【2023年11月】衛星データ利活用に関する論文とニュースをピックアップ!
2023年11月に公開された衛星データの利活用に関する論文の中でも宙畑編集部が気になったものをピックアップしました。
宙畑の新連載「#MonthlySatDataNews」では、前月に公開された衛星データの利活用に関する論文やニュースをピックアップして紹介します。
実は、本記事を制作するために、これは!と思った論文やニュースをTwitter上で「#MonthlySatDataNews」をつけて備忘録として宙畑編集部メンバーが投稿していました。宙畑読者のみなさまも是非ご参加いただけますと幸いです。
2023年11月の「#MonthlySatDataNews」を投稿いただいたのは4人でした!
ポルトガル沿岸の貝類のバイオトキシン汚染をSentinel-3の衛星画像を使って予測する解析。
汚染のみの一変数と、汚染と衛星データを使った時系列予測を比較し、あるエリアでは1~2週間の予測向上が見られた。https://t.co/tslAXLLv89
#MonthlySatDataNews— むた (@MutaAzusa) November 30, 2023
アゼルバイジャンのイミシュリ市?における都市化を衛星データから確認したもの。
都市化すると、庭や裏庭の畑(家庭菜園より少しい規模は大きそう)が増えているという短い結論。国によって都市化して増えるものが変わりそう。https://t.co/hHwzC7iunK#monthlysatdatanews
— 🛰ナカムラトモヤ(宙畑、sorano me)🛰 (@tomoucky) November 30, 2023
Living within the safe and just Earth system boundaries for blue water https://t.co/GG3tdFR5vJ #MonthlySatDataNews
地表水と地下水を定量評価することで,地域ごとの持続可能な水資源管理について論じてこうとする論文.地下水はGRACE使ってる— たなこう (@octobersky_031) November 24, 2023
Sentinel-2衛星画像から50cm解像度相当で建物および道路の抽出を提案した論文。
超解像を行い、その出力に対してセグメンテーションを実行するのではなく、低解像度の入力から直接(エンドツーエンドで)高解像度のセグメンテーション結果を出力。https://t.co/DBnxl5X0nl#MonthlySatDataNews pic.twitter.com/agNdpTQsuf
— ぴっかりん (@ra0kley) October 31, 2023
それではさっそく2023年11月の論文を紹介します。
Synthesizing long-term satellite imagery consistent with climate data: Application to daily snow cover
【どういう論文?】
・本研究では、気候変動の重要な指標である積雪量の変化を把握するために、気候データ、地形による影響、衛星データを用いて30m解像度の雪被覆画像を生成する新しい手法を提案する
・気候データと衛星観測データを用いて、高解像度の雪被覆推定を実現することに重点を置いている
【技術や方法のポイントはどこ?】
