【2024年5月】衛星データ利活用に関する論文とニュースをピックアップ!
2024年5月に公開された衛星データの利活用に関する論文の中でも宙畑編集部が気になったものをピックアップしました。
宙畑の新連載「#MonthlySatDataNews」では、前月に公開された衛星データの利活用に関する論文やニュースをピックアップして紹介します。
実は、本記事を制作するために、これは!と思った論文やニュースをTwitter上で「#MonthlySatDataNews」をつけて備忘録として宙畑編集部メンバーが投稿していました。宙畑読者のみなさまも是非ご参加いただけますと幸いです。
2024年5月の「#MonthlySatDataNews」を投稿いただいたのはこの方でした!
Advancing ecological quality assessment in China: Introducing the ARSEI and identifying key regional drivers https://t.co/UhiRbtZCaC #MonthlySatDataNews
RSEIにエアロゾルを加えた生態環境の質を評価するための改良型リモートセンシング生態指標(ARSEI)を開発して中国で評価— たなこう (@octobersky_031) May 18, 2024
それではさっそく2024年5月の論文を紹介します。
Future groundwater potential mapping using machine learning algorithms and climate change scenarios in Bangladesh
【どういう論文?】
・本論文は、バングラデシュにおける将来の地下水ポテンシャルゾーンを機械学習アルゴリズムと気候変動シナリオに基づいて推定することを目的とする
【技術や方法のポイントはどこ?】
◾️先行研究との違い
①複数の機械学習アルゴリズムの比較、ROC曲線による性能評価
・先行研究の多くは、GISやファジーロジックなどの単一手法に依存していた
・例えば、AHP(階層分析法)やファジーロジックは、各要因の重み付けを専門家の意見に基づいて行うため、主観性が入りやすい問題があった
・本研究では、人工ニューラルネットワーク(ANN)、ロジスティックモデルツリー、ロジスティック回帰の3つの異なる機械学習アルゴリズムを使用し、それぞれの性能をROC曲線を用いて評価した
※ROC曲線のAUCは、モデルの真陽性率と偽陽性率をバランスよく評価できる
◾️利用パラメーター
①曲率 (Curvature)
・地形の凹凸を示す指標であり、地形の形状が地下水の流れや蓄積に影響する
②排水密度 (Drainage Density)
・単位面積あたりの河川の総長、高い排水密度は低い地下水補給を示すことが多い
③傾斜 (Slope)
・地表面の傾斜度、急な傾斜は雨水が迅速に流れ、地下水補給が少なくなる
④粗さ (Roughness)
・地形の起伏の度合い、高い粗さは高い地下水補給を示すことが多い
⑤降雨量 (Rainfall)
・降水量、地下水の主な補給源となる
⑥気温 (Temperature)
・地域の温度、蒸発量に影響を与え、地下水の補給に影響する
⑦相対湿度 (Relative Humidity)
・大気中の湿度。蒸発と降水のバランスに影響を与える
⑧線密度 (Lineament Density)
・地質構造の線状特徴の密度。断層や亀裂が地下水の流動を助ける
⑨土地利用・被覆 (Land Use and Land Cover)
・土地の利用状況と被覆の種類、都市化や農業が地下水補給に影響を与える
⑩一般的な土壌タイプ (General Soil Types)
・土壌の種類、浸透率や保水力に影響
⑪地質 (Geology)
・地質構造、岩石の種類や構造が地下水の蓄積に影響する
⑫地形 (Geomorphology)
・地形的特徴、地形の形成過程が地下水の動態に影響
⑬トポグラフィックポジションインデックス (Topographic Position Index, TPI)
・地形の位置を示す指標、地形の高低差に基づく
⑭トポグラフィックウェットネスインデックス (Topographic Wetness Index, TWI)
・地形の湿潤度を示す指標、水の流れや蓄積に関与
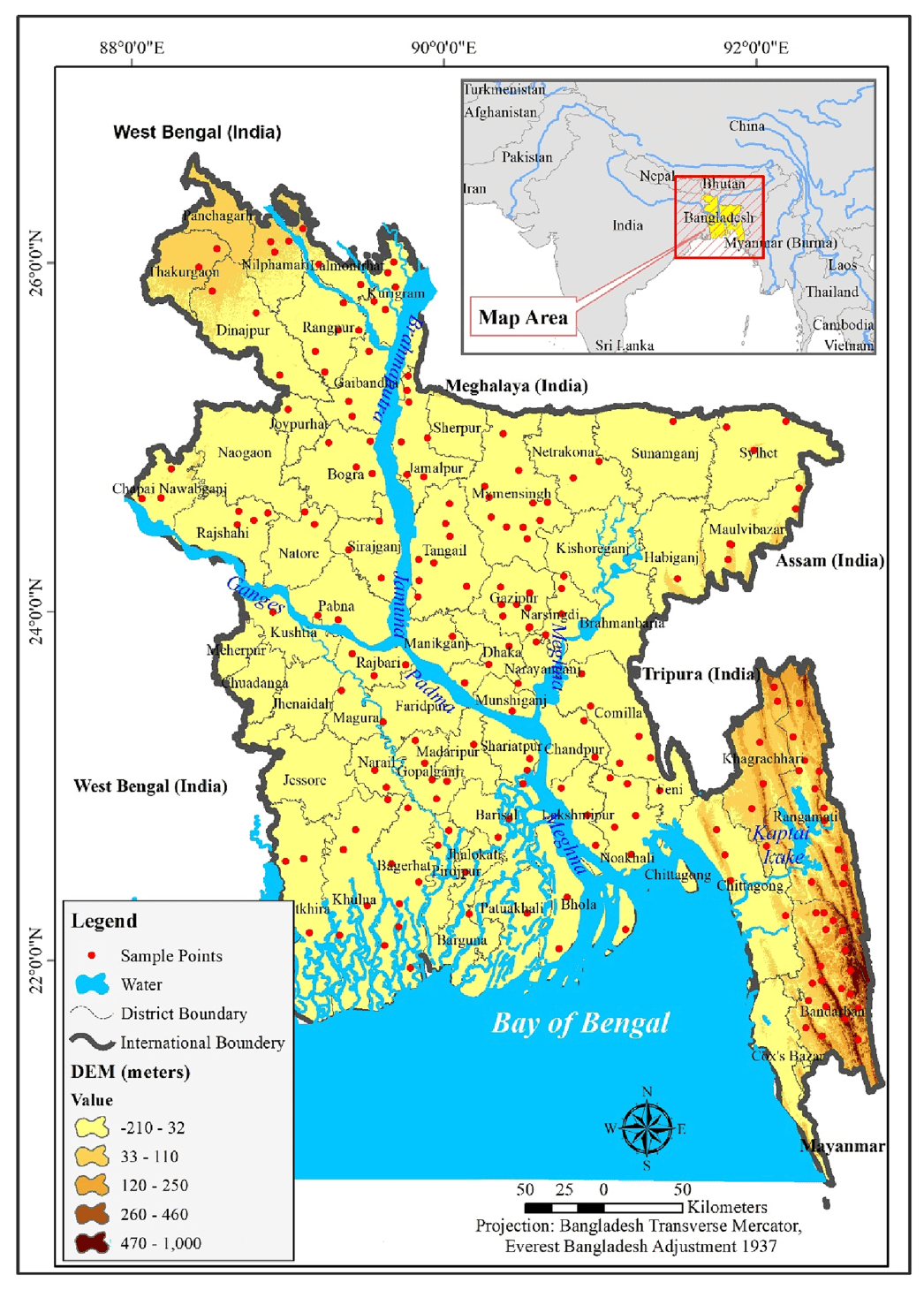
◾️研究エリア
・本研究の対象地域はバングラデシュである
・バングラデシュは、河川地帯の地形と熱帯気候に恵まれた地域となっていて、特に、ブラマプトラ川、ジャムナ川、パドマ川、メグナ川などの主要河川が国全体を通っていて、地下水ポテンシャルに大きな影響を与えている
◾️人工ニューラルネットワーク(ANN)
①概要
