【2025年5月】衛星データ利活用に関する論文とニュースをピックアップ!
2025年5月に公開された衛星データの利活用に関する論文の中でも宙畑編集部が気になったものをピックアップしました。
・Beluga Whale Detection from Satellite Imagery with Point Labels
(超高解像度の衛星画像を用いた、シロイルカ(beluga whale)とタテゴトアザラシ(harp seal)を自動検出する手法)・Generative AI for Urban Planning: Synthesizing Satellite Imagery via Diffusion Models
(生成AIによる都市開発案の画像生成手法)・Research and application of deep learning object detection methods for forest fire smoke recognition
(最新の深層学習の物体検出アルゴリズムである「YOLOv11x」を用いた、森林火災における「煙」と「炎」の検知モデル)・Beyond Pretty Pictures: Combined Single- and Multi-Image Super-resolution for Sentinel-2 Images
(Sentinel-2衛星画像(10m解像度)を高解像度(2.5m)に変換する「SEN4X」という新しい超解像技術)
宙畑の連載「#MonthlySatDataNews」では、前月に公開された衛星データの利活用に関する論文やニュースをピックアップして紹介します。
実は、本記事を制作するために、これは!と思った論文やニュースをTwitter上で「#MonthlySatDataNews」「#衛星論文」をつけて備忘録として宙畑編集部メンバーが投稿していました。宙畑読者のみなさまも是非ご参加いただけますと幸いです。
2025年5月の「#MonthlySatDataNews」「#衛星論文」を投稿いただいたのはこの方でした!
