衛星画像や航空写真を使った地上での撮影画像の位置推定「Cross-Viewによる位置推定」関連論文まとめ
スマートフォンなどで撮影された位置情報が付いていない画像を衛星画像や航空写真など視点が違う位置情報付きの画像をもとに撮影位置を推定する「Cross-Viewによる位置推定」に関連する論文をご紹介いたします。
1.Cross-Viewによる位置推定とは
スマートフォンなどで撮影された位置情報が付いていない画像を衛星画像や航空写真など視点が違う位置情報付きの画像をもとに撮影位置を推定する「Cross-Viewによる位置推定」に関連する論文をご紹介いたします。
大まかな仕組みは以下の通りです。
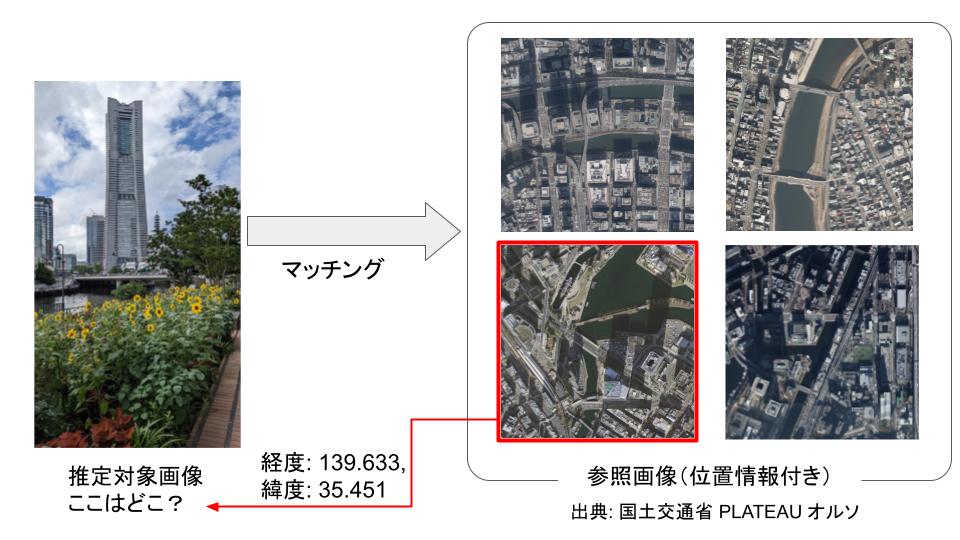
必要となるデータは、位置を推定したい画像(推定対象画像)と位置情報を推定するのに参照する画像(参照画像)の2つです。参照画像は撮影した位置情報がわかっている画像で、正確な場所を知るために利用する画像です。
推定対象画像と複数の参照画像を比較して、一番推定対象画像に特徴量が対応している参照画像を見つけ出し、推定対象画像の位置をおおまかに推定するという手法で推定していきます。
2.Cross-Viewによる位置推定の想定用途
つづいて、Cross-Viewによる位置推定がどのような場面で使われることが想定されているのかみていきます。
2-1. 災害時に撮影された画像から被災箇所の推定
風水害や地震などの自然災害発生時には、救助活動や生活再建に向けた取組が素早く行えるように被災箇所や状況を速やかに把握することが重要になってきます。SNSなどに被害箇所が撮影された画像が投稿されますが、その多くは位置情報が付いていません。
そのため、Cross-Viewによる位置推定により被災箇所の位置を推定し、救助活動などに活用していくことが期待されています。
2-2.都市部におけるUAVの自己位置推定
