SSDを用いて飛行機の物体検出にチャレンジしてみた
衛星データに機械学習を使って何か面白いことをしてみたい、そんな方へ。物体検出を試してみませんか? この記事では衛星データを用いて飛行機の物体検出にチャレンジしてみました。
衛星データに機械学習を使って何か面白いことをしてみたい、そんな方へ。物体検出を試してみませんか?
この記事では衛星データを用いて飛行機の物体検出にチャレンジしてみました。飛行機の検出ができると、例えば衛星データだけを用いて空港の利用者人数の大まかな推定などができるかもしれません。また、同様の手法を用いて船や駐車場にある車の数を数えることなどもできるかと思います。
基本的には本記事のコードを順に実行していけば飛行機の物体検出ができるようになっています。記事には至らぬ点があるかと思いますが、もしコメント等がありましたら、ご連絡いただけると助かります。
では、はじめましょう。
1. 物体検出とは何か?
そもそも物体検出とは何でしょうか。例えば、画像に写っているものを「猫」か「犬」かなど、複数のクラスに分類する問題を「画像分類」と言います。それに対して、画像に何が写っているかだけではなく、何がどこに写っているかまで特定する問題を「物体検出」と言います。

よく聞く活用例としては、船舶の検出があります。実際、Tellusで主催しているTellus Satellite Challengeというコンペティションでも、過去に船舶検出がテーマとして取り上げられました(参考記事)。他にも物体検出は、車両の検出であったり災害時における土砂崩れの位置の特定などに用いられたりしており、金融から防災まで幅広い業界で使われています!
2. 物体検出の手法
物体検出の手法はたくさんありますが、有名なものだと以下があります。現在盛んに使われている手法もこれらの派生系が多いです。
・ R-CNN系 (R-CNN, Fast R-CNN, Faster R-CNN):
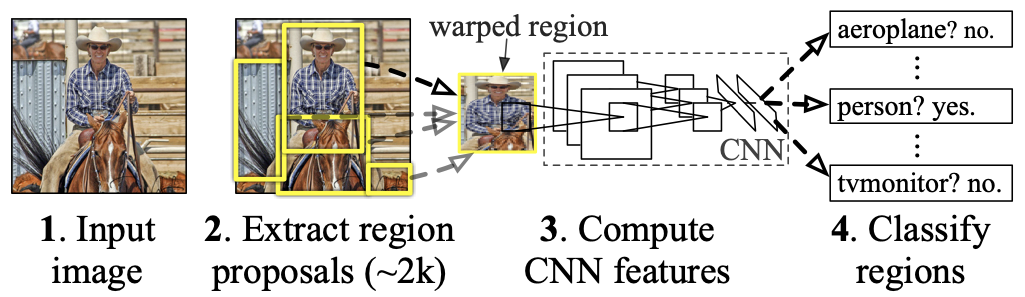
R-CNN(論文はこちら)は物体検出にCNNを持ち込んだ先駆けとなった手法です。まず画像中で物体がありそうな領域候補を絞り(Selective Search)、そこにCNNを用いて特徴量抽出を行います。その後に、得られた特徴量に対してSVM(サポートベクターマシーン)を用いて物体のクラスを分類します。
Fast R-CNNやFaster R-CNNは、クラス分類や領域候補の絞り込みにおいてもCNNを採用するなどして、計算の高速化を図ったものです。
・YOLO (論文はこちら):
一方YOLOでは、R-CNN系などで行われていた2段階のステップ(物体がありそうな領域の絞り込み、物体のクラス分類の予測)を、一つのネットワークで同時に行います。つまり、バウンディングボックスの座標とその物体が属するクラスの確率の予測を一つのネットワークで同時に出力します。そのため計算時間が大幅に短縮され、迅速な検出が可能となっています。
・SSD (論文はこちら):
YOLOと同じく、一つのネットワークで領域の検出、クラス分類を行う手法です。様々な大きさの特徴量マップを作成することにより、画像内の多様な大きさの物体を想定した特徴量を得ることができる構成になっています。今回、この記事ではこの手法を用います。
3. SSDのコードの実装の流れと全体像
コードの実装は以下のような手順で行います。
Step1: 教師データのダウンロード
Step2: 前処理
Step3: Datasetの作成
Step4: DataLoaderの作成
Step5: SSDモデルの作成
Step6: 損失関数の定義、最適化手法の設定
Step7: 学習・検証の実施
Step8: テストデータに対する推論
実装には、機械学習ライブラリーPyTorchを用いました。今回用いたコードはGitHubに載せており、以下のコマンドを実行することによりコードをご自身の開発環境にコピーできます。
git clone https://github.com/ryomaouchi/SSD_airplane_sorabtakeコードは、主に参考文献1 (書籍「つくりながら学ぶ!Pytorchによる発展ディープラーニング」)を参考にしながら、今回の問題設定に合わせて実装しました。そのため、コードは書籍のサポートリポジトリにあるコードが元にはなっていますが、大幅に改訂しているのでご注意ください。
以下が今回用いるコードの全体像です(Dataset_rareplanesとweightsというディレクトリはGitHubにはありませんが、main.ipynbの中で作成します)。各ディレクトリやファイルの補足説明を青色で書いています。
┣ main.ipynb
┃ (#一番メインの流れを記述したコード。基本的にはこれを実行していく。)
┃
┣ Dataset_rareplanes (#RarePlanesの合成教師データを格納するディレクトリ)
┃ ┣ train (#学習用データを入れる)
┃ ┃ ┣ images
┃ ┃ ┗ labels
┃ ┣ val (#検証用データを入れる)
┃ ┃ ┣ images
┃ ┃ ┗ labels
┃ ┗ test (#評価用データを入れる)
┃ ┣ images
┃ ┗ labels
┃
┣ utils (#必要となる様々なクラスや関数を定義したファイル群を格納)
┃ ┣ augumentation.py (#データの水増しを行う)
