【Kaggleコンペ解説連載】衛星画像による海氷と船舶の識別
データサイエンスコンペkaggleで実施された、衛星画像からの海氷と船舶抽出について、上位入賞者3名の解析手法について解説します。
皆さんはどうやってデータサイエンスを学んでいますか?
データサイエンス、特に深層学習を含めた機械学習の技術は日進月歩で発展しています。常に最新の手法を学ぶ必要があり、どの問題に対して何の手法が効果的かを知るには、本やWebサイトで情報を得るだけは限界があります。「百聞は一見に如かず」で、どんどんデータを触ることが一番の近道だと思います。
最近ではデータサイエンスコンペティション(コンペ)が世界中で行われています。これは、賞金をかけた文字通りのコンペで、一定のルールのもとで世界中のデータサイエンティストが分析スキルを競います。今回は、衛星に関連するデータについて、どのようなコンペが行われているのかを見ていきます。また、後半では具体的に一つのコンペを取り上げ、その入賞者のアプローチを考察してみたいと思います。
1. データサイエンスコンペティション
データサイエンスのコンペサイトとして最も有名なのは、Googleの「Kaggle(カグル」でしょう。
各コンペは、企業などの組織が課題設定と関連データの準備を行い、期間内に最も良い成績を収めた個人またはチームに賞金を出すものです。文字通りの“competition”(=競争)です。参加者は入賞すれば賞金が得られるだけでなく、コンペサイト上でメダルと呼ばれる称号を手にすることができ、自分のスキルレベルの客観的な目安とすることができます。一部の企業では自己研鑽の一環として社員のコンペ参加を認める動きがありますし、スキルの証明として採用要件としても活用され始めているようです。
2. Kaggleの衛星データ関連コンペ
衛星データに関しては、これまでどんなコンペが行われてきたのでしょうか。Kaggleで検索すると、内容的に衛星と関係が深そうなものが見つかります。そのいくつかをピックアップしてみます。
● Understanding Clouds from Satellite Images:雲の形のパターンを検出して分類するコンペ
● Draper Satellite Image Chronology:衛星画像を時系列に並び替えるコンペ
● Airbus Ship Detection Challenge:衛星画像から船舶を検出するコンペ
● Planet: Understanding the Amazon from Space:衛星画像の土地被覆を分類するコンペ
● Statoil/C-CORE Iceberg Classifier Challenge:衛星画像に写る物体が船か氷山か分類するコンペ
どれも主催者側の思惑が垣間見えるよう課題設定で、内容説明を読んでいるだけでも面白いです。このなかでは、最後の「Statoil/C-CORE Iceberg Classifier Challenge」が現在SIGNATEで開催中のコンペ「SARデータを用いた海氷領域の検知」に近いので、少し詳しく見ていきたいと思います。
3. Statoil/C-CORE Iceberg Classifier Challengeの概要
