シャープ独自開発の深層学習モデルによる衛星画像の超解像処理
超解像とは、元々の画像の解像度を擬似的に上げる技術のことです。機械学習分野における超解像は注目分野のうちの一つですが、衛星画像に超解像を適用するとどうなるのか、その技術や将来性について、シャープ株式会社研究開発事業本部 通信・映像技術研究所 第三研究室 課長・猪飼知宏さん、研究員・佐々木瑛一さんに伺ってきました。
xData Allianceに参画し、さくらインターネットとともに衛星データ利活用を進めるシャープ株式会社。本記事では、アライアンスの枠組みの中で取り組んでいる、機械学習による衛星画像の超解像についてご紹介します。
超解像とは、元々の画像の解像度を擬似的に上げる技術のことです。


機械学習分野における超解像は注目分野のうちの一つですが、衛星画像に超解像を適用するとどうなるのか、その技術や将来性について、シャープ株式会社(以下、SHARP)研究開発事業本部 通信・映像技術研究所 第三研究室 課長・猪飼知宏さん、研究員・佐々木瑛一さんに伺ってきました。
(1)SHARPと超解像
-そもそもなぜ、SHARPで超解像技術をやられているのでしょうか?

佐々木さん:
まず弊社の事業内容として、今キーワードとして挙げているのが8Kになります。このキーワードは弊社が液晶ディスプレイ(テレビ)事業を主力の1つとしていることがスタートラインとなっていますが、ディスプレイだけではなく、撮影や伝送など8Kを取り巻くエコシステム全体をターゲットとして見据えています。あとは、AIとIoTを組み合わせたワードである「AIoT」というものをキーワードに今、事業展開をしております。
例えば、今の地上波のテレビを観ようとすると、8Kの放送は、限られた放送局でやられている8Kの番組以外は8Kの映像は流れてこないので、フルHDの映像とか4Kの映像を映すときにはアップコンバーター(*1)が必要になります。
8Kを観たいんだけども、8Kコンテンツを持っていない方も多いので、それをどのように綺麗に表示するかという点で、「超解像」は必須になる技術です。
*1:足りない解像度を疑似的に上げる装置
– お二人はご専門は機械学習なんでしょうか?
猪飼さん:
元々専門は、機械学習というより映像処理全般で、映像を効率的に伝送したり高品質に表示したりするところなんですが、ここ3年くらいは映像処理に深層学習が良いということが言われていて、研究に取り組んでいます。
実際、100パラメータぐらいだったら、人間がチューニングしたほうが性能がいいんですけど、1万パラメータ、100万パラメータになると、深層学習の方が圧倒的に性能が良いですからね。
(2)背景ー超解像と衛星画像はベストフィット!?
– そもそも衛星画像を超解像してみよう、というのはどういった理由だったのですか?
佐々木さん:
近年、「ビッグデータ」というキーワードで、いろいろ世の中に存在しているデータをもっと有効活用しましょうという機運が高まってきていて、当然弊社におきましても同じ流れがあり、衛星データもその中のビッグデータの1つとして、我々としても非常に興味がありました。
猪飼さん:
たまたまTellusさんとお話する機会がありまして、その機会の中で「何かSHARPの技術で一緒にやれないか」という話になり、もともと我々はずっと超解像をやっていましたので、我々の持っている技術とフィットするということになりました。
– 衛星画像と聞いてどのような印象を持たれましたか?
猪飼さん:
超解像やディープランニングの精度を高めるには、データがたくさんにあるかどうかということが大事だと思っています。
特に、論文などでは顔の超解像など、ある特定の種類の画像に特化して多くのデータで学習すると、非常に驚くべき成果が出てくるということが分かっています。
地図データや航空写真、衛星画像でも、そういった画像に特化した超解像モデルを開発出来たら、そのオブジェクトを精度よく抽出できるのではないだろうかと思いました。
精度よく抽出できればその成果は物体検知の精度向上にも使えるので、超解像と衛星画というのはベストフィットするのではないか、と考えたのです。
(3)アルゴリズム概要ー複雑な画に強い超解像モデル

