高度のグラフをプロットする
Parameters
----------
tile : ndarray
標高タイル
bbox : object
標高タイルのバウンディングボックス
index : number
走査するピクセルのインデックス
direction : number
走査方向(0で上から下、1で左から右)
zoom : number
ズーム率
xtile : number
座標X
ytile : number
座標Y
xtile_size : number
X方向のタイル数
ytile_size : number
Y方向のタイル数
u : number
標高分解能[m](デフォルト 1.0[m])
"""
bbox = get_tile_bbox(z, x, y, xtile_size, ytile_size)
width = abs(bbox[2] - bbox[0])
height = abs(bbox[3] - bbox[1])
if direction == 0:
line = tile[:,index]
per_deg = -1 * height/tile.shape[0]
fixed_deg = width/tile.shape[1] * index + bbox[0]
deg = bbox[3]
title = 'height at {} degrees longitude'.format(fixed_deg)
else:
line = tile[index,:]
per_deg = width/tile.shape[1]
fixed_deg = -1 * height/tile.shape[0] * index + bbox[3]
deg = bbox[0]
title = 'height at {} degrees latitude'.format(fixed_deg)
heights = []
heights_err = []
degrees = []
for k in range(len(line)):
R = line[k,0]
G = line[k,1]
B = line[k,2]
try:
heights.append(calc_height_chiriin_style(R, G, B, u))
except ValueError as e:
heights.append(0)
heights_err.append((i,j))
degrees.append(deg)
deg += per_deg
fig, ax= plt.subplots(figsize=(8, 4))
plt.plot(degrees, heights)
plt.title(title)
ax.text(0.01, 0.95, 'Errors: {}'.format(len(heights_err)), transform=ax.transAxes)
plt.show()
それでは上高地までの標高の変化をプロットして確認してみましょう。
plot_height(gdem_img, 100, 1, z, x, y)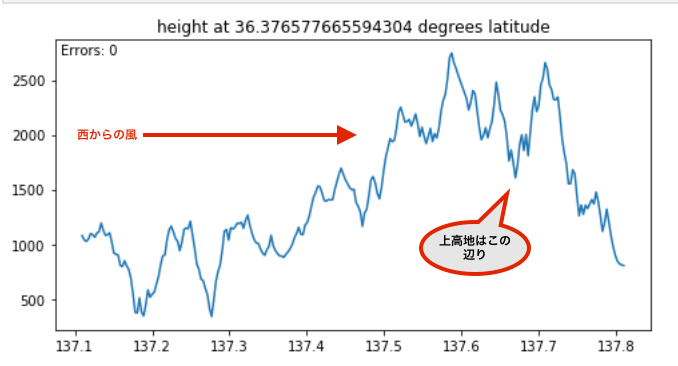
西からの風が吹いた場合、標高1,500mの上高地に至るまでに2,000mを超えるアルプスの山々を超えて風が届いているであろうことが標高データから読み取れました。
では、実際に西からの風が強まったときに天候が悪くなるのか、確認していきます。
4.AMeDASデータから風量と雨量の関係をみる
AMeDASデータの取得および保存
それでは早速、AMeDASからデータを取得してみたいと思います。
必要なライブラリを読み込んでいきます。
import os, requests, json
import pandas as pd
from datetime import datetime, date, timedelta
import math
from time import sleep
%matplotlib inline
TOKEN = "ここに自身のAPIトークンを貼り付けてください"
HOST = "https://gisapi.tellusxdp.com"
必要な関数を定義していきます。詳細はコードを見ていただくとして、定義している関数の一覧は下記のようになります。
- ●TellusAPIを呼び出す汎用関数(get_api_data)
- ●タイル座標から緯度経度を取得する(get_tile_bbox)
- ●AMeDASの1分間ごとのデータを取得する(get_amedas_1min)
def get_api_data(url, params={}):
"""
TellusAPIからデータを取得する
"""
