【2024年3月】衛星データ利活用に関する論文とニュースをピックアップ!
2024年3月に公開された衛星データの利活用に関する論文の中でも宙畑編集部が気になったものをピックアップしました。
宙畑の新連載「#MonthlySatDataNews」では、前月に公開された衛星データの利活用に関する論文やニュースをピックアップして紹介します。
実は、本記事を制作するために、これは!と思った論文やニュースをTwitter上で「#MonthlySatDataNews」をつけて備忘録として宙畑編集部メンバーが投稿していました。宙畑読者のみなさまも是非ご参加いただけますと幸いです。
それではさっそく2024年3月の論文を紹介します。
Transformer-Based Semantic Segmentation for Extraction of Building Footprints from Very-High-Resolution Images
どういう論文?
・Vision Transformer(ViT)ネットワークは、高解像度の衛星画像から物体を識別する際のセマンティックセグメンテーションタスクにおいて、従来の畳み込みニューラルネットワーク(CNN)よりも優れた性能を示しているものの、超高解像度(VHR)画像のオブジェクト抽出にどのように最適化すべきかは、十分な研究が行われてこなかった
・本研究では、衛星画像から建物のフットプリント(形状や面積)を抽出することを目的として、異なるハイパーパラメータ値を持つ複数のViTモデルを設計し、それらの精度に与える影響を比較検証を行なった。
技術や方法のポイントはどこ?

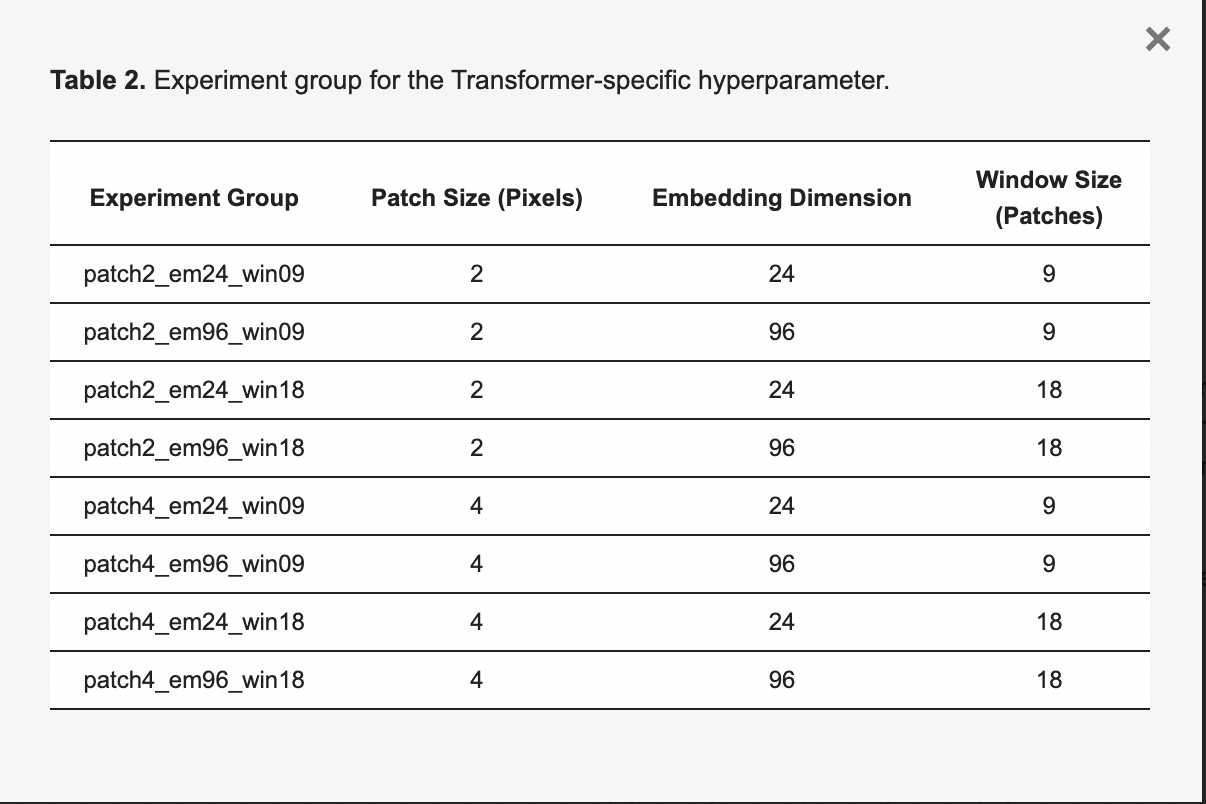
①パッチ分割
・本ステップでは、高解像度の衛星画像を一定サイズの小さなパッチに分割する
・通常の画像解析とは異なり、Transformerは画像全体ではなく、パッチ単位で情報を処理することで、画像の局所的な特徴を保持し、後続の処理でセルフアテンションメカニズムを効率的に適用する
②線形埋め込み
・各画像パッチを線形変換を通じて高次元ベクトルに変換する
・本変換により、画像の生のピクセルデータが、ニューラルネットワークで処理しやすい形式(数値データ)に変換される
③SwinTransformer
・パッチをさらに小さなウィンドウにグループ化し、ウィンドウ内で局所的なセルフアテンションを適用する
・また、一つのウィンドウから次のウィンドウへと、位置をずらしながら処理を行うことで、隣接するウィンドウ間で情報を共有し、画像全体を通して情報を繋げることができる
・ウィンドウ内のみに計算を限定することで、必要な計算量を減らし、速く処理することが可能である
④ピラミッドプーリングモジュール
・異なる解像度の特徴を複数のレベルで集約し、モデルが画像の大域的な文脈を理解できるようにする
・本ステップは、画像全体の様々なスケールの情報を取り込み、モデルが建物のようなオブジェクトの大きな形状や配置を把握するのに役立つ
⑤特徴ピラミッド融合
・ピラミッドプーリングモジュールからのグローバルな特徴とSwin Transformerからの局所的な特徴を組み合わせることで、より豊富で多層的な特徴表現を行う
⑥セグメンテーションヘッド
・本最終ステップでは、融合された特徴マップを元の画像サイズにマッピングするためにアップサンプリングを行う
議論の内容・結果は?
