【衛星データ×基盤モデル】Tellus AI PlaygroundでAIモデルを動かしてみた!
2025年8月19日にローンチしたTellusの新サービス「Tellus AI Playground」について、その概要と実行例、有用性について紹介します!
(1)はじめに
2025年8月19日、日本最大級の衛星データ基盤を提供するTellusが新サービス「Tellus AI Playground」をローンチしました。
「Tellus AI Playground」とはどういったサービスなのか、本記事では、実際に使ってみた記録と合わせてご紹介します。
本記事を通して、「Tellus AI Playground」の魅力を体感いただけますと幸いです。
(2)Tellus AI Playground とは
「Tellus AI Playground」は、ラベル付き衛星データセット、基盤モデル、高性能GPU環境「NVIDIA H100 GPU(以下、H100)」をワンパッケージで提供する法人向け国産クラウドサービスです。
Tellus AI Playgroundは、Tellus が既存に提供している衛星データを統合することで、衛星データの処理を円滑に進めることができる環境になっています。衛星データと計算資源がセットで提供されるというサービスです。
月額制で手軽に使いやすいようなサービス体系となっています。
Tellus AI Playgroundについての詳細はこちらのサイトをご覧ください。
基盤モデル
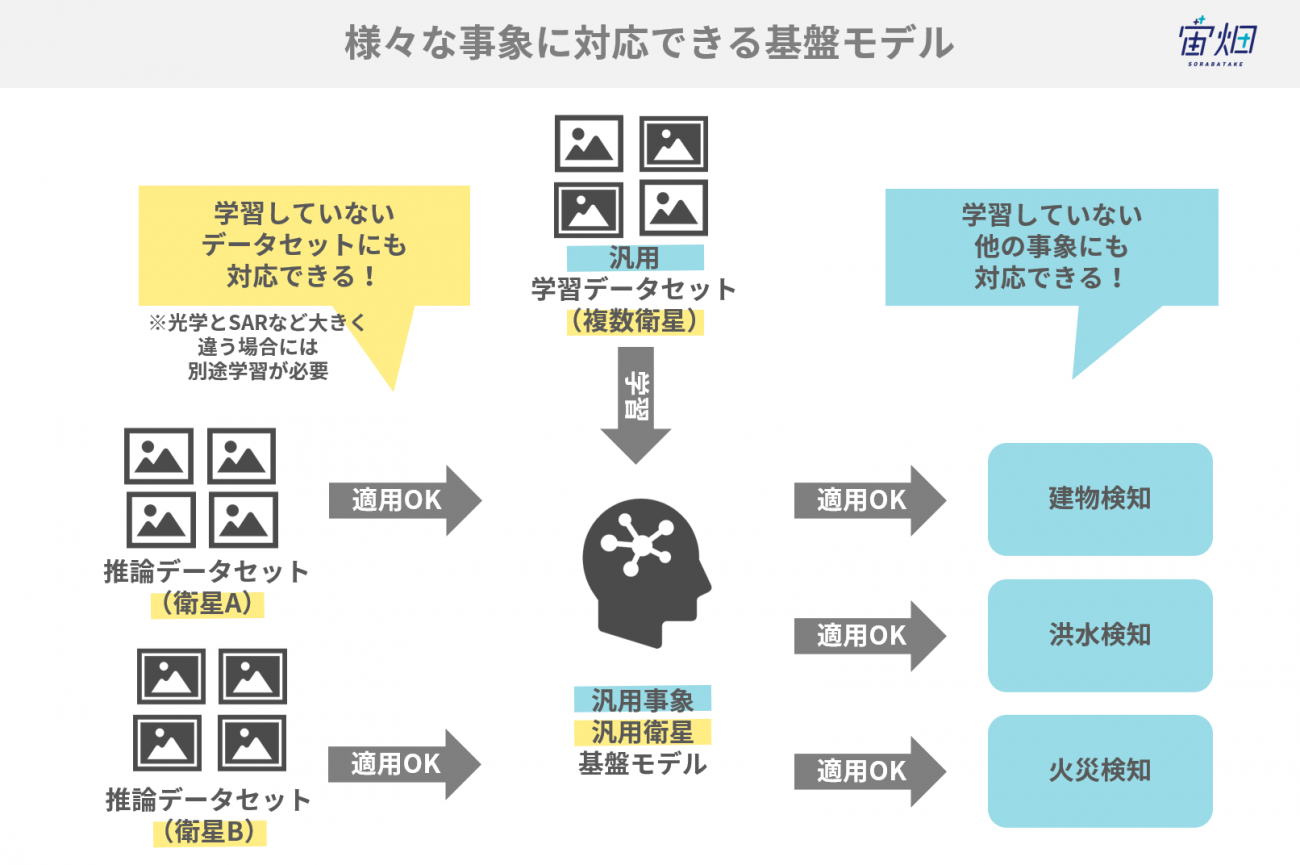
基盤モデル(Foundation Model)とは、大量データで一般的な特徴を学習したモデルのことで、個別の学習なしで、比較的簡単に様々なデータセットやタスクに汎用性高く対応できる点が特徴です。
基盤モデルはChatGPTなど言語分野で利用が進んできましたが、最近では、衛星データを取り扱う基盤モデルも登場しています。
宙畑でも以前、こちらの記事で紹介しています。
IBM と NASA の「Largest Geospatial AI」とは? 複数衛星のデータ融合と衛星基盤モデルによる先端技術の利用とその Python実装
Tellus AI Playgroundでは、現在GeoRSCLIPとSAM2が用意されています。
NVIDIA H100 GPU
Tellus AI Playgroundの中で提供されるNVIDIA H100 GPUとは、大規模生成AIやHPC(High Performance Computing)用に設計されたデータセンター向けGPUです。HBM3(80GBのメモリサイズ)と約 3TB/s のメモリ帯域、PCIe Gen5、4世代目 NVLink による 900GB/s の GPU 間接続、さらに NVLink Switch により多数 GPU へスケールでき、巨大モデルや MoE、並列分散学習のボトルネックを広く解消します。
H100は、単に前世代のGPUより高速であるという次元にはとどまりません。それは、まさに大規模画像解析が直面する根本的な課題を、ハードウェアレベルで解決するために設計された、次世代のコンピューティングプラットフォームなのです。
H100を所有するユーザーは、他の研究者や企業がソフトウェアの工夫で乗り越えようとしている壁を、圧倒的なパワーで正面から突破する、計り知れないアドバンテージを手にすることになります。一言で言うならば業務用の最強GPUです。
なお、本記事では宇宙に特化したサービスであるTellus AI Playgroundを使っていますが、宇宙に限らないH100の利用にご興味がある方は、さくらインターネットでVM型GPUクラウドサービス高火力VRT(バート)というサービスを提供していますので、こちらも合わせてチェックいただければと思います。
VM型GPUクラウドサービス 高火力 VRT(バート) | さくらインターネット
データセット
Tellusはこれまでも衛星データを数多く搭載してきたプラットフォームです。
今回のサービスでは、プリインストールのデータセットとして、Sentinel-2をベースにした、土地被覆クラスの割合と地物情報が付与されたデータセットが用意されています。
他にも、Tellusの担当者の方に相談すれば、Tellusに搭載している衛星データを使ったデータセットの作成も相談できるとのことです。
ぜひ、相談してみてください。
(3)Tellus AI Playgroundで準備されているものは?
本記事では、実際にTellus AI Playgroundで何ができるのかを実感いただけるよう、実践した結果も紹介します。
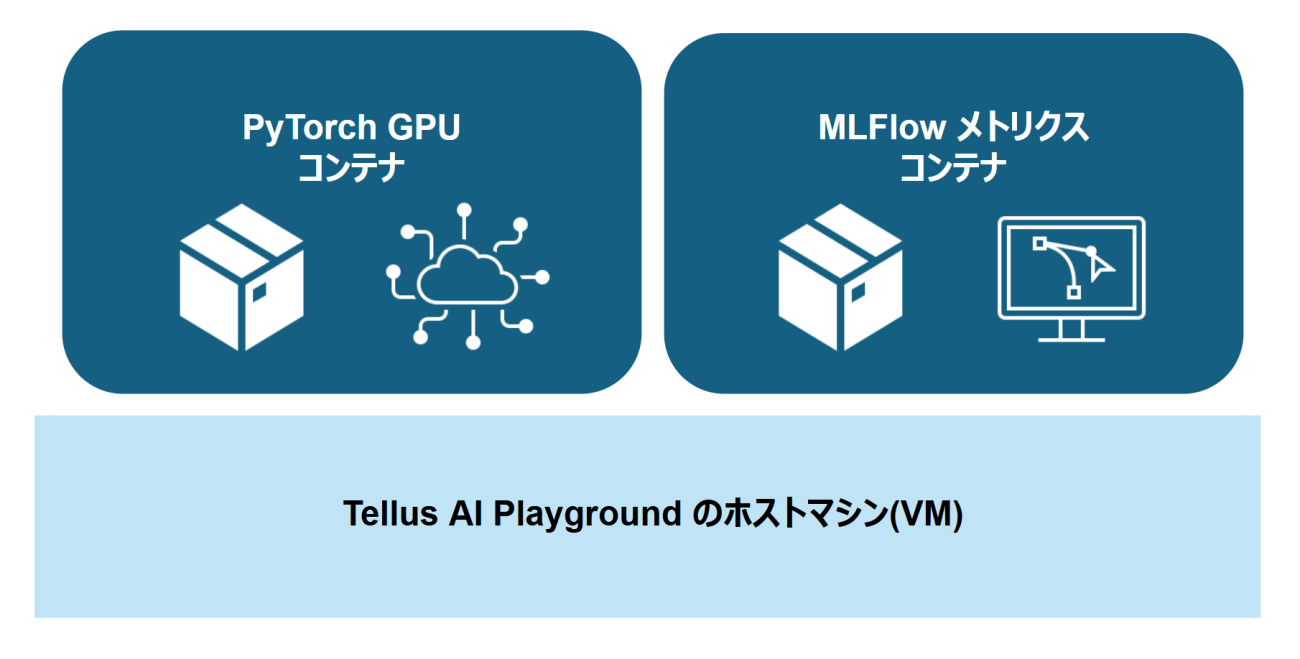
基本的には、一般的なクラウド環境と同じなのでSSHを使用してサーバーと接続して開発を行いますが、Tellus AI Playground では、機械学習処理を始めとしたGPU環境がすぐに可能なようにPyTorch の Docker コンテナが準備されています。
さらに、その実験ログやメトリクスなどを保存できる MLflow が起動しているコンテナも準備されています。
※PyTorchやMLFlowは利用者からの要望に応じて、Tellusがインストールを代行して実施してくれます。
(4)実践①Tellus AI Playground のサンプルコードを確認
Tellus AI Playground を初めて使用する時に動作確認やその高速処理を体感していただくために、いくつかのモデルとサンプルコードが提供されています。
1つ目は、CNN による MNIST の分類処理です。手書き数字の定番データセットを使ってGPU確認をしていきます。

実装コードは以下のようになっています。
import os
import sys
import argparse
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import mlflow
import mlflow.pytorch
from tqdm import tqdm
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 16, 3, 1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.fc = nn.Linear(16 * 13 * 13, 10)
def forward(self, x):
x = self.conv(x)
x = x.view(-1, 16 * 13 * 13)
return self.fc(x)
def train(args):
os.makedirs(args.output_dir, exist_ok=True)
mlflow.set_tracking_uri(args.tracking_uri)
mlflow.set_experiment(args.experiment_name)
transform = transforms.Compose([transforms.ToTensor()])
train_set = torchvision.datasets.MNIST(root=args.data_dir, train=True, download=True, transform=transform)
test_set = torchvision.datasets.MNIST(root=args.data_dir, train=False, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=args.batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=args.batch_size, shuffle=False)
if not torch.cuda.is_available():
raise RuntimeError("CUDA device not available. This script requires a GPU.")