┃ ┣ dataloader.py (#データセットやデータローダーの定義を行う)
┃ ┣ ssd_model.py (#SSDのモデルの中身を記述する)
┃ ┣ loss.py (#損失関数を定義)
┃ ┗ ssd_predict_show.py (#学習したモデルによる推論を表示する)
┃
┗ weights (#学習して得られたモデルをここに保存する)
4. コードの実装
コードの全体の流れはmain.ipynbというファイルに記述されており、このコードを順に実行していけば物体検出が行えるようになっています。その際、必要なクラスや関数などはutilsというディレクトリ内のファイル群で定義しており、main.ipynbでは必要に応じてこちらから引っ張って使用します。
本記事では主にmain.ipynbについての解説を行います。utils内のクラスなどの詳細な実装の説明は、コード中のコメントアウトによる補足説明や参考文献1などをご参照していただければと思います。
また、今回の計算は以下のTellusの環境で行いました。
#########################################
・専有環境 (さくらの専用サーバ)
– CPU: Xeon Silver 4114 10Core 2.20 GHz
– メモリ: 96GB
– ディスク (RAID1): SSD480GB + SSD960GB
#########################################
ちなみに、Tellusのメモリが8GBの仮想環境のプランでもコードが動くことを確認してありますので、それぞれお持ちの環境で試すこともできると思います。
では、main.ipynbの中身を順に見ていきましょう。
[必要なライブラリのインストール]
まずは必要なライブラリをインストールしましょう。
!pip install torch==1.0.1
!pip install torchvision==0.2.1import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import os
import sys
import time
import pandas as pd
import urllib.request
import zipfile
import tarfile
import cv2
import random
import xml.etree.ElementTree as ET
from math import sqrt
from glob import glob
from itertools import product
import torch
import torch.utils.data as data
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.nn.init as init
import torch.optim as optim
from torch.autograd import Function
# utilsというディレクトリ中のファイルから必要なコードをインポートする。
from utils.augmentations import Compose, ConvertFromInts, ToAbsoluteCoords, PhotometricDistort, Expand, RandomSampleCrop, RandomMirror, ToPercentCoords, Resize, SubtractMeans
from utils.dataloader import RareplanesDataset, DataTransform, xml_to_list, od_collate_fn, get_color_mean
[Step1: 教師データのダウンロード]
次に、学習に用いる教師データをダウンロードします。今回はRarePlanesという飛行機検出のための公開データセットを用います。RarePlanesに関しては以前に宙畑の記事で詳細に解説しているので、よければご覧になってください。
RarePlanesはMaxar Worldview-3による現実の衛星データに加え、大量の合成教師データも含んでいます。合成教師データとは人工的に教師画像を合成したもので、現実の衛星データを用いた学習を補助あるいは代替するものになり得ます。今回はRarePlanesの合成データのみを学習に用います。

コードの全体像のところで書かれているように、まずはData_rareplanesというデータを入れるためのディレクトリを作り、その下にtrain, val, testというディレクトリを作ります。
RarePlanesの合成データを全てダウンロードすると容量がとても大きい(~211GB)ので、一部だけをダウンロードします。そこで、今回はファイル名がそれぞれ10, 20, 30で終わる画像だけを選び、AWSからダウンロードします。データの総容量は5.3GBになります。
Tellusで提供されている開発環境では、権限の関係で直接データを持ってくることができないため、今回はデータを一旦ローカルPCなどにダウンロードし、その後にTellusの開発環境にアップロードしました。データのダウンロードはローカルPCで以下のコマンドを打つことにより実行できます。
#学習用データのダウンロード
