地理空間情報を扱うなら知っておきたいPythonライブラリ、GeoPandas入門~基礎編~
さまざまなデータを地理空間情報として重畳する上で有用なPythonのライブラリであるGeoPandas。前編ではGeoPandasを用いたデータの描画方法など基礎的な扱い方を紹介し、後編では衛星データと組み合わせて解析結果を可視化する方法を紹介します。
Pythonで地理空間情報を行う場合、GeoPandasの使い方を覚えておくととても便利です。
例えば、都道府県別の気象データを持っていたとします。そのテーブルデータ(csv)には地理情報と言えば、都道府県の名称くらいしかありません。このような場合、これを日本地図の上に重畳して可視化することはできません。
しかし、このデータに地図上に描画できる情報を与えることさえできれば、好きなデータを地図の上に重ねることができます。このようなことをしたい場合に、GeoPandasの使い方を知っておけば助けになります。
今回は、簡単な例を通じて、GeoPandasの魅力の一端を知ってみましょう。
今回の解析ではGoogle Colaboratoryを利用しています。ローカルでも動作します。
仮にローカルで実行する場合には、いくつかの処理は必要ありませんので都度スキップしてください。
今回利用するデータはこちら
この前編では
- ・ラスターデータとベクターデータの振り返り
- ・GeoPandasを利用してベクターデータの読み込みや描画
- ・csvデータとベクターデータの組み合わせによる解析
- ・やや高度な描画方法
- ・時系列動画(タイムラプス動画)の作成
- ・Plotlyを用いた可視化例
について紹介します。
ラスターとベクター
地理空間情報とはいわゆるGISというものです。まずは基礎中の基礎、画像の形式としてラスター、ベクターというものを思い出すに留め、この記事の後編では、実際にコードを動かしながら地理空間情報解析に必要な知識である、参照系の概念を説明します。
※参照系が何か気になる方はこちらの論文等をご覧ください
ラスターデータ

ラスターデータとは上のように格子状の中にデータが入ったものです。格子の大きさにより、画像の滑らかさが変わります。格子が細かいラスターデータは、より解像度の高い画像と考えらられ、格子が大きくなれば、荒い画像になります。
この一つ一つの格子をピクセルと呼びます。
ラスターはGeoPandasで扱うより、rasterioなどで扱うことが多いのですが、このピクセル座標を地理座標に置き換え、ピクセル一つ一つをテーブルデータとして扱うことができます。特に初めから地理座標を備えているGeoTIFFデータでは、この変換作業はとても楽です。

上の図を見れば明らかです。不鮮明な画像では、ピクセルの形がはっきりとわかりますが、高い解像度のものでは、ピクセルの形は捉えることができません。
ラスターデータは単に写真のようなデータというわけではなく、ピクセルの中に入っている値を用いて発展的な解析を行います。代表的なものとして植生の活性度を示すNDVIやEVIがあります。
他に、下図のように地表面温度の推定も求めることができます。

ピクセル座標が地理空間情報を含むと、実際に地図上にデータを重ねることができます。
画像自身は自分がどこに当てはまるのかを知っていません。ここに参照となるデータを与えてあげる(georeference)と、画像データがどこに位置するべきなのかを判断できます。
ベクターデータ
続いてベクターです。ベクターはラスターと違い、格子の中にデータを持たない、ピクセルで構築されていないデータです。
点のデータ、線のデータ、そしてポリゴンと呼ばれる多角形のデータがこれに当たります。例えば、市町村区の境界、Google Map上でお気に入りの場所に落としたピンがベクターデータになります。
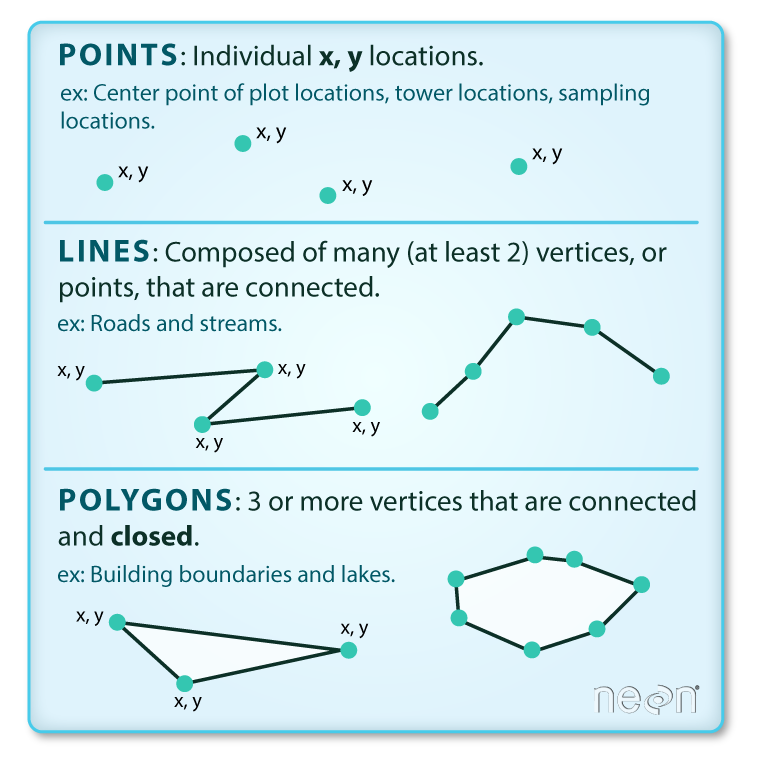
上図を見るとわかるように、ポイントは、一つの座標で構成されています。ラインは少なくとも2点の情報が必要であり、その線は閉じていません。ポリゴンでは、複数の点、線が閉じることが条件となります。もちろん、円もポリゴンです。
ベクターファイルの有名な形式としてはshp(shapefile)があります。GeoJSONも代表的なファイル形式と言えるでしょう。ベクターは数学的に記述されたデータであり、解像度という概念をもっていません。そのため拡大しても縮小しても、変化はありません。
GeoPandasを触ってみよう
