衛星データに雲が映っているか否かの画像分類を4つの手法で精度比較してみた
機械学習、AIなど最近はよく耳にしますよね。今回は衛星データに対して、機械学習の基本的なモデルをいくつか試してみようと思います。
機械学習、AIなど最近はよく耳にしますよね。今や需要予測やネット広告から農業、物流に至るまで、機械学習は業界を問わずに毎日使われています。ひょっとしたらあなたの仕事にも使えるかもしれません。
そこで自分でも機械学習のモデルを作成してみたいと思いますよね!?ということで、今回は衛星データに対して、機械学習の基本的なモデルをいくつか試してみようと思います。
以前紹介した記事、「CNNを使って衛星データに雲が映っているか否か画像分類してみた」では、深層学習ライブラリKerasを用いて、AVNIR-2の衛星画像に雲が含まれているかを予測するCNNのモデルを作りました。その結果、テストデータに対するモデルの予測精度は0.88と高い値が得られました。

この記事ではKerasではなくscikit-learnというライブラリを使ってみます。scikit-learnはPythonで書かれた機械学習のオープンソースライブラリーで、機械学習の様々なモデルを簡単に記述することができます。そのため機械学習を始めてみようという人にはぴったりなのです。
特に今回は、前回と同じ衛星データに対してCNN以外の様々なモデルを試します。具体的にはサポートベクターマシーンやXGBoostなどを実装してみて、どれくらいの精度が出そうか試してみます。さらに、計算高速化のための次元削減(PCA)なども行います。
でははじめましょう!
(1) データ構造
まずは用いるデータの構造を見てみましょう。用いる画像データ自体は以前のCNNの記事と同じなので、AVNIR-2の衛星画像データになります。ただ、ディレクトリへの分け方は前回と少し異なります。今回は全画像データを学習データ(1200枚=400+800枚)とテストデータ(400枚=200+200枚)に分けます。
● データ構造
┣ Dataset_AVNIR2
┣ train
┃ ┣ clear (400枚)
┃ ┣ cloudy (800枚)
┃ ┣ clear_augmented (2000枚)
┃ ┗ cloudy_augmented (4000枚)
┃
┗ test
┣ clear (200枚)
┗ cloudy (200枚)
clearには雲がない画像を入れ、cloudyには雲がある画像を入れてあります(下図)。

名前に”_augmented”と付いているディレクトリは、元のデータに加えて人工的に水増しした学習データをも含めたディレクトリになります(後述)。
(2) ライブラリーのインポート、人工的に画像データを増やす
まずは必要なライブラリーをインポートします。
import numpy as np
import random #擬似乱数を生成するライブラリー
from PIL import Image, ImageOps #画像処理ライブラリー
from sklearn.metrics import accuracy_score #モデルの正解率を計算するライブラリー
import glob #ファイルパス名を取得するライブラリ
import matplotlib.pyplot as plt #図をプロットするためのライブラリー
%matplotlib inline #図をJupyter Notebook内に表示させる
TOKEN = '(トークンを貼り付ける)'
DOMAIN = 'tellusxdp.com'
np.random.seed(0) #乱数のシードの設定
次に学習データの水増しを行います。一般に、学習データは多い方が精度は上がると思われます。とはいえ、さらに大量の衛星画像に雲があるかないかを逐一ラベリングするのは骨が折れますよね。
そこで、今ある学習データに加工したものを加えることで、学習データ数を人工的に増やしましょう。具体的には、各学習データの画像に対して上下反転、左右反転、90度回転、ランダムに切り取ると言う処理を施します。そして、それぞれの処理がなされた画像を新たに学習データに加えます(つまり一枚の画像あたり4枚の学習データが増えます)。前のCNNの記事では画像の水増しにKerasのImageDataGeneratorを使いましたが、今回は画像処理ライブラリPillow(PIL)というものを使ってみます。
まずは雲がない(clear)データを増やしてみましょう。
#雲がない画像ファイルのパスのリストを取得
files = glob.glob("./Dataset_AVNIR2/train/clear/*")
#出力ディレクトリのパス
output_dir = "./Dataset_AVNIR2/train/clear_augmented/"
#ランダムな領域の切り取りを行う関数
def random_crop(image, size=0.8):
image = np.array(image, dtype=np.float64)
height, width, _ = image.shape
crop_size = int(min(height, width) * size)
top = np.random.randint(0, height - crop_size)
left = np.random.randint(0, width - crop_size)
bottom = top + crop_size
right = left + crop_size
