AMeDASのデータから雲海の発生予測をして実際に見に行ってみた
雲海予測をTellusのAMeDASデータを用いて行ってみました。その予測をもとに、雲海が見れるだろう日に合わせて実際に現場を訪れたところ……
2022年8月31日以降、Tellus OSでのデータの閲覧方法など使い方が一部変更になっております。新しいTellus OSの基本操作は以下のリンクをご参照ください。
https://www.tellusxdp.com/ja/howtouse/tellus_os/start_tellus_os.html
雲海という言葉を聞いたことはありますか?
標高の高い場所から下の景色を見下ろしたときに、大海原のように広がった雲を見ることができます。このような現象を海にたとえて「雲海」と呼んでいます。関西の竹田城跡や、北海道の雲海テラスなどが有名ですが、都内から比較的気軽に行けるスポットとして、秩父も雲海スポットとして近年人気を博しています。
雲海が発生するかどうかは、朝晩の気温差や風の強さ、前日の雨量によって決まります。TellusではAMeDASのデータを利用することができるので、秩父の雲海発生確率を予測した上で、実際に雲海が見られるのか検証してみたいと思います。
(1)雲海が発生する条件
雲海が発生するには、以下のような条件が整っている必要があります。
・湿度が高いこと
・前日の日中の気温と当日の朝の気温差が大きいこと
・風が強くないこと
雲海がみられることで有名なスポットには、その様子を一目見ようと大勢の方がカメラを抱えて訪れています。しかし、上記のような天候条件が複数重なる必要があることから、綺麗な雲海が見られるかどうかは、運次第というところがありました。
そこで今回は、Tellusで取得できるAMeDASのデータを活用して、雨量や風量、気温差といった気象条件を使って、雲海の発生を予測してみました。
そして、実際に雲海スポットのひとつである「秩父ミューズパーク」を訪れ、雲海が発生するかを検証も実施しています。
(2)検出方法と使用するデータの説明
TellusのAMeDASデータから
・前日の雨量
・前日の最高気温と当日の最低気温の温度差
・当日朝6時ごろの風量
を取得し、雲海が発生したか否かのデータと掛け合わせて、雲海の発生予測を行う機械学習モデルを構築してます。
予測モデルの構築には、2017年の秩父ミューズパークにおける雲海が見られた日のデータが蓄積されている「秩父地域の雲海情報・発生率」を参考に用いました。
(3)コードと結果の紹介
必要なライブラリを読み込んでいきます。
TOKENの所には、ご自身のアクセストークンで書き換えてください。
import requests, json
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
from datetime import datetime, date, timedelta
from time import sleep
%matplotlib inline
TOKEN = “[ここにトークンを貼り付ける]”
次に、AMeDASのデータを取得する関数を定義します。
def get_amedas_1min(year, month, day, hour, minute, payload={}):
"""
/api/v1/amedas/1minを叩く
Parameters
----------
year : string
西暦年 (4桁の数字で指定) UTC
month : string
月 01~12 (2桁の数字で指定) UTC
day : string
日 01~31 (2桁の数字で指定) UTC
hour : string
時 00~23 (2桁の数字で指定) UTC
minute : dict
分 00~59 (2桁の数字で指定) UTC
payload : dict
パラメータ(min_lat,min_lon,max_lat,max_lon)
Returns
-------
content : list
結果
"""
url = 'https://gisapi.tellusxdp.com/api/v1/amedas/1min/{}/{}/{}/{}/{}/'.format(year, month, day, hour, minute)
headers = {
'Authorization': 'Bearer ' + TOKEN
}