device = torch.device("cuda")
model = SimpleCNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=args.lr)
try:
with mlflow.start_run(run_name="simple-cnn-mnist"):
mlflow.log_params({
"epochs": args.epochs,
"batch_size": args.batch_size,
"lr": args.lr,
"device": str(device),
})
for epoch in range(args.epochs):
# --- Training ---
model.train()
running_loss = 0.0
correct = 0
total = 0
progress = tqdm(train_loader, desc=f"Epoch {epoch+1}/{args.epochs}", unit="batch")
for inputs, labels in progress:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
progress.set_postfix(loss=loss.item())
epoch_loss = running_loss / total
epoch_acc = correct / total
mlflow.log_metric("loss", epoch_loss, step=epoch)
mlflow.log_metric("accuracy", epoch_acc, step=epoch)
# --- Evaluation ---
model.eval()
val_loss = 0.0
val_correct = 0
val_total = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item() * inputs.size(0)
_, predicted = outputs.max(1)
val_total += labels.size(0)
val_correct += predicted.eq(labels).sum().item()
val_loss /= val_total
val_acc = val_correct / val_total
mlflow.log_metric("val_loss", val_loss, step=epoch)
mlflow.log_metric("val_accuracy", val_acc, step=epoch)
# --- Save final model ---
weight_path = os.path.join(args.output_dir, args.weight_file)
torch.save(model.state_dict(), weight_path)
mlflow.log_artifact(weight_path)
mlflow.pytorch.log_model(model, artifact_path="model")
except Exception as e:
print("Training failed:", e, file=sys.stderr)
sys.exit(1)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--output_dir", type=str, required=True)
parser.add_argument("--weight_file", type=str, default="model_epoch_final.pt")
parser.add_argument("--data_dir", type=str, default="data")
parser.add_argument("--tracking_uri", type=str, default="http://mlflow-server:5000")
parser.add_argument("--experiment_name", type=str, default="CNN-MNIST")
parser.add_argument("--epochs", type=int, default=20)
parser.add_argument("--batch_size", type=int, default=64)
parser.add_argument("--lr", type=float, default=0.01)
args = parser.parse_args()
train(args)PyTrochのコンテナ環境には Jupyter1環境が手配されているのでJupyterLabに接続すると以下のような感じになります。
そして、申込時に依頼をすれば、環境構築はTellus側で代行してくれるので、こちらでは環境構築を一切せずにPyTorchが事前に準備されたコンテナ内にて学習することができます。
ここで学習されたLoss(損失値)やメトリクス(精度)については、接続されたMLflowコンテナに送られて記録されます。MLflowのGUI操作によって管理が可能になります。
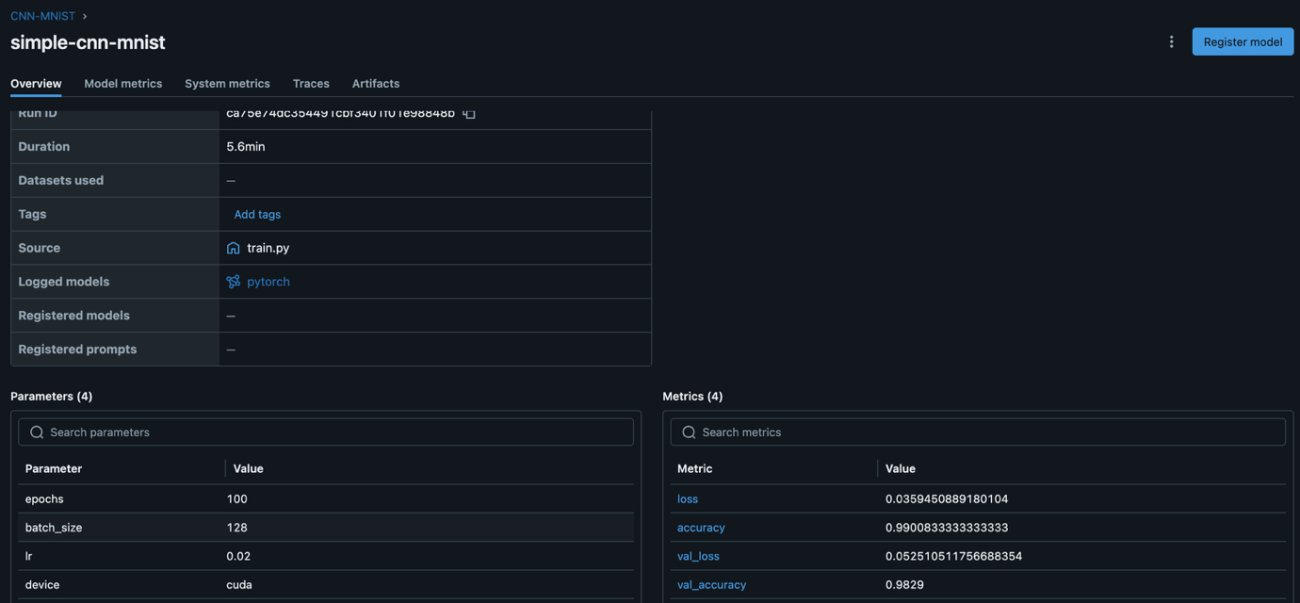
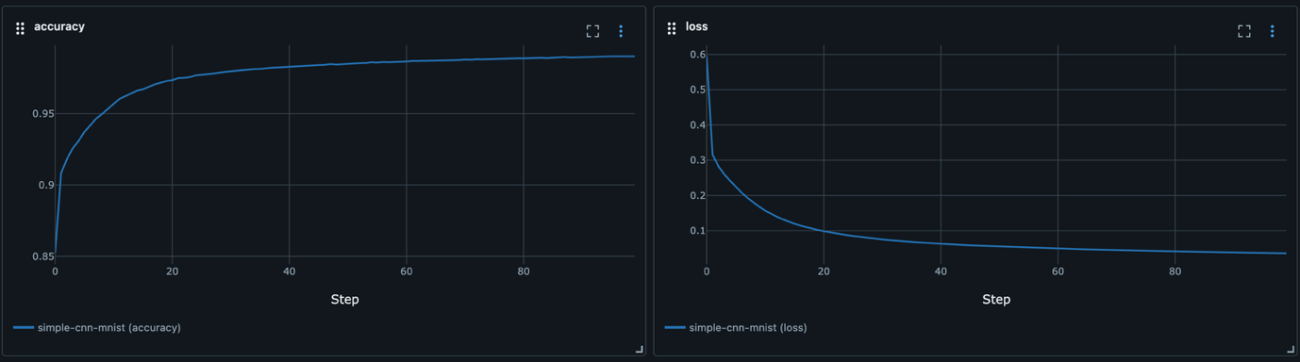
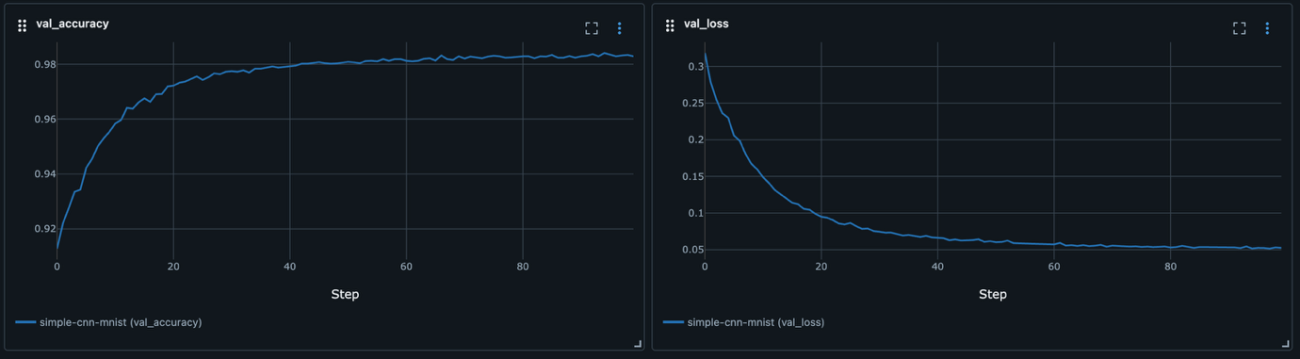
図 5のように、実行したスクリプトやパラメーター管理などが手軽にできるようになっています。このような環境が用意されているのは開発者の手助けになるのではないかと思います。
2つ目は、リモートセンシングの視覚言語モデル GeoRSCLIPです。論文名は RS5M and GeoRSCLIP: A Large Scale Vision-Language Dataset and A Large Vision-Language Model for Remote Sensing 2で、視覚言語モデル(Vision&Language)であるCLIPをリモートセンシングの領域で強化されたモデルです。
こちらも環境構築などの手間なく使用できます。
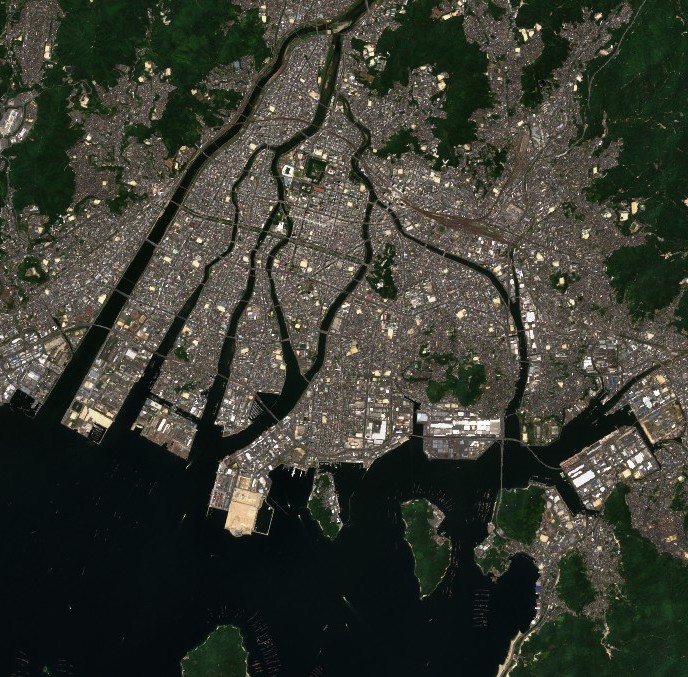
Credit : Contains modified Copernicus Sentinel data (2015-2022)
出力結果は以下のようになっています。
— 推論結果 —
対象画像: sample.jpg
テキスト: ‘空港の衛星画像’ 類似度スコア: 0.1030
テキスト: ‘海沿いの街’ 類似度スコア: 0.8773
テキスト: ‘たくさんの車’ 類似度スコア: 0.0068
テキスト: ‘雪山の衛星画像’ 類似度スコア: 0.0037
テキスト: ‘遊んでいる犬’ 類似度スコア: 0.0091最も類似度が高いテキスト: ‘海沿いの街’ スコア: 0.8773
このように画像と言語の類似度を算出してスコア表示することができます。
出力結果を確認すると、図 9の画像と空港を示す言語と類似度が高くなっていることが伺えます。このように画像からの言語による示唆を得ることが可能になっています。
3つ目は、SAM2こと、Segment Anything Model の後継機モデルの バージョン2です。SAMとは、Fetaが開発した汎用的なセグメンテーションするように設計されたモデルです。あらゆるクラスラベルを学習してゼロショットを実現するツールです。
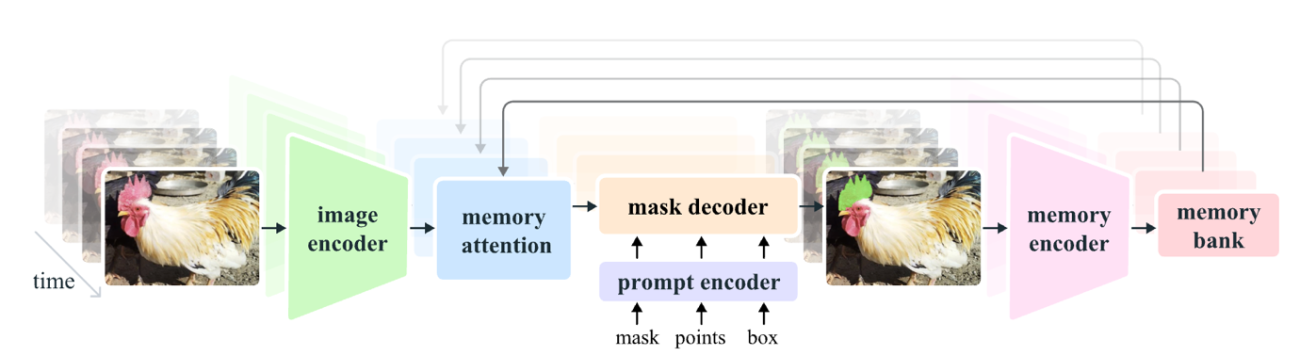
SAM2も同様に環境が完備されたコンテナによって即座に使用することができます。
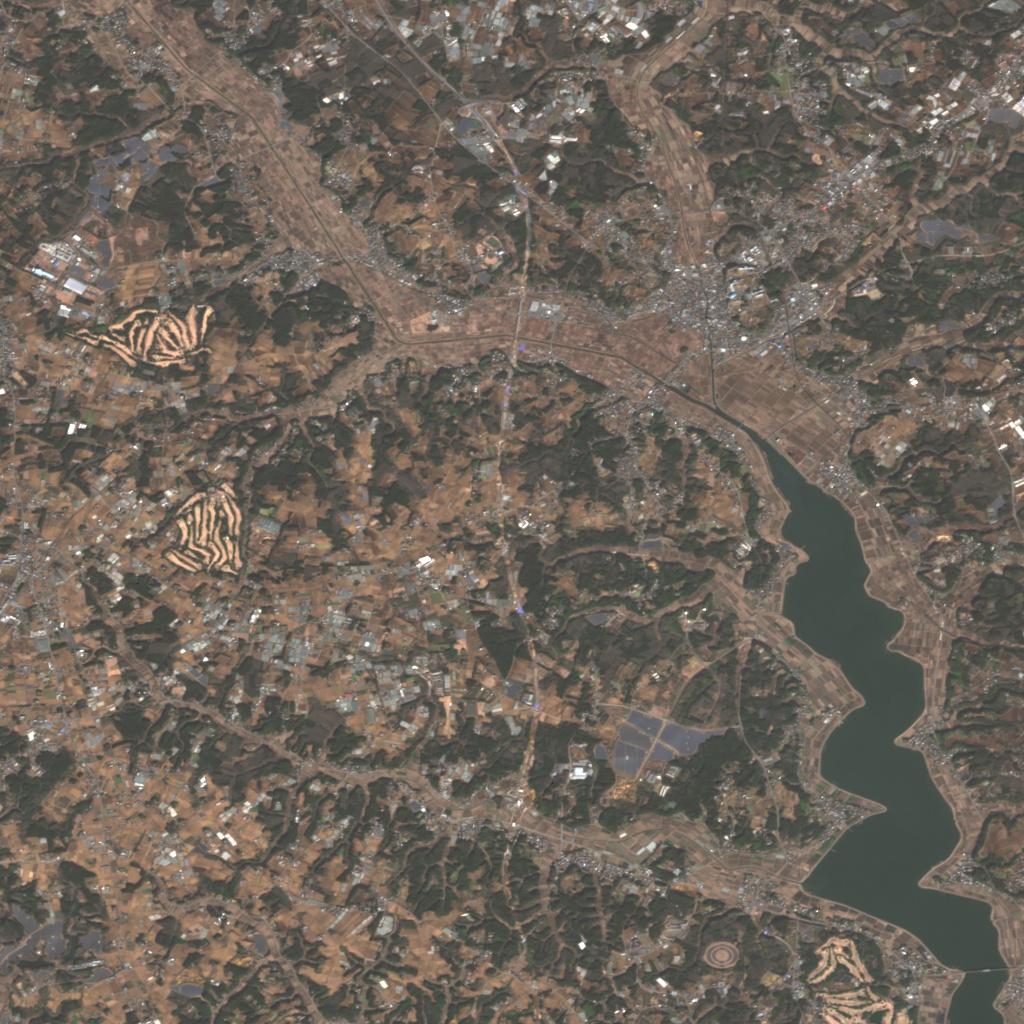
図 11の入力画像に対して、検知した結果は図 12の色付けされた領域になります。
このように高分解能な衛星画像であれば、ある程度の物体の領域を分割して汎用的に検知することが可能です。

ここまでで、3つのサンプルを紹介しました。では、1つ目のモデルの動作での GPU使用率を見ていきましょう。
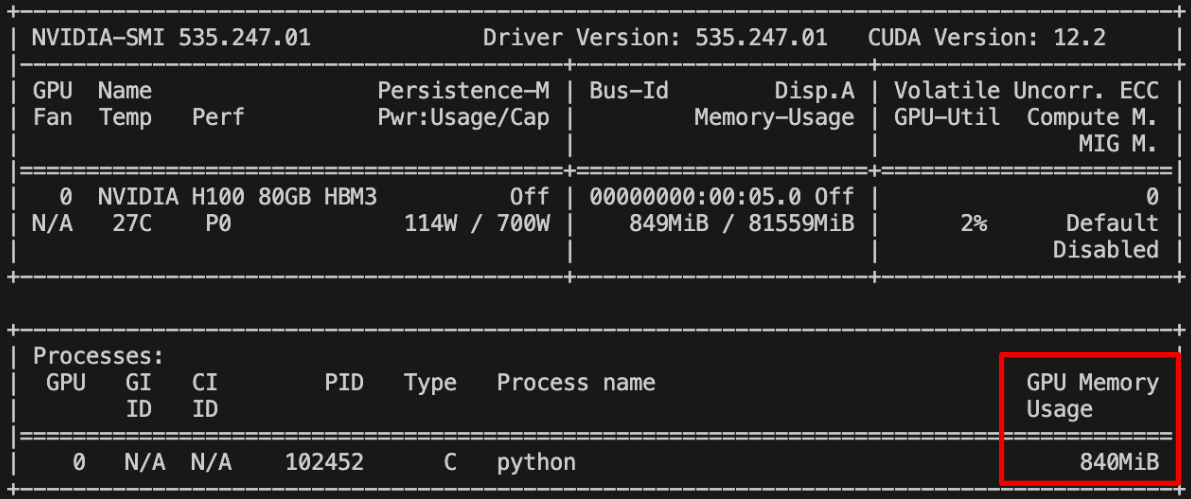
赤色の矩形の領域
図 13では、この程度の使用率です。H100 GPUのせっかくの良さが活かせていないので次では、もう少し重めの学習や実験をしておきましょう。
(5)実践②Tellus AI Playground で衛星画像から桜を検知
過去には宙畑で「衛星から桜は見える!」「商用最高級の衛星データなら桜の開花状況が分かる!?」など、桜×衛星データの記事があり、その実践編として、MAXARの高解像度4バンド衛星画像を使い、桜の自動検知から“お花見スポット探索”を行った記事も公開しています。
衛星データから桜の開花検知によるお花見スポット探索の実装と3Dでの表現【MAXARの衛星データでやってみた】
これらの記事ではメディアからも注目を集め、NHK様の番組『地球解析』の撮影協力をさせていただくきっかけになるなど反響も大きかったです。
こちらのデータを使用して、物体検知ではなく、セグメンテーションのタスクにしてGPU負荷が高い処理をすることで NVIDIA H100 GPUを搭載した Tellus AI Playground の真価を見定めていきたいと思います。
Tellus が提供する環境にはライセンス的にダウンロードして持ち出せない衛星データもありますが、データをアップロードして持ち込むことは許可されています。解析したいデータをアップロードして解析していきましょう。
まずは、宙畑編集部で購入したMAXARの衛星画像をアップロードして可視化してみましょう。
# 画像の読み込みと可視化
with rasterio.open(PATH_IMG) as src:
img = src.read([1, 2, 3]) # RGBバンドを読み込み
img = np.moveaxis(img, 0, -1) # チャンネルを最後の次元に移動
