データ数の少ない衛星データに対応!人工合成データを用いた機械学習論文解説
衛星データはデータ数が少ない。そんな問題に対応すべく人工的に教師画像とアノテーションを作るという方法を衛星画像に適用した事例をご紹介します!
「最近”衛星データ” × ”機械学習”ってよく耳にするし、自分もTellusの解析環境上で機械学習のモデルを学習してみたい…。」と思っている方もいらっしゃるのではないでしょうか?そんな時に必要になってくるのが、「教師データ」ですよね。
現在、機械学習で主流となっているConvolutional Neural Network(CNN)を用いるには、アノテーション(教師ラベルの付与)がなされた大量の教師データが必要となります。ありがたいことに世の中には様々な公開教師データセットが存在しています。例えば、有名なデータセットだと、ImageNet、MSCOCO、PASCALVOCなどがありますね。
ただ、自分が行う課題に対して、現実に存在するデータセットだけでは不十分という場合もあります。そのような場合は2つの選択肢があります。
一つは、必要な教師データの収集、アノテーションの作成などを自分で(あるいは外注して)行う方法。
もう一つは、人工的に教師画像とアノテーションを作るという方法です。これらの合成されたデータを現実世界のデータ(Real data)に対比させて、合成データ(Synthetic data)と呼びます。
後者の方法を用いれば、大量の教師データを少ないコストで作成できるのが大きな利点です。
人工的に合成された教師データセットは、車の自動運転や顔認識などの分野で既に存在し、その効果が確認されています(参考記事例)。

一方で、衛星データで利用できる合成データを含むデータセットは、今までほとんどありませんでした。そこに、つい最近Shermeyらによって、RarePlanesという飛行機検出のための合成データを含むデータセットが公開されました。このテーマについて扱っている論文はこちらです。
本記事ではこの論文をもとづいて、RarePlanesというデータセットについて解説していこうと思います!この記事を読むと合成教師データとは何か、またそれは機械学習にどれほど有用であるのかといったことが分かります。さらに、RarePlanesのデータセットは無料で公開されており、そのまま飛行機の物体検出やインスタンスセグメンテーションの教師画像として使えます。なので、自分で飛行機検出のモデルを学習してみたい、という方にも参考になる記事となっています!
1. RarePlanesの概要
RarePlanesとは、機械学習による飛行機検出のための教師データセットです。データは公開されており、AWSから無料でダウンロードできます。このデータセットの大きな特徴は以下の3つです。
・基となるデータが衛星由来データであること
・人工的に合成された画像(合成データ)を含むこと
・対象(=飛行機)に付随する細かい属性(ex. エンジンの数)のラベルを含むこと

上の図がRarePlanesのデータ例です。上の二列がMaxar WorldView-3衛星による現実の衛星データで下二列が合成データになります。一見するとほとんど違いが分かりませんよね。
このデータセットを利用することにより、物体検出、インスタンスセグメンテーション、ゼロショット学習(学習データに含まれていないクラスについて予測を行うための学習)などのタスクが可能となります。
