The 3rd Tellus Satellite Challenge実施!~入賞者たちのモデルに注目~
Tellus Satellite Challengeの第3弾「海氷領域の検知」が行われました。本記事では、その概要を解説し、入賞者のアプローチを紹介します。
(1)「Tellus Satellite Challenge」とは?
「Tellus」は、産業利用を目的とした衛星データプラットフォーム。日本政府の「宇宙産業ビジョン2030」が掲げる「2030年代早期に宇宙産業全体の市場規模の倍増する」という目標に向けて立ち上げられた事業です。このTellus事業の一環として、衛星データの利活用事例の可視化、優秀なデータサイエンティストの発掘、衛星データの周知・啓蒙、Tellusの利活用促進を目的としたデータ分析コンテスト「Tellus Satellite Challenge」が実施されています。
過去2回のTellus Satellite Challengeでは、それぞれ
をテーマとしたコンテストが実施され、その成果は以前の記事にて紹介しました(第1回、第2回)。


これらのチャレンジでは世界中のAI人材が参加し、SARや高解像度光学データを用いた課題に挑戦。衛星データ活用のベストプラクティスが得られました。
そしてこの度、Tellus Satellite Challengeの第3弾「海氷領域の検知」が行われました。以下では、チャレンジの趣意と入賞者のアプローチについて解説していきます。
記事執筆協力:齊藤 秀(SIGNATE)、青井紀之(SIGNATE)
(2)第3回チャレンジのテーマ
第3回のテーマは「SARデータを用いた海氷領域の検知」です。
毎年、北海道オホーツク海のあたりには流氷があらわれます。美しい流氷は観光資源として活用され、流氷ツアーなどで有名ですね。一方で、漁業や海運業にとっては、その存在は事故につながるリスクでもあり、流氷がどこにあるのかを常に把握しておく必要があります。
そこで、第一管区海上保安本部(海上保安庁)は、北海道周辺海域の海氷(流氷を含む海上の氷)の状況を速報として1日1回配信しています。海氷の把握は、航空機、巡視船艇による海氷観測、人工衛星による海氷観測画像の解析を組み合わせて実施されます。なかでも人工衛星は、一度に広範囲の海面の様子を把握でき、しかも合成開口レーダー(SAR)により昼夜・天候によらずに観測できることを強みとします。
しかし、SARデータからの海氷領域の判読には高度なスキルを要するのが実情です。そこで、今回のチャレンジでは、SARデータから海氷領域をより高い精度で検知するアルゴリズムの開発を目指します。
使用するデータは、北海道周辺海域における陸域観測技術衛星2号「だいち2号」(ALOS-2)搭載のPALSAR-2による観測データです。PALSAR-2は、電波を地表面に照射し、地表面から反射される電波を受信することで情報を得る、合成開口レーダ(SAR)と呼ばれるセンサです。SARは、昼夜を問わず、また天候によらず撮影できるのが特長です。詳細はこちらの記事(SIGNATE「衛星画像を用いた海氷検知」コンペ、その目的と画像のポイント)を参照ください。
本チャレンジにより、以下のことが見えてくると期待されます。
●専門家による高度な判読を、AIでどの程度支援可能になるのか?
●地上における海氷観測データを使用せずに、衛星データのみでどのレベルで判定が可能なのか?