image = image[top:bottom, left:right,:]
return Image.fromarray(np.uint8(image))
for item in files:
img = Image.open(item)
file_name = os.path.basename(item)[:-4]
img_flip = ImageOps.flip(img) # 画像の上下反転
img_flip.save(output_dir + file_name + "_flip.png") # 画像保存
img_mirror = ImageOps.mirror(img) # 画像の左右反転
img_mirror.save(output_dir + file_name + "_mirror.png") # 画像保存
img_rotate = img.rotate(90) # 画像の90度回転
img_rotate.save(output_dir + file_name + "_rot90.png") # 画像保存
img_crop = random_crop(img) # 画像の切り取り
img_crop = img_crop.resize((256, 256)) # 元のサイズに戻す
img_crop.save(output_dir + file_name + "_crop.png") # 画像保存
同様にして、雲があるデータ(cloudy)を水増しします。
#雲がある画像ファイルのパスのリストを取得
files = glob.glob("./Dataset_AVNIR2/train/cloudy/*")
#出力ディレクトリのパス
output_dir = "./Dataset_AVNIR2/train/cloudy_augmented/"
for item in files:
img = Image.open(item)
file_name = os.path.basename(item)[:-4]
img_flip = ImageOps.flip(img) # 画像の上下反転
img_flip.save(output_dir + file_name + "_flip.png") # 画像保存
img_mirror = ImageOps.mirror(img) # 画像の左右反転
img_mirror.save(output_dir + file_name + "_mirror.png") # 画像保存
img_rotate = img.rotate(90) # 画像の90度回転
img_rotate.save(output_dir + file_name + "_rot90.png") # 画像保存
img_crop = random_crop(img) # 画像の切り取り
img_crop = img_crop.resize((256, 256)) # 元のサイズに戻す
img_crop.save(output_dir + file_name + "_crop.png") # 画像保存
これで学習データが合計1200枚(=400+800)から6000枚(=2000+4000)にまで増えました。かなり増えましたね!
今回画像の水増しの際に行った処理(回転、反転など)はかなり簡単なものですが、他にも平行移動、せん断、明度の変更など様々な処理が知られています。気なる方はぜひ調べて見てください(参考記事)。
(3) 画像データの行列への読み込み
次にscikit-learnで扱うために、全画像データをまとめて1つの大きな行列の形に変換します。一枚一枚の画像をそれぞれ一列の配列に変換して、行列の各行に読み込みます。なので、行列は(画像枚数)×(一枚の画像あたりの全ピクセル数×3)という形になります。ここに3とあるのはRGBの三成分があるからです。
一枚一枚の画像の全ピクセル数は256×256です。ただ、今回は画像認識やセグメンテーション等の画像内の細かな特徴を扱うわけではなく、雲があるかどうかを判定することが目的になっています。そのため画像全体の傾向がわかればよく、それほど多くのピクセルはいらないと考え、画像サイズを128×128に変更しました。
では、まず6000枚の学習データを一つの行列に変換します。
num_of_data_clear = 2000 # 雲がない画像の枚数
num_of_data_cloudy = 4000 # 雲がある画像の枚数
num_of_data_total = num_of_data_clear + num_of_data_cloudy # 学習データの全枚数
N_col = 128*128*3 # 行列の列数
X_train = np.zeros((num_of_data_total, N_col)) # 学習データ格納のためゼロ行列生成
y_train = np.zeros((num_of_data_total)) # 学習データに対するラベルを格納するためのゼロ行列生成
# 雲がない画像を行列に読み込む
path_list = glob.glob("./Dataset_AVNIR2/train/clear_augmented/*")
i_count = 0
for item in path_list:
im = Image.open(item).convert('RGB')
img_resize =im.resize((128,128)) # 画像のサイズ変更
im_array = np.ravel(np.asarray(img_resize)) # 画像を配列に変換