GeoPandasとはそもそも何なのか。GeoPandasとはPandasによるテーブルデータの処理と、Shapelyによる幾何学的なデータ処理を併せ持ったものになります。そこにmatplotlibによる描画支援も行われているため、地理空間情報を簡単なテーブルデータで処理できるだけでなく、ちょっとしたコマンドで直接描画まで行えるという優れものです。
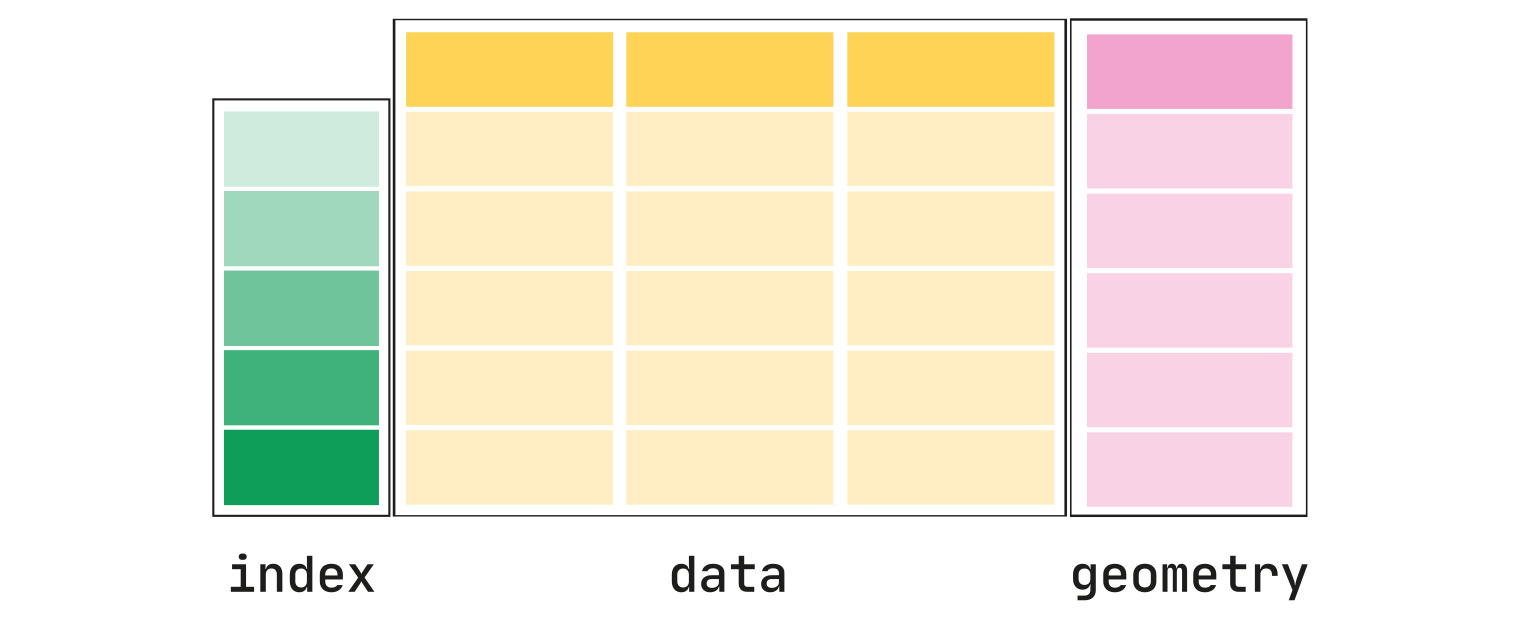
言葉で説明するよりも、図で見るとわかりやすいです。地理空間情報は様々な形式がありますが、それを上図のようなテーブルにしてしまい、shapelyにより処理される幾何情報はgeometryという列に保存されています。このようなテーブルデータをGeoDataFrameと呼びます。
geomtryでは
- ・PointsまたはMulti-Points
- ・LinesまたはMulti-Lines
- ・PolygonsまたはMulti-Polygons
が基本的なオブジェクトとして扱われます。
ColabでGeoPandas+αを使う準備をします。下記のセルを実行してください。
GeoPandasには以下の依存関係があります。
- ・numpy
- ・pandas
- ・shapely
- ・fiona
- ・pyproj
詳しくは公式リファレンスをご覧ください。
# Important library for many geopython libraries
!apt install gdal-bin python-gdal python3-gdal
# Install rtree - Geopandas requirment
!apt install python3-rtree
# Install Geopandas
!pip install git+git://github.com/geopandas/geopandas.git
# Install Folium for Geographic data visualization
# !pip install folium
!pip install plotly-express
!pip install --upgrade plotly
!pip install matplotlib-scalebar
# Use EE in Python
!pip install geemap
!pip install ipygee# Colab使用時
import os
os.kill(os.getpid(), 9)# Colab使用時
# Driveのマウント
# Filesからもワンクリックでマウント可能です
from google.colab import drive
drive.mount('/content/drive')ライブラリのインポートを行います。上記で全てがインストールされていれば、エラーなく実行できます。
import pandas as pd
import numpy as np
import os
import geopandas as gpd
from shapely.geometry import Point
import matplotlib
import matplotlib.pyplot as plt
import folium
import plotly_express as px
from datetime import datetime
import geemap
from ipygee import*データを使って実際に解析をしてみましょう。
今回は、e-statから初婚の平均年齢のデータをダウロードした上で可視化します。
レイアウトをいじってからダウンロードしてありますが、それ以外には特に加工はしていません。
初婚年齢データの読み込み
# 階層は適宜変更してください
marriageDf = pd.read_csv('/content/drive/MyDrive/Sorabatake/marriage.csv')データの中身を確認します。
marriageDf.info()RangeIndex: 680 entries, 0 to 679
Data columns (total 14 columns):
# Column Non-Null Count Dtype
— —— ————– —–
0 cat01_code 680 non-null int64
1 年齢(5歳階級) 680 non-null object
2 cat02_code 680 non-null int64
3 世帯の主な仕事 680 non-null object