第3回チャレンジには、2019年10月4日から11月30日までの実施期間を通して557人が参加し、応募されたモデルは2,074に上りました。難易度の高いチャレンジでしたが、多数のハイレベルなAIが集まりました。1位から10位のうち7チームは海外からの参加者が占めるという、国際的な闘いともなりました。
(3)課題概要
今回のチャレンジでは、IoU(intersection over union)という評価指標が用いられました。これは、正解の海氷領域をどれだけはみ出さずに覆えたかを表す指標です。0から1までの値をとり、正解の領域とピッタリ一致すれば1になります。IoUが大きいほど精度が高いことを表します。
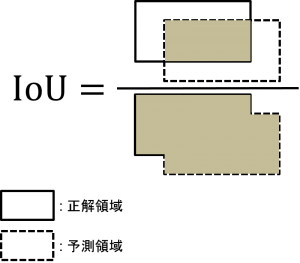
IoUは、今回のようなセグメンテーションタスクでよく使われる指標です。ずれに敏感な指標として知られており、微妙なずれによって数値が比較的大きく変わってしまうという特徴があります。高いIoUスコアを出すためには、海氷領域の微妙な曲がり具合なども捉える必要があります。目安として、0.8以上あればかなり高精度といえます。

学習用データとして80シーンが提供され、それぞれのシーンに対してSAR画像の種類であるHH偏波画像とHV偏波画像が与えられます。これらの画像には、ピクセル単位でラベル付け(アノテーション)がなされています。
ラベルは全部で7種類あり、海氷密度レベル別に、0(海氷なし)、1(海氷密度レベル1-3)、4(海氷密度レベル4-6)、7(海氷密度レベル7-8)、9(海氷密度レベル9-10)、11(湖)、12(陸)となっています。このうち、ラベル1、4、7、9の領域が海氷領域と定義されています。
評価用データとして40シーンが提供され、学習用データと同様に、HH偏波画像とHV偏波画像が与えられます。
(4)課題のポイント
この課題では2つのポイントがあげられます。
まず、1枚の画像サイズが非常に大きいことです。一辺が10,000ピクセル以上あり、そのままモデルに入力することは困難なため、モデルサイズが小さくても済むような工夫が必要となります。
もう一つはコントラストの低さです。見ていただければわかる通り、HH偏波画像もHV偏波画像も全体的に暗く、肉眼では海氷領域がわかりづらくなっています。そこで、機械学習モデルを上手く構築して、SARにおける海氷領域の微妙な特徴を捉えなければなりません。そのためには、HH偏波とHV偏波の特性を考慮した画像への前処理などの工夫が必要となってきます。
(5)入賞者の傾向
それでは、入賞者のアプローチを見ていきましょう。
入賞者のアプローチにはいくつかの共通点がありました。たとえば、
