地理空間情報を扱うなら知っておきたいPythonライブラリ、TileDB入門~LiDAR編~
本記事では、ドローンやスマートフォンにも搭載されており身近になりつつあるLiDARデータと、様々なデータを高速で処理できるTileDBの使い方について紹介します。
地上を観測しているデータは光学画像だけではなく、様々な種類のデータがあります。これまで衛星から取得できるデータの種類については紹介してきました。
SAR(合成開口レーダ)のキホン~事例、分かること、センサ、衛星、波長~
光の波長って何? なぜ人工衛星は人間の目に見えないものが見えるのか
衛星の光学画像・SARデータは解像度が課題になる場合があるため、ドローンやUAVのデータと組み合わせて利用することで、衛星データによるソリューションが開発される場合があります。
本記事では、そのような取り組みを実践してみるため、ドローンやUAV(Unmanned aerial vehicle:無人航空機)で地上を観測したLiDAR(light detection and ranging)と呼ばれるデータを扱いました。
LiDARデータは光学画像・SARデータと形式が異なります。今回はLiDARデータの解説と、様々な形式のデータを扱い解析ができる「TileDB」を利用してLiDARデータの可視化を行いました。
衛星データによる解析に興味があれば、是非試してみてはいかがでしょうか。
(1)LiDARデータとは
①データの特性・取得方法
LiDARデータとは光を用いたリモートセンシング技術の1つで、対象物に光を照射し、その反射を光センサで取得するまでの時間を計測することで距離を計測することができます。そのため、光が反射した点を空間的に把握でき、これらを集めることで平面の画像からでは分からないような立体的な形を捉えることができます。
元々は大気の測量に利用されていたこの技術は、大気の特徴を検知できるほど精度が高く立体的な把握ができるため、現在では自動運転、自律移動型ロボット、地形の測量などの領域で利用が期待されています。
LiDARデータは点ごとに座標(X, Y, Z)の位置情報と、そのほかにGPS情報、タイムスタンプ、RGB、点の属性ラベル(分類クラス)を保存できます。そのため、建物属性の点だけを表示するなど、属性を絞って空間的に可視化することもできます。
LiDARで地表データの計測する場合は、ドローン・UAVにLiDARを搭載して上空を飛行させ計測する方法と、可搬型のLiDARを持ち運んで計測する方法があります。
可搬型のLiDARは下図のように背負って歩くことで空間的な情報を取得します。(https://dmcmaas.co.jp/2022/05/1889/)
 |
 |
②活用事例
