駐車場に停まっている車両の検知精度アップ? 衛星データによる車両の回転検知とその実装方法
高解像度だからこそできる車両検知の方法を、「矩形による検知」「回転を考慮した検知」の2つの手法で、Maxar衛星画像を例に紹介します。
はじめに
近年の地上観測衛星業界の動向として、低軌道小型衛星を複数運用するマルチコンストレーションが盛んになっています。
これによって、高解像度のデータを、衛星プロバイダーから取得したい時期に取得できる機会が増えています。今後、高解像度のデータを扱う人の数も増えることが予想されます。
そこで、本記事では、高解像度だからこそできる車両検知の方法を、「矩形による検知」「回転を考慮した検知」の2つの手法で、Maxar衛星画像を例に紹介します。本記事がこれから衛星データを扱う人のスキルアップの一助となれますと幸いです。

車両検知について
車両検知を行う上で、画像処理技術は欠かせません。衛星画像も例にもれず、近年の画像処理の進歩の恩恵を受けています。
画像処理について学んだことがある方であれば、YOLOやSSD、Fast-RCNN などは一度は耳にしたことがあるでしょう。これらは、画像内の人間によって定義した認知物体を、AIを利用して自動的に検知する方法です。
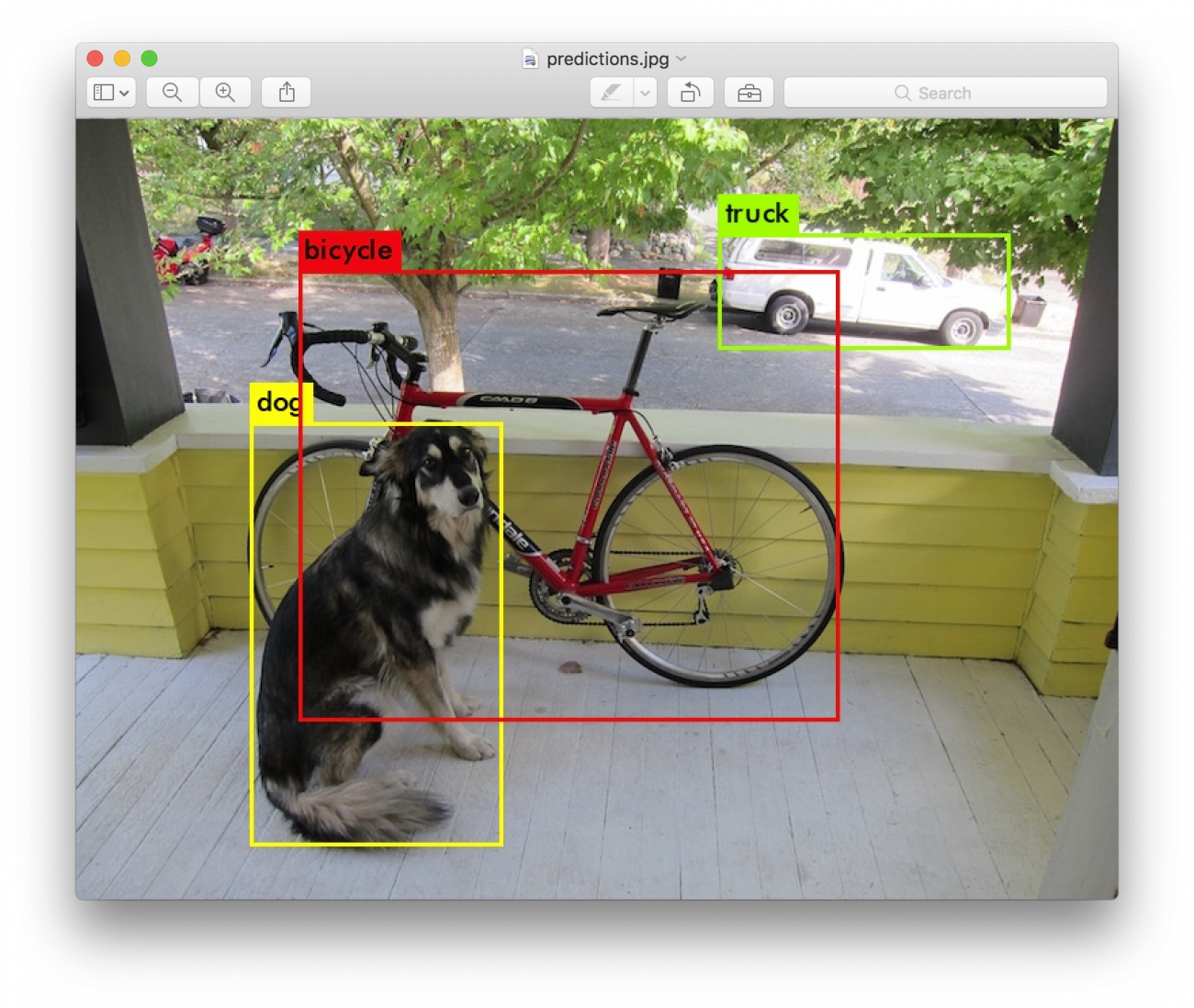
本記事では、衛星画像内の車両に着目して、それを検知していく方法をご紹介します。
アノテーションの可視化
Maxar衛星の光学画像にポリゴンによってアノテーションをしたので可視化してみます。
ポリゴンと Maxar 画像の動画
動画を見ていただくと分かる通り、車両は、人間の判読でなんとか判断できそうなくらいの小さい物体です。衛星画像では雲以外は衛星からの距離が離れているため、ほとんどの場合は微小物体になります。
そのため、物体検知をする際も数ピクセルのズレが致命的になることがわかます。よって衛星画像の処理は前処理や変換であっても丁寧に行うことがとても重要です。
アノテーション可視化の動画
あらためて、ポリゴンと Maxar画像をいくつかの視点で見てみましょう。

車両のアノテーションを引きのデータで見ると分かる通り、とても小さく、多くあることがわかります。
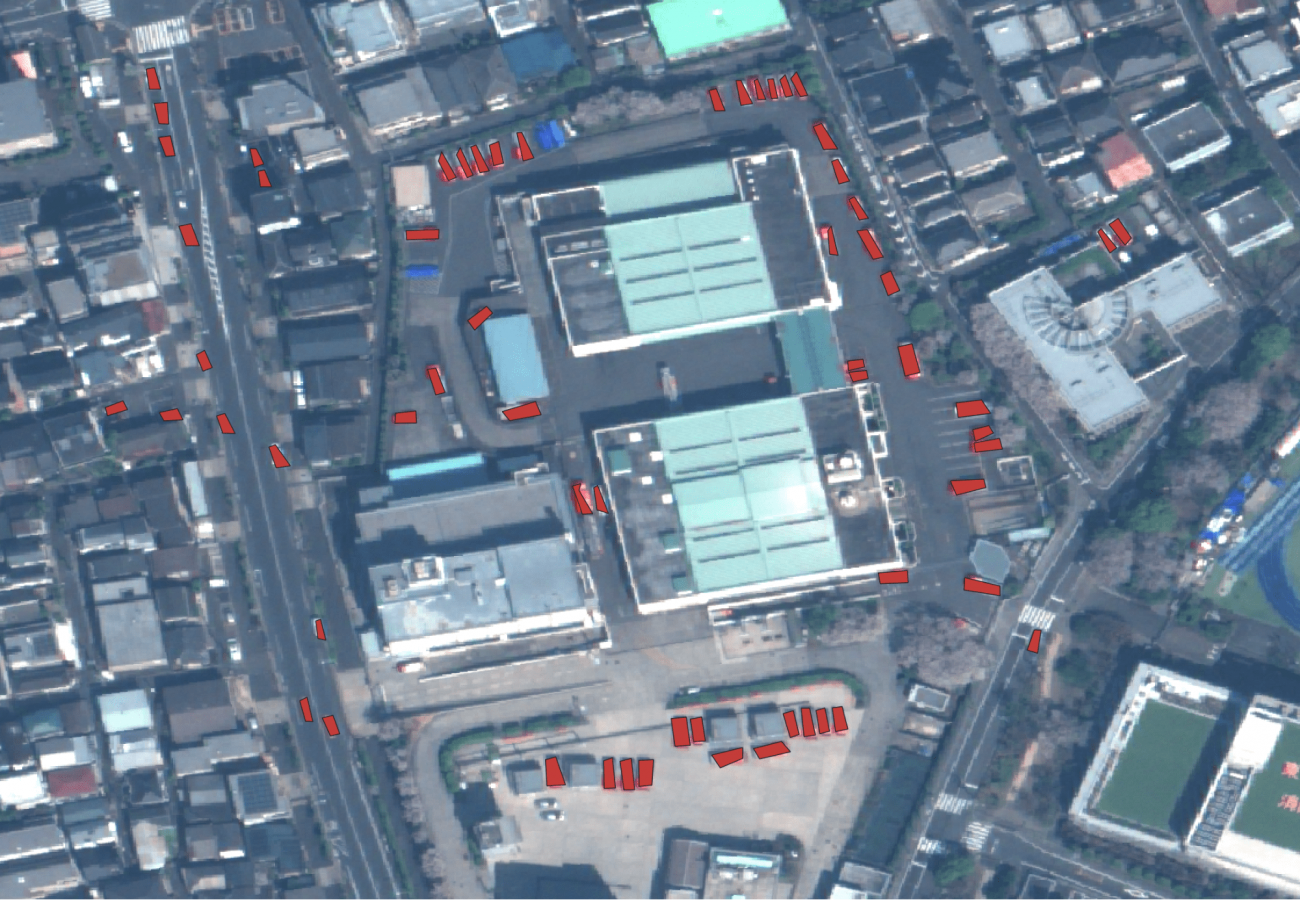
こちらは、建物の周辺の駐車場の可視化です。建物の隙間などは見逃しやすいので注意深く見ることが重要です。
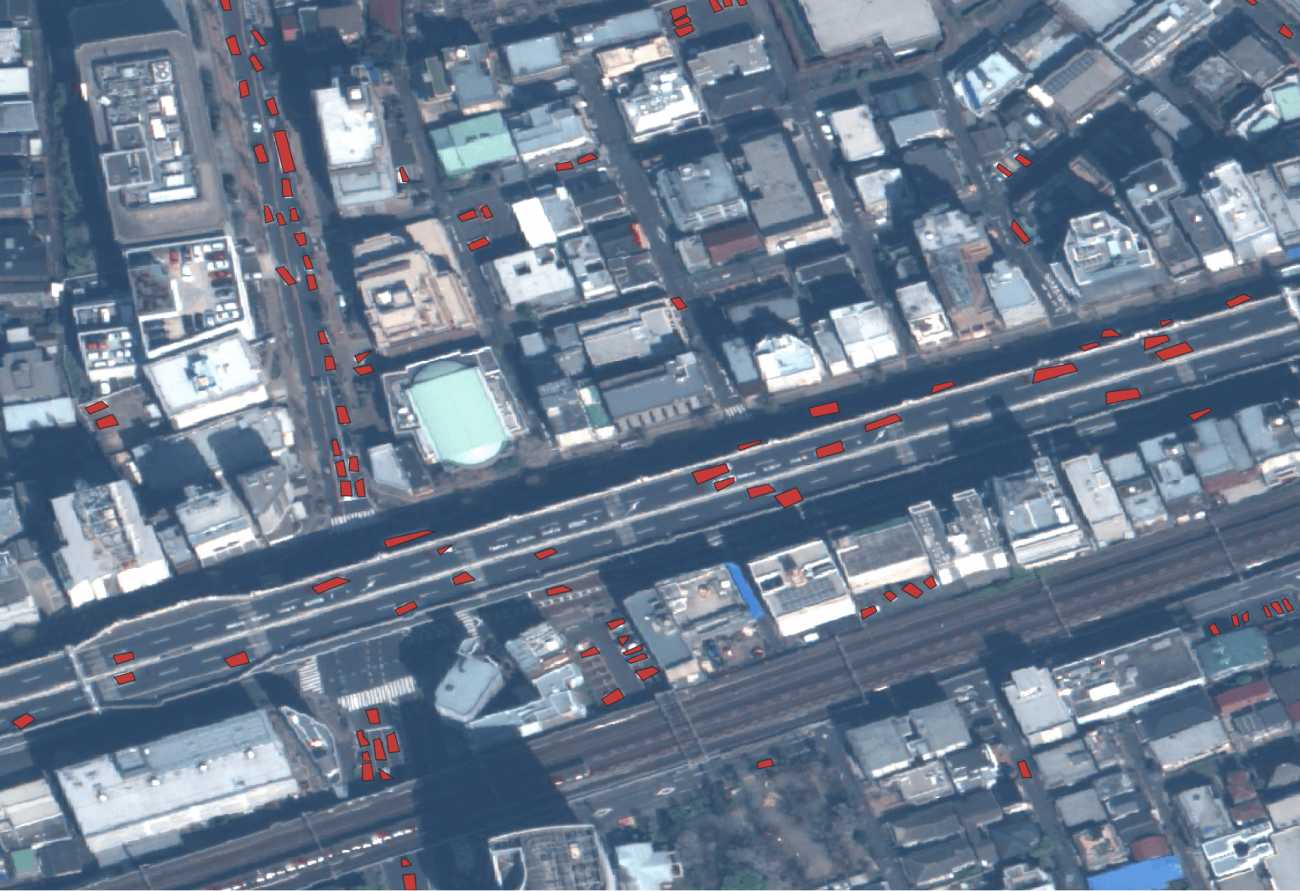
道路にはたくさんの車両があります。余談ですが、飛行機のように超高速で移動するため、RGBの画像がずれますが、車はそこまでの移動速度はでないため、ずれている車両はなさそうです。