- ●ダウンスケール
- ●スライディングウィンドウ
- ●ラベル画像の二値化
- ●高精度なセグメンテーションモデルに対するImageNetによる転移学習
- ●アンサンブル
などの手法が多く用いられていました。
画像のダウンスケールは、データがもつ細部の情報を多少捨てることになりますが、細部に含まれるノイズを除去するという意味があります。一方、スライディングウィンドウの利用には、細部の情報も使いつつ、モデルサイズをある程度小さくとどめるという効果があります。
ラベル画像の二値化は、7段階の海氷密度レベルを認識する問題を、より単純な海氷領域を認識する問題に置き換えることに相当します(そもそも海氷領域の検知ができればよいので、自然な処理だと言えます)。
今回は学習用データが80シーンと少なかったため、ImageNetによる転移学習を適用する入賞者が多く見られました。そこでは、SOTA(state of the art)なセグメンテーションモデルが用いられました。そして、精度をさらに向上させるため、アンサンブルを用いる傾向も見られました。
以下、前処理、モデリング、後処理の観点に着目し、各入賞者のアプローチをそれぞれ見ていきたいと思います。
(6)各入賞者のアプローチを詳しく解説(前処理)
まずは前処理の方法です。
1位の入賞者はダウンスケールを行っていますが、元の画像サイズとそこまで違わない8192×8192としていました。スライディングウィンドウも併用し、ウィンドウをスライドさせつつ、2048×2048にクロッピングした画像を生成し、512×512と1024×1024にダウンスケールした画像を作成していました。画像の情報を落とさずに、なるべく細部まで認識しようという工夫がうかがえます。
また、HH偏波画像とHV偏波画像の幾何平均をとった画像を新たに作り、3チャンネル画像を生成していました。検証の結果、幾何平均をとった画像を加えたほうが算術平均をとった場合よりも精度が良くなったそうです。3チャンネルとしたのは、後のモデリングでImageNetによる転移学習を行うためでもあります。ImageNetはRGB画像なので、それに合わせた形です。
一方2位の入賞者は、画像を0.25倍にダウンスケールし、スライディングウィンドウも併用し、512×512にクロッピングした画像を生成していました。
これは1位に比べるとかなり大胆なダウンスケールです。細部を認識することは多少あきらめつつ、ノイズの除去を狙ったようです。1位の方と同様に3チャンネル画像を生成していましたが、この方はHH偏波画像とHV偏波画像の算術平均をとった画像を加えていました。