こちらの記事(https://sorabatake.jp/14456/)でも紹介している論文では、森林の地上部バイオマス量を推定するために衛星データと合わせてLiDARデータを利用しています。LiDARデータを利用することで、地上部バイオマス量の推定精度が向上していることがわかります。(Stacked Sparse Autoencoder Modeling Using the Synergy of Airborne LiDAR and Satellite Optical and SAR Data to Map Forest Above-Ground Biomass)
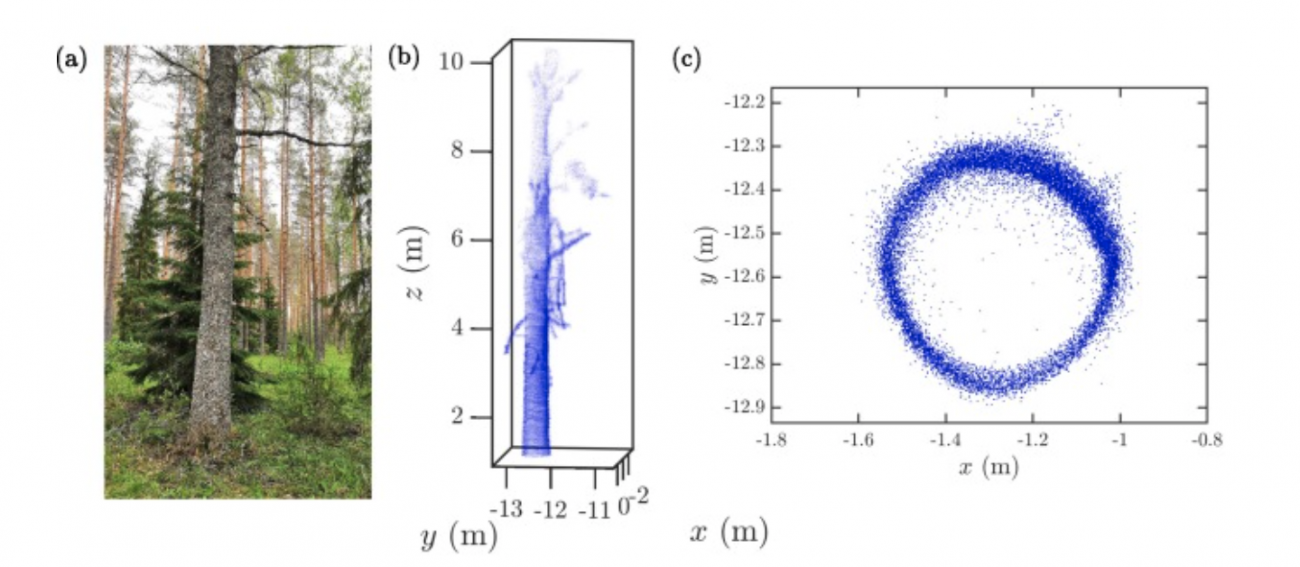
こちらの論文では森林をモニタリングするために、森林の樹冠下をLiDAR搭載のUAVで飛行し、樹木の検出や幹の直径を推定しています。この論文では樹木の検出率は100%、幹の体積推定誤差は15%以下と高く、これまでノギスやメジャーなど手作業で計測していたフィールド調査のデジタル化が期待されています。(Under-canopy UAV laser scanning for accurate forest field measurements)
(2)TileDBについて
①TileDBとは
TileDBは、様々な型のデータをシームレスかつ高速に処理できるデータベースで、多次元配列を格納するデータベース機能をクラウドで利用することができます。
そのため、画像のような平面(2次元)のデータだけではなく、LiDARの立体(3次元)データも扱いやすいという特長があります。
また、開発はJupyter Notebookインスタンスを利用できるので、コードの保存・共有が容易です。TileDB内では様々なデータを扱うチュートリアルなども公開されており、すぐに試すことができます。
②TileDBでできること
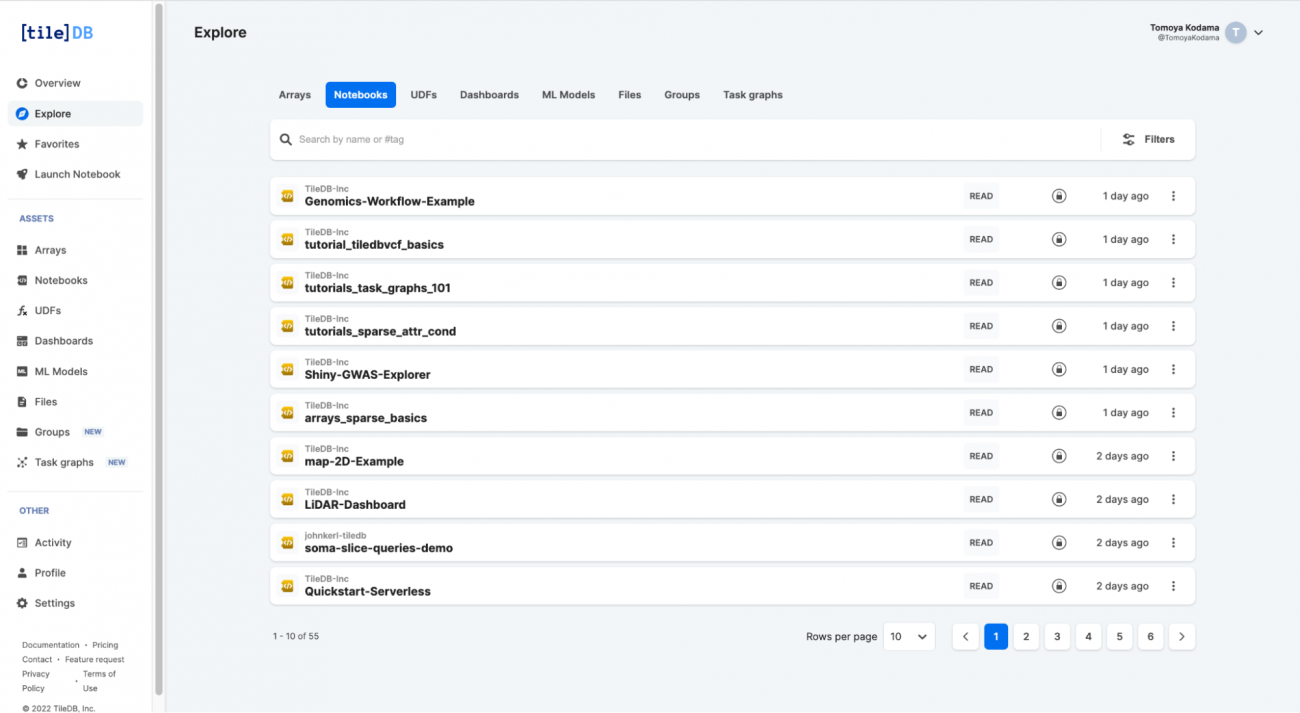
TileDBではデータ解析・開発に便利なAssetsが提供されており、様々な機能を利用できます。
| Arrays | 多次元配列データの次元数や各データの型など情報を表示 |
| Notebooks | 共有されているソースコードを検索 |
| UDFs | 関数を登録しFaas(Function as a Service)として利用 |
| DashBoards | 分析結果をダッシュボードで表示 |
| ML Models | 機械学習モデルをデプロイ |
| Files | ファイルをアップロード |
| Groups | メタデータやグループメンバーURIを含むフォルダを作成 |
| Task graphs | 関数やプロセスを可視化 |