aws s3 cp --recursive s3://rareplanes-public/synthetic/train/images ./Data_rareplanes/train/images/ --exclude "*.png" --include "*10.png"
aws s3 cp --recursive s3://rareplanes-public/synthetic/train/xmls ./Data_rareplanes/train/labels/ --exclude "*.xml" --include "*10.xml"
#検証用データのダウンロード
aws s3 cp --recursive s3://rareplanes-public/synthetic/train/images ./Data_rareplanes/val/images/ --exclude "*.png" --include "*20.png"
aws s3 cp --recursive s3://rareplanes-public/synthetic/train/xmls ./Data_rareplanes/val/labels/ --exclude "*.xml" --include "*20.xml"
#評価用データのダウンロード
aws s3 cp --recursive s3://rareplanes-public/synthetic/train/images ./Data_rareplanes/test/images/ --exclude "*.png" --include "*30.png"
aws s3 cp --recursive s3://rareplanes-public/synthetic/train/xmls ./Data_rareplanes/test/labels/ --exclude "*.xml" --include "*30.xml"
ここで注意なのですが、このコードの実行にはAWSのアカウント作成とconfigureが必要になります。詳細はmain.ipynbをご覧ください。
これで教師データの準備が整いました。
[Step2. 前処理]
次は前処理の定義です。
画像の前処理はDataTransformというクラスで実装します。このクラスはdataloaders.pyに記述されているので、詳細はそちらを参考にして下さい。ここでは要点だけを述べます。
今回実装するSSDのモデルでは、入力画像のサイズとして300×300を仮定しています。そこでこのクラスではまず画像をこの大きさにリサイズします。
また、色情報の規格化のために、各チャンネル(B, G, R)の平均を差し引く処理を行います。そのためには、全学習画像の各チャンネルごとの平均画素値が必要になります。それを計算する関数をdataloader.pyの中のget_color_meanとして定義します。
また一般的に、学習データを適切に水増しするとモデルの精度が上がることが知られています。DataTransformではそのような水増しも行います。具体的には、画像の色調をランダムに変化、画像を反転、画像内の一部をランダムに切り出すなどの処理を行い、これらも学習画像として使用します。
[Step3. Datasetの作成]
次にデータセットを作成します。これはRareplanesDatasetというクラスで行います (詳細な実装はdataloaders.pyをご参照ください)。
まずは、学習用画像とそのアノテーション(=教師ラベル)ファイル、また検証用画像とそのアノテーションファイルへのパスを、それぞれリストに格納します。
train_image_dir = './Data_rareplanes/train/images/'
train_img_paths = glob(os.path.join(train_image_dir, '*.png'))
#学習用画像ファイルのパスリスト
val_image_dir = './Data_rareplanes/val/images/'
val_img_paths = glob(os.path.join(val_image_dir, '*.png'))
#検証用画像ファイルのパスリスト
train_label_paths = [train_img_paths[i].replace('png', 'xml',1).replace('images','labels',1) for i in range(len(train_img_paths))]
#学習用データのアノテーションファイルのパスリスト
val_label_paths = [val_img_paths[i].replace('png', 'xml',1).replace('images','labels',1) for i in range(len(val_img_paths))]
#検証用データのアノテーションファイルのパスリスト
また、今回分類を行うクラス群をリストにします(といっても一つしかありません笑)。
my_classes = ["airplane"]各画像における飛行機のアノテーション情報はxmlという形式のファイルに記述されています。ご覧になっていただくとわかるのですが、このファイルには様々な情報が記述されています。
そこで、このファイルから各飛行機のバウンディングボックスの情報をリストとして取り出すためのクラスを、xml_to_listという名前でdataloaders.pyの中に実装します。バウンディングボックスとは、飛行機を囲った四角の四隅の座標のことをいいます。