以下に本データセットへの関連リンクをまとめておきました。よければご覧ください。
・元論文: RarePlanes: Synthetic Data Takes Flight
・データセットのユーザーガイド: RAREPLANES PUBLIC USER GUIDE
・関連コード: CODEBASE
・解説動画: RarePlanes Webinar: Accelerating Deep Learning With Synthetic Data
2. 現実の衛星データについて
合成データの有用性を検証するためには(8章で詳説します)、比較のために現実の衛星データも必要になります。そのため、RarePlanesには合成データのみならず、現実の衛星データをも含みます。
現実の衛星データは全てMaxar Worldview-3衛星から提供されています。この衛星の地上分解能(1ピクセルあたりの距離)は0.31-0.39mと非常に高分解能になっています。
データは22ヵ国の112地域から取得されています。また、データは253つのシーンで構成されており、面積としては2142平方キロメートルをカバーしています。
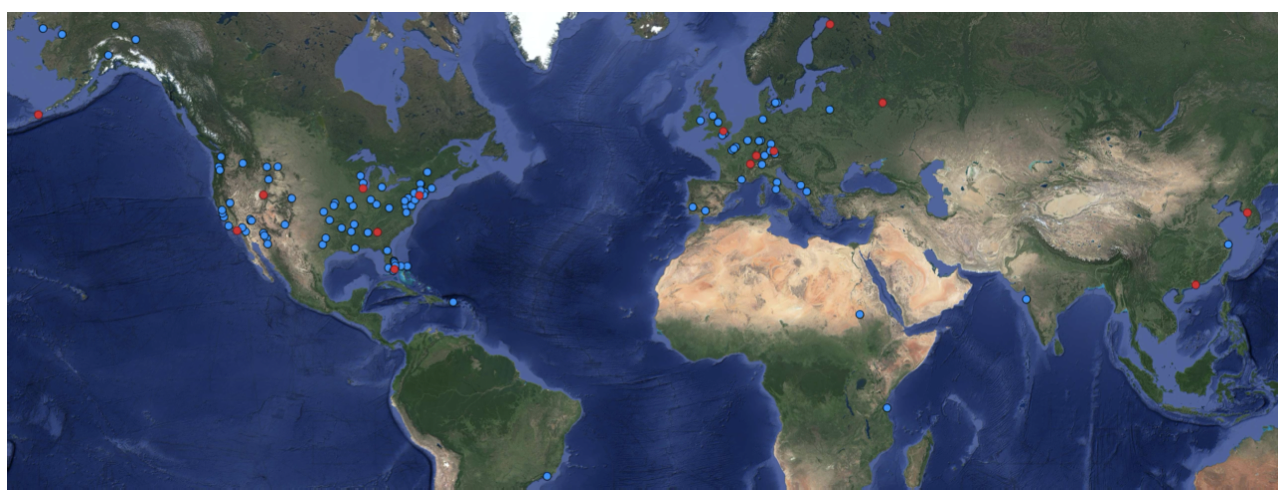
現実の衛星画像は様々な地形、天候、季節に加え、様々なルックアングル(3.2〜29.6°)、太陽高度(10.7〜79.0°)などをカバーするように選ばれています。そのため、この画像セットは多様な条件を包含しており、今回は含まれていないような新しい地域への汎用性も期待されます。
また、観測バンドの種類と対応する分解能としては、以下の3つを含んでいます。
| バンドの種類 | パンクロマティック
バンド(白黒画像) |
8つのマルチスペクトル
バンド(カラー画像) |
RGBのパンシャープンバンド※ |
| 分解能 (m) | 0.31 – 0.39 | 1.24 – 1.56 | 0.31 – 0.39 |
※パンシャープン:解像度の低いカラー画像を解像度の高い白黒画像で鮮鋭化した画像のこと。
3. 合成データについて
一般に、物体検出やセマンティック・セグメンテーションのためのアノテーション(教師ラベル)は、現実の画像に対して、labelImg、VoTT、VIAなどのツールを用い、手作業で作成することが多いです。
ただ、この作業を膨大な枚数の画像に対してとても骨が折れます。また現実の画像だけだと、多様な状況(例えば、多様な天候、多様な地質)を反映した学習データセットを用意することが、現実的に難しいと言う問題もあります。
そこで、考えられるのが合成データです。人工的に教師データを合成することにより、上記の面倒なアノテーション作業を効率化でき、また画像の多様性も容易にカバーすることができます。
繰り返しになりますが、合成データは、車の自動運転、顔認識などの分野ですでに盛んに利用されています。しかし、衛星データの分野ではまだ公開データセットはほとんど存在していません。
合成データの作り方なんて地上のデータも衛星データも同じでしょう、と思うかもしれません。しかし、そんなことはなく、大量かつ多様な合成衛星データを作るためには、特有の難しさがあります。例えば、様々なセンサーの分解能の違いや、地上を見る角度、データの取得日、日の当たり方、影などを考慮しなくてはいけません。他にも、季節や天候による、地上の見え方の変化なども考える必要があります。
