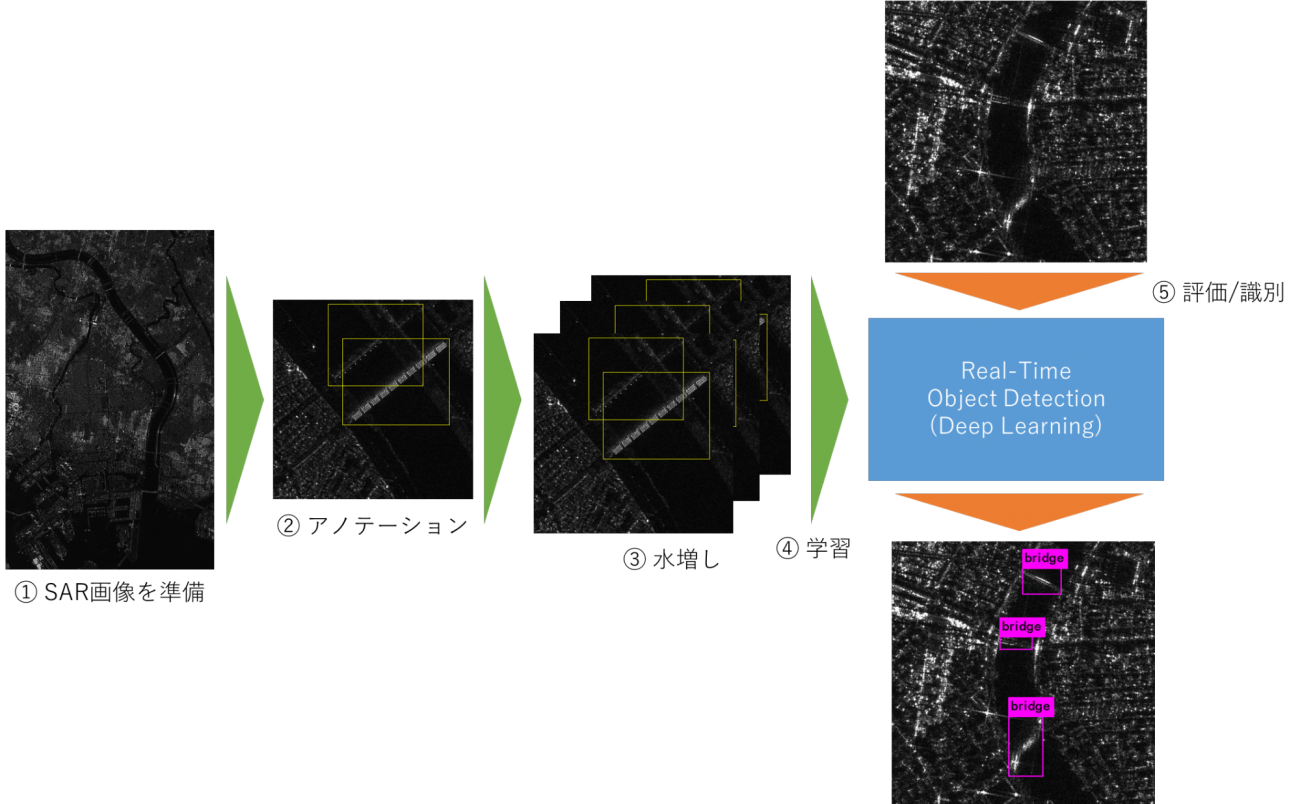
DeepLearning×SAR画像で王道の物体検出を実装!(アノテーションから学習、識別までの全工程を解説)
本稿ではSAR画像のアノテーションを行い、未学習のSAR画像を入力すると自動で物体検出(今回は橋)する識別機をDeep LearningのReal-Time Object Detection(高速処理)技術を用い実装していきます。
はじめに
本稿では、SAR画像のアノテーションを行い、未学習のSAR画像を入力すると自動で物体検出(今回は橋)する識別機をDeep LearningのReal-Time Object Detection(高速処理)技術を用い実装していきます。
Deep Learningを用いたSAR画像解析により、駐車された車の数から客入りをカウント/予測したり、海上のオイル漏れを検出したりする様々な価値あるサービスを提供する企業が増えてきました。
しかし、自身で同様のサービスを開発するには未だハードルが高いです。このようなサービスを開発するためには、次に示す2つの大きな課題があります。
・SAR画像のアノテーション(ラベル付けのこと)
・大規模画像の学習/識別
これら2つの課題をもう少し深堀りしていきます。
SAR画像のアノテーション
Deep Learningはデータを大量に学習させる必要があるため、アノテーションも大量に行わなければなりません。しかし、SAR画像は光学画像よりも判読が難しくアノテーションを行うには慣れが必要であり、容易にできることではありません。
加えて、アノテーションの誤りはDeep Learningの精度に大きく影響するため、極力排除する必要があります。このため、個人で行うには大変に厳しい作業です。この課題については、1対のペア(入力画像とラベル)を複数に分裂・コピーさせるデータ拡張(Data Augmentation)という技術である程度、緩和できるため本稿で実装及び解説していきます。
大規模画像の学習/識別
Deep LearningのObject Detectionと呼ばれるものの多くが対象にしている画像は200px以下程度の画像で、1枚あたりに1つの物体しか写っていないことが多いです。以下はDeep Learningのサンプルで良く用いられるMnistデータセットの1枚の画像(28px×28px)です。

これに対し、実画像やSAR画像の多くは1枚の画像に複数の物体が写り込んでいます。
加えて、SAR画像は一般的なデジタルカメラで撮影するよりも大きな画素数を有します。このため、Object DetectionではSAR画像を細かく切り抜きながら1枚1枚処理していかなければならず、処理が非常に遅くなる傾向があります。
この課題は、Real-Time Object Detection技術という複数の物体検出及び高速処理に特化したDeep Learningを用いることで、解決することができます。本稿では、この技術の火付け役となったYOLO v3という技術を基に実装及び解説していきます。

本稿では、読者の方が自身のタスクに対してSAR画像解析を適用できるよう、上記課題含め、開発の全工程を実装・解説していきます。最後に挑戦することを以下にまとめます。
・SARデータ(L2.1)を取得し、識別対象を決めて(今回は橋)アノテーションを行う
・Data Augmentationによりアノテーションデータの水増しを行う
・作成したデータセットをYOLO v3に学習させて、未学習データの識別を行う
Real-Time Object Detectionの技術紹介