r = requests.get(url, headers=headers, params=payload)
if r.status_code is not 200:
print(r.content)
raise ValueError('status error({}).'.format(r.status_code))
return json.loads(r.content)
上記で定義した関数を使って、予測対象である秩父地域の気象情報を取得するため、秩父観測所(観測所番号:43156)だけを抽出する関数を別途定義します。
また、下記コードの注意点として、60分 × 24時間 × 31日間 = 44640回のAPIアクセスが発生します。APIサーバへの負荷軽減のため0.5秒に一回だけアクセスするように制限をかけているため、44640 × 0.5 ÷ 60 = 372分かかります。下記コードによるAMeDASデータCSVファイルの作成処理は気長に待ちましょう。なお、計算時間を省略したい方は下記で生成するデータをこちらからダウンロードいただけます。
# 秩父の観測所番号(43156)のデータだけを取り出す
def filter_chichibu(data):
CHICHIBU_CODE = '43156'
return list(filter(lambda x: str(x['station']['prefecture_no']['value']).zfill(2) + str(x['station']['observatory_no']['value']).zfill(3) == CHICHIBU_CODE, data))[0]
chichibu_march = []
# 秩父の観測所の緯度経度(北緯35度59.4分 東経139度4.4分)を含む範囲を指定
payload = {
'min_lat': 35,
'min_lon': 139,
'max_lat': 36,
'max_lon': 140
}
# 秩父の観測所の2017年3月の観測データを1分間おきに取得する
for day in range(1, 32):
for hour in range(0, 24):
for min in range(0, 60):
chichibu = filter_chichibu(get_amedas_1min('2017', '3', str(day), str(hour), str(min), payload))
chichibu_march.append({
"datetime": datetime(2017, 3, day, hour = hour, minute = min), # 日時
"rain": chichibu['rain']['intensity']['value'] / 10, # 雨量
"wind": chichibu['wind']['velocity_ave']['value'] / 10, # 風量
"temperature": chichibu['temperature']['deg']['value'] / 10 # 気温
})
# APIへの負荷軽減のため、500msごとにアクセスする
sleep(0.5)
df = pd.DataFrame(chichibu_march)
df.to_csv('data.csv', index = False)
2017年3月の秩父観測所のデータをCSVファイルにまとめられたところで実際に読み込んでみましょう。
df = pd.read_csv('data.csv')
df.head()
3月の雨量、風量、気温のデータが分刻みで表示されています。
予測したいのは日にちごとの雲海が発生する確率ですので、日付と時刻を分割します。
# 年月日と時刻を分割する
df[['date', 'time']] = df['datetime'].apply(lambda x: pd.Series(str(x).split()))
df.head()
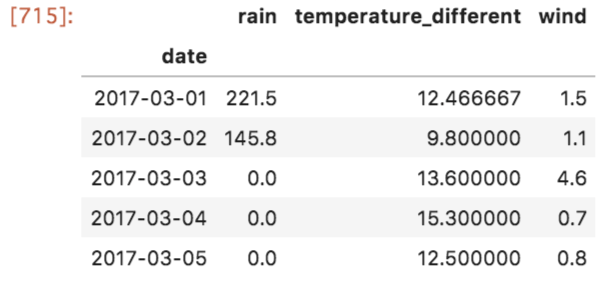
次に前日の雨量を求めます。
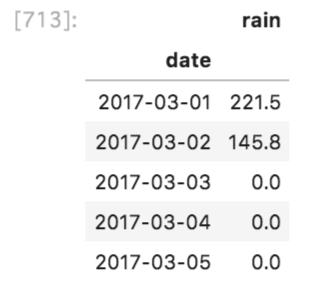
# 雨量は一日ごとの合計を求める
daily = df.drop(['datetime', 'wind', 'temperature'], axis = 1).groupby(['date']).sum()
daily.head()
