SRCNNを用いて衛星画像の超解像にチャレンジしてみた【コード付き】
今回の記事では実際にTellusを用いて、衛星データに対して超解像をやってみようと思います。
2022年8月31日以降、Tellus OSでのデータの閲覧方法など使い方が一部変更になっております。新しいTellus OSの基本操作は以下のリンクをご参照ください。
https://www.tellusxdp.com/ja/howtouse/tellus_os/start_tellus_os.html
記事作成時から、Tellusからデータを検索・取得するAPIが変更になっております。該当箇所のコードについては、以下のリンクをご参照ください。
https://www.tellusxdp.com/ja/howtouse/access/traveler_api_20220310_
firstpart.html
2022年8月31日以降、Tellus OSでのデータの閲覧方法など使い方が一部変更になっております。新しいTellus OSの基本操作は以下のリンクをご参照ください。
https://www.tellusxdp.com/ja/howtouse/tellus_os/start_tellus_os.html
先日、超画像×衛星画像でできること。関連論文の紹介とTellusでやるにはという記事で、超解像の様々な手法についてご紹介しました。今回の記事では実際にTellusを用いて、衛星データに対して超解像をやってみようと思います。
超解像とは、低解像度の画像(ぼやぼやしている画像)を擬似的に高解像度の画像(はっきりモノが見える)に変換する技術のことをいいます。

特に衛星画像で高い分解能を得ることは難しいので、このような超解像の技術が非常に役に立ちます。超解像によって、衛星画像に何が写っているかをヒトが認識しやすくなるというのはもちろんですが、それに加えて、機械学習による物体検知の精度が上がることなども期待されています。
参考: The Effects of Super-Resolution on Object Detection Performance in Satellite Imagery
超解像を行うには様々な手法がありますが、今回は特にSRCNNという単一画像超解像の基本的な手法を用いてみます。実装には、機械学習ライブラリ、Kerasを用います。
1. SRCNN(Super-Resolution Convolutional Neural Network)の概要
SRCNNはChao Dongらによって2014年に提示された手法で、論文はこちら。SRCNNは、名前の通り超解像(super resolution)にCNNを用いる手法です。それまでは、超解像にCNNは用いられてこなかったため、これはとても革新的な手法として受け止められました。
このSRCNNは低解像度画像をインプットとして受け取り、それを高解像度の画像に変換(マッピング)します。このマッピングの仕方を、学習データを用いて学習します。
SRCNNの凄いところはなんと言ってもシンプルなところ。出力層を含めてもたったの3層しかありません。1層目はパッチの抽出、2層目は非線形マッピング、3層目は再構築に対応しています(下図)。
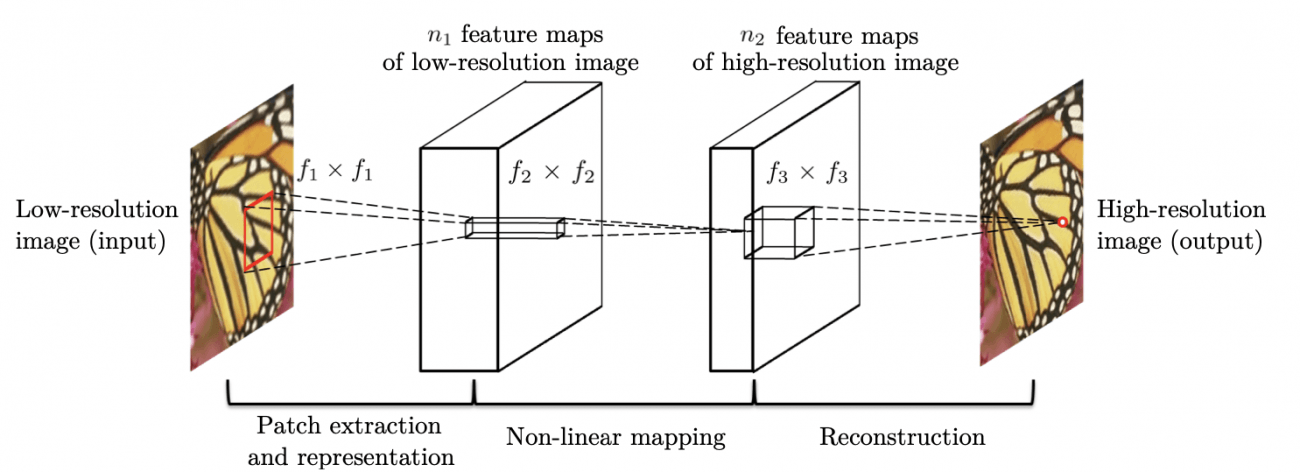
2. 衛星データの取得
さっそくTellusの開発環境を使って超解像を行っていきましょう。
※Tellusの利用登録はこちらから
衛星データはASNARO-1のものを使います。TellusのAPIにより、ASNARO-1のデータを取得するための詳細な方法については、こちらの記事をご参照下さい。
また、以降の内容は基本的にはTellusの開発環境(Jupyter Lab)で実行します。Jupyter Labを使う方法は「Tellusの開発環境でAPI引っ張ってみた」で確認できます。
まず「Data_ASNARO1_SRCNN」というディレクトリを作った後に、以下のコードを実行してください。
import os, json, requests, math
from skimage import io
from io import BytesIO
import matplotlib.pyplot as plt
import warnings
import random
import numpy as np
%matplotlib inline
random.seed(0)
TOKEN = "(トークンを貼り付ける)"
def get_ASNARO_scene(min_lat, min_lon, max_lat, max_lon):
url = "https://gisapi.tellusxdp.com/api/v1/asnaro1/scene" \
+ "?min_lat={}&min_lon={}&max_lat={}&max_lon={}".format(min_lat, min_lon, max_lat, max_lon)
headers = {
"content-type": "application/json",
"Authorization": "Bearer " + TOKEN
}
r = requests.get(url, headers=headers)
return r.json()
def get_tile_num(lat_deg, lon_deg, zoom):
#ズーム率と点(緯度、経度)を与えたときに点を含むタイル座標を求める
lat_rad = math.radians(lat_deg)
n = 2.0 ** zoom
xtile = int((lon_deg + 180.0) / 360.0 * n)
ytile = int((1.0 - math.log(math.tan(lat_rad) + (1 / math.cos(lat_rad))) / math.pi) / 2.0 * n)
return (xtile, ytile)
def get_tile_bbox(z, x, y):
#タイル座標(z, x, y)に対して、その画像の左下と右上の緯度経度を返す。