RarePlanesの合成データの作成には、AI.Reverieというプラットフォームが用いられています。まずは現実の場所の地理空間画像などのメタデータを用いて、その場所における3次元環境を合成します(下図)。次に、天気、データ取得日、日射量、見る角度、バイオーム、飛行機の分布などをパラメータとして様々な値を与え、大量かつ多様な合成データを作ります。今回は衛星の地上分解能としては、0.3mが仮定されています。

このようにして、15地域における50,000枚の画像と〜630,000個のアノテーションの合成データが作成されました。合成データがカバーする面積は9331.2平方キロメートルに当たります。現実の衛星データのアノテーション の数は14,700個であることを考えると、合成データの数は凄まじいですね。
4. 公開されているデータセットとの比較
1章で述べたように、RarePlanesの大きな特徴は以下の3点です。
・基となるデータが衛星由来データであること
・人工的に合成された画像(合成データ)を含むこと
・対象に付随する細かい属性のラベルを含むこと
これら三つは、いずれも近年機械学習の研究が盛んに行われている領域で、RarePlanesはこの三領域のいわば交点に位置するデータセットになります。
そこで、論文では、これらの特徴を持つ代表的な公開データセットとRarePlanesの比較がなされています。以下の表がその比較になります。
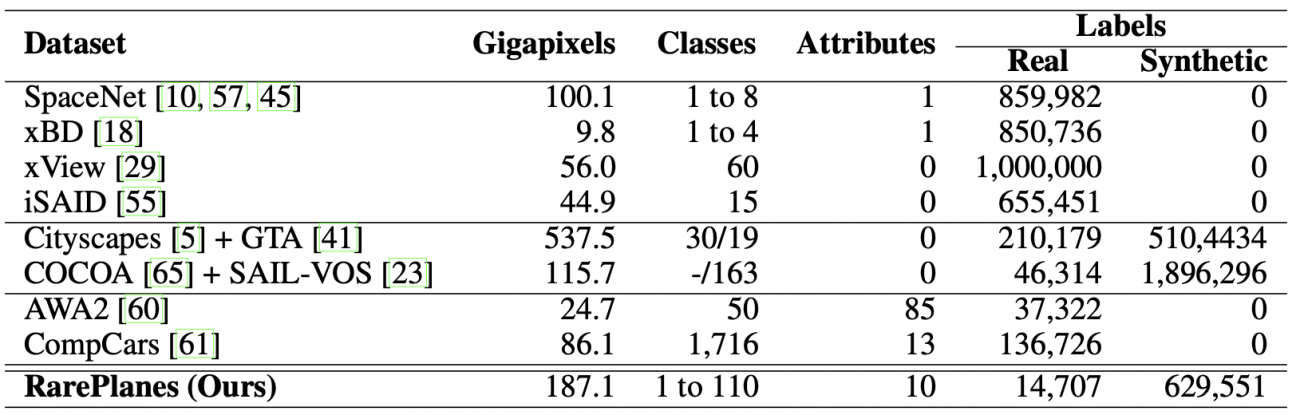
以下に、表で比較されているデータセットについて簡単に説明をします。
1.衛星データ:
・SpaceNet、xBD:建物のフットプリントや道路網のデータの抽出、建物の損害状況の評価などを目的としたデータセット。
・xView、iSAID:衛星画像における様々な物体に対する物体検出やインスタンスセグメンテーションを目的とするデータセット。
これらの衛星データセットに対するRarePlanes特有の特徴としては、合成データを含むことや、細かい属性のアノテーションを複数含むことが挙げられます。
2.合成データを含むデータセット:
・GTA:主に車の自動運転での利用を目的とした合成データセット。合成データの有効性を検証するために、しばしばCityscapesなどの現実のデータセットと一緒に使われている。
・SAIL-VOS:複数の物体が重なりあう状況の解決を目的とするデータセット。
また、表には載せられていませんが、注目すべきデータセットとして、以下のようなものも存在します。
・Synthinel-1:RarePlanes発表以前で合成データを含む唯一の衛星データセット。衛星画像における建物のマスクデータを含む。
RarePlanesは数少ない、合成データを含む衛星データセットとして名を連ねることになります。
3. 対象に付随する細かい属性のラベルも含む:
・The Comprehensive Cars:複数の属性(ex. ドアの数)のラベルを含む車のデータセット。
・AWA2: 複数の属性のラベル(ex. 魚を食べるか否か)を含む動物のデータセット
表で比較されているのは代表的なデータセットであり、ここでは触れられていない公開データセットは他にもたくさん存在します。例えば、衛星データセット集に関しては、以下のリンク先にまとめられています。ご興味のある方はぜひご覧ください!