im_regularized = im_array/255. # 正規化
X_train[i_count,:] = im_regularized
y_train[i_count] = 0 # 雲がないことを表すラベル
i_count += 1
# 雲がある画像を行列に読み込む
path_list = glob.glob("./Dataset_AVNIR2/train/cloudy_augmented/*")
for item in path_list:
im = Image.open(item).convert('RGB')
img_resize = im.resize((128,128)) # 画像のサイズ変更
im_array = np.ravel(np.asarray(img_resize)) # 画像を配列に変換
im_regularized = im_array/255. # 正規化
X_train[i_count,:] = im_regularized
y_train[i_count] = 1 # 雲があることを表すラベル
i_count += 1ちなみに上のコードで、各ピクセルでの値を最大値255で割っています。これは正規化と言われる処理で、これにより学習が効率化することが知られています。
同様にしてテストデータも別個の一つの行列に変換しましょう。
num_of_data_clear = 200 # 雲がない画像の枚数
num_of_data_cloudy = 200 # 雲がある画像の枚数
num_of_data_total = num_of_data_clear + num_of_data_cloudy # テストデータの全枚数
N_col = 128*128*3 # 行列の列数
X_test = np.zeros((num_of_data_total, N_col)) # テストデータ格納のためゼロ行列生成
y_test = np.zeros(num_of_data_total) # テストデータに対するラベルを格納するためのゼロ行列生成
# 雲がない画像を行列に読み込む
path_list = glob.glob("./Dataset_AVNIR2/test/clear/*")
i_count = 0
for item in path_list:
im = Image.open(item).convert('RGB')
img_resize =im.resize((128,128)) # 画像のサイズ変更
im_array = np.ravel(np.array(img_resize)) # 画像を配列に変換
im_mean_subtract = im_array/255. # 正規化
X_test[i_count,:] = im_mean_subtract
y_test[i_count] = 0 # 雲がないことを表すラベル
i_count += 1
# 雲がある画像を行列に読み込む
path_list = glob.glob("./Dataset_AVNIR2/test/cloudy/*")
for item in path_list:
im = Image.open(item).convert('RGB')
img_resize = im.resize((128,128)) # 画像のサイズ変更
im_array = np.ravel(np.array(img_resize)) # 画像を配列に変換
im_regularized = im_array/255. # 正規化
X_test[i_count,:] = im_regularized
y_test[i_count] = 1 # 雲があることを表すラベル
i_count += 1
さて、これで6000×49152の学習データに対する行列と、400×49152のテストデータに対する行列ができました。
(4) PCAによる次元削減
しかしこのような巨大な(6000×49152)行列を扱うことには一つ問題点があります。とても計算時間が掛かってしまうのです。
そこでPCA(Principle Component Analysis;主成分分析)という変数の次元を削減する手法を用いて、行列のサイズを縮小しましょう。
from sklearn.decomposition import PCA
N_dim = 100 # 49152(=128×128×3)の列を100列に落とし込む
pca = PCA(n_components=N_dim, random_state=0)
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
print('累積寄与率: {0}'.format(sum(pca.explained_variance_ratio_)))
実行すると
累積寄与率: 0.8499862474351219と表示されました。これは次元削減された変数がもとの情報量の85%を保持していることを表します。そのため、次元削減を行ってもそれほど情報が失われていないことが分かりますね。
さて、PCAにより学習データ、テストデータに対する行列のサイズがそれぞれ6000×100、400×100に縮小されました。
長くなりましたがこれで準備は完了です。これからが本番です!
(4) 機械学習モデルの実行
準備もできたところで、いよいよ様々な機械学習のモデルを試していきましょう。でも、機械学習のモデルと言ってもたくさんありますよね。どのモデルを使うのが良いのでしょうか?