衛星画像は1回の撮像での領域が広いため、どうしてもピクセルサイズが大きくなってしまします。しかしながら機械学習や分析の方法によっては、データ全てをメモリ上に載せることはできないので、小さい単位で取扱うためにパッチに分割して処理しています。
矩形による検知方法(mmdetectionを利用した物体検知)
まずは一般的な物体検知をしてきます。バウンディングボックス(矩形)と呼ばれる検知対象物の四隅を推定することで物体を特定する手法です。現在の物体検知のほとんどはこの方法が用いられています。以下などでも紹介されています。
衛星データからの石油タンク検出①データ前処理とYOLOXを使った学習
衛星データからの石油タンク検出② Tellusの衛星データ用いて検出結果を確認する
では、実際に画像を可視化してみます。
img = cv2.imread(f'{PATH_IMG}/{img_info["file_name"]}')
os.makedirs(OUTPUT, exist_ok=True)
plt.figure(figsize=(8, 8), facecolor='white')
plt.axis('off')
plt.imshow(img)

次に、ポリゴンの情報付きで可視化します。
plt.figure(figsize=(16, 16), facecolor='white')
plt.title('sample car annotation')
plt.imshow(img);
annIds = coco.getAnnIds(imgIds=img_info['id'], catIds=catIds, iscrowd=None)
anns = coco.loadAnns(annIds)
coco.showAnns(anns)



最後に、検知するためのバウンディングボックスも加えて可視化します。
plt.figure(figsize=(12, 12), facecolor='white')
plt.title(f'sample car bbox annotation index{image_idx}')
img = cv2.imread(f'{PATH_IMG}/{img_info["file_name"]}')
plt.imshow(img);
annIds = coco.getAnnIds(imgIds=img_info['id'], catIds=catIds, iscrowd=None)
anns = coco.loadAnns(annIds)
coco.showAnns(anns, draw_bbox=True)



モデルの構築は mmdetection という物体検知のフレームワークを利用します。
今回このフレームワークを選定した理由は、設定ファイルのみの変更で管理しやすいことと、多くの論文が実装されていて最新のモデルも検証できるからです。