headers = {
"content-type": "application/json",
"Authorization": "Bearer " + TOKEN
}
return requests.get(url, headers = headers, params = params)
def get_tile_bbox(z, x, y):
"""
タイル座標からバウンディングボックスを取得する
https://tools.ietf.org/html/rfc7946#section-5
Parameters
----------
z : int
タイルのズーム率
x : int
タイルのX座標
y : int
タイルのY座標
Returns
-------
bbox: tuple of number
タイルのバウンディングボックス
(左下経度, 左下緯度, 右上経度, 右上緯度)
"""
def num2deg(xtile, ytile, zoom):
# https://wiki.openstreetmap.org/wiki/Slippy_map_tilenames#Python
n = 2.0 ** zoom
lon_deg = xtile / n * 360.0 - 180.0
lat_rad = math.atan(math.sinh(math.pi * (1 - 2 * ytile / n)))
lat_deg = math.degrees(lat_rad)
return (lon_deg, lat_deg)
right_top = num2deg(x + 1, y, z)
left_bottom = num2deg(x, y + 1, z)
return (left_bottom[0], left_bottom[1], right_top[0], right_top[1])
def get_amedas_1min(year, month, day, hour, minute, payload={}):
"""
/api/v1/amedas/1minを叩く
Parameters
----------
year : string
西暦年 (4桁の数字で指定) UTC
month : string
月 01~12 (2桁の数字で指定) UTC
day : string
日 01~31 (2桁の数字で指定) UTC
hour : string
時 00~23 (2桁の数字で指定) UTC
minute : dict
分 00~59 (2桁の数字で指定) UTC
payload : dict
パラメータ(min_lat,min_lon,max_lat,max_lon)
Returns
-------
content : list
結果
"""
path = '/api/v1/amedas/1min/{}/{}/{}/{}/{}/'.format(year, month, day, hour, minute)
url = HOST + path
r = get_api_data(url, params=payload)
if r.status_code is not 200:
raise ValueError('status error({}).'.format(r.status_code))
return json.loads(r.content)
それでは関数の準備ができたところで、実際にAMeDASのデータを取得していきます。まずはTellusOS上にて、取得する対象のタイル座標を確認します。ある程度広域な範囲のデータを取得したいので、ズームレベルを6としています。
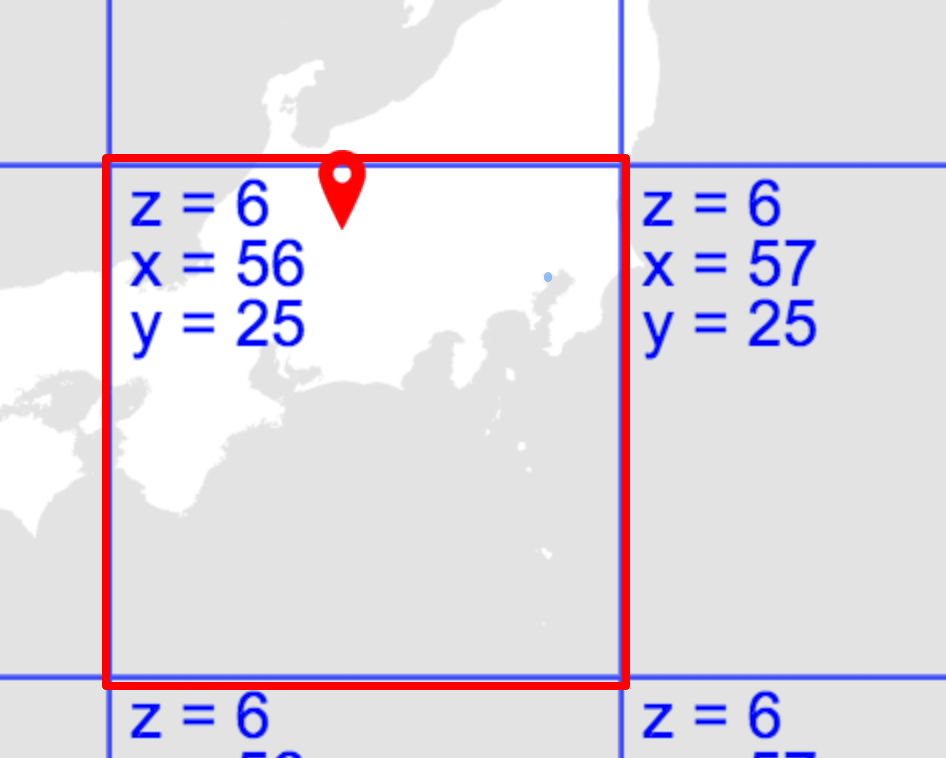
確認したタイル座標を変数に設定し、AMeDASのデータを取得します。こちらの処理は非常に時間がかかります(およそ24時間ぐらい)。気長にお待ちいただけたらと思います。
# 北アルプス周辺のタイル座標を指定
z = 9
x = 451
y = 200
bbox = get_tile_bbox(z, x, y)
# 対象領域の左下の緯度、経度を確認
print(bbox[1], bbox[0])
# 対象領域の右上の緯度、経度を確認
print(bbox[3], bbox[2])
# 北アルプス周辺の緯度経度範囲を指定
payload = {
'min_lon': bbox[0],
'min_lat': bbox[1],
'max_lon': bbox[2],
'max_lat': bbox[3]
}
print(payload)
columns = ['station_no', 'datetime', 'date', 'time', 'rain', 'wind', 'wind_direction', 'lon', 'lat']