さて、これらの関数やクラスを用いて以下のようにデータセットが定義できます。
input_size = 300 #今回は入力画像を300×300にする
#学習用データセットの定義
train_dataset = RareplanesDataset(train_img_paths, train_label_paths, phase = 'train', transform = DataTransform(input_size, color_mean), transform_anno = xml_to_list(my_classes))
#検証用データセットの定義
val_dataset = RareplanesDataset(val_img_paths, val_label_paths, phase = 'val', transform = DataTransform(input_size, color_mean), transform_anno = xml_to_list(my_classes))
[Step4. Dataloaderの作成]
次に上で定義したデータセットからデータをバッチ(小さなデータの集まり)として読み出すための、データローダーを定義します。バッチサイズは今回は32とします。
batch_size = 32
train_dataloader = data.DataLoader(
train_dataset, batch_size = batch_size, shuffle = True, collate_fn = od_collate_fn
)
val_dataloader = data.DataLoader(
val_dataset, batch_size = batch_size, shuffle = True, collate_fn = od_collate_fn
)
# 辞書型としてまとめておく
dataloaders_dict = {"train": train_dataloader, "val": val_dataloader}
[Step5. SSDモデルの作成]
さて、では次にコード実装の一番の肝となるSSDのモデルを定義していきます。
SSDのネットワーク構成は以下のようになっています。
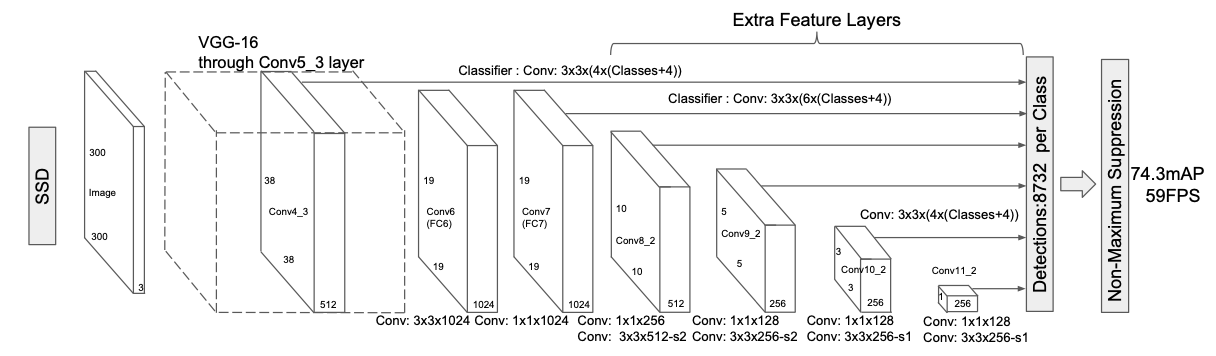
このネットワークの実装の詳細を説明するととても長くなってしまうので、詳細は参考文献1や元論文などをご覧いただけると幸いです。上のネットワーク構造をPytorchを用いて構成し、そのモデルをutils下のssd_model.pyというファイルに記述してあります。
上のネットワークは畳み込み層やMax Pooling層などの様々な層で構成されていますが、Pytorchを用いるとこれらの層はそれぞれたった一行程度のコードで記述できます。なので、複雑に見えるネットワークもレゴを組み立てるような感覚で作れてしまいます。
さて、得られたSSDモデルに対して、以下のようにしてネットワークのパラメータ設定を行います。
# utils下のssd_model.pyというファイルからSSDというクラスをインポート。
from utils.ssd_model import SSD
ssd_cfg = {
'num_classes': 2, # 背景も含めるためクラスの数は2。
'input_size': 300, # 入力画像のサイズは300×300にリサイズしている。
# 以下のパラメータの詳細は参考文献などをご覧ください。
'bbox_aspect_num': [4,6,6,6,4,4],
'feature_maps': [38,19,10,5,3,1],
'steps': [8,16,32,64,100,300],
'min_sizes': [30,60,111,162,213,264],
'max_sizes': [60,111,162,213,264,315],
'aspect_ratios': [[2],[2,3],[2,3],[2,3],[2],[2]]
}
net = SSD(phase='train', cfg = ssd_cfg)
次に、これらのネットワークの重みを初期化します。
SSDのネットワークはVGG-16をベースとしたモジュールを部分的に含みます。そこで、このモジュールに関しては、ImageNetの画像分類タスクで学習させた重みを用います。この学習済みモデルは以下のURLから入手できます。
# ディレクトリ「weights」が存在しない場合は作成する
weights_dir = "./weights/"
if not os.path.exists(weights_dir):
os.mkdir(weights_dir)
# 学習済みモデルをダウンロード
# MIT License
# Copyright (c) 2017 Max deGroot, Ellis Brown
# https://github.com/amdegroot/ssd.pytorch
url = "https://s3.amazonaws.com/amdegroot-models/vgg16_reducedfc.pth"
target_path = os.path.join(./weight, "vgg16_reducedfc.pth")