さらに直近で mmdetection は version 3.0 系の大幅な更新が行われたのでその最新のAIフレームワークの環境構築や例としてもご紹介できると考えた次第です。

使用するモデルは 3.0系で追加された RTMDet を使用します。
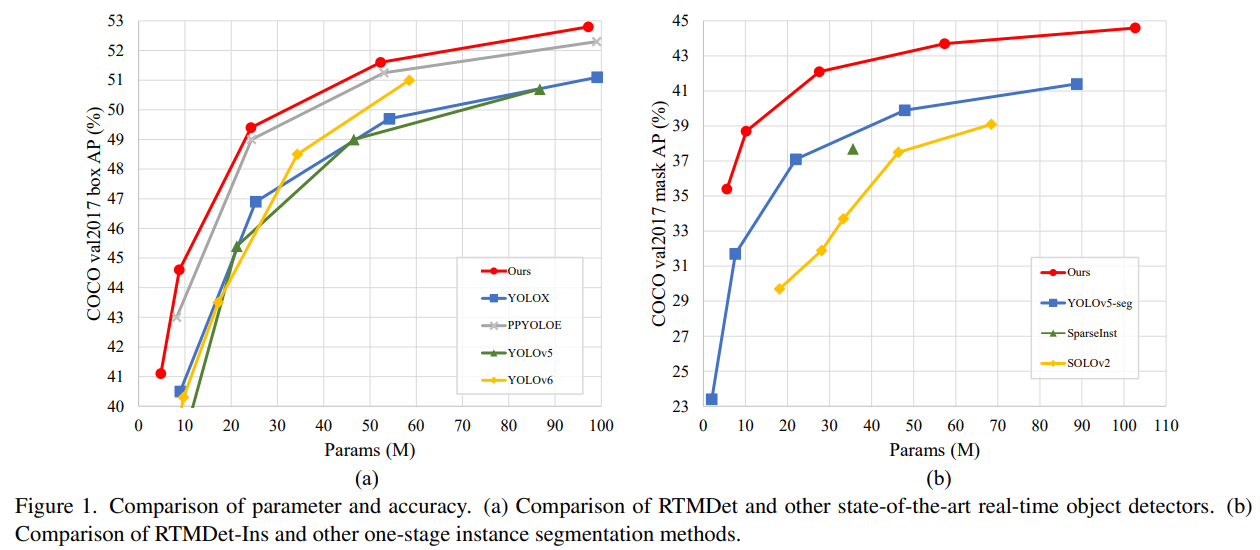
事前学習済みモデルも提供されていますので、ダウンロードを行います。
wget https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_l_8xb32-300e_coco/rtmdet_l_8xb32-300e_coco_20220719_112030-5a0be7c4.pth -P ./weights/
モデルを学習していきましょう。
python mmdetection/tools/train.py /workspace/src/cfg/rtm-l_det_basic.py学習したモデルを読み込みます。
model_name = './work_dirs/rtm-l_det_basic/rtm-l_det_basic.py'
checkpoint = './work_dirs/rtm-l_det_basic/epoch_40.pth'
device = 'cuda:0'
inferencer = DetInferencer(model_name, checkpoint, device)学習したモデルで推論します。
img = '../sample/train_scale1_h640_w640_oh0.5_ow0.5_min1_segs/maxar_001_0_6400_640_7040.jpg'
result = inferencer(img, out_dir='./output/003/')結果について確認します
print(result, max_length=4)結果
{
│ 'predictions': [
│ │ {
│ │ │ 'bboxes': [
│ │ │ │ [566.0130615234375, 569.0344848632812, 577.1096801757812, 585.2388916015625],
│ │ │ │ [541.0987548828125, 571.5909423828125, 552.1749877929688, 589.4445190429688],
│ │ │ │ [156.96763610839844, 292.3426208496094, 166.60226440429688, 312.1289367675781],
│ │ │ │ [605.4901733398438, 166.8843536376953, 611.8817138671875, 180.5867156982422],
│ │ │ │ ... +496