・2×2ピクセルのパッチサイズ(小さな特徴抽出が可能)と96次元の埋め込み(複雑な特徴表現が可能)を持つモデル( ‘patch2_em96_win09’モデル)が、全ての評価指標で最高のスコアを達成した
・同じパッチサイズと埋め込み次元を持つモデル間では、ウィンドウサイズが異なっても評価結果が類似しており、ウィンドウサイズが抽出精度に与える影響は小さいことが示された
・つまり、より小さい画像パッチと高次元の埋め込みが、建物抽出の精度を向上させることを示唆している
・パッチに関しては、一般的な4ピクセルや6ピクセルのパッチよりも、2ピクセルのパッチがVHR画像分析で好まれるという結果が示された

Credit : Jia Song, A-Xing Zhu, Yunqiang Zhu. (2024).Transformer-Based Semantic Segmentation for Extraction of Building Footprints from Very-High-Resolution Images Retrieved from https://www.mdpi.com/1424-8220/23/11/5166
・大規模な建物は、96次元の埋め込みを使用したモデルでより正確に抽出することがわかった

・小規模な建物に関しては、より小さい2×2ピクセルの画像パッチを使用したモデルが、4×4ピクセルの画像パッチを使用したモデルよりも優れた性能を発揮した

#VisionTransformer #ViT #swinTransformer #embedding
Rethinking Transformers Pre-training for Multi-Spectral Satellite Imagery
どういう論文?
・過去の衛星画像の事前学習手法では、画像内のピクセル間の距離(スケール)が異なる画像に対して一定の解像度やスケールで処理を行っていたため、特にマルチスペクトルデータのような異なるスケールを持つ画像の情報を十分に活用できていなかった
・本論文では、SatMAE++という事前学習時にマルチスケールの情報を活用する新しい手法を提案する
技術や方法のポイントはどこ?

①概要
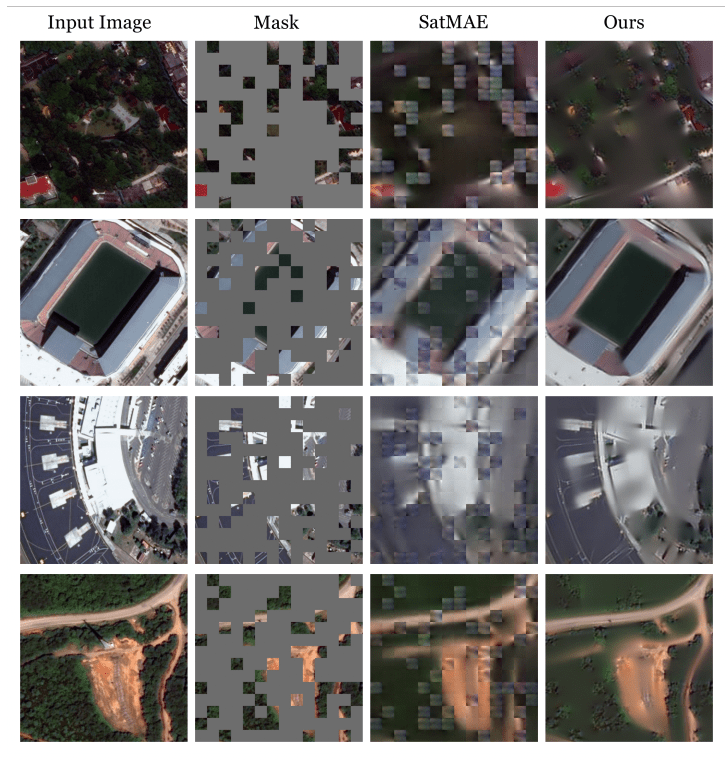
・SatMAE++とは、衛星画像データの解析に特化した、マルチスケール事前学習と畳み込みベースのアップサンプリングを利用した画像再構成手法である
・本手法では、異なるスペクトルデータの特性を理解し、精密な位置エンコーディングを通じて、画像内の複数のスケールとモダリティに対応可能なより深い特徴抽出と解析を可能にする
・特に、異なるスペクトル帯域の画像データを効率的に処理するために地表サンプル距離(Ground Sample Distance, GSD)に基づいてチャンネルをグルーピングし、位置エンコーディングを調整して異なるスケールのオブジェクトを識別できるように設計されている