さらにExploerから共有されているAssetsを検索でき、ExploerからNotebooksを検索することでチュートリアルのソースコードを取得することができます。
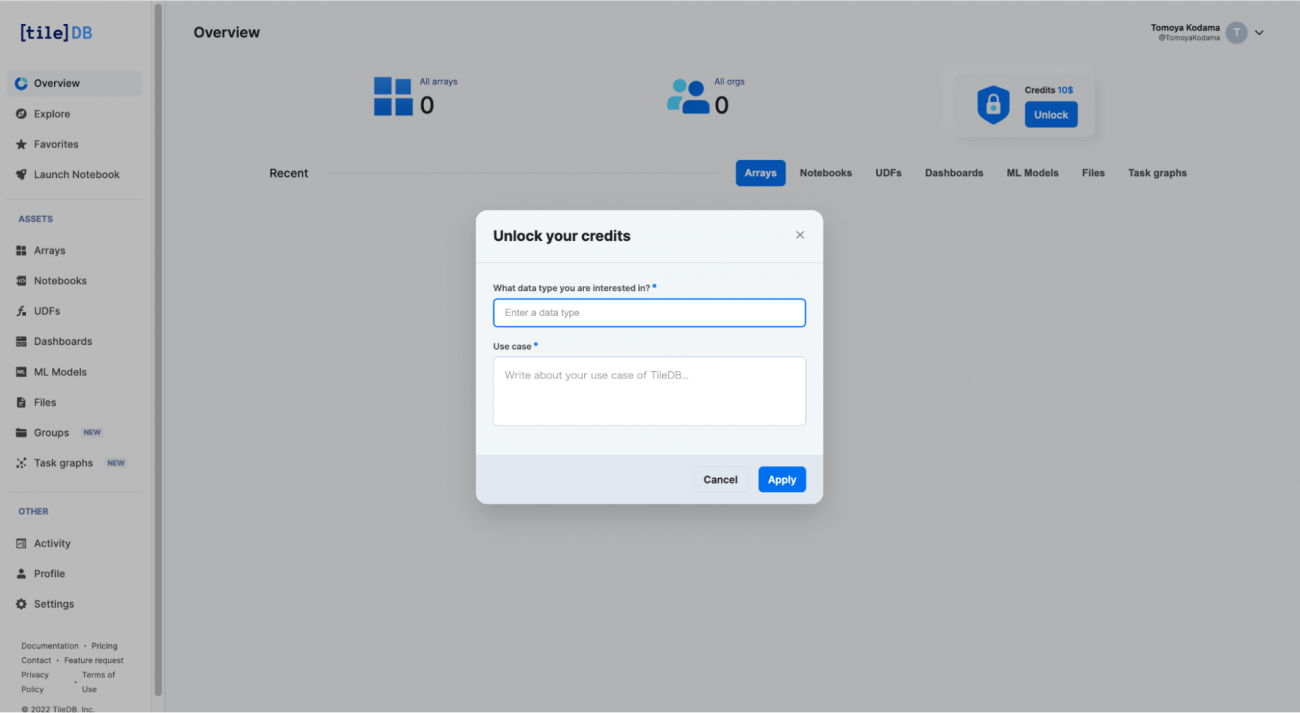
③TileDBの登録・契約について(10ドルの無料クレジット発行)
アカウントを開設すると10ドルのクレジットを受け取ることができます。クラウドの利用料に充てることができるため、はじめはTileDBのチュートリアルなどを無料で試すことができます。
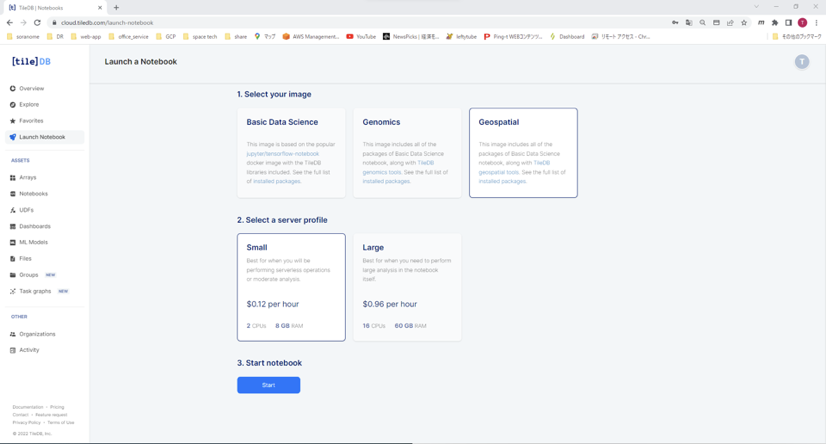
④開発環境について
開発環境は用途に応じて、マシンのスペック、インストールされているライブラリを選択することができます。マシンのスペックに応じて金額は異なります。
Small $0.12/hour:2 CPUs 8GB RAM
Large $0.96/hour:16 CPUs 60GB RAM
開発環境についてはLaunch Notebookから選択できます。
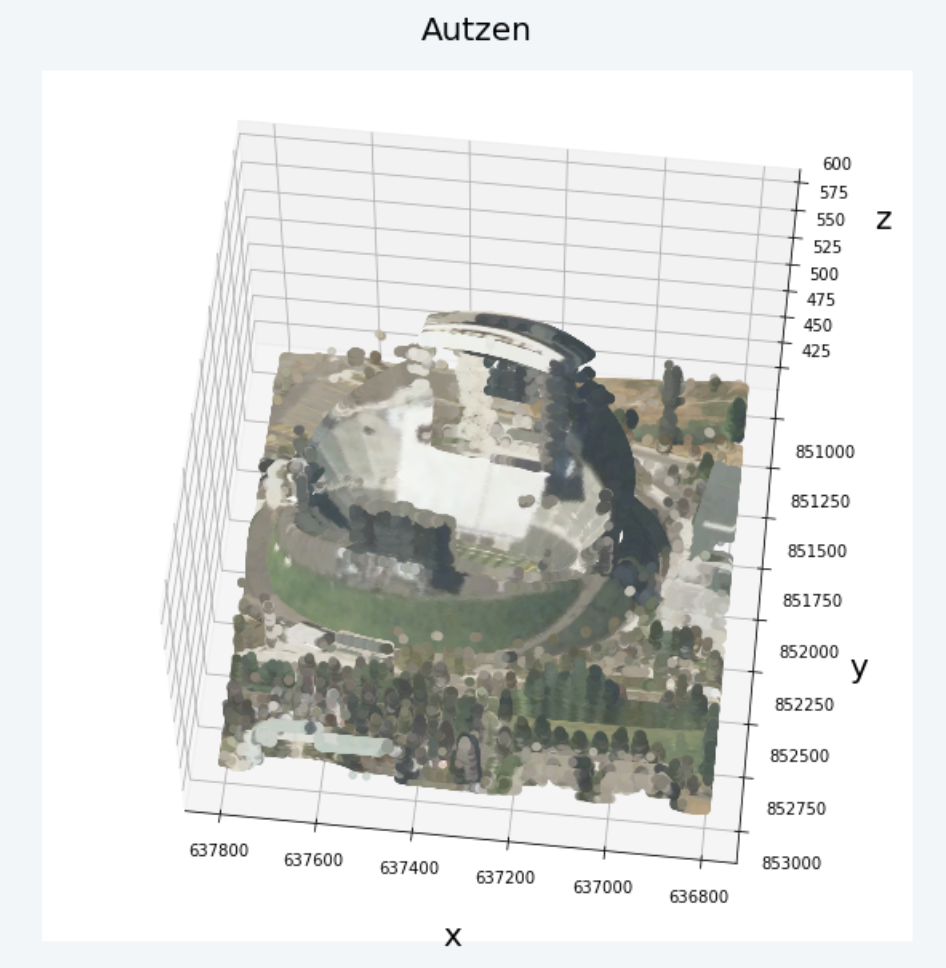
(3)データ可視化やってみた
今回はTileDBを使ってLiDARデータを空間的に可視化するチュートリアルを紹介します。開発環境は1. Select your image > Geospatial・2.Select a server profile > Smallを選択しました。
①チュートリアルの説明
tutorials_lidar_quickstartというプログラムでLiDARデータを可視化します。
ソースコードはこちらから確認することができます。
(https://cloud.tiledb.com/notebooks/details/TileDB-Inc/tutorials_lidar_quickstart/preview)
まずは必要なLiDARデータをダウンロードしてきます
!wget https://github.com/PDAL/data/blob/master/workshop/autzen.laz?raw=true -O autzen.lazダウンロードしたデータの情報をpdalで確認します。pdalとはPoint Data Abstraction Libraryの略で点群データ(LAS拡張子のLiDARデータ)を変換して処理するためのオープンソースライブラリです。
!pdal info autzen.laz | jq .必要なライブラリをインポートします。また、実行前に出力フォルダをクリーンアップしておきます。
import tiledb
output_array = '~/autzen_tiledb'
import json
import shutil
# Clean up any previous runs
try:
shutil.rmtree(output_array)
except:
passpdalのパイプラインを使用して、点群データをTileDB配列に取り込みます。
initial_pipeline = [
{
'type': 'readers.las',
'filename': "autzen.laz"
},
{
'type' : 'filters.stats'
},
{
'type': 'writers.tiledb',
'array_name': f"{output_array}",
'chunk_size': 10000000
}
]
with open('pipeline.json', 'w') as f:
json.dump(initial_pipeline, f)
!pdal pipeline -i pipeline.json --nostream次にTileDB配列の情報を確認してみます。TileDB配列は3つの次元と13の属性を持っています。TileDBは3次元に対して非常に高速なスライシング(データの絞り込み)ができます。データセット内のすべての点は3次元の小さい点として可視化します。
%%time
with tiledb.open(output_array) as arr:
print(f"Non-empty domain: {arr.nonempty_domain()}")
print(arr.schema)output
Non-empty domain: ((635577.79, 639003.73), (848882.15, 853537.66), (406.14, 615.26))
ArraySchema(
domain=Domain(*[
Dim(name='X', domain=(635576.79, 639004.73), tile='None', dtype='float64'),
Dim(name='Y', domain=(848881.15, 853538.66), tile='None', dtype='float64'),
Dim(name='Z', domain=(405.14, 616.26), tile='None', dtype='float64'),
]),
attrs=[
Attr(name='Intensity', dtype='uint16', var=False, nullable=False, filters=FilterList([Bzip2Filter(level=5), ])),
Attr(name='ReturnNumber', dtype='uint8', var=False, nullable=False, filters=FilterList([ZstdFilter(level=7), ])),