・生物学的ニューロンの機能を模倣した多層のモデルであり、入力層、隠れ層、および出力層から構成される
・各層のニューロンは重み付きの接続で繋がれており、データを処理して最終出力を生成する
②メリット
・ANNは複雑な非線形関係をモデル化する能力がある
・多層構造と多様な活性化関数を使用することで、高い予測精度が得られる
・大量のデータや多様なデータソースを扱うことができる
③デメリット
・モデルの内部構造が複雑であり、結果の解釈が難しい
・トレーニングには大量の計算資源と時間が必要となる
・過学習を防ぐための正則化やドロップアウトなどのテクニックが必要となる
※正則化・・・モデルのパラメータ(重み)にペナルティを加えることで、モデルが複雑になりすぎるのを防具こと
※ドロップアウト・・・トレーニングの各反復中にランダムに一部のニューロンを無効化(ドロップアウト)することで、ネットワークが特定のニューロンやその接続に過度に依存するのを防ぐこと
◾️ロジスティック回帰
①概要
・イベントの発生確率を予測するための統計モデルであり、特定の条件変数(入力変数)とイベント(地下水の存在)の関係を調査する
②メリット
・モデルの出力と係数の意味が明確で、結果の解釈が容易である
・他の複雑なモデルに比べて計算が速く、リソースの消費が少ない
・正則化によって過学習を防ぐことが容易である
③デメリット
・特徴量の線形結合を使用して確率を予測するため、非線形関係を十分にモデル化する能力が限られている
・重要な特徴量を適切に選択する必要があり、誤った特徴量がモデルの性能を低下させる可能性がある
◾️ロジスティックモデルツリー
①概要
・ロジスティック回帰と決定木を組み合わせたハイブリッドモデル
・データをいくつかの条件に基づいて分割され、各ノードで決定を行うツリー構造が作成される
・各ノードには条件(特徴量のしきい値)があり、例えば特徴量Xがある値より大きいか小さいかによってデータを分割する
・その上で、各ノードにロジスティック回帰モデルが適用される
②メリット
・ロジスティック回帰の精度と決定木の柔軟性を組み合わせることで、高い予測精度を実現する
・決定木の構造を持つため、各分割がどのように行われたか、また各ノードでどのようなロジスティック回帰が適用されたかを視覚的に理解しやすい
③デメリット
・モデルの構築と最適化に時間と計算資源を要する
・最適なパラメータを見つけるための調整が必要となる
【議論の内容・結果は?】
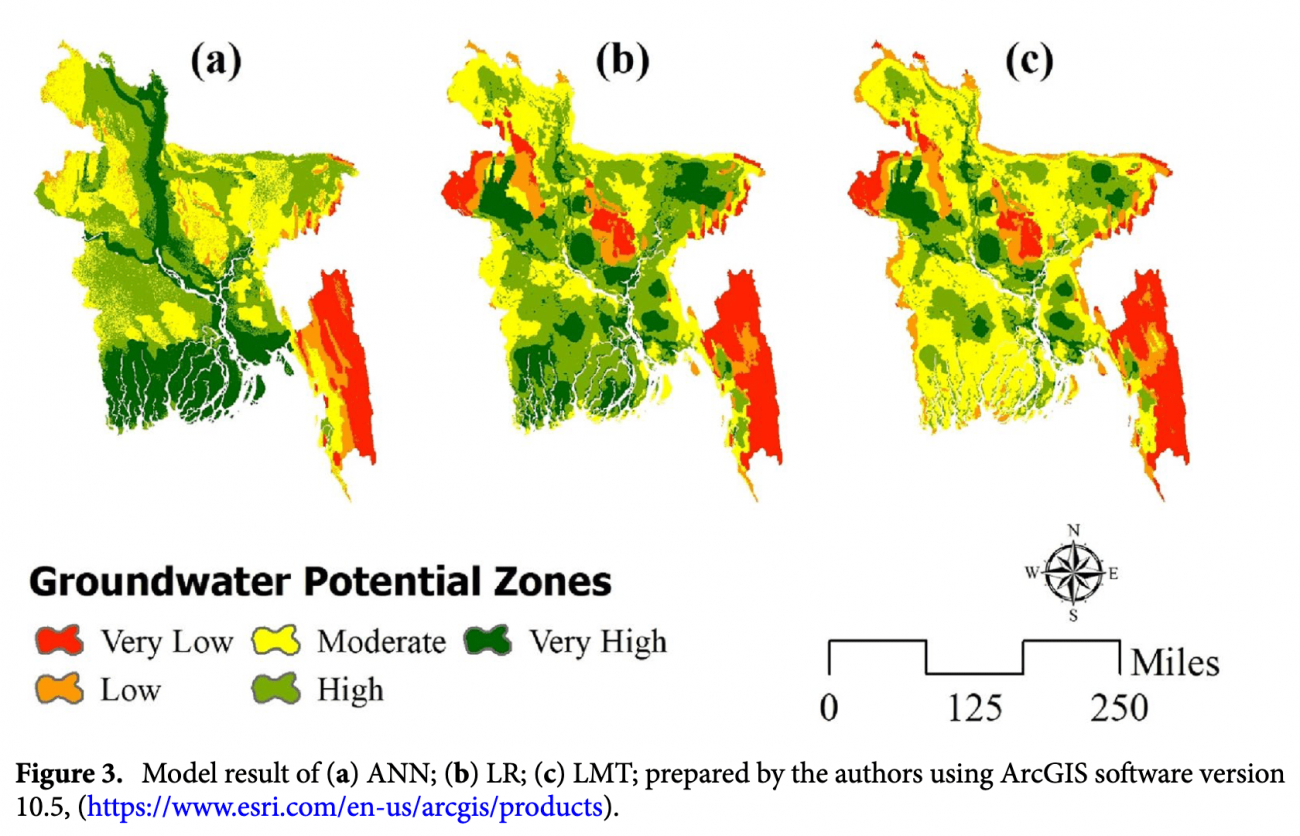
◾️各モデルの結果
⓪前提
・以下①〜③内の各割合は、研究エリア内に地下水がどれだけ存在する可能性が存在するかに関するポテンシャル分布を表現している
・例えば、「非常に高いポテンシャル: 33.50%」とあれば、研究エリア内の33.50%は地下水が非常に豊富に蓄積されている可能性があることを意味している
・各ポテンシャルは地下水のポテンシャル(量)がどれだけあるかを示しており、機械学習モデル(ANN, LR, LMT)の結果として得られた地下水ポテンシャルの予測値を、Jenks’ natural breaks classifierを用いて5つのポテンシャル種類に分類している
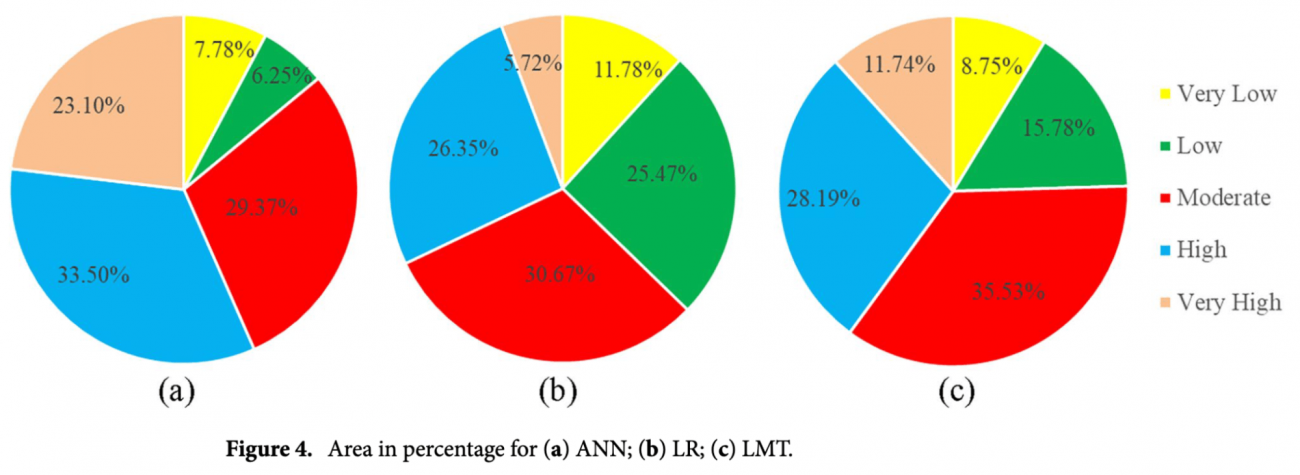
①人工ニューラルネットワーク(ANN)モデルを用いた各ポテンシャルごとのエリア比率
・非常に高いポテンシャル: 33.50%
・高いポテンシャル: 23.10%
・中程度のポテンシャル: 29.57%
・低いポテンシャル: 6.25%
・非常に低いポテンシャル: 7.78%
・特徴: 主な河川周辺に非常に高いポテンシャルゾーンが集中した
②ロジスティック回帰モデルを用いた各ポテンシャルごとのエリア比率・非常に高いポテンシャル: 5.72%
・高いポテンシャル: 26.35%
・中程度のポテンシャル: データなし
・低いポテンシャル: データなし
・非常に低いポテンシャル: データなし
・特徴: 南西部沿岸地域、主要な河川周辺を高いポテンシャルゾーンとして分類された
③ロジスティックモデルツリーを用いたポテンシャルごとのエリア比率
・非常に高いポテンシャル: 11.74%
・高いポテンシャル: 28.19%
・中程度のポテンシャル: 28.19%
・低いポテンシャル: 15.78%
・非常に低いポテンシャル: 8.75%
・特徴: 北西部および南東部の丘陵地帯が低いポテンシャルゾーンとして分類、沿岸地域が中程度のゾーンとして分類され、他のモデルと若干異なる結果が得られた
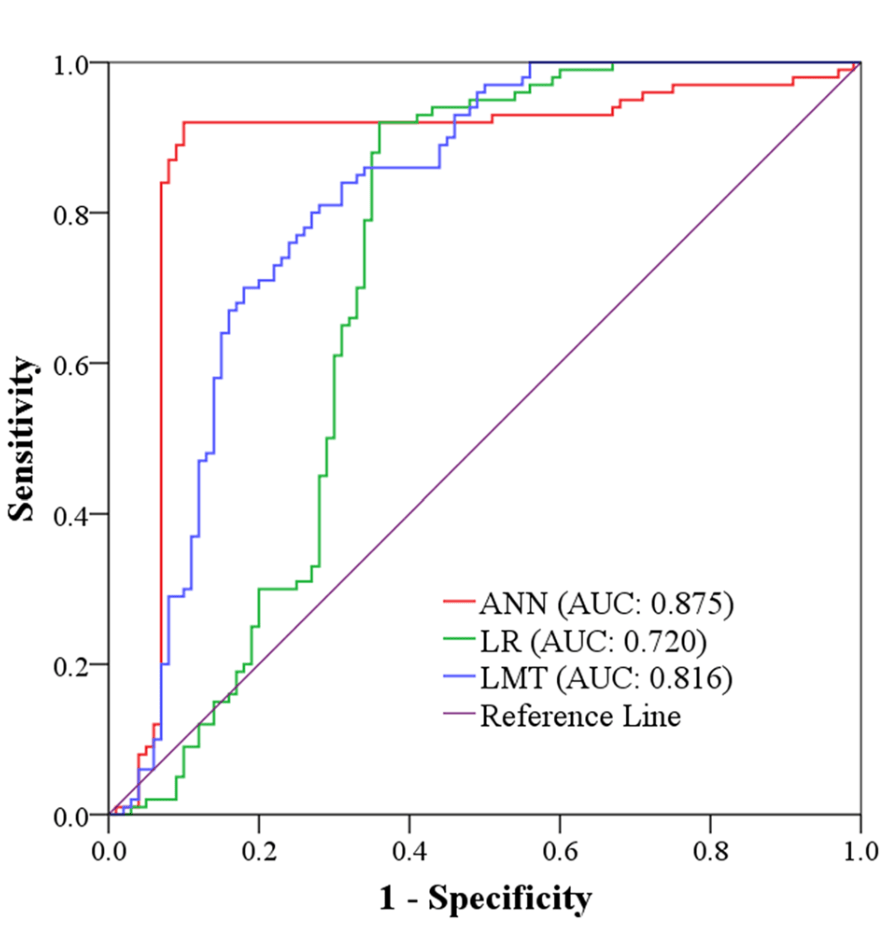
◾️モデルの精度評価
・正解データ: 地下水の存在が確認された地点(井戸の位置など)と地下水が存在しない地点のデータ