if not os.path.exists(target_path):
urllib.request.urlretrieve(url, target_path)
得られた学習済みモデルを使ってネットワークの重みを初期化します。VGGモジュール以外のモジュールに関しては、Heの初期値(参考記事例)を使用します。
# 学習済みモデルで重みを初期化
vgg_weights = torch.load('./weights/vgg16_reducedfc.pth')
net.vgg.load_state_dict(vgg_weights)
def weights_init(m):
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight.data)
if m.bias is not None:
nn.init.constant_(m.bias,0.0)
# 他の重みはHeの初期値で初期化する
net.extras.apply(weights_init)
net.loc.apply(weights_init)
net.conf.apply(weights_init)
#使用しているデバイスの定義
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
[Step6. 損失関数の定義、最適化手法の設定]
モデルの学習を行うためには、さらに、ネットワークから出力された値が教師ラベルとどれほどズレているかという指標、すなわち損失関数の定義が必要となります。
損失はクラス分類予測に起因するものと、バウンディングボックスの位置予測に起因するものの和となります。前者には交差エントロピー誤差関数を用い、後者にはSmooth L1損失関数というものを用います。実装はMultiBoxLossというクラスで行い、utils下のloss.py中に記述してあります。
# utilsというディレクトリ下のloss.pyというファイルからMultiBoxLossというクラスをインポート。
from utils.loss import MultiBoxLoss
criterion = MultiBoxLoss(jaccard_thresh=0.5, neg_pos = 3, device=device)
また、最適化手法にはPytorchに実装されているAdamを用います。
optimizer = optim.Adam(net.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)[Step7: 学習・検証の実施]
それではいよいよ学習をしていきます。そのために、train_modelという以下に定義する関数で学習の詳細を実装していきます。
def train_model(net,dataloaders_dict, criterion, optimizer, num_epochs):
# 使用デバイスの定義
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("使用Device:", device)
# (もしGPUを使用しているなら)ネットワークをGPUに渡す
net.to(device)
# ネットワークがある程度固定であれば、高速化させる
torch.backends.cudnn.benchmark = True
iteration = 1
epoch_train_loss = 0.0
epoch_val_loss = 0.0
logs = []
#学習開始
for epoch in range(num_epochs+1):
t_epoch_start = time.time()
t_iter_start = time.time()
print('------------')
print('Epoch {}/{}'.format(epoch+1, num_epochs))
print('------------')
for phase in ['train', 'val']:
if phase == 'train':
net.train()
print(' (train) ')
else:
#10エポックごとに検証用画像に対する損失を表示。
if ((epoch+1) % 10 == 0):
net.eval()
print('----------')
print(' (val) ')
else:
continue
for images, targets in dataloaders_dict[phase]:
images = images.to(device)
targets = [ann.to(device)
for ann in targets]
optimizer.zero_grad()
with torch.set_grad_enabled(phase=='train'):
outputs = net(images)
#損失関数は、バウンディングボックスの位置の予測に関するもの(=loss_l)と分類予測に関するもの(=loss_c)の和になる。
loss_l, loss_c = criterion(outputs, targets)
loss = loss_l + loss_c
if phase == 'train':
loss.backward()
nn.utils.clip_grad_value_(
net.parameters(), clip_value = 2.0