Attr(name='NumberOfReturns', dtype='uint8', var=False, nullable=False, filters=FilterList([ZstdFilter(level=7), ])),
Attr(name='ScanDirectionFlag', dtype='uint8', var=False, nullable=False, filters=FilterList([Bzip2Filter(level=5), ])),
Attr(name='EdgeOfFlightLine', dtype='uint8', var=False, nullable=False, filters=FilterList([Bzip2Filter(level=5), ])),
Attr(name='Classification', dtype='uint8', var=False, nullable=False, filters=FilterList([GzipFilter(level=9), ])),
Attr(name='ScanAngleRank', dtype='float32', var=False, nullable=False, filters=FilterList([Bzip2Filter(level=5), ])),
Attr(name='UserData', dtype='uint8', var=False, nullable=False, filters=FilterList([GzipFilter(level=9), ])),
Attr(name='PointSourceId', dtype='uint16', var=False, nullable=False, filters=FilterList([Bzip2Filter(level=-1), ])),
Attr(name='GpsTime', dtype='float64', var=False, nullable=False, filters=FilterList([ZstdFilter(level=7), ])),
Attr(name='Red', dtype='uint16', var=False, nullable=False, filters=FilterList([ZstdFilter(level=7), ])),
Attr(name='Green', dtype='uint16', var=False, nullable=False, filters=FilterList([ZstdFilter(level=7), ])),
Attr(name='Blue', dtype='uint16', var=False, nullable=False, filters=FilterList([ZstdFilter(level=7), ])),