・ANNモデル: AUC = 0.875
・ロジスティック回帰モデル: AUC = 0.720
・ロジスティックモデル: AUC = 0.816
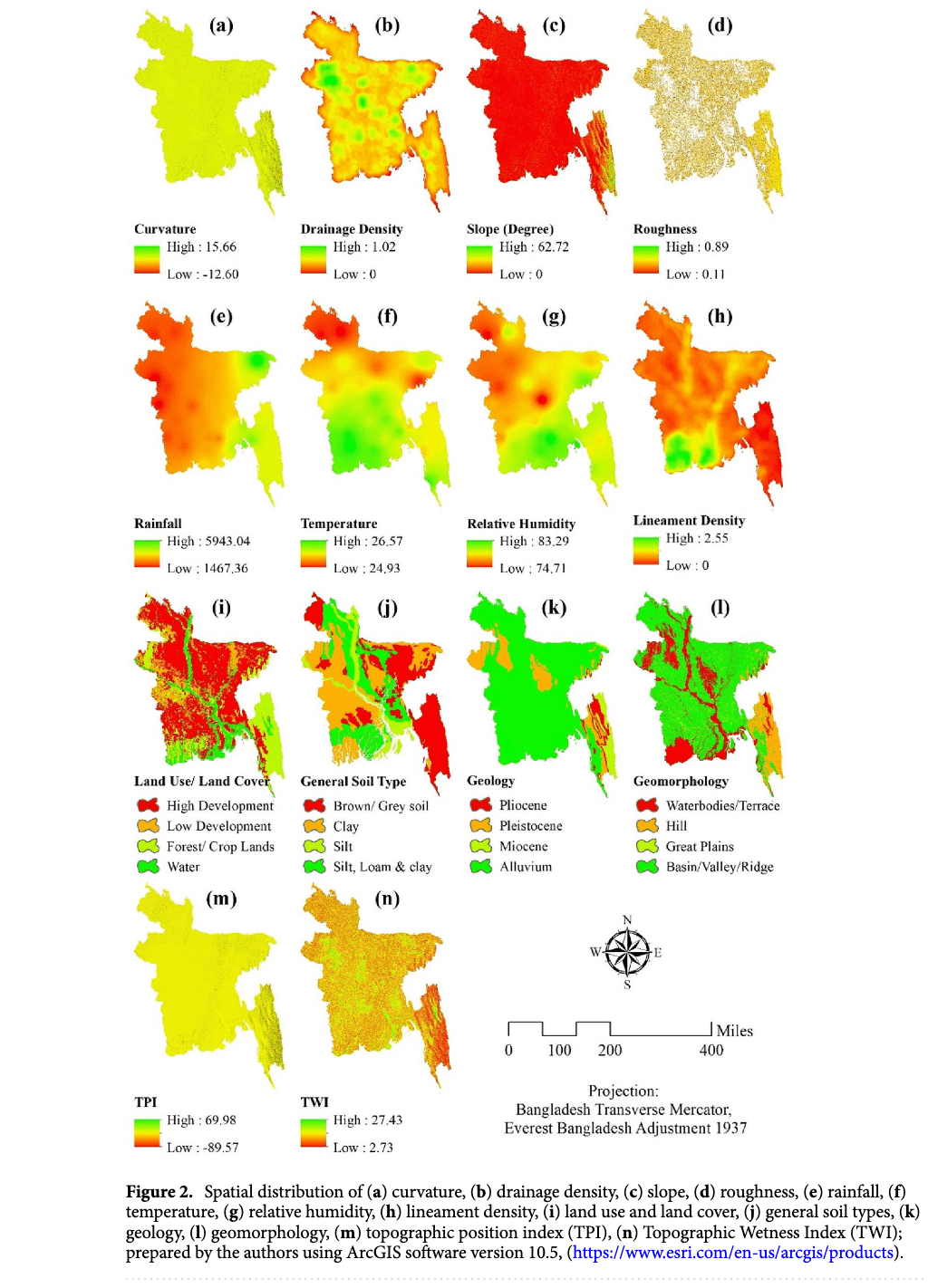
◾️各パラメータごとによるエリア内のポテンシャル分布予測結果
①a: Curvature (カーブ)
・地表のカーブは地下水の流れと集積に影響を与える
・高いカーブの地域(凸状)は地下水の流れが速くなり、低いカーブの地域(凹状)は地下水が集積しやすくなる
・南東部に高いカーブの地域が集中している
② b:Drainage Density (排水密度)
・低い排水密度の地域は浸透率が高く、地下水のポテンシャルが高い
・一方、排水密度が高い地域は浸透が妨げられ、地下水のポテンシャルが低くなる
・西部にやや高い排水密度の地域があり、南部は低い密度である
③c: Slope (勾配)
・勾配が大きいと雨水が早く流れ、地下水の補給が減少する
・平坦な地域は地下水の補給に適してる
・南東部と東部に急勾配の地域があり、大部分の土地は平坦である
④d: Roughness (粗さ)
・地形の起伏を示し、粗さが大きいほど地下水の流動が複雑になる
・粗さは全体的に低いが、所々に高い地域がある
⑤e: Rainfall (降雨量)
・降雨量が多い地域は地下水の補給が期待できるため、高いポテンシャルを持つ
・南東部と東部に降雨量が高い地域が集中している
⑥f: 気温 (Temperature)
・気温は蒸発量に影響し、地下水の補給に影響を与える
・温暖な地域は地下水の補給に適している
・南部は比較的高温で、北部は低温である
⑦g: Relative Humidity (相対湿度)
・湿度が高いと蒸発が減少し、地下水の補給が促進される
・海に近い南部で高湿度、内陸部で低湿度となっている
⑧h: Lineament Density (線密度)
・線状構造が多い地域は二次的な浸透率と透過性が高く、地下水のポテンシャルが高い
・南西部で高密度、他の地域では低密度となっている
⑨i: Land Use/Land Cover (土地利用/被覆)
・開発が進んだ地域は地下水の補給が妨げられる
・森林や農地が地下水の補給に適している
・開発が進んでいる地域が広く、特に南東部のチッタゴン丘陵地帯を除く全域で高開発地域が広がっている
⑩j: General Soil Type (土壌タイプ)
・土壌の種類により地下水の浸透率が異なる
・砂質土壌は高い浸透率を持つ
・南部と東部に混合型土壌が多く、粘土質土壌は東部に集中している
⑪k: Geology (地質)
・地質構造は地下水の貯留と移動に影響を与える
・古い地層は通常低い透水性を持つ
・中央部と西部は主に更新世、南東部は第三紀の地質が支配的である
◾️示唆
・ すべてのモデルにおいて、主要な河川の周辺地域が高い地下水ポテンシャルゾーンとして分類され、これらの河川が地下水ポテンシャルに重要な役割を果たしていることが示されている
・ANNモデルが最も高い精度を示しており、複雑なパターンを捉える能力が高いことが分かる
#地下水 #ROC曲線 #人工ニューラルネットワーク #ANN #ロジスティックモデルツリー #ロジスティック回帰
Automatic detection of methane emissions in multispectral satellite imagery using a vision transformer
【どういう論文?】
・本研究は、メタン排出の自動検出をマルチスペクトル衛星データを用いて行うディープラーニングモデルを開発し、現行の方法よりも高い空間解像度と時間解像度を実現することを目的とする
【技術や方法のポイントはどこ?】
◾️データベースの準備
①データ取得
・ESAのSentinel-2AとSentinel-2B衛星から取得したL1C TOA(大気頂面反射率)データを使用する
②バンド構成
・Sentinel-2には13のスペクトルバンドがあり、特にバンド12(SWIR: 短波赤外線)がメタン吸収に敏感で重要である
③解像度
・10mから60mの範囲で、バンド12は20mの解像度
・すべてのスペクトルバンドをバンド12の20mに再サンプリングする
④タイル選定
・25%以上の雲覆いを避け、クラウドカバーが少ない地域のタイルを選定する
⑤サブディビジョン
・110×110km²のタイルを2.5×2.5km²のウィンドウに分割する
◾️ 合成メタンプルーム生成
①概要
・メタンの検出を訓練するためのデータを作成するために、メタンがどのように拡散するかのモデルを使う
・実際のメタン排出データは限られているため、合成データを使用して大量の訓練データを生成する
②生成ステップ