①インプットデータ
・雪被覆の推定に必要な入力データとして、主に気候変数(気温と降水量)と環境変数(地形と影の有無)を使用
②雪被覆の推定プロセス
・各調査日に対して、前処理した気候変数と環境変数から入力ベクトルを作成
・K-近傍アルゴリズムを使用して与えられた入力ベクトルに最も近い過去の雪被覆データを見つけ、それを基に雪被覆の推定が行う(「近い」とは、気候変数と環境変数の組み合わせに基づく類似性の尺度を意味する)
・バイナリな雪被覆(雪があるかないかの単純な表現)の場合、K個の日付から最も頻繁に観測される雪被覆の状態(存在するかしないか)を選択する
・雪が存在する上で、NDSI(雪を検出するための指標)を計算する場合、K個の学習日の平均値を使用する
③実際の使用データセット
・Landsat 5~8衛星データ:地表反射率時系列データを使用して、日毎の雪被覆画像を作成
・Sentinel-2衛星データ:Sentinel-2のLevel-2Aの画像が学習データセットに追加し、より頻繁な雪被覆データを得るためにLandsatと組み合わせる
・気候データ:最低/最高気温と降水量データは、ERA5-LandとMeteoSwissの気候データセットから取得
・影のデータ:NASA SRTMデジタル標高データとMOD08 V6 Terraから生成
④その他条件
・研究地域:西スイス(最大標高3188mのアルプスの一部、397枚のほぼ晴天のLandsat/Sentinel-2画像が2000年から2019年まで利用可能)とThur Jonschwil流域(最大標高2445mで、181枚のほぼ晴天のLandsat/Sentinel-2画像が2000年から2019年まで利用可能)
⑤シナリオ
Satellite-Ageシナリオ
・2000年から2019年の間、衛星による雪被覆画像が利用可能な場合に適用
・このシナリオでは、MODISなどの補助データを活用
Pre-Satelliteシナリオ
・同じ期間内で、MODISやLandsat/Sentinelの30m雪被覆データが利用できない場合に適用
・この場合、気候データと地形による影の情報のみを予測因子として使用
【議論の内容・結果は?】
・複数のデータセット(温度指数モデル、MODIS、PlanetScope、MeteoSwiss、HRSI-FSCOG)との比較分析を行った
・シナリオ間の比較では、Satellite-Ageシナリオは、全体的な精度で1.32%、NDSIのRMSEで0.08の改善を示し、Pre-Satelliteシナリオよりも優れていた
・本研究手法は、温度指数モデルと比較して高い精度を達成した
・MODISとの比較では、Pre-Satelliteシナリオで合成された30 m雪被覆とNDSIは、MODISと比較して、雪被覆ではより高い性能、NDSIでは若干低い性能を示した
・PlanetScopeとの比較では、本研究手法による雪被覆の平均全体精度は85%であった
・地上観測所との比較では、20年間の日毎の積雪深データを用いた比較で、提案手法による雪被覆の精度は、実際の雪被覆画像と同様の精度を示した
・HRSI-FSCOGとの比較では、本研究手法による雪被覆の平均全体精度は94%と高かった
・気候データに関しては、1 km解像度の気候データを使用した場合、11 km解像度と比較して、全体的な精度とNDSIのRMSEにわずかだけ改善した