│ │ │ ],
│ │ │ 'labels': [0, 0, 0, 0, ... +496],
│ │ │ 'scores': [0.8861374855041504, 0.7544191479682922, 0.7300793528556824, 0.6662262678146362, ... +496]
│ │ }
│ ],
│ 'visualization': [
│ │ array([[[ 8, 11, 0],
│ │ [ 14, 17, 0],
│ │ [ 21, 24, 5],
│ │ ...,
│ │ [ 33, 34, 18],
│ │ [ 36, 37, 21],
│ │ [ 39, 40, 24]],
│
│ [[ 11, 14, 0],
│ │ [ 19, 22, 3],
│ │ [ 29, 32, 13],
│ │ ...,
│ │ [ 34, 35, 19],
│ │ [ 41, 42, 26],
│ │ [ 44, 45, 29]],
│
│ [[ 21, 24, 5],
│ │ [ 27, 30, 11],
│ │ [ 32, 35, 16],
│ │ ...,
│ │ [ 39, 40, 24],
│ │ [ 50, 51, 35],
│ │ [ 54, 55, 39]],
│
│ ...,
│
│ [[ 39, 36, 17],
│ │ [ 41, 40, 20],
│ │ [ 45, 42, 23],
│ │ ...,
│ │ [ 16, 10, 0],
│ │ [ 17, 10, 0],
│ │ [ 17, 10, 2]],
│
│ [[ 59, 58, 38],
│ │ [ 60, 62, 41],
│ │ [ 65, 64, 44],
│ │ ...,
│ │ [ 17, 11, 0],
│ │ [ 17, 13, 2],
│ │ [ 18, 14, 3]],
│
│ [[ 99, 101, 80],
│ │ [102, 104, 83],
│ │ [103, 105, 84],
│ │ ...,
│ │ [ 18, 12, 0],
│ │ [ 18, 14, 3],
│ │ [ 19, 15, 4]]], dtype=uint8)
│ ]
}
出力の意味としては、予測した検知物が何なのか(ここでは車のみ)、どの場所なのか(バウンディングボックス)、その確信度です。
こちらの情報を元に、画像上に可視化した画像を表示します。
Image.open('./output/003/vis/maxar_001_0_6400_640_7040.jpg')

元の画像と比べながら可視化していきます。
result = inferencer(PATH, out_dir='./output/003/', pred_score_thr=0.1, show=True,);