print(f'Loaded -> Image shape: {img.shape}')
def normalize_percentile_8bit(img, p1=2, p99=98):
"""画像の正規化(パーセンタイル)"""
img = img.astype(np.float32) # float32に変換
H, W, C = img.shape
for c in range(C):
p_min = np.percentile(img[:, :, c], p1)
p_max = np.percentile(img[:, :, c], p99)
img[:, :, c] = (img[:, :, c] - p_min) / (p_max - p_min)
img = np.clip(img, 0, 1) # 0-1の範囲にクリップ
img = (img * 255).astype(np.uint8) # 8ビットに変換
return img
img = normalize_percentile_8bit(img)
# BGR からRGBに変換
img = img[:, :, ::-1]
plt.figure(figsize=(16, 16), dpi=100, facecolor='w', edgecolor='k')
plt.imshow(img)
plt.title('Satellite Image © MAXAR Technologies')
plt.tight_layout()
plt.savefig(os.path.join(PATH_OUTPUT, 'satellite_image.png'),)
plt.show();
plt.clf();plt.close()
同じく桜が咲いている領域のマスクを可視化してみましょう。
# マスクの読み込みと可視化
with rasterio.open(PATH_MASK) as src:
mask = src.read(1) # マスクは単一バンド
mask = np.where(mask > 0, 1, 0) # 0以外の値を1に変換
print(f'Loaded -> Mask shape: {mask.shape}')
plt.figure(figsize=(16, 16), dpi=100, facecolor='w', edgecolor='k')
plt.imshow(mask, cmap='YlOrRd', vmin=0, vmax=1)
plt.title('Sakura Mask')
plt.tight_layout()
plt.savefig(os.path.join(PATH_OUTPUT, 'sakura_mask.png'),)
plt.show();
plt.clf();plt.close()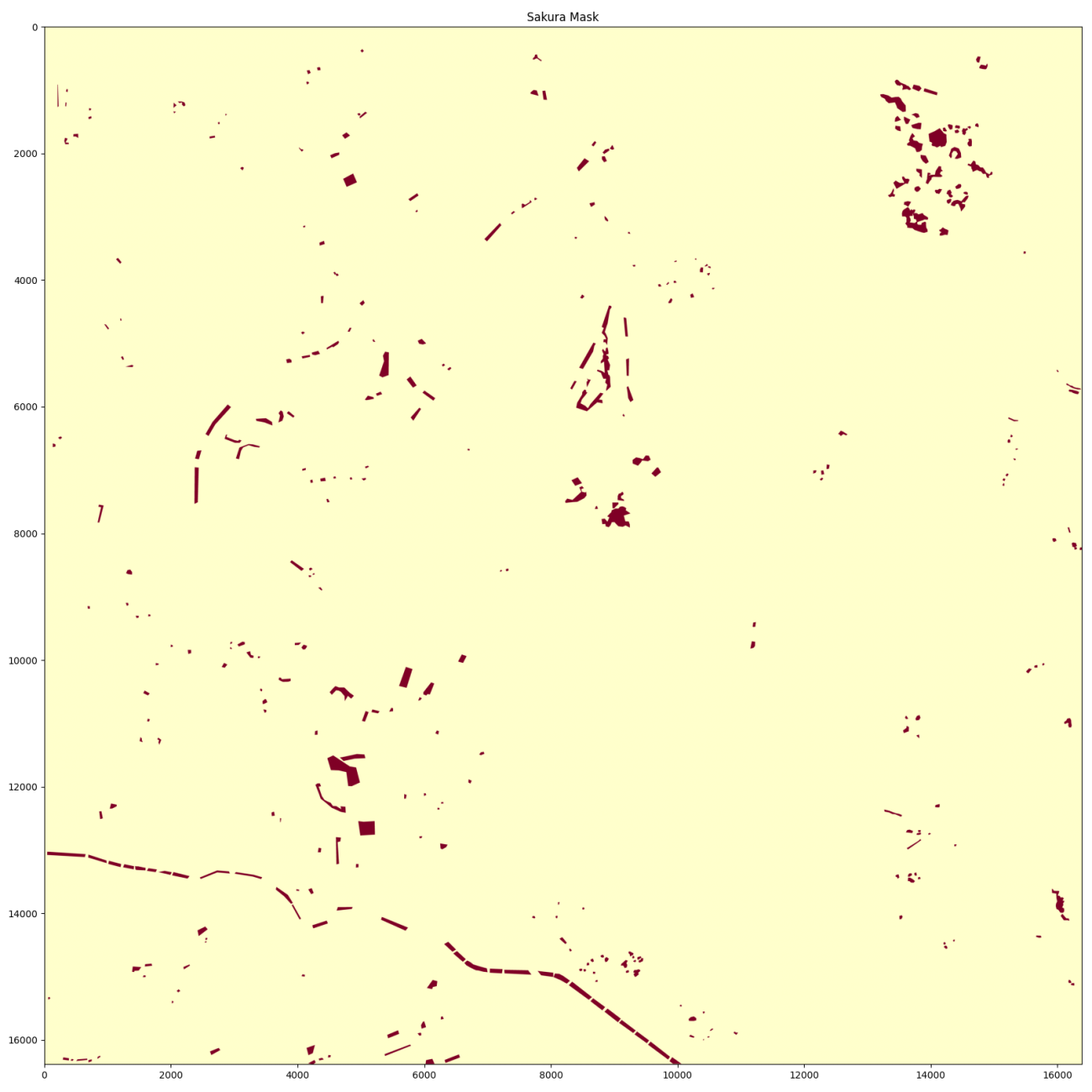
念の為、衛星画像と桜のマスクを重ね合わせて、地理空間的に正しいか確認しておきます。
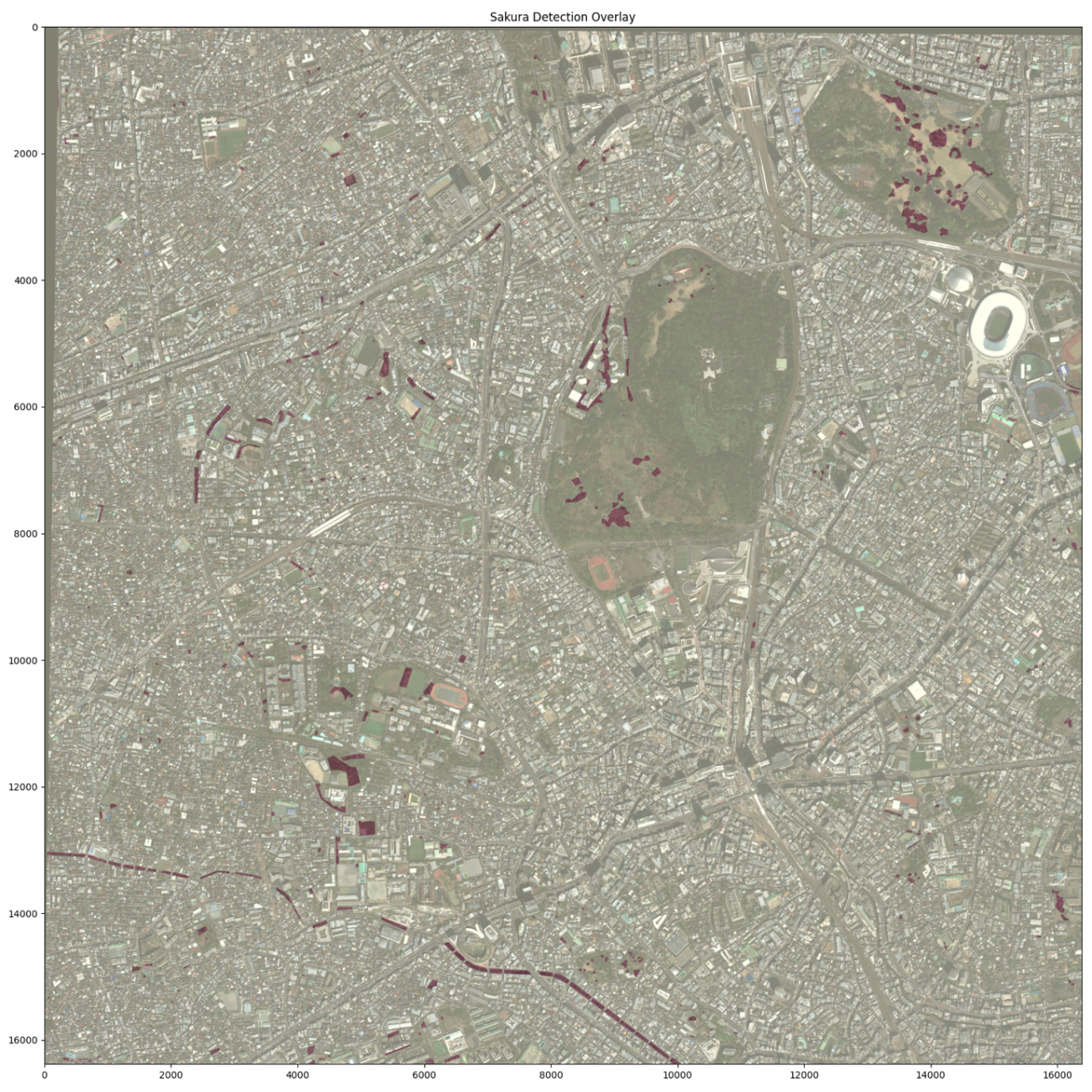
図 16から衛星画像とアノテーションのペアができていますね。川沿いの桜や公園の桜の位置で確認するとわかりやすいと思います。では、こちらを分割して機械学習のしやすいように処理していきましょう。
def save_patches_pair(
img: np.ndarray,
mask: np.ndarray,
patch_size: int,
out_dir: str,
mask_as_label: bool = True, # True: 0/1 のラベルで保存, False: 0/255 の可視化値で保存
):
"""
img: H x W x C (uint8 想定)
mask: H x W (0/1 想定)
"""
assert img.ndim == 3 and mask.ndim == 2, "imgはHWC, maskはHWの想定です"
H, W, C = img.shape
hm, wm = mask.shape
assert (H, W) == (hm, wm), f"画像とマスクのサイズ不一致: img={img.shape}, mask={mask.shape}"
out_dir = Path(out_dir)
out_dir.mkdir(parents=True, exist_ok=True)
# --- パディング(端数が出る場合に右端/下端を0で埋める) ---
H_pad = math.ceil(H / patch_size) * patch_size
W_pad = math.ceil(W / patch_size) * patch_size
pad_h = H_pad - H
pad_w = W_pad - W
if pad_h > 0 or pad_w > 0:
img_pad = np.pad(img, ((0, pad_h), (0, pad_w), (0, 0)), mode="constant", constant_values=0)
mask_pad = np.pad(mask, ((0, pad_h), (0, pad_w)), mode="constant", constant_values=0)
else:
img_pad = img
mask_pad = mask
# --- 走査して保存 ---
idx = 0
manifest_rows = []
for y in tqdm(range(0, H_pad, patch_size), desc="Processing patches", unit="patch", total=math.ceil(H_pad / patch_size)):
for x in range(0, W_pad, patch_size):
idx += 1
img_patch = img_pad[y:y+patch_size, x:x+patch_size, :]
mask_patch = mask_pad[y:y+patch_size, x:x+patch_size]
# 出力ファイル名(ゼロ詰め5桁)
stem = f"patch_{idx:05d}"
f_img = out_dir / f"{stem}_img.png"
f_mask = out_dir / f"{stem}_mask.png"
# マスク保存形式
if mask_as_label:
mask_out = mask_patch.astype(np.uint8) # 0/1 のまま
else:
mask_out = (mask_patch.astype(np.uint8) * 255) # 可視化しやすい 0/255
imageio.imwrite(f_img, img_patch) # PNG, uint8
imageio.imwrite(f_mask, mask_out) # PNG, uint8
# 元画像座標系でのパッチ範囲(パディング前の範囲をクリップ)
x0, y0 = x, y
x1, y1 = min(x + patch_size, W), min(y + patch_size, H)
# マニフェストに記録
frac_mask = float(mask_patch.sum()) / float(patch_size * patch_size) # 1の割合
manifest_rows.append({
"index": idx,
"img_path": str(f_img),
"mask_path": str(f_mask),
"x0": x0, "y0": y0, "x1": x1, "y1": y1,
"in_bounds_width": x1 - x0,
"in_bounds_height": y1 - y0,
"mask_sum": int(mask_patch.sum()),
"mask_frac": frac_mask,
})
# --- マニフェストCSV保存 ---
manifest_path = out_dir / "manifest.csv"
with open(manifest_path, "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(
f,
fieldnames=[
"index", "img_path", "mask_path",
"x0", "y0", "x1", "y1",
"in_bounds_width", "in_bounds_height",
"mask_sum", "mask_frac"
],
)
writer.writeheader()
writer.writerows(manifest_rows)
print(f"Saved {idx} patch pairs to: {out_dir}")
print(f"Manifest: {manifest_path}")
# ========= 実行 =========
OUT_PATCH_DIR = os.path.join(PATH_OUTPUT, "patch")
save_patches_pair(
img=img,
mask=mask,
patch_size=PATH_PATCH_SIZE,
out_dir=OUT_PATCH_DIR,
mask_as_label=False, # 学習用に0/1ラベルで保存。可視化重視なら False に
)
# ========= 設定 =========
VAL_RATIO = 0.2 # 検証データの割合
RANDOM_SEED = 2025 # 乱数シード(再現性)
LINK_METHOD = "copy" # "symlink" | "hardlink" | "copy"
PATCH_DIR = os.path.join(PATH_OUTPUT, "patch")
MANIFEST = os.path.join(PATCH_DIR, "manifest.csv")
DATASET_DIR = os.path.join(PATH_OUTPUT, "dataset")
# ========= 乱数の固定 =========
random.seed(RANDOM_SEED)
np.random.seed(RANDOM_SEED)