Deep Learningを用いた一般的な物体識別(VGG-16等)は以下のように、入力画像が与えられるとその物体が何であるかの確率が出てきます。

これに対して、Real-Time Object DetectionのYOLO v3は次のような出力を行います。

これまでの物体識別とYOLO v3の大きな違いは「複数の物体を識別できる」+「高解像度画像も高速に処理できる」といった点にあります。これは非常にSAR画像向けの技術だといえるのではないでしょうか。
Real-Time Object Detectionという技術は5年位(2015)前から注目され始め、主にYOLO、SSD及びR-CNNといった技術が代表的な手法として挙げられます。これら手法は様々な派生技術が生まれてきており、現在でもなお注目されている技術です。今回は、その中でも軽量で実装も簡単なYOLOを使っていきます。
YOLOの解説はインターネット上に沢山あるため、細かな解説は行わず簡単な動作原理のみを説明します。
YOLOはエンドツーエンドネットワークとも呼ばれ、単一のネットワーク構造から構築されます。このため、画像がYOLO(ニューラルネットワーク)に入力されると、そのまま物体の位置、クラスが出力されます。途中には何の追加処理も介しません。1つの(ニューラル)ネットワークで閉じているのが特徴です。ネットワークの構造及び出力がどのようになっているのかは、YOLO作者の論文で掲載されている以下の画像が分かりやすいです。
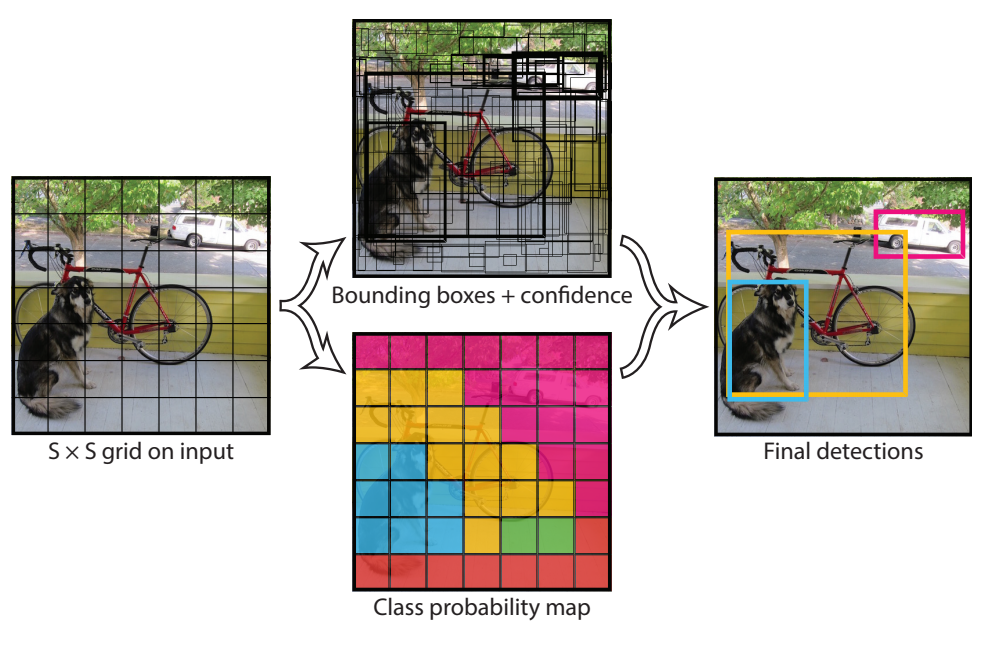
(Joseph Redmon, et.al, “You Only Look Once: Unified, Real-Time Object Detection”)
YOLOネットワークの出力は、「物体検出部」と「クラス識別部」の2つに分かれています。
「物体検出部」は面白いことに物体検出のみでクラス識別を行っていません。このため、「物体検出部」は物体の領域(矩形)を学習しているだけといえます。
一方、「クラス識別部」はどの画素がどのクラスに属するものなのかを識別しています。
勘の鋭い方は、画素情報とクラス情報が合わさった後者の「クラス識別部」のみで十分ではないか?と思われるかもしれません。
しかし、同じクラスの物体が重なりあって写っていた場合には、その境界を検出する必要があり、その役目を「物体検出部」が担っています。
このように、複数の物体検出を行うという観点で、YOLOは非常によくまとまった技術です。
最後に、YOLOネットワークの2つの出力(物体検出部及びクラス識別部)を統計的に処理することで、Final Detectionsと記されている画像が得られます。
これでYOLOの動作原理が分かったため、どのようなデータを学習させる必要があるかも分かりました。必要なデータを以下に記します。
・物体のクラス
・物体の位置 ([矩形の中心座標x] [矩形の中心座標y] [矩形の横幅w] [矩形の縦幅h])
こちらの詳細については、次項からデータセットの作成等を行っていくので順を追って解説してきたいと思います。
データセットの準備
今回は東京周辺のSAR画像を取得してデータセットを構築していきます。
東京といえば川が多いですから、架かる橋を識別対象にしたいと思います。まずはSAR画像を得るために以下のソースコードを実行します。
import os, requests
import geocoder # ! pip install geocoder
# Fields
BASE_API_URL = "https://file.tellusxdp.com/api/v1/origin/search/"
ACCESS_TOKEN = "YOUR_TOKEN"