次に前日との気温差を求めます。
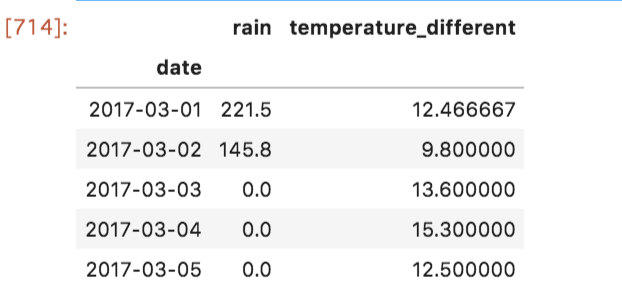
# 前日との気温差を求める
diffs = []
for date_str, v in daily[1:].iterrows():
format = "%Y-%m-%d"
day = datetime.strptime(date_str, format)
yesterday = day - timedelta(days = 1)
yesterday_str = yesterday.strftime(format)
# 前日の最高気温
max_temperature = df[df['date'] == yesterday_str]['temperature'].max()
# 当日の最低気温
min_temperature = df[df['date'] == date_str]['temperature'].min()
# 前日の最高気温 - 当日の最低気温
diff = max_temperature - min_temperature
diffs.append(diff)
# 初日は前日のデータがないため、全データの平均値を設定しておく
mean = sum(diffs) / len(diffs)
diffs.insert(0, mean)
daily['temperature_different'] = diffs
daily.head()
風力に関しては当日の朝6時のデータを採用します。
# 風向きは当日の06:00:00のものを使用する
winds = df[df['time'] == '00:06:00'][['date', 'wind']].set_index("date")
daily['wind'] = winds
daily.head()
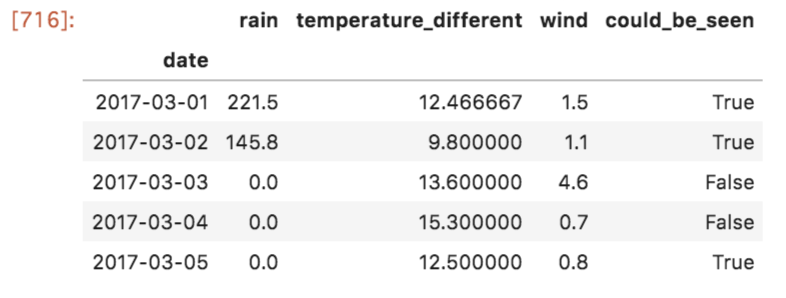
次に、「秩父地域の雲海情報・発生率」に掲載されている
「2017年:秩父ミューズパークの雲海発生状況(PDF)」 のうち、「よく見えた」「まずまず見えた」日を雲海が発生した日としてフラグを立てます。こちらの「見えた/見えなかった」のフラグが今回予測する対象となります。
could_be_seen_dates = [
'2017-03-01',
'2017-03-02',
'2017-03-05',
'2017-03-06',
'2017-03-13',
'2017-03-15',
'2017-03-27',
]
flags = [i[0] in could_be_seen_dates for i in daily.iterrows()]
daily['could_be_seen'] = flags
daily.head()
ここまでで事前準備は整いました。
それではscikit-leranという機械学習ライブラリを使って、雲海の発生予測モデルを作ってみましょう。今回は「決定木」と呼ばれるモデルを使用します。決定木モデルでは、どのようなルールで分類したかを確認することができるため、後ほど雲海の発生条件も確認してみたいと思います。
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth=5)
X_train = daily.drop(['could_be_seen'], axis=1)
y_train = daily['could_be_seen']
model.fit(X_train, y_train)
DecisionTreeClassifierを読み込み。fit関数で学習を行います。
これでモデルの構築は完了です。
それでは実際に秩父の天気予報から雲海が発生するか予測してみます。予測には下記の秩父の3月5日の天気予報を参考にデータを作成します。
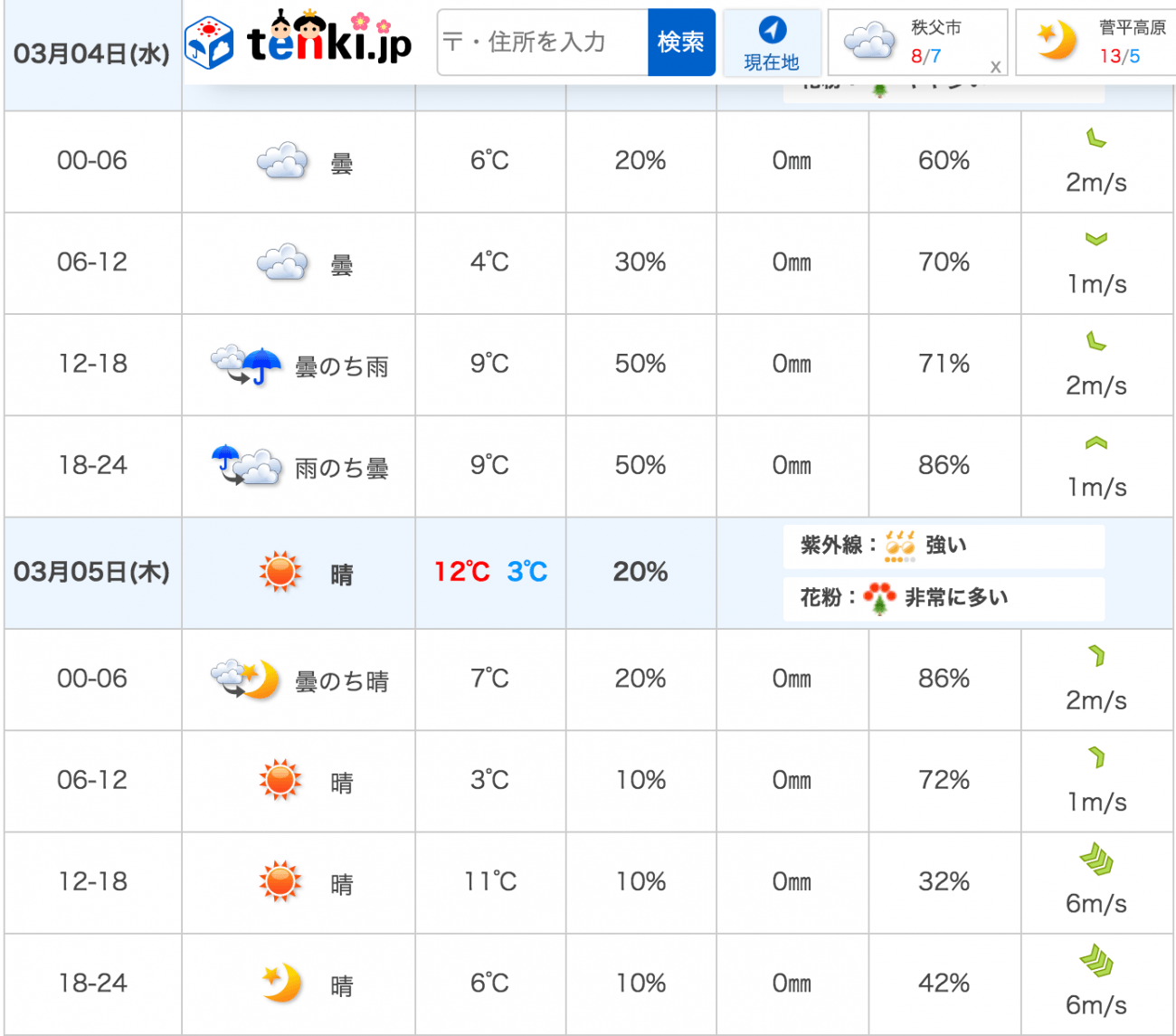
・前日の雨量合計:0mm
・前日の最高気温と当日の最低気温の差:6℃(9℃-3℃)
・当日6時台の風力:1m/s
として、モデルに予測させるデータを準備します。
X_test = pd.DataFrame([[0, 6, 1]],
columns = ['rain', 'temperature_different', 'wind'],
index=["2020-03-05"]
)
y_pred = model.predict(X_test)
y_pred