②ベースラインフレームワークの設定
・使用するSatMAEフレームワークは、自己教師あり学習アルゴリズムの一種で、画像データから一部情報をマスキングし、後にそのマスクされた情報を再構築することを目的としている
・地表サンプル距離(Ground Sample Distance, GSD)は、衛星画像内の1ピクセルが実際の地表の面積を示し、これに基づいて画像の各チャンネルをグルーピングする
・同じGSDを持つチャンネルをグルーピングすることで、スペクトル解析の一貫性を保つことができるようになり、モデルは異なるスペクトル特性を持つデータを効率的に処理し、各スペクトル帯域の情報を学習する能力が向上する
・衛星画像では、同一画像内でオブジェクトのスケール(大きさ)が変わる可能性があるため、位置エンコーディングを調整し、モデルが異なるスケールのオブジェクトを正確に識別できるように設計する
・修正した位置エンコーディングは、モデルが色情報(光学情報)と位置情報の関連性を同時に学習できるようサポートし、これによりモデルは空間的およびスペクトル的文脈をより精密に捉えることができる
・各チャンネルグループに対して別々に作成されたエンコーディングは結合され、この統合プロセスが全体の解析精度を向上させる
③パッチ埋め込みと位置エンコーディング
・入力画像をパッチに分割して(パッチ埋め込み)、特定の割合(75%)のパッチトークンをマスキングする
・マルチスペクトルデータでは、異なるバンドチャネルごとに別のパッチ埋め込み層を使用する
④エンコーディングとデコーディング
・マスキングされていないパッチトークンに位置エンコーディングを追加し、トランスフォーマーエンコーダに供給して特徴をエンコードする
⑤マルチスケール再構成
・エンコードされた特徴をデコーダで処理して、平均二乗誤差(MSE)で評価を行いながら、最初の出力スケール(通常は入力スケールと同じ)で画像を再構成する
・その上で、残差ブロック(2つの畳み込み層を含む)を通してアップサンプリングを行い、画像の局所的な詳細が強調されたより高い品質の画像を取得する
⑥利用データセット
・fMoW-RGB (Functional Map of the World):高解像度の衛星画像を含む大規模な公開データセットであり、62のカテゴリーに分けられ、分類タスク用に約363,000枚のバリデーション画像と53,000枚のテスト画像が含んでいる
・fMoW-Sentinel:fMoW-RGBを基に追加でSentinel-2データを含んでいて、fMoW-RGBと同様に62のカテゴリーがあるが、より多くの画像が含まれており、約712,874枚の訓練画像、84,939枚のバリデーション画像、84,966枚のテスト画像がある
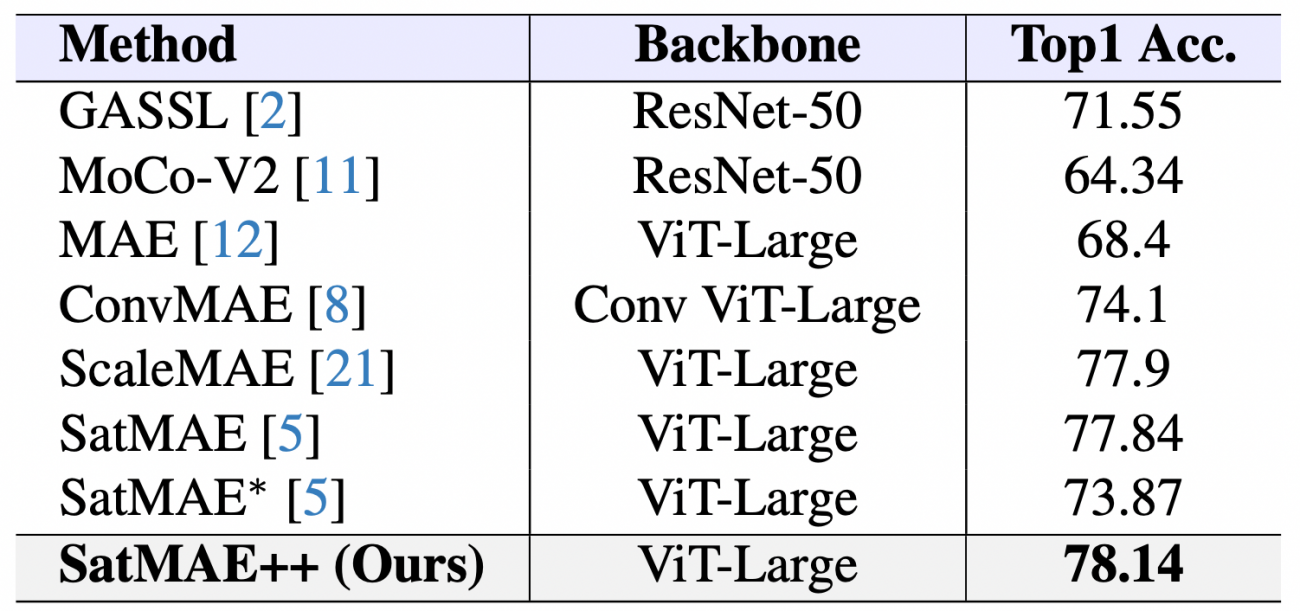
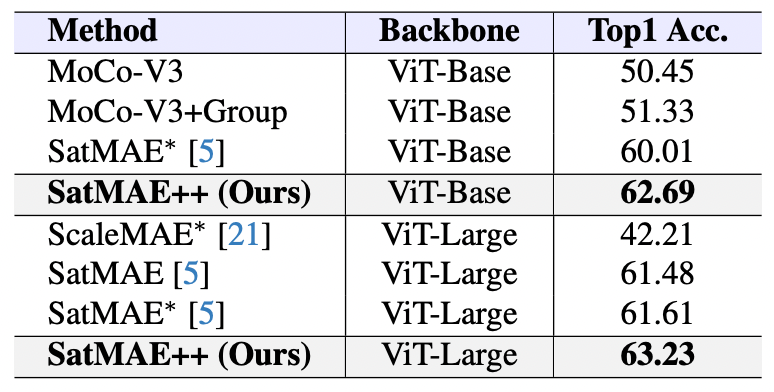
議論の内容・結果は?