・多様なシナリオをシミュレーションするために、メタンの排出量と風速をランダムに選ぶ
・Gaussianプルームモデルの数式を使って、メタンが風でどのように広がるかを計算する
・大気の乱流を模倣するために2次元の空間にランダムなノイズ(雑音)を追加する
・約20,000のプルームを生成し、訓練、バリデーション、テスト用に分割する
◾️合成プルーム埋め込み
①概要
・モデルにメタン排出を検出する方法を学習させるためには、メタンが存在する(ポジティブ)場合と存在しない(ネガティブ)場合の両方のデータが必要である
・合成プルーム埋め込みを通して、モデルはメタン排出の特徴を正確に識別できるようになる
・実際には、ビール-ランバートの法則を使用して、生成したメタンプルーム(ガウシアンプルーム)をSentinel-2衛星画像の特定のバンド(バンド12)に埋め込む
②ビール-ランバートの法則
・光が物質を通過する際にどの程度吸収されるかを説明する法則である
・本法則を使って、メタンが存在する場所での光の吸収をシミュレーションし、画像に反映させる
◾️マルチバンド・マルチパス(MBMP)メタン検出法
①概要
・衛星画像を解析して、地表からのメタン排出を見つける
②手法
・衛星画像には複数のスペクトルバンドがある中で、バンド12(SWIR: 短波赤外線)はメタン吸収に敏感であり、本性質を利用して、メタンの存在を示す信号を探す
・ 特に、MBMP法では複数のバンドの反射率を比較する式を使う
・例えば、ある時刻tのバンド12とバンド11の反射率を比べ、その違いを利用してメタンの存在を検出する
【議論の内容・結果は?】
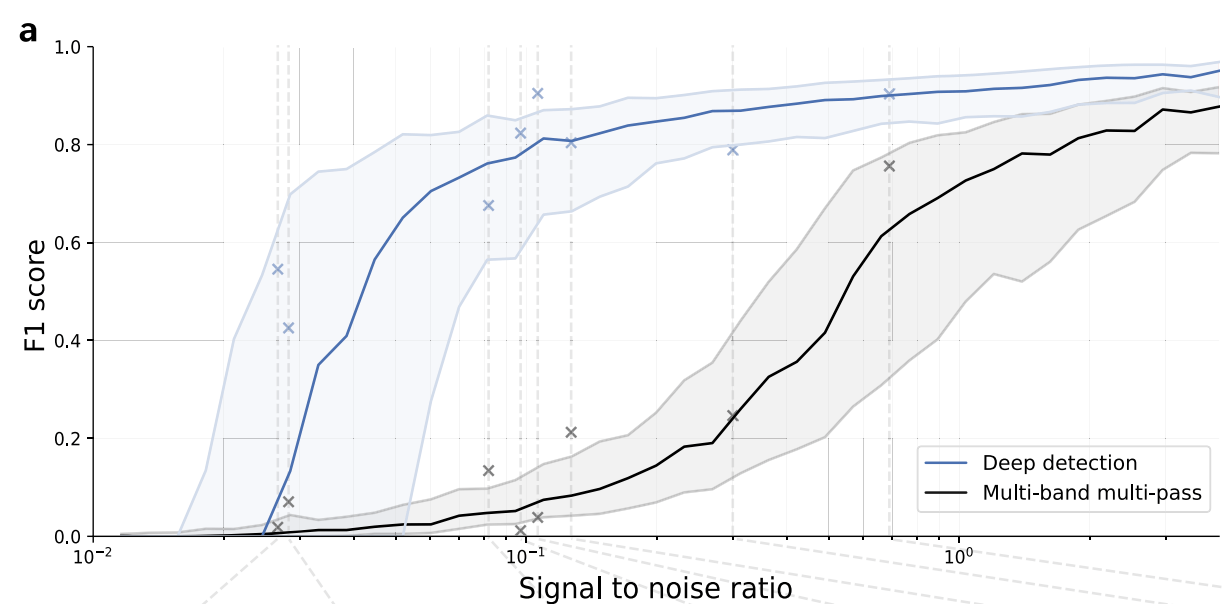
①ディープラーニングモデル vs. MBMP法
・F1スコアは、精度(precision)と再現率(recall)の平均であり、精度は正確に検出されたメタン排出の割合、再現率はすべてのメタン排出の中で正しく検出された割合を示す
・ディープラーニングモデルは、ノイズが多い(SNRが低い)環境でもメタン排出を正確に検出できるため、実用的な条件下で非常に有効である
・一方、MBMP法はノイズが少ない場合にのみ信頼性が高く、ディープラーニングモデルに比べて実用性が低いことがわかる
②検出画像一覧
・1列目は、メタンプルームが埋め込まれた後のバンド12(短波赤外線)の衛星画像データを示している
・2列目は、MBMP(マルチバンド・マルチパス)法を適用した結果を示している
・3列目は、ディープラーニングモデルを適用した結果を示している
・4列目は、実験で使用された合成メタンプルームの実際の位置を示していて、グランドトゥルースとして機能している画像である

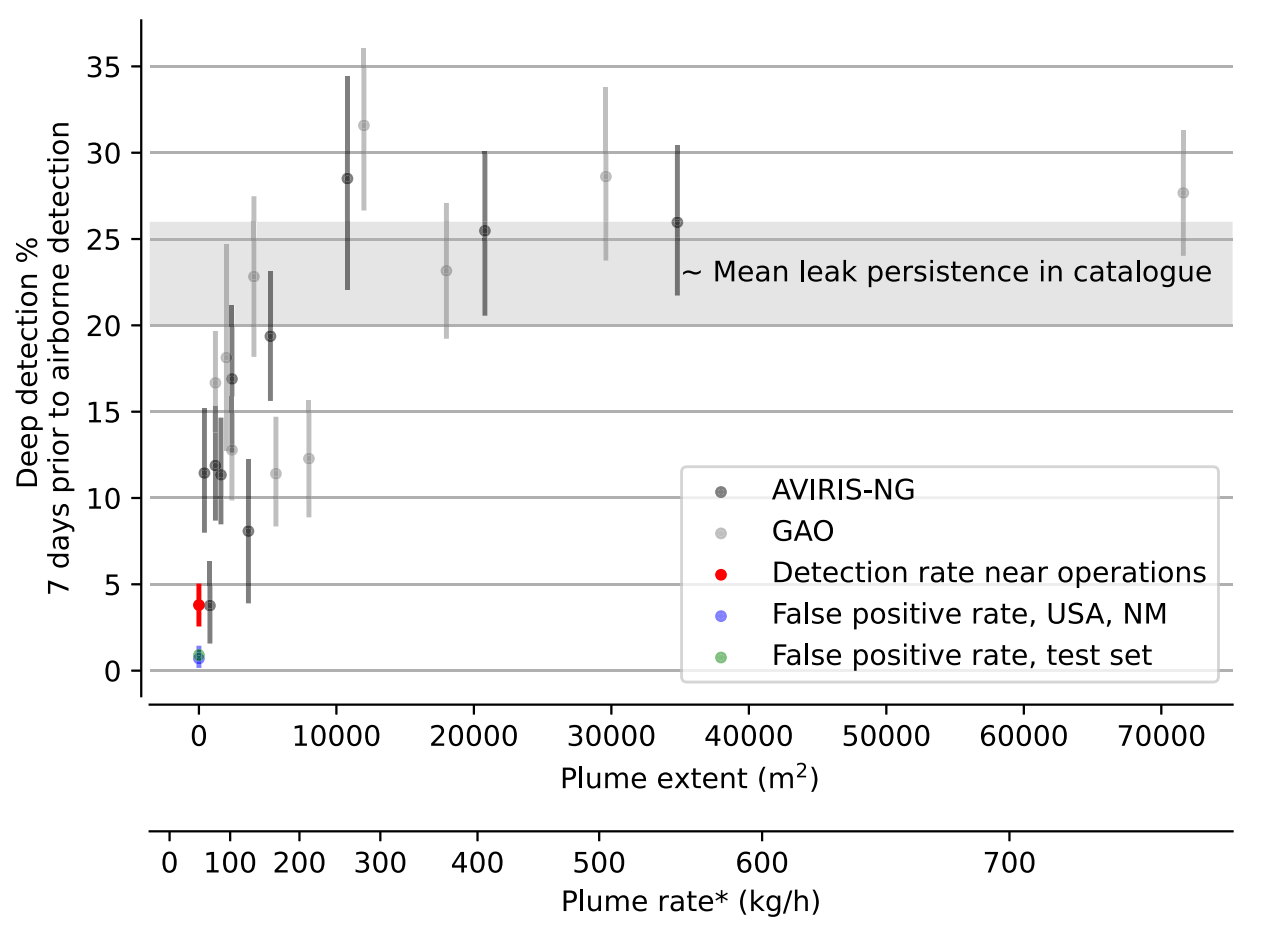
③実際のメタン検出データとの確認
・訓練されたディープラーニングモデルを使用して、既存のメタン漏出カタログに基づく検出性能を評価する
・漏出面積が10,000平方メートル以上のプルームが安定して検出されることを示していて、平均的な漏出率は200〜300 kg/hとなっている
④ディープラーニングモデルを用いたSentinel-2データでのメタン漏出検出の具体的な例
・異なる種類のインフラストラクチャ(油田、ガスプラント、パイプラインなど)でメタン漏出を正確に検出できることが示されている
・カタログ化された漏出地点と一致していることから、モデルの信頼性が確認できる
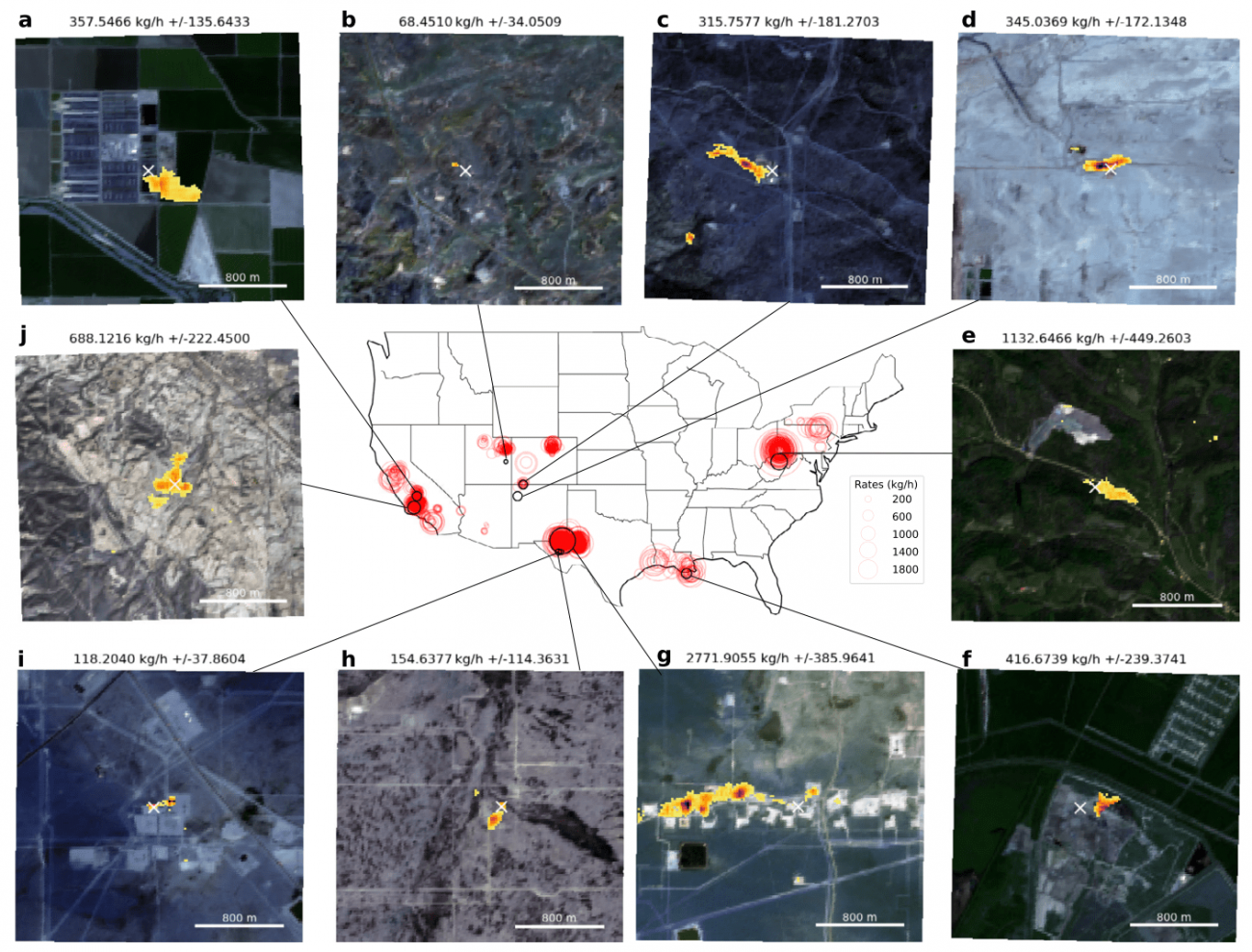
※画像b: パイプライン
※画像c: 天然ガスプラント
※画像d: 炭鉱
※画像e, g, h, i: 石油・ガスインフラ
※画像f: 天然ガスプラント
※画像j: 油田
Bertrand Rouet-Leduc, Claudia Hulbert(2024).Automatic detection of methane emissions in multispectral satellite imagery using a vision transformer
#メタン #マルチバンドマルチパス #MBMP #Sentinel-2
Advances in Deep Learning Recognition of Landslides Based on Remote Sensing Images
【どういう論文?】
・本論文は、地球温暖化や降雨の増加によって増加している地すべりの危険性とリスクを背景に、衛星画像を用いた深層学習による地すべり検出の進展についてまとめたものである
【手法一覧】
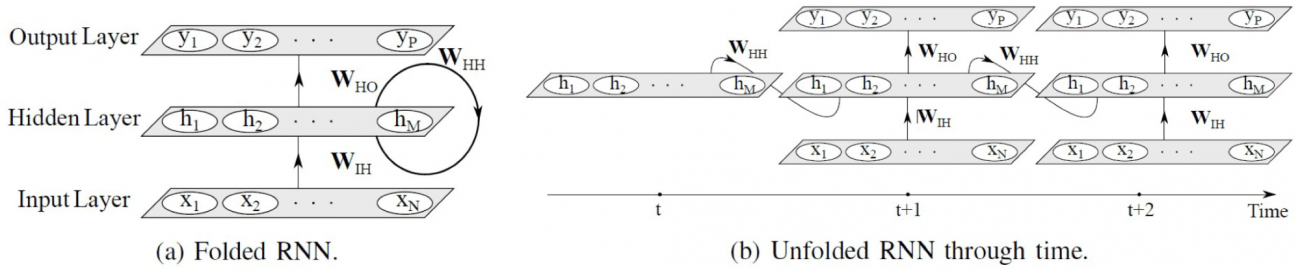
◾️再帰型ニューラルネットワーク(RNN)
①概要