)
optimizer.step()
# 2イテレーションごとにかかった時間と損失を表示。
if (iteration % 2 ==0):
t_iter_finish = time.time()
duration = t_iter_finish - t_iter_start
print('イテレーション {} || Loss: {:.4f} || 10iter:{:.4f} sec.'.format(
iteration, loss.item(), duration))
t_iter_start = time.time()
epoch_train_loss += loss.item()
iteration += 1
else:
epoch_val_loss += loss.item()
t_epoch_finish = time.time()
print('------------')
print('epoch {} || Epoch_TRAIN_Loss:{:.4f} || Epoch_VAL_Loss:{:.4f}'.format(
epoch+1, epoch_train_loss, epoch_val_loss))
print('timer: {:.4f} sec.'.format(t_epoch_finish - t_epoch_start))
t_epoch_start = time.time()
log_epoch = {'epoch': epoch+1, 'train_loss': epoch_train_loss, 'val_loss': epoch_val_loss}
logs.append(log_epoch)
df = pd.DataFrame(logs)
df.to_csv("log_output.csv")
epoch_train_loss = 0.0
epoch_val_loss = 0.0
#10エポックごとに重みを保存する。
if ((epoch+1)%10 ==0):
torch.save(net.state_dict(),'weights/SSD300_'+str(epoch+1)+'.pth')
いよいよ、上で定義したtrain_modelという関数を用いて学習を行っていきます。
今回計算は200エポック行いました。これほど計算を回さなくてもそれなりの精度は出るので、計算が終わるのを待つのがもどかしいという方はnum_epochsを(例えば50くらいまで)減らしても良いと思います。
# 計算するエポック数
num_epochs = 200
train_model(net, dataloaders_dict, criterion, optimizer, num_epochs = num_epochs)
出力は以下のようになります。
使用Device: cpu
------------
Epoch 1/200
------------
(train)
イテレーション 2 || Loss: 3509.4802 || 10iter:52.2317 sec.
イテレーション 4 || Loss: 99.7308 || 10iter:53.4657 sec.
イテレーション 6 || Loss: 17.1309 || 10iter:51.2001 sec.
イテレーション 8 || Loss: 30.4145 || 10iter:52.1168 sec.
イテレーション 10 || Loss: 15.8940 || 10iter:52.4673 sec.
イテレーション 12 || Loss: 10.5187 || 10iter:52.4800 sec.
イテレーション 14 || Loss: 9.1825 || 10iter:46.5551 sec.
------------
epoch 1 || Epoch_TRAIN_Loss:3818.9820 || Epoch_VAL_Loss:0.0000
timer: 360.5179 sec.
------------
Epoch 2/200
------------
(train)
イテレーション 16 || Loss: 8.4894 || 10iter:50.7820 sec.
. . . . . . . . .
------------
Epoch 201/200
------------
(train)
イテレーション 2802 || Loss: 3.1097 || 10iter:54.2413 sec.
イテレーション 2804 || Loss: 3.5624 || 10iter:55.0426 sec.
イテレーション 2806 || Loss: 2.7226 || 10iter:51.6822 sec.
イテレーション 2808 || Loss: 3.2201 || 10iter:51.3310 sec.
イテレーション 2810 || Loss: 2.7209 || 10iter:52.9426 sec.
イテレーション 2812 || Loss: 3.0924 || 10iter:52.6623 sec.
イテレーション 2814 || Loss: 2.9761 || 10iter:46.9799 sec.
------------
epoch 201 || Epoch_TRAIN_Loss:41.8153 || Epoch_VAL_Loss:0.0000
timer: 364.8839 sec.