# ========= CSV 読み込み & バリデーション =========
df = pd.read_csv(MANIFEST)
# 必須列チェック
required_cols = {"index", "img_path", "mask_path", "mask_frac"}
missing = required_cols - set(df.columns)
if missing:
raise ValueError(f"manifest.csv に必要な列が不足しています: {missing}")
# ファイル実在確認(欠損は除外し警告)
def exists_or_none(p):
try:
return Path(p).exists()
except Exception:
return False
df["img_exists"] = df["img_path"].apply(exists_or_none)
df["mask_exists"] = df["mask_path"].apply(exists_or_none)
if (~df["img_exists"] | ~df["mask_exists"]).any():
missing_rows = df.loc[(~df["img_exists"]) | (~df["mask_exists"]), ["index","img_path","mask_path"]]
print("⚠️ 次のパッチでファイルが見つかりません。これらは分割から除外します。")
print(missing_rows.to_string(index=False))
df = df[df["img_exists"] & df["mask_exists"]].copy()
if len(df) == 0:
raise RuntimeError("有効なパッチがありません。manifest.csvとファイル配置を確認してください。")
# ========= 層化サンプリング用のビン作成(mask_fracの分布維持) =========
# 5分位でビン分け。重複で割れない場合は等間隔ビンにフォールバック。
try:
df["strata"] = pd.qcut(df["mask_frac"], q=5, labels=False, duplicates="drop")
except Exception:
# 等間隔 5 ビン(値域が狭い場合は1ビン)
vmin, vmax = float(df["mask_frac"].min()), float(df["mask_frac"].max())
if np.isclose(vmin, vmax):
df["strata"] = 0
else:
bins = np.linspace(vmin, vmax, 6) # 5区間
df["strata"] = np.digitize(df["mask_frac"], bins[1:-1], right=True)
df["strata"] = df["strata"].fillna(0).astype(int)
df["nonempty"] = (df["mask_frac"] > 0).astype(int)
# ========= train/val に分割(層化) =========
val_idx = (
df.groupby("strata", group_keys=False)
.apply(lambda g: g.sample(frac=VAL_RATIO, random_state=RANDOM_SEED))
.index
)
df["split"] = "train"
df.loc[val_idx, "split"] = "val"
# ========= 出力ディレクトリ準備 =========
def ensure_dirs(base):
for split in ("train", "val"):
for sub in ("images", "masks"):
Path(base, split, sub).mkdir(parents=True, exist_ok=True)
ensure_dirs(DATASET_DIR)
# ========= リンク/コピー関数 =========
def link_or_copy(src: str, dst: str, method: str = LINK_METHOD):
src_p = Path(src)
dst_p = Path(dst)
if dst_p.exists():
dst_p.unlink()
try:
if method == "symlink":
dst_p.symlink_to(src_p.resolve())
elif method == "hardlink":
os.link(src_p, dst_p)
else:
shutil.copy2(src_p, dst_p)
except Exception as e:
# フォールバックでコピー
print(f"⚠️ {method} に失敗したためコピーへ切替: {dst} ({e})")
shutil.copy2(src_p, dst_p)
# ========= 実ファイルを split ディレクトリへ配置 =========
def place_pair(row):
split = row["split"]
stem = f"patch_{int(row['index']):05d}"
img_dst = Path(DATASET_DIR, split, "images", Path(row["img_path"]).name) # 元のファイル名を維持
mask_dst = Path(DATASET_DIR, split, "masks", Path(row["mask_path"]).name)
link_or_copy(row["img_path"], img_dst)
link_or_copy(row["mask_path"], mask_dst)
df.apply(place_pair, axis=1)
# ========= 分割ごとのCSV/リストを書き出し =========
train_df = df[df["split"] == "train"].copy()
val_df = df[df["split"] == "val"].copy()
# 相対パス(DATASET_DIRからの相対)も保存しておくと再配置に頑健
def to_rel(path_abs):
try:
return str(Path(path_abs).resolve().relative_to(Path(DATASET_DIR).resolve()))
except Exception:
return path_abs
for sub in ("img_path", "mask_path"):
train_df[f"{sub}_rel"] = train_df[sub].apply(to_rel)
val_df[f"{sub}_rel"] = val_df[sub].apply(to_rel)
train_csv = Path(DATASET_DIR, "train.csv")
val_csv = Path(DATASET_DIR, "val.csv")
train_df.to_csv(train_csv, index=False)
val_df.to_csv(val_csv, index=False)
# 典型的なデータローダー向けのリスト(image,mask のタブ区切り)
def export_list(df_, out_txt):
lines = []
for _, r in df_.iterrows():
img_rel = f"{r['split']}/images/{Path(r['img_path']).name}"
mask_rel = f"{r['split']}/masks/{Path(r['mask_path']).name}"
lines.append(f"{img_rel}\t{mask_rel}")
Path(out_txt).write_text("\n".join(lines), encoding="utf-8")
export_list(train_df, Path(DATASET_DIR, "train_list.tsv"))
export_list(val_df, Path(DATASET_DIR, "val_list.tsv"))
# ========= サマリ表示 =========
def summarize(df_):
n = len(df_)
n_pos = int((df_["nonempty"] == 1).sum())
frac_pos = n_pos / n if n > 0 else 0.0
return n, n_pos, frac_pos
n_all, n_pos_all, frac_pos_all = summarize(df)
n_tr, n_pos_tr, frac_pos_tr = summarize(train_df)
n_va, n_pos_va, frac_pos_va = summarize(val_df)
print("✅ Split completed.")
print(f"ALL : {n_all:5d} | positives={n_pos_all:5d} ({frac_pos_all:.1%})")
print(f"TRAIN: {n_tr:5d} | positives={n_pos_tr:5d} ({frac_pos_tr:.1%}) -> {train_csv}")
print(f"VAL : {n_va:5d} | positives={n_pos_va:5d} ({frac_pos_va:.1%}) -> {val_csv}")
print(f"Lists: {Path(DATASET_DIR,'train_list.tsv')} , {Path(DATASET_DIR,'val_list.tsv')}")
print(f"Data : {DATASET_DIR}/")✅ Split completed.