Coarse-to-fine matching via cross fusion of satellite images
【どういう論文?】
・マルチモーダル衛星画像のマッチングにおいては、異なる撮影角度やセンサー特性により、同じ地点の特徴点を異なる画像間で一貫して識別することが困難である
・上記の問題に対処するため、本論文ではDF-Net(デュアルブランチ融合ネットワーク)を提案し、広範な特徴の融合とクロスモーダル特徴の類似性を捉えることを目指す
【技術や方法のポイントはどこ?】
・既存の衛星画像マッチング手法が直面する非線形放射計差や局所的な幾何学的歪みによる課題を解決する
・DF-Netは衛星画像のペア間での正確な対応関係を確立するために設計されたネットワークであり、その主要な構成要素とプロセスは次のように整理できる
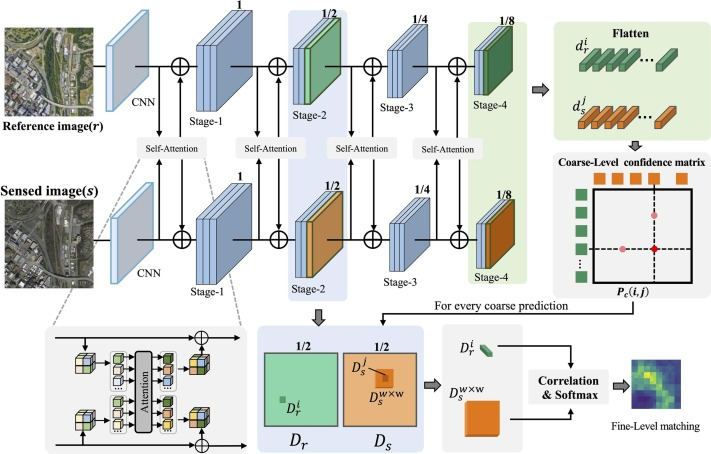
①デュアルブランチネットワーク構造
・DF-Netは、高解像度マップと低解像度マップを生成するために、2つの独立したパスを持つ残差ネットワークに基づいている。これらのパスは、デュアルブランチ構造を形成し、画像の異なる解像度の特徴を抽出する
②セルフアテンションメカニズム
・セルフアテンションメカニズムは、デュアルブランチネットワークの横に位置しており、異なるモードの特徴を統合することで、包括的で詳細な特徴記述を可能にする
・本メカニズムは、局所的特徴とグローバルな文脈情報の両方を考慮することで、より豊かな特徴表現を実現し、異なる画像モード間での一貫性を高める
③マッチングプロセス
・DF-Netのマッチングフェーズは、大まかな対応関係を確立する「粗いマッチング」と、これらの対応関係を細かく調整する「細かいマッチング」の2つの段階に分けられる
・まず、粗いマッチングでは、低解像度特徴マップから抽出された1次元ベクトルを用いて信頼度マトリックス(2つの画像間の各特徴点の類似度評価)を作成し、このマトリックスを基に最初ののマッチング予測を行う
・次に、細かいマッチングでは、粗いマッチングの結果を高解像度特徴マップに投影し、小さな局所窓内での詳細な位置合わせを行い、サブピクセルレベルのマッチング精度を達成する
④その他特徴
・DF-Netは並列残差ブロックで構成されており、各ブロックにジャンプ接続があり、訓練と最適化が容易である
・特徴抽出は、畳み込み操作と4段階の残差ネットワークを通じて行われる
・垂直クロスアテンションモジュールはセルフアテンションに基づいており、グローバルな情報を捉えるための受容野を拡大し、異なるモード間の特徴の相関を高めることで類似性のある特徴記述を派生させる
・低解像度の特徴マップはマッチング層によって区別され、特徴間のスコアマトリックスが計算され、このマトリックスに基づいて、可能な粗いマッチングをフィルタリングする
・粗いマッチングで確立された対応関係は、細かいマッチングによって元の画像サイズに精細化され、完全連結層ベースの類似度メソッドを用いて、細かいマッチング結果をさらに洗練させる
【議論の内容・結果は?】
①前提
・Rep.(Repeatability):画像ペア間で同じ位置に検出されるピクセルの数の比率で、繰り返し検出されるピクセルの割合