都市部においてはビルなどに反射して複数のルートを通ってGNSS波が伝播します。直接受信した電波に比べ、反射した電波はわずかな遅れが生じて受信されるため、その分距離が遠いと計測され、正確な測位が難しくなるといった問題があります。
UAVには地上を撮影するカメラが搭載されていることが多いため、GNSS測位がうまく使えない場合にカメラ画像を用いて自己位置を推定することが想定されています。
3.Cross-View関連論文
簡単にCross-Viewによる位置推定について触れたところで、本題の論文紹介を行っていきます。本記事では現在の論文のもとになっているものから最新のものまで3本紹介いたします。
3-1.深層学習を用いたCross-Viewによる位置推定
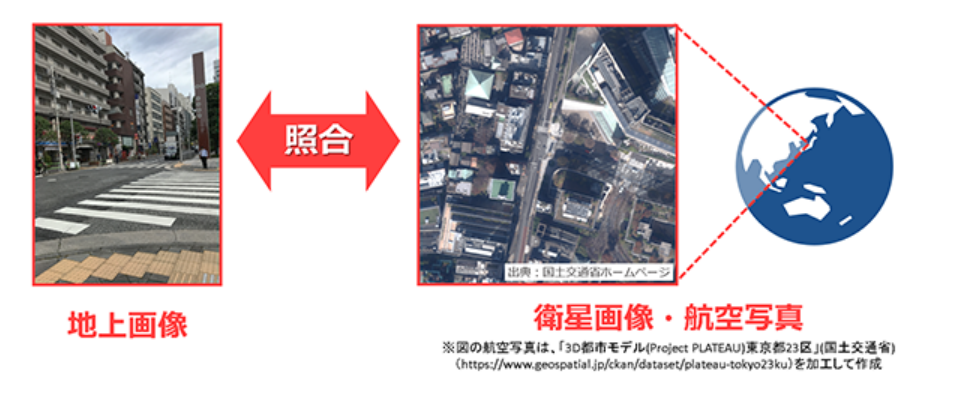
1つ目に紹介する論文は、2017年に発表された深層学習を用いたCross-Viewによる位置推定の草分け的な論文です。この論文では、街中にある建物に着目して推定対象画像である地上視点画像と参照画像である位置情報付きの鳥瞰画像のマッチングを行い、位置を推定する手法を提案しています。
この論文の提案手法は2017年以前の手法と比べ以下の3点が異なります。
1.地上視点画像と鳥瞰画像のマッチングに建物を使用
2.建物のマッチングだけではなく、鳥瞰画像から建物を検出しその位置情報を使用することによりグローバルな位置情報も考慮する
3.建物高さについての深度マップや画像の縮尺に関するメタデータなど推定対象画像と参照画像以外のデータが不要
具体的には、以下のフローに沿って位置を推定していきます。
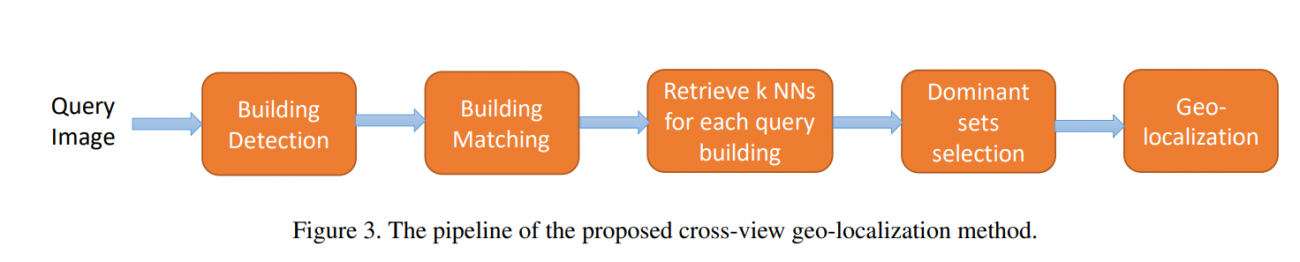
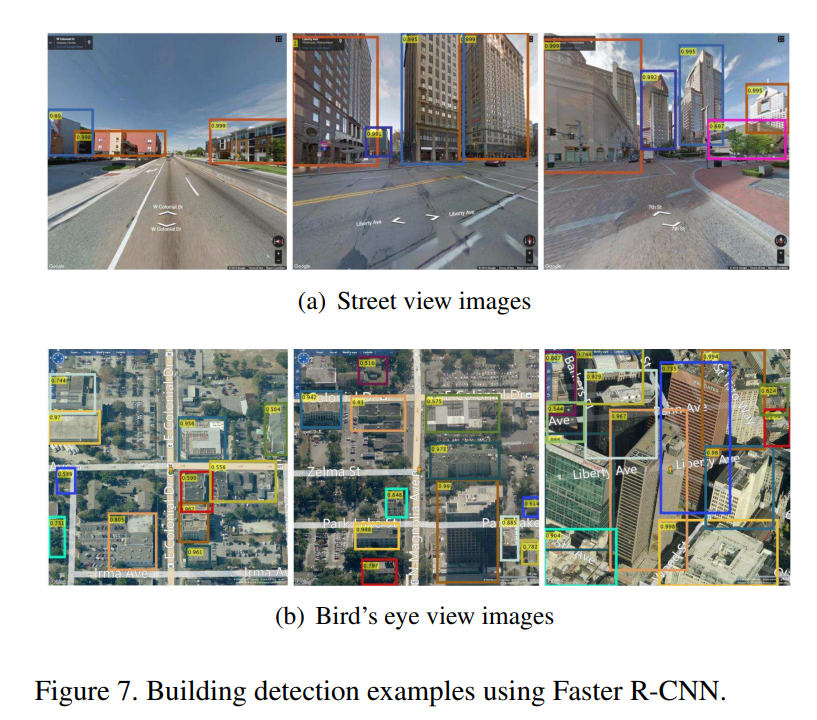
1.推定対象画像と参照画像に対してFaster R-CNNを用いてマッチング対象となる建物を検出する
2.Siamese Networkを用いて推定対象画像と参照画像にて検出された建物のマッチングを行う