ALL : 1024 | positives= 286 (27.9%)
TRAIN: 819 | positives= 229 (28.0%) -> output/sakura_detection/dataset/train.csv
VAL : 205 | positives= 57 (27.8%) -> output/sakura_detection/dataset/val.csv
Lists: output/sakura_detection/dataset/train_list.tsv , output/sakura_detection/dataset/val_list.tsv
Data : output/sakura_detection/dataset/
では、学習して実験してみましょう。学習するスクリプトは以下です。
以下のコードでは、交差検証ができるようにデータセットを2セットに分割して学習と検証を繰り返して、それぞれが検証データになるようにしています。また、GPU使用率がわかるような処理も加えております。
# -*- coding: utf-8 -*-
# ライブラリのインポート
import os, sys, math, random, json, time
from pathlib import Path
import csv
import shutil
import imageio.v2 as imageio
from tqdm import tqdm
import numpy as np
import rasterio
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
from PIL import Image, ImageFile
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import StratifiedKFold
import segmentation_models_pytorch as smp
# ========= 出力ディレクトリの準備 =========
DATASET_DIR: str = "output/sakura_detection/dataset" # データセットのディレクトリ
PATH_OUTPUT: str = 'output/sakura_detection/exp1/'
os.makedirs(PATH_OUTPUT, exist_ok=True)
# ========= ユーザー設定 =========
NUM_EPOCHS = 15
BATCH_SIZE = 8
LR = 1e-4
NUM_WORKERS = 4
PIN_MEMORY = True
PERSISTENT = False
PREFETCH = 4 # NUM_WORKERS>0 のときのみ有効
NUM_FOLDS = 2
THRESH = 0.5
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
RANDOM_SEED = 2025
matplotlib.use("Agg") # 非インタラクティブ描画(PNG保存のみ)
# 乱数固定
def seed_everything(seed: int = 42):
random.seed(seed); np.random.seed(seed)
torch.manual_seed(seed); torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
seed_everything(RANDOM_SEED)
# ========= データ読み込み =========
DATASET_DIR = Path(DATASET_DIR)
train_csv = DATASET_DIR / "train.csv"
val_csv = DATASET_DIR / "val.csv"
if not train_csv.exists() or not val_csv.exists():
raise FileNotFoundError("train.csv / val.csv が見つかりません。前段の分割コードを実行してください。")
df_all = pd.concat([pd.read_csv(train_csv), pd.read_csv(val_csv)], ignore_index=True)
if "nonempty" not in df_all.columns:
df_all["nonempty"] = (df_all.get("mask_frac", 0) > 0).astype(int)
# パス存在確認
for pcol in ["img_path", "mask_path"]:
if not df_all[pcol].map(lambda p: Path(p).exists()).all():
missing = df_all.loc[~df_all[pcol].map(lambda p: Path(p).exists()), ["index", pcol]]
raise FileNotFoundError(f"ファイルが見つからない行があります:\n{missing.head()}")
# ========= Dataset(flip augmentationのみ) =========
ImageFile.LOAD_TRUNCATED_IMAGES = True
IMAGENET_MEAN = np.array([0.485, 0.456, 0.406], dtype=np.float32)
IMAGENET_STD = np.array([0.229, 0.224, 0.225], dtype=np.float32)
class SegPairDataset(Dataset):
def __init__(self, df: pd.DataFrame, augment: bool = True):
self.df = df.reset_index(drop=True)
self.augment = augment
def __len__(self): return len(self.df)
def _open_image(self, path: str):
try:
img = Image.open(path).convert("RGB")
arr = np.asarray(img, dtype=np.float32) / 255.0 # HWC
arr = (arr - IMAGENET_MEAN) / IMAGENET_STD
arr = np.transpose(arr, (2, 0, 1)) # CHW
return arr
except Exception as e:
raise RuntimeError(f"[Image open failed] {path}\n{e}")
def _open_mask(self, path: str):
try:
m = Image.open(path).convert("L")
m = np.asarray(m, dtype=np.float32)
m = (m > 0.5).astype(np.float32) # 0/1
m = np.expand_dims(m, axis=0) # 1HW
return m
except Exception as e:
raise RuntimeError(f"[Mask open failed] {path}\n{e}")
def _random_flip(self, img, mask):
if self.augment:
if random.random() < 0.5: # H-flip
img = img[:, :, ::-1].copy(); mask = mask[:, :, ::-1].copy()
if random.random() = thresh).float()
tp = (preds * target).sum().item()
tn = ((1 - preds) * (1 - target)).sum().item()
fp = (preds * (1 - target)).sum().item()
fn = ((1 - preds) * target).sum().item()
eps = 1e-8
acc = (tp + tn) / (tp + tn + fp + fn + eps)
f1 = (2 * tp) / (2 * tp + fp + fn + eps)
return acc, f1
# ========= 1エポック学習/評価 =========
def train_one_epoch(model, loader, optimizer, loss_fn, device):
model.train()
tl, ta, tf, n = 0.0, 0.0, 0.0, 0
for batch in loader:
images = batch["image"].to(device, non_blocking=True)
masks = batch["mask"].to(device, non_blocking=True)
optimizer.zero_grad(set_to_none=True)
logits = model(images)
loss = loss_fn(logits, masks)
loss.backward()
optimizer.step()
with torch.no_grad():
acc, f1 = compute_metrics(logits, masks)
tl += loss.item(); ta += acc; tf += f1; n += 1
return {"loss": tl/max(n,1), "acc": ta/max(n,1), "f1": tf/max(n,1)}
@torch.no_grad()
def evaluate(model, loader, loss_fn, device):
model.eval()
vl, va, vf, n = 0.0, 0.0, 0.0, 0
for batch in loader:
images = batch["image"].to(device, non_blocking=True)
masks = batch["mask"].to(device, non_blocking=True)
logits = model(images)
loss = loss_fn(logits, masks)
acc, f1 = compute_metrics(logits, masks)
vl += loss.item(); va += acc; vf += f1; n += 1
return {"loss": vl/max(n,1), "acc": va/max(n,1), "f1": vf/max(n,1)}
# ========= CV実験関数(★ encoder_name を引数化) =========
def run_cv_experiment(encoder_name: str,
df_all: pd.DataFrame,
out_root: Path,
num_folds: int = NUM_FOLDS,
num_epochs: int = NUM_EPOCHS,
batch_size: int = BATCH_SIZE,
lr: float = LR,
random_seed: int = RANDOM_SEED,
device: str = DEVICE):
seed_everything(random_seed)
tag = encoder_name.replace("/", "-")
models_dir = out_root / "models" / tag
logs_dir = out_root / "logs" / tag
plots_dir = out_root / "plots" / tag
for d in [models_dir, logs_dir, plots_dir]: d.mkdir(parents=True, exist_ok=True)
y_strata = df_all["nonempty"].values
skf = StratifiedKFold(n_splits=num_folds, shuffle=True, random_state=random_seed)
all_hist = []
gpu_env = {}
if torch.cuda.is_available():
prop = torch.cuda.get_device_properties(0)
gpu_env = {
"gpu_name": prop.name,
"total_mem_gb": round(prop.total_memory / (1024**3), 3),
"cuda_version": torch.version.cuda,
"torch_cuda": torch.version.cuda is not None
}
else:
gpu_env = {"gpu_name": None, "total_mem_gb": None, "cuda_version": None, "torch_cuda": False}
# fold loop
for fold, (tr_idx, va_idx) in tqdm(enumerate(skf.split(df_all, y_strata), start=1), total=num_folds):
print(f"\n========== [{tag}] Fold {fold}/{num_folds} ==========")
df_tr = df_all.iloc[tr_idx].reset_index(drop=True)
df_va = df_all.iloc[va_idx].reset_index(drop=True)
ds_tr = SegPairDataset(df_tr, augment=True)
ds_va = SegPairDataset(df_va, augment=False)
dl_tr = DataLoader(ds_tr, batch_size=batch_size, shuffle=True,
num_workers=NUM_WORKERS, pin_memory=PIN_MEMORY,
persistent_workers=PERSISTENT,
prefetch_factor=PREFETCH if NUM_WORKERS>0 else None)
dl_va = DataLoader(ds_va, batch_size=batch_size, shuffle=False,
num_workers=NUM_WORKERS, pin_memory=PIN_MEMORY,
persistent_workers=PERSISTENT,
prefetch_factor=PREFETCH if NUM_WORKERS>0 else None)
# --- model (imagenet weightsが無ければNoneにフォールバック) ---
try:
model = smp.Unet(encoder_name=encoder_name, encoder_weights="imagenet",
in_channels=3, classes=1, activation=None).to(device)
except Exception as e:
print(f"⚠️ {encoder_name} に 'imagenet' 重みが無いため encoder_weights=None で再作成: {e}")
model = smp.Unet(encoder_name=encoder_name, encoder_weights=None,