さて、次にRarePlanesのデータについてより詳細にみていきましょう。
5. RarePlanesにおけるアノテーションの方法
RarePlanesは、14,707つの現実の衛星データに対するアノテーションと、629,551個の合成データに対するアノテーションが付与されています。RarePlaneでは以下の3通りのやり方で、アノテーションが行われています(下図)。

図の左が一般的なバウンディングボックスで、標準的な物体検出ではこのアノテーションスタイルが用いられます。
図の真ん中は、ダイアモンドポリゴンと呼ばれる、このデータセットに特有のアノテーションスタイルです。これは、飛行機の機首、左翼、尾翼、右翼を順番に繋いだものです。このアノテーションの仕方の利点としては、飛行機の長さや横幅などが簡単に計算できるという点があります。また、左のバウンディングボックス型のアノテーションに簡単に変換することも可能です。
最後に図の右は、Fullインスタンスセグメンテーションラベルであり、こちらのラベルは合成データに対してのみ与えられています。インスタンスセグメンテーションなどを行う際に用いるアノテーションスタイルとなります。
6. RarePlanesにおける細かい属性について
上で述べたようなアノテーションがなされた後、さらに細かい属性についても専門家によってアノテーションが付与されています。細かい属性とは具体的に言うと、エンジンの数、機体の長さなどです。以下に詳しくみていきましょう。
下図が細かい属性を並べたものです。5つの特徴(feature)と10つの属性(attribute)と33つの副属性(subattribute)があります。
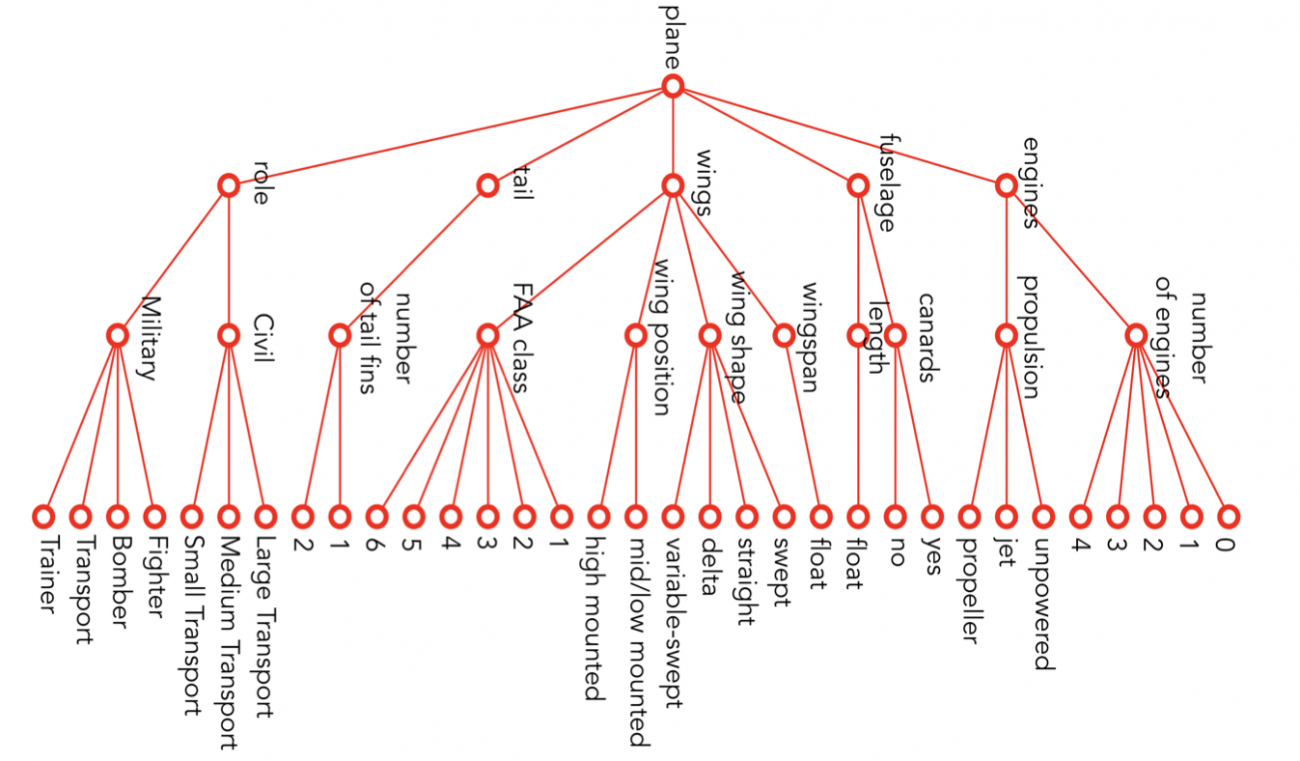
大まかな用語の説明は以下のようになります。
・Engines: エンジンの数(0~4)、推進のタイプ (unpowered, jet, プロペラ)
・Fuselage(機体): 飛行機の長さ(メートル)、Canards(先尾翼)があるか(Yes、No)
・Wings: Wingの形状 (‘staright’, ‘swept’, ‘delta’, ”variable-swept’;下図参照)、Wingの位置、Wingの幅 (メートル)、FAA Aircraft Design Group Wingspan Class
