任意データの散布図作成! オープンデータを用いてお好みの市町村を探す方法
人口データと標高データの散布図作成方法を紹介し、他にも市町村別にどのようなデータを確認できると興味深いのかといったアイデアを紹介します。
2022年8月31日以降、Tellus OSでのデータの閲覧方法など使い方が一部変更になっております。新しいTellus OSの基本操作は以下のリンクをご参照ください。
https://www.tellusxdp.com/ja/howtouse/tellus_os/start_tellus_os.html
「Tellus OSのエディタβ版で市町村別の人口密度を可視化! 自分だけの日本地図の作り方紹介」ではTellus OS上で市町村の人口密度を5段階に分けて表示する方法を紹介しました。データを確認してみると標高が高いところは人口密度が少ないということがお判りいただけたかと思います。
本記事では、人口データと標高データの散布図を確認し、その他にもどのようなデータを確認できると興味深いのかといったアイデアを紹介します。
記事の最後にはTellus の開発環境で散布図を表示する方法も紹介しておりますので、開発環境をお持ちの方はぜひチャレンジしてみてください。
★Tellusの利用登録はこちらから
(1)Tellus OSエディタβ版のおさらい
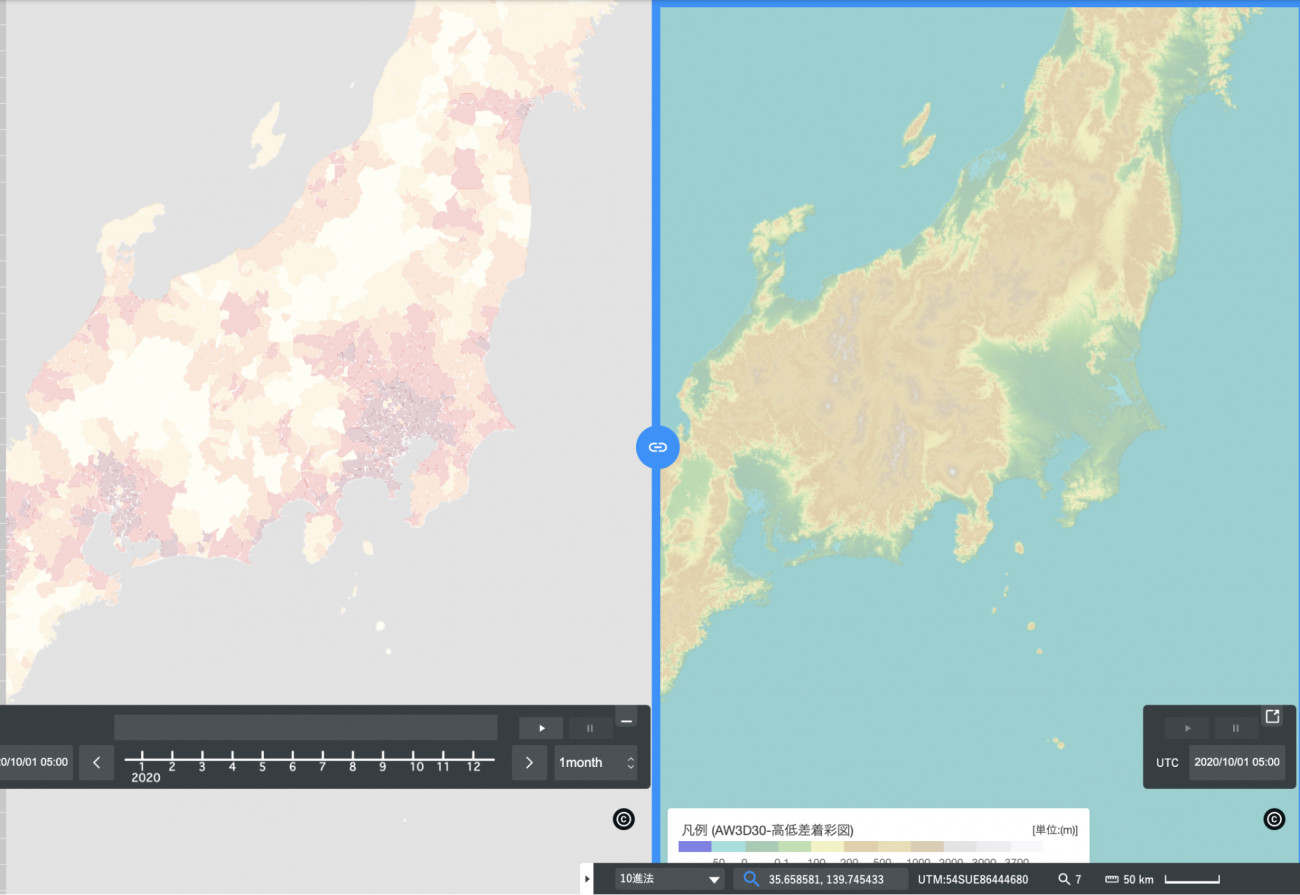
「Tellus OSのエディタβ版で市町村別の人口密度を可視化! 自分だけの日本地図の作り方紹介」では、市町村別の人口密度データと標高データを並べたときに、標高が高いところほど人口密度が低いことが見て取れました。
果たして本当にその傾向は正しいのでしょうか。
実際に数字を並べてみたときにどのような散布図になるのか、その結果をさっそく見てみましょう。
(2)人口と標高の関係性を散布図で確認
解析の結果、人口と標高の関係は以下のようになりました。左が人口と標高の散布図、右のが人口密度と標高の散布図になります。
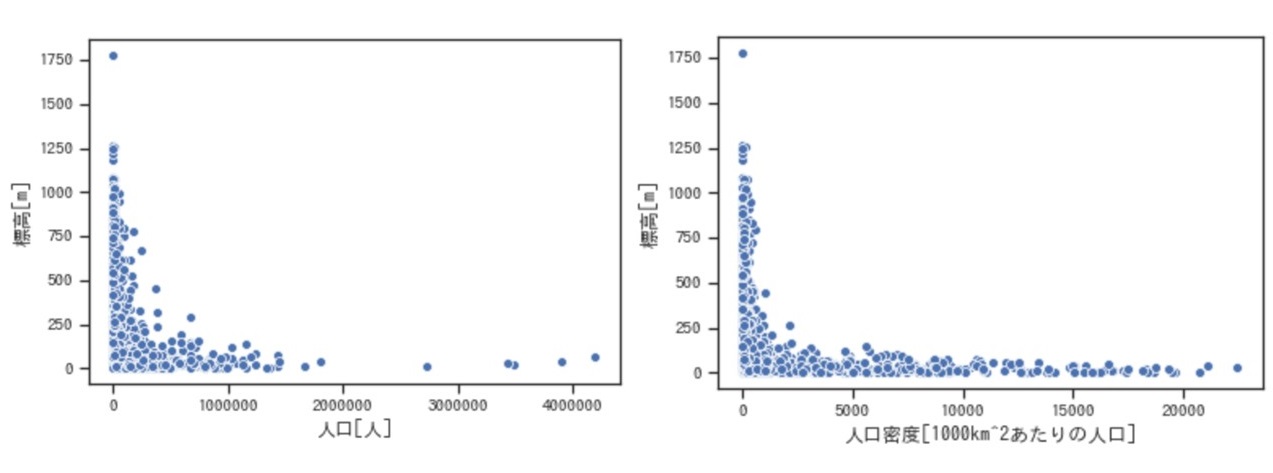
ご覧いただくと分かる通り、標高が1,000メートルを超えると人口は20,000人を超える市町村がなく、人口密度でみるとよりその傾向が目立ちます。この散布図から、標高が高い場所ほど人が住んでいないだろうということがより可視化できました。
また、標高が最も高い市町村として飛びぬけているのは檜枝岐村という福島県会津地方に位置する村で、1878年の郡区町村編制法施行時に発足し、現在に至るまで一度も合併をしていない数少ない村のようです。
Tellus OSを見ると確かに標高が高い位置に村があることが分かります。
さらに、海と隣接している市町村をオレンジ色で目立たせてみた散布図が以下になります。
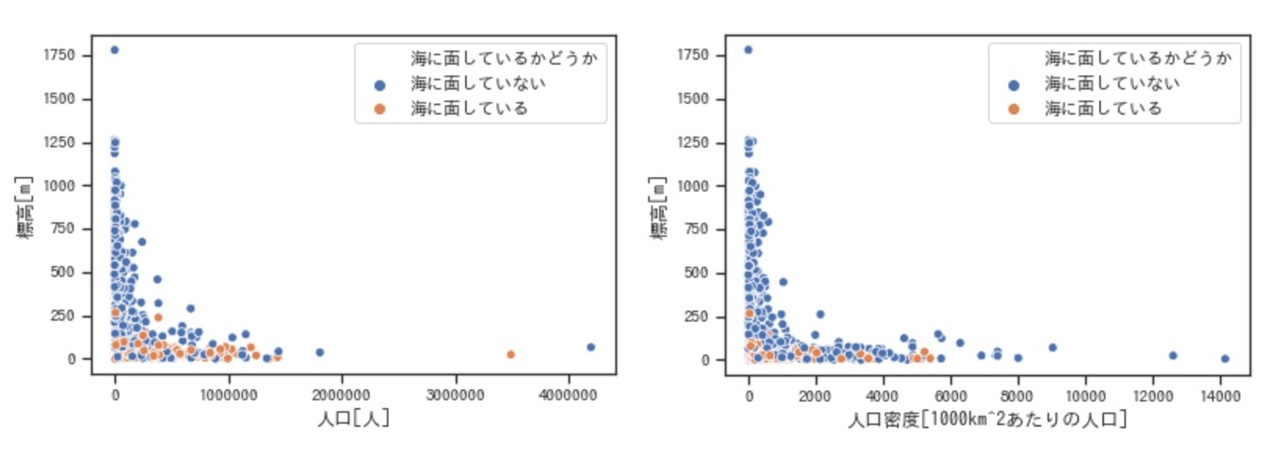