def num2deg(xtile, ytile, zoom): #https://wiki.openstreetmap.org/wiki/Slippy_map_tilenames#Python
n = 2.0 ** zoom
lon_deg = xtile / n * 360.0 - 180.0
lat_rad = math.atan(math.sinh(math.pi * (1 - 2 * ytile / n)))
lat_deg = math.degrees(lat_rad)
return (lon_deg, lat_deg)
right_top = num2deg(x + 1, y, z)
left_bottom = num2deg(x, y + 1, z)
return (left_bottom[0], left_bottom[1], right_top[0], right_top[1])
def get_ASNARO_image(scene_id, zoom, xtile, ytile):
url = " https://gisapi.tellusxdp.com/ASNARO-1/{}/{}/{}/{}.png".format(scene_id, zoom, xtile, ytile)
headers = {
"Authorization": "Bearer " + TOKEN
}
r = requests.get(url, headers=headers)
return io.imread(BytesIO(r.content))
# 関東近辺のシーンを取得する。
scene = get_ASNARO_scene(35.2, 138.0, 37.1, 140.5)
# 得られたシーン群の中からランダムに30つ選ぶ。
random_scenes = random.sample(scene, 30)
# ズーム率17で各シーンから切り出せるタイル画像を最大300枚まで取得する。
zoom = 17
for scene in random_scenes:
count = 0
(xtile, ytile) = get_tile_num(scene['max_lat'], scene['min_lon'], zoom)
x_len = 0
while(True):
bbox = get_tile_bbox(zoom, xtile + x_len + 1, ytile)
tile_lon = bbox[0]
if(tile_lon > scene['max_lon']):
break
x_len += 1
y_len = 0
while(True):
bbox = get_tile_bbox(zoom, xtile, ytile + y_len + 1)
tile_lat = bbox[3]
if(tile_lat 0.99):
with warnings.catch_warnings():
warnings.simplefilter('ignore')
io.imsave(os.getcwd()+
'/Data_ASNARO1_SRCNN/{}_{}_{}.png'.format(zoom,
xtile + x, ytile + y), img)
count += 1
except Exception as e:
print(e)
#取得枚数が300枚を超えたら次のシーンへ移る。
if count >= 300:
break
else:
continue
break
まあまあ時間が掛かるので、気長に待ちます(体感30分くらいでした)。
待った結果、6616枚の画像が入手できました。これをランダムに6000枚の学習用画像と616枚の評価用画像に分割します。データ構造は以下のようになります。
●データ構造
┗ Data_ASNARO1_SRCNN
┣ train (6000枚)
┗ test (616枚)
3. データの読み込み・モデルの定義
さて、データの準備もできたところで、Kerasを用いてSRCNNを実装していきましょう。まずは必要なライブラリーをインストールします。
from keras import backend as K
from keras.models import Sequential, Model, load_model
from keras.layers import Input, Dense, Input, Conv2D, Conv2DTranspose, MaxPooling2D, UpSampling2D, Lambda, Activation, Flatten, Add
from keras.optimizers import Adam, SGD
from keras.preprocessing.image import array_to_img, img_to_array, load_img,ImageDataGenerator
学習においては、高解像度画像(正解データ)と低解像度画像(インプットデータ)のペアが必要となります。ただ、SRCNNのネットワークでは入力画像と出力画像のサイズが同じです。そのため、インプットデータとしては、低解像度画像を高解像度画像と同じサイズまで古典的な手法で拡大した荒い画像を用います。
そこで、まずはASNARO-1の高解像度画像(正解データ)のサイズを4倍だけ縮小したのちに、再び元のサイズに拡大することで、これをインプットデータとします。
それではデータを読み込みましょう。
def drop_resolution(x,scale):
#画像のサイズをいったん縮小したのちに再び拡大することで、低解像度の画像を作る。
size=(x.shape[0],x.shape[1])
small_size=(int(size[0]/scale),int(size[1]/scale))
img=array_to_img(x)
small_img=img.resize(small_size, 3)
return img_to_array(small_img.resize(img.size,3))