PATH_INF = f'output/003/vis/{os.path.basename(PATH)}'
plt.figure(figsize=(20, 10), dpi=100, facecolor='w', edgecolor='k')
plt.subplot(1, 2, 1)
plt.title(f'Original Image {i+1}')
plt.imshow(Image.open(PATH))
plt.subplot(1, 2, 2)
plt.title(f'Inference Result {i+1}')
plt.imshow(Image.open(PATH_INF))
plt.tight_layout()
plt.show();




定性的にも車両検知できているのが確認できると思います。
Maxar World View 3 の画像は 50cm 分解能と言われているので車両くらいの検知は衛星画像でも可能ということがわかります。
回転を考慮した検知方法(mmrotateを利用した回転検知)
ここまでの矩形による検知結果を見て、衛星画像は丁寧な処理が必要なのに、車両を覆う矩形で検知してしまって良いのかと思った人はいるかもしれません。
検知領域が重なってしまったり、本来検知したい領域より過敏に大きくなってしまったりで、精度が低下してしまうことは多々あります。
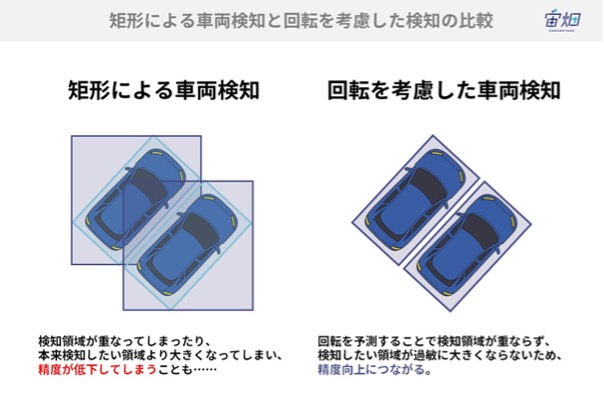
それらを改善するアプローチの1つが今回紹介する回転を考慮した検知です。特に駐車場に停まっている車の数を数えたいときなどは、検知領域が重なってしまう場合は精度が低下してしまうケースがありますので、回転を考慮した検知を用いたほうがよいでしょう。
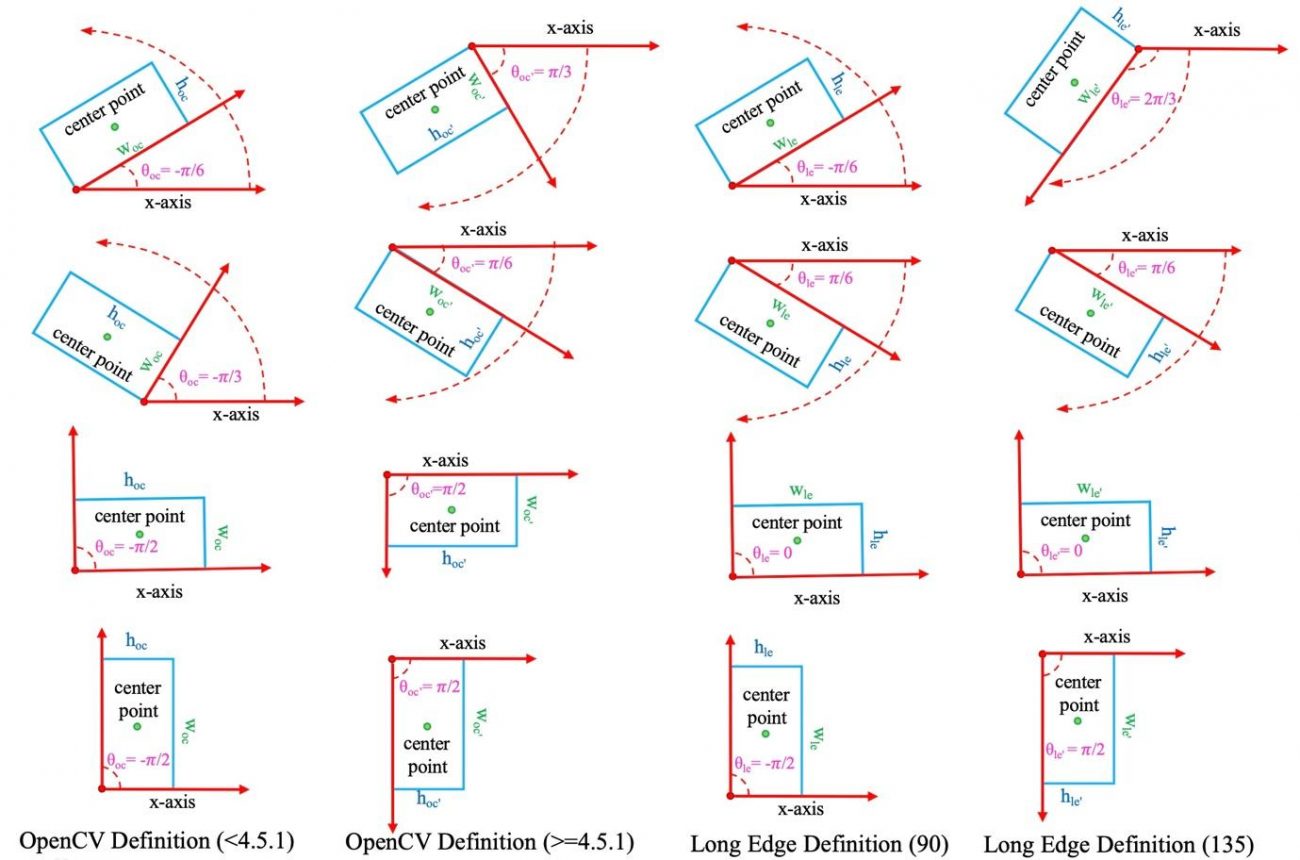
物体を検出する際に、矩形の回転も予測させることで斜めのバウンディングボックスなどを実現する手法になります。
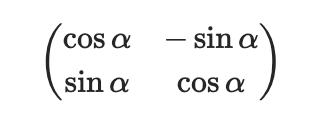
回転は回転行列によって定義されてポリゴンを覆う最小の角度を推定してくれるように学習します。

モデルの構築は mmrotate という回転検知のフレームワークを利用します。mmdetection と同じ mmcv シリーズの1つです。
回転検知の学習を行う前に、検知するポリゴンのデータを変換します。具体的には DOTA というデータ形式にポリゴンから変換します。
for phase in ['train', 'valid']:
COUNT_NO_LABEL = 0
os.makedirs(COCO_ROOT + '/' + phase, exist_ok=True)
coco = COCO(f'{COCO_ROOT}/{phase}.json')