そこでscikit-learnのページに以下のような、モデルを選ぶための便利なフローチャート図がありました。これに従って色々なモデルを試していこうと思います。
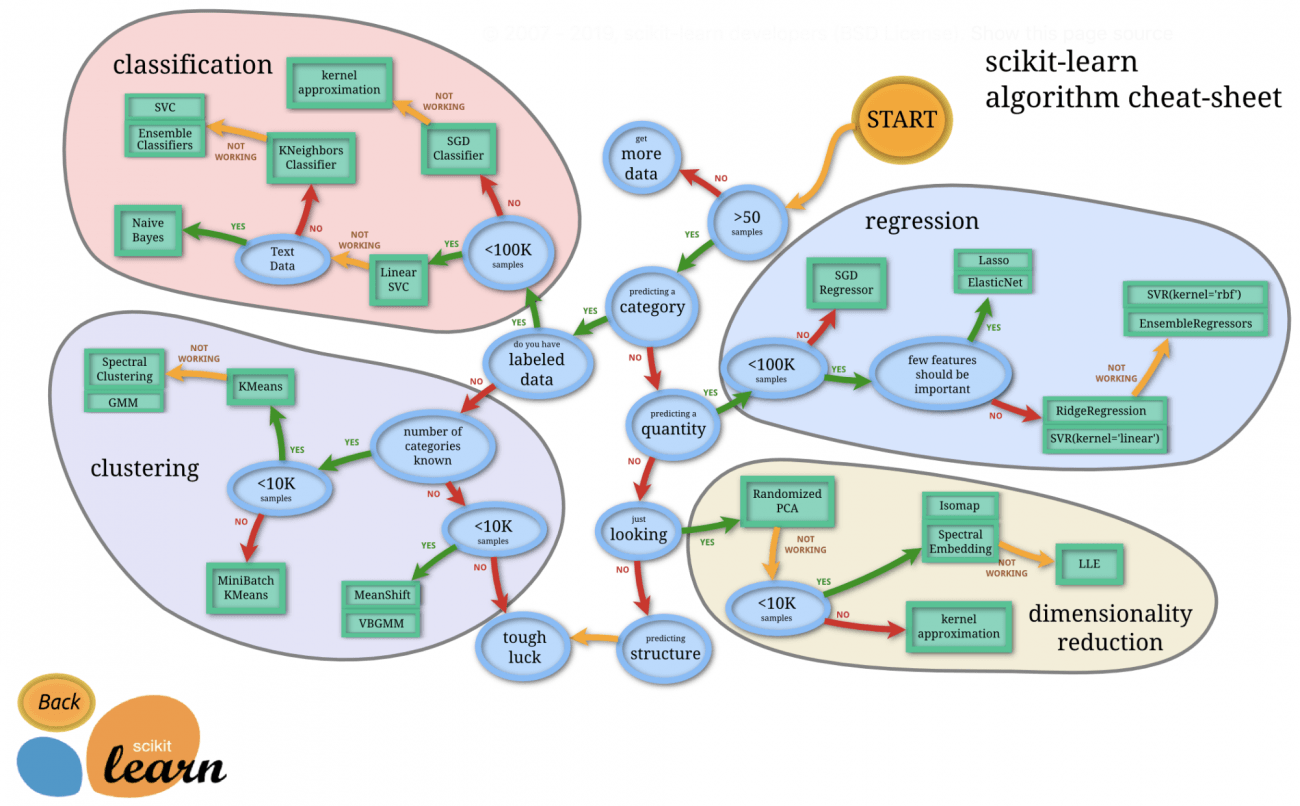
STARTから始めましょう。まず学習データ数(=6000枚)は50を超えるので、一つ目の分岐点はYesですね。今回は画像を雲があるかないかの二グループに分類するので、次の分岐点もYes。さらに今回は各画像にラベリングがなされているので、その次の分岐点もYesとなり、結局Classification(分類問題)の島に辿り着きました。
では、Classificationの島の中のフローチャートを辿っていきましょう。
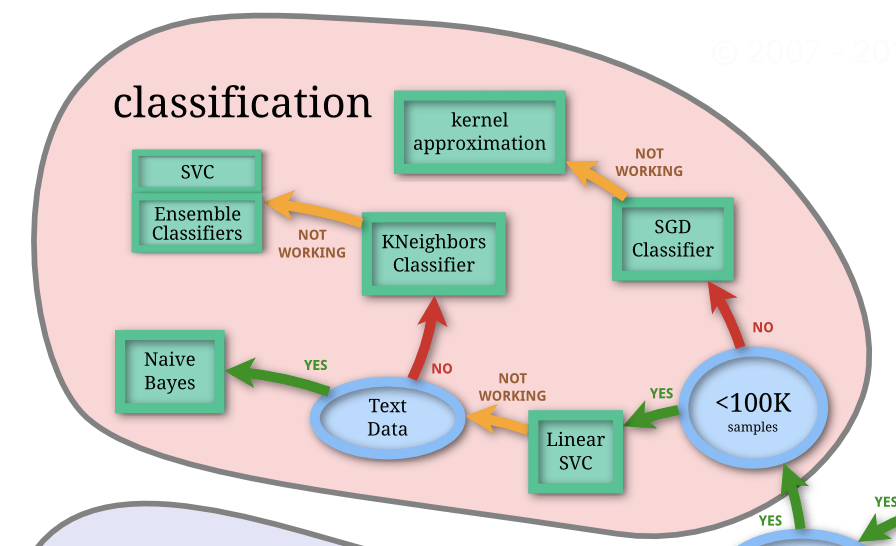
まず学習データ数(=6000=6K枚<100K)なので、一つ目の分岐点はYes。ということで、最初のモデルとしてLinear SVCを試してみましょう。
モデル1: 線形サポートベクターマシー (Linear SVC)
サポートベクターマシーンは、マージン最大化という考え方のもとに分類をするモデルです。詳細はscilit-learnの解説ページをご覧になって下さい。
ともあれ実装してみましょう。scikit-leanを用いることで、以下のように数行のコードで学習ができてしまいます!
from sklearn.svm import LinearSVC # ライブラリのインポート
model = LinearSVC(C=0.3, random_state=0) # インスタンスを生成
model.fit(X_train_pca, y_train) # モデルの学習
# 学習データに対する精度
print("Train :", model.score(X_train_pca, y_train))
# テストデータに対する精度
print("Test :", model.score(X_test_pca, y_test))
結果はこちら。
Train : 0.6796666666666666
Test : 0.6425全然精度が出ませんでした…。CNNの0.88の精度にはとても及びません。
そこでフローチャートの次のステップに行ってみましょう。今回扱うのはテキストデータではないのでNoの方に進みます。