df = pd.DataFrame([], columns=columns)
# 2017年10月北アルプス周辺の観測所データを1分間おきに取得する
for day in range(1, 32):
print('day: ', day)
for hour in range(0, 24):
for min in range(0, 60):
amedas_data = get_amedas_1min('2017', '10', str(day), str(hour), str(min), payload)
dt = datetime(2017, 10, day, hour = hour, minute = min)
d, t = str(dt).split() # 日別、時間別の分析がしやすいように、日時と時間を分割して格納する
amedas_df = pd.DataFrame(list(map(lambda amedas:
[
str(amedas['station']['prefecture_no']['value']).zfill(2) + str(amedas['station']['observatory_no']['value']).zfill(3),
dt, # 日時
d, # 日付
t, # 時刻
amedas['rain']['intensity']['value'] / 10, # 雨量
amedas['wind']['velocity_ave']['value'] / 10, # 風量
amedas['wind']['direction_ave_16direction']['value'], # 風向き
amedas['coordinates'][0], # 経度
amedas['coordinates'][1], # 緯度
]
, amedas_data)), columns=columns)
df = df.append(amedas_df)
# APIへの負荷軽減のため、300msごとにアクセスする
sleep(0.3)
df.to_csv('alpes_amedas_all_data.csv', index = False)
データが取得できたら、再度保存したCSVファイルから読み込み直します。その際、異常値があるので、前後のデータで補完しています。
df = pd.read_csv('alpes_amedas_all_data.csv')
# 異常値は前後のデータで補完する
df[df['rain'] > 200000000] = None
df['rain'] = df['rain'].interpolate()
df[df['wind'] > 200000000] = None
df['wind'] = df['wind'].interpolate()
観測所の可視化
取得できたAMeDASデータから、ある日のデータだけを抜き出し、観測所の位置を地図上にプロットしてみます。地図の描画にはfoliumというライブラリを使いますので、そちらを別途読み込みます。
!conda install -y folium
import folium
a_day = df[df['datetime'] == '2017-10-01 06:00:00']
# 奥穂高岳 緯度: 36.2892 経度: 137.648018
center_lat = 36.2892
center_lon = 137.648018
_map = folium.Map(location=[center_lat, center_lon], zoom_start=10)
for k, v in a_day.iterrows():
folium.Marker([v.lat, v.lon], popup=str(v['station_no']), icon=folium.Icon()).add_to(_map)
_map
今回は北アルプス近辺の雨量と風の関係を調べたいので、下記の地図にあるように「雨量のデータ」を上高地観測所から、「風量のデータ」を神岡観測所(北西)、高山観測所(南西)、松本今井観測所(南東)、穂高観測所(北東)と上高地観測所に対し4方向に位置する観測所からそれぞれ取得することにします。
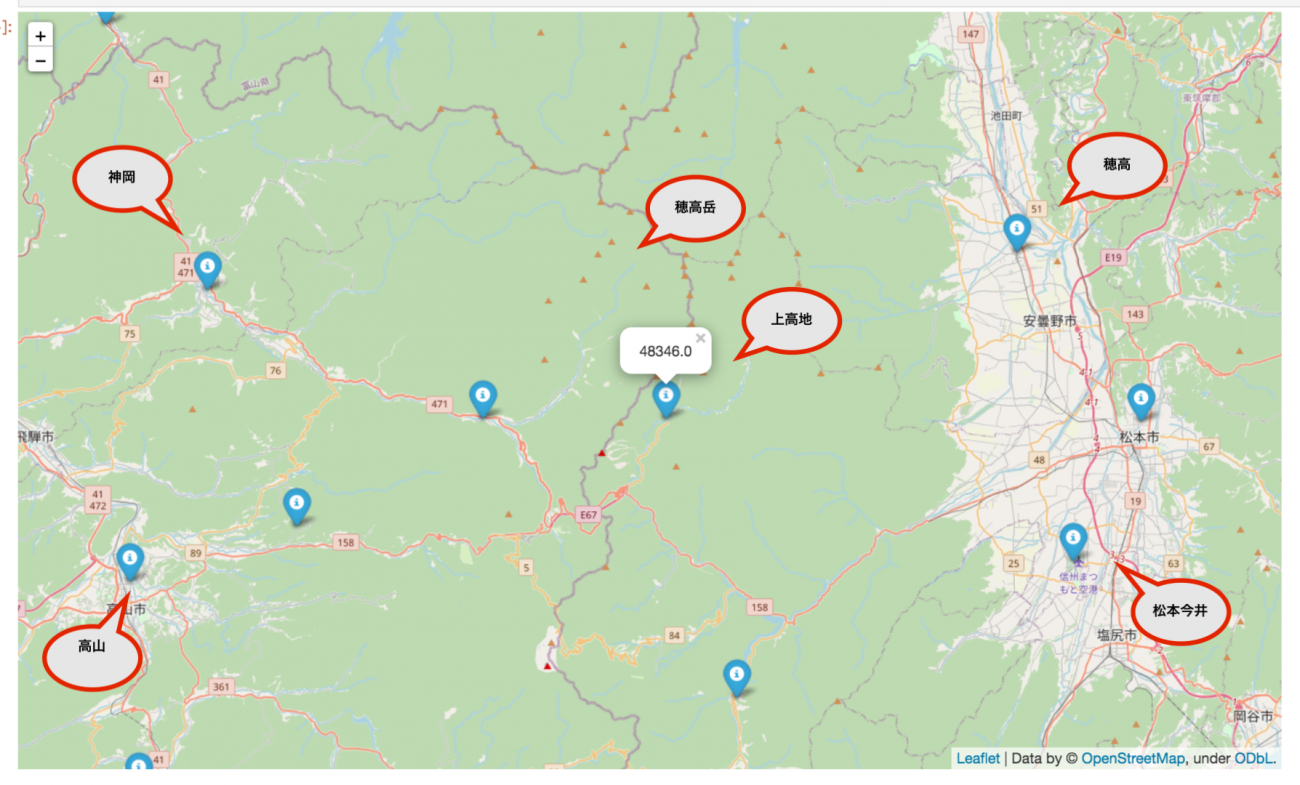
風量・雨量データの分析
観測所番号から対象となる観測所のデータを取り出します。
# 神岡観測所
kamioka = df[df['station_no'] == 52051]
# 高山観測所
takayama = df[df['station_no'] == 52146]