Research and application of deep learning object detection methods for forest fire smoke recognition #衛星論文
煙と炎の検出モデル
煙の方が検出精度よいらしい https://t.co/UnpUjSYiK0— たなこう (@octobersky_031) May 11, 2025
Generative AI for Urban Planning: Synthesizing Satellite Imagery via Diffusion Models #衛星論文https://t.co/owSWLZXc7I
都市の構造図から、リアルな衛星画像を生成する試み— たなこう (@octobersky_031) May 18, 2025
それではさっそく2025年5月の論文を紹介します。
Beluga Whale Detection from Satellite Imagery with Point Labels
【どういう論文?】
本論文は、超高解像度の衛星画像を用いてシロイルカ(beluga whale)とタテゴトアザラシ(harp seal)を自動検出する方法を提案する
【技術や方法のポイントはどこ?】
◾️先行研究の課題
・高品質なバウンディングボックスアノテーションの手動作成に非常に手間がかかる
・加えて、シロイルカは群れで泳ぐことが多く個体同士が非常に近接しているのにもかかわらず、従来の点アノテーション(クジラの位置を示す点)は一律の大きさの円や四角を描いてバウンディングボックスを作成していたため、一定の枠の中に複数のクジラが入ってしまい、結果として、個体数のカウントに誤差が生じてモデル学習や評価に悪影響を及ぼしていた
・また、衛星画像では、クジラがはっきり見える場合(「確実なクジラ」)と、波や水の濁り輪郭がぼやけて見える場合(「不確実なクジラ」)があるが、アノテーションの際には確実なクジラのみをアノテーション対象とするため、実用性の観点で問題があった
◾️本研究のアプローチ
・10億規模のデータセットで事前訓練された基盤モデルであるSegment Anything Model(SAM)を活用し、点アノテーションから自動バウンディングボックス生成の手法に変更
