衛星データからの石油タンク検出①データ前処理とYOLOXを使った学習
衛星データから、石油タンクを検出する解析を行います。今回はデータの前処理とYOLOXを使って学習を行うところまでを紹介します。
本記事は、技術評論社から出版されている月刊誌Software Designに宙畑が寄稿した連載「衛星データプラットフォームTellusハンズオン」の内容から、一部修正して掲載するものです。
前回の記事では、機械学習を利用した衛星データのいくつかの解析事例と、物体検出の解析に利用できるデータセットを紹介しました。
今回は、前回紹介したデータセットと機械学習ライブラリを利用し、物体検出を行っていきます。
衛星データ×機械学習タスクの代表的な分類まとめ~物体検出、セマンティックセグメンテーション、画像分類、超解像~
YOLOXとは
今回はYOLOXという機械学習ライブラリ注1を利用して学習や物体検出を行います。
YOLOXは物体検出タスクで有名なYOLOシリーズから派生したライブラリで、既存のYOLOシリーズから、学習の高速化や精度の改善が行われています。最近ではKaggleにてヒトデの物体検出コンペティション注2が開催され、そこで利用されているコードを見ると多くのチームがYOLOシリーズを取り入れていました。
今回は、取得した学習データがYOLOXに適した形式になるよう前処理を行っていきます。
アノテーションと呼ばれる画像に関連する情報(画像のどの位置に物体が存在するか等)を変換していきますが、YOLOXの対応データ形式はYOLOフォーマットではなくCOCOフォーマットである必要があります。
COCOフォーマットは一つのアノテーションデータで複数の画像系タスクが行えるように設計されており、今回は物体検出ですが、他にも境界線を予測するセグメンテーションタスクや人のポーズ推定等のデータとして表現が可能なため色々な場面で利用することができます。
また、転移学習を行うため学習済みモデルはYOLOXが公式に公開している、YOLOX-sを利用します注3。
注1) https://github.com/Megvii-BaseDetection/YOLOX
注2) https://www.kaggle.com/c/tensorflow-great-barrier-reef
注3) ほかにもYOLOXでは、エッジ端末などでも利用しやすい、小さめのYOLO -Nanoや精度を出すために、ネットワークを大きくしたYOLOX-xなども用意されています
データ前処理
それではデータの前処理を行っていきます。
今回はJupyter notebookやGoogle Colabratory上でのセル実行を想定したコードになっています。また、環境としては、GPU利用を前提としています。
まずは、必要なライブラリをリスト1で呼び出しましょう。
リスト1 必要なライブラリをインストール
import os
import pandas as pd
import ast
from PIL import Image
import shutil as sh
from pathlib import Path
import json
from sklearn.model_selection import train_test_splitYOLOXもGitHubからインストールしておきます。
YOLOXをインストール
!git clone https://github.com/Megvii-BaseDetection/YOLOX -q
%cd YOLOX
!git checkout tags/0.2.0 -b v0.2
!pip install -U pip && pip install -r requirements.txt
!pip install -v -e .
%cd次に、画像データの取得と、アノテーションデータを読み込んでいきます(リスト2)。
リスト2 アノテーションデータを読み込む
DATA_DIR = Path('../airbus-oil-storage-detection-dataset')
img_list = list(DATA_DIR.glob('images/*.jpg'))
img = Image.open(img_list[0])
IMAGE_HEIGHT, IMAGE_WIDTH = img.size
# CSV上では境界座標情報が文字列になっているので、Pythonで読み込めるようタプル型に変換する
def literal_eval(x):
return ast.literal_eval(x.rstrip('\r\n'))
# アノテーションデータをデータフレームに取り込む
df = pd.read_csv(DATA_DIR / "annotations.csv",
converters={'bounds': literal_eval})
| image_id | class | bounds |
| 0918a15c-8cfb-4da7-92cf-1f5098a76760 | oil-storage-tank | (1205, 1493, 1231, 1516) |
アノテーションデータは表1のように、画像データの名前にひもづくID「image_id」、分類情報で今回はoil-storage-tankのみの「class」、画像のどの座標に対象物があるかを示す「bounds」があります。