# 松本今井観測所
matsumotoimai = df[df['station_no'] == 48363]
# 穂高地観測所
hotaka = df[df['station_no'] == 48296]
# 上高地観測所
kamikouchi = df[df['station_no'] == 48346]
また、データを扱いやすくするために時刻に関するデータを少し整形しています。
def add_date_hour(df):
# 時刻だけを抽出したカラムを追加
df['hour'] = df['time'].apply(lambda t: t[:2])
# 日時と時刻を繋げたカラムを追加
df['date_hour'] = df['date'] + " " + df['hour'] + ":00"
return df
kamioka = add_date_hour(kamioka)
takayama = add_date_hour(takayama)
matsumotoimai = add_date_hour(matsumotoimai)
hotaka = add_date_hour(hotaka)
kamikouchi = add_date_hour(kamikouchi)
方角を北西、南西、南東、北東の4方向に集約するための関数を定義します。
def separated_directions(df):
columns = ['wind_ne', 'wind_se', 'wind_sw', 'wind_nw']
directions_df = pd.DataFrame(columns=columns, index=df.index)
for k, row in df.iterrows():
direction = row['wind_direction']
direction_df = pd.DataFrame([[0, 0, 0, 0]],
columns = columns,
index = [k])
# '北北東', '北東', '東北東', '東' は'北東(wind_ne)'としてまとめる。
if direction in {1, 2, 3, 4}:
direction_df['wind_ne'] = row['wind']
# '東南東', '南東', '南南東', '南' は'南東(wind_se)'としてまとめる。
elif direction in {5, 6, 7, 8}:
direction_df['wind_se'] = row['wind']
# '南南西', '南西', '西南西', '西' は'南西(wind_sw)'としてまとめる。
elif direction in {9, 10, 11, 12}:
direction_df['wind_sw'] = row['wind']
# '西北西', '北西', '北北西', '北' は'北西(wind_nw)'としてまとめる。
elif direction in {13, 14, 15, 16}:
direction_df['wind_nw'] = row['wind']
directions_df.update(direction_df)
return directions_df
上記の関数を使って各観測所の風量を4方向で集約したカラムを追加していきます。
kamioka = pd.concat([kamioka, separated_directions(kamioka)], axis=1)
takayama = pd.concat([takayama, separated_directions(takayama)], axis=1)
matsumotoimai = pd.concat([matsumotoimai, separated_directions(matsumotoimai)], axis=1)
hotaka = pd.concat([hotaka, separated_directions(hotaka)], axis=1)
そしてデータを1時間ごとの最大値を使用するように、集計していきます。
# 北東、南東、南西、北西の風の1時間合計値をそれぞれの観測所で集計
total_wind_nw = kamioka.groupby(['station_no', 'date_hour'], as_index=False).agg({'wind_nw': 'max'})[['date_hour', 'wind_nw']]
total_wind_sw = takayama.groupby(['station_no', 'date_hour'], as_index=False).agg({'wind_sw': 'max'})[['date_hour', 'wind_sw']]