では次のモデル、KNeighbours Classifierを試してみましょう。
モデル2: KNeighbors Classifier (k-近傍法)
k-近傍法は、分類が未知の新しいデータに対して直近のk点を探し、それらの多数決でそのデータの分類を決めるというモデルです(詳細はこちら)。今回はkの数としては学習データ数(6000)の平方根で与えました。
from sklearn.neighbors import KNeighborsClassifier # ライブラリのインポート
n_neighbors = int(np.sqrt(6000)) # kの設定
model = KNeighborsClassifier(n_neighbors = n_neighbors)
model.fit(X_train_pca, y_train) # モデルの学習
# 精度
print("Train :", model.score(X_train_pca, y_train))
print("Test :", model.score(X_test_pca, y_test))
結果はこちら。
Train : 0.6793333333333333
Test : 0.6875テストデータに対する精度は線形サポートベクターマシーンよりはわずかに向上しましたが、それでもやはり精度はよくありませんね。
そこでフローチャートの最後へと進みます。非線形SVCとEnsemble Classifierの二つを試してみよ、と書かれていますね。
では、まず非線形サポートベクターマシーン(SVC)から試してみましょう。
モデル3: 非線形サポートベクターマシーン
ここではモデル1とは違って、RBFカーネルを用いた非線形なサポートベクターマシーンを使います。
from sklearn.svm import SVC # ライブラリのインポート
model = SVC(C=0.3, kernel='rbf', random_state=0) # インスタンスを生成
model.fit(X_train_pca, y_train) # モデルの学習
# 精度
print("Train :", model.score(X_train_pca, y_train))
print("Test :", model.score(X_test_pca, y_test))
結果はどうでしょうか??