4 cat03_code 680 non-null int64
5 総数・再掲 680 non-null object
6 cat04_code 680 non-null int64
7 夫・妻 680 non-null object
8 area_code 680 non-null int64
9 都道府県(特別区−指定都市再掲) 680 non-null object
10 time_code 680 non-null int64
11 時間軸(年次) 680 non-null object
12 unit 680 non-null object
13 value 680 non-null float64
dtypes: float64(1), int64(6), object(7)
memory usage: 74.5+ KB
こちらはe-statからダウンロードしたものとなります。ダウンロード前にレイアウトをいじってからダウンロードしてありますが、それ以外には特に加工はしていません。
ここでは、簡単なデータクリーニングも含めて進めていきましょう。
marriageDf.head()
marriageDf.describe(include='all')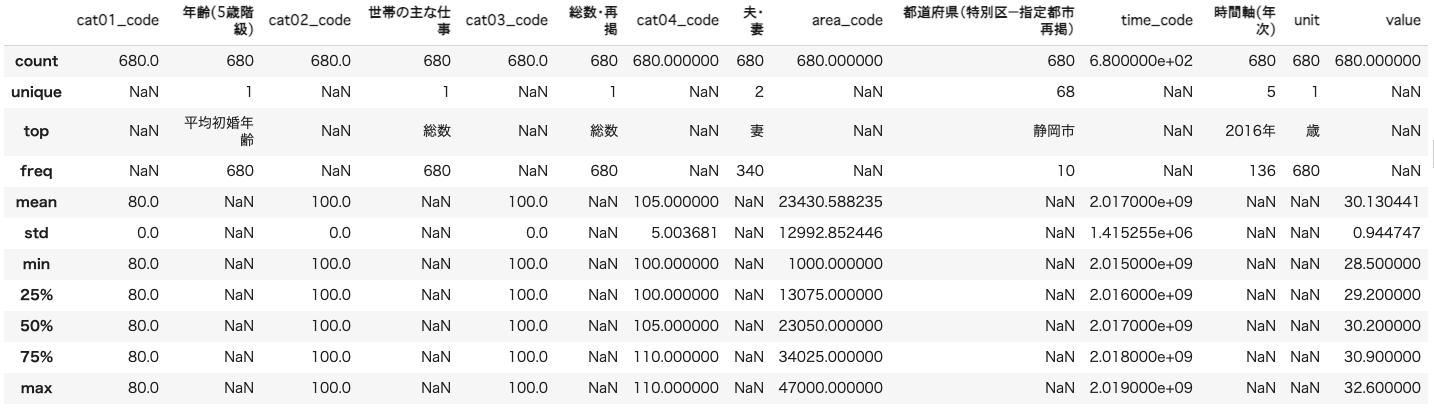
列名を変更します。
marriageDf = marriageDf.loc[:,['夫・妻','都道府県(特別区−指定都市再掲)','時間軸(年次)','value']].\
rename(columns={'夫・妻':'sex','都道府県(特別区−指定都市再掲)':'prefecture','時間軸(年次)':'year','value':'avgAge'}).copy()続いて、値も編集します。
具体的には、
- ・夫はmale、妻はfemale
- ・xxxx年から年を削除
- ・都道府県レベルのみ抽出
します。
marriageDf.sex = marriageDf.sex.replace('夫','male',regex=False).replace('妻','female',regex=False)
marriageDf.year = marriageDf.year.replace('年$','',regex=True)
# marriageDf.year = pd.to_datetime(marriageDf.year, format = '%Y').dt.to_period('y')
marriageDf.year = marriageDf.year.astype('int64')includeStr = ['県$','道$','都$','府$']
marriageDf = marriageDf.loc[marriageDf.prefecture.str.contains('|'.join(includeStr)),:].reset_index(drop=True)marriageDf.describe(include='all') # describe all variables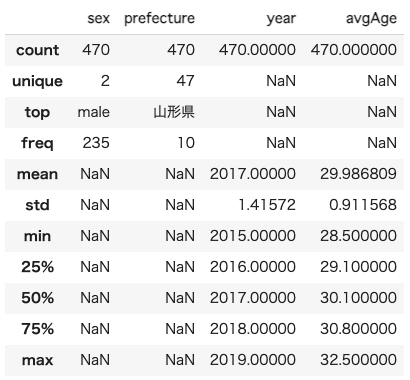
初婚年齢が最も低い値を探してみましょう。
marriageDf.loc[marriageDf.avgAge == marriageDf.avgAge.min(),:]佐賀県の28.5歳と表示されます。
初婚年齢が最も高い値を探してみましょう。
marriageDf.loc[marriageDf.avgAge == marriageDf.avgAge.max(),:]東京都の32.5歳と表示されます。
つまり、都道府県レベルで見ると、佐賀県が最も早く、東京都が最も遅く結婚していることがわかります。
ベクターファイルの読み込み
GADMからファイルをダウンロードします。
シェープファイルをダウンロードし、解凍すると以下のファイルが含まれています。
- ・.cpg
- ・.dbf
- ・.prj
- ・.shp
- ・.shx
です。geopandasではシェープファイルを読み込む際に、.shpしか指定しません。しかし、GeoPandasでデータを読み込むためには、.shp、.dbf、そして.shxは同じフォルダに存在している必要があります。仮にこれらのファイルが欠けてしまっている場合、pythonはエラーを返します。解凍したファイルからshpだけを残して他のファイルを削除しないようにしましょう。
