Kaggleランカーの5人に聞いた、2023年面白かったコンペ5選と論文5選
Kaggleなどの主要なデータサイエンスコンペティションに参加した方々にアンケートを実施し、2023年の印象深いコンペティションや論文、AIサービスをまとめました。
記事の趣旨とアンケートに回答いただいたみなさまの紹介
2023年は、ChatGPT-4やGeminiなどのサービスが登場するなど、AIの急速な発展が目覚ましい年でした。多くの企業や研究機関がAIを活用した新製品やサービスを生み出し、画期的なブレークスルーが数多く報告されました。
私たち宙畑は、衛星データの利活用・促進を目指す専門メディアとして、AIの分野における技術動向にも注目しています。人間による従来の解析手法には限界があり、膨大な衛星データを効率的に処理するためにはAIの導入が不可欠だからです。
そこで今年も、Kaggleなどの主要なデータサイエンスコンペティションに参加した方々にアンケートを実施し、2023年の印象深いコンペティションや論文、AIサービスをまとめました。急速に進化するAI技術の中で、AI分野にもたらされた新たな知見をご紹介します。
今回アンケートに回答いただいたのは以下の5名の皆様です。
・カレーちゃんさま(@currypurin)
・SiNpcwさま(@SiNpcw)
・YujiAriyasuさま(@aryyyyy221)
・Hiroki Yamamotoさま(@tereka114)
・shinmura0さま(@shinmura0)
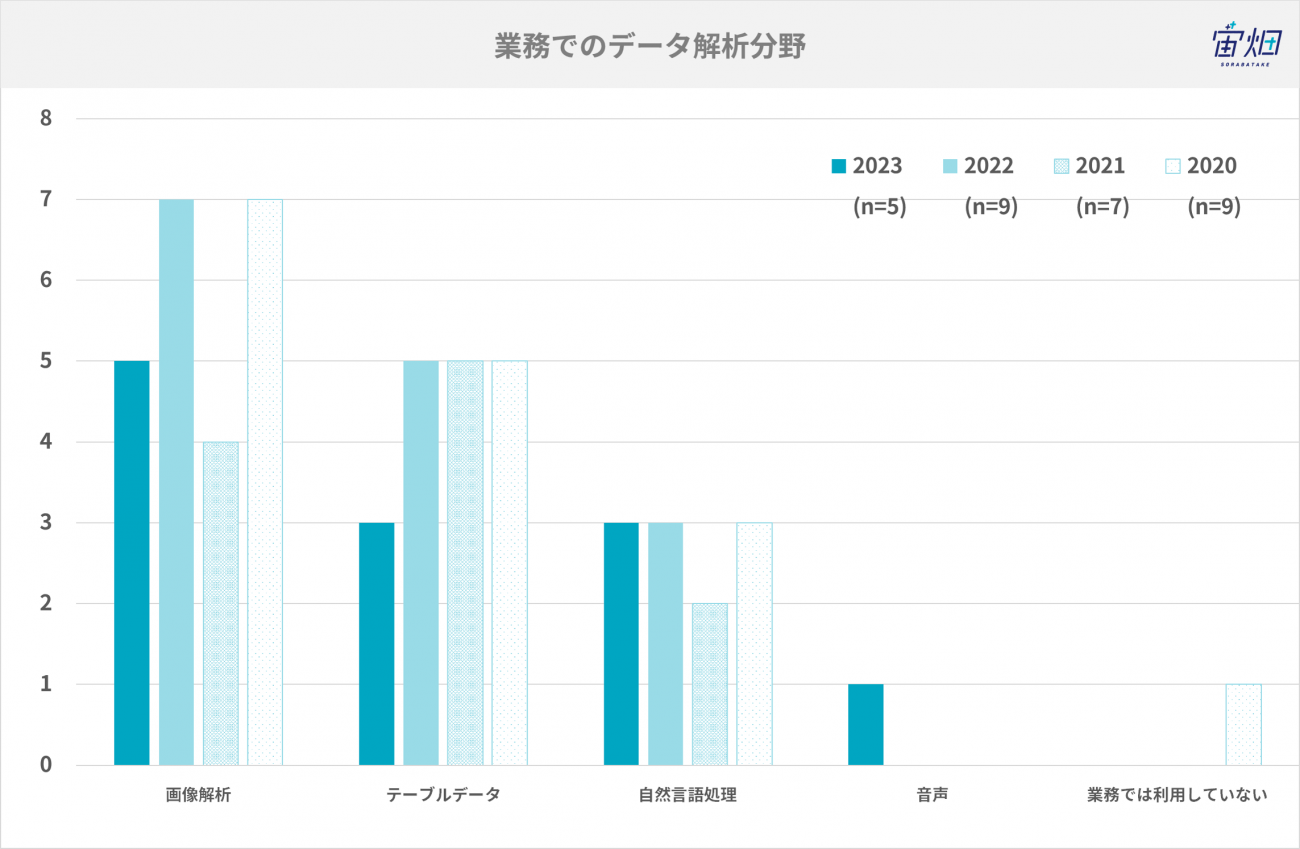
業務でのデータ解析分野
普段業務で利用しているデータ解析分野は、以下の通りです。今年は全員が画像解析業務をされており、3名の方がテーブルデータや自然言語処理もされています。
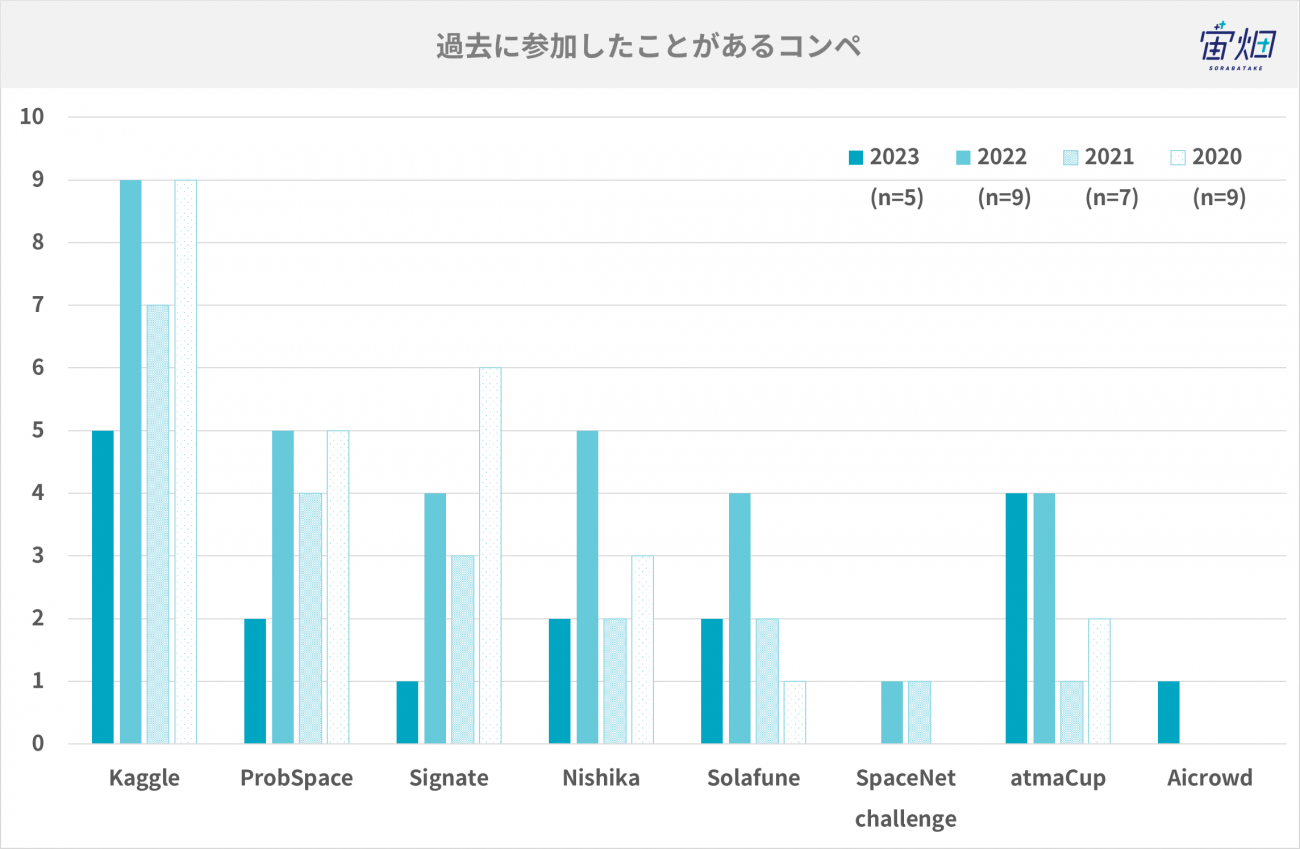
過去に参加したことがあるコンペとコンペに参加する理由
過去に参加したことがあるコンペは以下の通りです。やはりKaggleは全員経験があり、次いで国内のコンペティションであるatmaCupに参加されている方が多いです。衛星データを扱うコンペティションで有名なSolafuneに参加された方も2名いらっしゃいました。
続いて、コンペに参加している理由を伺ったところ、以下のような理由を回答いただきました。
・自分自身のスキルアップのため
・面白い・楽しいから
・業務に役立てるため
・最新の技術について学ぶため
コンペに参加する理由として多かったのは「自分自身のスキルアップのため」「面白い・楽しいから」でした。
では、実際に2023年ではどのようなコンペや論文が面白い、興味深いと思われたのかを紹介していきます。
(2)2023年、面白かったコンペ
画像解析:Benetech - Making Graphs Accessible
コンペのURL:https://www.kaggle.com/competitions/benetech-making-graphs-accessible
視覚障害などで学習に困難を抱える学生が活字の教材にアクセスするために、STEM教材のグラフデータを自動抽出する機械学習モデルの開発が目的のコンペです。4種類のグラフから情報を抽出し、教育資料を誰もが読み取りやすくするような状態を目指します。複数の種類があるグラフからデータを読み取るという取り掛かり方が難しい課題でした。