HEADERS = {"Authorization": "Bearer " + ACCESS_TOKEN}
TARGET_PLACE = "Skytree, Tokyo"
SAVE_DIRECTORY="./data/"
# Functions
def rect_vs_point(ax, ay, aw, ah, bx, by):
return 1 if bx > ax and bx ay and by < ah else 0
def get_scene_list(_get_params={}):
query = "palsar2-l21"
r = requests.get(BASE_API_URL + query, _get_params, headers=HEADERS)
if not r.status_code == requests.codes.ok:
r.raise_for_status()
return r.json()
def get_scenes(_target_json, _get_params={}):
# get file list
r = requests.get(_target_json["publish_link"], _get_params, headers=HEADERS)
if not r.status_code == requests.codes.ok:
r.raise_for_status()
file_list = r.json()['files']
dataset_id = _target_json['dataset_id'] # folder name
# make dir
if os.path.exists(SAVE_DIRECTORY + dataset_id) == False:
os.makedirs(SAVE_DIRECTORY + dataset_id)
# downloading
print("[Start downloading]", dataset_id)
for _tmp in file_list:
r = requests.get(_tmp['url'], headers=HEADERS, stream=True)
if not r.status_code == requests.codes.ok:
r.raise_for_status()
with open(os.path.join(SAVE_DIRECTORY, dataset_id, _tmp['file_name']), "wb") as f:
f.write(r.content)
print(" - [Done]", _tmp['file_name'])
print("finished")
return
# Entry point
def main():
# extract slc list around the address
gc = geocoder.osm(TARGET_PLACE, timeout=5.0) # get latlon
#print(gc.latlng)
scene_list_json = get_scene_list({"page_size":"1000", "mode":"SM1", "left_bottom_lat": gc.latlng[0], "left_bottom_lon": gc.latlng[1], "right_top_lat": gc.latlng[0], "right_top_lon": gc.latlng[1]})
#print(scene_list_json["count"])