機械学習を行う際には、これらの学習データからトレーニングデータ(学習に用いるデータ)とバリデーションデータ(学習に用いずモデル精度の評価時に利用するデータ)に分ける必要があり、それぞれのデータで利用するimage_idを分けます。
image_ids = df['image_id'].unique()
train_image_ids, validation_image_ids = train_test_split(image_ids, test_size=0.2, random_state=0)COCOフォーマットのデータ構造に合うようにディレクトリを作成しておきましょう(リスト3)。
リスト3 ディレクトリの作成
HOME_DIR = './'
DATASET_PATH = 'dataset/images'
!mkdir {HOME_DIR}dataset
!mkdir {HOME_DIR}{DATASET_PATH}
!mkdir {HOME_DIR}{DATASET_PATH}/train2017
!mkdir {HOME_DIR}{DATASET_PATH}/val2017
!mkdir {HOME_DIR}{DATASET_PATH}/annotationsYOLOX-sのモデルは入力画像サイズが640×640で学習されていたので、今回利用する画像もそのサイズに合わせてリサイズしておきます(リスト4)。
リスト4 画像のリサイズ
RESIZE_WIDTH = 640
RESIZE_WIDTH_RATE = RESIZE_WIDTH / IMAGE_WIDTH
RESIZE_HEIGHT = 640
RESIZE_HEIGHT_RATE = RESIZE_HEIGHT / IMAGE_HEIGHT
# 画像をリサイズして、validation_image_idsのリストに従って、トレーニングとバリデーションのフォルダに振り分けて保存する
for img_path in img_list:
pil_img = Image.open(img_path, mode='r')
resized_img = pil_img.resize((RESIZE_WIDTH, RESIZE_HEIGHT))
save_folder_name = 'val2017' if img_path.stem in validation_image_ids else 'train2017'
dataset_image_path = f'{HOME_DIR}{DATASET_PATH}/{save_folder_name}/{img_path.stem}.jpg'
resized_img.save(dataset_image_path)次に、COCO フォーマットで利用できる形にアノテーション情報を変換していきます(リスト5)
リスト5 アノテーション情報の変換
# JSON形式のアノテーションデータを保存する
def save_annotation_json(json_annotation, filename):
with open(filename, 'w') as f:
output_json = json.dumps(json_annotation)
f.write(output_json)
# COCOフォーマットに合わせたJSON情報を生成する
def dataset2coco(df):
# info: データセット情報
# license: データセットライセンス情報
# categories: カテゴリ情報
# images: 画像情報
# annotations: アノテーション情報
annotations_json = {"info": [], "licenses": [], "categories": [], "images": [], "annotations": []}
# メタ情報
# year: データセット公開年
# version: データセットバージョン
# description: データセット説明文
# contributor: 貢献者
# url: 関連ホームページURL
# date_created: データセット作成日時
info = {"year": "2022", "version": "1", "description": "Airbus Oil Strage Detection dataset - COCO format", "contributor": "", "url": "", "date_created": "2022-02-22T15:00:00+00:00"}
annotations_json["info"].append(info)
# ライセンス情報ですが、自分で利用するデータセットで公開するものではないので Unknown にしています
license = {"id": 1,"url": "","name": "Unknown"}
annotations_json["licenses"].append(license)
# カテゴリ情報
# id: ユニークな識別ID(int)
# name: カテゴリ名
# supercategory: 大カテゴリ(公開されているCOCOデータセットだと cat や dog のカテゴリに対して、animal のような supercategory が存在する)
category = {"id": 0, "name": "oil-storage-tank", "supercategory": "none"}