in_channels=3, classes=1, activation=None).to(device)
loss_fn = nn.BCEWithLogitsLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
best_f1 = -1.0
best_path = models_dir / f"unet_{tag}_fold{fold}_best.pth"
history = {"epoch": [], "train_loss": [], "train_acc": [], "train_f1": [],
"val_loss": [], "val_acc": [], "val_f1": [], "gpu_peak_alloc_gb": []}
for epoch in range(1, num_epochs+1):
print(f"[{tag}] Fold {fold} Epoch {epoch}/{num_epochs} (device={device})")
# --- GPUピークの計測をリセット ---
if torch.cuda.is_available():
torch.cuda.reset_peak_memory_stats()
tr = train_one_epoch(model, dl_tr, optimizer, loss_fn, device)
va = evaluate(model, dl_va, loss_fn, device)
# --- エポック中のGPUピーク(allocated) ---
if torch.cuda.is_available():
peak_gb = torch.cuda.max_memory_allocated() / (1024**3)
else:
peak_gb = float("nan")
# ログ
history["epoch"].append(epoch)
history["train_loss"].append(tr["loss"]); history["train_acc"].append(tr["acc"]); history["train_f1"].append(tr["f1"])
history["val_loss"].append(va["loss"]); history["val_acc"].append(va["acc"]); history["val_f1"].append(va["f1"])
history["gpu_peak_alloc_gb"].append(peak_gb)
print(f" Train: loss={tr['loss']:.4f}, acc={tr['acc']:.4f}, f1={tr['f1']:.4f}")
print(f" Val: loss={va['loss']:.4f}, acc={va['acc']:.4f}, f1={va['f1']:.4f} | GPU peak={peak_gb:.3f} GB")
# ベスト更新(Val F1)
if va["f1"] > best_f1:
best_f1 = va["f1"]
torch.save({"model_state": model.state_dict(),
"epoch": epoch, "val_f1": best_f1,
"encoder_name": encoder_name}, best_path)
print(f" ✅ Best updated: {best_path.name} (val_f1={best_f1:.4f})")
# foldログ保存 & 図
hist_df = pd.DataFrame(history)
hist_csv = logs_dir / f"fold{fold}_log.csv"
hist_df.to_csv(hist_csv, index=False, encoding="utf-8")
print(f"📄 Saved log: {hist_csv}")
plt.figure(figsize=(16,5))
plt.subplot(1,3,1)
plt.plot(hist_df["epoch"], hist_df["train_loss"], label="train")
plt.plot(hist_df["epoch"], hist_df["val_loss"], label="val")
plt.title(f"{tag} Fold{fold} - BCE Loss"); plt.xlabel("epoch"); plt.ylabel("loss"); plt.grid(True); plt.legend()
plt.subplot(1,3,2)
plt.plot(hist_df["epoch"], hist_df["train_acc"], label="train")
plt.plot(hist_df["epoch"], hist_df["val_acc"], label="val")
plt.title(f"{tag} Fold{fold} - Accuracy"); plt.xlabel("epoch"); plt.ylabel("acc"); plt.grid(True); plt.legend()
plt.subplot(1,3,3)
plt.plot(hist_df["epoch"], hist_df["train_f1"], label="train")
plt.plot(hist_df["epoch"], hist_df["val_f1"], label="val")
plt.title(f"{tag} Fold{fold} - F1"); plt.xlabel("epoch"); plt.ylabel("F1"); plt.grid(True); plt.legend()
fig_path = plots_dir / f"fold{fold}_curves.png"
plt.tight_layout(); plt.savefig(fig_path, dpi=150); plt.close()
print(f"🖼 Saved plot: {fig_path}")
# 集約用
hist_df["fold"] = fold
all_hist.append(hist_df)
# ========== 実験集約 ==========
cv_df = pd.concat(all_hist, ignore_index=True)
cv_df.to_csv(logs_dir / "cv_all_logs.csv", index=False, encoding="utf-8")
# エポック平均(fold平均ではなくfold全履歴のepoch平均)
cv_mean = (cv_df.groupby("epoch")[["train_loss","val_loss","train_acc","val_acc","train_f1","val_f1","gpu_peak_alloc_gb"]]
.mean().reset_index())
plt.figure(figsize=(14,5))
plt.subplot(1,2,1)
plt.plot(cv_mean["epoch"], cv_mean["train_loss"], label="train")
plt.plot(cv_mean["epoch"], cv_mean["val_loss"], label="val")
plt.title(f"{tag} CV Mean - BCE Loss"); plt.xlabel("epoch"); plt.ylabel("loss"); plt.grid(True); plt.legend()
plt.subplot(1,2,2)
plt.plot(cv_mean["epoch"], cv_mean["val_acc"], label="val Acc")
plt.plot(cv_mean["epoch"], cv_mean["val_f1"], label="val F1")
plt.title(f"{tag} CV Mean - Metrics"); plt.xlabel("epoch"); plt.ylabel("score"); plt.grid(True); plt.legend()
cv_plot = plots_dir / "cv_mean_curves.png"
plt.tight_layout(); plt.savefig(cv_plot, dpi=150); plt.close()
print(f"✅ Completed [{tag}]. CV mean plot: {cv_plot}")
# 各foldのベストF1まとめ
summary = []
for fold in range(1, NUM_FOLDS+1):
h = pd.read_csv(logs_dir / f"fold{fold}_log.csv")
best_row = h.loc[h["val_f1"].idxmax()]
summary.append({
"encoder": tag,
"fold": fold,
"best_epoch": int(best_row["epoch"]),
"best_val_loss": float(best_row["val_loss"]),
"best_val_acc": float(best_row["val_acc"]),
"best_val_f1": float(best_row["val_f1"]),
"best_gpu_peak_alloc_gb": float(h["gpu_peak_alloc_gb"].max()),
"model_path": str((out_root / "models" / tag / f"unet_{tag}_fold{fold}_best.pth").resolve())
})
summary_df = pd.DataFrame(summary)
summary_path = logs_dir / "cv_summary.csv"
summary_df.to_csv(summary_path, index=False, encoding="utf-8")
# 実験全体でのGPUピーク(fold/epoch全体の最大)
overall_gpu_peak = float(cv_df["gpu_peak_alloc_gb"].max()) if "gpu_peak_alloc_gb" in cv_df.columns else float("nan")
meta = {"encoder": tag, "gpu_env": gpu_env, "overall_gpu_peak_alloc_gb": overall_gpu_peak}
with open(logs_dir / "experiment_meta.json", "w", encoding="utf-8") as f:
json.dump(meta, f, ensure_ascii=False, indent=2)
print(f"📊 Summary: {summary_path}")
print(f"🧠 GPU env: {gpu_env} | overall_peak={overall_gpu_peak:.3f} GB")
return {
"encoder": tag,
"summary_csv": str(summary_path),
"cv_logs_csv": str((logs_dir / "cv_all_logs.csv").resolve()),
"cv_mean_plot": str(cv_plot),
"overall_gpu_peak_alloc_gb": overall_gpu_peak,
"gpu_env": gpu_env
}
# ========= 複数エンコーダでの一括実験(★ ループ実行) =========
def run_experiments(encoders, df_all: pd.DataFrame, out_root: Path):
results = []
for enc in encoders:
res = run_cv_experiment(enc, df_all, out_root)
results.append(res)
# 全実験まとめ
rows = []
for r in results:
sum_df = pd.read_csv(r["summary_csv"])
for _, s in sum_df.iterrows():
rows.append({
"encoder": r["encoder"],
"fold": int(s["fold"]),
"best_epoch": int(s["best_epoch"]),
"best_val_f1": float(s["best_val_f1"]),
"best_val_acc": float(s["best_val_acc"]),
"best_val_loss": float(s["best_val_loss"]),
"best_gpu_peak_alloc_gb": float(s["best_gpu_peak_alloc_gb"]),
"model_path": s["model_path"]
})
all_summary = pd.DataFrame(rows)
all_summary_csv = Path(PATH_OUTPUT) / "logs" / "experiments_summary.csv"
all_summary_csv.parent.mkdir(parents=True, exist_ok=True)
all_summary.to_csv(all_summary_csv, index=False, encoding="utf-8")
print(f"🧾 All experiments summary: {all_summary_csv}")
# 参考: エンコーダごとの Val F1 平均バー図
mean_by_enc = (all_summary.groupby("encoder")["best_val_f1"].mean()
.sort_values(ascending=False))
plt.figure(figsize=(8,4))
mean_by_enc.plot(kind="bar")
plt.title("Mean best Val F1 by encoder"); plt.ylabel("F1"); plt.grid(True, axis="y")
comp_plot = Path(PATH_OUTPUT) / "plots" / "encoders_valF1_comparison.png"
comp_plot.parent.mkdir(parents=True, exist_ok=True)
plt.tight_layout(); plt.savefig(comp_plot, dpi=150); plt.close()
print(f"📈 Encoders comparison plot: {comp_plot}")
return {"summary_csv": str(all_summary_csv), "comparison_plot": str(comp_plot)}
if __name__ == "__main__":
# ========= 実行例 =========
encoders_to_try = [
"efficientnet-b6",
]
OUT_ROOT = Path(PATH_OUTPUT)
results_all = run_experiments(encoders_to_try, df_all, OUT_ROOT)