まず、このコンペが実施された背景として、航海安全の課題があります。航海中の船舶にとって、氷山を見つけることは安全上重要です。今は目で見て把握しようとしていますが、悪天候時には困難に。主催のエネルギー企業Statoil社(現:Equinor社)は氷山をより正確に判別したいと考え、Kaggleのコンペを開いたとのことでした。ちなみに賞金は総額$50,000(1位:$25,000、2位:$15,000、3位:$10,000)です。

「氷山の一角」の下には航海安全上の脅威が… Source : https://imgur.com/q7uAjTM
4. Statoil/C-CORE Iceberg Classifier Challengeのデータ
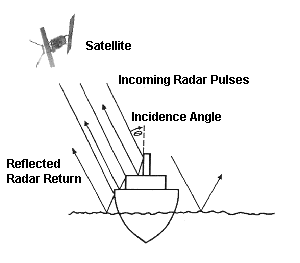
このコンペでは合成開口レーダー(SAR)衛星sentinel-1のレーダー画像(HHとHV)が提供されており、ここから画像中に氷山が含まれる確率を学習し予測するのが課題です。SARやHH、HVについては前述の宙畑の記事を参考にしてください。
画像には氷山(Iceberg)と、氷山と見分けがつきにくい船舶(Ship)が含まれているようです。まずはわかりやすい例から実際に画像を見てみましょう。


この例では船は長方形に近く、氷山は三角っぽくて何とか見分けがつきそうです。(正直、一枚だけ見せられてもわからない気がしますが…)
次にわかりにくい例も見てみましょう。


これはもうただの点です。私には絶対にわからないです。そこで、畳み込みニューラルネットワーク(CNN)等の機械学習手法を使うことで画像に含まれる形状に関する特徴や、人間にはわかりにくい反射強度の特徴等を学習することが出来るので、点にしか見えない氷山を検出することができるかもしれません。コンペ参加者には、このような75×75ピクセルの画像が、マイクロ波入射角情報と共に合計5625枚与えられます。参加者はデータから氷山が含まれている確率を学習して、未知のデータにどれくらい適用できたかを競います。
5. Statoil/C-CORE Iceberg Classifier Challengeで上位入賞者が用いた手法
このコンペは2018年1月23日に終了しており、賞金が授与される上位3名(チーム)も確定しています。
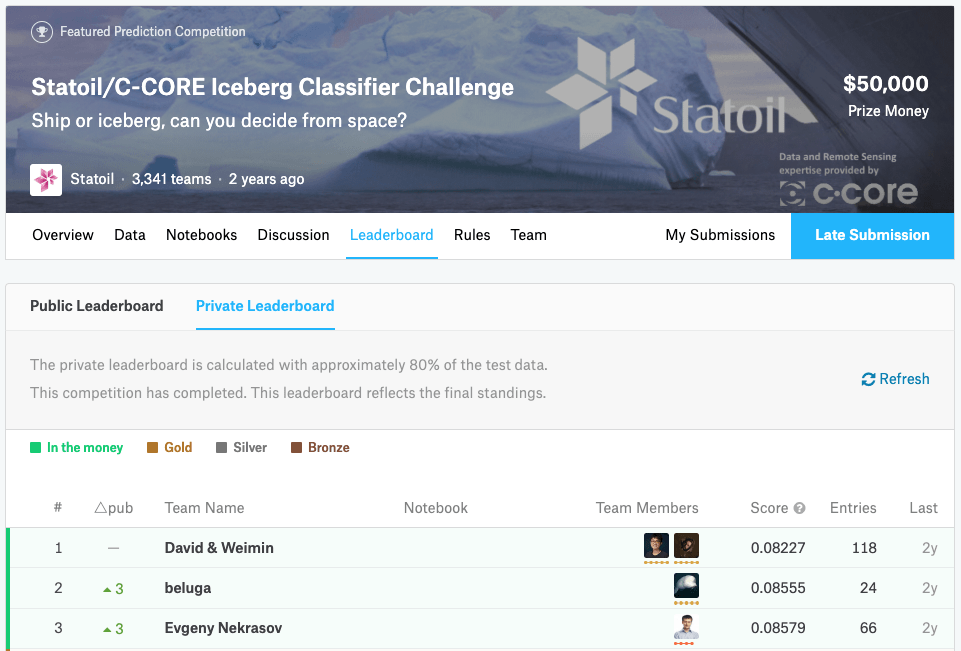
Kaggleでは上位入賞者の手法が“Discussion”のページで公開されます。トップ3名がどのように課題にアプローチしたのか、見ていきましょう。
3位入賞者の手法:
3位に入賞した方の手法はこちらのページにまとめられています。
この方は七つのモデルを用いています。なぜ複数のモデルを用いるかというと、人間でも「三人寄れば文殊の知恵」といいますが、複数のモデルの結果を総合すると結果が向上することが知られているからです。これはいわゆるアンサンブル学習とよばれる手法であり、この方はなかでもXGBoost (eXtreme Gradient Boosting)という手法をとっています。XGBoostは決定木を複数用いる(アンサンブルする)手法であり、欠測値があっても使えることや、比較的高精度で結果が得られることから、kaggle等のコンペではよく用いられます。
また、この方の報告によれば、画像データだけでなく、衛星がマイクロ波をどのような角度で照射したかという入射角(incident angle)の情報が有用だったといいます。この方は画像モデルとは別に入射角だけを扱うモデルを準備し、画像そのものに含まれるデータだけではなく、入射角も使って識別精度を向上させています。