計算はnum_epoch+1で終了するのでご注意ください。
エポックに伴う損失関数の変化をプロットして見ましょう。以下のコードで表示できます。
#損失関数のプロット
log_data = pd.read_csv("log_output.csv")
#エポック10ごとに切り出す
log_data_10 = log_data[log_data["epoch"] % 10 == 0]
plt.xlabel("epoch", fontsize= 15)
plt.ylabel("Loss", fontsize= 15)
plt.plot(log_data_10["epoch"],log_data_10["train_loss"], label="Train loss")
plt.plot(log_data_10["epoch"],log_data_10["val_loss"], label="Val loss")
plt.legend(bbox_to_anchor=(0.9, 0.9), loc='upper right', borderaxespad=0, fontsize=15)
plt.show()
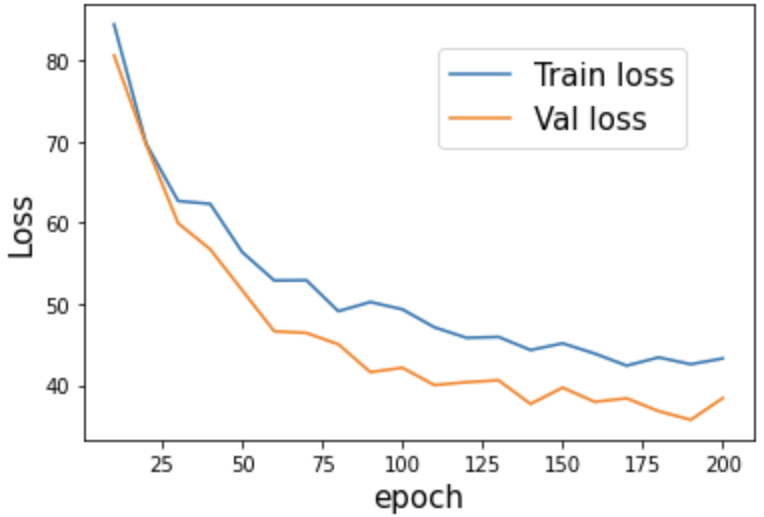
結果は下図のようになりました。損失が学習用画像と検証用画像のどちらにおいてもきちんと減少しており、エポック数が大きくなるにつれて平坦になってきていることが分かりますね。また、学習用画像と検証用画像の損失関数に大きな差がないので、過学習もさほど起こしていないと考えられます。
[Step8: テストデータに対する推論]
さて、では最後に学習したモデルを用いてテスト用画像に対して飛行機の検出を行ってみましょう。この記事ではテストデータに対する評価指標(e.g. mAP)を計算するというところまでは行わず、代表的な2枚のテスト画像に対してのみ推論をおこなってみようと思います。その2枚とは、Data_rareplanesのテスト用画像一枚と ASNARO1の成田国際空港の画像です。
そのためには、まずSSDのネットワークの設定を推論用に切り替えます。また、
上の学習で得られた最終的な重み(‘./weights/SSD300_200.pth’)を読み込みます。ここで注意点なのですが、先ほどエポック数(num_epochs)をご自身で変更なさっている場合は、読み込むファイル名も’SSD300_(設定したエポック数).pth’と変更する必要があります。
# ネットワークを推論ように切り替える
net = SSD(phase='inference', cfg = ssd_cfg)
# 上で学習した重みを読み込む
net_weights = torch.load('./weights/SSD300_200.pth', map_location={'cuda:0': 'cpu'})
net.load_state_dict(net_weights)
・Data_rareplanesのtestディレクトリ中にある一枚
それでは、テスト用画像一枚に対して表示してみましょう。
# 推論結果を表示するためのクラスSSDPredictShowをutils下のssd_predict_show.pyから読み込む
from utils.ssd_predict_show import SSDPredictShow
test_image_dir = './Data_rareplanes/test/images/'
test_img_paths = glob(os.path.join(test_image_dir, '*.png'))
# 評価用画像を一枚読み込む
img_file_path = test_img_paths[1]
ssd = SSDPredictShow(color_mean, eval_categories = my_classes, net = net)
ssd.show(img_file_path, data_confidence_level=0.3)
得られた結果を元画像と比べてみます。
・元画像

・今回の予測結果

かなり小さな飛行機までも検出できており、精度はとても良いように見えます。
でも、ふと疑問に思いますよね?