・Tail: 垂直尾翼の数 (1,2)
・Role: 飛行機の使用用途を民用(大型・中型、小型の輸送機)、軍事用(戦闘機、爆撃機、輸送機、練習機)の計7つに分類

これら属性のラベルは、ゼロショット学習(学習データに含まれていないクラスについて予測を行うための学習)のアルゴリズム開発などに重宝すると言われています(参考論文)。
7. RarePlanesのデータをダウンロードする方法
RarePlanesのデータをダウンロードする詳細な方法については、こちらのページに記載されています。ここでは大事な点だけを書きます。
データはAWS Open-Data Programを通して、無料でダウンロードできます。まずはAWSのサイトに行ってアカウントを作りましょう。
そしてAWS CLIをインストールし、configureします。
そうすればあとは簡単です。例えば現実の衛星データを全てダウンロードしたかったら、以下のコマンドを実行するだけです。
aws s3 cp --recursive s3://rareplanes-public/real/tarballs/ . また、合成データをダウンロードしたいときは以下のコマンドを打ちます。
aws s3 cp --recursive s3://rareplanes-public/synthetic/ . どちらのデータも100GB以上あるので、ダウンロードするときはご注意ください。特に申請いただいたTellusの開発環境の種類によっては、全データをダウンロードすると容量が足りないということもあるかもしれません。その場合は、部分的にダウンロードしていただくのが良いでしょう。例えば、以下のようなコマンドを打つと、学習用の合成データのうち、ロンドン空港の画像のみをダウンロードできます。
aws s3 cp --recursive s3://rareplanes-public/synthetic/train/images . --exclude "*.png" --include "London*.png"8. 合成データの性能評価
さて、衛星データに対して人工的に合成データを作ったという話ですが、やはり気になることがありますよね。つまりそれを使って学習したモデルは本当に精度が出るの?という疑問です。