# 階層は適宜変更してください
jpnShp = gpd.read_file('/content/drive/MyDrive/Sorabatake/japanSHP/gadm36_JPN_1.shp')jpnShp.head()今回は行政レベル1を利用しているため、都道府県レベルでのデータを利用することができます。
データフレーム内でgeometryの列が地図上に対象を描画するために必要な情報になります。
geopandasではフィルタリングもお手の物です。Pandasに慣れている場合には、問題なくデータのクリーニングが行えます。データの操作を行う前に、簡単な可視化を行ってみましょう。
以下の3行のコマンドで描画することが可能です。
ax = jpnShp.plot(figsize=(10, 10))
jpnShp.plot(ax=ax)
plt.show();
今回は都道府県レベルのデータを利用していますので、境界も描画します。
併せて、名前も重畳します。
# 日本のシェープデータを可視化する
ax = jpnShp.plot(figsize=(14, 14))
jpnShp.apply(lambda x: ax.annotate(s=x.NAME_1, xy=x.geometry.centroid.coords[0], ha='center', color = 'black', size = 6),axis=1)
jpnShp.plot(ax = ax, edgecolors='black')
plt.title('Administrative level 1 map in Japan', fontsize=16)
plt.show();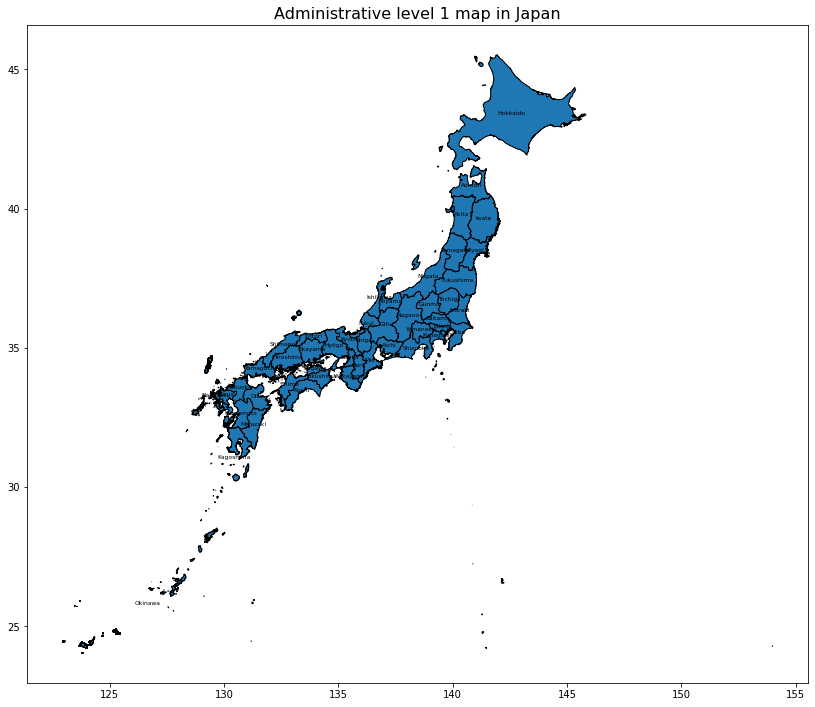
GeoDataFramedではShapelyとmatplotlibにより、簡単にベクターデータを可視化することができます。それでは、この図と先ほど取得したe-statのデータを結合し、さらに描画を行います。
shpとcsvの結合
シェープファイルのようなデータは、地図上にデータを投影するために必要なデータを既に持っています。単なるテーブルデータは、このようなデータを持っていません。しかし、今回のシェープファイルは都道府県の形を描画する以上のデータを含んでいません。
例えば、果物の都道府県別収穫量のデーブルデータを持っているとして、一方でこのデータには地図上にデータを描くための情報は含まれていません。このような場合に上で示したシェープファイルを利用すれば、果物の収穫量を持った都道府県のデータ(GeoDataFrame)が作成できます。
今回は、平均初婚年齢ですが、やることは同じです。早速試してみましょう。
# 不必要な列の削除
japan = jpnShp.loc[:,['NAME_1','NL_NAME_1','geometry']].copy()combDf = japan.merge(marriageDf,left_on='NL_NAME_1',right_on='prefecture',how='left') # データの結合
combDf.head() # check再度、描画を行います。今度は、2019年の平均初婚年齢を日本地図に重畳します。
from matplotlib_scalebar.scalebar import ScaleBar
from mpl_toolkits.axes_grid1 import make_axes_locatable縮尺や方位を入れないとGIS屋さんに怒られるので、入れ忘れないようにしましょう。
Pythonで縮尺を入れるためには、ScaleBarを利用するのが良いです(Cartopyを使えばもっと正確です)。
※個人的にはPythonでの縮尺追加は面倒です。もっとシンプルに論文で使える、プレゼンで使える地理空間情報の可視化であればRの方が楽に実行できます。
ScaleBarでは1ピクセルあたりの長さと、その単にを指定する必要があります。今回は50とkmを指定していますので、1ピクセルあたり50kmという計算になります。また長さは、 1, 2, 5, 10, 15, 20, 25, 50, 75, 100, 125, 150, 200, 500 or 750のみしか扱えませんので、縮尺と実際の長さにはややずれが生じることが考えられます。細かい精度まで気にしなければならない場合には、自分で緯度経度を基にして距離を算出して縮尺を作るのが良いと思います。