予測の結果は「発生する」と出ました。
学習に使ったデータ数が2017年3月(=31日分)と少ないので、予測精度に関しては決して高いとは言えませんが、雲海が見られる可能性はゼロではなさそうです。
このモデルがどのように分類を行なっているのかを可視化できるdtreevizライブラリを使って、分類ルールを確認してみます。
分類ルールの可視化には、dtreepltというライブラリを使いますので、まずはそちらを読み込みます。
参考:[Python]Graphviz不要の決定木可視化ライブラリdtreepltをつくった
# 必要なライブラリをインストール
!conda install git+https://github.com/nekoumei/dtreeplt.git
from dtreeplt import dtreeplt
dtree = dtreeplt(
model=model,
feature_names = daily.columns,
target_names = 'could_be_seen'
)
fig = dtree.view()
出力された画像を確認してみましょう。
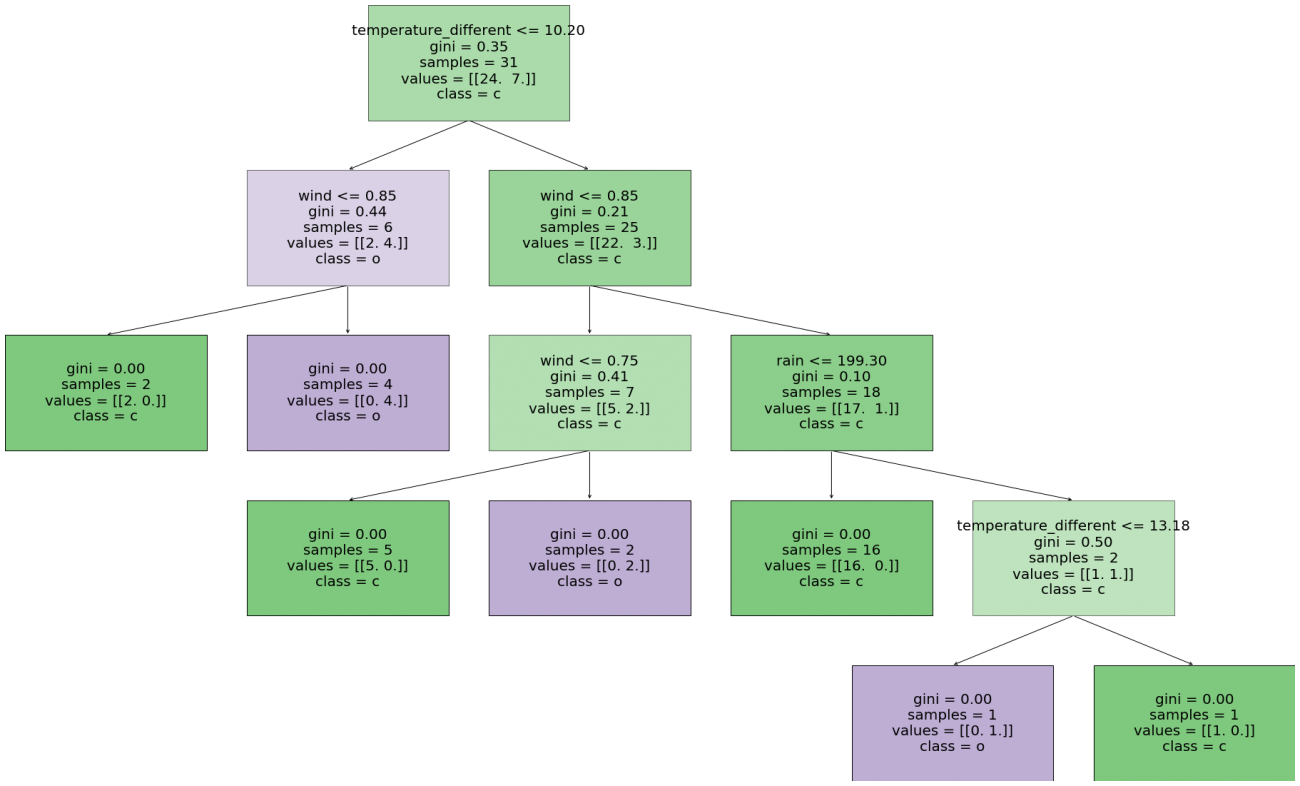
一番左の枝に注目してみますと、最初に「気温差」が10.2℃以上か、それより低いかでグルーピングした後、風力が0.85より低ければ雲海が発生する、それ以上であれば発生しない、と分類していることが読み取れます。
このように決定木モデルでは分類ルールを可視化することができます。
(4)実際に予測通り雲海を拝めるのか、現場を訪れてみた
構築したモデルでは3月5日は雲海を見ることができると予測されましたが、果たして本当に見ることができるのか、実際に目で見て確認するために秩父へと出かけて検証しました。
予測した日付の前日である3月4日にレンタカーを借りて、秩父に向けて出発します。
この日の夜はゲストハウスで宿泊しました。