そこで、論文では、RarePlanesのデータに対して物体検出とインスタンスセグメンテーションをそれぞれ実行することで、合成データの有用性を検証しています。具体的には、二つのネットワーク(Faster R-CNN、Mask R-CNN)に対し、学習データを以下の3パターンに分けてそれぞれ学習し、各場合について予測精度の比較をしています。
- 現実の衛星データのみ(Real)
- 合成データのみ(Synth)
- 合成データに現実の衛星データのごく一部(~10%)を加える(FT; Fine Tuning)
学習にはDetectron2というフレームワークを使用し、検出は分類を行わない飛行機そのものの検出と民用飛行機の分類(“Small”、”Medium”、”Large”)の2つが行われています。
論文によると、結果は以下のようになります。mAP(mean average precison)、AR(average recall)などは評価指標です。
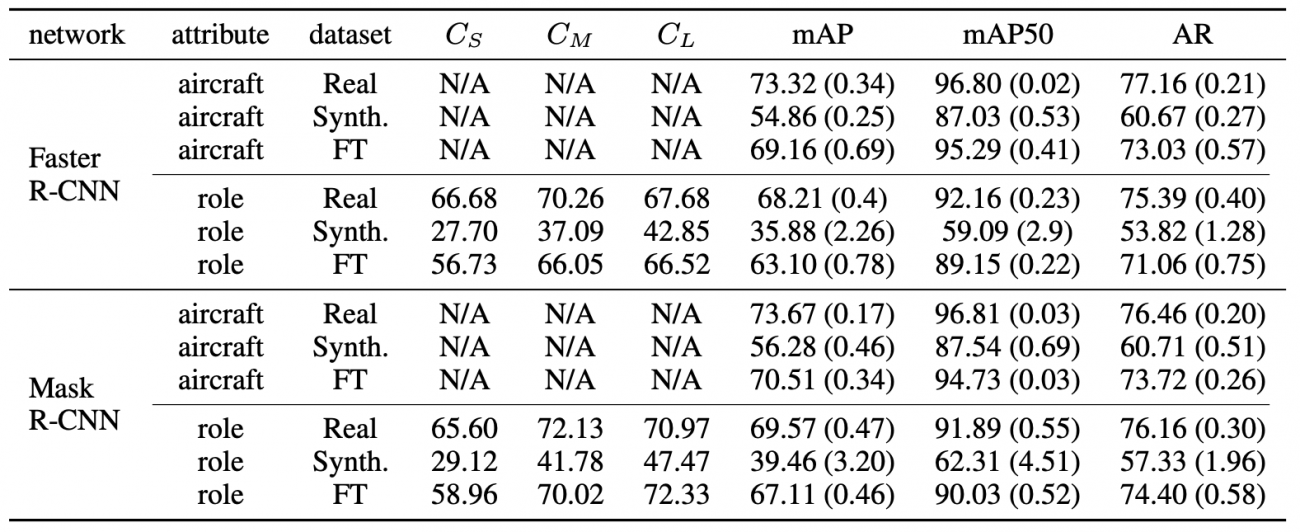
表を見ると、全体的な傾向として、合成データのみで学習すると、現実の衛星データのみで学習したモデルよりはやはり精度は劣ってしまうことが分かります。例えば、Faster-RCNNを用いた飛行機の検出に対するmAP50は、現実の衛星データのみを用いた場合は96.80%であるのに対し、合成データのみを用いた場合は87.03%となっています。
ただ、注目するべきは合成データにほんのわずかな現実の衛星データ(~10%)を加えたデータセット(FT)を用いた場合です。この場合、評価指標は全ての現実の衛星データを用いた場合(Real)と同じくらい高くなっていることがわかります。例えば、Faster-RCNNに対してFTを用いた場合のmAP50は95.29%となっており、現実の衛星データのみを用いた場合(mAP: 96.80%)に非常に肉薄しています。
上のような結果は以下の図(元論文の図6)をみてもらってもよく分かると思います。図は3通りの学習データを使った場合の、それぞれの飛行機検出の予測結果を表しています。合成データに対して現実の衛星データをわずかに混ぜ合わせると、検出の精度が向上しているのがみて取れますね。