def data_generator(data_dir,mode,scale,target_size=(256,256),batch_size=32,shuffle=True):
for imgs in ImageDataGenerator().flow_from_directory(
directory=data_dir,
classes=[mode],
class_mode=None,
color_mode='rgb',
target_size=target_size,
batch_size=batch_size,
shuffle=shuffle
):
x=np.array([
drop_resolution(img,scale) for img in imgs
])
yield x/255.,imgs/255.
DATA_DIR='./Data_ASNARO1_SRCNN/'
N_TRAIN_DATA=6000 #学習用データ数
N_TEST_DATA=616 #評価用データ数
BATCH_SIZE=32 #バッチサイズ
train_data_generator=data_generator(
DATA_DIR,'train', scale=4.0, batch_size=BATCH_SIZE
)
test_x,test_y=next(
data_generator(
DATA_DIR,'test',scale=4.0, batch_size=N_TEST_DATA,shuffle=False
)
)
次にSRCNNのネットワーク構成を定義します。今回は元論文で基準として採用されていたパラメーター値を採用します。つまり第一層、第二層、第三層に対して、フィルター数 = (64, 32, 3)、カーネルサイズ=(9,1,5)を適用します。
model = Sequential()
model.add(Conv2D(filters=64, kernel_size= 9, activation='relu', padding='same', input_shape=(None,None,3)))
model.add(Conv2D(filters=32, kernel_size= 1, activation='relu', padding='same'))
model.add(Conv2D(filters=3, kernel_size= 5, padding='same'))
model.summary()
たったこの数行でネットワークが構成できてしまうのが、Kerasのすごいところですね…。
4. モデルの学習
では、モデルの学習を行いましょう!と行きたいところですが、その前に……超解像の分野では評価関数としてはPSNR(Peak Signal to Noise Ratio:ピーク信号対雑音比)を用いるのが一般的です。
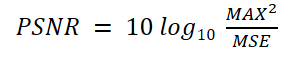
MAXは正解データが取りうる最大値で今回の場合は1.0で、MSEは出力結果と正解データの平均二乗誤差です。MSEが分母に入っているため、出力が正解に近ければ近いほどMSEが小さくなり、PSNRは大きくなります。単位はdB(デシベル)で表します。
そこで、まずはこのPSNRを関数として定義します。
def psnr(y_true,y_pred):
return -10*K.log(K.mean(K.flatten((y_true-y_pred))**2)
)/np.log(10)
次に、モデルをコンパイルし、学習データを用いてネットワークの学習をします。
損失関数は元論文にしたがって、MSE(平均二乗誤差)を用い、オプティマイザーはAdamを用いました。今回は200エポック学習します。
model.compile(
loss='mean_squared_error',
optimizer= 'adam',
metrics=[psnr]
)
model.fit_generator(
train_data_generator,
validation_data=(test_x,test_y),
steps_per_epoch=N_TRAIN_DATA//BATCH_SIZE,
epochs=200
)
学習が始まると、以下のような出力がなされます。学習には相当時間が掛かります(数日程度)。もしこの計算をもっと高速にしたい場合は、TellusのGPUプランに申込むのがいいかもしれません。
Epoch 1/200
Found 6000 images belonging to 1 classes.
187/187 [==============================] - 50s 270ms/step - loss: 0.0124 - psnr: 19.4878 - val_loss: 0.0094 - val_psnr: 20.7444
Epoch 2/200
187/187 [==============================] - 47s 253ms/step - loss: 0.0094 - psnr: 20.3751 - val_loss: 0.0084 - val_psnr: 21.2547
Epoch 3/200
187/187 [==============================] - 47s 253ms/step - loss: 0.0086 - psnr: 20.7265 - val_loss: 0.0076 - val_psnr: 21.6969
Epoch 4/200
187/187 [==============================] - 47s 253ms/step - loss: 0.0078 - psnr: 21.1911 - val_loss: 0.0072 - val_psnr: 22.0746
Epoch 5/200
187/187 [==============================] - 47s 251ms/step - loss: 0.0081 - psnr: 21.0456 - val_loss: 0.0114 - val_psnr: 20.6750
.