target_places_json = [_ for _ in scene_list_json['items'] if rect_vs_point(_['bbox'][1], _['bbox'][0], _['bbox'][3], _['bbox'][2], gc.latlng[0], gc.latlng[1])] # lot_min, lat_min, lot_max...
#print(target_places_json)
target_ids = [_['dataset_id'] for _ in target_places_json]
print("[Matched SLCs]", target_ids)
# download
for target_id in target_ids:
target_json = [_ for _ in scene_list_json['items'] if _['dataset_id'] == target_id][0]
# download the target file
get_scenes(target_json)
if __name__=="__main__":
main()
このソースコードでは隅田川、荒川に挟まれているスカイツリーが写っているSAR画像を取得しています。実行すると次のような結果が得られます。
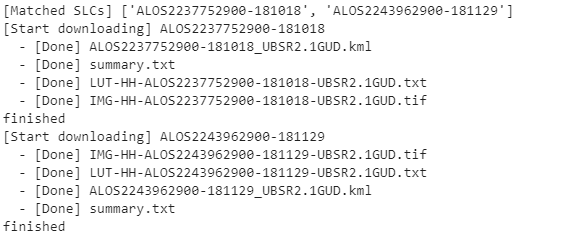
今回は取得したSAR画像の中から「ALOS2237752900-181018」を使っていきたいと思います。しかし、元画像の情報量が大きすぎるため、プログラム上で処理することが難しいです。そこで、位置情報の削減及びビット数を下げるために一度PNGに変換し、画像を切り抜きます。以下のコードを実行してください。
import os, requests, subprocess
import cv2
# Entry point
def main():
# fileds
file_name = "./data/ALOS2237752900-181018/IMG-HH-ALOS2237752900-181018-UBSR2.1GUD.tif"
output_name = file_name + ".png"
cnv_cmd = "gdal_translate -of PNG " + file_name + " " + output_name
# convert tif -> png
process = (subprocess.Popen(cnv_cmd, stdout=subprocess.PIPE,shell=True).communicate()[0]).decode('utf-8')
# read, crop and write
tmp = cv2.imread(output_name)
cropping = tmp[8800:16000, 17500:21920]
cv2.imwrite(file_name + "_cropped.png", cropping)
if __name__=="__main__":
main()
実行すると「WORKING_PATH/data/ALOS2237752900-181018/」配下に以下のファイルがあるはずです。
・IMG-HH-ALOS2237752900-181018-UBSR2.1GUD.tif.png
・IMG-HH-ALOS2237752900-181018-UBSR2.1GUD.tif_cropped.png
「IMG-HH-ALOS2237752900-181018-UBSR2.1GUD.tif_cropped.png」は次のような荒川を中心として切り抜いた画像です。

今回はこの画像をアノテーションしていきます。アノテーションで必要な要素は1つの物体を矩形で囲う左上座標、右下座標の4パラメータです。後は手作業になるので、気合で頑張りましょう。