catIds = coco.getCatIds(catNms=['car']);
imgIds = coco.getImgIds(catIds=catIds);
print('\n' , f'{len(imgIds)} images for {phase}')
for idx_img in tqdm(imgIds, total=len(imgIds)):
try:
img_info = coco.loadImgs(imgIds[idx_img])[0]
annIds = coco.getAnnIds(imgIds=img_info['id'], catIds=catIds, iscrowd=None)
anns = coco.loadAnns(annIds)
DOTA_FMTS = []
for ann in anns:
bbox = ann['segmentation'][0]
if len(bbox) < 8:
# put tmp point
bbox += bbox
bbox = bbox[:8]
bbox = list(map(str,map(round, bbox)))
DOTA_FMTS.append(' '.join(bbox) + f' car 0')
img = cv2.imread(f'{COCO_ROOT}/{img_info["file_name"]}')
cv2.imwrite(f'{COCO_ROOT}/{phase}/{img_info["file_name"]}', img)
# write to txet file
with open(f'{COCO_ROOT}/{phase}/{img_info["file_name"]}.txt', 'w') as f:
f.write('\n'.join(DOTA_FMTS))
except Exception as e:
COUNT_NO_LABEL += 1
print(f'{COUNT_NO_LABEL} images have no label phase {phase}')使用するモデルは Oriented RepPoints です。
このモデルも事前学習済みモデルが公開されていますのでダウンロードして使用します。
wget https://download.openmmlab.com/mmrotate/v0.1.0/orientedreppoints/oriented_reppoints_r50_fpn_1x_dota_le135/oriented_reppoints_r50_fpn_1x_dota_le135-ef072de9.pth -P ./weights/では、準備が整ったので学習します。
python mmrotate/tools/train.py cfg/oriented_reppoints_segs.py