コメント@YujiAriyasu
グラフの画像からデータの各値を読み取るという、一見してどう解くのが最適かパッと浮かばない難しいコンペだったため。最終的な上位solutionも色々なパターンがあり、知恵比べの余地が大きかった。
1位のSolutionではまず棒グラフ、折れ線グラフ、散布図などのグラフのタイプごとに分類し、その後グラフの種類別に値を読み取るモデルが作成されていました。
一方で2位のSolutionは学習元となるグラフを大量に生成してモデルをトレーニングし、そのモデルを基にコンペティションの画像を使ってファインチューニングを行う手法を取りました。
このように様々なアプローチがある興味深いコンペティションでした。
画像解析・テーブルデータ :1st and Future - Player Contact Detection
コンペのURL:https://www.kaggle.com/competitions/nfl-player-contact-detection
NFL(The National Football League)が主催するこのコンペでは、試合中の選手間や選手と地面での接触を検出するAIモデルを開発することが目標です。ビデオと選手に装着したセンサーによる追跡データを用いて接触瞬間を特定し、特定のタイプの接触と障害の相関関係を特定することで予防に活用でき、選手の安全性向上に貢献します。
コメント@shinmura0
本コンペは、NFLのプレー動画・選手に付けたセンサデータから、ある選手とある選手が、接触したか判定するコンペだった。接触は、動画だけでは捉えきれないこともあり、そこをセンサーデータで補完していくのが肝だった。privateLBで少しshakeした点も大変興味深く、画像重視ではshakeが小さかったものの、センサーデータ重視ではshakeが大きかった。画像が頑強性を持っている(shakeが小さい)のは、納得感があり、そういった意味でも勉強になった。
Shakeとはコンペティション中に公開されているPublic Leader Borad(以下、PublicLB)という暫定結果と、コンペティションの最終結果となるPrivate Leader Board(以下、PrivateLB)の間で生じる差のことです。本コンペティションではPublicLBでは1位だったチームが2位に落ち、代わりに7位だったチームが大逆転での優勝となっています。Shakeが小さいというのは未知のデータに対しても正しく予測が行える汎用性を持っているということです。エンジニアは精度が高いだけでなく、汎用性が高い機械学習モデルを作るようにしています。
テーブルデータ :IceCube - Neutrinos in Deep Ice
コンペのURL:https://www.kaggle.com/competitions/icecube-neutrinos-in-deep-ice