annotations_json["categories"].append(category)
# 画像情報
# 画像の image_id からユニークな値を抽出して image_id を key、index 値を value にした辞書型のデータを生成
image_ids_dict = {k: v for v, k in enumerate(df['image_id'].unique())}
for key, value in image_ids_dict.items():
# id: ユニークな識別ID(int)
# license: ライセンスID(ライセンス情報で作成したもの)
# file_name: ファイル名
# height: 画像高さ
# width: 画像幅
# date_captured: 画像の撮影日(今回は不明だったため作成日時に揃える)
images = {"id": value, "license": 1, "file_name": key + '.jpg', "height": RESIZE_HEIGHT,
"width": RESIZE_WIDTH, "date_captured": "2022-02-22T15:00:00+00:00"}
annotations_json["images"].append(images)
# アノテーション情報
for index, annotation_row in enumerate(df.itertuples()):
# 対象領域のx座標とy座標を取得する
x_min, y_min, x_max, y_max = annotation_row.bounds
# 座標から高さと幅を求めて、リサイズ時の縮小率をかける
width = (x_max - x_min) * RESIZE_WIDTH_RATE
height = (y_max - y_min) * RESIZE_HEIGHT_RATE
# id: ユニークな識別ID(int)
# image_id: 画像情報で定義したID
# category_id: カテゴリ情報で定義したID
# bbox: 対象領域情報 [開始x座標, 開始y座標, 幅, 高さ]
# area: 対象領域面積
# segmentation: セグメンテーション情報(物体検出タスク時には利用しない)
# iscrowd: 一つ一つの物体を追えない程集まっていて群衆になっている場合には1を指定
image_annotations = {"id": index, "image_id": image_ids_dict[annotation_row.image_id], "category_id": 0, "bbox": [x_min * RESIZE_WIDTH_RATE, y_min * RESIZE_HEIGHT_RATE, width, height], "area": width * height, "segmentation": [], "iscrowd": 0}
annotations_json["annotations"].append(image_annotations)
print(f"COCO json format completed! Files: {len(df)}")
return annotations_json
train_annotation_json = dataset2coco(df[df['image_id'].isin(train_image_ids)])
validation_annotation_json = dataset2coco(df[df['image_id'].isin(validation_image_ids)])
save_annotation_json(train_annotation_json,f"{HOME_DIR}{DATASET_PATH}/annotations/train.json")
save_annotation_json(validation_annotation_json,f"{HOME_DIR}{DATASET_PATH}/annotations/valid.json")YOLOXの設定
YOLOXで学習を行うために、設定ファイルを生成します(リスト6)。
デフォルトの学習設定値を利用しつつ、必要な情報を追加します。元のファイルはGitHubからダウンロードしてきたYOLOXディレクトリ内の「YOLOX/exps/default/yolox_s.py」にあります。
リスト6 設定ファイルの生成
config_file = '''
#!/usr/bin/env python3
import os
from yolox.exp import Exp as MyExp
class Exp(MyExp):
def __init__(self):
super(Exp, self).__init__()
self.depth = 0.33
self.width = 0.50
self.exp_name = os.path.split(os.path.realpath(__file__))[1].split(".")[0]
# 以下設定追加
self.data_dir = "./dataset/images"