3位の方は2048×3008にダウンスケールを行っていて、スライディングウィンドウは併用していませんでした。これには誤検知を少なくする意図もあったと思われます。1位、2位と同様に3チャンネル画像を作成していましたが、3人の中では一番シンプルにHH偏波画像2枚とHV偏波画像1枚によって作成していました。
1位と3位は予測時に上下反転や左右反転させた画像を水増ししていましたが、2位は行っていませんでした。

(7)各入賞者のアプローチを詳しく解説(モデリング)
続いてモデリングです。
1位は、HighResolutionNetというSOTAなセグメンテーションモデル4つとUNet(encoderはEfficientNet)8つの合計12個の深層学習モデルを用いており、ImageNetによる学習済みモデルによって転移学習を行っていました。UNetは学習条件に応じて2種類作っていたので、実質的に3種類のモデルを作成していたことになります。HighResolutionNetとUNetのネットワーク構造を以下に示しておきます。
HighResolutionNetは、4ステージ4並列のサブネットワークです。1xの解像度 (HR) を持ったfeature mapが常に伝播し、他のスケールのfeature mapと相互作用する設計となっています。これは、高解像度から始まり徐々に低解像度のサブネットワークを加えていく構造です。最終層では4スケールが出力されますが、最も精度の高い1xの出力のみが使用されます。詳しくはhttps://arxiv.org/abs/1908.07919を参照してください。
UNetは主に医療分野の画像認識などで使われる深層学習モデルで、スキップコネクションをもつのを特徴とし、畳み込みやプーリングの過程で失われる位置情報が保存されるようになっています。「UNet」という名前は見た目がU字となっていることに由来するそうです。詳しくはhttps://arxiv.org/abs/1505.04597を参照してください。
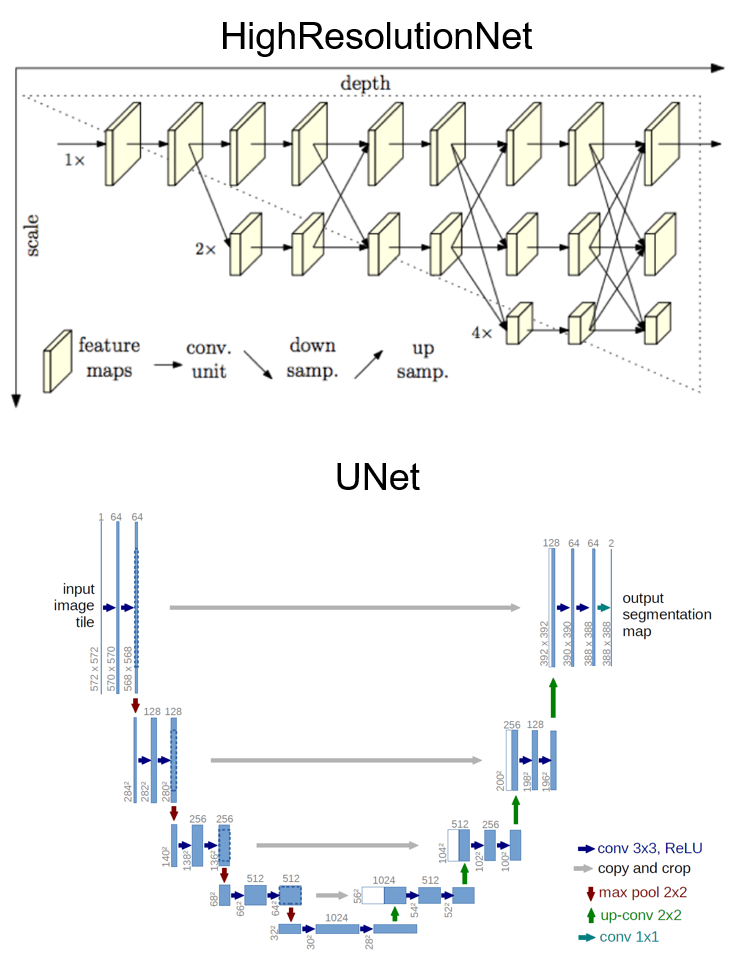
1位の方はHighResolutionNetに対しては512×512の画像を、UNetに対しては1024×1024の画像を入力していました。つまりHighResolutionNetでは大雑把に、UNetでは細かく見ることを選択したようです。
一方2位の方はUNetを使い、encoder別に3種類のモデル(ResNext101、Senet154、Dpn92)を用いていました。1位と同様にImageNetによる学習済みモデルによって転移学習を行い、さらに5-fold分の学習パターンを作って学習させることで合計3×5=15個のモデルを作成していました。これはバギングと呼ばれるテクニックで、よく用いられます。予測時の画像データ水増しを行っていないぶん、モデルの数を多くしたのだと思われます。