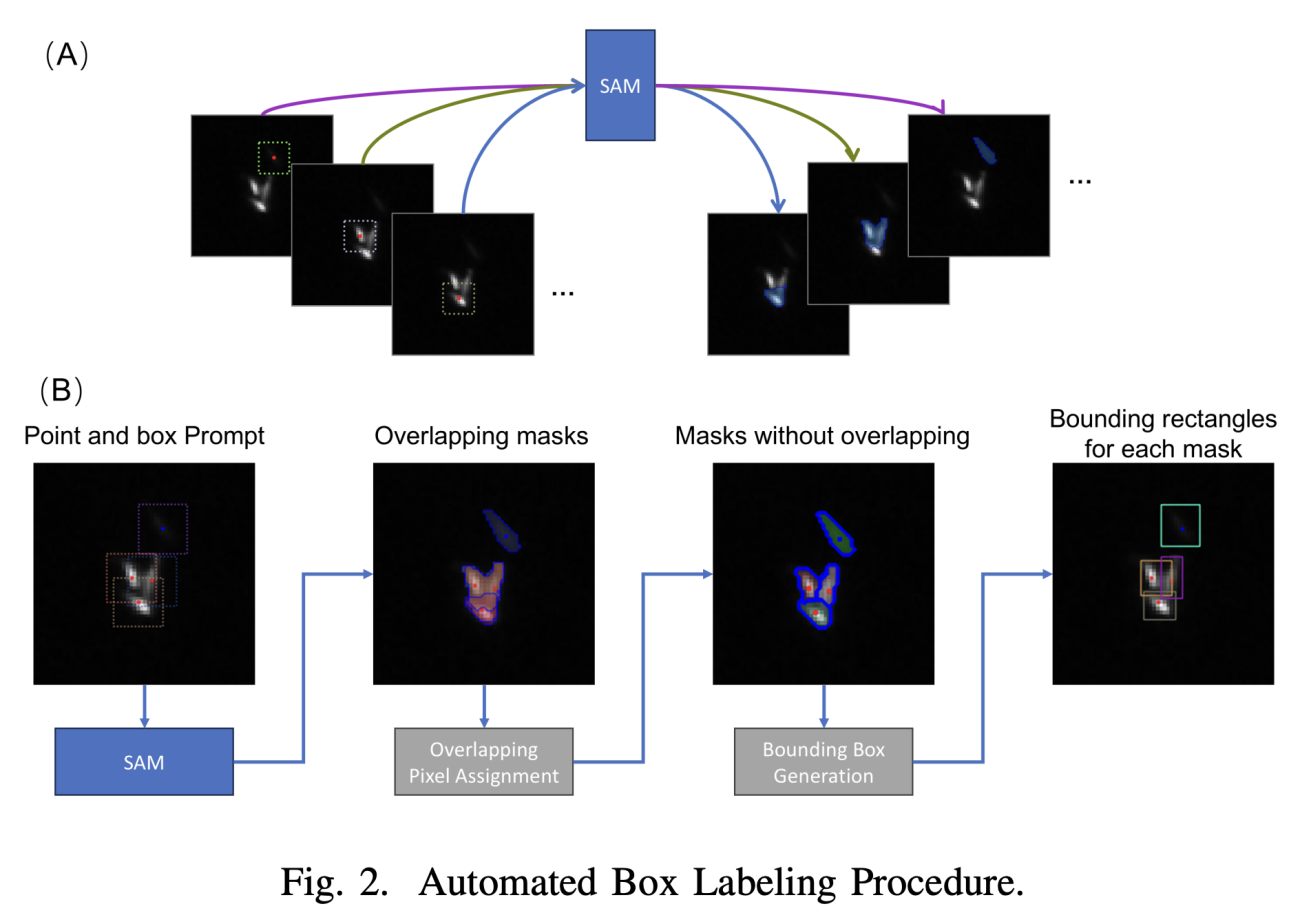
https://arxiv.org/abs/2505.12066
・SAMが生成したセグメンテーションマスクが重複する場合において、重複ピクセル割り当てアルゴリズムを適用して個体ごとに分離する
・(SAMが生成したバウンディングボックスで訓練した)YOLOv8を用いた、「確実なクジラ」「不確実なクジラ」「タテゴトアザラシ」の3クラス検出
◾️データセット
・撮影地域:カナダ北部のClearwater FiordとChurchill River
・撮影期間:2021-2022年の夏季
・使用衛星:WorldView-3(解像度0.3m)、WorldView-2(解像度0.46m)
https://arxiv.org/abs/2505.12066
【議論の内容・結果は?】
◾️SAMの自動アノテーション性能
①定量面
・確実なクジラ:19%が修正必要であった
・不確実なクジラ:21%が修正必要であった
・タテゴトアザラシ:4%が修正必要であった
②示唆
・アザラシは、小さくて形がはっきりしているので、AIにとって「簡単な問題」であり、不確実なクジラは、波や水の濁りで輪郭がぼやけているので、AIにとって「難しい問題」であると考えられる
◾️YOLO-SAMの検出性能
・全体のF1スコア:72.2%
・タテゴトアザラシのF1スコア:70.3%
・「確実なクジラ」の再現率:58.2%(YOLO-Bufferの47.2%を大幅上回る)
・タテゴトアザラシの再現率:73.1%(YOLO-Bufferの71.6%を上回る)
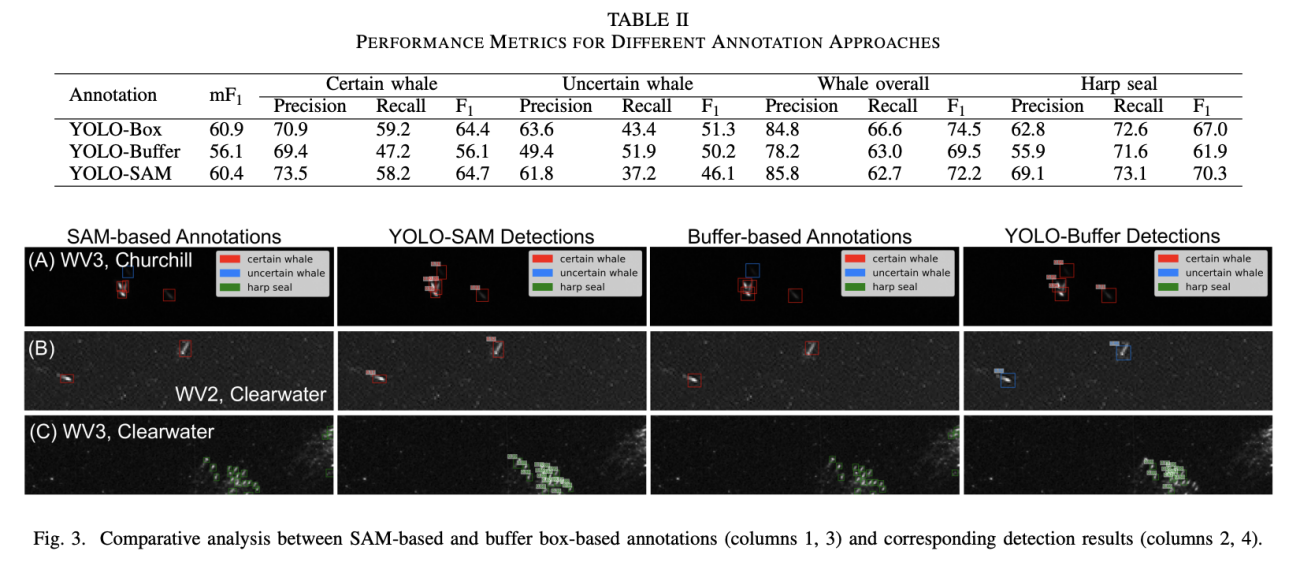
https://arxiv.org/abs/2505.12066
※YOLO-Buffer(従来手法):固定サイズの枠を使用
※YOLO-Box:人間が手作業で完璧に修正したデータを使用
※YOLO-SAM:AIが自動で作ったデータを使用