海に隣接している市町村は今回散布図に表示している約1,700のうち500ほどありました。散布図をご覧いただくと分かる通り、(当たり前ですが)海に隣接しているのは標高が低い市町村が多いですね。
今回、市町村別の標高データは、市町村より細かい番地毎の緯度経度情報から取得した標高データを市町村データにまとめる際に平均をとっています。そのため、海に隣接していながら標高が250m近くあるという市区町村も散布図で存在しています。散布図では一つしか見えていませんが、そのような市町村は複数あり、特に四国が多かったです。
このデータを眺めながら、海に隣接していて標高が低い土地である場合は、例えば津波の被害への警戒を強める必要がある地方自治体とも言えるでしょう。ぜひご自身の住む街が上記散布図のどの位置にあるかを考えながら、ご自身の住む地方自治体のハザードマップを探してみてください。
このように、1700の市町村について、複数の変数を選んで散布図を作成してみると知らなかった特徴的な街の発見や、自分が住んでいる街であればリスクや魅力など新しい視点を得ることができそうですね。
次章では、例えばこんな散布図作成ができるのではないかというアイデアを5つ紹介します。
(3)オープンデータを用いた自分好みの市町村を探すアイデア5選
1.津波リスクの可視化:地震の発生数x海岸堤防の高さ(海に隣接している市町村に絞る)
海に隣接している市町村に絞って地震の発生数と海岸堤防の高さを散布図に落としてみることで、津波に対する安全性が見えるかもしれません。
東日本大震災以降、地震・津波被害への対策について国レベル、各市町村で対策が進んでおり、その一つが津波被害に備えた海岸堤防の高さの見直しです。
しかし、安全だと定めた新基準に対して、高さに安心して逃げなくなる、景観が悪くなると言った理由で地域民の反対があり、従来の高さを維持するという判断からその地域の津波に対する安全性が変わっていないというケース(※)もあるようです。
※東日本大震災後の防潮堤の設計の考え方
もしご自身が住んでいる市町村が海に隣接している、もしくは移住を検討しているという場合はぜひお試しください。
2.快適に星空観測ができる場所:夜間の光x夜の気温
星空観測をしていると体が冷えてしまい、寒いところにいると30分も同じ場所にいられないということも。
そのため、「流れ星が見える場所はどこ? 衛星データで近場の星空観光スポットを探せ!」で見たように夜間の光をもとに星が良く見えるだろう場所を探し、AMeDASのデータから夜間の気温を見て心地よく長時間星空が観測できる場所を探すことができるかもしれません。
※市町村別も良いですが、この散布図は日本に限らず、世界に目を向けても面白そうですね
3.子育てがしやすい街:公園の数x子育て世帯比率
公園の数と各市町村の全世帯数に対する子育て世帯の比率をを散布図で並べることで、子どもが多く、子育てがしやすい市町村が分かるかもしれません。