この時にモデルが予測した結果と正解のズレを計算するための損失関数として、Contrastive Lossを採用しており、推定対象画像と参照画像において同じ建物に対応しているペアと対応していないペアを学ぶようにしています。
3.推定対象画像の建物それぞれにおいて、マッチングスコアから可能性が高い建物を参照画像からk個選択
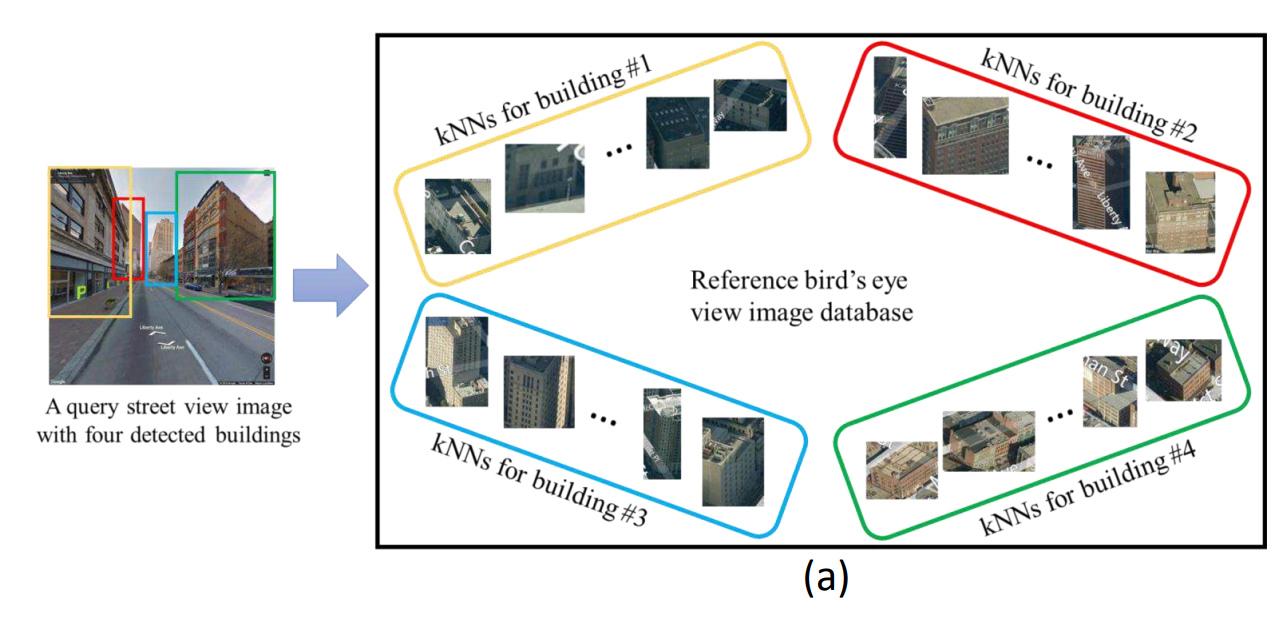
4.推定対象画像と参照画像において同じ建物が映っているか判定するためのマッチングスコアと建物それぞれの位置情報を用いて最適な組み合わせを選定し、推定対象画像の位置を推定
最終的に推定対象画像に付与する位置情報としては、検出された建物(図だと4つ)の推定された位置座標の平均値を用いています。
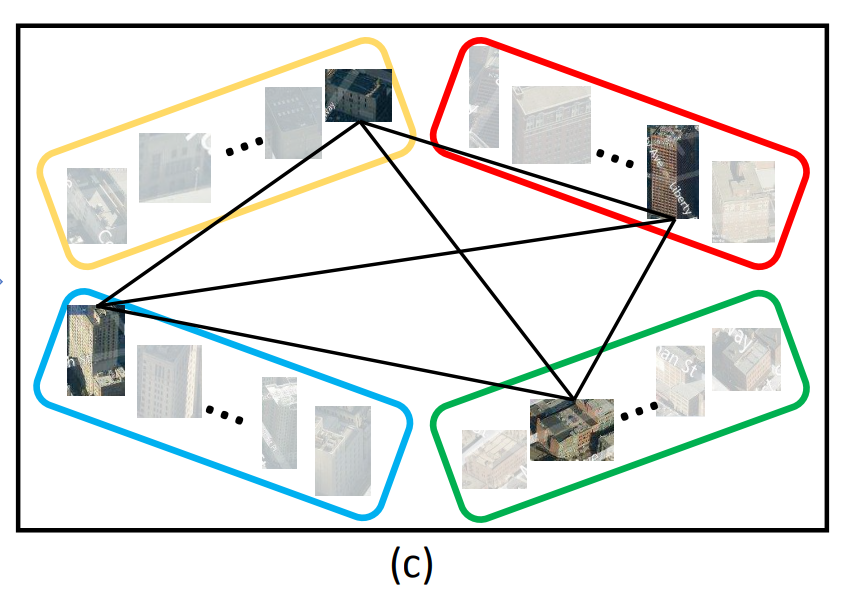
3. および 4. のフローを行う理由としては、建物画像のマッチングのみで推定を行うと位置推定時にまったく他の場所にある類似した建物を用いられる可能性があるからです。検出された参照画像の建物それぞれの位置が近くなるような組み合わせを探すことで、より正確に位置推定が行えるようにしています。
論文中では、ピッツバーグとマンハッタンの航空写真および地上視点画像を用いて実験を行っています。
実験結果として、以下の2つのことが分かりました。
・推定対象画像を1箇所につき、0°、90°、180°、270°の4方向取得し、参照画像とマッチングした方が精度が高い
これは、マッチングする際に利用する建物数が増えることからも直感的に分かります。・従来の画像特徴量(SIFT)を用いたCross-Viewによる位置推定に比べ、提案手法の方が汎化性能が高い
まったく学習を行っていない地域で、提案手法とSIFTによる手法を比較した結果、提案手法の方が精度が高い結果となっています。
3-2.ドローン画像を用いて見た目のギャップを埋める