#シロイルカ #belugawhale #タテゴトアザラシ #harpseals #SegmentAnythingModel #SAM #YOLOv8 #物体検出 #自動アノテーション
Generative AI for Urban Planning: Synthesizing Satellite Imagery via Diffusion Models
【どういう論文?】
・本論文は、新しい都市開発案を視覚化するために建築家などが何週間もかけて手作業で図面や3Dモデルを作成していた中で、生成AIを用いてそのプロセスを数分に短縮することを実現するための手法を提案する
【技術や方法のポイントはどこ?】
◾️先行研究の課題
①現実の都市計画適用への限界
・既存インフラ(道路、水域、鉄道)の物理的制約を考慮しない非現実的な計画
・建築家などのの専門的記述や要求仕様を理解できない
・特定地域でのみ動作し、他都市への適用が困難
②データ調達の難しさ
・都市計画データのラベリングには高度な専門知識が必要
・各都市固有の法規制・文化的背景による汎用性の欠如
・都市は常に変化するため、データセットの継続更新が必要
◾️本研究のアプローチ
・GANから拡散モデルへの移行
・衛星画像とOpenStreetMapの情報を元にした自動空間マッチング(1枚あたり数秒、ほぼゼロコスト)
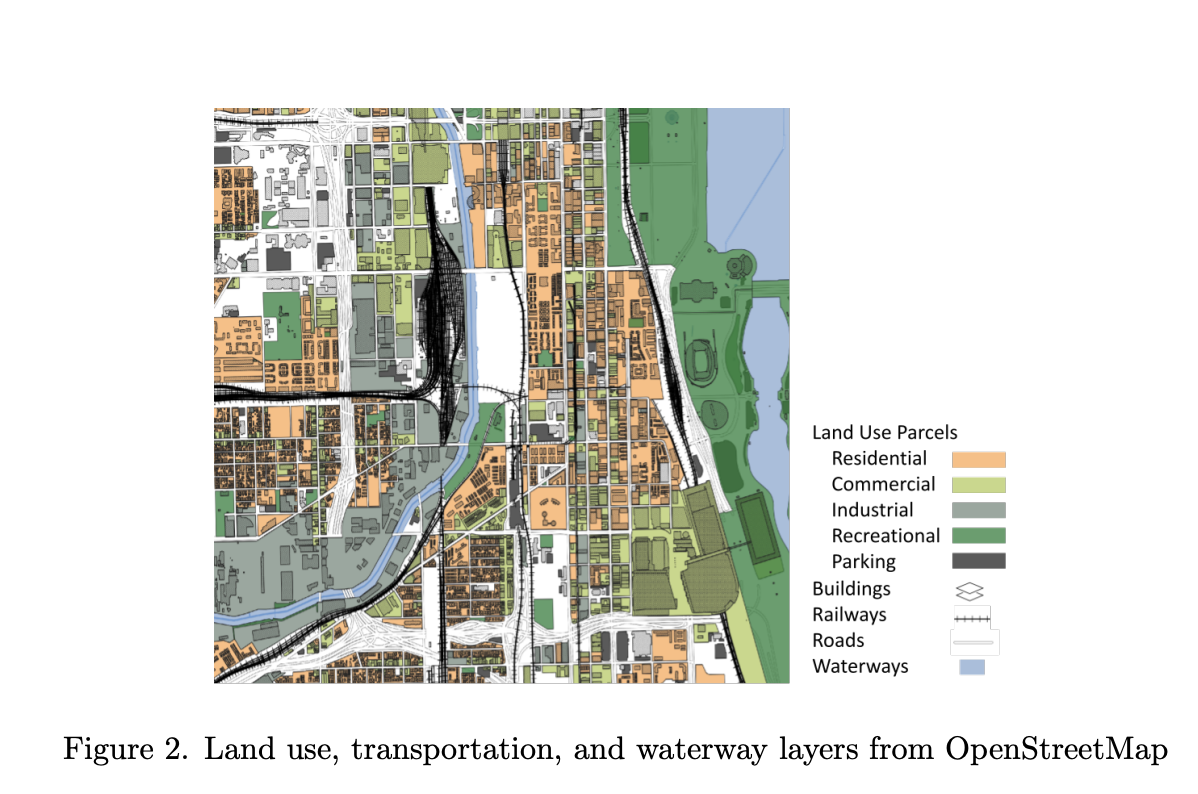
https://www.arxiv.org/abs/2505.08833
・ControlNetフレームワークを用いた、自然言語による詳細仕様(土地利用比率、建物タイプ、密度等)や、ピクセルレベルでの空間制約(道路、水域、既存建物の正確な位置)の制御
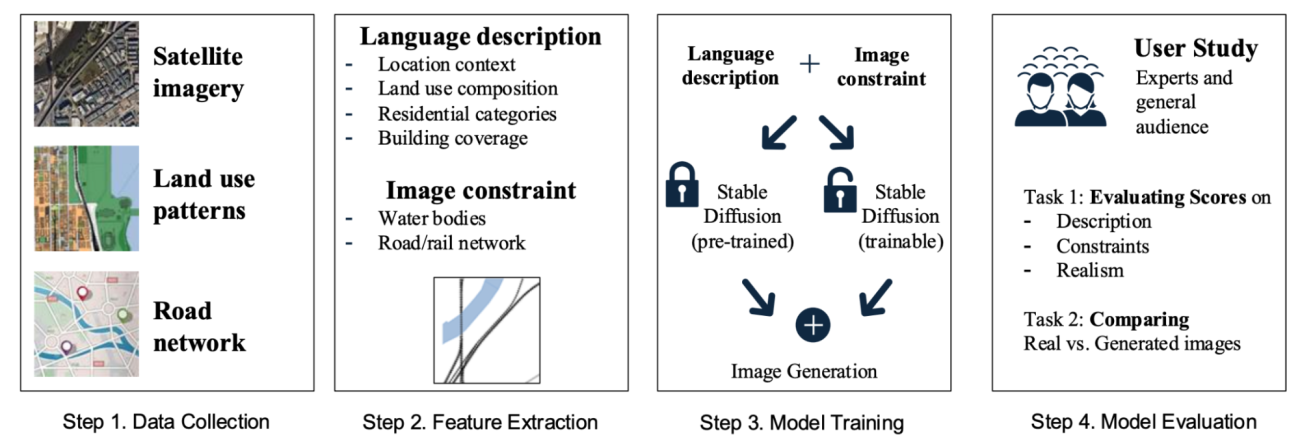

https://www.arxiv.org/abs/2505.08833
【議論の内容・結果は?】
◾️土地利用制御の精密性
・シカゴの実際の土地利用(住宅10%、公園50%、工業30%)を基準として、住宅比率を0%から40%へ段階的増加、公園比率を60%から20%へ段階的減少させる精密な制御実験(画像生成)を実施
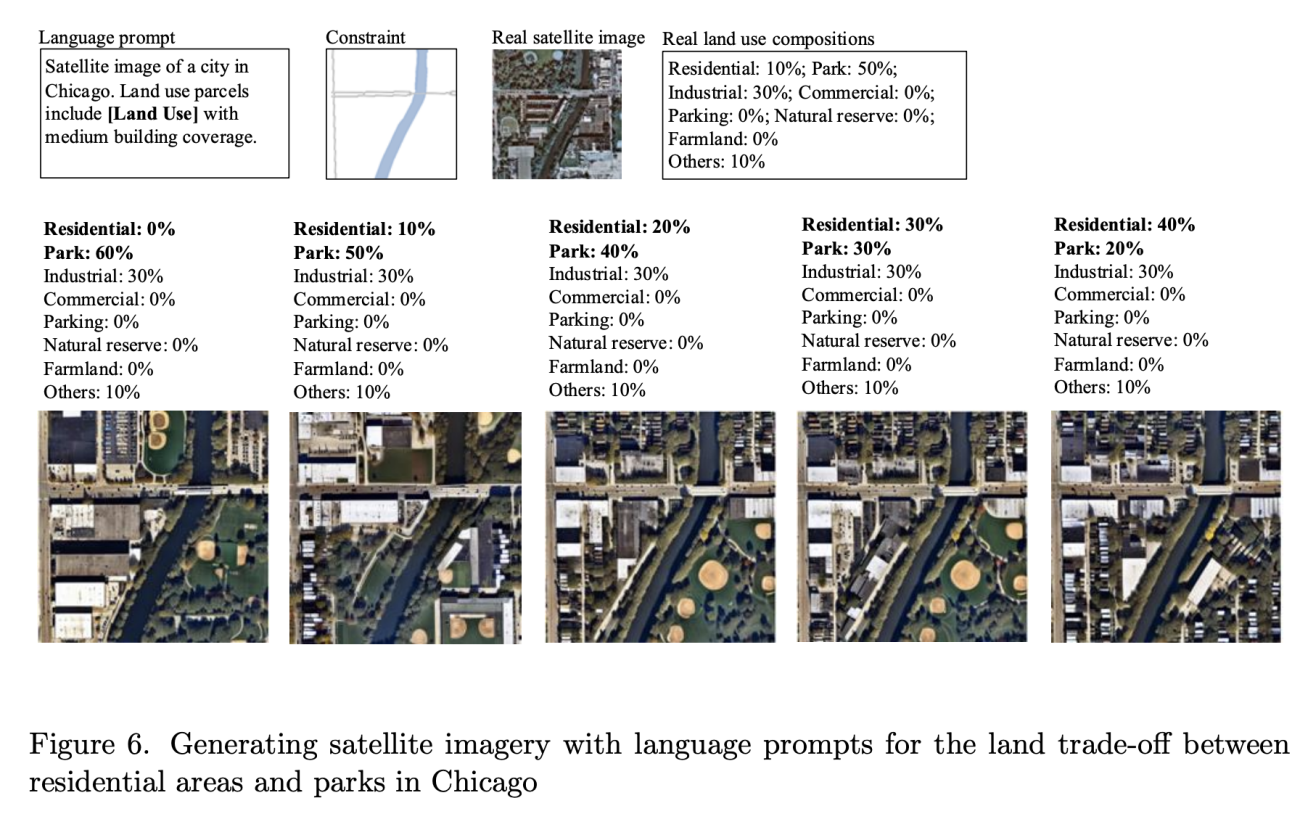