「合成教師データを使ってモデルを学習し合成教師データに対してテストするって、一回も現実の画像を扱っていないじゃん!そんなモデルは役に立つの?」
そこで次に、今回学習したモデルを現実の衛星画像であるASNAROR-1に対してテストしてみようと思います。
・ASNARO1の成田国際空港の画像
そのために、まずはASNARO-1の画像をTellusの開発環境を用いてダウンロードします。開発環境で以下のコードを実行することで成田国際空港の画像を保存できます。
今回はズームを17に設定し3×3のタイルを結合して一枚の画像にしました。複数のタイル画像を連結する方法などは宙畑のこちらの記事をご参照ください。
import requests
from skimage import io
from io import BytesIO
%matplotlib inline
TOKEN = "(自分のトークンを貼り付ける)"
def get_combined_image(get_image_func, z, topleft_x, topleft_y, size_x=1, size_y=1, option={}, params={}):
rows = []
blank = np.zeros((256, 256, 4), dtype=np.uint8)
for y in range(size_y):
row = []
for x in range(size_x):
try:
img = get_image_func(z, topleft_x + x, topleft_y + y, option, params)
except Exception as e:
img = blank
row.append(img)
rows.append(np.hstack(row))
return np.vstack(rows)
def get_asnaro1_image(z, x, y, option, params={}):
url = 'https://gisapi.tellusxdp.com/ASNARO-1/{}/{}/{}/{}.png'.format(option['entityId'], z, x, y)
headers = {
'Authorization': 'Bearer ' + TOKEN
}
r = requests.get(url, headers=headers, params=params)
if not r.status_code == requests.codes.ok:
r.raise_for_status()
return io.imread(BytesIO(r.content))
option = {
'entityId': '20190110093424839_AS1' # 成田国際空港が写っているシーン
}
z = 17 # ズーム率
x = 116650 # 起点となるタイルのx座標
y = 51570 # 起点となるタイルのy座標
#起点となるタイルから3×3枚のタイルを結合
combined = get_combined_image(get_asnaro1_image, z, x, y, 3, 3, option)
#io.imshow(combined)
io.imsave('./Narita_airport_ASNARO1_zoom17.png', combined)
コードを実行すると、Narita_airport_ASNARO1_zoom17.pngというファイルがダウンロードされます。
上で得られたASNARO-1の画像に対して、先ほど学習したモデルを用いて飛行機の検出を行ってみましょう。
from utils.ssd_predict_show import SSDPredictShow
img_file_path = "./Narita_airport_ASNARO1_zoom17.png"
ssd = SSDPredictShow(color_mean, eval_categories = my_classes, net = net)
ssd.show(img_file_path, data_confidence_level=0.3)
得られた結果の比較がこちらです(左: 元画像、右: 予測結果)。

わずかな誤検出はあるものの、全ての飛行機を検出できていることが分かります。学習には現実の衛星データは一切用いなかったのにこの精度が得られるのは驚きですね。
5. 考察・今後に向けて
本記事ではRarePlanesの合成教師データを用いて、飛行機検出のためのSSDのモデルを学習させました。ASNARO-1などの衛星画像に対して検出を行ってみましたところ、かなりの精度で飛行機を検出することができました。
今回学習したモデルなどを用いて最近の空港における飛行機の数をカウントしてやれば、たとえばコロナウイルスによる渡航自粛によって飛行機がどれほど減ったか、などが確認できるかもしれません。こちらのページにSentinel-2の衛星画像を用いてそのような問題にチャレンジした資料などが上がっているので、よければ参考にしてみてください。
また、今回は飛行機の検出を行いましたが、他の物体の検出をしてみても面白いかもしれ
ません。例えば、ショッピングモールの駐車場における車。日々の駐車場の車の数の変化をモニターすることによって、そのショッピングモールがどれほどの利益を出していそうかなどがある程度推定できると思います。他にもゴルフ場の数を数えたり、ワイン畑の数を数えたり、石油タンクの数を数えてみたりしたら何か面白いことが分かるかもしれません。
物体検出は活用の幅はとても広く夢が広がりますね。みなさんも物体検出を用いた面白そうなアイデアを思いついたらぜひ宙畑までお知らせください!
参考文献.
- 1. 小川雄太郎 著「つくりながら学ぶ!Pytorchによる発展ディープラーニング」マイナビ出版、2019年
- 2. Liu et al. (2016): SSD: Single Shot MultiBox Detector (https://arxiv.org/abs/1512.02325)
- 3. Shermeyer et al. (2020): RarePlanes: Synthetic Data Takes Flight (https://arxiv.org/abs/2006.02963)