・MMA(Mean Matching Accuracy):指定されたピクセル閾値内での正確な対応点の平均割合
・RMSE(Root-Mean-Square Error):全体的なマッチング性能を評価するために使用する指標で、マッチングポイント間の平均二乗誤差の平方根
②結果
・DF-Netは他の比較手法よりも高いRep.とMMAを達成した
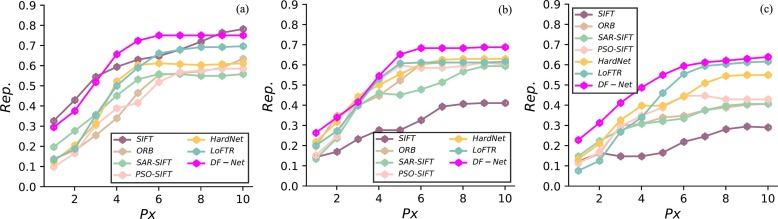
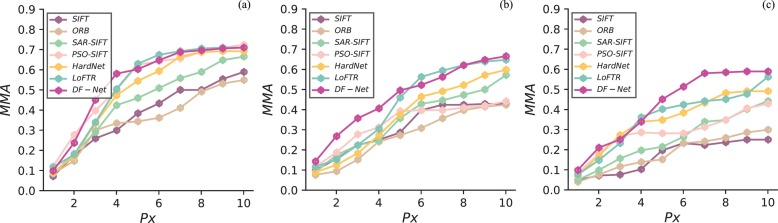
・これらの結果は、DF-Netが特にマルチモーダル画像マッチングにおいて高い性能を発揮することを示している
・DF-Netの平均再現性(Rep.)が0.71、平均マッチング精度(MMA)が0.65、そして根平均二乗誤差(RMSE)が2.34であることから、クロスモーダルマッチングにおいて優れた性能を持つことを示している
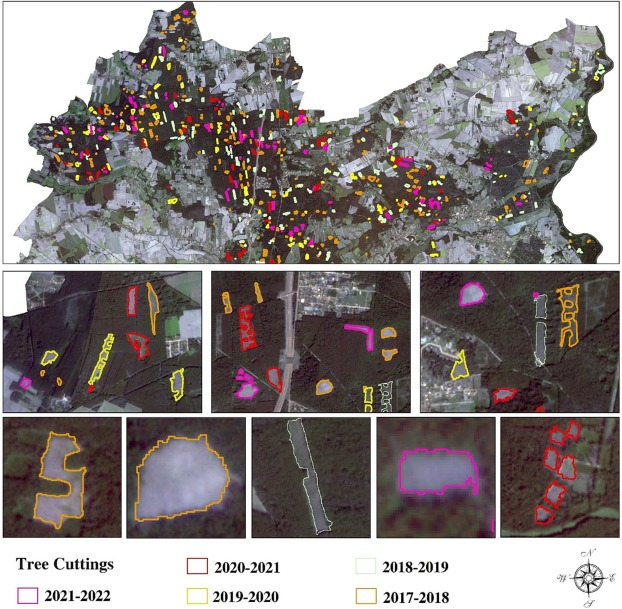
Comparing Object-Based and Pixel-Based Machine Learning Models for Tree-Cutting Detection with PlanetScope Satellite Images: Exploring Model Generalization
【どういう論文?】
・森林における衛星データの活用に関して、低分解能の衛星画像では、森林内の微妙な変化や小規模な伐採エリアの検出が難しく、LiDARデータなどを光学衛星画像と統合する方法は、データの可用性やコスト、技術的な課題がある
・本研究では、PlanetScope衛星からの高解像度(VHR)画像を利用することで、直接、森林/地表の変化を認識する方法を提案する
・また、ピクセルベース(PBIA)とオブジェクトベース(OBIA)の画像解析手法を比較し、森林の正確なマッピングと伐採検出におけるそれぞれの有効性を評価する
・ランダムフォレスト(RF)、サポートベクターマシン(SVM)、ニューラルネットワーク(Nnet)の3つの機械学習モデルの訓練と評価を行っている
【技術や方法のポイントはどこ?】
①データ収集と前処理
・空中レーザースキャン(ALS)を使用して、森林の高さ情報を取得し、キャノピー高さモデル(CHM)を生成。
・高解像度航空写真(VHR)を利用して、時間経過に伴う森林の変化を捉えるための参照データセットを作成
②特徴抽出と機械学習モデルの訓練
・PlanetScope衛星画像から得たデータを用いて、植生指数(VIs)やテクスチャに関する特徴(GLCM)を抽出
・上記の特徴を利用して、ランダムフォレスト(RF)、サポートベクターマシン(SVM)、ニューラルネットワーク(Nnet)という3種類の機械学習モデルを訓練
・上記のモデルをピクセルベースの方法(PBIA)とオブジェクトベースの方法(OBIA)の2つの異なるアプローチを使用して比較
・PBIAでは、画像の各ピクセルを独立したデータポイントとして扱い、それぞれのピクセルの特徴に基づいて分析する
・対して、OBIAでは、関連するピクセルをグループ化して意味のあるオブジェクトとして扱い、これらのオブジェクト全体の特徴を分析する
【議論の内容・結果は?】
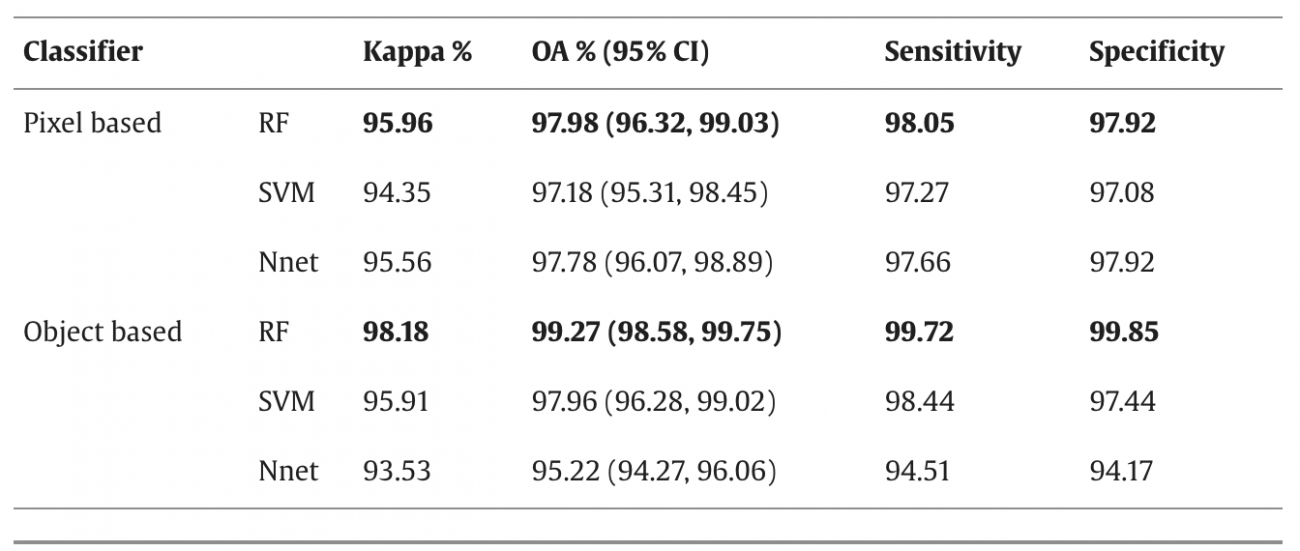