公式GitHubリポジトリのURL: https://github.com/layumi/University1652-Baseline
2つ目に紹介する論文はドローン画像を用いた論文です。地上視点画像と衛星画像間では、見た目が大きく異なりマッチングすることが人間でも難しいタスクです。
そこで、見た目のギャップを埋めるためにドローン画像を導入したデータセットの整備およびCross-Viewによる位置推定を行う手法をこの論文では提案しています。
ドローン画像をCross-Viewによる位置推定に導入することで、以下の2つのタスクが新しくできるようになるとのことです。
1.Drone-view target localization
ドローン画像が推定対象画像として与えられたときに、参照画像として最も類似した衛星画像を探して位置を特定する2.Drone navigation
衛星画像が推定対象画像として与えられたときに、参照画像としてドローンが今まで撮影した画像から最も関連性が高い場所を見つける
まず、この論文で整備されたUniversity-1652データセットについてみていきます。
世界中の72大学にある1652の建築物を対象として、衛星画像、疑似的なドローン画像、地上視点画像を収集しています。大学の建築物を対象とした理由に関しては以下の2つを挙げています。
・東京タワーのような特徴的な建物がデータセット中に含まれバイアスが発生する可能性を防ぐ
・ドローンは通常ランドマーク周辺の飛行が禁止されている
また、画像に関して現実世界でドローンを飛行させるとコストがかかるため、以下の図のようにGoogle Earthが提供する3Dモデルを活用してシミュレーションを行い、取得しています。
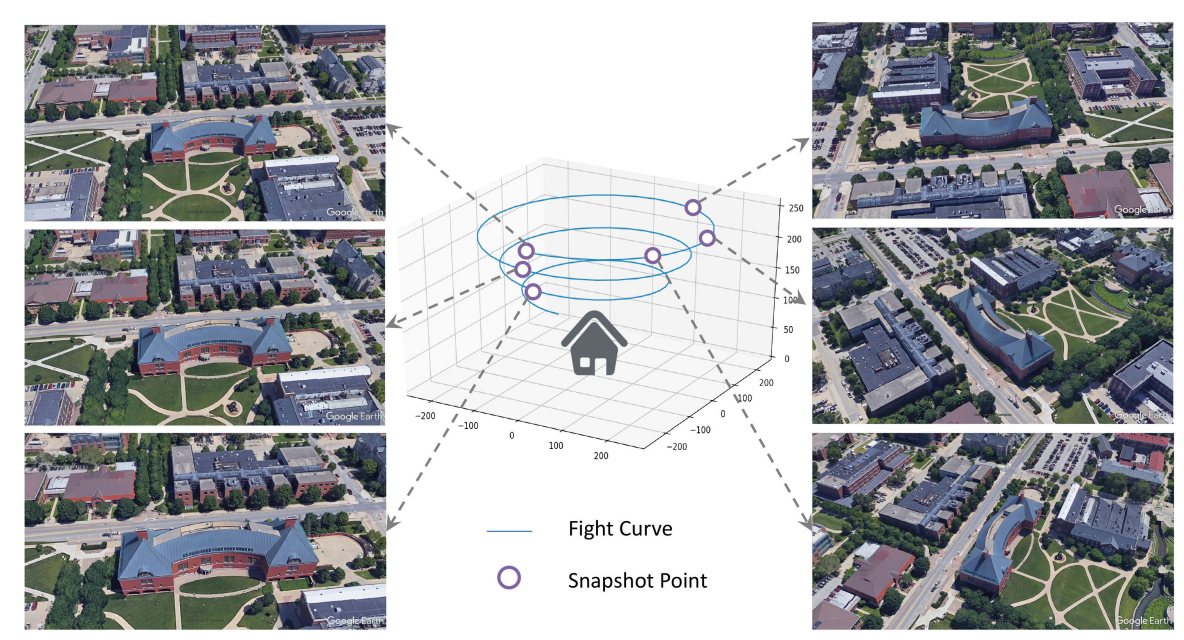
衛星画像に関してはGoogleマップを、地上視点画像に関してはGoogleストリートビューを活用して収集し、最終的に地上視点画像、ドローン画像、衛星画像が対応付けられたデータセットを作成しています。