],
cell_order='hilbert',
tile_order=None,
capacity=100000,
sparse=True,
allows_duplicates=True,
coords_filters=FilterList([ZstdFilter(level=7)]),
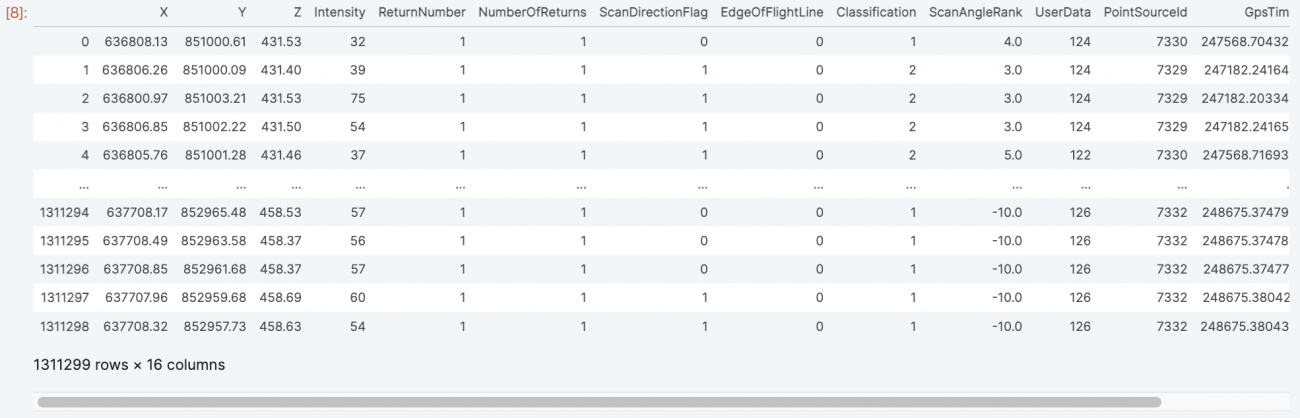
)TileDB配列からスライスし、Pandas dataframeに格納します。TileDBはこのスライスを高速で実施することができます。
%%time
with tiledb.open(output_array) as arr:
df = arr.df[636800:637800, 851000:853000, 406.14:615.26]
dfoutput
matplotでスライスしたデータを可視化します。
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
import numpy as np
def plot(pts):
rgbs = np.array(list(zip(pts['Red'], pts['Green'], pts['Blue']))) / 255.0
fig = plt.figure(figsize=(10, 10))
ax = fig.add_subplot(111, projection='3d')
ax.ticklabel_format(useOffset=False)
ax.scatter(pts['X'], pts['Y'], pts['Z'], c=rgbs)
ax.set_xlabel('x', fontsize=20, labelpad=20)
ax.set_ylabel('y', fontsize=20, labelpad=35)
ax.set_zlabel('z', fontsize=20, labelpad=25)
ax.set_title('Autzen', fontsize=20, pad=20)
ax.view_init(60, 96)
ax.tick_params(axis='y', pad=20)
ax.tick_params(axis='z', pad=10)
plt.show()output
BabylonJSを使ってインタラクティブにデータを可視化します。
import pybabylonjs
data = {
'X': df['X'][::10],
'Y': df['Y'][::10],
'Z': df['Z'][::10],
'Red': df['Red'][::10] / 255.0,