①ピクセルベース対オブジェクトベースの機械学習モデル
・オブジェクトベースのランダムフォレスト(OBIA RF)分類器は全体的な精度(OA)が99.27%、カッパ値が98.18%で、他のモデルよりも優れていた
・オブジェクトベースのニューラルネットワーク(OBIA Nnet)はOAが95.22%、カッパ値が93.53%と最も低かった
・RFモデルは感度が99.72%、特異性が99.85%であり、他のSVMとNnetモデルよりも正確な正の事例(非森林地域)と負の事例(森林地域)の識別において優れていた
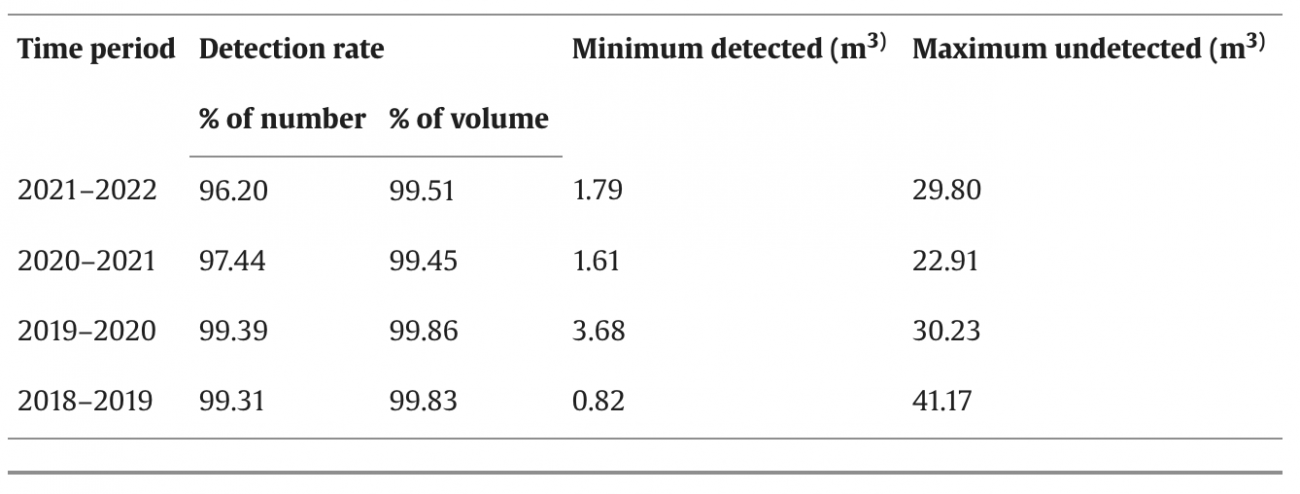
②伐採検出の精度評価
・伐採エリアの検出率は、伐採の総数に対して96.20%から99.39%、伐採の総容積に対しては99.45%から99.86%に及んだ
・最も高い検出精度は2019年から2021年の期間に観察され、伐採の総数で99.39%、総容積で99.86%が検出された
・最小の検出可能な伐採量は2018年から2019年の期間で0.82m³とされ、最大の未検出伐採エリアは同じ期間で41.17m³に達した
Using deep transfer learning and satellite imagery to estimate urban air quality in data-poor regions
【どういう論文?】
・本研究は、低・中所得国(LMICs)の都市での大気質(Air Quality)を推定するための新しい深層学習手法(以下、DeepAQ)を提案する
・高所得国(High-Income Countries, HICs)におけるMaxar衛星画像と地上データを用いて訓練されたDeepAQモデルを、転移学習を使用してLMICs(アフリカのガーナとアクラ)の都市に適用する
【技術や方法のポイントはどこ?】
・ResNet-34ベースのCNNと生成的敵対ネットワーク(GAN)を組み合わせたモデルを採用する
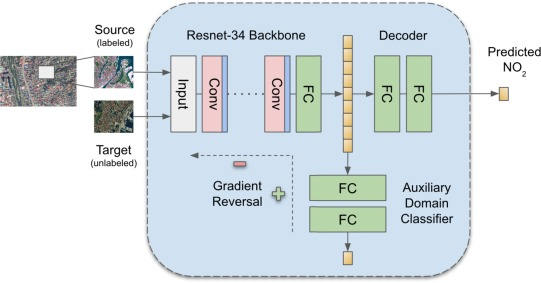
・転移学習では、ソースドメイン(HICsの都市)から得た知識をターゲットドメイン(LMICsの都市)に適用する
・教師なしのドメイン適応(Unsupervised Domain Adaptation, UDA)を採用し、ラベルのないターゲットドメインへのモデル適応を行う。
・UDAは、ソースとターゲットの特徴を共通の特徴空間にマッピングし、モデルが訓練とテストのドメインデータサンプルを区別できないようにする
・訓練データには、MAXAR WorldView2 (WV2)の300以上の生の衛星画像を使用し、80×80ピクセルのパッチを抽出し、それぞれ200 m x 200 mの領域をカバー
・補助入力として、各パッチから最寄りの主要道路までの距離が与えられ、モデルの学習中にローカライズされたアテンションを喚起する
・近接する道路との距離は、NO2レベルと強く相関するため、モデルは入力パッチの予測値を決定する際に、補助入力値が類似した近くのパッチに注目する
【議論の内容・結果は?】
・ロサンゼルスでの訓練データを使用したモデルでは、R2スコアが0.806、相関係数が0.91に達し、高い精度で大気質を推定できることを示した
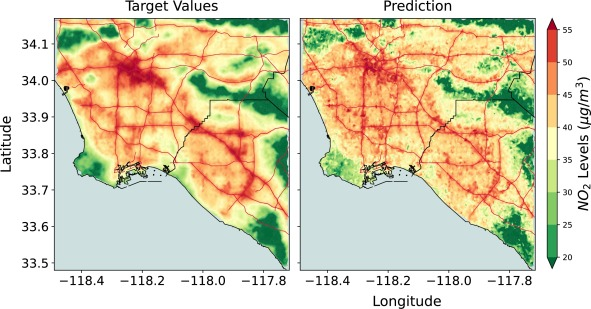