https://www.arxiv.org/abs/2505.08833
◾️都市間学習による各都市の(視覚的・都市設計的な)特徴抽出
・完全に同一の制約条件と土地利用の記述(プロンプト)の下で。3都市の生成結果を比較した結果、各都市固有の(視覚的・都市設計的な)特徴DNA特徴を可視化することができた
・(視覚的・都市設計的な)特徴の一例として、シカゴでは格子型の町が自然に引き継がれており、ロサンゼルスでは他都市よりも明らかに明らかに道路幅が広く車社会への適用を示した
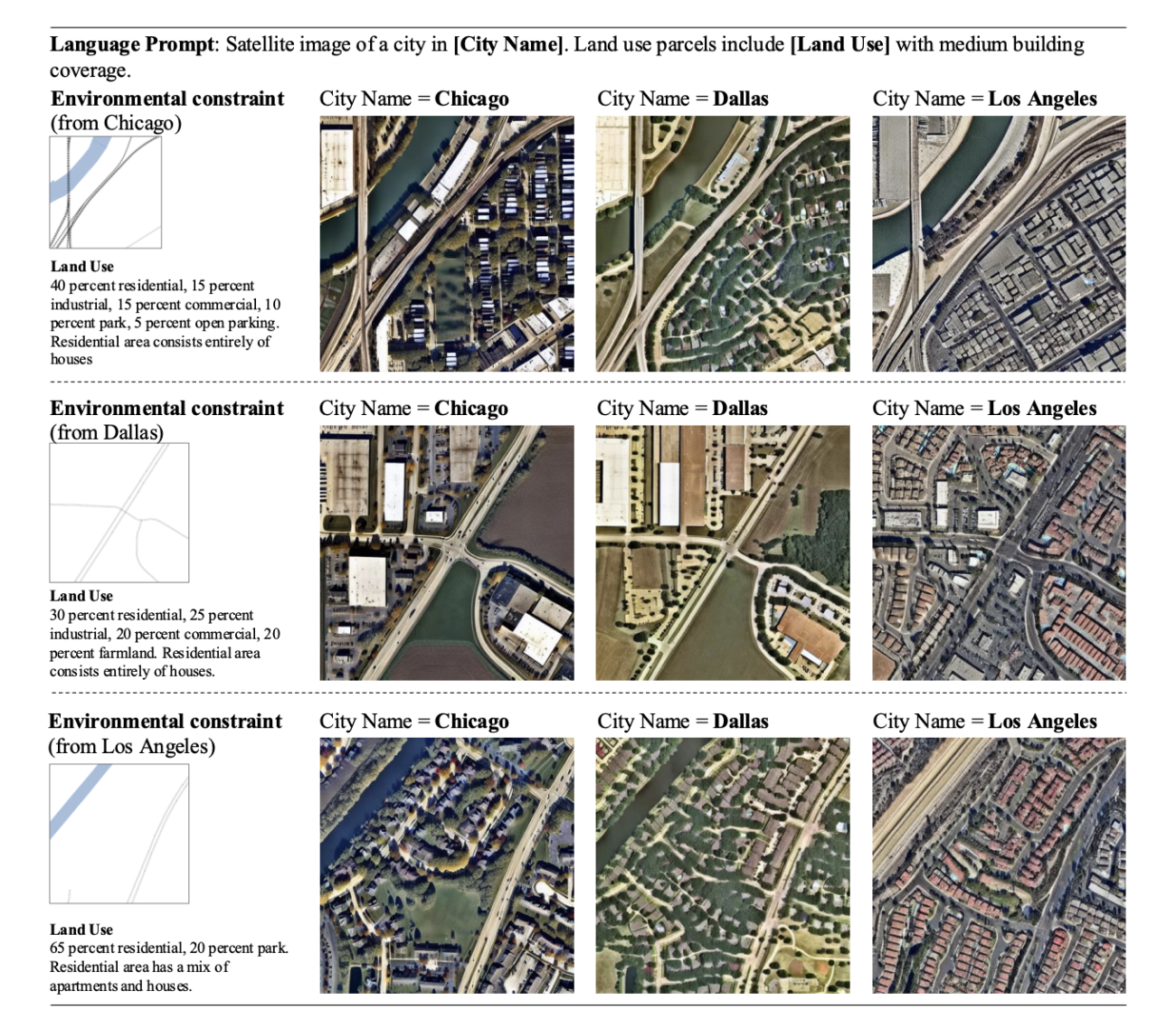
https://www.arxiv.org/abs/2505.08833
◾️プロンプトの複雑性
・詳細なプロンプトを用いると、性能が低下する(ノイズが増える)ことがわかった
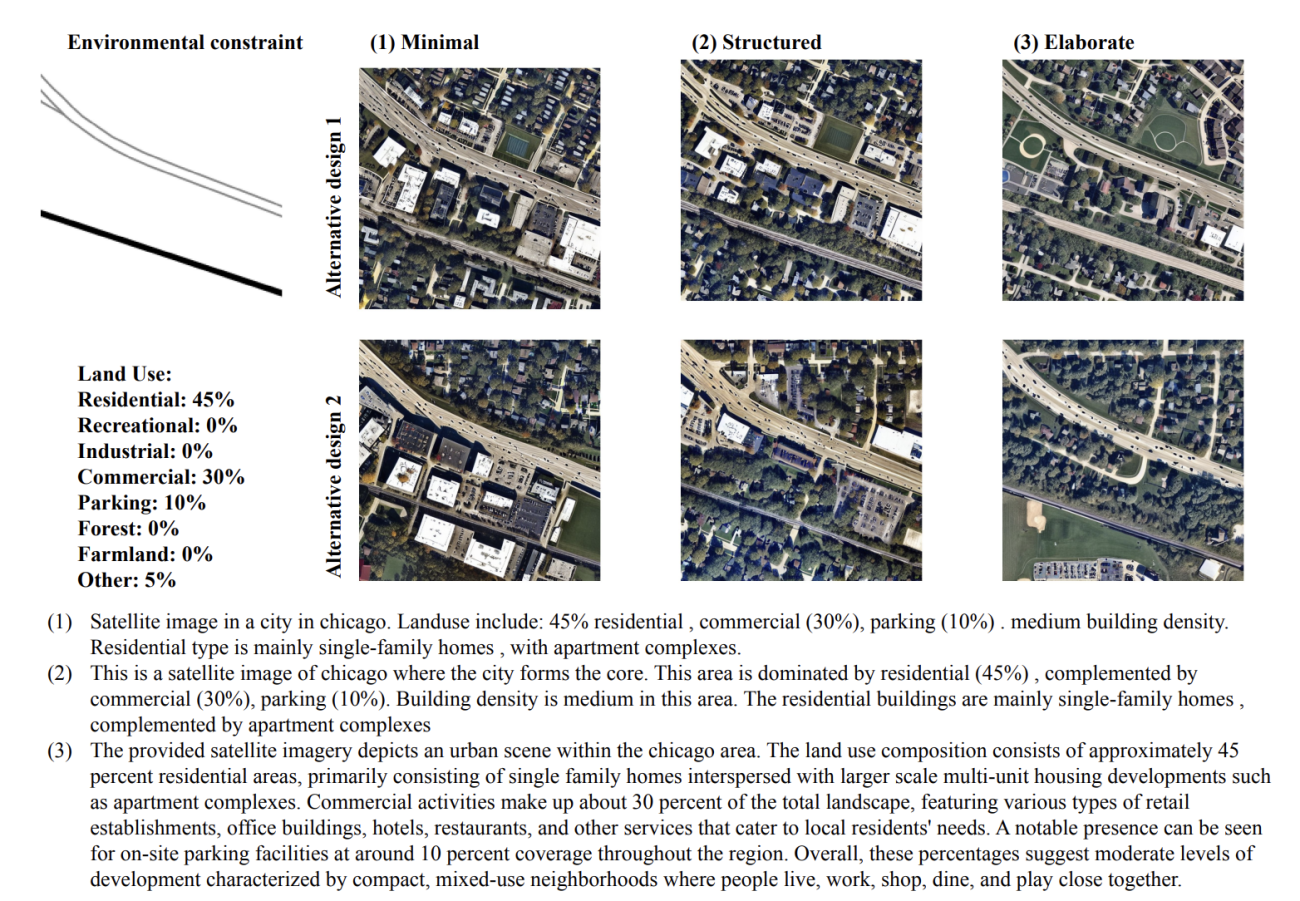
https://www.arxiv.org/abs/2505.08833
◾️環境制約を用いた画像生成
・実際の都市計画で遭遇する主要な制約条件を用いて画像を生成した
※a・・・水域制約
※b・・・道路制約
※c・・・鉄道制約
※d・・・土地利用制約(制御領域内での工業建物の一貫保持)

https://www.arxiv.org/abs/2505.08833
#ControlNet #DiffusionModels #GenerativeAI #都市計画 #空間計画 #生成AI
Research and application of deep learning object detection methods for forest fire smoke recognition
【どういう論文?】
本論文は、最新の深層学習物体検出アルゴリズムである「YOLOv11x」を用いて、森林火災の早期発見に不可欠な「煙」と「炎」を画像から検知するモデルを提案する
【技術や方法のポイントはどこ?】
◾️先行研究の課題
・セマンティックセグメンテーションでは、ピクセル単位で火災領域を特定できるものの、計算が複雑で時間がかかり、リアルタイムの警報には不向きな場合があった