このコンペの目的は、「IceCube」検出器のデータを用いて、ニュートリノ粒子の方向を予測するモデルを開発することです。IceCubeは南極の氷の中に設置された全長2.5㎞に及ぶ、宇宙からのニュートリノを検出する装置です。より高速で正確なアルゴリズムの開発により、宇宙物理学の理解が深まる可能性があります。データ分析を物理学に応用するという点でチャレンジングなコンペでした。
コメント@SiNpcw
テーマがニュートリノを扱うという壮大なテーマであること。また物理とデータ分析を紐付けられるという観点でも面白い。最終的な解法としては Transformer が有用ではあったがコンペを通してGraphNeural Network (GNN)に関する経験や活用方法などを知ることができた。またここで得たGNN知見を全く別ドメインの業務においても活用できた。
本コンペティションで有用だったTransformerは機械翻訳などの自然言語処理から始まり音声処理や時系列データといったシーケンスがあるデータなどに幅広く利用されています。本コンペティションではニュートリノのイベントに関する時系列データを扱うため、Transformerとの相性が良かったようです。
自然言語処理:Kaggle - LLM Science Exam
コンペのURL:https://www.kaggle.com/competitions/kaggle-llm-science-exam/
本コンペはLLMが作成した科学系の難問に回答するAIモデルを開発することが目標です。LLMの自己評価能力や、リソース制約下でのLLM運用可能性の研究に貢献します。GPT-3.5が作成した問題に、より小規模なモデルで回答することで、LLMの能力とサイズの関係性を探ります。LLMをテーマとしている点があまり前例がなく、注目度の高いコンペでした。
コメント@currypurin
LLMやRAG(Retrieval Augmented Generation)というこれまでのコンペで扱われていないテーマにどうチャレンジするのかという面白さがあり、それに対する解法の多様さもあり、面白いコンペでした。
本コンペティションはLLMによって作成された難しい科学のテストに対して正しく回答するというユニークなテーマです。Wikipediaのデータが教師データとして与えられモデルをトレーニングします。LLMは近年の機械学習のトレンドでもあり、数多くのユーザがこのコンペティションに挑みました。
推薦:Amazon KDD Cup 2023 Challenge
コンペのURL:https://www.aicrowd.com/challenges/amazon-kdd-cup-23-multilingual-recommendation-challenge
このコンペは多言語・不均衡データを用いたEコマースの購買意図予測が目的です。6つの地域・言語の顧客セッションデータを使用し、次の購入商品予測や商品タイトル生成に取り組みます。多言語推薦システムの開発を促進し、グローバルな顧客体験向上を目指します。販売データに対するデータ分析の事例は多いですが、その中でもAmazonのデータを分析できるという点でとても実践的ですね。
コメント@tereka114
Amazonのデータを利用した実践的な推薦システムの開発、実業務にも応用できる要素が多く、やることが多く、学びにもなった