以下のようにGIMP等の画像処理ソフトを用いて、座標情報を書き出していきましょう。

(赤丸が矩形の開始地点、左下にその座標が確認できる) Credit : original data provided by JAXA
GIMPでもいいですが、他にもVoTTやlabelimgというアノテーションツールが世の中にはありますので、読者の方の環境に合わせて適切なツールを選択いただければと思います。
この作業を終えると、次のような行列が作成できるはずです。
物体1 クラス0 300 500 350 550
物体2 クラス0 530 220 900 413
物体3 クラス0 120 500 200 600
今回、読者の方にこの作業をして頂くのは大変なので「bbox.npz」というファイルを用意しました。この中には各橋の位置情報が保存されています。用意した画像に橋の位置情報を合成すると以下のような画像が得られます。

この情報を基にデータの水増し及び学習等を行っていきます。「bbox.npz」には110個程度の橋情報が保存されています。データの水増しを行わない場合、これが1千、1万と必要になります。
データセットの水増し
これからデータセットの水増しを行うとともに、YOLO v3で学習できるデータ表現に変換していきます。
ここまでで、Tellus開発環境の中の「data/ALOS2237752900-181018/」配下に以下のファイルがある状態です。
・IMG-HH-ALOS2237752900-181018-UBSR2.1GUD.tif_cropped.png : SAR画像
・bbox.npz : 橋の位置情報
※bbox.npzはこちら からダウンロードできます。
これからSAR画像と橋の位置情報を基に、ランダム切り抜き(移動)によるデータの水増し、及びYOLO v3で学習できるデータ表現への変換を以下のコードで行います。
import os, requests, subprocess
import cv2
import copy as cp
import numpy as np
import random
# vs target
def rectvsrect(_x1, _y1, _w1, _h1, _x2, _y2, _w2, _h2):
if _x1 < _x2 and _y1 _w2 and _h1 > _h2:
return True
return False
# Entry point
def main():
# fileds
src_name = "./data/ALOS2237752900-181018/IMG-HH-ALOS2237752900-181018-UBSR2.1GUD.tif"
file_name = src_name + "_cropped.png" # previous processing
output_dir = "./data/datasets/"
src_bbox = np.load("./data/ALOS2237752900-181018/bbox.npy") # bbox
src_img = cv2.imread(file_name)
dataset_num = 1100
max_size = 416
count = 0
object_ratio = 1.0
file_list = []
# make dir
if os.path.exists(output_dir) == False:
os.makedirs(output_dir)
# start processing
print("generating datasets...")