Train : 0.8581666666666666
Test : 0.7775
CNNの精度、0.88には及びませんが、線形サポートベクターマシーン、k-近傍法よりはかなり精度が上がりました。
モデル4: XGBoost
最後はアンサンブル学習です。アンサンブル学習と言っても様々な種類がありますが、今回はXGBoostという手法を用います。
XGBoostはKaggleなどのコンペティションで頻繁に用いられている手法で、決定木を複数作りアンサンブル学習します。弱学習器(性能がさほど高くない手法)を直列に使い、逐一改善しながら新しい決定木を作っていく手法です。XGBoostはsckit-learnとは別のオープンソースであり、詳細はこちらに記載されています。
それでは実装していきましょう。基本的な実装の手順はこれまでと同じです。
import xgboost as xgb # ライブラリのインポート
model = xgb.XGBClassifier(n_estimators=80, max_depth=4, gamma=3) # インスタンスの生成
model.fit(X_train_pca, y_train) # モデルの学習
# 精度
print("Train :", model.score(X_train_pca, y_train))
print("Test :", model.score(X_test_pca, y_test))
さて、結果はというと…?
Train : 0.9753333333333334
Test : 0.867テストデータに対する精度は0.87という、CNNの精度0.88にはわずかに及びませんが匹敵するほどの高い精度が出ました!
(4)結果のまとめ
以上の全モデルの結果をまとめると以下のようになります。
| モデル名 | テストデータに対する精度 |
| CNN | 0.88 |
| 線形サポートベクターマシーン | 0.64 |
| k-近傍法 | 0.69 |
| 非線形サポートベクターマシーン | 0.78 |
| XGBoost | 0.87 |
線形サポートベクターマシンやk-近傍法ではCNNほどの精度は出せませんでした。しかし、非線形サポートベクターマシーンではまずまずの精度、またXGBoostではCNNに匹敵する精度を出すことが分かりました!
というわけでCNN以外のモデルでも十分高精度を目指せそうですね。
(5)考察
とはいえ、k-NNなどのいくつかのモデルでは精度があまり出ませんでした。そこで最後に、精度があまり出ない原因や、今後どうやったら精度をあげることができるかを考察してみようと思います。
機械学習では学習曲線(Learning curve)というものが知られています。これは様々な数の学習データに対してモデルの学習と評価を行い、用いた学習データ数に対してモデルの精度(や損失関数)をプロットしたものです。
この図を見ることで、モデルが過学習(後述)していないかどうかを調べたり、学習データ数をこれ以上増やすことに意味はあるかなどが分かります。
何はともあれ図をプロットしてみましょう。学習曲線はscikit-learnのlearning_curveメソッドを用いて計算できます。様々な数の学習データに対して、それを学習用と検証用に分割し、まずは学習用データを用いてモデルの学習をします。次に、そのモデルを用いて、学習用データと検証用データのそれぞれに対する精度を求めます。
コードを見ていきましょう。たとえば線形サポートベクターマシーンに対しては以下のようにして、様々な数の学習データに対してモデルの学習・評価を行います。
train_sizes = np.array([0.1, 0.33, 0.55, 0.78, 1. ]) # 用いる学習データの割合を全体の0.1〜1まで変化させる
train_sizes, train_scores_linearSVC, test_scores_linearSVC = learning_curve(