・ SatMAE++をfMoW-RGBおよびfMoW-Sentinelといった大規模なリモートセンシングデータセットで事前学習し、Top1精度(正確に最も可能性の高いカテゴリを予測する能力)を評価したところ、今回の提案手法であるSatMAE++が一番優れていた
#VisionTransformer #ViT #SatMAE++ #アップサンプリング #マルチスケール
Segment Anything Model for Road Network Graph Extraction
どういう論文?
・本研究は、Segment Anything Model (SAM)を基にして、セマンティックセグメンテーションとトランスフォーマーベースのグラフニューラルネットワークを活用しながら、道路の曲がり角や長さ、交差点の位置などを正確に識別してマッピングするSAM-Roadモデル手法を提案する
技術や方法のポイントはどこ?
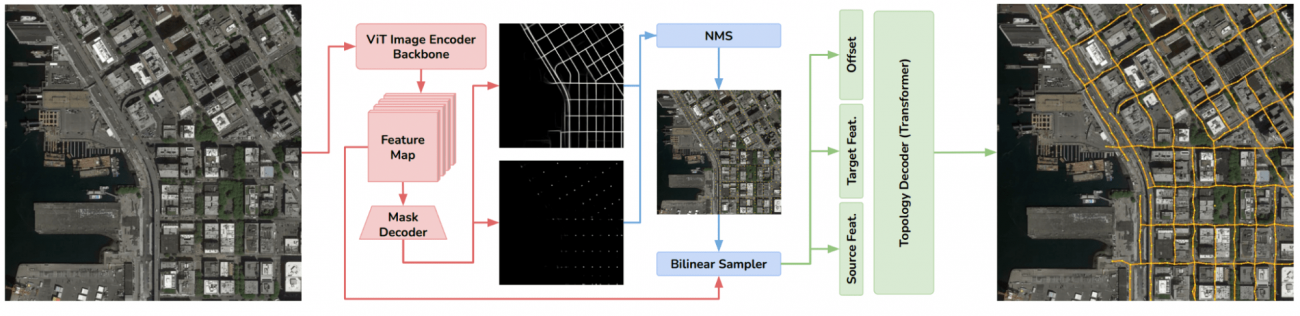
①画像エンコーダ
・事前訓練されたSegment Anything Model (SAM)の画像エンコーダを使用する
・RGB衛星画像を入力として受け取って特徴マップを生成する
・本特徴マップは16×16のパッチに分割され、各パッチが独自の特徴ベクトルにエンコードされる
②ジオメトリーデコーダー
・トランスポーズ畳み込み層(transposed convolution layers)を使用して、入力画像の特徴マップから道路と交差点の存在を示す確率を計算する
・トランスポーズ畳み込み層とは、画像のダウンサンプリングで失われた空間情報を復元するために使われるニューラルネットワークの層である
③非最大抑制(Non-Maximum Suppression, NMS)
・確率マップから、重要な特徴点(ここでは道路や交差点)を抽出するためにNMSを適用する
・NMSとは、候補ピクセルの中で、局所的な最大値を持つもの(つまりその周囲のピクセルよりも確率が高いもの)を選択しつつ、 抽出した頂点(ピクセル)間において、最小間隔を保って頂点が密集しすぎないように確率マップを生成する手法である
・NMSにより、道路と交差点の2つの存在確率マップが生成される
④トポロジーデコーダー
・特定のソース頂点からある半径以内に最も近い頂点を識別する(ターゲット頂点と呼ばれる)
・それぞれのソース頂点とターゲット頂点のペアについて、二頂点間にエッジ(つまり道路の接続)が存在するかどうかの確率を予測する
・予測の際には、頂点の特徴だけでなく、それらの空間的な位置関係(距離や相対位置)も利用する
⑤スライディングウィンドウ推論
・ウィンドウごとに局所的な予測を行い、その後、全体のグラフとして集約する
議論の内容・結果は?