このコンペティションはkaggleではなく、Amazonが主催するAmazonの購買データを使った商品購入のレコメンドに関するコンペティションでした。ある商品を買った人は別のこういう商品も買う傾向にある、という分析を行って適切に商品をレコメンドすることでユーザ体験を向上させることができます。このような身近なテーマのコンペティションは自分の経験を基に解法のアイデアが浮かびやすいですね。
(3)2023年、面白かった論文
2022年に引き続き画像解析と自然言語処理が面白かった論文として選ばれました。
画像解析:Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
論文のURL:https://arxiv.org/pdf/2303.05499
この論文では、画像の中から特定の物体を見つける新しい技術を紹介しています。この技術は、言葉と画像の情報を組み合わせて、人の指示に従って任意の物体を探せるようにします。COCOなどのデータセットでテストし、この技術が非常に優れた成績を出していることも報告されています。
コメント@SiNpcw
ZeroShotの物体検出を実現するという点。テキストだけを用いてオブジェクトを識別する能力を持っており、カテゴリ名や自然言語から指定の物体を検出できる点が挙げられる。類似手法としてDETICが存在する。DETICにおいてもテキストと画像ペアを用いた学習しており一定レベルのZeroShot/FewShot物体検出を持っているが、使用感として学習データに存在しないモノに対しては、本論文手法のモデルに分があるように感じた。
ZeroShotとは機械学習モデルが未学習のタスクやデータに対して、事前知識を活用して推論を行う手法です。例えばひび割れを検知したい場合、従来ではひび割れの画像が学習の際に大量に必要でしたが、ZeroShotでは不要になります。
画像解析:Segment Any Anomaly without Training via Hybrid Prompt Regularization
論文のURL:https://arxiv.org/abs/2305.10724
この論文では、新しい異常検出技術「Segment Any Anomaly + (SAA+)」を紹介しています。この技術は、事前の特定の学習なしに、異常な部分を画像から見つけることができます。既存の方法は特定の分野に特化しているため、他の異常パターンにはあまり対応できませんでした。この技術は、多くの異常検出テストで優れた成績を出しています。
コメント@shinmura0
今までの外観検査(異常検知)技術では、人間側の趣向をAIに教えるのが難しかった。例えば、変色はOKだが、打痕はNGなど。しかし、この手法では、予め人間が異常を定義できるため、変色などの際どいOK品を擬陽性(False Positive)にすることなく、精度を上げることが可能になった。まだまだ処理時間は遅いが、将来的には主力になる可能性を秘めている。
この論文では人間の異常をAIに伝えるために「黒い穴」や「白い泡」,「部材が長すぎる」などの言語情報と実際の異常がある画像を使ってモデルをトレーニングさせています。先ほど紹介したGrounding DINOの論文は、こちらの論文の基となったモデルの1つとして引用されています。