3位は2位と同様、UNetを用いており、encoder別に2種類のモデル(DenseNet161とDpn92)を用いていました。やはりImageNetによる学習済みモデルによって転移学習を行っていました。4-fold分の学習パターンを作り学習させて合計2×4=8個のモデルを作成していました。
3者とも、かなり重いモデルを複数個学習させているので、相当のマシンパワーが必要だったことがうかがえます。いずれにせよ、入賞者の方々は先進技術をキャッチアップしたうえで、今回のチャレンジに応用されていました。
(8)各入賞者のアプローチを詳しく解説(後処理)
最後に、モデルが出力した結果を集約する後処理の工程です。
まず1位はモデルの種類ごとに平均で集約し、3つの結果を得たあと、これらの重み付き平均をとったものを最終的な結果としていました。この重みは検証によって最適化していました。一方で2位と3位は単純に平均をとった値を最終的な結果としていました。
結果を詳しく見ていきましょう。まず精度の比較です。
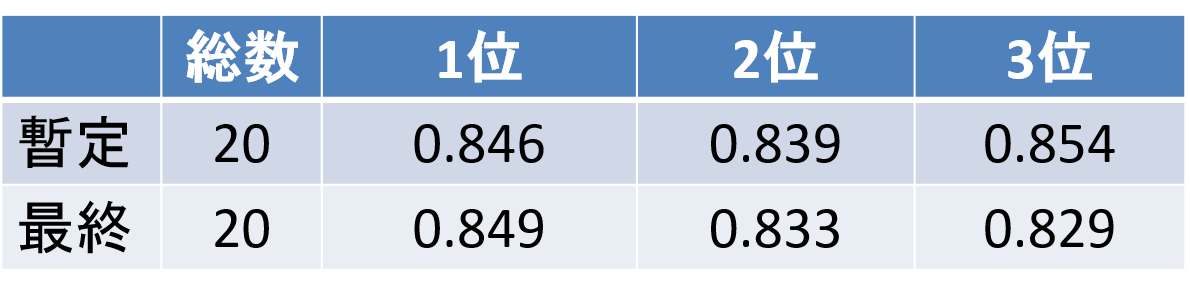
「暫定」と「最終」は、それぞれコンテスト期間中のスコアとコンテスト終了後のスコアです。評価用データを2つに分けて、それぞれ暫定評価用と最終評価用としていました。3者とも0.8を超えており、これはかなりの高精度だといえます。
1位~3位はほぼ横一線で接戦でしたが、暫定では3位がトップでした。暫定と最終を比べてもほぼ変わらないスコアとなっているので、いずれも汎化性能が高いモデルだったことがわかります。SOTAな深層学習モデルを複数アンサンブルしたことがやはり効いたと思われます。そんな中、入賞者の間では、重み付き平均の重みを最適化し、入力画像生成の工夫の仕方などをしっかり検証した1位に軍配が上がった形となりました。
次に、それぞれのIoU値の分布を見てみたいと思います。
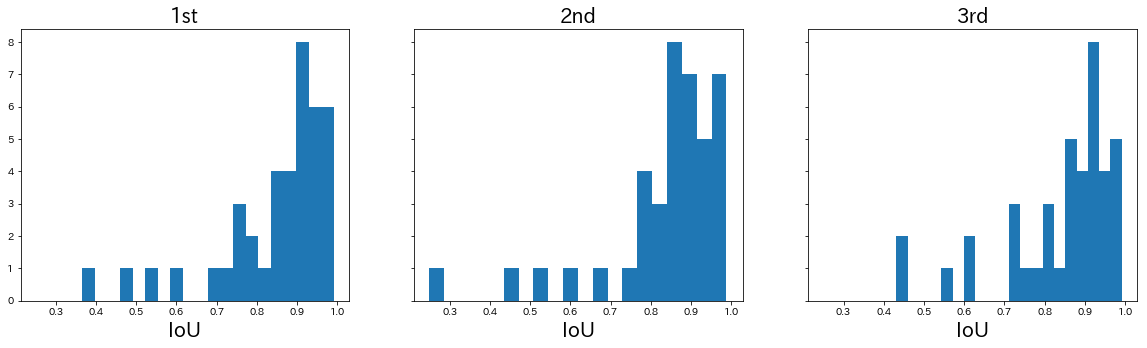
概ね同じような分布であったのがわかります。半数以上は0.8以上でしたが、0.5以下の認識が難しかった例が1、2個あったのがわかります。
では実際にそれぞれの出力結果をいくつか見てみたいと思います。まず、下図はIoU値が0.95以上のほぼ完璧に正解できた例です。
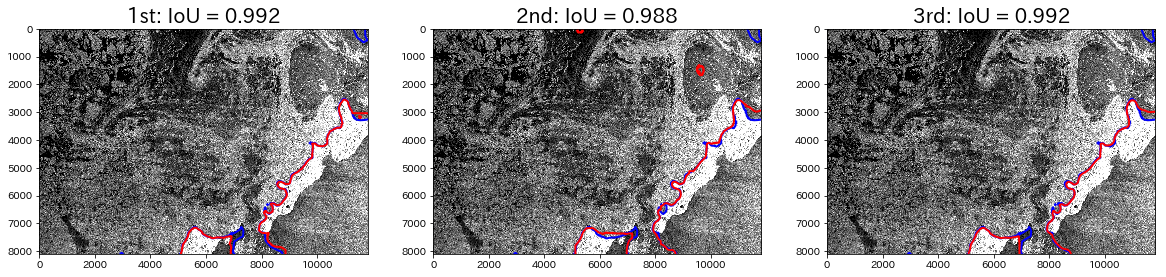
赤色が予測領域の境界線で、青色が正解領域の境界線です。ややわかりづらいですが、左上の領域が海氷領域で、右下の白い部分が島です。境界がほぼ一致しているのがわかります。