print(results_all)モデルはUNetというセグメンテーションで定番のモデルを使用します。バックボーンは effcientnet-b6 という大きめの CNN(Convolutional Neural Network)を設定しています。画像サイズも 512×512画素のサイズの入力を使用するので計算量もそれなりに必要な構成にしました。
さらに、処理の経過時間がわかるように時間計測の処理も加えてみます。
# 時間計測開始
start_time = time.time()
!python train_exp1.py
# 時間計測終了
end_time = time.time()
elapsed_time = end_time - start_time
print(f"⏱ Total elapsed time: {elapsed_time:.2f} seconds")
# 分割と秒に変換
elapsed_minutes = elapsed_time // 60
elapsed_seconds = elapsed_time % 60
print(f"⏱ Total elapsed time: {int(elapsed_minutes)} minutes, {int(elapsed_seconds)} seconds")0%| | 0/2 [00:00 ========== [efficientnet-b6] Fold 1/2 ==========
[efficientnet-b6] Fold 1 Epoch 1/15 (device=cuda)
Train: loss=0.5391, acc=0.8271, f1=0.0257
Val: loss=0.4124, acc=0.9621, f1=0.0821 | GPU peak=18.176 GB
✅ Best updated: unet_efficientnet-b6_fold1_best.pth (val_f1=0.0821)
[efficientnet-b6] Fold 1 Epoch 2/15 (device=cuda)
Train: loss=0.3380, acc=0.9844, f1=0.2552
Val: loss=0.2820, acc=0.9872, f1=0.2920 | GPU peak=18.176 GB
✅ Best updated: unet_efficientnet-b6_fold1_best.pth (val_f1=0.2920)
[efficientnet-b6] Fold 1 Epoch 3/15 (device=cuda)
Train: loss=0.2310, acc=0.9916, f1=0.3458
Val: loss=0.1970, acc=0.9905, f1=0.2563 | GPU peak=18.176 GB
[efficientnet-b6] Fold 1 Epoch 4/15 (device=cuda)
Train: loss=0.1744, acc=0.9930, f1=0.4242
Val: loss=0.1566, acc=0.9908, f1=0.3191 | GPU peak=18.176 GB
✅ Best updated: unet_efficientnet-b6_fold1_best.pth (val_f1=0.3191)
[efficientnet-b6] Fold 1 Epoch 5/15 (device=cuda)
Train: loss=0.1372, acc=0.9933, f1=0.4698
Val: loss=0.1274, acc=0.9909, f1=0.3232 | GPU peak=18.176 GB
✅ Best updated: unet_efficientnet-b6_fold1_best.pth (val_f1=0.3232)
[efficientnet-b6] Fold 1 Epoch 6/15 (device=cuda)
Train: loss=0.1139, acc=0.9933, f1=0.5020
Val: loss=0.1113, acc=0.9880, f1=0.3086 | GPU peak=18.176 GB
[efficientnet-b6] Fold 1 Epoch 7/15 (device=cuda)
Train: loss=0.0944, acc=0.9945, f1=0.5494
Val: loss=0.0966, acc=0.9911, f1=0.2574 | GPU peak=18.176 GB
[efficientnet-b6] Fold 1 Epoch 8/15 (device=cuda)
Train: loss=0.0802, acc=0.9951, f1=0.5910
Val: loss=0.0833, acc=0.9903, f1=0.3612 | GPU peak=18.176 GB
✅ Best updated: unet_efficientnet-b6_fold1_best.pth (val_f1=0.3612)
[efficientnet-b6] Fold 1 Epoch 9/15 (device=cuda)
Train: loss=0.0696, acc=0.9951, f1=0.5941
Val: loss=0.0756, acc=0.9914, f1=0.2537 | GPU peak=18.176 GB
[efficientnet-b6] Fold 1 Epoch 10/15 (device=cuda)
Train: loss=0.0607, acc=0.9956, f1=0.5883
Val: loss=0.0687, acc=0.9902, f1=0.3330 | GPU peak=18.176 GB
[efficientnet-b6] Fold 1 Epoch 11/15 (device=cuda)
Train: loss=0.0546, acc=0.9953, f1=0.6138
Val: loss=0.0632, acc=0.9913, f1=0.2869 | GPU peak=18.176 GB
[efficientnet-b6] Fold 1 Epoch 12/15 (device=cuda)
Train: loss=0.0479, acc=0.9962, f1=0.6543
Val: loss=0.0570, acc=0.9910, f1=0.3595 | GPU peak=18.176 GB
[efficientnet-b6] Fold 1 Epoch 13/15 (device=cuda)
Train: loss=0.0429, acc=0.9962, f1=0.6192
Val: loss=0.0541, acc=0.9910, f1=0.3444 | GPU peak=18.176 GB
[efficientnet-b6] Fold 1 Epoch 14/15 (device=cuda)
Train: loss=0.0393, acc=0.9961, f1=0.6607
Val: loss=0.0535, acc=0.9911, f1=0.3304 | GPU peak=18.176 GB
[efficientnet-b6] Fold 1 Epoch 15/15 (device=cuda)
Train: loss=0.0359, acc=0.9963, f1=0.6551
Val: loss=0.0500, acc=0.9909, f1=0.3409 | GPU peak=18.176 GB
📄 Saved log: output/sakura_detection/exp1/logs/efficientnet-b6/fold1_log.csv
🖼 Saved plot: output/sakura_detection/exp1/plots/efficientnet-b6/fold1_curves.png
50%|██████████████████████ | 1/2 [02:53<02:53, 173.37s/it]
========== [efficientnet-b6] Fold 2/2 ==========
[efficientnet-b6] Fold 2 Epoch 1/15 (device=cuda)
Train: loss=0.3423, acc=0.9567, f1=0.0266
Val: loss=0.2588, acc=0.9903, f1=0.1940 | GPU peak=18.173 GB
✅ Best updated: unet_efficientnet-b6_fold2_best.pth (val_f1=0.1940)
[efficientnet-b6] Fold 2 Epoch 2/15 (device=cuda)
Train: loss=0.2150, acc=0.9891, f1=0.3182
Val: loss=0.1646, acc=0.9925, f1=0.3391 | GPU peak=18.173 GB
✅ Best updated: unet_efficientnet-b6_fold2_best.pth (val_f1=0.3391)
[efficientnet-b6] Fold 2 Epoch 3/15 (device=cuda)
Train: loss=0.1476, acc=0.9909, f1=0.4457
Val: loss=0.1206, acc=0.9924, f1=0.3505 | GPU peak=18.173 GB
✅ Best updated: unet_efficientnet-b6_fold2_best.pth (val_f1=0.3505)
[efficientnet-b6] Fold 2 Epoch 4/15 (device=cuda)
Train: loss=0.1094, acc=0.9920, f1=0.5065
Val: loss=0.0973, acc=0.9892, f1=0.3523 | GPU peak=18.173 GB
✅ Best updated: unet_efficientnet-b6_fold2_best.pth (val_f1=0.3523)
[efficientnet-b6] Fold 2 Epoch 5/15 (device=cuda)
Train: loss=0.0872, acc=0.9926, f1=0.5046
Val: loss=0.0787, acc=0.9927, f1=0.3020 | GPU peak=18.173 GB
[efficientnet-b6] Fold 2 Epoch 6/15 (device=cuda)
Train: loss=0.0708, acc=0.9936, f1=0.5536
Val: loss=0.0662, acc=0.9921, f1=0.3863 | GPU peak=18.173 GB
✅ Best updated: unet_efficientnet-b6_fold2_best.pth (val_f1=0.3863)
[efficientnet-b6] Fold 2 Epoch 7/15 (device=cuda)
Train: loss=0.0600, acc=0.9940, f1=0.5693
Val: loss=0.0580, acc=0.9926, f1=0.3838 | GPU peak=18.173 GB
[efficientnet-b6] Fold 2 Epoch 8/15 (device=cuda)
Train: loss=0.0503, acc=0.9948, f1=0.5875
Val: loss=0.0525, acc=0.9922, f1=0.4159 | GPU peak=18.173 GB
✅ Best updated: unet_efficientnet-b6_fold2_best.pth (val_f1=0.4159)
[efficientnet-b6] Fold 2 Epoch 9/15 (device=cuda)
Train: loss=0.0438, acc=0.9949, f1=0.6147
Val: loss=0.0493, acc=0.9928, f1=0.3621 | GPU peak=18.173 GB
[efficientnet-b6] Fold 2 Epoch 10/15 (device=cuda)
Train: loss=0.0374, acc=0.9951, f1=0.6468
Val: loss=0.0435, acc=0.9929, f1=0.3722 | GPU peak=18.173 GB
[efficientnet-b6] Fold 2 Epoch 11/15 (device=cuda)
Train: loss=0.0328, acc=0.9956, f1=0.6326
Val: loss=0.0399, acc=0.9915, f1=0.4418 | GPU peak=18.173 GB
✅ Best updated: unet_efficientnet-b6_fold2_best.pth (val_f1=0.4418)
[efficientnet-b6] Fold 2 Epoch 12/15 (device=cuda)
Train: loss=0.0297, acc=0.9958, f1=0.6561
Val: loss=0.0389, acc=0.9918, f1=0.4243 | GPU peak=18.173 GB
[efficientnet-b6] Fold 2 Epoch 13/15 (device=cuda)
Train: loss=0.0268, acc=0.9961, f1=0.7171
Val: loss=0.0413, acc=0.9893, f1=0.4146 | GPU peak=18.173 GB
[efficientnet-b6] Fold 2 Epoch 14/15 (device=cuda)
Train: loss=0.0248, acc=0.9961, f1=0.6745
Val: loss=0.0338, acc=0.9930, f1=0.4116 | GPU peak=18.173 GB
[efficientnet-b6] Fold 2 Epoch 15/15 (device=cuda)
Train: loss=0.0228, acc=0.9963, f1=0.6756
Val: loss=0.0339, acc=0.9919, f1=0.4350 | GPU peak=18.173 GB
📄 Saved log: output/sakura_detection/exp1/logs/efficientnet-b6/fold2_log.csv
🖼 Saved plot: output/sakura_detection/exp1/plots/efficientnet-b6/fold2_curves.png
100%|████████████████████████████████████████████| 2/2 [05:43<00:00, 171.94s/it]
✅ Completed [efficientnet-b6]. CV mean plot: output/sakura_detection/exp1/plots/efficientnet-b6/cv_mean_curves.png
📊 Summary: output/sakura_detection/exp1/logs/efficientnet-b6/cv_summary.csv
🧠 GPU env: {‘gpu_name’: ‘NVIDIA H100 80GB HBM3’, ‘total_mem_gb’: 79.109, ‘cuda_version’: ‘12.6’, ‘torch_cuda’: True} | overall_peak=18.176 GB
🧾 All experiments summary: output/sakura_detection/exp1/logs/experiments_summary.csv