shinmura0さん本人が実際に触ってみた記事もぜひご覧ください。
自然言語処理:Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes
論文のURL:https://arxiv.org/abs/2305.02301v2
この論文は、少ないデータで小さなモデルを訓練し、大きな言語モデル(LLM)を超える性能を出す新しい方法「Distilling step-by-step」を提案しています。これにより、計算効率が向上し、モデルの性能が向上します。
コメント@YujiAriyasu
大きいモデルが流行っていますが、小さくて悪くない精度のモデルの需要も基本的にはずっと残り続けると考えています。Chain of Thought Promptingを利用した蒸留というアイデアも面白かった。
LLM(Large Language Models)の性能を上げる指標の一つにパラメータ数があります。このパラメータ数が大きいと一般に計算コストが上がり、自分のPCだけでは動かせなくなります。しかし誰しもが高性能なモデルが必要なわけではなく、ローカルPCで効率的に動作する軽量なモデルが必要とされるケースもあります。本論文は、そのような軽量なモデルの訓練に関するものです。
LLM:A Survey of Large Language Models
論文のURL:https://arxiv.org/abs/2303.18223
この論文はAIが言語理解と生成において進化する過程を調査し、特に大規模言語モデル(LLM)の重要性と進展を論じています。
コメント@currypurin
多くのLLMが発表されているが、そのLLMの進化や、設計、能力、応用など詳しくまとめられている。
LLMの歴史、進展、最新情報などをまとめた論文となっています。引用論文数が900以上もあるので、LLMについて体系的に知りたい方にとっては十分な情報ソースになると思います。
LLaMA: Open and Efficient Foundation Language Models
論文のURL:https://arxiv.org/pdf/2302.13971
この論文はLLaMAに関する基本的な内容を記述しています。LLaMAは7Bから65Bパラメータの大規模言語モデル群です。公開データのみで学習し、より大きな既存モデルと同等以上の性能を達成しました。特に13Bモデルは175BのGPT-3を上回り、65Bモデルはさらに優れた結果を示しています。
コメント@tereka114
現地点で最も精度が高いLocal LLMは他の論文(Mistralなど)になるが、最も有名なのはLLaMAであることからこちらを選定しました。LLaMAをベースとしたモデルが多く、基本となるため。
LLaMAはMetaが発表したLLMで、以下の特徴があります。利用のハードルが低いので好んで使われています。
・モデルは小型で高性能
・無料で商用利用も可能
・オープンソース
(4)2023年、面白かったサービス
注目のAIサービスもアンケート調査項目に追加しました。AIを普段扱っている人達が注目するサービスにはどのようなものがあるでしょうか?