self.train_ann = "train.json"
self.val_ann = "valid.json"
self.num_classes = 1
'''
CONFIG_PATH='airbus_config.py'
with open(CONFIG_PATH, 'w') as f:
f.write(config_file)また、今回の学習で利用するカテゴリ名を coco_classes.py で指定します(リスト7)。今回の学習データには oil-storage-tankしか含まれていませんが、複数のクラスが含まれているデータに対しても、このファイルで指定したカテゴリ名のみが学習の対象になります。
リスト7 学習で利用するClass情報を更新
# ./YOLOX/yolox/data/datasets/coco_classes.py
coco_cls = '''
COCO_CLASSES = (
"oil-storage-tank", ※ここのみ変更
)
'''
with open('./YOLOX/yolox/data/datasets/coco_classes.py', 'w') as f:
f.write(coco_cls)以下の手順で、学習済みモデルデータをダウンロードします。
学習済みモデルデータをダウンロード
sh = 'wget https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_s.pth'
MODEL_FILE = 'yolox_s.pth'
with open('script.sh', 'w') as file:
file.write(sh)
!bash script.shYOLOXで学習を行う
学習データの前処理とYOLOXの設定ができたので、以下のコマンドで学習を実行します。それぞれのオプションは `-f` 設定ファイル指定、`-d` 学習時のデバイス数、`-b` バッチサイズ(一度にまとめて処理をするデータ量)、`–fp16` 混合精度学習有効、`-o` 学習時にGPUメモリを優先、`-c` 学習済みモデルデータファイル指定、を意味しています。
学習の実行
!python ./YOLOX/tools/train.py \
-f airbus_config.py \
-d 1 \
-b 16 \
--fp16 \
-o \
-c {MODEL_FILE}学習のepochごとに、./YOLOX_outputs/airbus_configにモデル情報が保存され、バリデーションデータでスコアが良かったものが、
./YOLOX_outputs/airbus_config/best_ckpt.pthとして保存されます。
結果の確認
学習で得られたbest_ckpt.pthを用いて、データセットでトレーニング画像とは別にアノテーション情報が付いていないextrasデータ(物体検出の対象となっている画像データ)に対して、実際に未知のデータでも石油タンクを物体検出できるか確認します(リスト8)。
リスト8 石油タンクの物体検出ができているか確認
TEST_IMAGE_PATH = f"{DATA_DIR}/extras/588fc1fb-b86a-4fb4-8161-d9bd3a1556ca.jpg"
pil_test_img = Image.open(TEST_IMAGE_PATH, mode='r')
resized_test_img = pil_img.resize((RESIZE_WIDTH, RESIZE_HEIGHT))
resized_test_img.save('test.jpg')
MODEL_PATH = "./YOLOX_outputs/airbus_config/best_ckpt.pth"実行の結果画像が「./YOLOX_outputs/airbus_config/vis_res/」出力されるので、以下のコマンドで確認します。それぞれのオプションは `-f` 設定ファイル指定、`-c` 学習済みモデルデータファイル指定、`–path` 対象画像ファイルパス、`–tsize` 画像サイズ、`–save_result` 結果を保存するか、`–device` 利用デバイス、を意味しています。
画像の出力
!python ./YOLOX/tools/demo.py image \
-f airbus_config.py \
-c {MODEL_PATH} \
--path ./test.jpg \
--tsize 640 \
--save_result \
--device gpu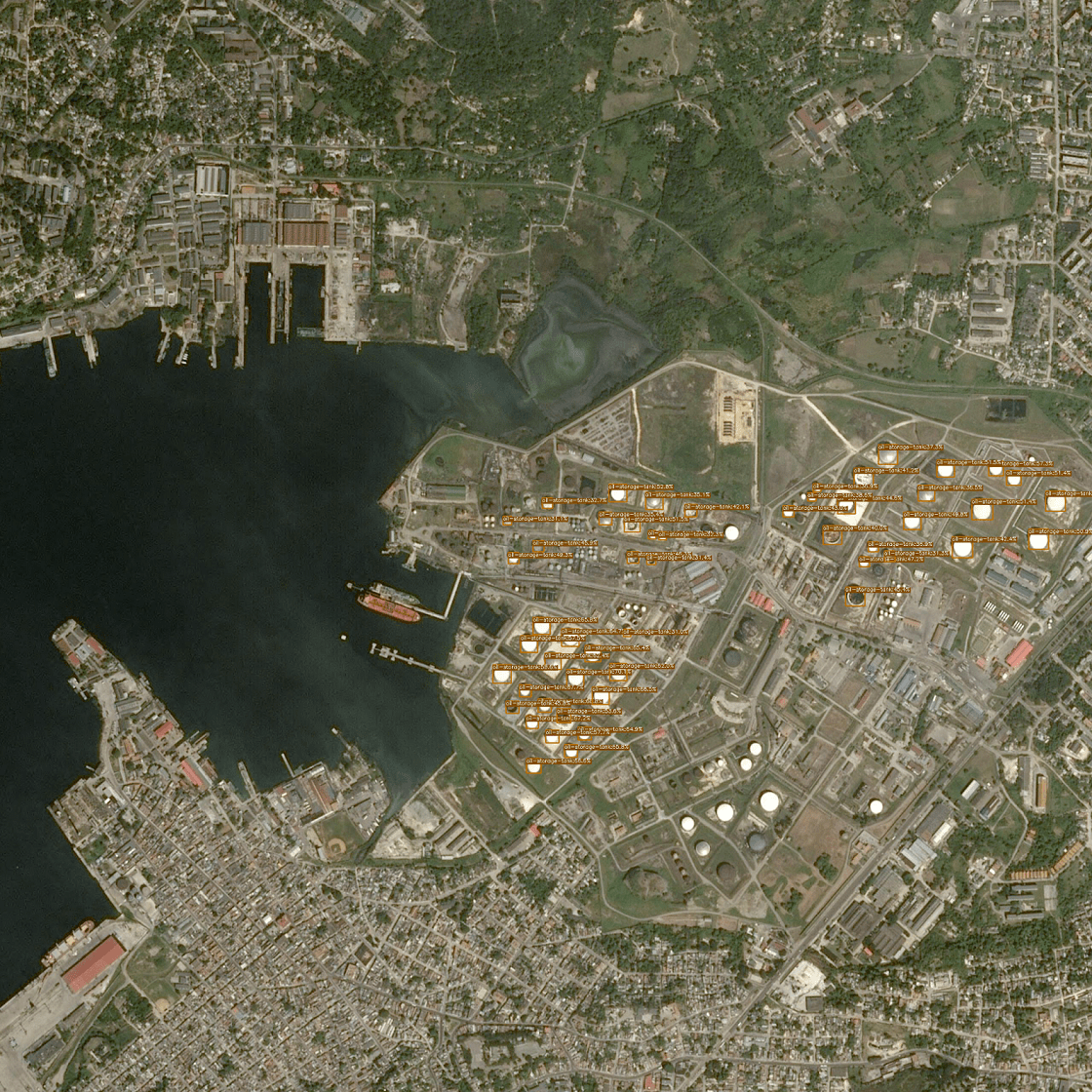
Credit : Airbus DS GEO S.A.
すべてではないですが、石油タンクを物体検知できています。ここから精度を上げていくには、設定ファイルでepoch数を増やしたり、より規模の大きい事前学習モデルを利用したりする必要があります。
データセットを使って物体検出を行い、石油タンクの抽出をすることができました。次回はTellusで公開されている衛星データを使って石油タンクの抽出ができるか挑戦します。
今回ご紹介したコードは以下のリンクよりご確認いただけます。
https://www.kaggle.com/code/regonn/airbus-oil-storage-detection-simple-yolox