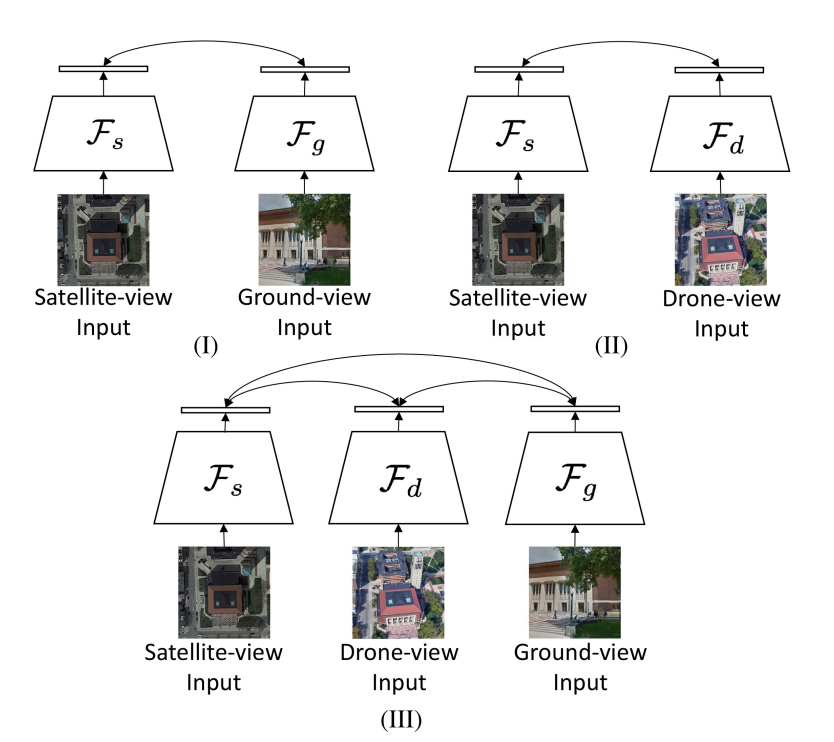
ネットワークアーキテクチャとして、3つの異なるプラットフォームからのデータが含まれるため、3つのブランチをもつCNN(下の図の(Ⅲ))を使用しています。
CNNとは視覚野における形状などの特徴抽出の仕組みをモデル化したニューラルネットワークのことです。なお、衛星画像用のCNNとドローンシミュレーション画像用のCNNはどちらも上空の視点から撮影していることから画像間で類似した特徴が多いため、画像から特徴抽出を行う部分の重みを共有した構造としています。
また、損失関数としてinstance lossを採用しています。
論文中では、様々な実験を行っていますが今回は2つ紹介いたします。
1つ目は参照画像として衛星画像を使用し、推定対象画像として地上視点画像とドローンシミュレーション画像の精度比較を行った実験です。
結果としては、ドローンシミュレーション画像を推定対象画像とした方が衛星画像とのマッチング精度が向上しました。これは、ドローンシミュレーション画像が地上画像に比べ、衛星画像と似たような視点であり、樹木などの障害物を避けて撮影することができるためと推察しています。
2つ目はドローン画像においてシミュレーション画像ではなく、実際に撮影した画像を用いた場合の検証です。実際のドローン画像を用いて追加学習を行い、シミュレーション画像による結果との違いを検証しています。
結果としては、シミュレーションのドローン画像と変わらない結果を得ることができています。このことから、たとえシミュレーション画像を利用したとしても、現実世界でも利用可能な高い一般化性能を持つことが分かっています。
3-3.ビデオに対する位置推定
Shruti Vyas, Chen Chen, and Mubarak Shah. GAMa: Cross-view Video Geo-localization. In ECCV, 2022.