– 今回衛星画像の超解像の条件を教えてください。
佐々木さん:今回は教師データとして15枚の高解像度の衛星画像(IKONOS(いこのす)、分解能3m)を使い、超解像をかける画像として、低解像度の衛星画像(AVNIR-2(あぶにーるつー)、分解能10m)の画像を使って、人の目で見て綺麗だと思えることを目的として、超解像を行いました。
超解像自体は、RGBを使えれば輝度単体のみ利用する場合よりもそちらの方が基本的に性能が良いといわれているので、今回はRGBの画像を入力に利用しました。先行研究[1][2]も基本それを使っているので、色のコンポーネントとしては、輝度だけでなく3色の世界でやっています。
猪飼さん:
社内ですでにあった複数のモデルの中から衛星画像の複雑性を考慮して、複雑な画の超解像に強いモデルを選択しました。
深い層になっても学習できるようにいわゆる残差構造やスキップコネクション的なものも入れており、アクティベーション関数も高性能と呼ばれるReluの亜種を使用しました。途中パラメータ数が爆発しないように絞る処理もあります。特徴を捉える能力が向上した分、後述のSRCNNと比べ小さな物体の再現がかなり向上しています。
– どのようにして開発を進められたのでしょうか?
猪飼さん:まず、世の中でよく知られている一般画像(DIV2K)のデータセットで学習してみて、衛星画像のデータセットで学習するのと違いがあるかということを確認しました。

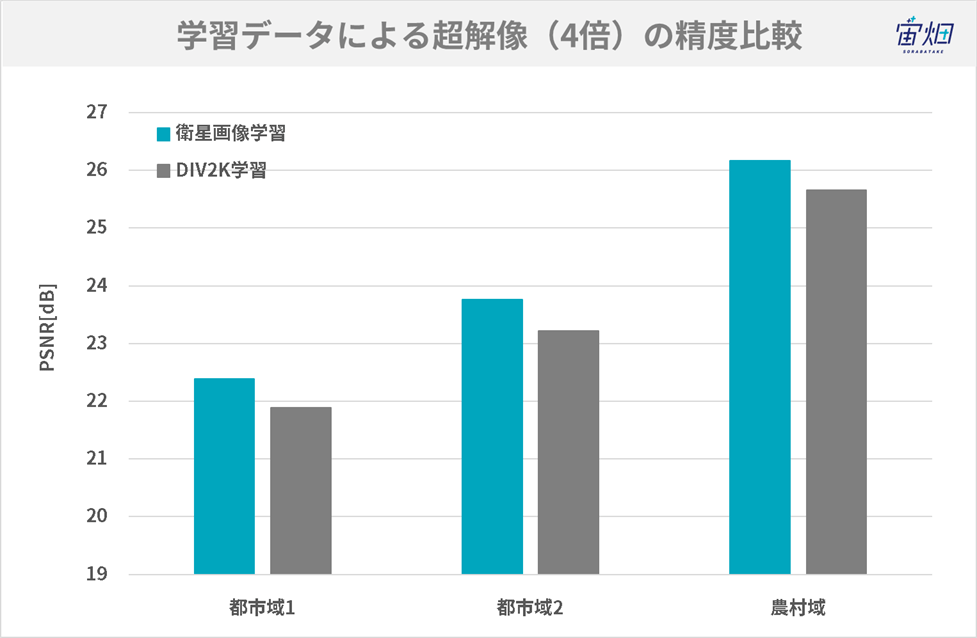
猪飼さん:そうしたところ、圧倒的に違う結果になりました。
一見すると、一般画像(DIV2K)で学習させたモデルでも衛星画像で学習させたモデルでもいい画は出ているんですけども、オブジェクトの細かいところを見れば見るほど、違いがはっきりわかると。衛星画像の超解像は学習データによる違いが大きいというのは最初の段階でわかりました。
コスト関数であるPSNR(Peak signal-to-noise ratio)上ももちろん利用しているのですが、画を見るとPSNRの値以上に差が出るという感じがしました。
使うモデルを決めて、学習データを決めたらもうすぐ終わりじゃないかと思ったんですけど、そのあとがけっこう長くてですね。パラメーターチューニングの嵐をずっと繰り返していました。
– パラメータのチューニングは何に時間が掛かったのでしょうか?
猪飼さん:結局、PSNRではない違うコスト関数を入れているんですけれども、その調整が今までの画像とちょっと違っているところがありまして。
というのは、衛星画像によって、「こっちの画ではいいんだけれども、こっちの画では駄目だ」っていうところがありまして。我々のほうで、いろいろな衛星データを見て、みんな総合的にいい画を出すということが難しいかったかなと思っています。
– 都市部と地方などで様子が異なるというのもその一つですか?