・ニューヨークへの転移学習では、ベースラインモデルに比べてR2スコアが約2.7倍向上し、NRMSEも32%低下
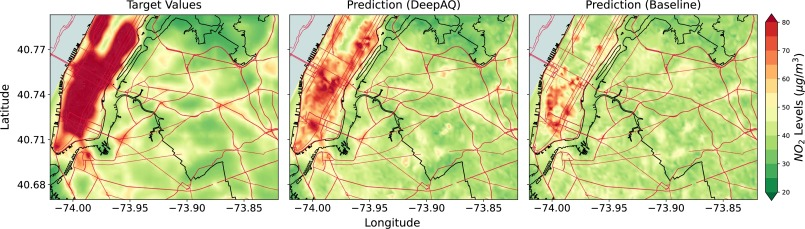
・ Accra(Ghana)での実験では、R2スコアが0.541、NRMSEが0.297となり、ベースラインモデルよりも約26%改善
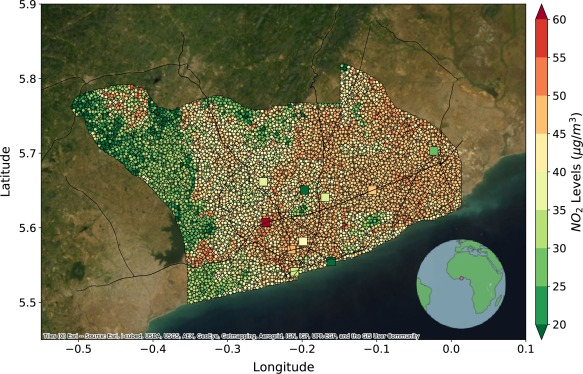
・DeepAQの主な制限は、極端な値の予測での精度低下であるが、これは訓練データが極端な範囲で少ないためである
・複数の都市から得たデータを使用することで、より幅広い特徴の学習が可能になる可能性がある
・DeepAQは完全な地上データの代替ではなく、補完的な手法として提案されており、地域固有の情報を追加することで精度をさらに向上させることが可能と示唆された
Forecasting freshwater cyanobacterial harmful algal blooms for Sentinel-3 satellite resolved U.S. lakes and reservoirs
【どういう論文?】
・本研究は、アメリカ合衆国の2192の湖と貯水池におけるシアノバクテリア(藍藻、cyanoHAB)の有害藻類の発生を予測する手法を提案する
・Sentinel-3のデータを用いて、シアノバクテリアの生物量を検出し、
WHO(世界保健機関)のアラートレベル1を超える発生確率を予測する
【技術や方法のポイントはどこ?】
①衛星データを用いたシアノバクテリアの監視
・シアノバクテリアの生物量を推定するのに利用される特定の光の波長(665 nm、681 nm、709 nm)のデータを利用する
・これは、シアノバクテリアが特定の波長の光を吸収する性質を利用したClcyanoアルゴリズムによって推定する手法である
②環境予測因子の使用
・湖の水面温度、降水量、湖の深さ、湖の表面積といった環境要素を、シアノバクテリアの発生を予測するための因子として利用する
・水面温度は、空気温度や湖の地理的特徴を考慮して、PRISM気候データに基づくランダムフォレストモデルによって推定される
③INLA(統合ネステッドラプラス近似)モデルの適用
・本モデルは、複数の計算ステップを経て、シアノバクテリアの発生確率を推定する
※INLAとは・・・複雑なベイジアンモデルの近似計算を効率的に行うための方法である。通常、データから何かを予測するためには多くの計算が必要だが、INLAはこれをもっと簡単に解決する方法を提供する。まず、何を分析するか(この場合はシアノバクテリアの発生)と、そのデータにどのような規則が適用されるかを決める。 実際のデータの計算には複雑な数式が必要だが、INLAは「近似」という方法を使って、もっと簡単にこれを推定する。
【議論の内容・結果は?】
・モデルの評価結果は、AUC(曲線下面積)は0.96、精度、感度、特異性はすべて0.90以上だった
・精密度は0.42とやや低めだった(陽性と予測された事例の中に誤った予測が多い。モデルは陽性の判断をする際にやや慎重さに欠ける可能性がある)が、偽陰性率は0.01と非常に低く、F1スコアとカッパ値はそれぞれ0.58と0.53で、良好なモデル性能を示した
・以下の画像では、WHO 警戒レベル1の可能性が高い湖は暖色で示している(寒色は逆を示す)