公式実装(GitHubリポジトリ)のURL: https://github.com/svyas23/GAMa
ECCV2022における発表動画:
3つ目に紹介する論文は、地上視点として今までに紹介してきたような画像ではなく動画を推定対象とし、航空写真とマッチングすることで位置推定を行う論文です。地上視点の動画に着目したCross-Viewによる位置推定例は今までほぼないため、データセットの整備と動画に対する位置推定手法の提案をこの論文では行っています。
まずは、この論文で整備されたGAMaデータセットについてみていきます。地上視点の動画データとして、街中を走行中の車に搭載されたカメラの録画データであるBDD100kデータセットを用いています。
この動画データは、1本40秒ほどの長さで、録画時に携帯電話などで取得した毎秒の位置情報も別ファイルで一緒に公開されています。また、航空写真はAppleマップからズームレベル19(解像度約30cm)でダウンロードして使用しています。
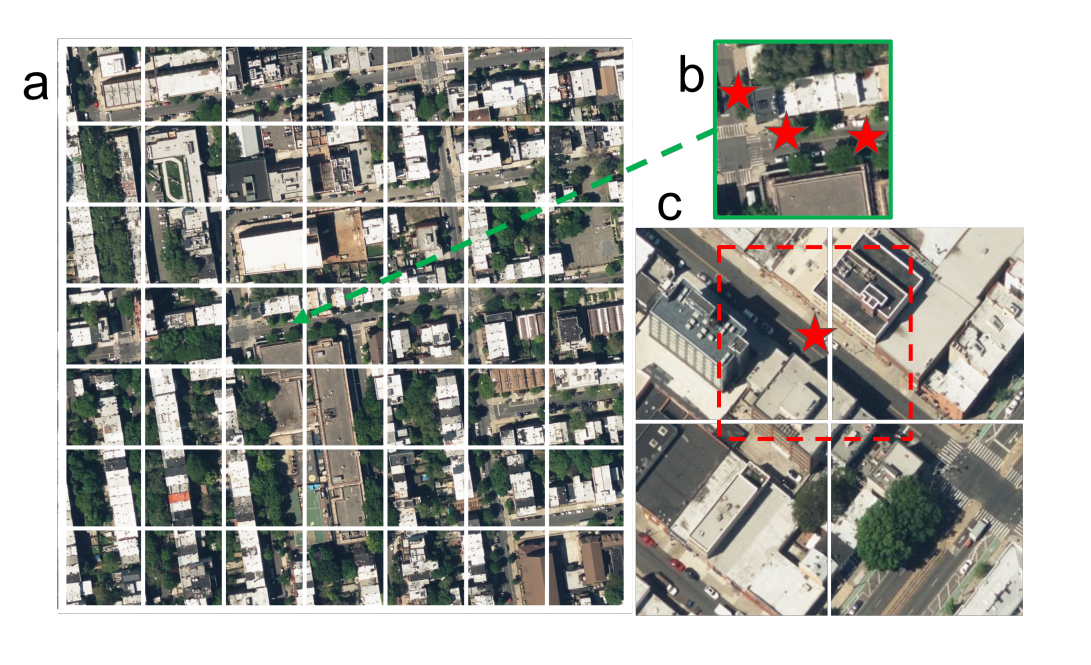
GAMaデータセットは、1つ当たりの動画に対応する大きな航空写真(a)とそれを49分割した小さな航空写真(b)、動画データに付与されている毎秒の位置情報を中心に切り出した航空写真(cの赤色の破線で描かれた枠)から構成されています。
続いて、提案手法についてみていきます。具体的には、動画と共に公開されている毎秒ごとの位置情報の座標を中心に画像サイズが256pxになるようにクロップした航空写真と0.5秒間隔でクリップした短いビデオ間のマッチングを行うGAMa-Net(詳しくは後述)と1つ当たりの動画に対応する航空写真とGAMa-Netの入力に使用した航空写真のマッチングを行うScreening Network(詳しくは後述)の2つのネットワークから構成されています。
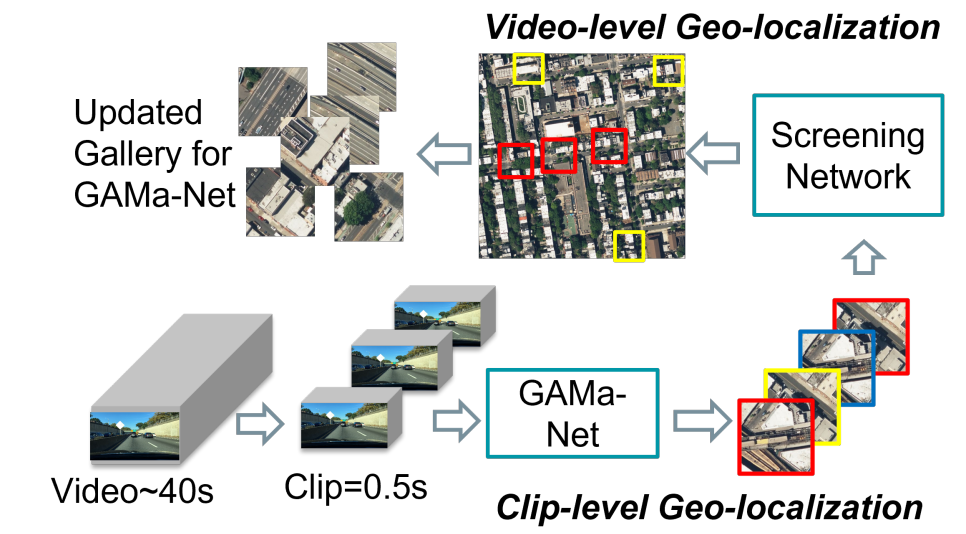
Screening Networkから構成されている。(図は紹介論文より引用)
GAMa-Net
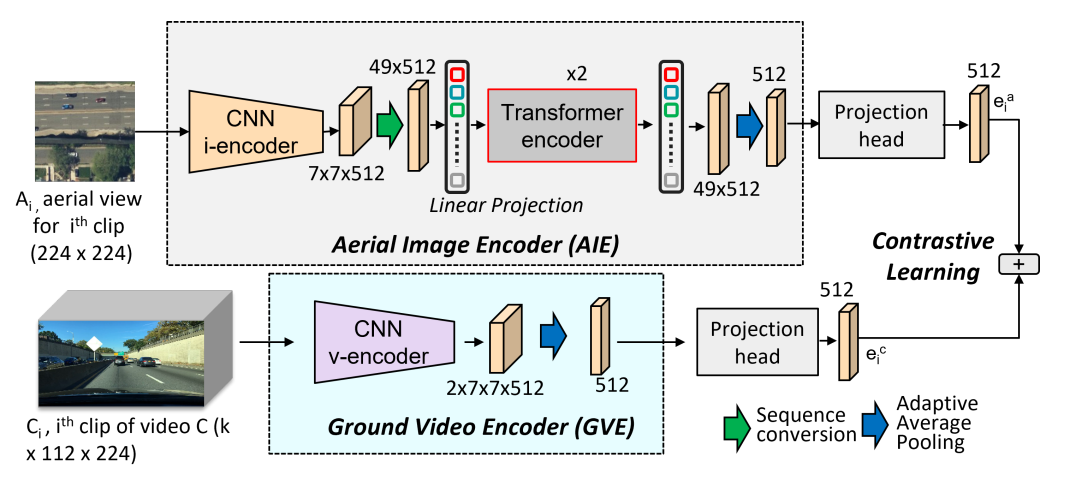