・SAM-Road は、Cityscaleデータセットでは 90.47%、SpaceNetデータセット では 93.03% という最高の精度を達成した

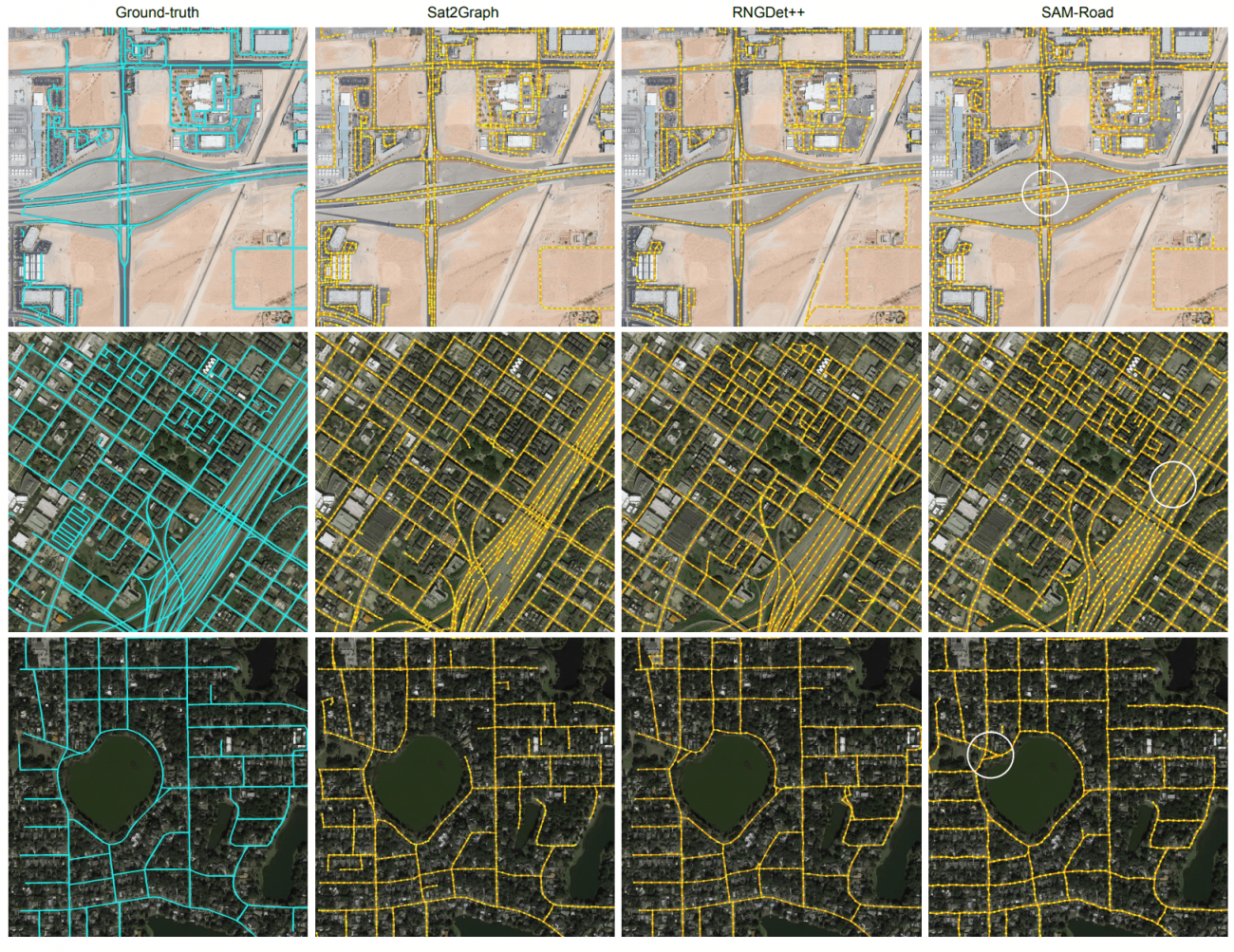
・また、オフセット(頂点間の相対位置情報)を使用すると、トポロジーの精度が向上した
・オフセットを含めない場合、モデルが道路の接続を正しく認識するのが難しくなり、性能が若干低下する
#SegmentAnythingModel #SAM #SAM-Road
YOLOv8-BYTE: Ship tracking algorithm using short-time sequence SAR images for disaster response leveraging GeoAI
どういう論文?
・本論文では、データ拡張、Swin-Transformer、カルマンフィルタを組み合わせた、複数の船舶の効果的な追跡を実現する手法を提案する
技術や方法のポイントはどこ?
・YOLOv8とLW-swin transformerというディープラーニングアルゴリズムを統合した検出モデルを利用する
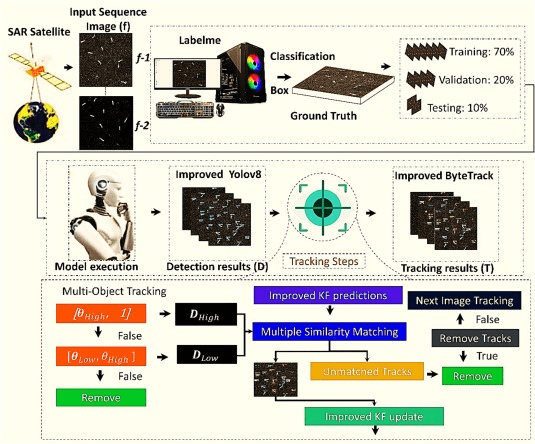
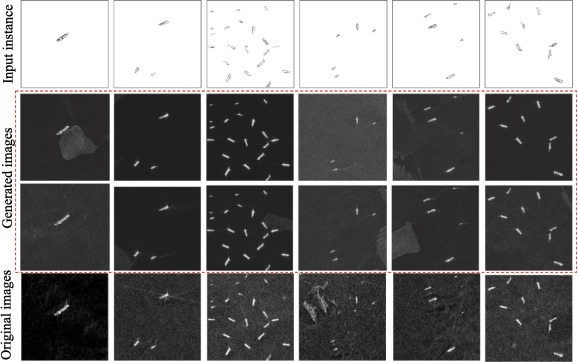
・モデルの性能と堅牢性を高めるために、Ship-Goという、任意のオブジェクト(船など)をSAR画像に統合してデータを拡張する手法を用いて、サンプルの量と多様性を増加させた
・また、モデルの一般化能力を高め、長距離依存性を扱うことで全体的な性能を向上させることができるSwin transformerネットワークを追加した
・Swin Transformerは、基本的なトランスフォーマーのフラットなアテンションメカニズムと対照的に、階層的なアテンションシステムを使用しており、入力画像をブロックに分割し、各ブロックを独立した小さな画像として処理する
・階層的な設計により、データ入力サイズの増加に伴う計算複雑性が軽減され、各レベルで独立してアテンションを計算することで、異なるレベルでの依存関係をより効果的に捉えることができるようになる
・加えて、Swin Transformerの異なる階層間で情報を交換し、全体的なパフォーマンスを向上させるクロスティア接続というレイヤーも採用している
・最終的に、カルマンフィルタとByteTrack技術を用いて、動いている物体(この場合は船)の現在の位置と速度に基づいて、船がどこに向かっているかを予測する
議論の内容・結果は?