total_wind_se = matsumotoimai.groupby(['station_no', 'date_hour'], as_index=False).agg({'wind_se': 'max'})[['date_hour', 'wind_se']]
total_wind_ne = hotaka.groupby(['station_no', 'date_hour'], as_index=False).agg({'wind_ne': 'max'})[['date_hour', 'wind_ne']]
total_rain = kamikouchi.groupby(['station_no', 'date_hour'], as_index=False).agg({'rain': 'sum'})
作成した各風量のデータをプロットする関数を定義します。
# 10/6~10/9の期間のデータの変化をプロットする関数
def plot_three_days_value(df, value, color):
plt.figure(figsize=(100,30))
target = df[120:216]
x = target['date_hour']
y = target[value]
plt.plot(x, y, color=color, lw=5)
それでは、雨量のデータとともにグラフにプロットしてそれぞれの傾向を見てみましょう。
plt.ylim([0,10])
plot_three_days_value(total_wind_nw, 'wind_nw', color="red")
plot_three_days_value(total_wind_sw, 'wind_sw', color="pink")
plot_three_days_value(total_wind_se, 'wind_se', color="gray")
plot_three_days_value(total_wind_ne, 'wind_ne', color="green")
plt.ylim([0,50])
plot_three_days_value(total_rain, 'rain', color="blue")
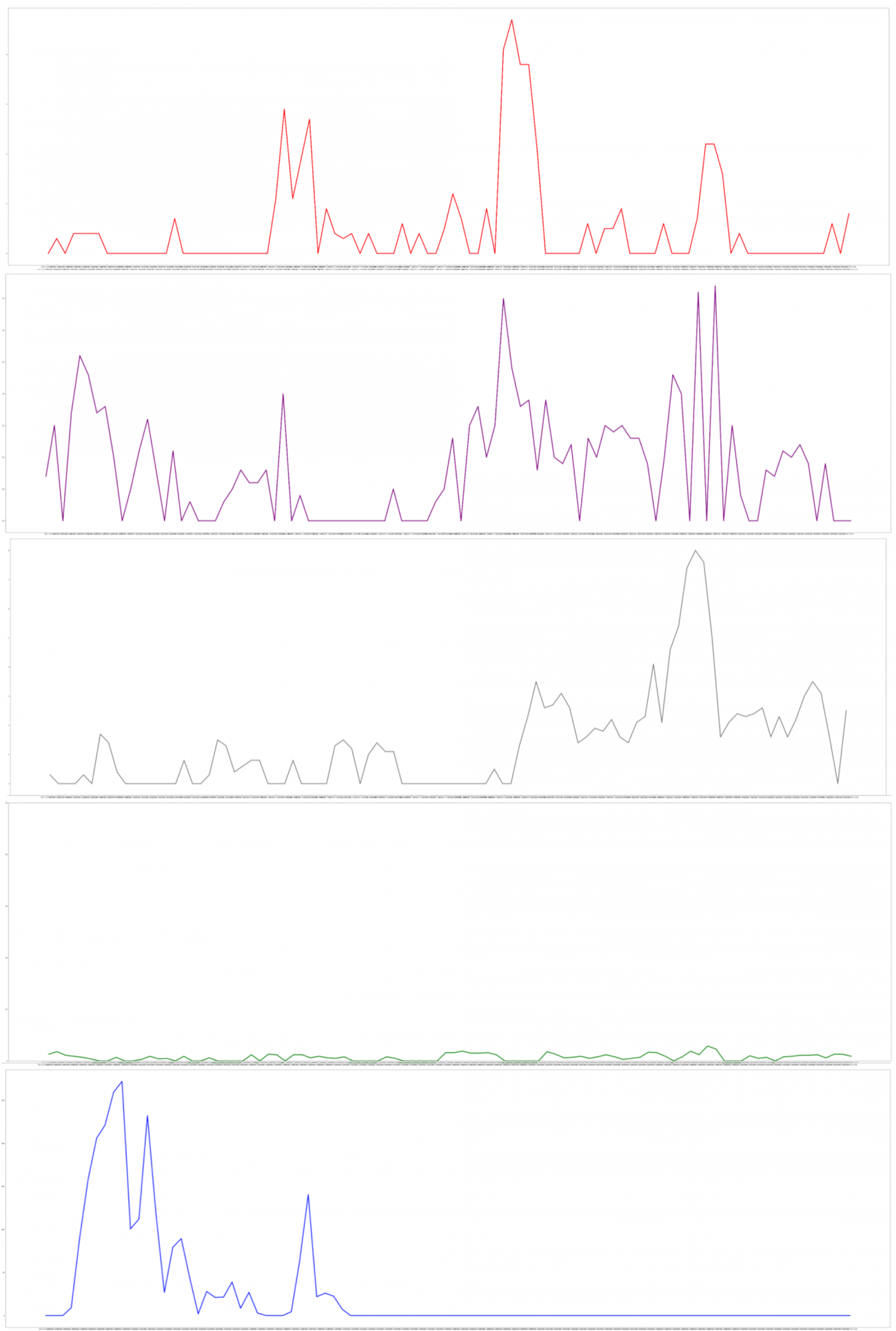
グラフだけを見ると、明確な傾向は読み取れなさそうですね。
そこで次に、scikit-learnというライブラリを使って、各方角からの風量と雨量の関係を定量的に分析していみたいと思います。
scikit-learnによる回帰分析
まず、対象となる10月06日から10月09日のデータだけを取り出す関数を定義します。
def get_three_days_data(df):
return df[120:216]対象となるデータは下記の範囲になります。
get_three_days_data(total_rain)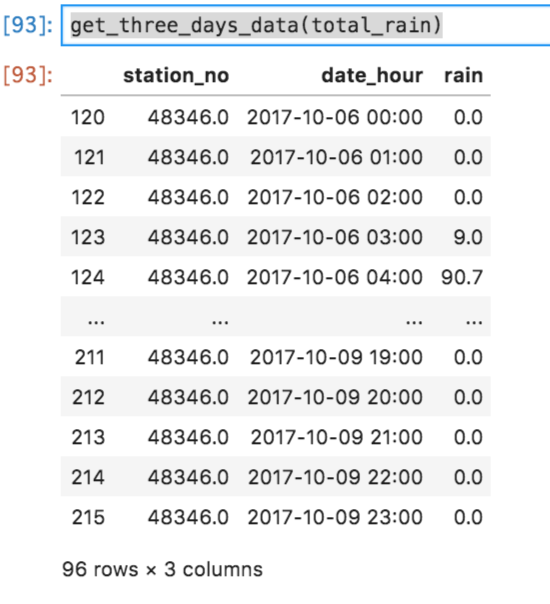
それではscikit-learnによる回帰分析を行っていきたいと思います。scikit-learnおよび回帰分析についての説明はネット上に詳細な記事がたくさん書かれていますのでここでは触れないことにします。例えば下記の記事などを参考にしてください。
それでは、回帰分析を実行します。予測では、偏西風の吹く方角である西から吹く風が雨量に強く影響を与えているのではないかと思いますが、果たして結果は…
from sklearn import linear_model
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
model = linear_model.LinearRegression()
# 説明変数には 4方向の風量 を利用
X = pd.concat([
get_three_days_data(total_wind_nw)['wind_nw'],
get_three_days_data(total_wind_sw)['wind_sw'],
get_three_days_data(total_wind_se)['wind_se'],
get_three_days_data(total_wind_ne)['wind_ne'],
], axis=1)
# 目的変数は上高地観測所の雨量
y = get_three_days_data(total_rain)['rain'].values.reshape(-1, 1)
# 予測モデルを作成
model.fit(X, y)
# 偏回帰係数
print(X.columns)
print(model.coef_)