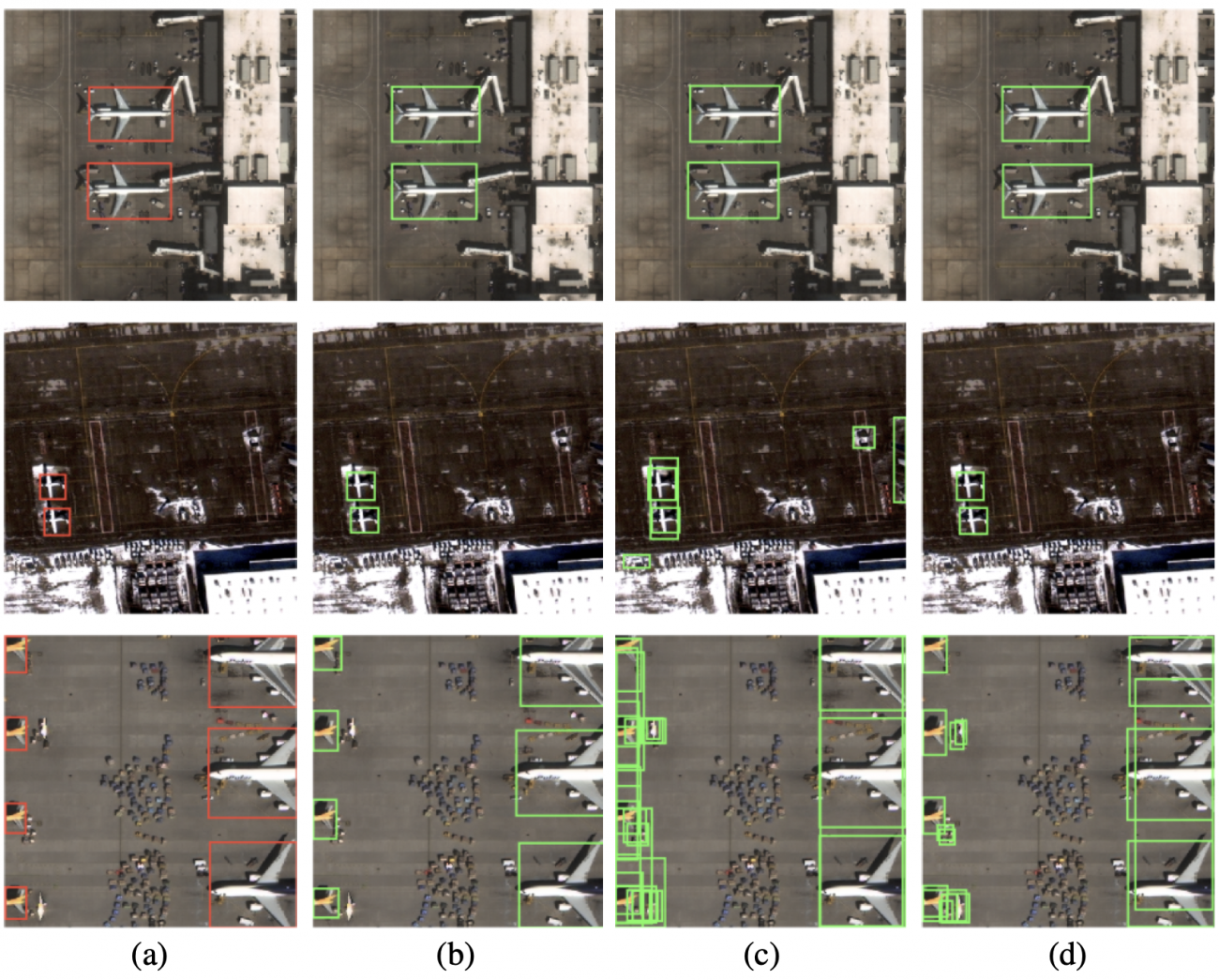
高分解な衛星データを大量に入手するのは、一般的には困難であることが多いと思います。そのため、わずかな現実の衛星画像に合成データを加えることによって、モデルの精度が格段に向上するというのは、とても画期的な結果だと思います。
9. 考えられる応用先
RarePlanesのデータのまず考えられる応用先はもちろん飛行機検出です。データは無料でダウンロードできますし、画像データとともにアノテーションデータも提供されています。そのため、自分でこれらのデータを用いて飛行機検出のためのモデルを学習できます。
飛行機の検出ができれば、例えば空港で待機している飛行機の数を数えることで、コロナによる航空会社への影響、株価予測などが可能かもしれません。他にも、観光地の空港にある飛行機をカウントすることで、その地域の観光収入の予測などにもひょっとしたら使えるかもしれません。
また、今回の論文では飛行機の合成データがテーマでした。しかし、類似した手法で衛星データにおける車、トラック、船などの合成データを作ることも可能かと思われます。このような合成データがあれば、数少ない現実の高分解能な衛星データに混ぜ合わせることで、高精度の車や船舶検出のモデルを作ることも可能かもしれません。これは高分解能なデータの入手が困難な衛星データにおいては朗報だと思います。
10. まとめ
本記事では、RarePlanesという飛行機検出のためのデータセットについて、元論文をもとに解説しました。データセットはAWSから無料でダウンロードでき、飛行機検出のモデルの学習に利用できます。特に、このデータセットは合成データを数多く含むことが特徴的です。このような合成データは、今後の衛星データ活用においてどんどん重要性を増していくのではないでしょうか。
また、今回は飛行機のデータセットに焦点を当てて紹介しました。ただ、4章でも述べたように、他にも建物検出、土地被覆分類、道路網などの教師データセットも続々と公開されています。このような公開データセットを用いて、皆様もTellusの開発環境で機械学習などにチャレンジしてみてはいかがでしょうか。
★Tellusの登録はこちらから