①アブレーション研究
・構成1: Swin Transformer、学習可能な残差、データ拡張なしのベースラインモデルの場合、リコール91.80%、精度92.45%、AP(平均精度)90.90%を達成した
・構成2: Swin Transformerを含むが、学習可能な残差とデータ拡張は含まない場合、リコールがわずかに増加し(92.21%)、APはわずかに減少し(90.14%)、精度は安定した
・構成3: Swin Transformerと学習可能な残差を含む場合、APが大幅に改善され(93.56%)、リコールと精度も向上したが、モデルのパラメータが増加した
・構成4: Swin Transformer、学習可能な残差、データ拡張を全て含む場合、最も印象的な結果を示し、リコール96.36%、精度97.60%、AP96.72%を達成した
・本アブレーション研究から、Swin Transformer、学習可能な残差、データ拡張の各コンポーネントが、YOLOv8-BYTEアルゴリズムの性能向上に大きく貢献していることが示された

・ベースのモデル(YOLOv8 + ByteTrack)と提案モデル(YOLOv8-BYTE)の比較で、提案モデルが全ての指標で改善が見られ、特にMOTA、HOTA、MOTPが大幅に向上した
・YOLOv8-BYTEモデルは、高次追跡精度(HOTA)が最も高く、他のモデルと比較して優れた追跡能力を示した
・IDスイッチの数が少なく、フレームレートはやや低いものの、追跡の精度と信頼性で他のモデルを上回っている
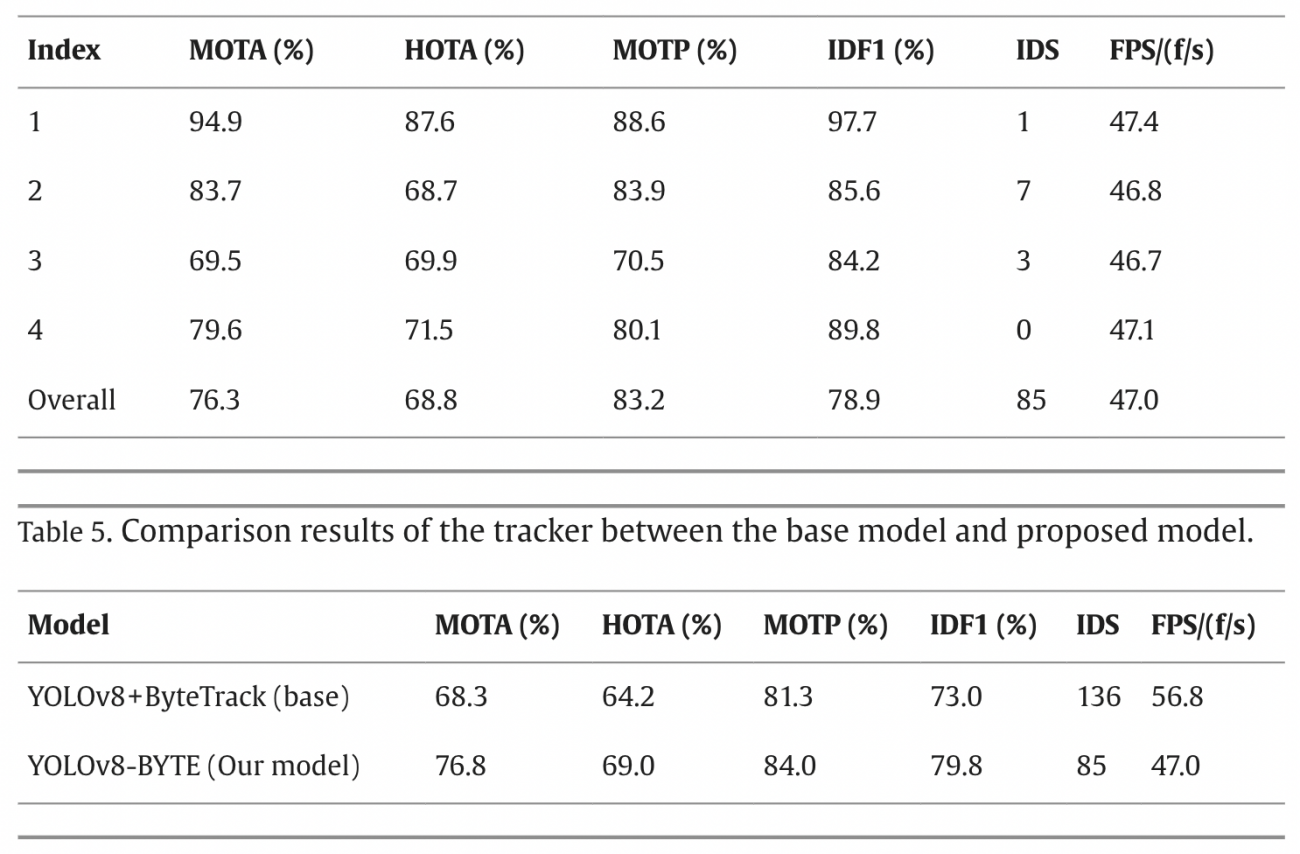

・MOTA (Multi-Object Tracking Accuracy):追跡システムがどれだけ正確にオブジェクトを追跡しているかを示す割合であり、値が高いほど、追跡システムの性能が良いことを意味する
・HOTA (Higher Order Tracking Accuracy):高次追跡精度とは、追跡の全体的な質を測定するための指標で、検出精度と追跡精度の両方を考慮し、オブジェクトをどれだけ正確に検出し、追跡を続けられるかを示す
・MOTP (Multi-Object Tracking Precision):追跡されたオブジェクトの位置の精度を測定し、値が低いほど、追跡の位置精度が高いことを意味する
・IDF1 (Identification F1 Score):識別F1スコアは、追跡中にオブジェクトのIDをどれだけ正確に保持できるかを測る指標であり、精度とリコールの平均を計算し、追跡の正確さと一貫性を示す
・IDS (ID Switches):IDスイッチの数で、追跡中にオブジェクトの識別がどれだけ変わるかを示し、低い値は、追跡システムが一貫して同じオブジェクトを追跡し続けていることを意味する
・FPS (Frames Per Second):1秒間に処理されるフレーム数で、システムの処理速度を示し、高いFPSは、追跡システムがより高速に動作していることを意味し、リアルタイムでの追跡に適している
・ベースライン モデルとカルマンフィルター手法による改良モデル間の追跡結果の比較の通りであり、 赤いボックスはベースライン モデルの追跡結果を表し、青いボックスは船舶追跡用のByteTrack 技術の改良された追跡検出結果を示した

#SwinTransformer #カルマンフィルタ #船舶追跡 #YOLOv8 #ShipGo #SAR #ByteTrack
Mitigating underestimation of fire emissions from the Advanced Himawari Imager: A machine learning and multi-satellite ensemble approach
どういう論文?