・ RNNは1986年に提案されたモデルで、その特徴はデータの時系列的な依存関係をモデル化できる点にある
・各ノードが過去の情報を「記憶」として保持し、新しい入力と共に次の状態を予測する
・しかし、長期の依存関係を学習する際には、「勾配消失」という問題に直面しやすい
・上記問題を解決するために、LSTMやGRUなどの改良型RNNが開発されている
②用途・性質
・山崩れのような連続したデータの流れを追いかけるための記憶を持つカメラのような性質を持つ
③利点と課題
・時系列データに強く、過去の情報を活用して現在の状態を推測するのに優れていることが利点
・計算量が大きく、長期的な依存関係の学習が困難なことがあることが課題
◾️CNN(畳み込みニューラルネットワーク)
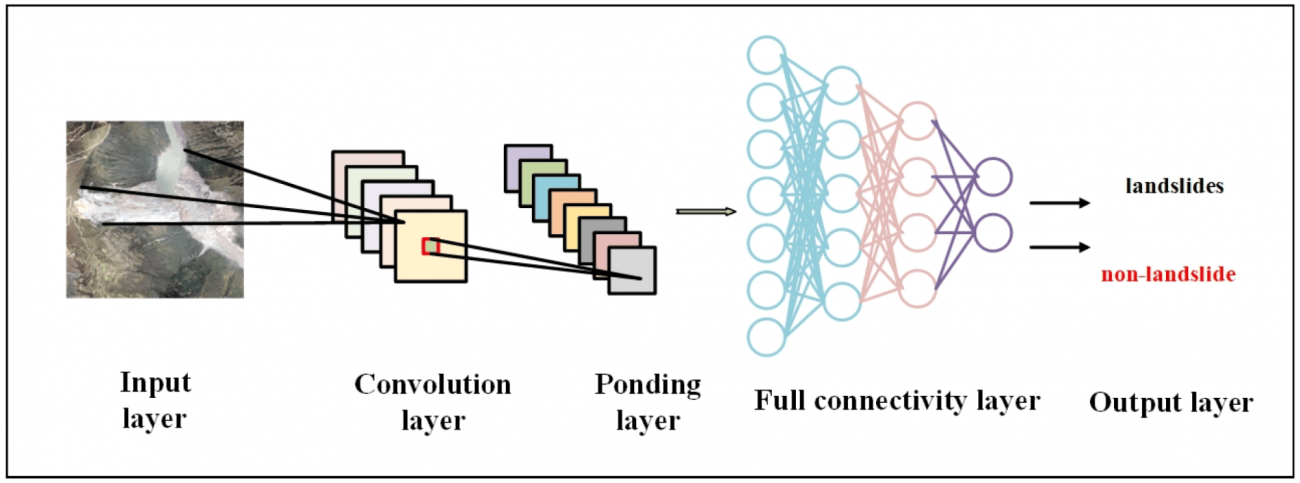
①概要
・CNNは1998年にによって提案されたモデルで、特に画像データの特徴抽出に特化している
・畳み込み層、プーリング層、全結合層から構成され、畳み込み層では画像から特徴を抽出し、プーリング層でデータを縮小して処理を効率化する
②用途・性質
・山崩れの現場を細かく調査するように、画像内の局所的な特徴を効率的に捉える
③利点と課題
・局所的な特徴を効果的に捉えることができ、画像認識に非常に強力であることが利点
・全結合層においてパラメータ数が多くなりがちで、過学習を起こしやすいことが課題
◾️Mask R-CNN
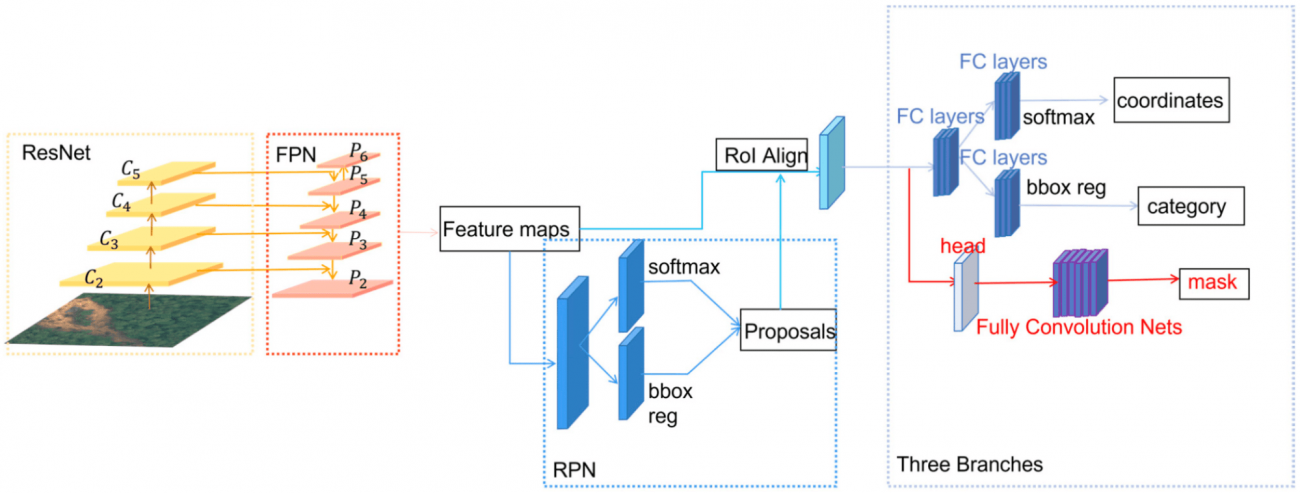
①概要
・Mask R-CNNは、オブジェクトのセグメンテーション(ピクセルレベルでの分類)を可能にするモデルで、R-CNNを基にしている
・Fast R-CNNのアーキテクチャを引き継ぎ、各オブジェクト候補に対してバウンディングボックスとクラスラベルを予測する
・各オブジェクト候補のバウンディングボックス内で、ピクセルレベルでオブジェクトの形状を抽出し、マスクを形成する
②用途・性質
・山崩れの全体像だけでなく、その詳細まで精密にマッピングする高度な探査性質を持つ
③利点と課題
・高精度なオブジェクト認識とセグメンテーションが可能で、詳細な画像解析に適していることが利点
・計算コストが非常に高く、リアルタイム処理には不向きであることが課題
◾️U-Net
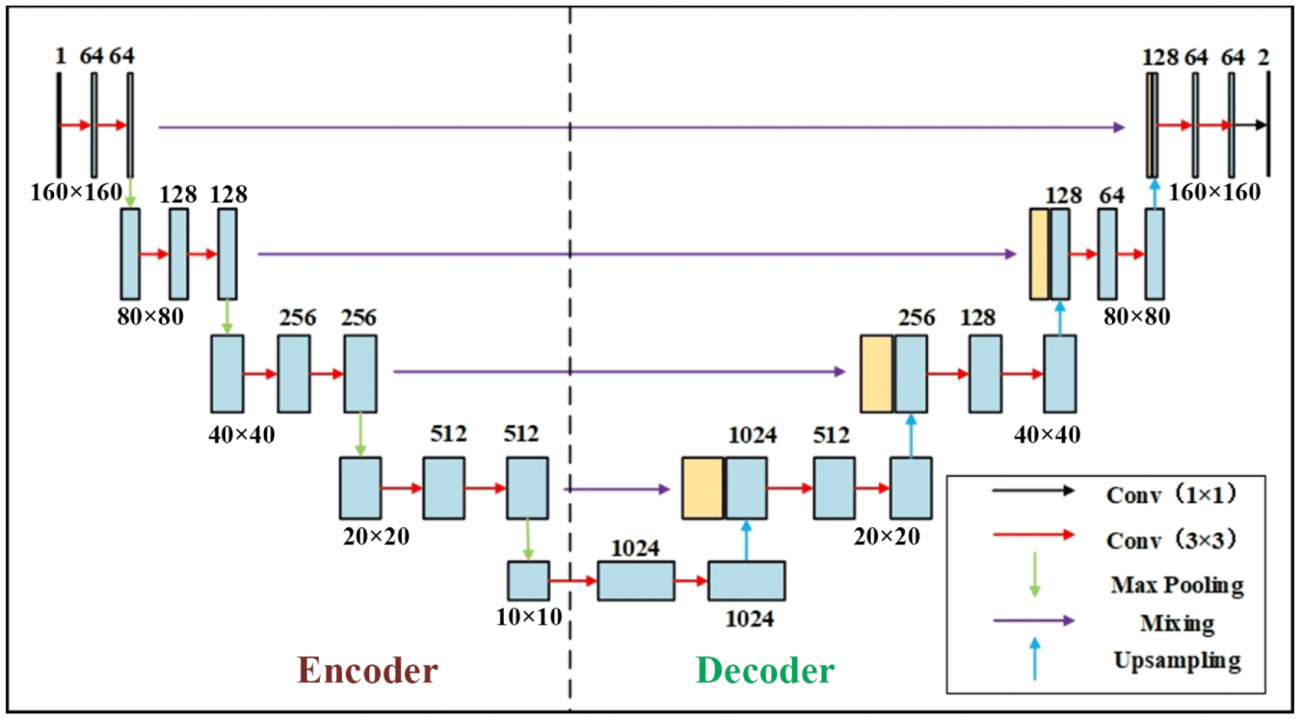
①概要
・主に医療画像のセグメンテーションに使用される深層学習モデルで、構造はエンコーダ(縮小パス)とデコーダ(拡大パス)の2部分から成り立っている
・まず、エンコーダーが画像から重要な特徴を抽出し、次元を減らすことでデータの圧縮を行う
・上記過程で、畳み込み層とプーリング層が使用され、画像の解像度が徐々に下がる
・最後に、デコーダがエンコーダで抽出した特徴を元に、画像の詳細な情報を復元する
・アップサンプリング(拡大)を行いながら、特徴マップを再構築していく
②用途・性質
・U-Netの能力は、限られた量のトレーニングデータからも高い精度で複雑なセグメンテーションタスクを学習できることである
③利点と課題
・精度の高い画像セグメンテーションが可能で、少ないデータでも効果的に学習できることが利点
・複雑なモデル構造により、計算リソースを多く必要とすることが課題
◾️YOLO
①概要
・リアルタイムオブジェクト検出に特化したモデルで、画像全体を一度に処理して、オブジェクトの位置とカテゴリを高速に予測する
・まず、画像を複数のグリッドに分割し、各グリッドセルがオブジェクトの中心を含むかどうかを予測する
・次に、各グリッドセルについて、バウンディングボックスの座標とその確信度(オブジェクトが存在する確率とその正確さ)を予測する
・同時に、各バウンディングボックスのクラス(オブジェクトの種類)を予測する
②用途・性質
・ビデオストリームのリアルタイム分析、交通監視、スポーツ分析、公共の安全保障など、高速処理が要求される環境で広く利用されている
・YOLOは、画像を一度に全体として処理することで、非常に高速な検出速度を実現する
・全体の画像から直接バウンディングボックスとクラスラベルを予測するため、従来のステップバイステップのアプローチに比べて処理が速く、効率的である
③利点と課題
・非常に高速であり、リアルタイム処理に適していることが利点
・小さいオブジェクトの検出精度が低下することがあることが課題
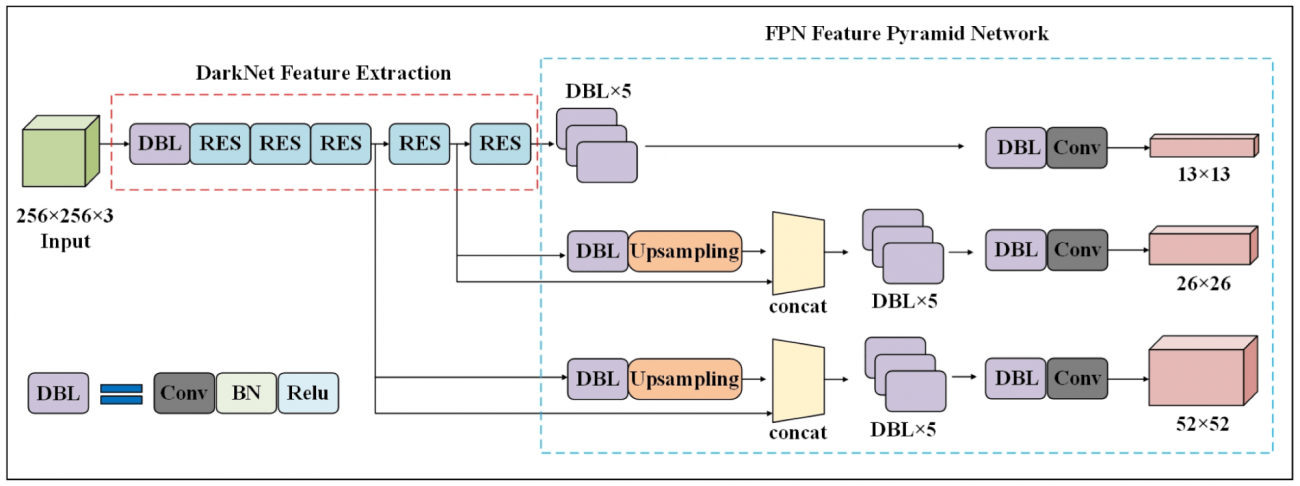
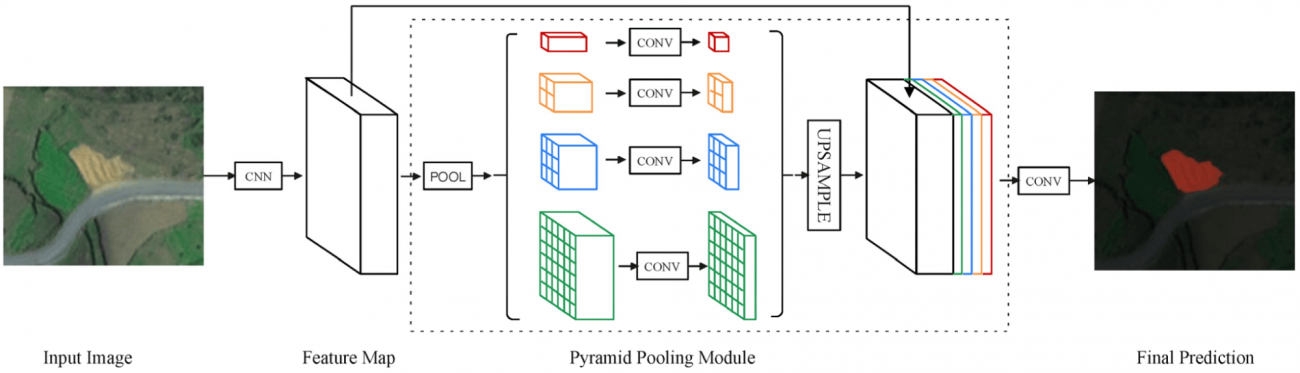
◾️PSPNet(Pyramid Scene Parsing Network)
①概要
・PSPNetは、多層の望遠鏡のように、異なるズームレベルで広範囲から詳細までを捉えることができる