公園の数ではなく、公園の面積の方が適切である可能性もあるので、まずは散布図に落としてみたいところです。
4.洗濯物が乾きやすい街:湿度x気温
外干しの洗濯もので重要なのは湿度、気温、風の強さと一般的に言われています。そこで、湿度は50%以下の日が3年間のうち何日あったのか、気温は天気が晴れで20度以上の日が3年間のうちに何日あったのかを散布図に落とすことで外での洗濯物ができる日が多い街を探せるでしょう。
風の強さについても、平均風速が一定以上の市町村は色をつけるなどしてより正確に洗濯物が乾きやすい街を探せるかもしれません。
5.様々な魚種の地魚をコスパ良く味わえる街:漁港別品目別上場水揚量x漁港別品目別卸売価格
最後のアイデアは市町村の数ではないのですが、「漁港別品目別上場水揚量・卸売価格」というデータを見ると、日本にある約200の魚市場で上がった魚の魚種とその量、卸売価格を確認することができます。
そこで、各市場別に何種類の魚が獲れているか、またその平均の価格はいくらかを散布図に落とすことで、多くの種類の魚を味わえる場所が分かるかもしれません。
魚好きの方はぜひお試しください。
(4)コード解説
最後に、本記事で紹介した散布図を作成するコードを紹介します。
今回必要なライブラリをimportします。
from urllib.request import urlretrieve
import zipfile
import os
import math
import requests
from io import BytesIO
from skimage import io
import geopandas as gpd
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
input_path = "shapefile" # 展開先フォルダ名
TOKEN = "XXXXX" # トークン
e-Statから人口データをダウンロードします。
def convert_to_two_characters(x):
string = str(x)
if len(string) == 1:
return "0" + string
else:
return string
urls = []
for i in range(1, 47):
number = convert_to_two_characters(i)
urls.append(f"https://www.e-stat.go.jp/gis/statmap-search/data?dlserveyId=A002005212015&code={number}&coordSys=1&format=shape&downloadType=5")
for i, url in enumerate(urls):