# 男性
# 方位の作成についての参考記事:
## https://mohammadimranhasan.com/geospatial-data-mapping-with-python/
combDf2019M = combDf.loc[(combDf.year == 2019)&(combDf.sex == 'male'),:].reset_index(drop=True).copy()
ax = combDf2019M.plot(figsize=(16, 16))
scalebar = ScaleBar(50, location='lower right',units='km')
ax.add_artist(scalebar) # 200km
ax.text(x=153.215-0.55, y=40.4, s='N', fontsize=30) # North Arrow
ax.arrow(153.215, 39.36, 0, 1, length_includes_head=True,
head_width=0.8, head_length=1.5, overhang=.1, facecolor='k') # North Arrow
combDf2019M.apply(lambda x: ax.annotate(s=x.NAME_1, xy=x.geometry.centroid.coords[0], ha='center', color = 'black', size = 6),axis=1)
combDf2019M.plot(column='avgAge', cmap = 'rainbow', edgecolors='black', ax = ax, legend=True,legend_kwds={'label': "Average age of first marriage",'orientation': "vertical"})
plt.title('Average Age of First Marriage among Males by Prefectures in 2019', fontsize=16)
plt.show();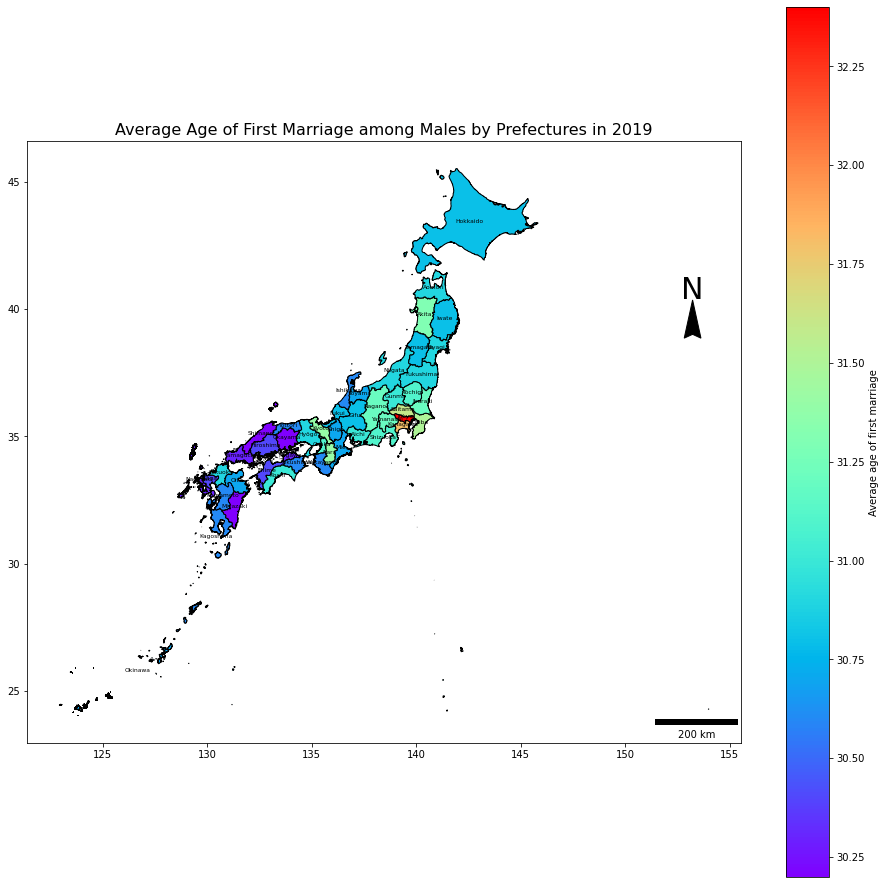
図を見ると、東京が平均初婚年齢が高いことが分かります。その一方で西日本側、特に中国・四国・九州地方では平均初婚年齢がやや若いのがわかるかと思います。
このように、単に値としてみるより、地図で可視化するというのは、非常にわかりやすく、大まかな地理的な変異を捉えることに役立ちます。
加えて女性も見てみましょう。
# 女性
combDf2019F = combDf.loc[(combDf.year == 2019)&(combDf.sex == 'female'),:].reset_index(drop=True).copy()
ax = combDf2019F.plot(figsize=(16, 16))
scalebar = ScaleBar(50, location='lower right',units='km')
ax.add_artist(scalebar) # 200km
ax.text(x=153.215-0.55, y=40.4, s='N', fontsize=30) # North Arrow
ax.arrow(153.215, 39.36, 0, 1, length_includes_head=True,
head_width=0.8, head_length=1.5, overhang=.1, facecolor='k') # North Arrow
combDf2019F.apply(lambda x: ax.annotate(s=x.NAME_1, xy=x.geometry.centroid.coords[0], ha='center', color = 'black', size = 6),axis=1)
combDf2019M.plot(column='avgAge', cmap = 'rainbow', edgecolors='black', ax = ax, legend=True,legend_kwds={'label': "Average age of first marriage",'orientation': "vertical"})
plt.title('Average Age of First Marriage among Females by Prefectures in 2019', fontsize=16)
plt.show();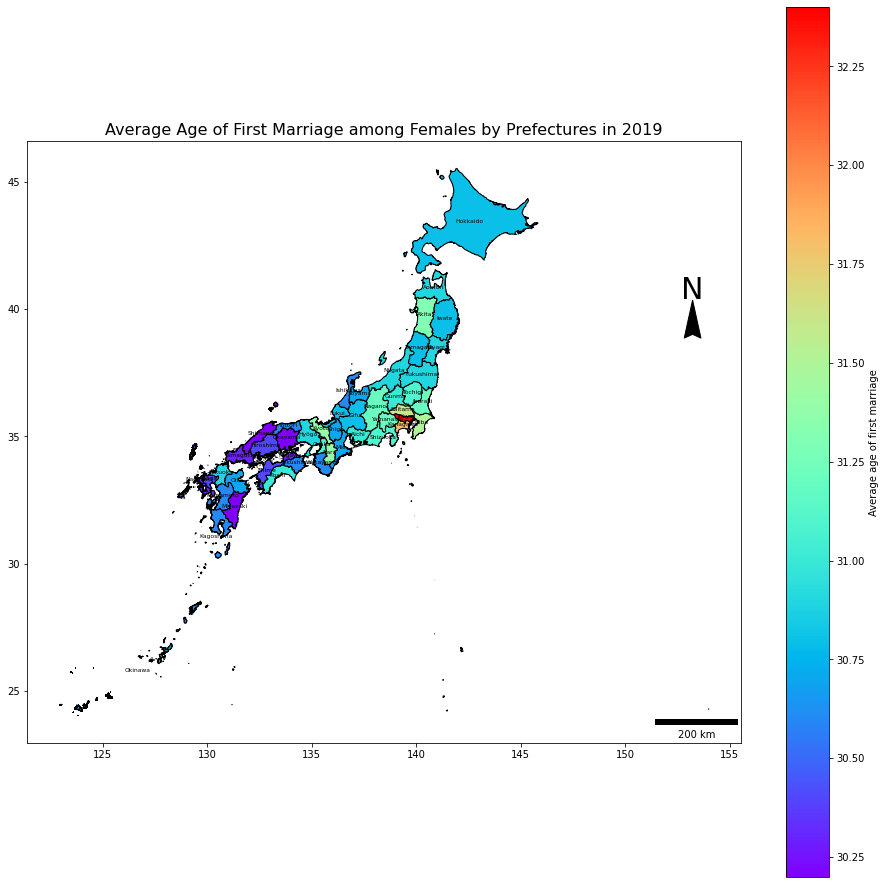
女性も傾向は同じですね!