# 切片 (誤差)
print(model.intercept_)

出力結果の2行目を見ますと、南西の風がもっとも影響が大きく、他の風はむしろ吹くほど雨量を減らす方向に働くという結果が出ています。
次に、風が吹く時間帯とその後の雨量に影響が出るまでの時差を考慮してみたいと思います。これは、風を観測すると同時に雨雲ができるのではないため、その時差も考慮しておくためです。具体的には、風が吹いてから雲ができ、雨に変わるまでに24時間の時差が生じると考え、データの時間帯を24時間分ずらしてもう一度回帰分析を行なってみます。
24時間ずらしたデータは下記のようになります。
get_three_days_data(total_wind_ne.shift(24))
それでは再び回帰分析を行なってみます。
from sklearn import linear_model
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
model = linear_model.LinearRegression()
# 説明変数には 4方向の風量 を利用
X = pd.concat([
get_three_days_data(total_wind_nw.shift(24))['wind_nw'],
get_three_days_data(total_wind_sw.shift(24))['wind_sw'],
get_three_days_data(total_wind_se.shift(24))['wind_se'],
get_three_days_data(total_wind_ne.shift(24))['wind_ne'],
], axis=1)
# 目的変数は上高地観測所の雨量
y = get_three_days_data(total_rain)['rain'].values.reshape(-1, 1)
# 予測モデルを作成
model.fit(X, y)
# 偏回帰係数
print(X.columns)
print(model.coef_)
# 切片 (誤差)
print(model.intercept_)

今度は北西の風が11.65…と雨量に対して正の作用を及ぼすとの結果が出ました。
また、あらためて、24時間前の南東の風および北西の風、そして雨量の関係をグラフにして確認してみます。
plt.ylim([0,10])
plot_three_days_value(total_wind_nw.shift(24), 'wind_nw', color="red")
plot_three_days_value(total_wind_sw.shift(24), 'wind_sw', color="pink")
plot_three_days_value(total_wind_se.shift(24), 'wind_se', color="yellow")
plot_three_days_value(total_wind_ne.shift(24), 'wind_ne', color="green")
plt.ylim([0,50])
plot_three_days_value(total_rain, 'rain', color="blue")
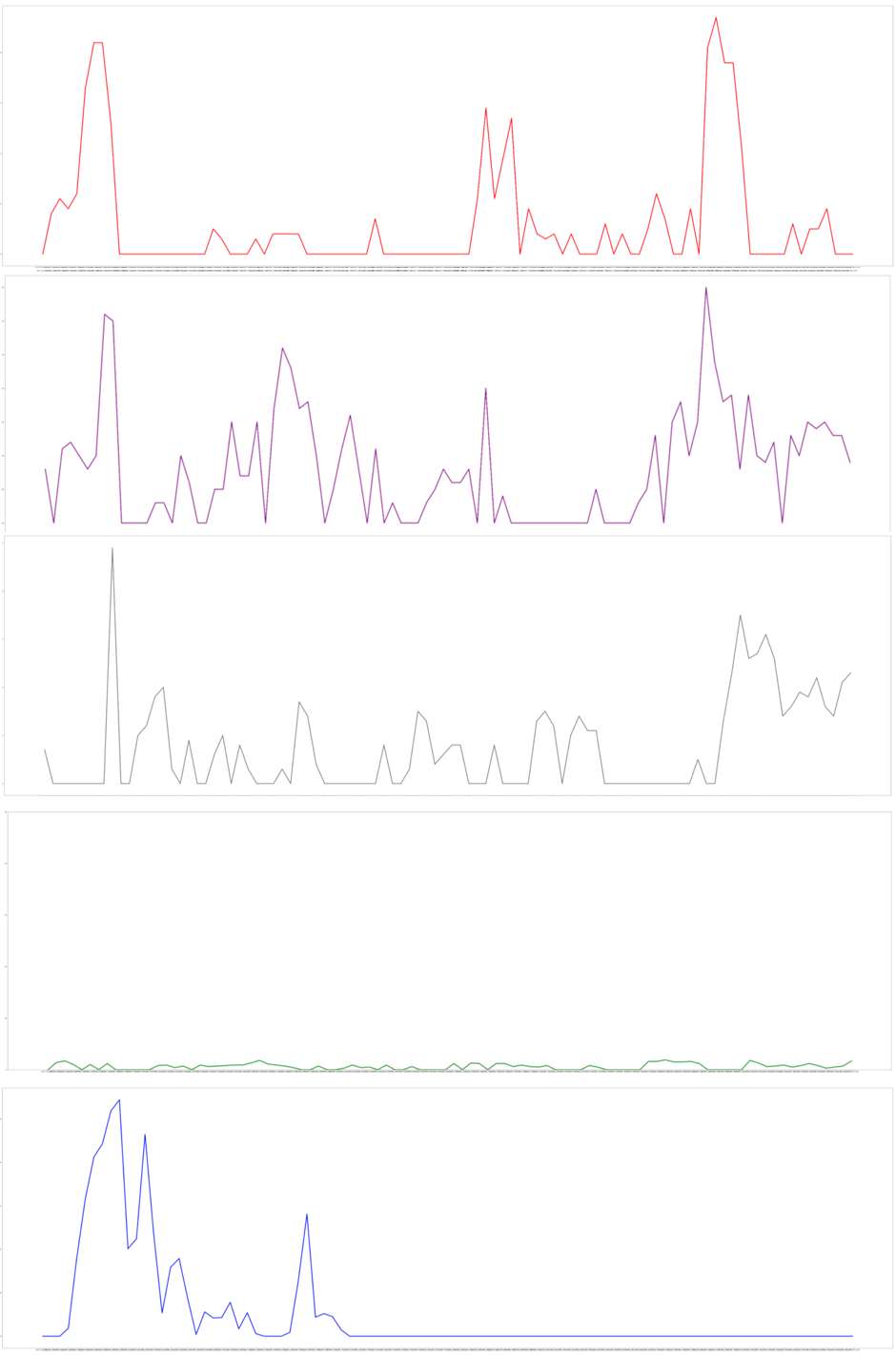
このグラフを見ると1枚目の北西の風の10月5日ごろの風量のグラフと、10月6日の雨量のグラフと立ち上がり方は似ているように見えます。このことから北西の風が吹くと、翌日の北アルプス近辺の雨量に影響を与えることがある、ということが言えそうです。
しかし、同様に北西の風が吹いた場合でも、北アルプス近辺での雨量に影響しない日も見て取れます。これには風量以外の湿度などの要因も多分に影響しているのではないかと考えられます。この辺りはさらに検証の余地がありそうです。
5. 違う日程の風量と雨量の関係も見てみる
次に日にちに変えて、同様の結果が得られるかを検証してみます。
再びYAMAPから同時期の北アルプス山行記録の記述を参考にしています。
2017.10.12(木) 2 DAYS 秋の涸沢,パノラマコース2017 槍ヶ岳・穂高岳・上高地
朝から雨の中、雨具を着けて出発。雨のためか、人通りは少ない。
(中略)
二日目も雨、明日まで雨、雪などの天気予報のため、下山を決める。
10月12日から10月13日にかけて、ずっと天気が悪かったようです。この二日間に前日を加えた三日間を対象に、再び回帰分析を行ってみたいと思います。
# 10/11〜10/13の三日間のデータを取得する関数
def get_other_three_days_data(df):
return df[240:312]