'Green': df['Green'][::10] / 255.0,
'Blue': df['Blue'][::10] / 255.0
}
babylon = pybabylonjs.BabylonJS()
babylon.value = data
babylon.z_scale = .2
# ctrl or right click - pan, wheel to zoom, left click to rotate
babylonoutput
TileDB配列はあらゆる種類のsplをサポートしています。以下ではデータ数をカウントしています。
%%time
import tiledb, tiledb.sql, pandas
db = tiledb.sql.connect()
res = pandas.read_sql(sql=
select COUNT(*) from `{output_array}`
WHERE X >= 636800 AND X = 851000 AND Y = 406.14 AND Z <= 615.26
, con=db)
res測した公開点群データを利用しました。
https://www.geospatial.jp/ckan/dataset/h29abiradouyuurinkauav
この中から186.lasという点群データを可視化するために、TileDBにアップロードします。上記チュートリアルの入力データautzen.lazに対応した変数を186.lasに変更して実行してみます。
また、スライスする座標の範囲を入力データに合わせて変更します。TileDB配列の情報からX,Y,Zの範囲を確認できます。
修正前
with tiledb.open(output_array) as arr:
df = arr.df[636800:637800, 851000:853000, 406.14:615.26]
df修正後
with tiledb.open(output_array) as arr:
df = arr.df[-27369.996:-27333.036, -124932.255:-124900.007, 139.77700000000002:156.903]
dfoutput
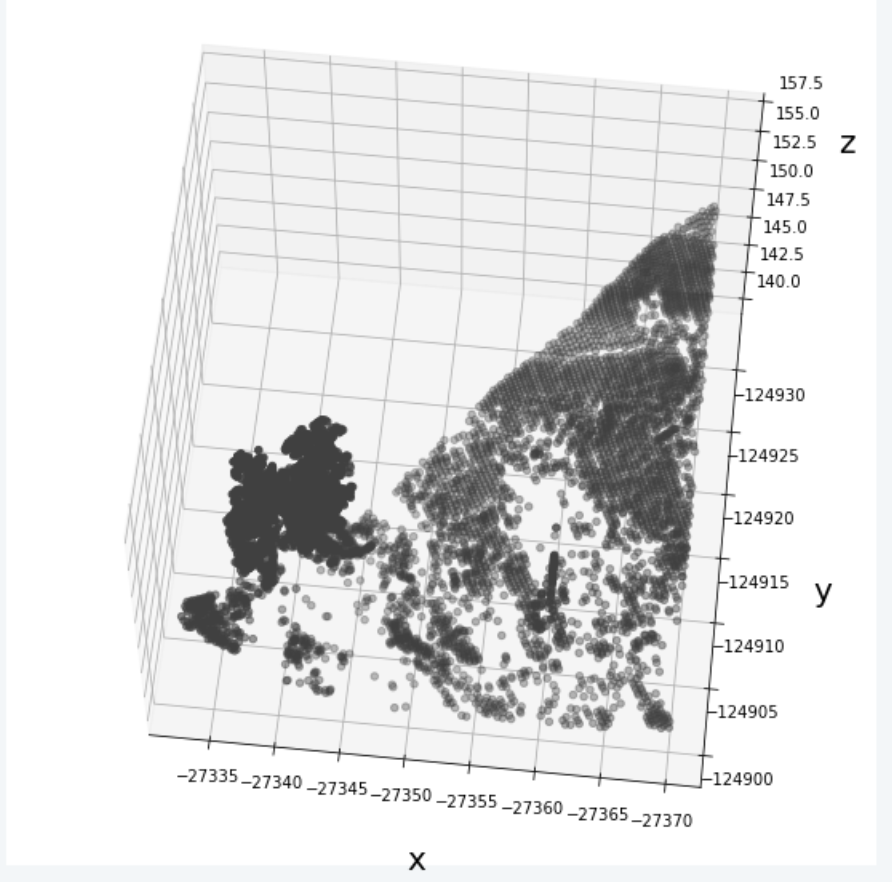
点群データを可視化することで、丘に木が生えていることがわかります。
(4)まとめ
地上の観測で期待されているLiDARデータと様々なデータを高速で処理できるTileDBを紹介しました。活用事例で紹介したLiDAR+他のデータ(光学衛星データなど)を組み合わせて解析するような場合に、異なるフォーマットのデータも扱えるTileDBの多次元配列をはじめ他の機能を活用することで解析しやすくなるかもしれません。