これらの図がコロプレスマップと呼ばれるものです。
5年分をまとめて描画します。このようにすることで時間ごとの変化が分かりやすくなります。
combDf2018M = combDf.loc[(combDf.year == 2018)&(combDf.sex == 'male'),:].reset_index(drop=True).copy()
combDf2017M = combDf.loc[(combDf.year == 2017)&(combDf.sex == 'male'),:].reset_index(drop=True).copy()
combDf2016M = combDf.loc[(combDf.year == 2016)&(combDf.sex == 'male'),:].reset_index(drop=True).copy()
combDf2015M = combDf.loc[(combDf.year == 2015)&(combDf.sex == 'male'),:].reset_index(drop=True).copy()with plt.rc_context(rc={'font.family': 'serif', 'font.weight': 'bold', 'font.size': 12}):
fig, ((ax1, ax2), (ax3, ax4), (ax5, ax6)) = plt.subplots(nrows=3, ncols=2, figsize = (20,20))
fig.autofmt_xdate(rotation = 45)
# 2019
scalebar = ScaleBar(50, location='lower right',units='km')
combDf2019M.plot(column='avgAge', cmap = 'rainbow', edgecolors='black', ax = ax1, legend=True,vmin=28.5, vmax=32.5)
ax1.set_title('Average age of first marriage in 2019', fontsize=10)
ax1.text(x=152.215-0.85, y=40.7, s='N', fontsize=15) # North Arrow
ax1.arrow(152.215, 39.36, 0, 1, length_includes_head=True, head_width=0.8, head_length=1.5, overhang=.1, facecolor='k') # North Arrow
ax1.add_artist(scalebar)
# 2018
scalebar = ScaleBar(50, location='lower right',units='km')
combDf2018M.plot(column='avgAge', cmap = 'rainbow', edgecolors='black', ax = ax2, legend=True,vmin=28.5, vmax=32.5)
ax2.set_title('Average age of first marriage in 2018', fontsize=10)
ax2.text(x=152.215-0.85, y=40.7, s='N', fontsize=15) # North Arrow
ax2.arrow(152.215, 39.36, 0, 1, length_includes_head=True, head_width=0.8, head_length=1.5, overhang=.1, facecolor='k') # North Arrow
ax2.add_artist(scalebar)
# 2017
scalebar = ScaleBar(50, location='lower right',units='km')
combDf2017M.plot(column='avgAge', cmap = 'rainbow', edgecolors='black', ax = ax3, legend=True, vmin=28.5, vmax=32.5)
ax3.set_title('Average age of first marriage in 2017', fontsize=10)
ax3.text(x=152.215-0.85, y=40.7, s='N', fontsize=15) # North Arrow
ax3.arrow(152.215, 39.36, 0, 1, length_includes_head=True, head_width=0.8, head_length=1.5, overhang=.1, facecolor='k') # North Arrow
ax3.add_artist(scalebar)
# 2016
scalebar = ScaleBar(50, location='lower right',units='km')
combDf2016M.plot(column='avgAge', cmap = 'rainbow', edgecolors='black', ax = ax4, legend=True, vmin=28.5, vmax=32.5)
ax4.set_title('Average age of first marriage in 2016', fontsize=10)
ax4.text(x=152.215-0.85, y=40.7, s='N', fontsize=15) # North Arrow
ax4.arrow(152.215, 39.36, 0, 1, length_includes_head=True, head_width=0.8, head_length=1.5, overhang=.1, facecolor='k') # North Arrow
ax4.add_artist(scalebar)
# 2015
scalebar = ScaleBar(50, location='lower right',units='km')
combDf2015M.plot(column='avgAge', cmap = 'rainbow', edgecolors='black', ax = ax5, legend=True, vmin=28.5, vmax=32.5)