物体検知の定量指標である mAP に関しても回転検知(0.221)は矩形検知(0.137)と比べて向上しています。
モデルを初期化します。
config = 'work_dirs/oriented_reppoints_segs/oriented_reppoints_segs.py'
checkpoint = 'work_dirs/oriented_reppoints_segs/epoch_30.pth'
device='cuda:0'
config = mmcv.Config.fromfile(config)
config.model.pretrained = None
model = build_detector(config.model)学習したモデルを読み込んで、推論の準備を行います。
checkpoint = load_checkpoint(model, checkpoint)
model.CLASSES = checkpoint['meta']['CLASSES']
model.cfg = config
model.to(device)さて、推論していきましょう。
img = '../sample/train_scale1_h640_w640_oh0.5_ow0.5_min1_segs/maxar_001_0_4480_640_5120.jpg'
result = inference_detector(model, img)推論結果を可視化します。
show_result_pyplot(model, img, result,
score_thr=0.1, palette='dota',
)

斜めの車両も検知できています。
いくつか可視化していきます。
file_name = os.path.basename(PATH)
print(i, 'th -> inference:', file_name)
result = inference_detector(model, PATH)
show_result_pyplot(model, PATH, result,
score_thr=0.1,
palette='dota',
out_file=f'output/003/{file_name}.png',
);



車両検知や回転検知の利用
技術的な話題ばかりになってしまいましたが、高解像度衛星画像とAIによる自動検知の利用面も紹介したいと思います。
まず、車両検知については、駐車場の監視です。現地でデータの取得がしやすい日本では効果性は薄いかもしれませんが、発展途上国などでは効果的かもしれません。

次に、交通情報の取得です。
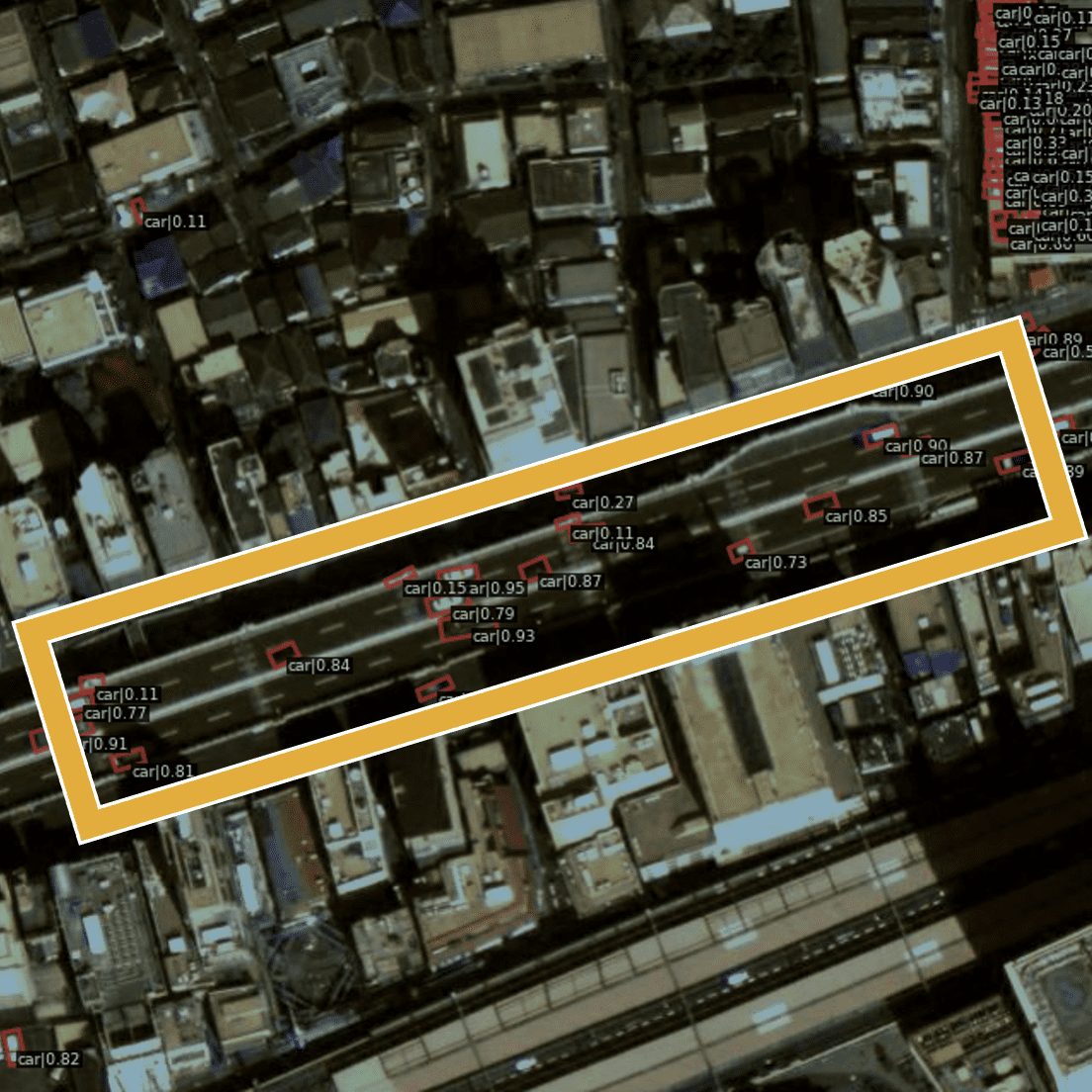
カーナビなどの GNSS 情報から取得したりするのが一般的ですが、衛星画像でも可能です。こちらも同じく、IT, IoTが飽和されていない地域などでは有効ではないかと思います。