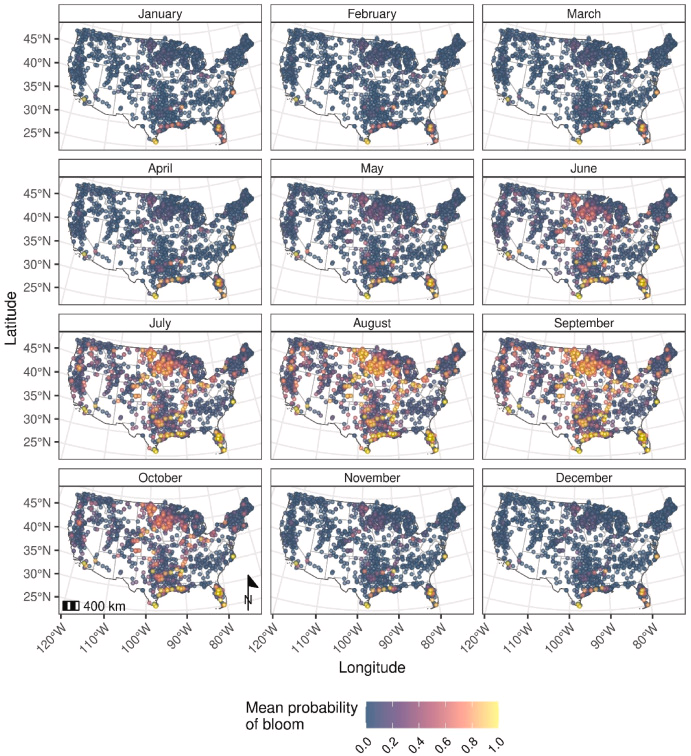
・本モデルはアメリカ合衆国内の広範囲にわたる湖の監視に応用されたが、水面近くのみの予測であり、深さによるバイオマスの変動は考慮されていない
Sand subfractions by proximal and satellite sensing: Optimizing agricultural expansion in tropical sandy soils
【どういう論文?】
・本研究は、熱帯地域における砂質土壌の砂の細分類をリモートセンシング技術を使用して予測し、農業拡大の最適化を図る手法を提案する
【技術や方法のポイントはどこ?】
①サンプリング
・0〜20 cmの深さでブラジル・マットグロッソ州の216箇所でサンプリングした
・総砂(TS)、シルト、粘土をピペット法で分類し、TSはさらに5つの細分類(非常に細かい砂、細かい砂、中粗砂、粗い砂、非常に粗い砂)した
②実験室データ
・FieldSpec 3分光放射計を使用し、350–2500 nmのスペクトルデータを収集
・Bruker Alpha II装置を使用し、土壌サンプルのスペクトルデータを取得
③衛星データ
・Landsat-5およびSentinel-2から衛星画像を取得
・GEOS3システム(Geospatial Soil Sensing System)を使用して、取得した衛星画像から土壌の裸地(植生のない土地)の反射率データを抽出
・抽出したデータから、特定のスペクトルバンド比率や指数(Red/Green、Red/SWIR1、SWIR1/SWIR2、NDVI、GSIなど)を計算
④Landsat、Sentinel、ASTERデータの畳み込み
・異なる衛星センサーから得られるデータの分析能力を実験室条件下で評価するべく、実験室で取得したスペクトルデータに対し、Landsat-5、Sentinel-2、ASTERのスペクトルバンドに相当する範囲で畳み込みを実施
⑤データの処理と分析:
・土壌の全砂(TS)、粘土、シルト、砂の細分類と、上記③と④で得られた”反射率データ”との間でPearson相関分析を実施
・AlradSpectraソフトウェアを用いて、上記のデータから9つの予測モデルを構築
【議論の内容・結果は?】
・TSの減少に伴い、特にSWIRとMIRで反射強度が低下した
・上記の変化は、Landsat-5とASTERでより多くのバンドにわたって観察された
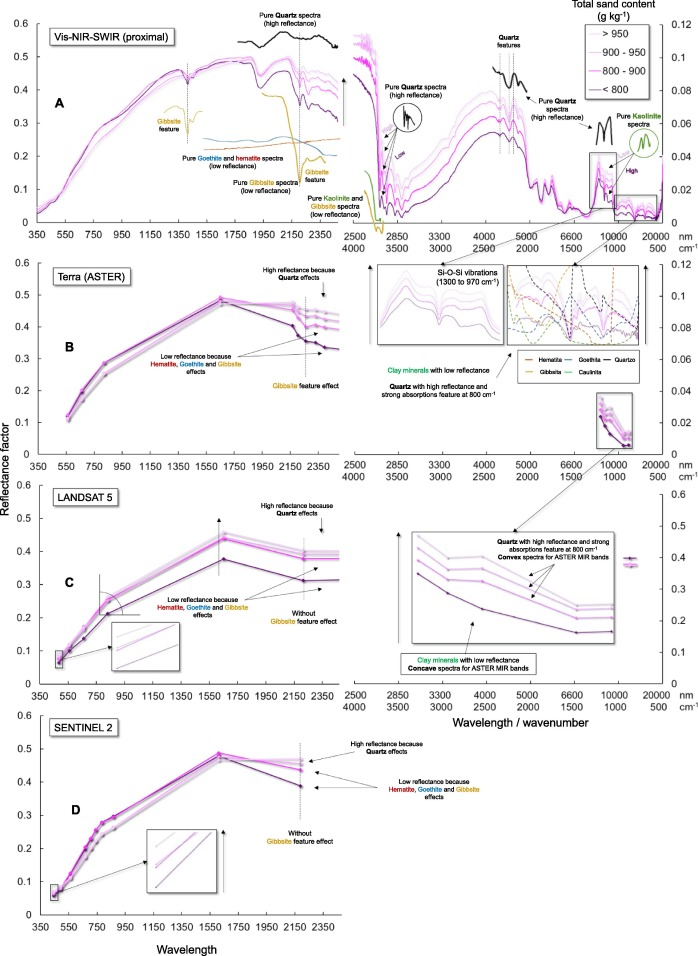
・PCA分析の結果、SWIRの単独使用がVis-NIR-SWIRを合わせたものよりもデータセットの変動をより正確に説明することを示した
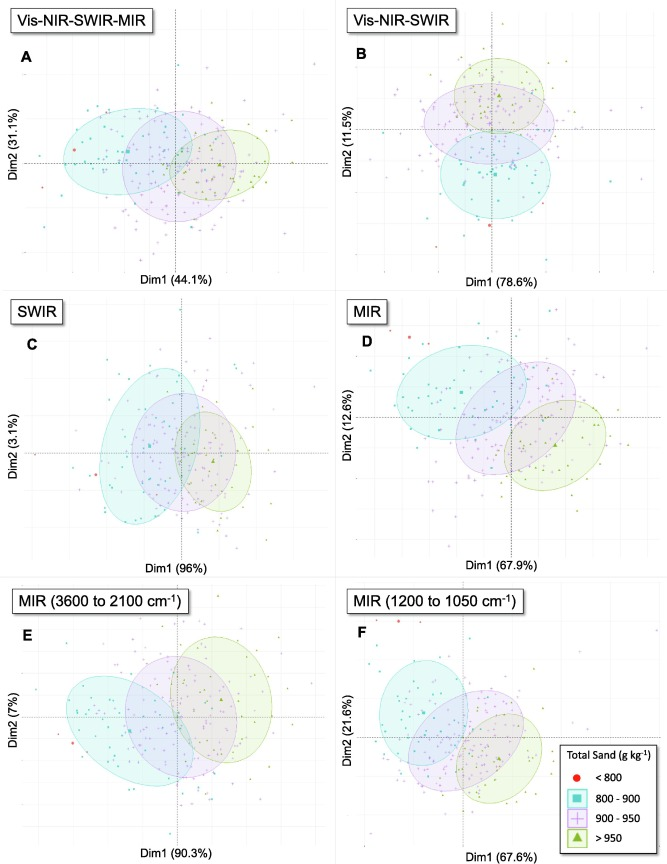
・SWIRでは、純粋な石英は高い反射率を示し、純粋な粘土鉱物は高い吸収を示した
・LS5、LS5c、SENT、SENTc、ASTERc、pXRFの予測変数と土壌の粒径分画との間に相関を確認できた
・R2、RMSE、RPIQによる評価で、最も優れたモデルはVNS + MとASTERcであった
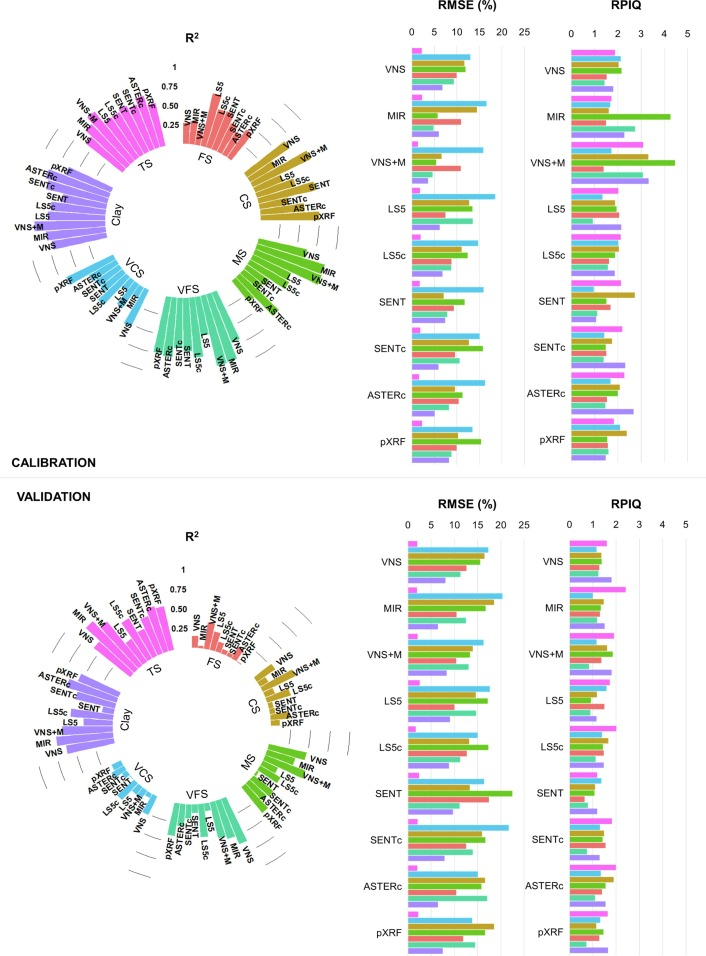
・結論としては以下が挙げられる