・画像を様々なスケールで解析し、それぞれのスケールから得られる情報を統合して一つの豊かな特徴マップを生成する
②用途・性質
・ピラミッドプーリングモジュールを利用して、一つの画像を通じて異なる「焦点距離」での詳細を組み合わせることにより、より豊かな情報を得ることができる
③利点と課題
・異なるスケールで特徴を捉える能力により、画像の詳細とグローバルなコンテキストの両方を同時に理解できることが利点
・ピラミッドプーリングモジュールは多様なスケールの特徴を処理するため、計算資源を多く消費する必要があり、リソースに制限のある環境ではデプロイが困難であることが課題
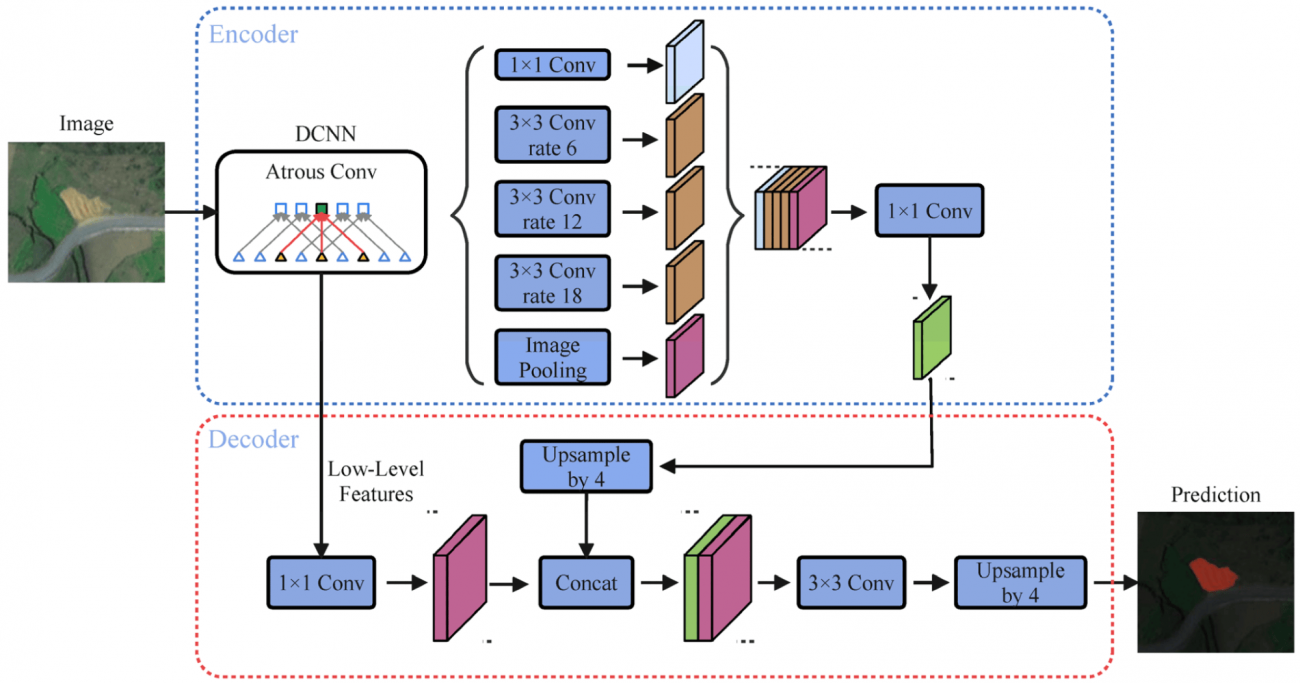
◾️DeepLabV3
①概要
・DeepLabV3+は、異なるスケールでの特徴を捉えるためにアトラス畳み込みと空間ピラミッドプーリングを使用する
・アトラス畳み込みでは、さまざまな「焦点距離」で画像を見ることで、近景から遠景まで異なるコンテキストの情報を捉える
・上記により、画像の各部分がどのように全体に関連しているかをより正確に解析し、特に複雑なシーンのセグメンテーションにおいて、細かい詳細まで識別する能力を持つ
・異なる距離のレンズを使い分けるカメラマンのように、画像のさまざまな「距離」から詳細を捉える
②用途・性質
・アトラス畳み込みは「穴あき畳み込み」とも呼ばれ、通常の畳み込みと異なり、カーネル(フィルター)の各要素の間に「穴」(スペース)を設けることで、カーネルがカバーする範囲が広がり、より広い範囲の情報を一度に収集できるようになる
③利点と課題
・複雑なシーンにおいても、細かいオブジェクトの識別から広範囲な背景認識まで、高いレベルのセグメンテーションを実現できることが利点
・高度なピラミッドプーリングの実装には技術的な複雑さが伴うため、最適化と効率化が課題
◾️トランスフォーマー
・トランスフォーマーは自己注意機構を使い、入力されたデータの全ての部分が互いに関連を持つようにする
・上記により、遠く離れたデータポイント間の関係も捉えることができ、文脈全体を通じて情報が流れる
・画像で言えば、画像の一部を見ただけで全体の状況を把握することができるような能力を持っている
#地すべり #RNN #CNN #Mask-R-CNN #R-CNN #U-Net #YOLO #PSPNet #DeepLabV3
Transformer-based semantic segmentation for large-scale building footprint extraction from very-high resolution satellite images
【どういう論文?】
・本論文は、高解像度の衛星データから大規模な建物のフットプリントを抽出するために、トランスフォーマーベースのセマンティックセグメンテーション技術、特にSwin TransformerをバックボーンとするMask2Formerというアーキテクチャを利用する手法を提案する
【技術や方法のポイントはどこ?】
①研究地域
・アラブ首長国連邦(UAE)のシャルジャ市北部
・322平方キロメートルの広さを持ち、さまざまな種類の都市景観(住宅、公共、産業、商業建築)が含まれている
②利用データ
・2017年6月7日に取得されたWorldView-3(WV-3)衛星画像を使用する
(マルチスペクトルチャネル:空間解像度は1.28メートル、パンクロマチックバンド:空間解像度は0.31メートル)
③データ前処理
・WV-3画像タイルは、まずFLAASH(Fast Line-of-sight Atmospheric Analysis of Spectral Hypercubes)大気補正アルゴリズムを用いて処理する
・上記により、大気の影響を除去し、データの品質を向上させる
・その後、Gram-Schmidtパンシャープニング技術を用いて空間解像度を0.31メートルに向上させて、パンクロマチックバンドの高解像度とマルチスペクトルチャネルのスペクトル情報の組み合わせを可能にし、より詳細な画像データが得られるようにする
④データセット
・訓練データ:11,416ペアの画像とマスク
・検証データ:650ペアの画像とマスク
・テストデータ:662ペアの画像とマスク
⑤Mask2Former
・画像セグメンテーションにおける汎用的なアーキテクチャで、バックボーンネットワーク
、ピクセルデコーダー、トランスフォーマーデコーダーの3つから構成されている
・一部のトランスフォーマーモデルは、全てのピクセル間の相互作用を考慮するため、計算量が大きくなる傾向がある中で、 Mask2Formerは、シフトウィンドウ技術を使用するSwin Transformerをバックボーンにすることで、計算量を抑えつつ高い性能を維持する