・第一段階(候補領域の提案)と第二段階(候補領域の分類)で構成される物体検出(R-CNN系)手法は、精度は高いものの、処理速度が遅く、刻一刻と状況が変わる火災検知には適していなかった
◾️本研究のアプローチ
・「速さ」と「精度」を高いレベルで両立する一段階物体検出アルゴリズムである「YOLOv11」を採用する
※YOLOは、候補領域の特定とクラス分類を同時に行うため、非常に高速である
◾️データセット
①FFS (Forest Fire Smoke)
・森林火災の煙に特化したデータセット
・火災(14,300枚)、煙(14,300枚)、非火災(14,300枚)が均等に含まれる計42,900枚の画像で構成
②WD (Wildfire Dataset)
・様々な環境下の山火事を集めた計2,700枚のデータセット
・煙や炎だけでなく、「煙と紛らわしい雲」や「炎と紛らわしい太陽光」といった、誤検知を誘発しやすい画像も含まれており、モデルの識別能力をより厳しく評価するのに役立つ


https://doi.org/10.1038/s41598-025-98086-w
【議論の内容・結果は?】
◾️学習の成功有無(損失関数の評価)
・box_loss(物体の位置のズレ)、cls_loss(物体の種類(炎か煙か)のズレ)、dfl_loss (位置の精密さのズレ)に関して、それぞれ収束している
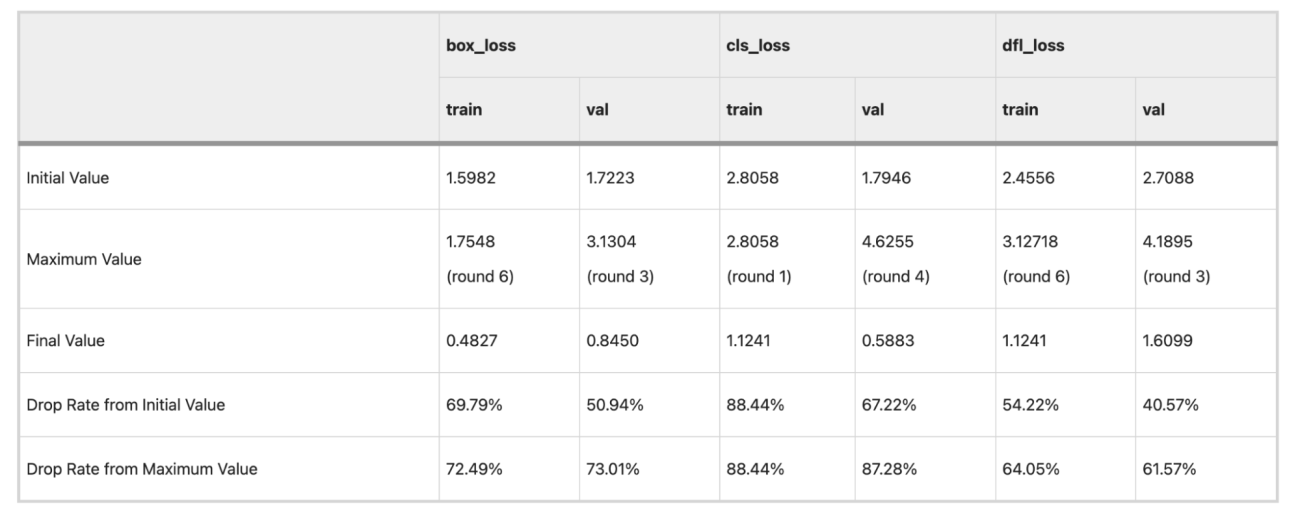
https://doi.org/10.1038/s41598-025-98086-w
◾️精度指標の評価
・適合率 (Precision) は、0.9487となっており、AIが「火事」と判断したうち、94.9%が実際に火事だったことを示した(誤報の少なさを表している)
・再現率 (Recall) は0.850となっており、実際に発生していた火事のうち、85.0%をAIが見つけ出せたことを示す(見逃しの少なさを表している)
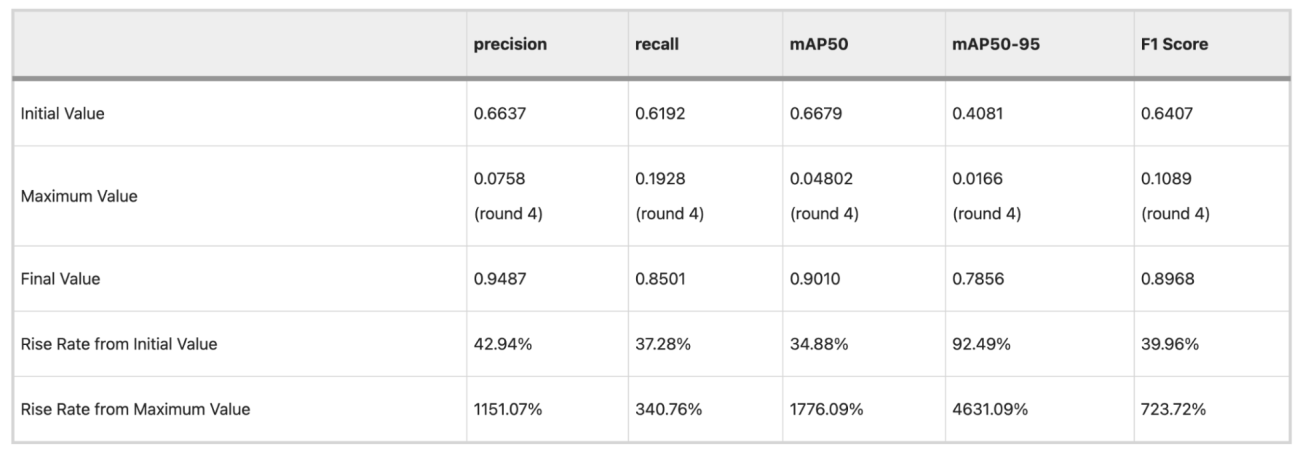
https://doi.org/10.1038/s41598-025-98086-w