for i in range(99999):
offset_x = random.randint(0, (src_img.shape[1] - max_size))
offset_y = random.randint(0, (src_img.shape[0] - max_size))
limit_x = offset_x + max_size
limit_y = offset_y + max_size
train_x = cp.deepcopy(src_img[offset_y:limit_y, offset_x:limit_x])
# train_x = cv2.equalizeHist(train_x[:,:,0])
view_x = cp.deepcopy(src_img[offset_y:limit_y, offset_x:limit_x])
# calculate bbox
label_str = ""
included_flag = False
for _box in src_bbox:
collision = rectvsrect(offset_x, offset_y, limit_x, limit_y, _box[0], _box[1], _box[2], _box[3])
if collision:
_box_offset_x = int(_box[0]) - offset_x
_box_offset_y = int(_box[1]) - offset_y
_box_limit_x = int(_box[2]) - offset_x
_box_limit_y = int(_box[3]) - offset_y
_box_center_w = (_box_limit_x - _box_offset_x) # box full-length in x
_box_center_h = (_box_limit_y - _box_offset_y) # box full-length in y
_box_center_x = _box_offset_x + (_box_center_w * 0.5) # box center in x
_box_center_y = _box_offset_y + (_box_center_h * 0.5) # box center in y
_box_center_w_norm = _box_center_w / max_size
_box_center_h_norm = _box_center_h / max_size
_box_center_x_norm = _box_center_x / max_size
_box_center_y_norm = _box_center_y / max_size
label_str += "0 " + str(_box_center_x_norm) + " " + str(_box_center_y_norm) + " " + str(_box_center_w_norm) + " " + str(_box_center_h_norm) + "\n"
# test view
view_x = cv2.rectangle(view_x, (_box_offset_x, _box_offset_y), (_box_limit_x, _box_limit_y), (0, 255, 255))
included_flag = True
# bridge included ?
if not included_flag and random.random() < object_ratio:
continue
# write image
output_name = output_dir + str(count)
cv2.imwrite(output_name +".png", train_x)
cv2.imwrite(output_name +"_view.jpg", view_x)
# write label
file = open(output_name + ".txt", 'w')
file.write(label_str)
file.close()
# progress
count += 1
print("Generated:", count, "/", dataset_num)
if count == dataset_num:
break
if __name__=="__main__":
main()
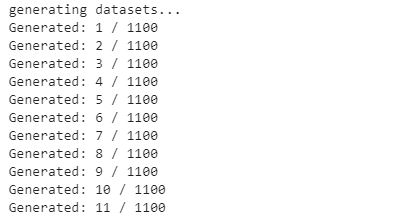
実行すると次のようなログが書き出されます。この数字は書き出されている画像の数です。全て書き出されると処理は終了します。
上記コードの簡単な説明をします。
次のコードで橋の位置情報を読み込んでいます。読み込み終わるとNumpy形式で位置情報を得ることが出来ます。
src_bbox = np.load("./data/ALOS2237752900-181018/bbox.npy") # bbox次のコードでSAR画像をランダムに切り抜いて、データの水増しを開始しています。
# start processing
print("generating datasets...")