📈 Encoders comparison plot: output/sakura_detection/exp1/plots/encoders_valF1_comparison.png
{‘summary_csv’: ‘output/sakura_detection/exp1/logs/experiments_summary.csv’, ‘comparison_plot’: ‘output/sakura_detection/exp1/plots/encoders_valF1_comparison.png’}
⏱ Total elapsed time: 349.56 seconds
⏱ Total elapsed time: 5 minutes, 49 seconds
GPUのメモリ使用量は、約18GBで合計の処理時間は、5分49秒です。
学習中のGPU使用率は 99% 以上を記録していたので、GPUを使い倒せていたかなと思います。
とはいえ、これは他のGPUと比較しないと高速なのかどうかがわかりません。
今回は、著者(安井)の身近にある GPU の2種類と同じコードで実験してみました。
使用した GPU は NVIDIA GeForce RTX 3090 と NVIDIA RTX A6000 です。どちらも当時はある程度高価で優秀なGPUです。時間の処理結果としては、表 1の通りです。
| GPU | 処理時間 | 合計メモリ |
|---|---|---|
| RTX 3090 | 13分59秒 | 24GB |
| RTX A6000 | 18分10秒 | 48GB |
| H100 HBM3 | 5分49秒 | 80GB |
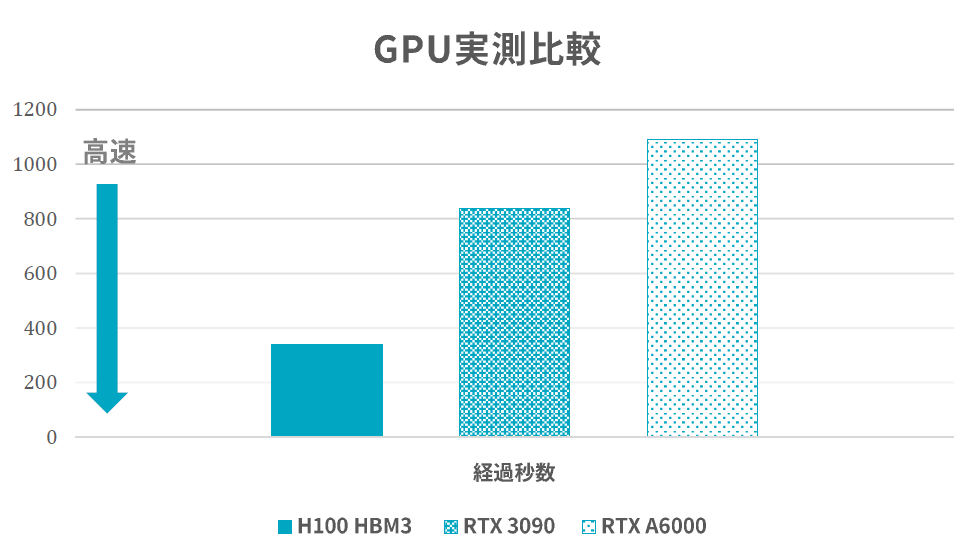
実測なのでGPUだけではなく、CPUやメモリの速度にも依存するので一概にはいえないですが、圧倒的な処理速度を提供してくれます。どの処理においても GPU使用率が99%以上だったのでGPUがボトルネックのコードになっています。よって、信頼性の高い結果ではないかと思っています。
さらに、3時間ほどGPUを600W以上で使用しましたがデバイス温度が10℃以上上がらないという冷却の安定さには驚きました。自宅だと30℃以上も温度が上昇してしまいます。さくらインターネットのインフラ基盤があるおかげですね。
高速処理がどれほどなのか、皆さんもぜひ体感してみてください。
(6)Tellus AI Playground で半歩先の性能
さて、H100 GPUの優位性の1つに速さを紹介しました。ここでは、その他にも有用な魅力を紹介致します。それは実験の可用性が上がることです。可能なことが増えることでモデルの精度向上や汎化性能の向上、また動かせるモデルも増えるようになります。
本検証での評価指標はF1スコアを採用しています。理由としては、桜のアノテーションは桜の咲いていない領域に対してとても少ないです。そのような時に全て桜ではないと答えると元々が桜でない状態なのでほとんどなために、ほぼ正解であると判断されてしまいます。このような桜の有無が画像内で不均衡な状況は単純精度では判断しにくいからです。F1スコアは 0~1の範囲で大きいほど良い指標です。衛星画像でもしばしば、F1スコアが採用されることが多い印象です。この評価指標に対して、GPUメモリを大きくしてみて簡単な実験をしてみたいと思います。

以前の実験ではこのような指標の推移になっています。
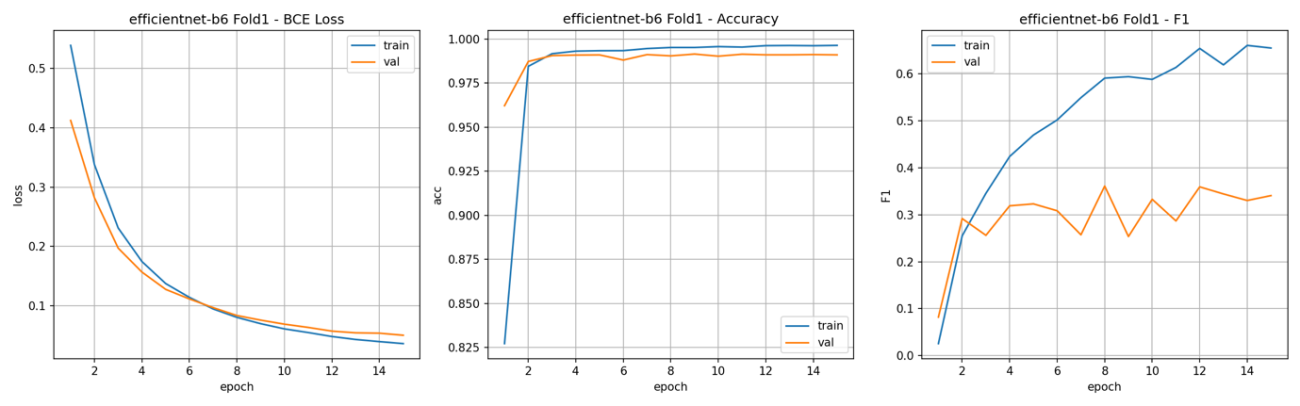
左: 損失値(ブルー:学習, オレンジ:検証)
中央:単純精度(ブルー:学習, オレンジ:検証)
右:F1スコア(ブルー:学習, オレンジ:検証)
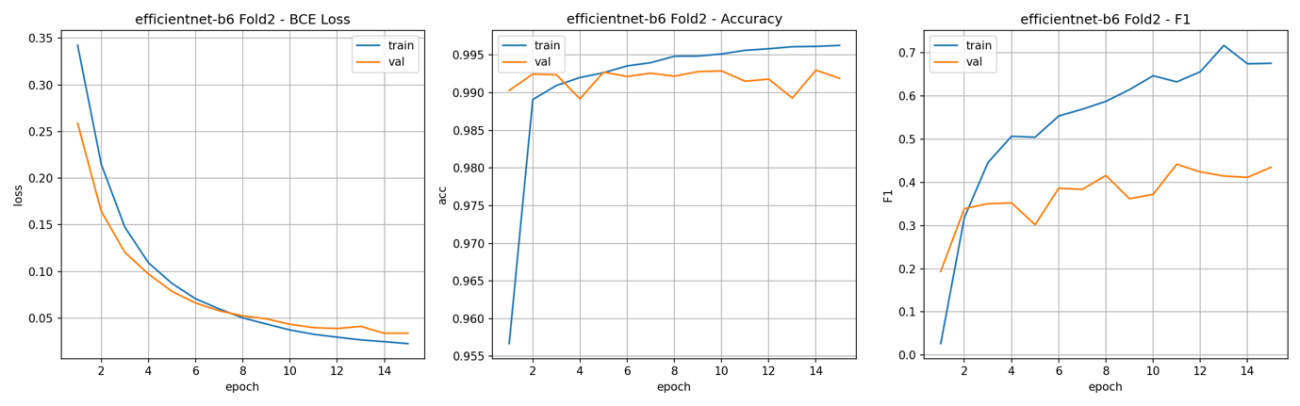
左: 損失値(ブルー:学習, オレンジ:検証)
中央:単純精度(ブルー:学習, オレンジ:検証)
右:F1スコア(ブルー:学習, オレンジ:検証)
H100 GPU によってメモリサイズが大幅に拡大したので、モデルを学習する際にSGDによるランダムサンプリングしてくる時のバッチの数が増やせるようになります。いわゆる、バッチサイズを増やすことが可能です。
このバッチサイズは、データの特性やモデルによって、最適な数にばらつきがあります。似たようなことでは、SyncBatchNormでもそれぞれのGPUで正規化するのと、1つのGPUでBatchNormするのでは精度が変化します。
正規化に影響するバッチサイズはとても重要です。例えば、一般的にバッチサイズを大きくし過ぎると検証性能は低下しますが、モデルの学習が収束するのは高速になります。
そこで、対策としては線形スケールに学習率(Learning Ratio)を大きくして探索範囲を広げるなどをして精度を担保します。他にも、不均衡なサンプリングはモデルの学習を非常に不安定にさせます。本記事のデータのようにネガティブサンプルが多い場合は学習に失敗することがあります。
では、H100 GPUの80GBのメモリを活かした大きなバッチサイズで学習をしてみて精度指標の比較をしてみたいと思います。実験するバッチサイズは、速度検証で用いた8から、16、32まで大きくすると共に学習率も線形スケール倍してみます。
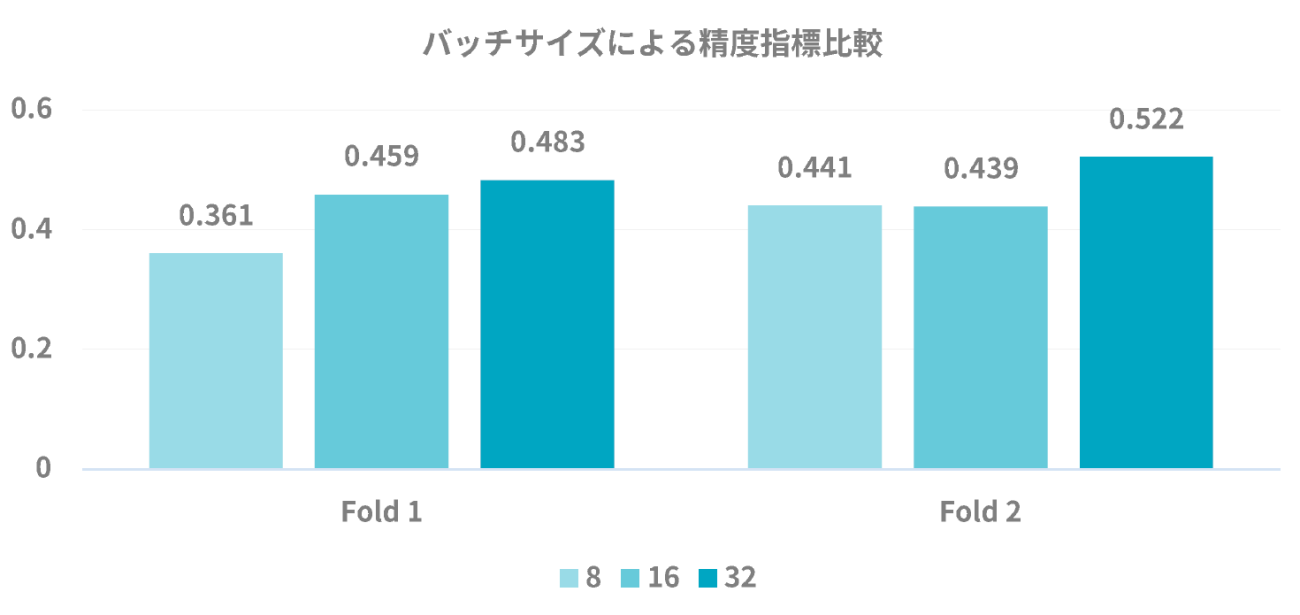
図 21のようにバッチサイズと学習率を共に線形的に増やしていく方が精度指標ではよくなっています。
一方でGPUメモリはどれくらい使用しているのでしょうか。それぞれのGPUごとの最大時のメモリ使用率を図 22では、表にしています。
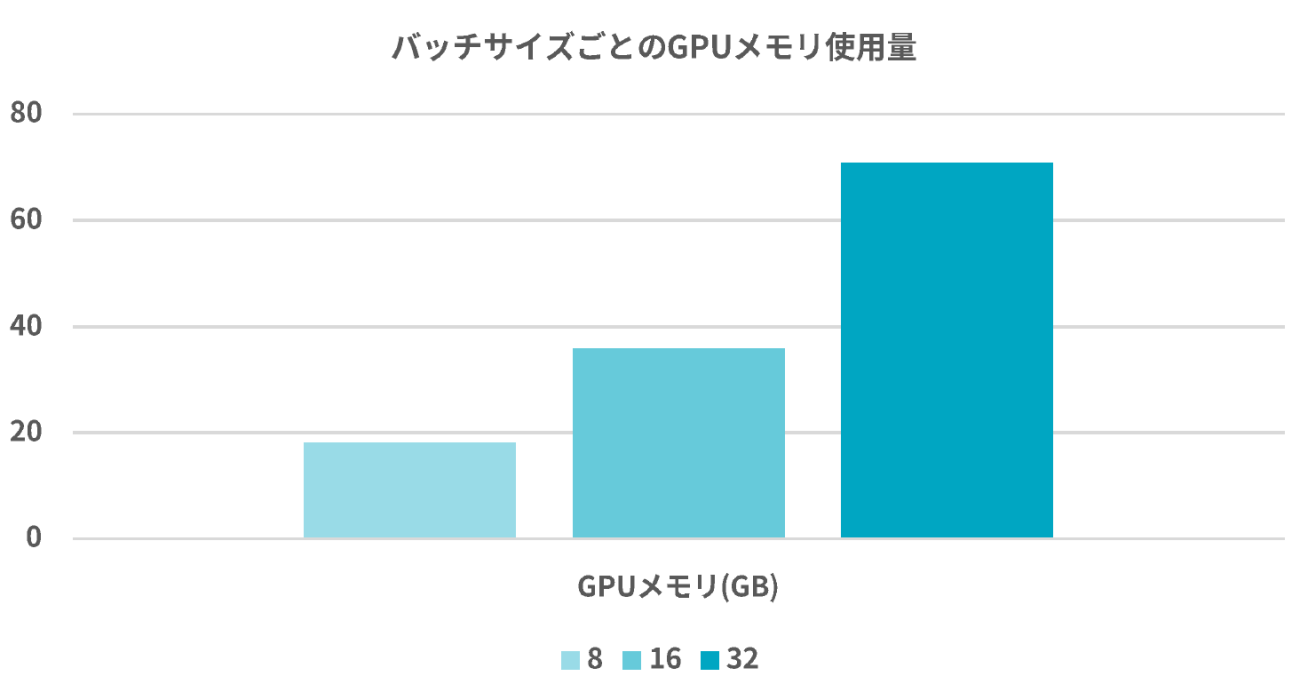
16バッチサイズでの 35GB程度が個人で扱えるGPUの限界だと思いますので、H100 GPUでの精度は企業レベルでの精度と言っても過言ではないでしょう。
また、今回の結果は不均衡が原因とも限らず、バックボーンに選択したモデル自体が大きいのでバッチサイズの拡大で正規化が強く働いただけかもしれません。
実験中のメトリクスの変化の詳細なプロットも掲載しておきます。Fold12の平均値を集計しています。
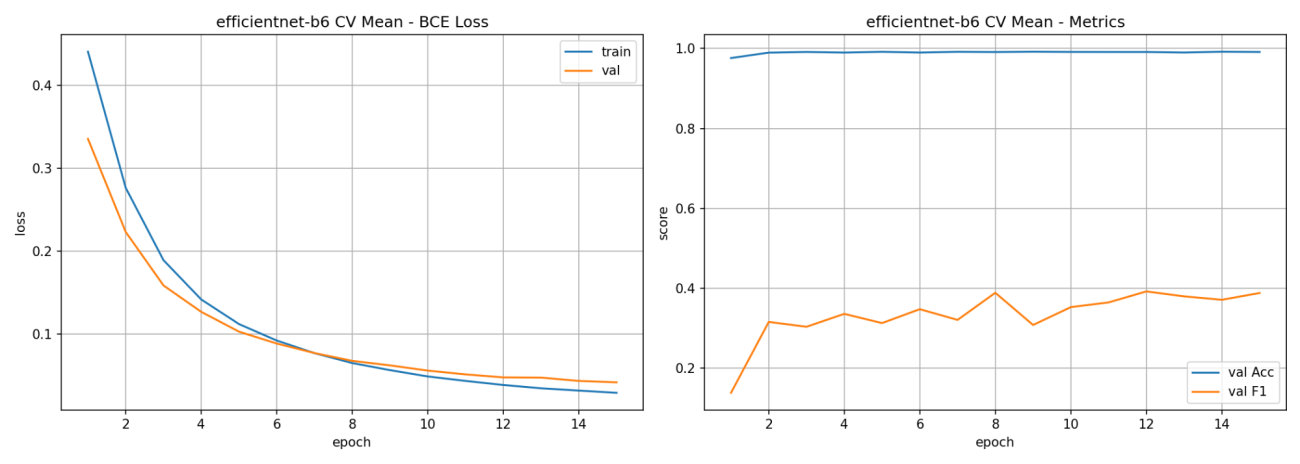
左:損失値(ブルー:学習, オレンジ:検証)
右:検証時の指標比較(ブルー:単純精度, オレンジ:F1スコア)
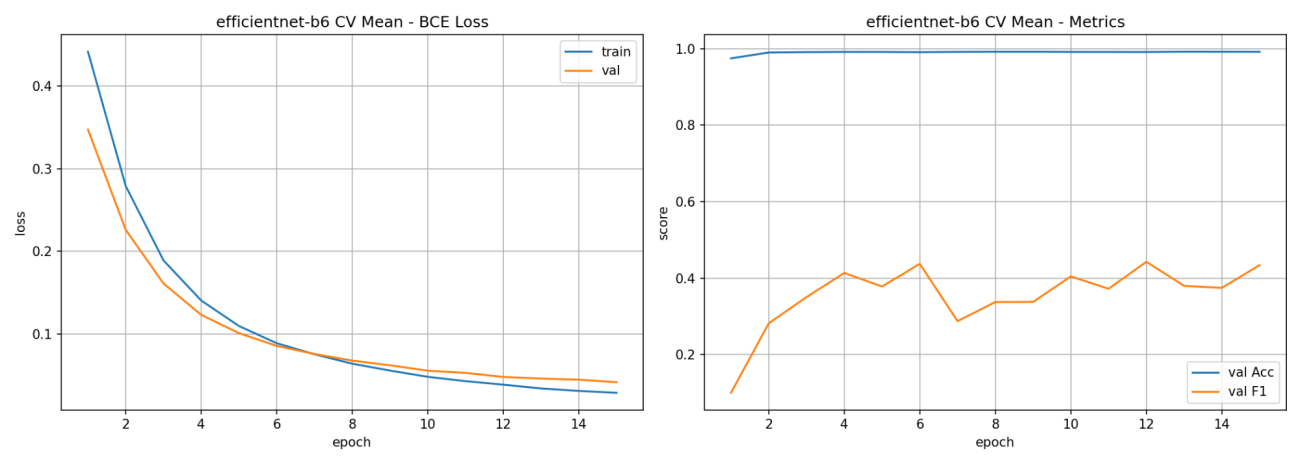
左:損失値(ブルー:学習, オレンジ:検証)
右:検証時の指標比較(ブルー:単純精度, オレンジ:F1スコア)
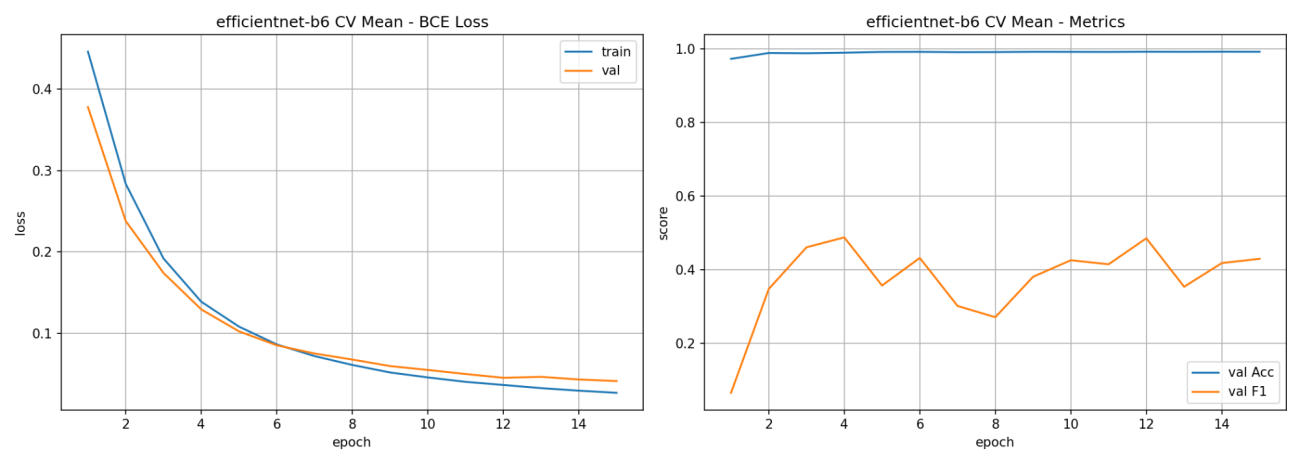
左:損失値(ブルー:学習, オレンジ:検証)
右:検証時の指標比較(ブルー:単純精度, オレンジ:F1スコア)
本記事での実験は、セグメンテーションのタスクを行いました。それ以外にも、基盤モデル、GANなどの学習にはGPUメモリのサイズはとても影響します。特に学習時の安定性には重要視されています。バッチサイズが小さいと学習が進みづらく、実験回数も稼げないために非効率になることが悩みになってきます。計算資源が取り合いの時代だからこそです。
加えて、バッチサイズだけではなく、大規模言語モデル(LLM)や生成AIでは、モデル本体のパラメーター数が多く、GPUメモリを多く使用します。近年では、メモリが小さくても処理できるように分割して処理するライブラリが増加はしているもののGPUメモリが大きいことに越したことはありません。
基盤モデルや生成AIで登場するTransformerは、その自己注意機構の計算量が入力トークン数の二乗に比例する(O(N^2))という特性から、高解像度画像に対して計算量が爆発的に増加する問題を抱えています。入力解像度を2倍にするだけで計算量が16倍になる問題は、ViT(Vision Transformer)を高解像度画像に適用する上での最大の障壁でした。H100に搭載された「Transformer Engine」は、この課題に対するNVIDIAの革新的な解答です。この専用エンジンは、ViTをはじめとするTransformerアーキテクチャの計算をハードウェアレベルで最適化してくれます。
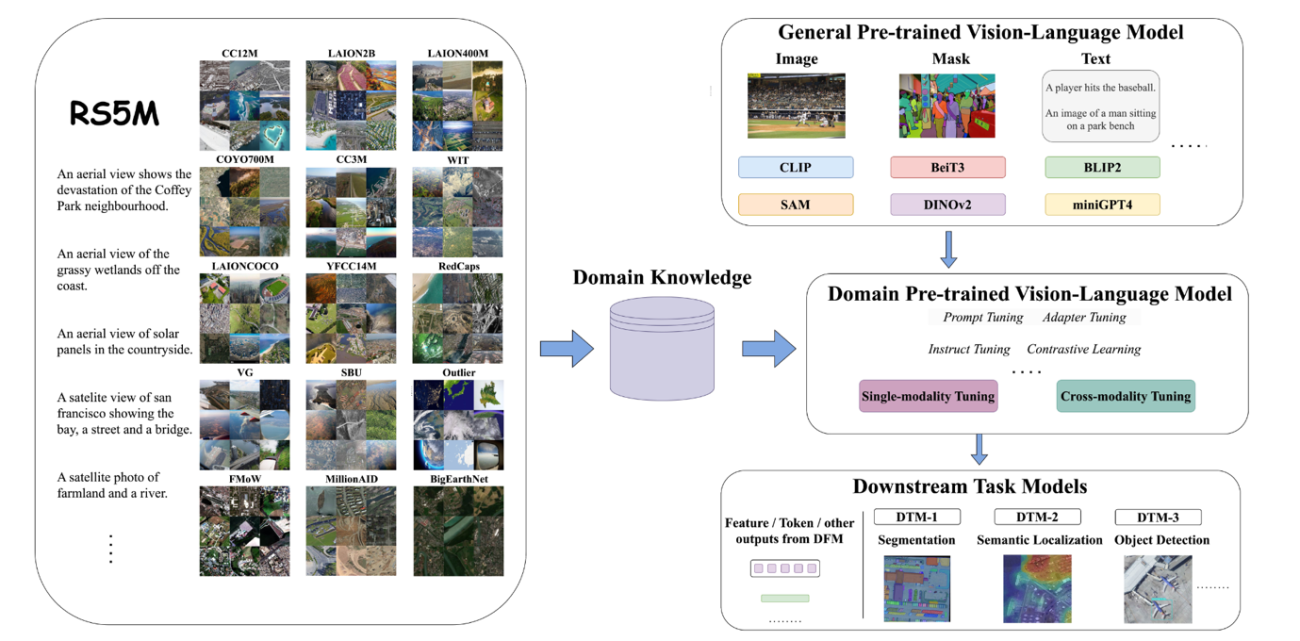
基盤モデルや生成AIは衛星画像とも相性が良く、多くの研究やソリューションが生み出されています。
IBM と NASA の「Largest Geospatial AI」とは? 複数衛星のデータ融合と衛星基盤モデルによる先端技術の利用とその Python実装
(7)Tellus AI Playgroundの展望と利用メリット
この Tellus AI Playground は衛星データを拡充させていく予定です。現状は、デフォルトでSentinel-2が格納されているのみですが商用衛星も追加していきます。もちろん、今まで通り Tellus APIで衛星データを Tellus AI Playground 環境にダウンロードすることも可能です。
そして、サービスのビジネス的な差別化ポイントは、大きく「戦略」と「基盤技術」の二層で説明できると考えます。
まず戦略面では、衛星データの利用を特定分野に閉じず、研究・行政・民間の多様なユースケースを横断的に受け入れる“オープンプラットフォーム”を志向している点が特徴です。
多くの先行事例が特定領域に最適化した垂直統合型の体裁をとるのに対し、同社は用途の想定を狭めず、ユーザーが自らの課題定義に合わせて機能を組み合わせられる設計思想を採用しています。これにより、新規事業の検証から本番運用、さらには研究開発用途に至るまで、利用フェーズに応じた拡張がしやすい柔軟性を提供します。
次に競合状況を俯瞰すると、例えば「Google Earth Engine(GEE)」のように豊富なデータアーカイブを備えたグローバルな標準的基盤が存在し、国内でも特定テーマに特化したサービスが徐々に増えています。
三菱電機などが出資する衛星データサービス企画(Satellite Data Servies; SDS)のように、産業セグメントや利用目的を明確に絞るアプローチは、導入効果を素早く打ち出せる一方、汎用性や横展開に制約が生じやすい側面があります。
これに対しTellusは、はじめから用途を限定しないことで、ユーザー側の発想や既存システムとの統合余地を最大化しようとしています。ユースケースの発見は現場から生まれるという前提に立ち、上流の探索段階での自由度と、下流の運用段階での拡張性を両立させる設計です。
この“オープン”の意味は、単なるアクセス開放やAPI公開に留まりません。データ取り込み、前処理、解析、学習、推論、可視化といったパイプラインをモジュール化し、ユーザーが自分のワークフローに合わせて差し替え・増補できること、外部のOSSや既存の地理空間基盤(STAC/OGC準拠のカタログやタイル配信など)と互換性を担保することまで含んでいます。
必要なところだけを置き換えることや段階的に高度化できる選択肢が広がります。
技術面の差別化では、実行基盤として国産クラウドを中核に据えている点が顕著です。
多くの競合が海外事業者のクラウド上で稼働するなか、Tellusはさくらインターネットが基盤技術を支え、データ主権や法規制順守、機密区画での運用など、日本国内の厳格な要件に応えやすい構成を優先しています。
これは、安全保障や公共性の高い案件、自治体の災害対応、重要インフラの保守監視といった領域で、データ所在や運用プロセスを国内に閉じたいというニーズに適合しやすいという意味を持ちます。運用面でも、国内タイムゾーンでのサポート、インシデントレスポンスの即応性、調達・審査における説明容易性などが、ユーザーの安心材料として作用します。
(8)まとめ
新しい Tellus AI Playground のサービス紹介から簡単なチュートリアルや実験までまさに AI で遊びつくす内容でした。衛星データxAIで環境をお悩みでしたらぜひ、ご検討してみてはいかがでしょうか?
宙畑では、衛星データの発展や宇宙領域の促進を応援しております!
今回ご紹介したTellus AI Playgroundは以下のサイトから申込いただけます。
https://ai-playground.tellusxdp.com/
【参考文献】
・Goyal, Priya, et al. “Accurate, large minibatch sgd: Training imagenet in 1 hour.” arXiv preprint arXiv:1706.02677 (2017).
・Hoffer, Elad, Itay Hubara, and Daniel Soudry. “Train longer, generalize better: closing the generalization gap in large batch training of neural networks.” Advances in neural information processing systems 30 (2017).
・https://github.com/NVIDIA/TransformerEngine
・Gao, Fengli, and Huicai Zhong. “Study on the large batch size training of neural networks based on the second order gradient.” arXiv preprint arXiv:2012.08795 (2020).
・Li, Shuaipeng, et al. “Surge phenomenon in optimal learning rate and batch size scaling.” Advances in Neural Information Processing Systems 37 (2024): 132722-132746.
・Lau, Tim Tsz-Kit, et al. “Adaptive Batch Size Schedules for Distributed Training of Language Models with Data and Model Parallelism.” arXiv preprint arXiv:2412.21124 (2024).
・https://techblitz.com/startup-interview/tellus/
・Smith, Samuel L., et al. “Don’t decay the learning rate, increase the batch size.” arXiv preprint arXiv:1711.00489 (2017).
・Smith, Samuel L., Pieter-Jan Kindermans, Chris Ying, and Quoc V. Le. “Don’t Decay the Learning Rate, Increase the Batch Size.” International Conference on Learning Representations (ICLR) 2018, 2018.
・https://www.nvidia.com/ja-jp/data-center/h100/
・https://jupyter.org/
・Zhang, Zilun, et al. “Rs5m and georsclip: A large scale vision-language dataset and a large vision-language model for remote sensing.” IEEE Transactions on Geoscience and Remote Sensing (2024).