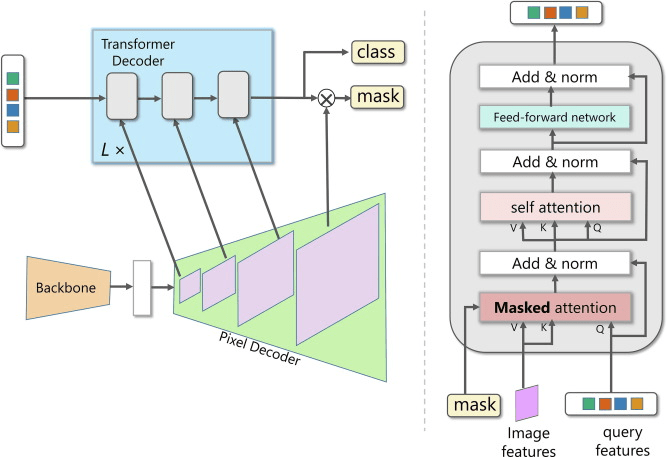
⑥Swin Transformer
・シフトウィンドウ技術:自己注意計算を非重複のローカルウィンドウに限定しつつ、各ウィンドウ内で計算した特徴を隣のウィンドウとも関連づけて調整し、全体として連続性があるようにする
・階層的な特徴表現:パッチパーティション、パッチマージング、線形埋め込み、Swin Transformerブロックの4つのステージを持ち、各ステージでトークンの数を減らしながら特徴表現を階層的に生成する
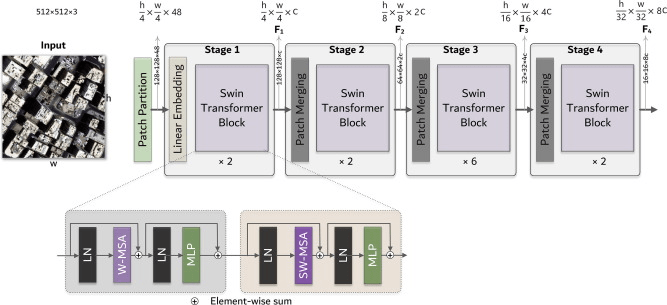
【議論の内容・結果は?】
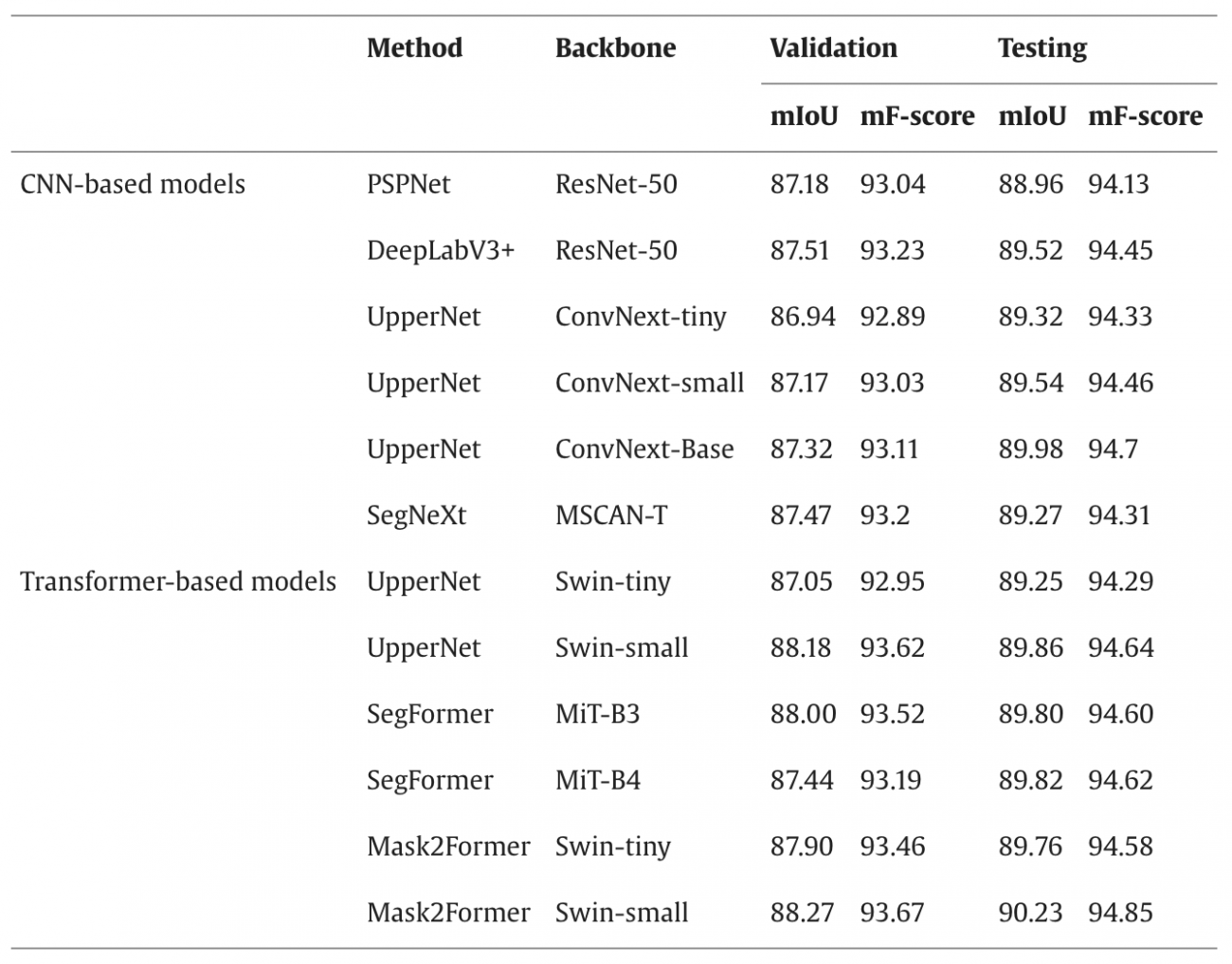
①元データ検証
・テストデータセットでのmIoUは88.96%から90.23%、Fスコアは94.13%から94.85%の範囲であり、トランスフォーマーモデルはCNNモデルよりも優れた性能を示した
・特に、Swin-smallバックボーンを持つMask2Formerモデルは、mIoU 90.23%、Fスコア 94.85%を達成し、他のモデルと比較して優れた性能を示した


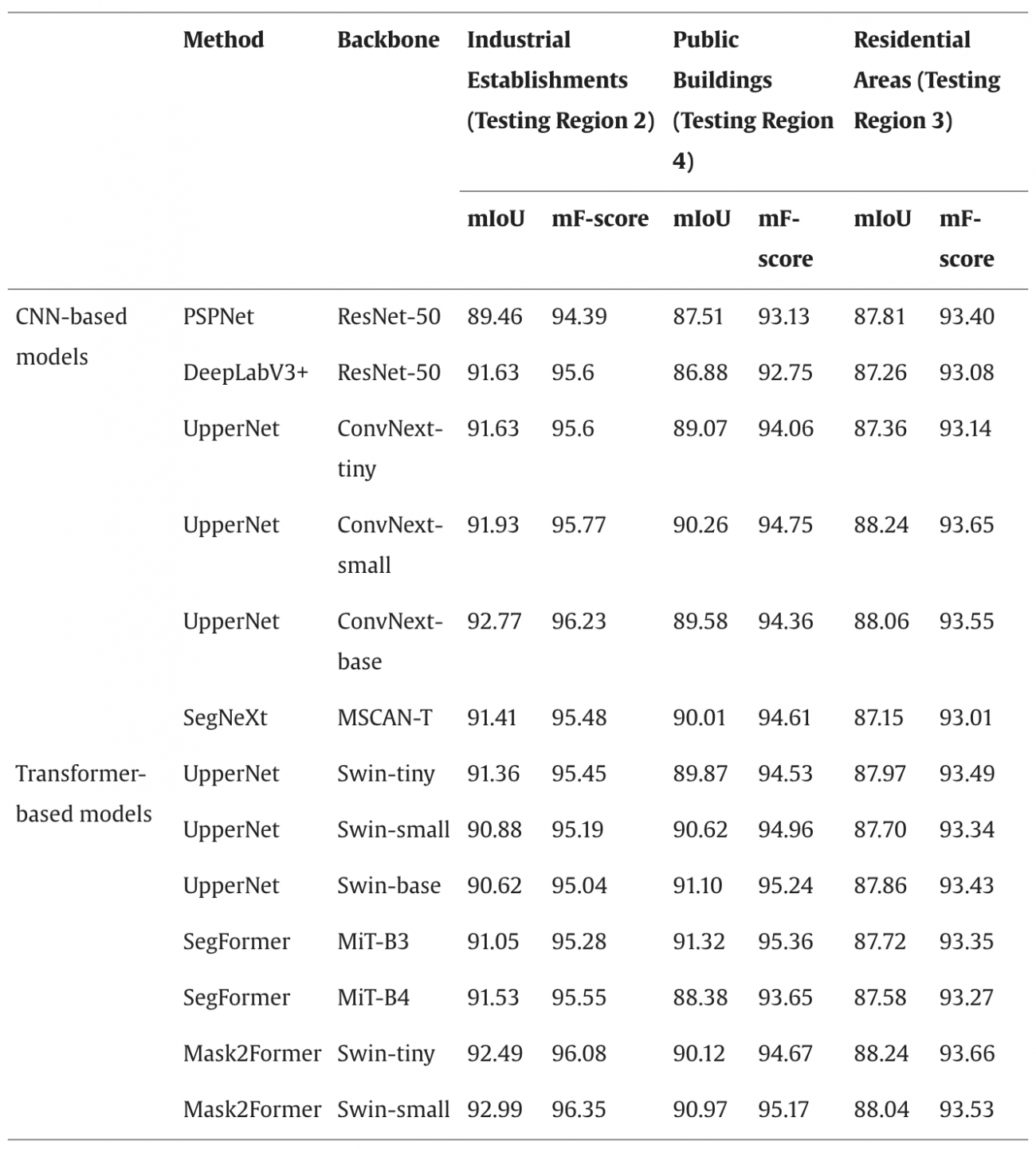
②汎化能力検証
・次に、モデルの一般化能力を評価するため、3つの未確認のテストデータセットで建物フットプリントを抽出した
・本データセットは、合計18平方キロメートルの領域をカバーしており、工業地域、政府施設、住宅地域などの複雑な景観を利用している
・工業地域では、Mask2Former(Swin-smallバックボーン)がほとんどのCNNベースモデルよりも1%から3.53%高いmIoUを達成した
・ただし、UpperNet(ConvNext-baseバックボーン)には0.22%の差で劣るが、こちらは計算コストが非常に高い
・住宅地域においては、CNNモデルとトランスフォーマーモデルの性能はほぼ同等であった
・公共建築地域はトランスフォーマーモデルがCNNモデルを1%から4.4%上回る性能を示した
#フットプリント #トランスフォーマーベース #セマンティックセグメンテーション #Swin Transformer #Mask2Former #WorldView-3 #パンシャープニング
Urban development pattern’s influence on extreme rainfall occurrences
【どういう論文?】
・本論文は、都市の開発パターンが極端な降雨の発生とその影響にどのように関連しているかを研究することを目的とする
【技術や方法のポイントはどこ?】
◾️都市パターンごとの降雨分布分析
①データセット
・都市データは、Global Artificial Impervious Areas (GAIA)という不透水エリア(道路や建物などの人工構造物)を30メートルの解像度で提供されているデータセット(2003年から2018年期間)を使用する
・降雨データは、Integrated Multi-Satellite Retrievals of Global Precipitation Measurement (IMERG)プロダクトを使用し、0.1度(約10キロメートル)の空間解像度および日次の時間解像度で取得する
②分析方法
・各都市の2001-2005年と2016-2020年の期間での降雨データを比較し、極端な降雨頻度(99パーセンタイル日降雨量)の変化を評価する
・①の短期でのシミュレーション結果と実際の長期観測データを比較し、異なる都市開発パターンの降雨影響を検証する
◾️降雨影響シュミレーション
・異なる都市開発パターンが降雨パターンに与える影響を数値的に解析し、シミュレーションによってその影響を明確にする
・そこで、Real Atmosphere, Ideal Land surface(RAIL)シミュレーションという手法を使用する
・具体的には、異なる都市開発シナリオ(Circular、Ribbon、Satellite、Edge、Scatter)を設定し、各シナリオにおける都市の空間配置を模倣する
・初期条件と境界条件をNCEP Final Operational Global Analysisプロダクトから取得し、 同地域の2012年8月20日から21日の降雨イベントをシミュレーションする
【議論の内容・結果は?】
◾️都市パターンごとの降雨分布分析
①前提(都市分類方法)
・都市開発パターンを総都市面積とランドスケープ形状指数(LSI)の二つの指標を用いて都市の空間配置(密集状況)を評価する
・上記評価を元に、K-meansクラスタリングを用いて都市を3つのグループに分類する