for i in range(99999):
offset_x = random.randint(0, (src_img.shape[1] - max_size))
offset_y = random.randint(0, (src_img.shape[0] - max_size))
次のコードでデータ水増し毎にYOLO v3のデータ形式に変換しています。
_box_offset_x = int(_box[0]) - offset_x
_box_offset_y = int(_box[1]) - offset_y
_box_limit_x = int(_box[2]) - offset_x
_box_limit_y = int(_box[3]) - offset_y
_box_center_w = (_box_limit_x - _box_offset_x) # box full-length in x
_box_center_h = (_box_limit_y - _box_offset_y) # box full-length in y
_box_center_x = _box_offset_x + (_box_center_w * 0.5) # box center in x
_box_center_y = _box_offset_y + (_box_center_h * 0.5) # box center in y
_box_center_w_norm = _box_center_w / max_size
_box_center_h_norm = _box_center_h / max_size
_box_center_x_norm = _box_center_x / max_size
_box_center_y_norm = _box_center_y / max_size
label_str += "0 " + str(_box_center_x_norm) + " " + str(_box_center_y_norm) + " " + str(_box_center_w_norm) + " " + str(_box_center_h_norm) + "\n"
YOLO v3では次のようなペアデータが必要です。
入力: 画像.png
ラベル: 画像.txt
ラベルの中身は以下のように記述されている必要があります。
[クラス番号] [矩形の中心座標x] [矩形の中心座標y] [矩形の横幅w] [矩形の縦幅h]
なお、座標の数字は全て割合(真ん中なら0.5)で書かれている必要があります。
これらの処理が全て終わると「./data/datasets/」配下が次のようになります。
画像番号の後に「_view」とついているものはラベルを分かりやすく黄色の矩形で重畳した以下のような可視画像です。

YOLO v3による学習及び識別
インストール
ようやくデータセットが整備できたので、次にYOLO v3を動作させたいと思います。
まずは著者本家のGithubからYOLO v3本体を持ってきましょう。ファイルパスはご自身の好きな作業フォルダで行ってください。
$ git clone https://github.com/pjreddie/darknet.git
$ cd darknet次にMakefileを開きます。
$ vi Makefile環境に合わせてファイル冒頭5行のフラグを立てて下さい。もしGPUがある場合は1、ない場合は0等。私の環境ではGPU及びCUDNNがインストールされているので次のようになりました。
GPU=1
CUDNN=1
OPENCV=0
OPENMP=0
DEBUG=0それでは、コンパイルします。
$ make実行します。
$ ./darknet以下のようなエラーが出ていれば動作しています。
usage: ./darknet データ設置
それではYOLO v3のフォルダ内に次のようにデータを設置していきます。これからの作業は「darknet」フォルダ配下で行ってください。
darknet
| – …
|- cfg
|- task
|- datasets.data
|- class.txt
|- train.txt
|- test.txt
|- yolov3-voc.cfg
|- datasets
|- img1.png
|- img1.txt
|- img2.png
|- img2.txt
|- …
次のコマンドでフォルダを作成します。
$ mkdir cfg/bridge
$ cd cfg/bridgeこの「bridge」フォルダの中に前章で作成した「datasets」をコピーします。
次に、datasets.dataを作成します。中身は次のように書いてください。
classes= 1
train = /YOUR_PATH/darknet/cfg/bridge/train.txt
valid = /YOUR_PATH/darknet/cfg/bridge/test.txt
names = /YOUR_PATH/darknet/cfg/bridge/class.txt
backup = /YOUR_PATH/darknet/cfg/bridge/backup
`classes`はクラスの数、`train`及び`valid`はデータセットのパスが書かれたテキスト、`names`はクラスの名前、`backup`は重みの保存先です。
次にclass.txtを作成して次のように書いてください。