短くクリップした地上視点の動画を入力として受け取り、それに対応する航空写真とのマッチングを行うネットワークです。このネットワークは、動画から特徴を得るためのGround Video Encoder(GVE)と参照画像の航空写真から特徴を得るためのAerial Image Encoder(AIE)から構成されています。
GVEでは、地上から撮影した動画から時間軸方向も含めて特徴を抽出するために3D-ResNet18を用いています。AIEでは特徴抽出にResNet18を使用し、その後にTransformerが続く構造となっています。
Transformerは航空写真の中から地上動画で見える建物の壁面などマッチングに重要な特徴に着目するために使用しているようです。このネットワークの損失関数としてはNT-Xentを用いており、対応しているペアと対応していないペアを学習するようにしています。
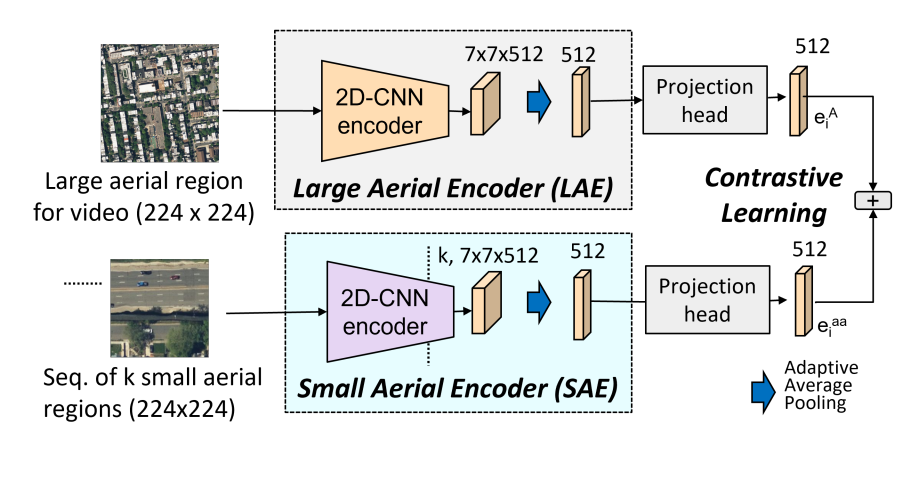
Screening Network
GAMa-Netで参照画像として使用した小さな航空写真を1つの動画に対応する大きな航空写真とのマッチングを行うネットワークです。このネットワークもそれぞれの航空写真の特徴を抽出する2つのエンコーダーから構成されています。
GAMa-Netに構成は似ていますが、入力が双方とも航空写真なのでResNet18を用いている点、視点が同じなためTransformerがない点が異なります。
提案手法と動画をフレームごとに切り出して静止画ベースで位置推定を行う既存手法を比較する実験を行ったところ、判読時間は遅くなったものの精度が向上していることが分かりました。
また、GAMa-Netの参照画像で使用する画像について、49等分した航空写真と動画の位置情報を中心に切り出した航空写真で精度を比較する実験を行っています。結果としては、動画の位置情報を中心に切り出した航空写真の方が精度が高いことが示されました。
しかし、実際に位置を推定したいのは位置情報が付与されていない動画です。そのため、49等分した航空写真のように画像端から等間隔で切り出した航空写真でも精度が低下せずに推定できるようにすることが課題として挙げられています。
4.Cross-Viewのよる位置推定を試す際のデータセット
最後に、実際に試してみる際に使うことができるデータセットを紹介いたします。ここでは紹介した論文中に出てきたデータセットを表形式で紹介いたします。
| データ セット名 |