Original data provided by JAXA
猪飼さん:結局難しいのは都市部で、他はそこまで別に何かをしなくても大丈夫だなという結果でした。
都市部はけっこう綺麗な——建物なら四角っぽくて、道だったら線がきちんと伸びているという超解像をしたいんですけど、ノイズのある画を入れた場合に、例えば、ノイズであったり造語ですけれども2線化って言ってもいいのか、線が2本になってしまうようなときがありまして。例えば本当は1本の道路のはずなのに、そこを勝手に2本に増やしてくるとか笑
– 総合的にいい画を出すために、どういった評価をされたんでしょうか
佐々木さん:基本的には、手で何パターンも試して、目で見てということをやりましたですね。今回手でやって、数をとにかくこなして。数値は出てくるんですけども、主観で答えを見ないと結果わからないので。
NIQEというコスト関数が一般的に論文で使われているので我々も試したのですが、正直変なオブジェクトを出しても、それが本物っぽければいいという、嘘を作ってもNIQEはいい値になってしまって、それは我々の用途には合わないだろうということで結局、参考値以上には使いませんでした。
– 実際に得られた結果を教えてください。


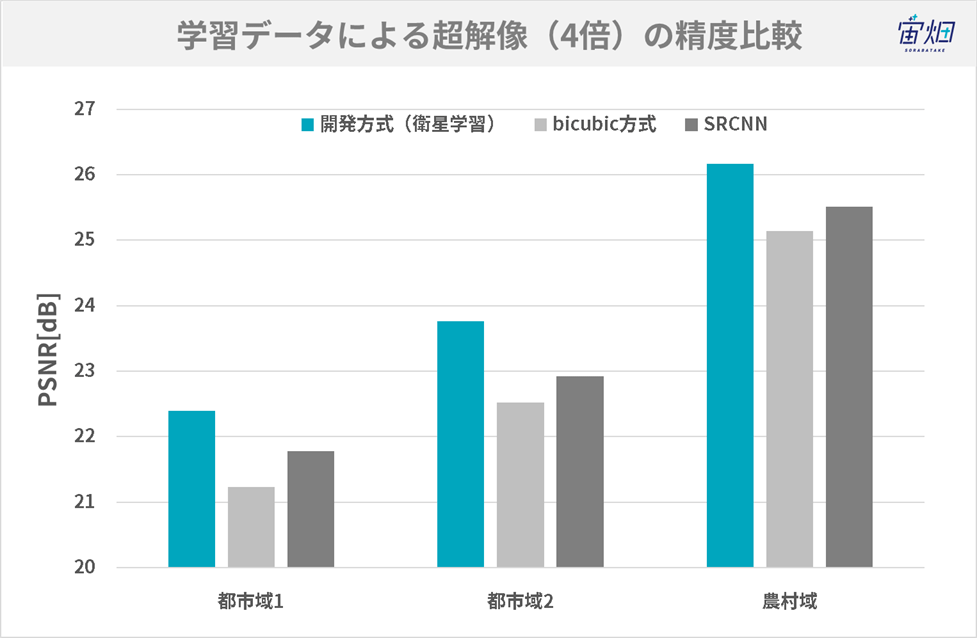
画像の例とPSNR等の評価結果は上の通りです。単純に3次関数で補間(bicubic拡大)した場合と比べて、かなり鮮明になっていることが分かります。特に農村域(IKONOS-2)で高い値が出ています。
また、素朴なAI超解像方式であるSRCNNと比較して、今回のモデルが良い値を示していることが分かります。特に、複雑な都市部での超解像で差が顕著です。程度問題ですが、パラメータ数は正義であるといえましょう。
(4)衛星データの色味やノイズの影響に苦戦
– 衛星画像ならではの難しさはありましたか?
佐々木さん:衛星に搭載されているカメラの性能が違って、絵柄とか色味とかが、そのときどきで全然違ったりもするようなので、その点は苦労しました。
研究で使われる一般のデータセットは、かなり編集が施された、すごいノイズのない綺麗な画なんですよね。今の衛星画像って、まだノイズが残っていたり、センサによって特色が変わる可能性のある、生に近いものを扱うことが多いように見えていて。
そういうものの種類が違うものが入ってきたときに出方の違いに対して、同じ超解像をかけたときに、どうしてもうまくいかないときがあるのかなと思います。
– ノイズの影響が大きかったということですね。
佐々木さん:要は超解像するときって、すごい細かい点を見て、「こういうもののはずだ」って推論するんですけど、そこってノイズの影響受けちゃって、学習したときのノイズ感と違うものがあったときに、それは「学習したときはこういう形だったはず」っていって推論しちゃうと、違うものを出す可能性が高い。
単純に、ノイズなのか、本物なのかわからなくなっちゃうっていうところですかね。
– そのために学習用のデータに何か工夫をされたのでしょうか。
猪飼さん:一般画像(DIV2K)を少しだけ入れました。衛星に悪影響を与えない範囲で。
どんな衛星画像が入ってくるかわからない段階では、ほんの少しユニバーサルの方に振ったほうが安全じゃないかと考えたためです。学習の際、地図画像で学習して地図画像が入ってくればもちろんいい画が出てくるわけですけれども、今回の場合、学習した高解像度の衛星画像とインプットに使う別の低解像度の衛星画像では、異なる色味や異なる形が入ってくるわけで。それを考えると、ほんの少しだけ違う画を混ぜてバリエーションを増やしたほうが安全かなと。
佐々木さん:実際に今回は高解像度の衛星画像で学習したネットワークを利用して、最後、低解像度の画像から答えのない状態の超解像をするっていうことをしましたけども、やはり出ている画像を安定させるためには、そういった混ぜ物をしたほうが安定していた感じはしています。衛星画像間でも。