ChatGPT
サービスのURL:https://openai.com/blog/chatgpt/
OpenAIが2022年11月にリリースして話題になった、AIチャットボット。
コメント@currypurin
ChatGPTでGPT4が使えるようになり、あまりの能力に驚きました。その後、Advanced Data AnalysisというPythonを実行できる環境やDALL-E(画像生成)も使えるようになり、技術が生活を変えるところが面白かったです。
コメント@tereka114
公式だけあり、ChatGPTのモデルを使った最も優れたサービスであるため。特にGPTsやCode Interpreterなど他の生成AI(ClaudeV3, gemini)にはないものがある。
Gemini
サービスのURL:https://gemini.google.com/
ChatGPT、Gemini、Claude-3などは作っている会社が違うものの、どれも性能は高いです。GCPやDall-Eなどの他サービスとの連携といった、チャット以外の機能の違いでどのサービスを使うかを選んでも良いかと思います。
コメント@SiNpcw
選定理由として競争が起きたことを挙げる。GoogleがGPT-4 (GPT-4V)への対抗策として打ち出したサービス。API経由にてGemini ProとGPT-4Vを比較した結果、日本語における認識はGeminiに分があるように感じた。また既存のGCPサービスとの統合もしやすいため扱いやすかった。2024年のはじめにもGeminiのアップデートにぶつけるようにOpenAI Soraなどより新しい技術を出している。競争が起きたことでこの分野の発展速度がより早くなる可能性があると考えている。
イルシル
サービスのURL:https://elucile.lubis.co.jp/
イルシルはAIを搭載したスライド自動生成サービスです。テキストからAIがスライドを自動生成してくれます。このようなAIを使った業務補助サービスは今後も増えていき、業務の本質的な部分へ割く時間が増えていくと思われます。
コメント@YujiAriyasu
スライドを非常に短時間でそれっぽく作ることができる。拡張性もちょうど良かったです。
ZOO
サービスのURL:https://zoo.dev/text-to-cad
ZOOはテキスト入力からCADの図面を作るサービスです。テキストから何かを作るAIは近年増えています。例えば絵、スライド、CAD、人物、動画、小説などなどたくさんのAIがあります。
コメント@shinmura0
日本の主要産業である製造業において、CADを自動生成することができれば、大幅な時間短縮につながる。そういった意味で、テキストからCADを生成できる本サービスには、大きな期待を持っている。将来的には、製造業だけではなく、各個人が自分で自分の物を設計できるような未来になると更に面白い。
(5)今後のデータ解析コンペや技術への期待と目標
Kagglerの皆様に今後のコンペや技術への期待や目標をお伺いしました。
今後どのようなコンペがあると面白いと思いますか?
様々なアイデアがありましたが近年の急速な技術発展の内容がコンペになると面白そうです。
・より難しいコンペが増えそうでワクワクしています!
・画像+音データが時系列に並んだマルチモーダルコンペ。Kaggleの鳥コンペが、こういった形式になると面白い。
・AIによる作成物かどうかの判定するコンペ。画像だけではなく音声や動画の生成が非常に現実に近いものとなってきており、一見すると判らないというものも多い。そのためセキュリティ分野の一端としてLLMやGPTなどの生成AIによる作成物かどうかの判定を行うコンペが増えるのではないかと想定される。どのように見破るのか?という観点で使える技術や手法に興味がある。
・これからも新しい技術が出てくると思うので、そこにチャレンジするコンペが行われると面白いと思います。
・VQA、LLMを始めとした基盤モデルの発展に伴う精度の高いソリューションを見たい。
今後どのような技術が生まれると面白いと思いますか?