CVUSA | CVACT | VIGOR | University- 1652 |
GAMa |
| 使用 プラット フォーム |
地上、 航空機、 衛星 |
地上、 衛星 |
地上、 航空機 |
地上、 衛星、 ドローン |
地上、 航空写真 |
| ライセンス | 不明 (データ取得 にはメール する必要あり) |
研究目的のみ 再配布禁止 |
研究目的のみ 再配布禁止 |
研究目的のみ 再配布禁止 |
不明 |
| URL | https://mvrl. cse.wustl. edu/ datasets/ cvusa/ |
https:// github.com/ Liumouliu/ OriCNN |
https:// github.com/ Jeff-Zilence/ VIGOR/ blob/main/ data/DATASET .md |
https:// github. com/layumi/ University 1652- Baseline# dataset– preparation |
https:// github. com/ svyas23/ GAMa |
上の表のライセンスの行を見ると分かるように、商用利用できるデータセットはいまのところほぼ無いと思われます。これは、GoogleのストリートビューやGoogle Earthの画像を用いてデータセットを作っているためです。
日本においては、国土地理院の地図・空中写真閲覧サービスや国土交通省のPLATEAUオルソにて航空写真が商用利用可能なライセンスで公開が行われています。また、地上視点の画像は、Mapillaryが商用利用可能なライセンスで公開を行っております。これらのデータを組み合わせて、日本における商用利用可能なデータセットを作成することも深層学習モデルを開発する上で考えられるかもしれません。
5.まとめ
本記事では、Cross-Viewによる位置推定について簡単な説明と論文紹介を行いました。最近、Cross-Viewによる位置推定に関する論文が増えてきているため、今後ますます身近なタスクになってくるかもしれません。
また、現在は商用利用可能なデータセットがほぼ無いと思われますが、日本では幸いなことに商用利用可能なライセンスで航空写真が公開されています。そのため、データセットやソリューションが日本から出てくる日も近いかもしれません。