bridge次にtrain.txtを作成して次のように書き込んでください。
/YOUR_PATH/darknet/cfg/bridge/datasets/0.png
/YOUR_PATH/darknet/cfg/bridge/datasets/1.png
・
・
・
/YOUR_PATH/darknet/cfg/bridge/datasets/999.png
以上で全てのデータが揃いました。次にYOLO v3のネットワークを作成します。
次のコマンドでベースとなるネットワークをコピーしてください。
$ ./cfg/yolov3-voc.cfg ./cfg/bridge/yolov3-voc.cfg次にコピーした./cfg/bridge/yolov3-voc.cfgの中身を次のように書き換えます。
まず`classes`で検索すると次のような箇所が3つ引っ掛かります。
[convolutional]
size=1
stride=1
pad=1
filters=75
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=20
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
これを自身のタスクに合ったように次のように書き換えて下さい。
[convolutional]
size=1
stride=1
pad=1
#filters=75
filters=18
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=1
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
ここでfiltersの計算式は次によって求められます。
filters=mask_num * (classes + 5)これらの書き換え内容やインストール方法についてより細かく知りたい場合は次を参考にして下さい: https://qiita.com/harmegiddo/items/c3db5fd567fa4c6cc9fb
これにて事前準備終了です。
学習
それではいよいよ学習を行います。フォルダは「darknet」配下で実行します。
以下のコマンドで学習を開始できます。
$ ./darknet detector train ./cfg/bridge/datasets.data cfg/bridge/yolov3-voc.cfg学習が開始されると、次のようになります。
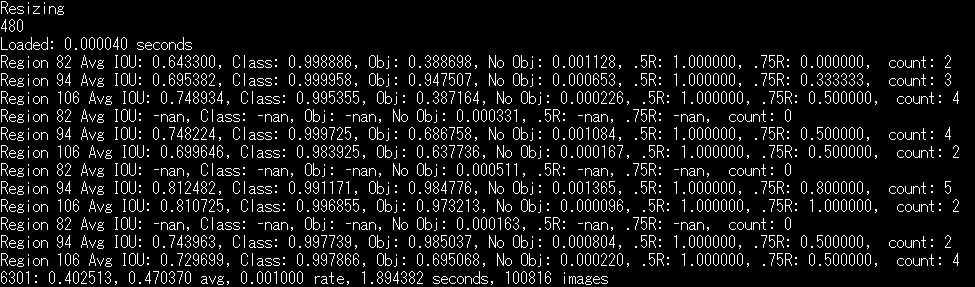
後は1万回程の学習が終わるまで待ちましょう。
識別
識別は次のコマンドで行うことが出来ます。
$ ./darknet detector test cfg/bridge/datasets.data cfg/task/yolov3-voc.cfg cfg/ bridge /backup/yolov3-voc_XXX.weight ./cfg/bridge/datasets/XXX.png -thresh 0.1XXXは適宜、書き換えて下さい。最後の`-thresh`は物体検出の閾値を示しています。ある物体である確率が10%以上のものを検出したい場合は`-thresh 0.1`になります。
これを実行すると同フォルダ配下に`predictions.png`が書き出されます。
それではテストデータの次の画像で識別を行ってみたいと思います。


見事に橋が検出されていることが分かります。
実行ログを見ると次のように表示されていました。

416×416の画像を0.4秒弱で処理できるのは非常に凄いですね!橋の確率も75%以上と答えており、十分な精度です。
評価
学習データセットに一切含まれていない異なる日付に観測されたSAR画像でも、問題なく橋を識別できるのか評価します。今回は「IMG-HH-ALOS2237752900-181018-UBSR2.1GUD」と同等の観測場所である「IMG-HH-ALOS2243962900-181129-UBSR2.1GUD」のSAR画像を用います。
入力画像

識別画像

かなり正確に橋の位置を識別できているのではないでしょうか。
右側の画像は特にビル等の建物も多く誤検知が発生しそうな画像にも関わらず、しっかりと橋を識別できています。
どちらの画像も橋の確度は7割を超えていました。一方でビル等の建物は確度でいうと2%未満で非常に信頼のできる結果となりました。
まとめ
今回は以下に示す通り、SARデータで識別したい対象(橋)を決めて、データセットを作り、Deep Learningを用いて学習、識別するといった機械学習開発を行う上での全工程の流れを実装・解説してきました。
・SARデータ(L2.1)を取得し、識別対象を決めて(今回は橋)アノテーションを行う
・Data Augmentationによりアノテーションデータの水増しを行う
・作成したデータセットをYOLO v3に学習させて、未学習データの識別を行う
全体の流れを体感頂くために、データの水増しは移動のみ等、実装を簡素にしているところもありますが、それでもかなりの精度で橋を識別することができました。
ぜひ、読者の方もご自身で識別してみたい対象で試してみては如何でしょうか。もし、さらに精度を向上させたい等の考えがある方は水増し方法に回転を加える等の工夫を凝らしてもよいかもしれません。
以上ありがとうございました。