-Vis-NIR-SWIR反射率と主要な砂粒子径は逆相関
-MIRスペクトルは化学的・鉱物学的効果をより顕著に反映し、反射パターンが逆転する
-SWIRとMIRバンドは、砂質土壌のテクスチャ分画の特徴付けと予測に不可欠
-ASTERは、土壌のテクスチャクラスと鉱物学的組成の識別に有効
-実験室データのモデルは、標準および畳み込まれた衛星モデルと比較して、わずかに高い精度を示した
Riverine litter monitoring from multispectral fine pixel satellite images
【どういう論文?】
・本研究は、マルチスペクトル衛星画像を利用して河川に浮かぶごみを検出し、表面積を定量化する技術を提案する
【技術や方法のポイントはどこ?】
①使用データ
・衛星画像:Planet Labs PBCの約200のDoveとSkysatおよびMaxarのGeoEye-1
・具体的な画像: PlanetScopeから28枚、Skysatから7枚のクラウドフリー画像
②データ処理
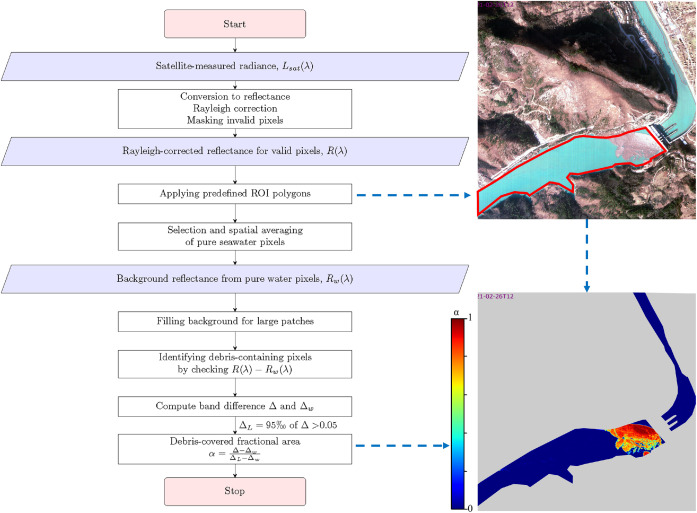
・水の背景反射率とごみの反射率の違いを利用(NIRと緑の波長差を使用)して、ピクセルごとに浮遊ごみの割合を計算
・NIR波長帯は740 – 900 nmの間を利用することを推奨する
【議論の内容・結果は?】
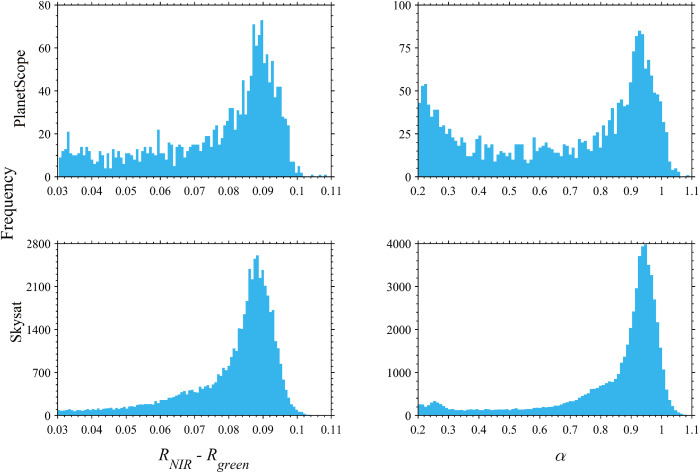
・バンド差Δ = R(λNIR) − R(λG) は、近赤外(NIR)と緑(G)の波長での反射率の差を示す
・このバンド差を用いて、画素がどの程度ごみで覆われているかを示すごみ被覆率(α)が算出される
・α=1は、ΔRのヒストグラムにおいて95パーセンタイルに相当し、完全にごみで覆われたピクセルを意味する
・PlanetScopeとSkysatで得られたデータにおいて、値が0.9から1.0の範囲でピークを示している場合、これは大規模なごみの集積を示す
・値が0.3未満の場合、散在する小さなごみのパッチを示唆していると考えられるが、実際には、衛星の計測ノイズ(計測機器の誤差)によるものである可能性が高い(このような小さな値はPlanetScopeの方がSkysatよりも多く見られた)
・値が0.5以上の場合、PlanetScopeとSkysatから得られたごみ被覆面積の推定値は密接に一致していたが、値が0より大きい場合、推定値は40%まで大きく乖離した
・GeoEyeとSkysatの画像を用いたアルゴリズムと手動推定の間で非常に強い線形相関(R² = 0.9961、α>0.5およびR² = 0.9969、α>0)が見られ、アルゴリズムの信頼性を確認できた
以上、2023年11月に公開された論文をピックアップして紹介しました。
皆様の業務や趣味を考えた時に、ピンとくる衛星データ利活用に関する話題はありましたか?
最後に、#MonthlySatDataNewsのタグをつけてTwitterに投稿された全ての論文をご紹介します。
Non-Visible Light Data Synthesis and Application: A Case Study for Synthetic Aperture Radar Imagery
来月以降も「#MonthlySatDataNews」を続けていきますので、お楽しみに!