ax5.set_title('Average age of first marriage in 2015', fontsize=10)
ax5.text(x=152.215-0.85, y=40.7, s='N', fontsize=15) # North Arrow
ax5.arrow(152.215, 39.36, 0, 1, length_includes_head=True, head_width=0.8, head_length=1.5, overhang=.1, facecolor='k') # North Arrow
ax5.add_artist(scalebar)
# Blank
ax6.axis('off')
# plt.tight_layout(pad=4)
plt.show();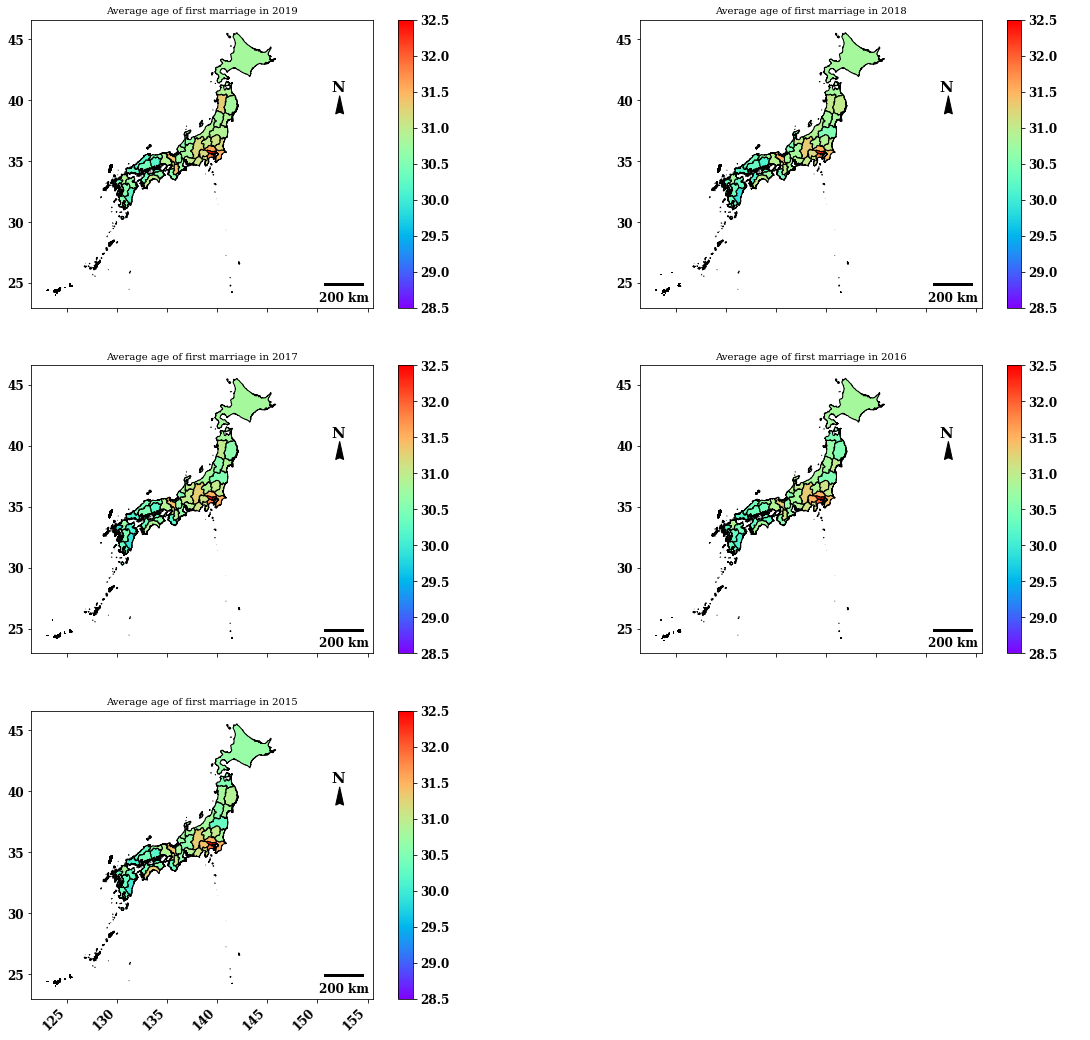
2015〜2019の5年間で、傾向に大きな変化がないことがわかります。
続けて、時系列動画(タイムラプス動画)を作成しましょう。地図の可視化では動画を見せる方が理解が早かったりします。今回は5年間のデータですが、これが30年間のような長いスケールになると、時間変化していく様子は動画の方が理解しやすくなります。
動画作成手順としては、png画像を作成し、ffmpegを利用します。
maleDf = combDf.loc[combDf.sex == 'male',:] # Extract males' values
dateMin = maleDf['year'].min()
n_years = maleDf['year'].nunique()# 画像とアニメーションの参考記事
## https://qiita.com/croquette0212/items/8ff251d5da77e803c253
## https://medium.com/tech-carnot/time-lapse-choropleth-map-visualization-using-geopandas-8adb77a7d14
for i in range(0,n_years):
nyear = dateMin + i
#Get cumulative df till that date
dfYear = maleDf.loc[maleDf['year'] == nyear,:]
fig, ax = plt.subplots(1, figsize=(10,8))
dfYear.plot(column='avgAge',
cmap='Blues', linewidth=0.8, ax=ax, edgecolor='0.8')
# remove the axis
ax.axis('off')
# add a title
ax.set_title('Average Age of First Marriage among Males',
fontdict={'fontsize': '25', 'fontweight' : '3'})
# Create colorbar as a legend
sm = plt.cm.ScalarMappable(cmap='rainbow',
norm=plt.Normalize(vmin=dfYear['avgAge'].min(), vmax=dfYear['avgAge'].max()))
# add the colorbar to the figure
cbar = fig.colorbar(sm)
fontsize = 20
# Positions for the date
date_x = 140
date_y = 30
syear = str(nyear)
ax.text(date_x, date_y,
f"{syear}",
color='black',
fontsize=fontsize)
fig.savefig(f"/content/drive/MyDrive/Sorabatake/videoff/frame_{i:03d}.png",
dpi=100, bbox_inches='tight')
plt.close()画像の準備ができました。上の保存フォルダについては、ご自身の好きなフォルダで問題ありません。
この画像を用いて、ffmpegで動画の作成を開始します。今回はターミナルのコマンドを持ちますので、!を先頭につけたコマンドを追加しています。
imgDir = '/content/drive/MyDrive/Sorabatake/videoff' # 動画の保存場所
if not os.path.exists(imgDir):
os.makedirs(imgDir) # フォルダ作成
# 同じ動画名にならないように注意
!ffmpeg -framerate 1 -i "$imgDir/frame_%03d.png" -c:v h264 -r 30 "$imgDir/avgAgevideo.mp4"作成した動画はvlcなどの動画ソフトで閲覧が可能です。
Plotlyを使う
描画として、さらにPlotlyを利用してみましょう。こちらでは動的な可視化が行えるようになります。
fig = px.choropleth(combDf, # データフレーム
locations="NAME_1", # 場所の名称を取得
color="avgAge", # 色付けするデータ指定
hover_name="NAME_1", # マウスホバーで表示するデータ
animation_frame="year", # 時間データ指定
projection="natural earth", # 投影する面指定
color_continuous_scale = 'Peach', # 色指定
range_color=[28,33] # 色付けするデータの範囲を指定
)
fig.update_geos(
center=dict(lon=136, lat=37), scope='asia',
lataxis_range=[28,47], lonaxis_range=[125, 150]
)
fig.show()
# plt.close(fig)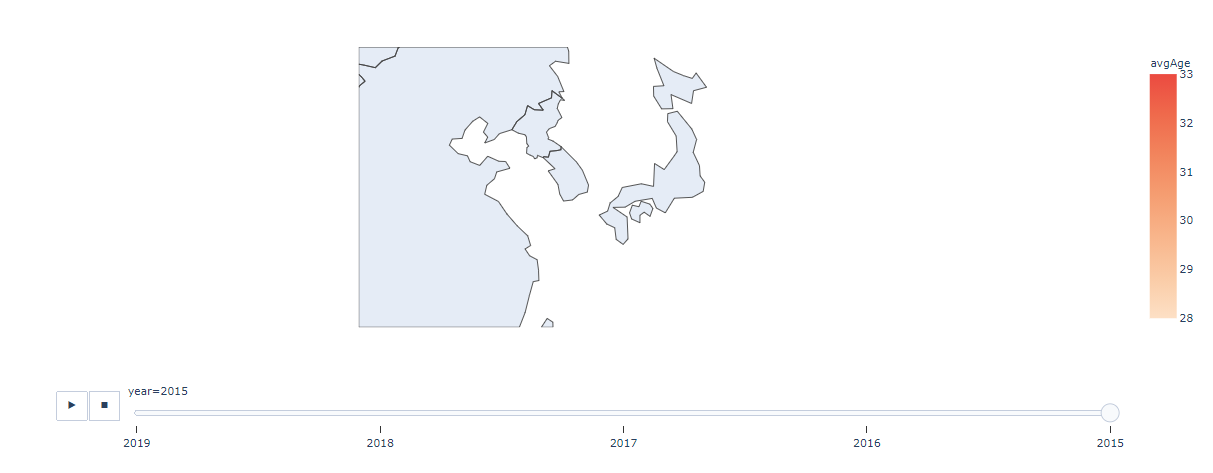
と思ったら、悲しい。日本の行政区域は含まれていないのですね。諦めましょう。