なかなか味のあるゲストハウスでした。
早々にチェックアウトを済ませて、Twitterにて「雲海発生予測」をチェックします。
明日(2020/03/05)早朝の秩父地方の雲海発生確率は64%です。#秩父雲海 詳細情報→翌朝の天気:晴、予想最低気温:2.0度、露点:5.7度、現在湿度:93.0、本日の降水量合計:0.0mm、風の状況:○
— 秩父の雲海予報 (@chichibu_unkai) March 4, 2020
観測予定日の雲海発生確率は64%とのこと。これは期待できるのでは……!

さて、朝を迎えてこの日は5時起き。今回の目的地である「秩父ミューズパーク」へ向けて車を走らせます。霧が立ち込める中、ヘッドライトを頼りに細い道を進んで行きます。

秩父ミューズパークの第10駐車場に着き、車を止め、少し歩くと展望台。展望台を登ってみると、同じく雲海を見に来た人がちらほらと。肝心の雲海はというと……。

うっすらともやがかったぐらいには見えております。
ですが「雲の大海原」と言えるほどには発生していないかな、という状況……まだ日も昇りきっていないので少し待ってみます。

日の出とともに、少しずつ雲海っぽくなってきた気がします……!

ところどころ街並みは見えているので、視界全体を覆うほどの雲海というわけではないですが、なかなか幻想的な雲海を見ることができたと思います。
「秩父地域の雲海情報・発生率」に記載されている「まずまずみれた」に当たるレベルには雲海が発生したと言えるのではないでしょうか。

雲海の中に佇む武甲山が雄々しく見えました。

(5)まとめ
AMeDASのデータを使って雲海の発生を予測してみました。そして現地を訪れ、実際に雲海をこの目で見ることができました。
今回は事前の予測通りに雲海を目にすることができましたが、雲海発生の確率をより精度よく予測するためには、もっと大量のデータが必要になると思います。今回は考慮に入れませんでしたが、当日の湿度などその他の条件も考慮に入れて学習モデルを構築してみたらより精度が高まるかもしれません。
また、AMeDAS以外のその他の情報、衛星画像が捉えた雲の分布や被雲率などを説明変数に入れることでも精度の良いモデルが作れるかもしれません。
ぜひ、本記事を参考にいろいろとお試しいただければと思います。