次に、IoU値が0.86くらいの例を見てみます。
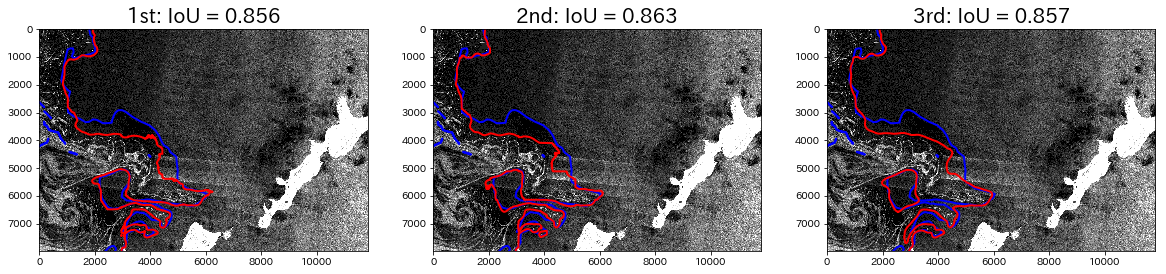
これは左側の領域が海氷領域です。ほぼ形はとらえていますが、未検出の領域が存在します。次に、IoU値が0.6以下の例をいくつか見てみます。


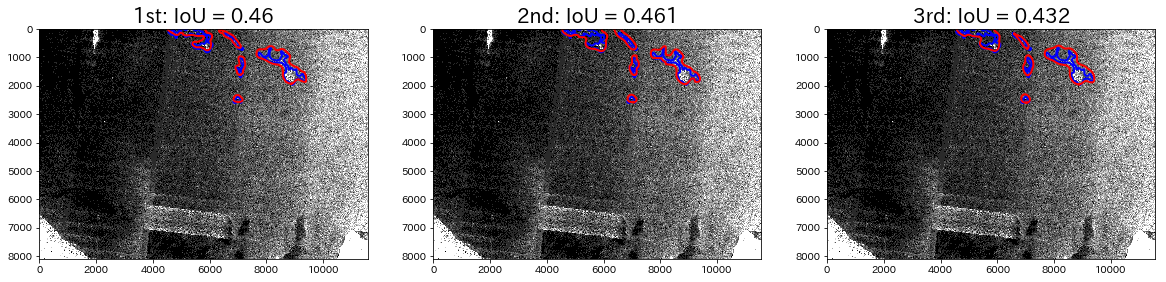
全体的に正解領域の面積が小さく、形も曲がりくねっているので、確かに難しそうです。
上手の1行目の例を見ると、全員大まかに形はとらえていますが、特に1位と2位の結果が類似しており、誤検出が目立ちます。1位と2位はスライディングウィンドウを適用しているため、誤検出が多くなってしまったと思われます。3位はダウンスケールをしているだけなので、誤検出は比較的少なかったようです。
一方で、2行目と3行目上の例を見ると、1位と2位は比較的細部まで形を捉えていますが、3位は大雑把にしか形を捉えられていません。これらの例に関しては、スライディングウィンドウを用いたかどうかで差がついたようです。
総合すると、スライドウィンドウによって細部を捉えた1位と2位が若干リードして勝ったようです。正解領域の面積が小さいと認識が難しい傾向がありそうです。そこで、入賞者全体における正解面積とIoU値の関係を見てみたいと思います。
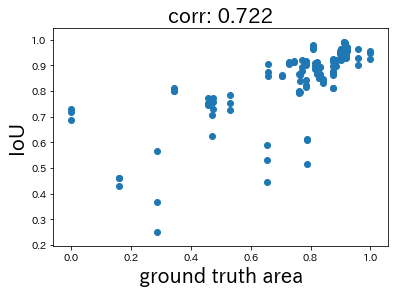
横軸は正解面積の対数をとり、正規化の処理を加えた値です。相関係数は0.722となり、正の相関が認められました。やはり正解領域の面積が小さいほうが認識することが難しい傾向があるようです。誤検出する確率が高くなり、海氷領域もわかりづらくなるためだと思われます。
(9)コンテスト全体の総評
結果としては、入賞者全員が0.8以上の高スコアを出すという、ハイレベルな戦いとなりました。ベースとなる方法はほぼ共通しており、SAR画像に対する最適な深層学習モデリングのアプローチが見えたのではないかと思います。
今回のコンテストで使ったSAR画像は元々16ビットでしたが、データ容量の関係で8ビットに落として使いました。8ビットにしたことで、いくらか情報が失われてしまったので、16ビットのままにしたほうが認識することが難しかった例のスコアも上がり、さらに高い精度になった可能性があります。
入賞者たちからは「データの質が高かった」、「非常に楽しかった」、「次のコンテストが開催されれば参加したい」などのコメントをいただきました。優れた結果が得られただけでなく、Tellusのさらなる普及につながる有意義なコンテストになったのではないかと思います。