model_linearSVC, X_train_pca, y_train, cv=5, train_sizes=train_sizes, random_state=0, shuffle=True
) # 様々学習データ数に対して、モデルを学習・評価する。
# 各学習データ数の場合について学習用データと検証用データに対する精度を求める。
train_scores_mean_linearSVC = np.mean(train_scores_linearSVC, axis=1)
train_scores_std_linearSVC = np.std(train_scores_linearSVC, axis=1)
validation_scores_mean_linearSVC = np.mean(validation_scores_linearSVC, axis=1)
validation_scores_std_linearSVC = np.std(validation_scores_linearSVC, axis=1)
同様にして他のモデルについても計算を行い、train_socres_mean_kNN、 train_socres_mean_nonlinearSVC、train_socres_mean_xgbなどを計算します(コードは上と同じなため省略)。
これらを用いて学習曲線は以下のようにプロットできます。
fig, ax = plt.subplots(2, 2, figsize=(12, 8))
plt.subplots_adjust(wspace=0.4, hspace=0.6)
# Linear SVCの学習曲線
ax[0,0].plot(train_sizes, train_scores_mean_linearSVC, 'o-', color="r", label="Training score")
ax[0,0].plot(train_sizes, validation_scores_mean_linearSVC, 'o-', color="g", label="Test score")
ax[0, 0].set_title('Linear SVC')
ax[0, 0].set_xlabel('Number of Taining data')
ax[0, 0].set_ylabel('Accyracy')
ax[0,0].set_ylim(0.4, 0.8)
ax[0,0].legend(loc="best")
# kNNの学習曲線
ax[1,0].plot(train_sizes, train_scores_mean_kNN, 'o-', color="r", label="Training score")
ax[1,0].plot(train_sizes, validation_scores_mean_kNN, 'o-', color="g", label="Test score")
ax[1, 0].set_title('k-NN')
ax[1, 0].set_xlabel('Number of Taining data')
ax[1, 0].set_ylabel('Accuracy')
ax[1,0].set_ylim(0.5, 0.7)
ax[1,0].legend(loc="best")
# 非線形SVCの学習曲線
ax[0,1].plot(train_sizes, train_scores_mean_nonlinearSVC, 'o-', color="r", label="Training score")
ax[0,1].plot(train_sizes, validation_scores_mean_nonlinearSVC, 'o-', color="g", label="Test score")
ax[0, 1].set_title('non-linear SVC')
ax[0, 1].set_xlabel('Number of Taining data')
ax[0, 1].set_ylabel('Accuracy')
ax[0,1].set_ylim(0.7, 0.9)