# e-stat 国勢調査 小地域(町丁・字等別) 東京都全域
shapefile_url = url
shapefile_name = f"./data-zip/${i}.zip"
# ダウンロード
urlretrieve(url=shapefile_url, filename=shapefile_name)
with zipfile.ZipFile(shapefile_name) as existing_zip:
existing_zip.extractall(input_path)
ダウンロードしたファイルをjupyter notebook上で読み込みます。
files = os.listdir(input_path)
shapefiles = [file for file in files if ".shp" in file]
dataframes = []
for shapefile in shapefiles:
shapefile_path = os.path.join(input_path, shapefile)
df = gpd.read_file(shapefile_path, encoding='cp932')
# 陸地だけにする
df = df.loc[df["HCODE"] == 8101, :]
dataframes.append(df)
標高を取得する関数を定義します。
今回、標高を取得するためにyahooから提供されている標高APIを使用します。
標高APIを使用して標高を取得するには緯度経度が必要なのですが、そちらに関してはe-Statからダウンロードして読み込んできたデータの中に「X_CODE」「Y_CODE」というプロパティがありますので、そちらを使用しました。
標高APIにはyahooデベロッパー登録が必要となっております。登録したあと、application idを取得します。詳細はこちらをご覧ください。
application idを取得した後、以下のコードを実行します。
import requests
import json
import urllib.parse
applicationID = "XXXXX"
def get_latlon(location: str):
try:
url = f"https://map.yahooapis.jp/geocode/V1/geoCoder?appid={applicationID}&query={urllib.parse.quote(location)}&output=json"
headers = {"content-type": "application/json"}
r = requests.get(url, headers=headers)
data = r.json()
lonlat = data["Feature"][0]["Geometry"]["Coordinates"].split(",")