# 10/11~10/13の期間のデータの変化をプロットする関数
def plot_other_three_days_value(df, value, color):
plt.figure(figsize=(100,30))
target = df[240:312]
x = target['date_hour']
y = target[value]
plt.plot(x, y, color=color, lw=5)
再び24時間分ずらした風量と、雨量の関係をグラフにしてみます。
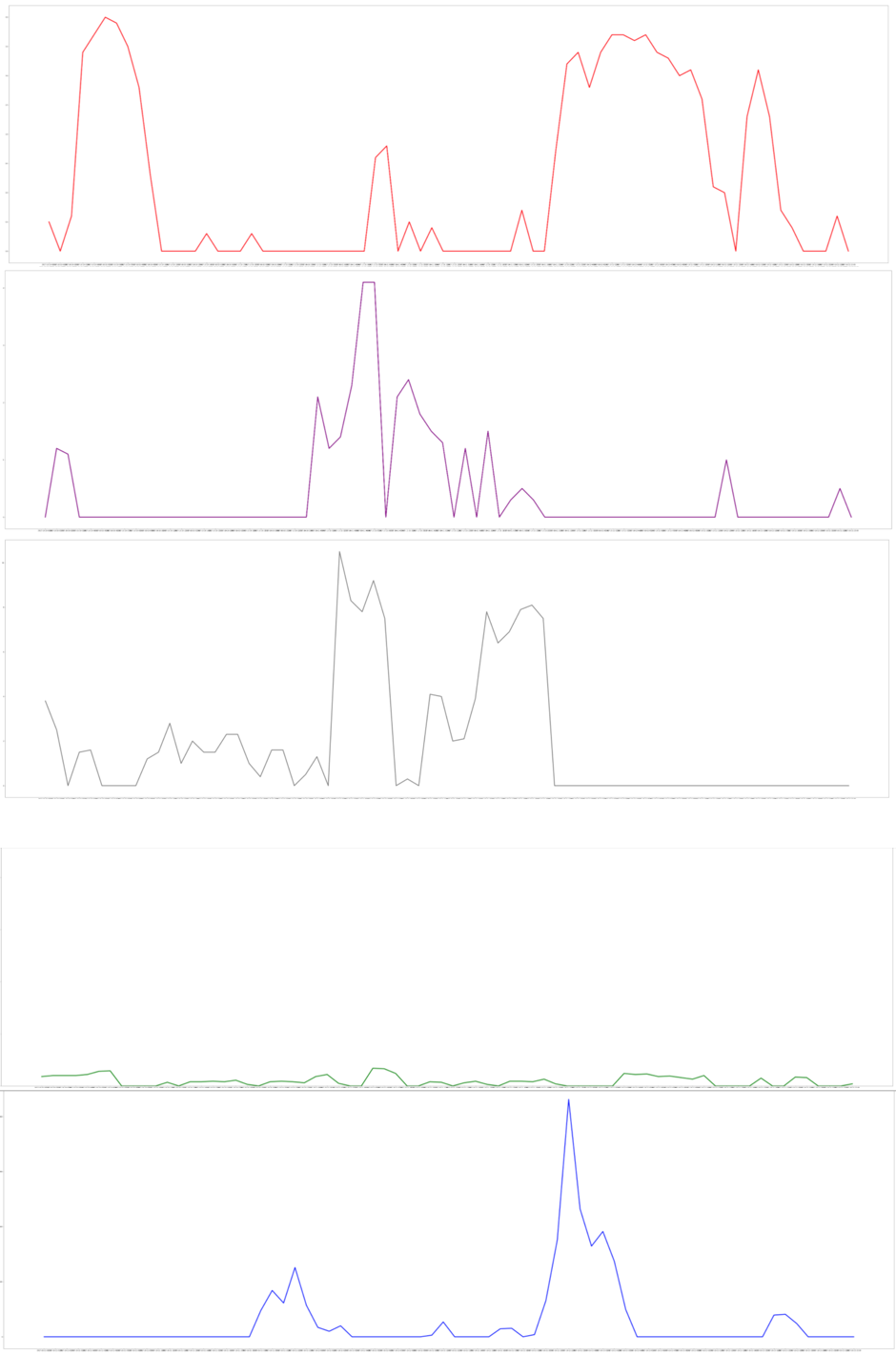
1枚目の北西の風の立ち上がりと、雨量の大きい立ち上がりがなんとなく形が似ているようにも見えますが、2枚目、3枚目の南西、南東の風も大きく変化していますので、どの向きの風が相関していてもおかしくなさそうです。
では実際に回帰分析を行ってみましょう。
from sklearn import linear_model
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
model = linear_model.LinearRegression()
# 説明変数には 4方向の風量 を利用
X = pd.concat([
get_other_three_days_data(total_wind_nw.shift(24))['wind_nw'],
get_other_three_days_data(total_wind_sw.shift(24))['wind_sw'],
get_other_three_days_data(total_wind_se.shift(24))['wind_se'],
get_other_three_days_data(total_wind_ne.shift(24))['wind_ne'],
], axis=1)
# 目的変数は上高地観測所の雨量
y = get_other_three_days_data(total_rain)['rain'].values.reshape(-1, 1)
# 予測モデルを作成
model.fit(X, y)
# 偏回帰係数
print(X.columns)
print(model.coef_)
# 切片 (誤差)
print(model.intercept_)
結果は18.13…と再び24時間前の北西の風の強さが雨量と相関しているという結果が得られました。
これらのことから当初の検証項目に挙げていた条件1の「西風が強いときに本当に天気が崩れているのか」については、降雨量と北西の風、もしくは、南西の風に正の相関があると分かったことから、当初想定していた結果が得られたと言えそうです。
ただし、今回は条件1だけを考える場合においても厳密には、以下のような検証も必要になるでしょう。
・24時間前より以前の風向きと風量、降水量の検証
・1年を通しての風向きと風量、降水量の検証
・その他の山での検証
など
また、現状の分析の課題という観点では以下のことが言えます。
・三日間のデータしか使っていない
・説明変数(特徴量)のおける分散拡大要因を考慮していない
・説明変数が風のみ(風以外を考慮してない)
・差分系列などを考慮していない
・自己相関を考慮していない
・モデル検証などがない
ぜひ本記事を読んでさらに深ぼってみたいと思われた方は試してみてください。
6.ひまわり8号の衛星画像から雲の動きを観察する
2017年10月06日から10月09日までの雲の動きを確認するために、ひまわり8号の衛星画像からそれぞれの日にちの9時〜15時台の画像を繋げたGIF画像を生成してみます。
まずは必要なライブラリを読み込みます。
from skimage import io
from io import BytesIOひまわり8号の衛星画像を取得する関数を定義します。
def get_himawari8_scene(band, yyyy, mm, dd, hhmmss, z, x, y):
url = 'https://gisapi.tellusxdp.com/himawari8/{}/{}/{}/{}/{}/{}/{}/{}.png'.format(band, yyyy, mm, dd, hhmmss, z, x, y)
r = get_api_data(url)
if r.status_code is not 200:
raise ValueError('status error({}).'.format(r.status_code))
return io.imread(BytesIO(r.content))
GIF画像を生成します。begin_dayおよびfilenameを変えることで、異なる日付のGIF画像を生成することができます。