◾️PR曲線の評価
・煙カテゴリのmAP@0.5は0.962に達した一方、炎カテゴリは0.841であった
・つまり、モデルは「炎」よりも「煙」の検出の方が得意であることがわかった
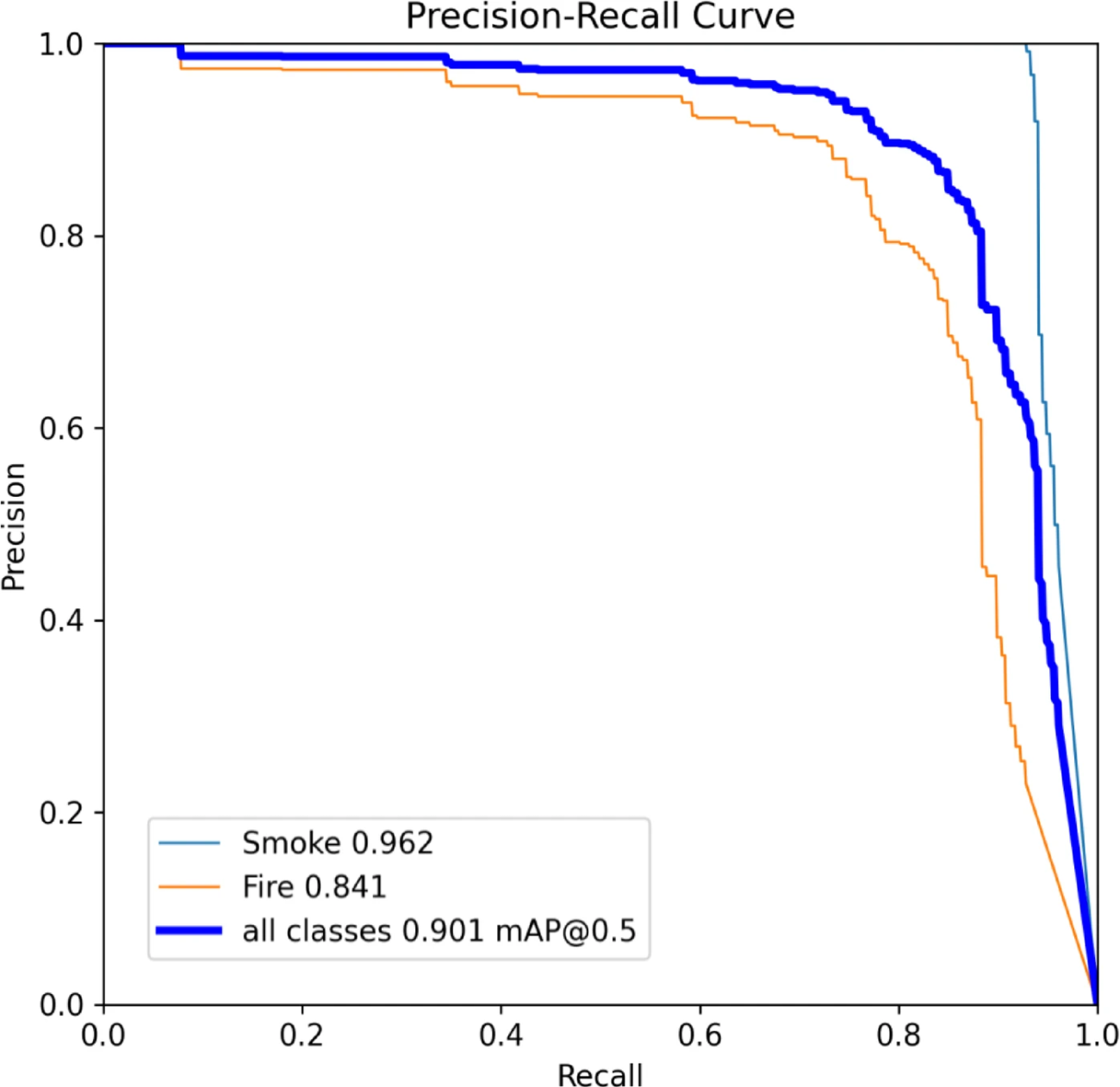
https://doi.org/10.1038/s41598-025-98086-w
#森林火災 #災害管理 #YOLOv11 #煙検知 #炎検知
Beyond Pretty Pictures: Combined Single- and Multi-Image Super-resolution for Sentinel-2 Images
【どういう論文?】
本論文は、Sentinel-2衛星画像(10m解像度)を高解像度(2.5m)に変換する「SEN4X」という新しい超解像技術を提案する
【技術や方法のポイントはどこ?】
◾️先行研究の課題
①SISR(単一画像超解像)
・大量の高解像度衛星画像(Pléiades Neoなど)からの学習済みパターンから細部を推測する手法だが、ハルシネーションが非常に起きやすい
②MISR(複数画像超解像)
・複数の観測データから情報を得つつ画像を生成するが、平均化効果によりぼやけた画像になるケースが多い
③評価指標
・PSNR、SSIMなどの従来指標は「見た目の品質」は測れるが、実際の分析タスクでの有用性とは相関が低い
※PSNR (Peak Signal-to-Noise Ratio)・・・2つの画像の画素ごとの差を測る古典的な指標
※SSIM (Structural Similarity Index Measure)・・・人間の視覚が画像の構造的な情報を重視することに着目した指標(PSNRより人間の感覚に近い)
◾️本研究のアプローチ
①概要
MISRの「複数データに基づく忠実性」とSISRの「学習済み事前分布に基づく精細な復元能力」を組み合わせたハイブリッドモデルを開発
②構成
・浅層特徴抽出 (Shallow Feature Extractor)・・・まず、複数の入力画像から基本的な特徴を抽出する