・日本のひまわり衛星からのデータは火災をうまく検出できなかったり、計算されたエネルギー量が実際よりも少なく出てしまうことがあった(火災放射能力[FRP]の過小評価)
・本論文は、機械学習を用いたMIR(中赤外)輝度法に基づくFRP推定モデルと、優れた火災検出モデルを組み合わせることで、FRPの過小評価問題を解決する手法を提案する
技術や方法のポイントはどこ?

①FRPモデリング
・データ:過去の火災データ(Himawari-8 AHIデータ)やMIR放射率、センサー係数やMODISから得られるNDVIデータを使用する
・基準FRPの算出:中赤外放射法を用いて、火災から放出される熱エネルギー(FRP)を計算し、各火災ごとにどれだけのエネルギーが放出されたかの基準値を得る
・機械学習によるFRP推定:基準FRP値、衛星データからの追加の特性(輝度温度差など)から、一般的な機械学習手法(ランダムフォレスト、サポートベクター回帰、ニューラルネットワーク)を適用して、特性とFRPとの関係をモデリングすることで、各火災イベントに対する推定FRP値(火災のエネルギー放出量を表し、排出量計算に使用)を算出する
②FRPのアンサンブル
・FRP推定値をさらに精密化するために、異なる衛星データソースからの情報を統合し、補正する
・具体的には、火災のエネルギー放出量が日中の時間帯によって変化するため、日周変動を考慮した調整や、MODISが検出したFRP値と地球静止衛星が検出したFRP値の違いを計算し、その差(オフセット)を使って元データ(Himawari-8 AHIデータ)に修正をかける
③排出量の推定
・推定されたFRPを使用して、火災による排出量を計算する
・本プロセスでは、火災放射エネルギー、変換係数、排出係数を組み合わせた計算を行う
・得られた排出量は、火災の環境への影響を理解するための重要な指標となる
※変換係数(Conversion Factor, CF):FRPから質量単位(例えば、kg)に排出量を変換するための係数
※排出係数(Emission Factor, EF):特定の燃料または火災タイプが燃焼する際にどれだけの汚染物質が排出されるかを示す
④比較評価
・火災による排出量をTROPOMIなどの観測データと比較し、FRPベースの推定との一致を評価する
議論の内容・結果は?
・FRPの過小評価問題を解決する上で、本手法では、空間分解能が2kmであるHimawari-8 AHIのデータセットを主に利用しているため、適用できるケースが最大2km規模の火災に限定される可能性がある
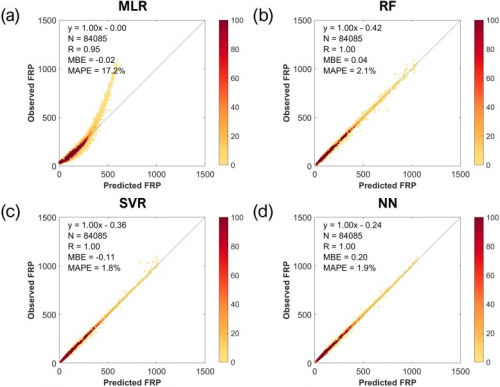
・ FRPのモデリングにおいて機械学習が多重線形回帰よりもはるかに優れたパフォーマンスを示した
・高FRPにおいては、ニューラルネットワークは強い一貫性を示したが、ランダムフォレストとサポートベクター回帰では多くの不一致が生じた
・FRP モデリングではニューラルネットワークをMIR 放射輝度法の代わりに使用できる可能性が高い
Mitigating underestimation of fire emissions from the Advanced Himawari Imager : A machine learning and multi-satellite ensemble approach
・火災による窒素酸化物(NO2)の排出を評価するために、TROPOMIからのNO2 VCDデータが使用して算出した結果と、地球静止衛星に基づく日周サイクル調整(GDC)、MODISに基づく線形補間オフセット調整(MLO)、およびアンサンブル法(Ensemble)のそれぞれによる算出結果を比較したところ、GDC法は他の方法よりも排出量を低く見積もり、MLO法とアンサンブル法は比較的近い結果を示した

#FRP Himawari-8 #MIR #MODIS #NDVI #中赤外輝度法 #火災 #TROPOMI
Exploring Robust Features for Few-Shot Object Detection in Satellite Imagery
どういう論文?