return (lonlat[0], lonlat[1])
except:
return (0, 0)
def get_height(prefecture):
lon = prefecture["X_CODE"]
lat = prefecture["Y_CODE"]
# (lon, lat) = get_latlon(location)
url = f"https://map.yahooapis.jp/alt/V1/getAltitude?appid={applicationID}&coordinates={lon},{lat}&output=json"
headers = {"content-type": "application/json"}
r = requests.get(url, headers=headers)
data = r.json()
time.sleep(1)
return data["Feature"][0]["Property"]["Altitude"]
これで、標高を取得する関数を定義できました。
次に以下のコードを実行し、標高を実際に取得します。
from tqdm import tqdm
import time
prefectures = []
for index, prefecture in enumerate(dataframes):
prefecture["JINKO_DENSITY"] = prefecture["JINKO"] / (prefecture["AREA"])
prefecture = prefecture.sort_values('JINKO_DENSITY', ascending=True)
prefecture['JINKO_LEVEL'] = prefecture['JINKO_DENSITY'].map(level)
prefecture["HYOKO"] = prefecture.apply(get_height, axis=1)
prefectures.append(prefecture)
このままだと都道府県別になっているため、データを都道府県別から日本全体になるようにします。
japan = pd.concat(dataframes)最後に、標高と人口の関係、標高と人口密度の関係を散布図で表示します。
sns.scatterplot(x="JINKO", y="HYOKO", data=japan)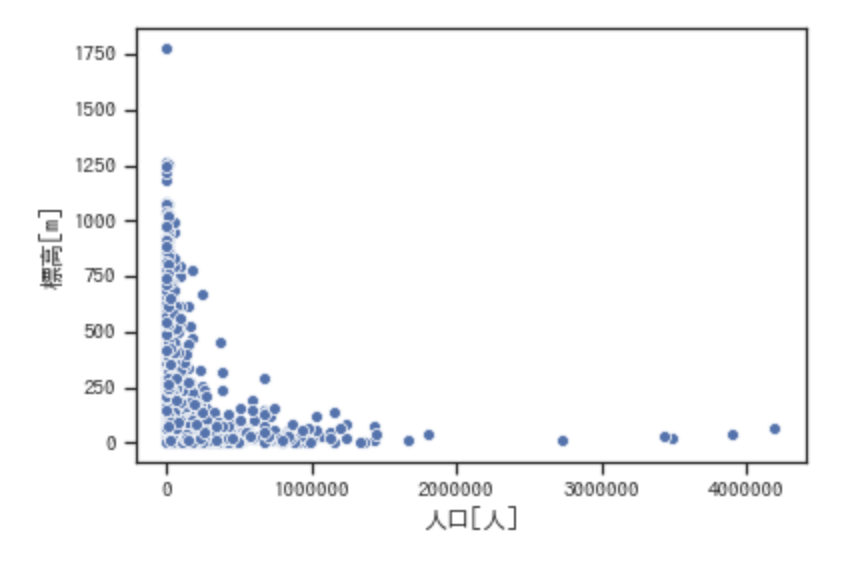
次に、海に面している市区町村を目立たせます。
目立たせる前に、どの市区町村が海に面しているかというデータが必要になってきますが、今回はネット上にまとめているサイトが存在していましたので、そちらをスクレイピング してお借りしたいと思います。
次のコードを実行し、スクレイピングと関数定義をします。