(5) 超解像×衛星データで物体認識の精度を上げる
– 今回開発したアルゴリズムを使ってどんな応用が考えられるのでしょうか。
佐々木さん:今回は単純に目視で綺麗な画を出すということにフォーカスしてやりましたが、最終的にはビッグデータを活用する文脈において、衛星映像を使って何か認識するとかいったときに、その精度を上げる一助になっていたりすると1番嬉しいなと思います。
そのままの衛星の映像を認識の何かに入れたときの精度よりも、画像データの前処理として超解像をかけて、画像解析するとデータ容量としては大きくなってしまうけれども性能があがるとか、そういう話が想定できます。
– 例えばTellusだと船舶検出だったりとか、あとは海氷の検出とかのコンテストをやっていたりしますが、そういったところの精度が上がると期待できる、みたいな感じですか?
猪飼さん:そうですね。Tellusさんでやっている認識系のアルゴリズムを我々も使うことができたら面白いかもしれないですね。今回のように「人間の目で見てよさそう」みたいな、「自然そう」みたいな話をしているところから、認識系のアルゴリズムをかませると、その認識の正答率で評価ができるようになるので。
– 他にやってみたい解析はありますか?
佐々木さん:衛星データはマクロなデータなので、空間的な話というよりも、時間的な方向をうまく機械学習で扱えると、良いのかなと思います。「時間方向の変化がどういうことがあったから、こういうことが言える」というのがあると思うんです。そこのデータをうまく集められて、ニューラルネットワークで使ってうまく使って学習できると、面白いデータが出てきたりするかもしれないなとは思いますね。
過去の衛星画像が何枚かあって、それを使って未来を予測するとか、そういう話になると思います。
(6)まとめ
今回SHARPさんが行われた衛星画像の超解像についてまとめると、以下の3点です。
・衛星画像の超解像では、一般画像だけではなく衛星データで学習させることで結果が改善する。
・都市部など複雑な物体の超解像は難しく、PSNR等の一般的なコスト関数だけでは見た目の綺麗さを評価しきれず、目視による調整が必要だった。
・衛星画像はノイズの影響が大きく衛星ごとに色味が異なるため、一般画像による学習を少し混ぜた方が安定する。
今回の超解像では、人の目で見て綺麗に見えるということを目的にしましたが、衛星画像は衛星ごとに色見が異なり、一般画像と比べてノイズも多いためパラメータの調整は一筋縄では行かないという課題があります。
宇宙業界側の視点で見ると、ここ10年で打ち上げられる衛星の機数が増え、生成される衛星画像が爆発的に増えて行く中で、人の目で見て画像の中に写っているものを1枚1枚判断していくことには限界があると考えられ、超解像によって物体識別の精度が高められることが期待されます。
海外でも、例えば欧州の衛星データプラットフォームUP42で中解像度の衛星画像から超解像を行う技術が研究されています。

https://medium.com/up42/quadruple-image-resolution-with-super-resolution-6e5cbab81cd7
また、2019年だけでも衛星画像の超解像について論文が増えてきています。
https://www.mdpi.com/2072-4292/11/13/1588
画像系の機械学習をやられている方はぜひこの機会にチャレンジして見てはいかがでしょうか?
「Tellus」で無料の衛星データを触ってみよう!
日本発のオープン&フリーなデータプラットフォーム「Tellus」で、まずは衛星データを見て、触ってみませんか?
★Tellusの利用登録はこちらから