この入射角の重要性については、コンペティション中に共有された情報のなかでも指摘されていました。その情報とは、「自動生成された画像かどうかは、入射角の数値を見れば区別がつく」というものです。少し詳しく言うと、主催者側が自動生成によってデータを水増し(data augmentation)をしていたのですが、各画像が水増しされて生み出されたデータかどうか、入射角の数値の小数点以下の桁数を確認すれば判別できるという情報でした。
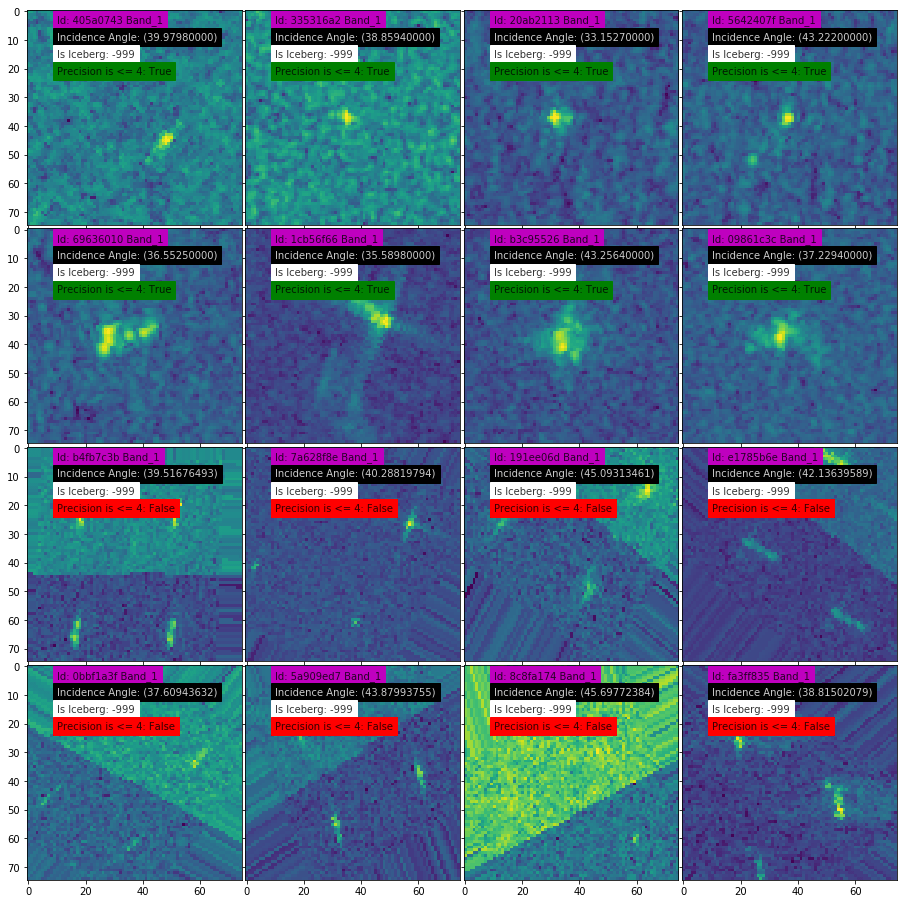
この情報をもとに、3位の方はさらに分析を進めていきます。周辺に物体がなければ船、周辺に物体が存在すると氷山の可能性が高いなど、周囲の物体の有無に着目し、その指標として入射角データが使えることに気がつきます。
これは少し不思議な話で、入射角は衛星の観測条件であり、物体があるかどうかは直接関係ないはずです。私が思うに海面に対して入射角が大きければ、海面に出ている物体の反射する表面積が大きくなるので、小さな物体でも検出できる可能性が高まります。つまり入射角が大きければ周辺に物体があるかどうか発見しやすくなるため、入射角の大小で周辺に物体があった場合により精度の高い予測がモデルの中でできたのかもしれません。
2位入賞者の手法:
2位に入賞した方の手法はこちらのページにまとめられています。
この方は数百のランダムなハイパーパラメータを持つCNN(畳み込みニューラルネットワーク)モデルを準備しました。徹底的に学習させた少数のモデルを使うのではなく、弱いモデルをたくさん用意してアンサンブルして使う戦略で、大きく三つのアプローチをとっています。
1. HHとHVの2チャンネル画像をそのまま入力するCNNを用いる。これはゼロから学習したとのこと。
2. HHとHVの画素平均値を追加して3チャンネル画像として入力するCNNを用いる。VGG16(16層からなる有名なCNNモデル)の転移学習を実施。
3. 疑似ラベルを使ってデータを倍にしたモデル(ただし、これはあまり役に立たなかったとのこと)。
この後、入射角のないデータは除外して3位の方と同じくXGBoostを用いてモデルのアンサンブルを行っていますが、3位の方よりもたくさんのモデルをアンサンブルしており、一つ一つのモデルは低い精度でもそれを数百組み合わせることで高い精度を実現しています。
この方は、最後に「私にはGPU環境がなく、それは画像処理系の課題においては辛いことです(I do not have my own GPU which is actually quite painful in computer vision challenges.)」と発言しています。この方の入賞は、CPU環境でもちゃんと工夫すれば画像をうまく学習できることを証明しているともいえ、一枚一枚のデータサイズが大きい衛星データを扱う際には見習うべき点があるように思えます。
1位入賞者の手法:
1位に入賞した方の手法はこちらのページにまとめられています。
この方の手法の概略は次のとおりです。
- VGG、GoogLeNet等の有名なモデルを含めた100以上のモデルを学習。ここには入射角を用いるモデルも含まれるとのこと。
- 1.の可視化(下図)を使って、入射角からデータを予測しやすいグループ(Group1)と予測しにくいグループ(Group2)に分ける。