ax[0,1].legend(loc="best")
# XGBoostの学習曲線
ax[1,1].plot(train_sizes, train_scores_mean_xgb, 'o-', color="r", label="Training score")
ax[1,1].plot(train_sizes, validation_scores_mean_xgb, 'o-', color="g", label="Test score")
ax[1, 1].set_title('XGBoost')
ax[1, 1].set_xlabel('Number of Taining data')
ax[1, 1].set_ylabel('Accuracy')
ax[1,1].set_ylim(0.7, 1.0)
ax[1,1].legend(loc="best")結果は以下のようになります!
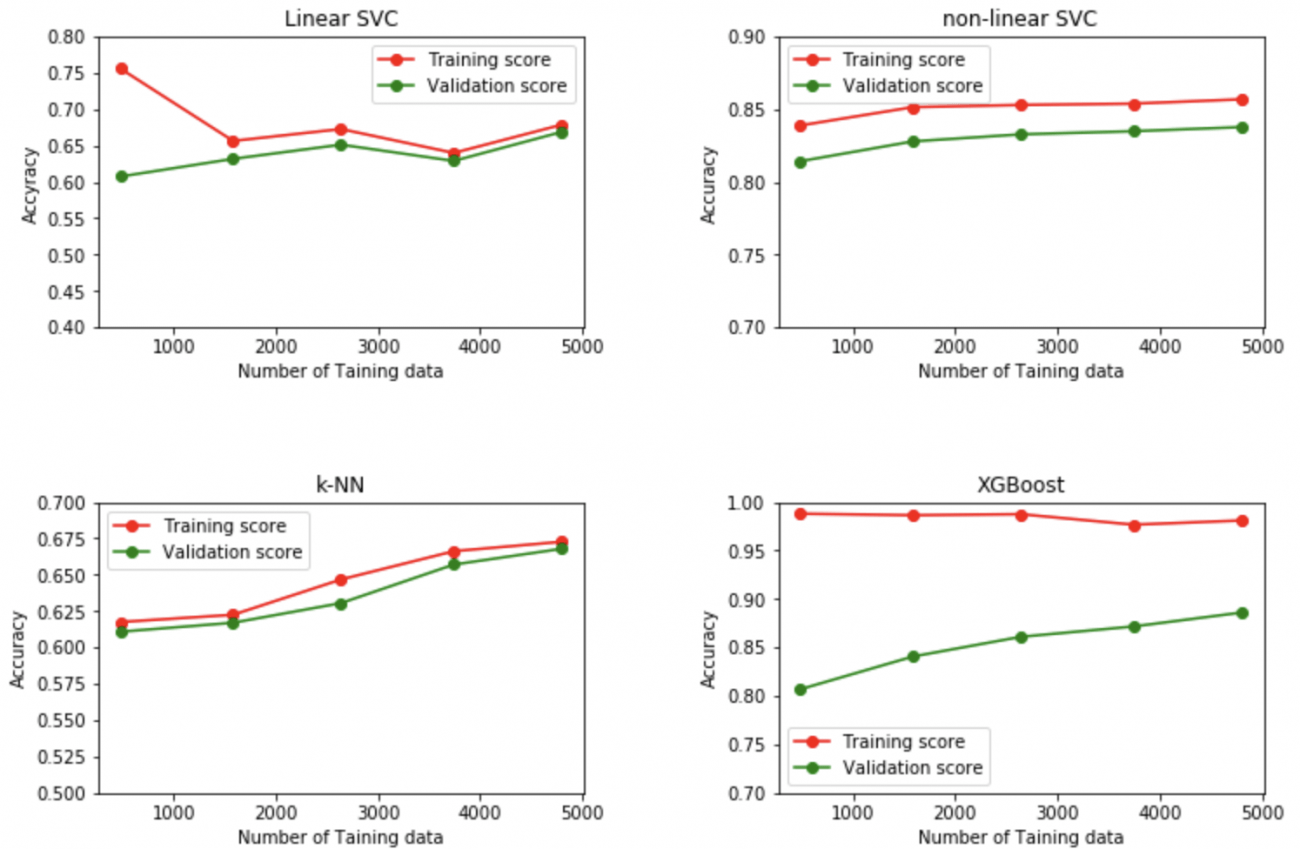
さて、この図から何が分かるでしょうか。以下の3つの点について考えてみましょう。
① 学習データを増やせば精度も上がる?
まず線形、非線形のどちらの場合についてもサポートベクターマシーンは、学習データを増やしてもあまり精度が増えていません。このため、いくら汗水流して大量の衛星画像に雲の有無をラベリングして、学習データを増やしたところで精度はこれ以上増えなさそうです。
ただk-NNとXGBoostに関しては、学習データ数とともに精度が上がっています。そのため、もっと学習データを増やすことにより、さらなる精度の向上が期待できます。例えば、画像の水増しの枚数をもっと増やすのも手かもしれません。
②モデルは過学習している?
XGBoostの学習曲線を見ると、学習データに対する精度(赤)と検証用データに対する精度(緑)が大きく解離していることが分かります。これはまさに過学習の特徴で、モデルが学習データに適応しすぎており、新しいデータ(検証用データ)に対する汎化性能に乏しいことを示しています。これは決定木の枝の深さなどのパラメーターを調節することで、改善できるかもしれません。
一方他の3モデル(線形・非線形SVC、k-NN)に関しては両者の解離はほとんど見られないため、過学習は起こしていないと考えられます。
③他に考えられる精度があまり出ない原因
今回はXGBoost以外のモデルではあまり高い精度が出ませんでした。上で見たようにこれは学習データ数だけの問題でもなさそうです。この原因はどこにあるのでしょうか。
今回は画像データを一列の配列に変換して扱いました。そのため、近接したピクセルは近いピクセル値を持つ、などの画像が持つ特有の性質は失われています。これが高い精度が出なかった一つの理由かもしれません。ちなみに、画像特有の性質を生かす、というのはCNNが得意とするところですね。
他にも、例えばPCAで失われた情報量が多すぎたという可能性も考えられます。PCAによってどこまで次元を落として良いのか、ということに関してもう少し議論してみると良いかもしれません。
また、どのモデルもハイパーパラメーターという我々、モデルの製作者が設定すべきパラメーターがたくさんあります。モデルの精度や過学習の度合いはこれらのパラメーターの値に強く依存することが知られています。そのため、これらのパラメーターに関するグリッドサーチ(色々な値を試して一番高い精度が出るパラメーター値を見つける)を行えば、もっと精度が上がると思われます。
(6) 最後に
最後まで読んでくださってありがとうございました。scikit-learnやKerasなどの機械学習、画像認識のためのオープンソースライブラリーが今や非常に普及しています。皆さんも普段のお仕事や衛星データに機械学習を使ってみてはいかがでしょうか。
皆さんも自分ならこうする、などの意見があれば宙畑までお願いします!
「Tellus」で衛星データを触ってみよう!
日本発のオープン&フリーなデータプラットフォーム「Tellus」で、まずは衛星データを見て、触ってみませんか?
★Tellusの利用登録はこちらから