仮にポイントデータを重ねるのであれば、scatterを利用してbubble mapを描くことができます。
こちらの記事をご参照ください。また、treemapであれば、地図に描画するのと同じように分かりやすく全体の違いを捉えることができます。そちらを試してみましょう。
df2019 = combDf.loc[combDf.year == 2019,:]
fig = px.treemap(df2019, path=['prefecture'], values='avgAge', color='avgAge', color_continuous_scale='magma')
fig.show()
同じように全体は掴みやすいのですが、地理的な変異を捉えることが難しいため、基本的は地図上で描画できるのが望ましいと思います。
最後に、まとめて描画します。
表示されるラベルは平均初婚年齢にしてあります。
import plotly.graph_objects as go
from plotly.subplots import make_subplotsdf2018 = combDf.loc[combDf.year == 2018,:]
df2017 = combDf.loc[combDf.year == 2017,:]
df2016 = combDf.loc[combDf.year == 2016,:]
df2015 = combDf.loc[combDf.year == 2015,:]fig = make_subplots(
cols = 2, rows = 3,
column_widths=[0.5, 0.5],
specs = [[{'type': 'treemap'}, {'type': 'treemap'}],
[{'type': 'treemap'}, {'type': 'treemap'}],
[{'type': 'treemap'}, {'type': 'treemap'}]],
horizontal_spacing = 0.01,
vertical_spacing = 0.01
)
fig.add_trace(go.Treemap(
labels = df2019['prefecture'].values,
parents = df2019['year'].values,
values = df2019['avgAge'].values,
marker=dict(
colors=df2018['avgAge'],
colorscale='magma'),
textinfo = "label+value",
),row = 1, col = 1)
fig.add_trace(go.Treemap(
labels = df2018['prefecture'].values,
parents = df2018['year'].values,
values = df2018['avgAge'].values,
marker=dict(
colors=df2018['avgAge'],
colorscale='magma'),
textinfo = "label+value",
),row = 1, col = 2)
fig.add_trace(go.Treemap(
labels = df2017['prefecture'].values,
parents = df2017['year'].values,
values = df2017['avgAge'].values,
marker=dict(
colors=df2017['avgAge'],
colorscale='magma'),
textinfo = "label+value",
),row = 2, col = 1)
fig.add_trace(go.Treemap(
labels = df2016['prefecture'].values,
parents = df2016['year'].values,
values = df2016['avgAge'].values,
marker=dict(
colors=df2016['avgAge'],
colorscale='magma'),
textinfo = "label+value",
),row = 2, col = 2)
fig.add_trace(go.Treemap(
labels = df2015['prefecture'].values,
parents = df2015['year'].values,
values = df2015['avgAge'].values,
marker=dict(
colors=df2015['avgAge'],
colorscale='magma'),
textinfo = "label+value",
),row = 3, col = 1)
fig.update_layout(height = 1400, width = 1400, paper_bgcolor="LightSteelBlue")
fig.show()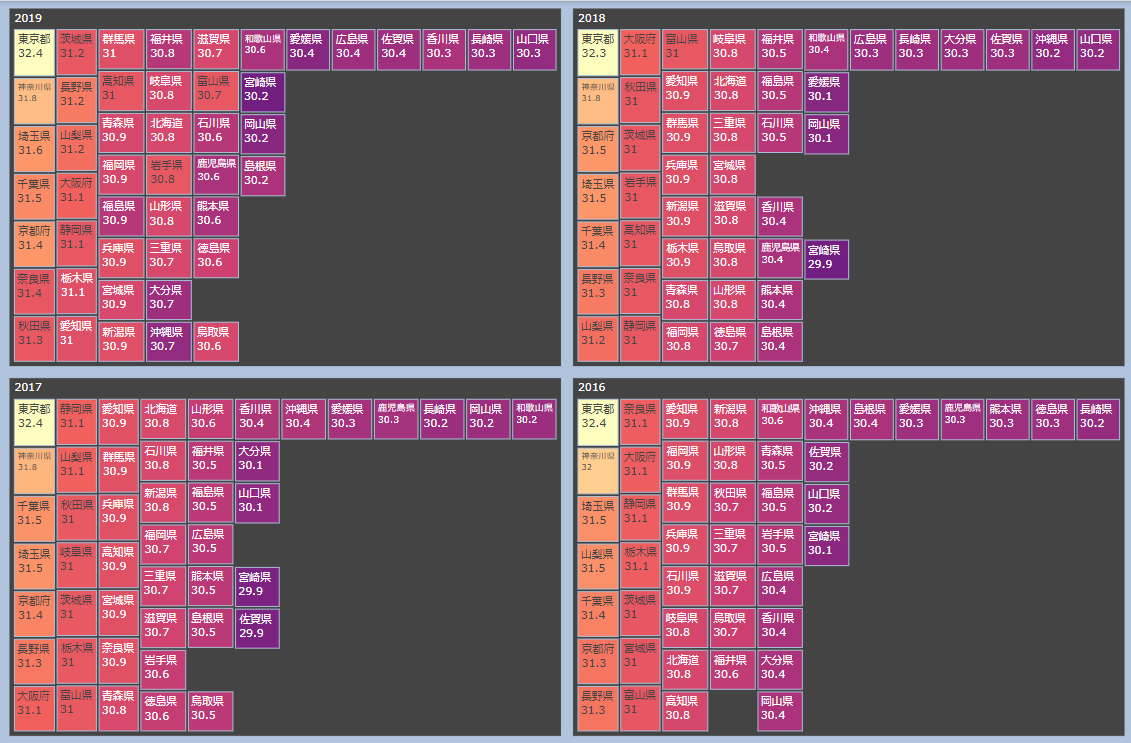

数字が出るので分かりやすいです。結局、微妙な差異はあるものの、30歳というのが一つの目安になっているようです。
平均ですので、世の中これより遅く結婚する人も早く結婚する人もいるわけです。いつ結婚するにしても、家庭円満でありたいものです。
以上でGeoPandas入門(前編)を終わります。
公式のドキュメントには様々な情報が記載されており、かなり勉強になる感じです。GISデータはRでも解析を行うことができます。Rでの地理空間情報解析の方が便利なパッケージが揃っており、かゆいところに手が届くという印象です。一方でPythonは高次元な配列情報を効率よく解析できるライブラリがある、また専門性の高い特殊なライブラリあり、そこがRに比べると強みかと思います。
汎用性ではR、機械学習+深層学習+GISとか気象データ解析ならPythonといった具合でしょうか。あくまで個人的な感想です。
汎用的な参考文献
以下はよく利用する地理空間解析のサイトです。辞書的に使えます。
PythonとGIS
ライブラリ関連
空間参照系に関して
Rでの地理空間情報解析