import os
from pathlib import Path
from datetime import datetime
from datetime import timedelta
import matplotlib.pyplot as plt
import matplotlib.animation as animation
basepath = Path(os.path.expanduser('~'))
fig, ax = plt.subplots()
ims = []
begin_year = 2017
begin_month = 10
begin_day = 6
begin_hour = 6
hours = 15
interval_hours = 1
filename = './himawari20171006.gif'
band = 'B03'
z = 6
x = 56
y = 25
begin_datetime = datetime(begin_year, begin_month, begin_day, begin_hour, 20, 0, 0) - timedelta(hours=9)
end_datetime = begin_datetime + timedelta(hours=hours)
temp_start = begin_datetime
while temp_start < end_datetime:
try:
title = ax.text(0.5, 1.05, (temp_start + timedelta(hours=9)).strftime('%Y/%m/%d %H:00:00'),
ha='center', va='bottom', transform=ax.transAxes)
img = get_himawari8_scene(band, str(temp_start.year), str(temp_start.month).zfill(2), str(temp_start.day).zfill(2), temp_start.strftime('%H%M%S'), z, x, y)
ims.append([plt.imshow(img, cmap='gray'), title])
except ValueError as e:
print(e)
temp_start = temp_start + timedelta(hours=interval_hours)
ani = animation.ArtistAnimation(fig, ims)
ani.save(filename, writer='pillow')
plt.close()
from IPython.display import HTML
print(' ')
HTML('')
')
HTML('')
生成した画像は以下の通りです。

これらの画像を見ると、1枚目の10月6日の画像は確かに北東からの雲の流れが全体を覆っているのに対し、残りの3枚は日中にかかる雲の量が穏やかな様子がみて取れます。このことからも10月6日に偏西風による雲が広範囲に発生していたということが言えそうです。
7.まとめ
AMeDASのデータから風量と雨量の関係を考察してみました。今回対象とした2017年10月06日から10月09日の4日間では西からの風(=偏西風)が時間差を伴って北アルプス付近で雨となっている可能性がありそう、ということがわかりました。
異なるエリアや時期によってこの結果は大いに変わる可能性があるので注意が必要ですが、北陸のあたりで強い偏西風が吹いていることが予想される場合、翌日の登山では注意をするとよいでしょう。
今回は風向きが南寄りに変わったか否か、また、水蒸気量を検証の材料にいれておりませんがそれらの検証を行うとより山の天気が変わりやすい予兆を捉えることができるかもしれません。
また、ひまわり8号の衛星画像から、中部地方全域の雲の動きを確認してみました。より詳細な地域の雲の推移を見ることは残念ながら叶いませんでしたが、広域な範囲での雲の推移(=大まかな天気の傾向)をざっくり把握するには、ひまわり8号の衛星画像は向いています。
最後に、筆者が2018年に北アルプス穂高岳を縦走した際に、初日の悪天を乗り越えた後に見ることができたいくつかの光景を紹介させていただきます。


山の天気が変わりやすいということは、悪天候が過ぎ去った後には必ず晴天とともにご褒美のような素晴らしい景色が待ち構えている、そう捉えて天候の回復を待つことも、ある意味登山の醍醐味ではないかと思います。衛星データを使って山岳気象への理解を深めることで読者の方のアウトドアライフをより充実したものにしていただけたら幸いです。