・分類軸は、都市比率と都市化率を用いる
・都市比率は、特定の領域において都市エリアが占める割合を示す
・都市化率は、一定期間における都市エリアの相対的な増加率を示す
②前提(都市分類結果)
[グループI]
・低い都市比率(平均4%)と低い都市化率(平均27%)
・低・中所得国の地域、例えば南米の南東部、アフリカの西部、インドの北東部が該当する
[グループII]
・高い都市比率(平均43%)と低い都市化率(平均6.8%)
・アメリカの東部、西ヨーロッパ、南アジア、中国の北部など、高所得国や人口密集地域に集中している
[グループIII]
・低い都市比率(平均4%)と高い都市化率(平均27%)
・主に低所得から中所得の国に位置しており、その多くは南アメリカの南東部、西アフリカ、北東インドに集中している
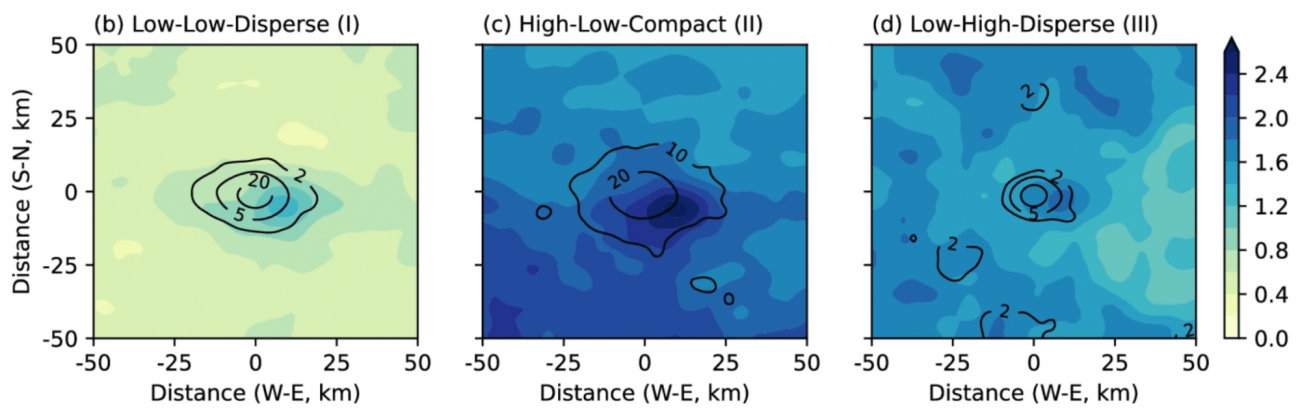
③都市パターンごとの平均の極端降雨頻度と分布
[グループI]
・極端な降雨頻度の変化率は比較的低い
[グループII]
・極端な降雨頻度の変化率が高く、都市中心部で特に顕著となっている
[グループIII]
・極端な降雨頻度の変化率が高く、複数の「ホットスポット」が存在している
◾️Real Atmosphere, Ideal Land surface(RAIL)シミュレーション結果
①降雨蓄積に関して
・降雨蓄積(特定の地域に一定期間に降った雨の総量)の減少に関しては、都市の存在は都市ドメイン(研究対象地域)全体の降雨蓄積を減少させることがわかった
・減少の程度はシナリオごとに異なり、約0.8 mmから2.6 mm(全都市ドメインの平均降雨量は約25 mm)となっている
・なお、Circularシナリオでは、降雨量の減少が統計的に有意(−2.3 ± 0.65 mm, P < 0.01)である
・Ribbonシナリオにおいては、降雨量の減少が統計的に有意(−2.6 ± 0.69 mm, P < 0.01)である
・他のシナリオは降雨量の変化は統計的に有意でなかった
②極端な降雨頻度に関して
・一方で、全ての都市シナリオで、極端な降雨の頻度(1時間あたりの降雨量が10 mm/hを超える回数)が増加した
・特にコンパクトな都市シナリオ(Circular、Ribbon)では、都市と農村の境界付近で顕著な「ホットスポット」が形成され、極端な降雨頻度の増加が約2時間見られた
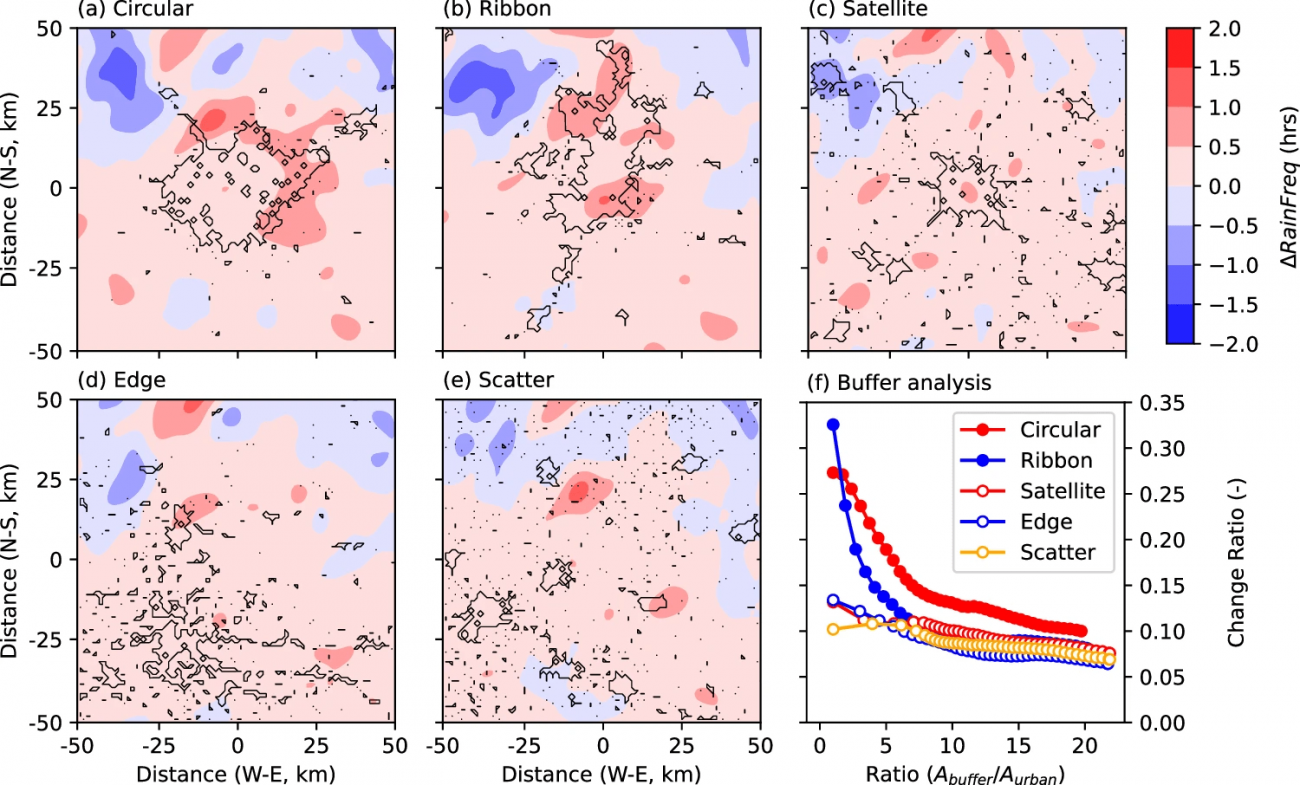
◾️雨量異常における都市特有のサイン
①温度異常と都市開発パターン
・コンパクトな都市シナリオ(Circular、Ribbon)では、都市全域の地表温度の異常値は約0.29℃、対して分散型シティ(Satellite、Edge、Scatter)は約0.32℃であった
・分散型シティでは、都市の熱が近隣の農村地域に移動しやすくなるため、地表温度の異常が大きくなる
②都市-農村熱対比(Urban Heat Island, UHI)
・コンパクトシティ(Circular、Ribbon)のUHI強度はそれぞれ平均1.4℃および1.2℃
・分散型シティ(Satellite、Edge、Scatter)のUHI強度はそれぞれ平均0.8℃、0.9℃、0.7℃
・原因は、コンパクトシティが農地に比べて空気抵抗の差が大きく、熱の対比が顕著になるためである
③低層湿度収束(Moist Convergence)
・UHI強度の上昇は、都市に向かって湿度の収束を促進する
・上記は、850 hPaの高度での鉛直速度(上昇気流)として観測され、コンパクトシティではこの収束が特に強くなる
・本収束は、極端な降雨の頻度と強い相関関係を示す
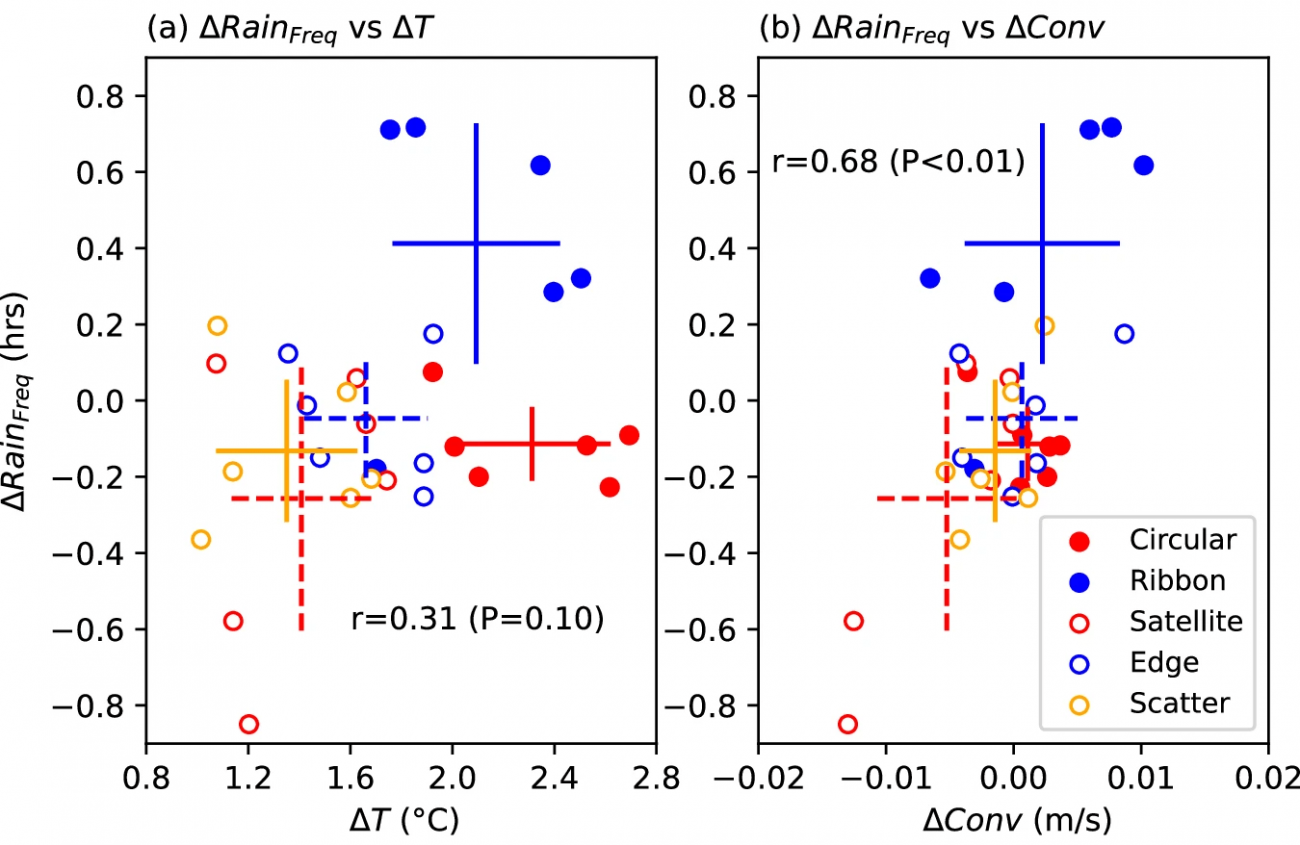
#降雨 #GAIA #不透水エリア #IMERG #RAIL #都市開発シナリオ #UHI
以上、2024年5月に公開された論文をピックアップして紹介しました。
皆様の業務や趣味を考えた時に、ピンとくる衛星データ利活用に関する話題はありましたか?
最後に、#MonthlySatDataNewsのタグをつけてTwitterに投稿された全ての論文をご紹介します。
The Impacts of Drought Changes on Alpine Vegetation during the Growing Season over the Tibetan Plateau in 1982–2018
Future groundwater potentialmapping using machine learningalgorithms and climate changescenarios in Bangladesh
来月以降も「#MonthlySatDataNews」を続けていきますので、お楽しみに!