2023年はLLMが普及し、多くの人が触ったり、業務で活用されたりした年でした。今後の仕事とAIの関係がどうなっていくか、注目していきたいですね。
・画像系の強いzero shot learningのモデル
・AIがより高速・低電力のAIを生み出す、SDGsなAIの実現
・より広い範囲での人を支援する技術。今日では生成AIの発展により画像や音声・動画を生成することができるようになっている。これらは現在人が生み出しているクリエイティブなモノをより補助、代替、効率化する技術である。ゲームや映画、3Dモデリングなどのエンタテインメント分野との親和性が高く露出も多い。一方で産業分野においてはまだ適用が進んでいないように見える。そのため、例えば3Dモデリング技術を部品の自動設計のように活用するなど産業分野など広い範囲に波及・適用されると面白いと考える。
・Kagglerのような、データ分析をする人が不要になる時代が来そうで、どのようになるか楽しみです。
・LLMのさらなる進化、今までできていなかったことが急速に達成されつつあるので、どのようなことまでできるのか期待したい。
2024年の目標を教えてください
自身の飛躍は勿論ですが、AIを活用した創作活動に意欲を燃やす方もいらっしゃいました。
・今まで通り楽しむのみと思っています
・生成AIを勉強して、マンガや映画を製作してみたい。
・LLM、生成AIの業務適用およびコンペを通して技術キャッチアップは引続き継続したい。
・Kaggleのコンペに取り組んでいきたいです。
・LLMやVLMのさらなる活用。LLMやVLMはまだまだ発展途中であり、今年は更にできることが増えるのではと考えている。引き続きキャッチアップをして業務や論文執筆など、技術を使った貢献をしていきたい。
(6)Kagglerの皆様に聞いた衛星データ使ってやってみたいこと
最後に、本記事を掲載している「宙畑(そらばたけ)」が宇宙ビジネスメディアということで、「衛星データ」についてもお伺いしました。地球規模での課題解決や3Dデータへの取込みなどでコメントをいただきました。
・同一の場所で、時系列に並んだ画像データ(動画データ)を分析してみたい。例えば、風力発電所を撮影したものから、風速を予想したり、工場の煙から、工場の稼働率を推定するようなコンペ。
・農作物収穫予想の高度化や災害リスク検知やハザードマップとの連携した解析などの高度化ができないかをやってみたい。
・衛星データを使った需要予測
・衛星写真を用いたVLM(Vision and Language Model)の活用
(7)2023年に開催された衛星データコンペ
Google Research - Identify Contrails to Reduce Global Warming
Kaggleでは静止衛星の画像から、雲を検出するコンペティションが開催されました。
衛星画像の5倍超解像度化 (for OSS)
https://solafune.com/ja/competitions/7a1fc5e3-49bd-4ec1-8378-974951398c98?menu=about&tab=overview
衛星画像を主に扱うsolafuneでは、OSSのための超解像コンペティションが開催されました。
生成画像とオリジナル画像の分類
https://solafune.com/ja/competitions/05724228-0ac1-4488-a42f-e945f2117632?menu=about&tab=overview
衛星画像を撮影するのは高価な一方、機械学習のためには大量の画像が必要です。低コストでライセンスフリーの衛星画像を作成するためのコンペティションとして開催されました。
衛星画像の雲領域検出
https://solafune.com/ja/competitions/65571524-39b0-4972-9001-ba6b61d6b20f?menu=about&tab=overview
Kaggleと同じで雲を検出するコンペティションがsolafuneでも開催されました。
(8)まとめ
本記事では、Kaggler5名の方にご協力いただき、2023年の面白かったコンペティションや論文、AIサービスについてご紹介をしました。
また、宙畑では2022年8月より、衛星データと機械学習に関する論文を毎月まとめて紹介しています。興味があればこちらもぜひご覧下さい。