今回は最終的にファイルに保存し、Githubにアップロードするため、isExistSeaはbooleanではなく、「0:海に面していない」・「1:海に面している」と定義しています。
import requests
from bs4 import BeautifulSoup
load_url = "https://uub.jp/cpf/rinsetsu.html"
html = requests.get(load_url)
soup = BeautifulSoup(html.content, "html.parser")
target = soup.find_all(class_="al bw")
data = []
for element in soup.find_all(class_="al bw"):
# print(element.contents)
if (element.contents[2].text == "海"):
isExistSea = "海に面している"
else:
isExistSea = "海に面していない"
data.append([element.contents[1].text, isExistSea])
def get_is_exist_sea(city_name):
for i in data:
if (city_name == i[0]):
return i[1]海に面しているかいないかは市区町村レベルの情報になっているので、使用するデータも市区町村レベルに揃えます。
人口は合計、標高は平均をとって新しいgeopandas dataframeを作成します。
sum_dataframe = japan.dissolve(by="CITY_NAME", aggfunc='sum')
mean_dataframe = japan.dissolve(by="CITY_NAME", aggfunc="mean")
city_name = sum_dataframe[sum_dataframe.columns[sum_dataframe.columns == 'CITY_NAME']]
jinko = sum_dataframe[sum_dataframe.columns[sum_dataframe.columns == 'JINKO']]
hyoko = mean_dataframe[mean_dataframe.columns[mean_dataframe.columns == 'HYOKO']]
newDataframe = city_name.join(jinko).join(hyoko).reset_index()
定義した関数を用いて、海に面しているかいないかの情報を加えます。
newDataframe["JINKO_DENSITY"] = newDataframe["JINKO"] / (newDataframe["AREA"])