.
.
.
.
Epoch 195/200
187/187 [==============================] - 47s 250ms/step - loss: 0.0049 - psnr: 23.2101 - val_loss: 0.0049 - val_psnr: 23.7697
Epoch 196/200
187/187 [==============================] - 47s 251ms/step - loss: 0.0050 - psnr: 23.1422 - val_loss: 0.0053 - val_psnr: 23.2070
Epoch 197/200
187/187 [==============================] - 47s 251ms/step - loss: 0.0049 - psnr: 23.1455 - val_loss: 0.0049 - val_psnr: 23.7604
Epoch 198/200
187/187 [==============================] - 47s 250ms/step - loss: 0.0049 - psnr: 23.2479 - val_loss: 0.0053 - val_psnr: 23.3400
Epoch 199/200
187/187 [==============================] - 47s 252ms/step - loss: 0.0050 - psnr: 23.0964 - val_loss: 0.0051 - val_psnr: 23.5275
Epoch 200/200
187/187 [==============================] - 47s 249ms/step - loss: 0.0050 - psnr: 23.1375 - val_loss: 0.0049 - val_psnr: 23.8679
さて、これで学習は完了です。最終エポックにおけるPSNRの値は、学習用データに対しては23.14.、評価用データに対しては23.87となりました。
5. 学習したモデルによる高解像度画像の生成
いよいよ学習したモデルを使って、高解像度画像を構成します。インプットとして低解像度にデグレードしたテスト画像を与え、高解像度画像への変換を行います。
pred=model.predict(test_x)これでSRCNNによる高解像度画像の予測ができました。では、変換された高解像度画像を見てみましょう。試しに一つ評価用画像を見てみます。
fig = plt.figure(figsize=(50,50), facecolor="w")
N_show = 229 #N_show番目の評価用データを表示。
plt.subplot(1,3,1)
plt.title("Orignial",fontsize=80)
plt.tight_layout()
plt.imshow(test_y[N_show,:,:])
plt.subplot(1,3,2)
plt.title("Low resolution",fontsize=80)
plt.tight_layout()
plt.imshow(test_x[N_show,:,:])
plt.subplot(1,3,3)
plt.title("SRCNN result",fontsize=80)
plt.tight_layout()
plt.imshow(pred[N_show,:,:])
すると以下のような街の画像が表示されました。左側が元の高解像度画像、真ん中がインプットとして与えた低解像度画像、右側がSRCNNによって変換された高解像度画像です。

SRCNNによる画像は、インプット画像に対してより建物の輪郭がはっきりしていますね。SRCNNにより構成されたこの画像のPSNR値は25.78でした。
他の場所も見てみましょう。今度は農村部の画像です。

こちらもやはりSRCNNによる高解像度化によって、田んぼや森の輪郭がはっきりしていますね。SRCNNにより構成された画像のPSNR値は28.73でした。
他の研究(例えばこの記事)でも示されているように、農村部に比べて都市部の超解像は超解像の精度が出にくいようですね。
6. まとめ
今回はTellusを用いてダウンロードしたASNARO-1の衛星画像に対して、SRCNNを用いた超解像を行いました。
SRCNNが提唱された元論文で示されているように、SRCNNはフィルター数、カーネルサイズ、層の数などによってもモデルの性能が変化します。今回は標準的なパラーメータ設定でネットワークを構成しましたが、これらのパラメータをいくつか試してみて、より超解像の精度が上がるかどうか試してみてもいいかもしれません。
また以前の記事「超画像×衛星画像でできること。関連論文の紹介とTellusでやるには」でも紹介したように、超解像は近年盛んに研究が行われており、他にもGANを用いたものなど様々な手法が現れています。気になる方は記事や元論文を辿ってみて、ぜひ衛星データに(もちろん他のデータにも)適用してみてください。
※ 文中では引用しなかった参考記事・参考書
・太田 満久,須藤 広大,黒澤 匠雅,小田 大輔. 現場で使える!「TensorFlow開発入門 Kerasによる深層学習モデル構築手法」
・川嶋一誠、中村良介(2018)、「深層学習を用いた衛星画像の超解像手法、川嶋一誠、中村良介
「Tellus」で衛星データを触ってみよう!
日本発のオープン&フリーなデータプラットフォーム「Tellus」で、まずは衛星データを見て、触ってみませんか?
★Tellusの利用登録はこちらから