- 1.のモデル群を予測しにくいグループ(Group2)のデータを使って追加学習させ、能力を向上させる。
1位の方も、2位や3位の方と同様に100以上の複数のモデルをアンサンブルしており、精度を高めるための工夫をしています。
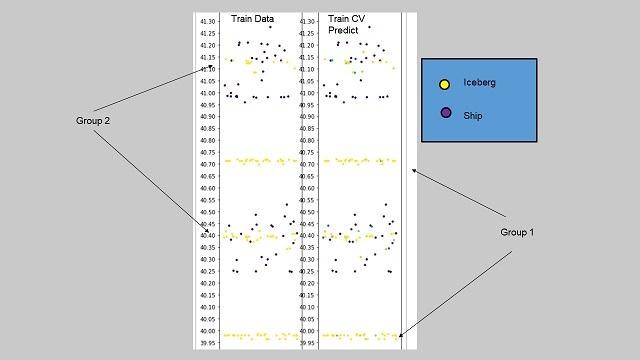
さらに1位の方は3位の方と同じく入射角に注目しています。上図は縦軸に入射角を、横軸の点が画像一枚一枚としたグラフですが、この図から海氷(黄丸)と船(紫丸)が入射角を使うことである程度分類できることがわかります。しかし、海氷と船が両方存在するような角度の範囲もあります(Group2)。そこで、一度モデルにデータをすべて学習させた後で、予測しにくいグループ(Group2)だけをさらに追加で学習させています。苦手な問題だけ集中的に解かせて、弱点を克服させたという感じです。
1位の方はモデルの構築から入るのではなく、「データの顔」をしっかり見て、それに応じた戦略を立てています。こうした、データの特徴と構造を理解する初動分析のやり方は探索的データ解析(Exploratory Data Analysis, EDA)とよばれ、データ分析の基本中の基本です。こうしたEDAと高度なアンサンブル学習を組み合わせた結果、この方は見事1位に輝いています。
6. まとめ
学生時代、私は「観測データの分析から入るな、データを可視化して“データの顔”を見ろ」に指導教官から言われてきました。今回取り上げたコンペにおける上位入賞者は全員、どのようなデータがあって各データが結果とどのような関係にあるかについて、しっかり考察したうえでデータを活用しています。どうしても派手なモデルや手法(CNNなど)に意識が向きがちな機械学習ですが、特に1位の方は「入射角」の重要性に気づき、その知見を活かすようにモデルや学習に取り入れています。事前学習をさせておいて、EDAから発見した難しいデータだけ追加学習するというこの方のアプローチは、データサイエンスのお手本といえると思います。やはり基本は大事ですね。
また上位入賞者は、複数のモデルを使うアンサンブル学習を当たり前のように使っています。一つのモデルを鍛え上げるのではなく、複数のモデルを準備してトータルスコアを高めるという発想です。沢山のモデルを扱うためアンサンブル学習では、画像を扱う場合は特に、モデルごとの学習過程含め計算コストが上がりがちです。しかし2位の方はGPUマシンなしで入賞したとのことで、有限の計算リソースを有効に活用するアプローチは本当に素晴らしいと思います。私自身もコストや機械学習環境の環境整備の煩雑さからGPU環境を使うのに非常に苦労してきたのでとても勇気づけられました。
このように、データコンペではコンペ終了後に上位入賞者のアプローチが共有されるのが普通です。上位に入賞できなくても、自分でコンペで取り組んでおけば、こうした知見を吸収することができます。機械学習の活用において正解のアプローチを見つけることは非常に難しいですが、スキルをもった人のアプローチを垣間見ることで、ある意味「答え合わせ」ができる機会は貴重です。スキルを身につけるには非常に効率が良い場だと思いますので、ぜひコンペを活用してみてはいかがでしょうか。
「Tellus」で衛星データを触ってみよう!
日本発のオープン&フリーなデータプラットフォーム「Tellus」で、まずは衛星データを見て、触ってみませんか?
★Tellusの利用登録はこちらから