newDataframe["海に面しているかどうか"] = newDataframe["CITY_NAME"].map(get_is_exist_sea)
newDataframe["JINKO_DENSITY"] = newDataframe["JINKO_DENSITY"].map(lambda x: x * 10**6)
これで準備ができました。
最後に、海に面しているかどうかを凡例にして色分けして散布図を表示します。
sns.set(font='IPAGothic', style='ticks', rc={'grid.linestyle': '-'})
sns.scatterplot(x="JINKO", y="HYOKO", hue='海に面しているかどうか', data=newDataframe)
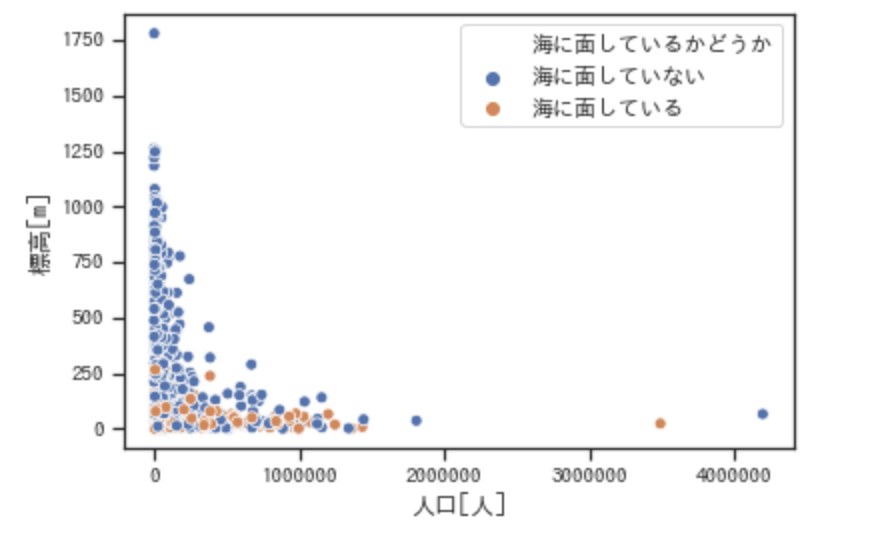
(2)では人口の条件によってデータを抽出しています。条件で抽出するには以下のようにします。
newDataframe = newDataframe[newDataframe['JINKO'] < 2000000]この状態でもう一度以下のコードを実行します。
sns.scatterplot(x="JINKO", y="HYOKO", hue='isExistSea', data=newDataframe)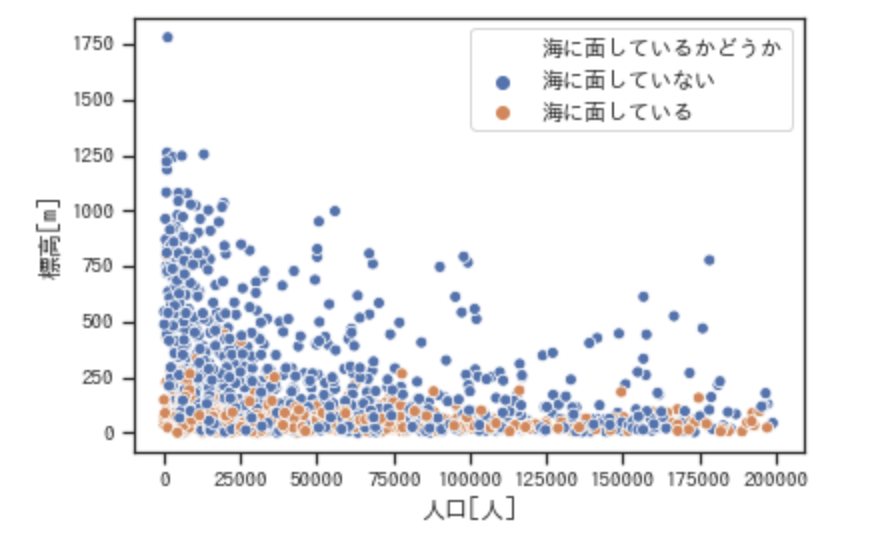
このように表示されます。
人口ではなく、人口密度で表示したい場合は以下のようにします。
newDataframe["JINKO_DENSITY"] = newDataframe["JINKO"] / (newDataframe["AREA"])
newDataframe["JINKO_DENSITY"] = newDataframe["JINKO_DENSITY"].map(lambda x: x * 10**6)
sns.scatterplot(x="JINKO_DENSITY", y="HYOKO", hue='海に面しているかどうか', data=newDataframe)これを実行すると
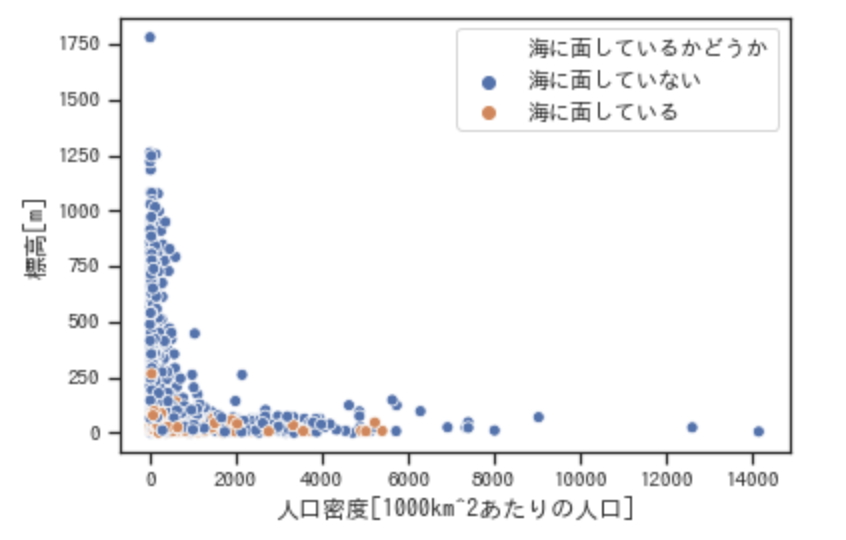
このように表示されます。
(5)まとめ
以上、市町村別のデータを散布図に落とす方法、また、散布図のアイデアを紹介しました。
「衛星データを利用して理想の家探しはできるのか!?理想高めなOLの日本全国住まい探しの旅【前編】」でも自分好みのデータから移住先を探してみるというチャレンジをしています。ぜひこちらの記事も見ながら、お好みの市町村を探してみてください。
Tellusに触ってみたい方は無料登録を!
日本発のオープン&フリーなデータプラットフォーム「Tellus」で、まずは衛星データを見て、触ってみませんか?
★Tellusの利用登録はこちらから