・再帰的融合 (Recursive Fusion)・・・次に、MISRコンポーネントを通して、複数の画像の特徴量をペアで次々と融合させていき、最終的に1つのリッチな特徴表現にまとめ上げ、複数観測間のわずかなズレを利用した高解像度化の土台を作る
・深層特徴抽出 (Deep Feature Extraction)・・・融合された特徴量を、SISRコンポーネント(Swin Transformerベース)に入力し、学習済みの膨大なパターン知識を用いて、精細なディテールを再構築する
・アップサンプリング・・・最後にピクセルシャッフル層で画像の解像度を4倍に引き上げる

【議論の内容・結果は?】
◾️土地被覆分類の結果
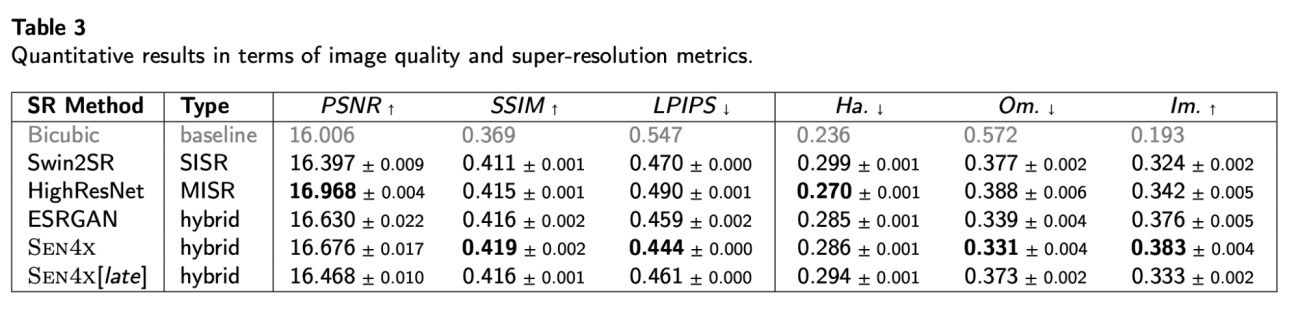
・SEN4Xが、テストされた全ての超解像モデルの中で最高の分類精度を達成した
・mIoUスコアは0.516で、SISR単体のSwin2SR (0.489) を2.7ポイント、MISR単体のHighResNet (0.387) を12.9ポイントも上回った
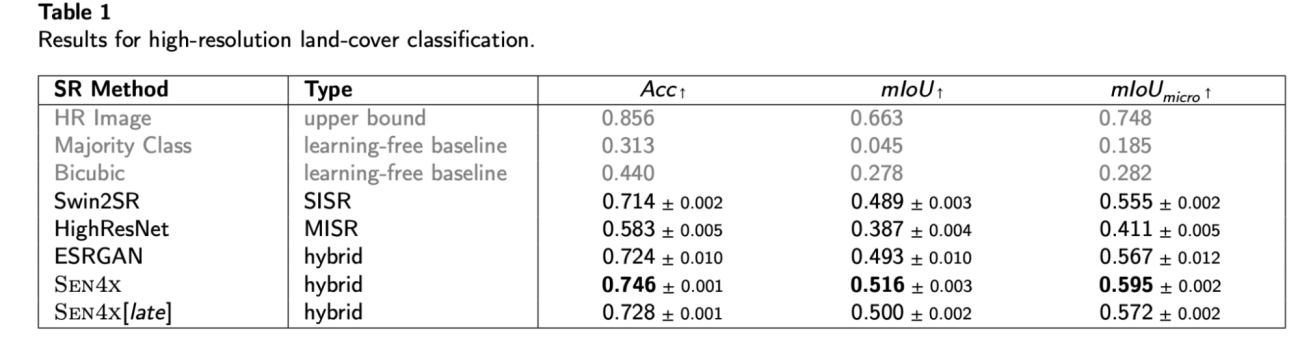
◾️従来の画質指標と実用性の乖離
・PSNR(値が高いほど良い)のような伝統的な画質指標は、分類性能とほとんど相関しなかった
・例えば、分類性能が最も低かったHighResNetは、PSNRでは最も高いスコアを記録している
・一方で、AIの知覚的類似性を測るLPIPS(値が低いほど良い)は、分類性能と最もよく相関していた
◾️定性比較
・実際の画像と分類結果マップを並べたこの図を見ると、SEN4Xが他の手法に比べて、細い道路や密集した建物をより正確に復元・分類できていることが視覚的に確認できる
・水域や草地のような広くて均質な領域はどの手法でもある程度正しく分類できるが、主に差が出るのは都市部の複雑な構造物であることもわかった

#SEN4X #Sentinel2 #Super-Resolution #SwinTransformer
来月以降も「#MonthlySatDataNews」「#衛星論文」を続けていきますので、お楽しみに!