続いて、回転検知の利用です。検知自体はほぼ同じなので、向きの情報をどれくらい重視するかが肝心です。
例えば、不審船の横付けなどがわかるような船舶などの監視です。細長い検知対象物において、回転検知は基本的には優位になるのでそのようなケースでは利用してみても良いでしょう。
本記事のGitHub:コードと環境
本記事で使用したコードは以下で公開しております。
Github: https://github.com/sorabatake/article_32976_car-detection
動作環境には Docker Compose + Nvidia Docker の環境が必要です。
mmdetection の環境構築は以下です。
docker compose -f compose_mmdet-3.yml up -dhttp://localhost:6667/lab で JupyterLab で Notebook を実行できます。
学習
https://github.com/sorabatake/article_32976_car-detection/blob/main/src/002_train_mmdet.ipynb
推論
https://github.com/sorabatake/article_32976_car-detection/blob/main/src/003_inference_mmdet.ipynb
mmrotate の環境構築は以下です。
docker compose -f compose_mmrotate.yml up -dhttp://localhost:6767/lab で JupyterLab で Notebook を実行できます。
学習
https://github.com/sorabatake/article_32976_car-detection/blob/main/src/002_train_mmrotate.ipynb
推論
https://github.com/sorabatake/article_32976_car-detection/blob/main/src/003_inference_mmrotate.ipynb
データの可視化と分析は共通して以下です
https://github.com/sorabatake/article_32976_car-detection/blob/main/src/001_prepare.ipynb
ファイルの配置は以下の記事に従っています。
GitHubの使い方と宙畑のGitHubアカウント紹介~実際にコードも動かしてみよう~
まとめ
高解像度画像による車両検知と回転検知を行いました。他の衛星画像にアノテーションして実際にご自身の手元で回転検知などのモデルを作ってサービスを作ってみてはいかがでしょうか。