・衛星画像における、YOLO、Faster-RCNN、Mask-RCNNなどの教師ありオブジェクト検出手法は高性能だが大量のアノテーションデータを必要とする
・本論文は、Few-Shotを用いて衛星画像内のオブジェクトを検出する手法に焦点を当てた研究である
技術や方法のポイントはどこ?

①領域提案ネットワーク(RPN:Region Proposal Network)
・オブジェクトが存在する可能性のある画像内の領域を特定するためのネットワークである
・アンカーボックス(事前に定義された形状とサイズのボックス)を使用して、オブジェクトの可能性のある位置とサイズを予測する
②Faster-RCNN
・画像内のオブジェクトを検出し、それらを分類するための高速かつ効果的な二段階オブジェクト検出アルゴリズムである
・領域提案ネットワークがオブジェクトの候補領域(領域提案)を生成したのち、Faster-RCNNを用いて、オブジェクトの正確な位置を精密に特定してそれぞれの領域を特定のクラスに分類する
・バックボーンとしては、視覚モデルDINOv2と視覚言語モデルCLIPを使用する
③初期のプロトタイプ作成
・同じカテゴリーに属する物体(例えば「車」)の画像サンプルをいくつか集め、各画像から、形や色、サイズなどの特徴を抽出し、集めた全画像の特徴から平均値を計算することで、カテゴリー全体を代表する特徴(プロトタイプ)を作成する
・背景も同様に、物体がない場所の特徴を代表するプロトタイプを作成する
※本プロセスは①②とは独立したプロセスである
④オブジェクト分類(識別)
・①②にて抽出した特徴と③で作成したプロトタイプ間のコサイン類似度を計算し、類似度マップを生成する
・類似度が最も高いプロトタイプに基づいてクラスを割り当てる
⑤プロトタイプのファインチューニング
・平均化された特徴だけを使用した初期のプロトタイプは、特定のケースでの分類精度が低下している可能性がある
・そこで、既存のプロトタイプを使用し、実際の画像データを元にして、各クラスをより正確に表現するための学習を行う
・分類器は、アノテートされたバウンディングボックスのグラウンドトゥルースを用いて、クロスエントロピー損失関数を最小化することにより、プロトタイプセットを最適化する
⑥学習データ
・DOTAデータセットを使用する
・DOTAデータセットは、2,806枚の大きな画像に403,318のアノテーション、飛行機、船、小型車両、貯蔵タンクなど16の一般的なクラスが含まれいる
⑦テストデータ
・SIMDデータセットは、さまざまな航空機のタイプを含む特定のカテゴリーに焦点を当てており、例えば、プロペラ機、戦闘機、エアライナー、一般的な乗り物(車、バン、トラックなど)が含まれている
・DIORデータセットは、より多様なカテゴリーを含むデータセットで、空港、列車駅、煙突、料金所など、都市や産業のインフラ関連のオブジェクトが含まれいる
⑧評価
・新規クラスに対するモデルの少数ショット検出性能は、mAP50(平均精度の50%交差点)スコアを使用する
議論の内容・結果は?
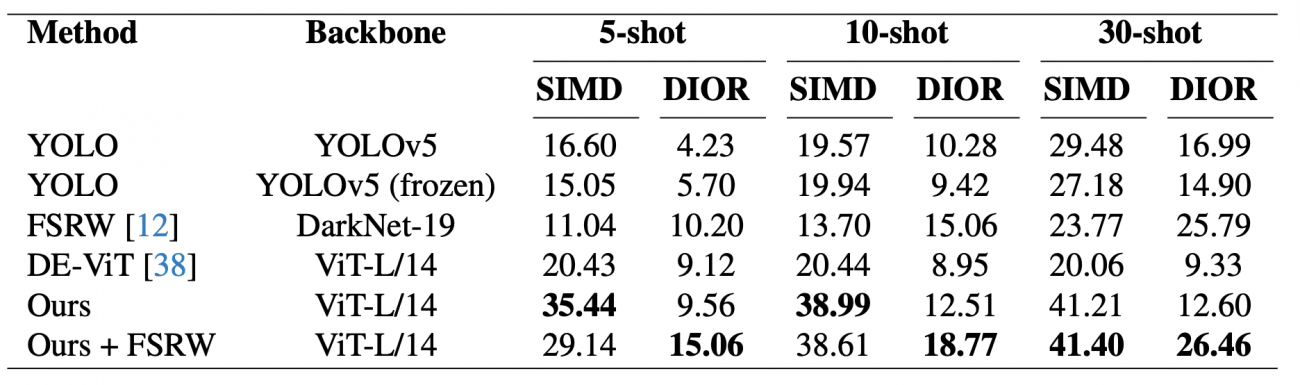
①SIMDデータセットでの高パフォーマンス
・提案手法は、今回トライした5-shot、10-shot、30-shotのすべての学習)において、SIMDデータセットの方が顕著に高いパフォーマンスを示した
・モデルが少数の例からでも効果的に学習し、新規クラスのオブジェクトを正確に検出できることを意味する
②DIORデータセットでの障害
・DIORデータセットには、DOTAデータセットに含まれていない新規クラスが含まれており、これが提案手法のパフォーマンスに影響を与えた可能性が高く評価が悪い
・しかし、FSRWを組み合わせることで、パフォーマンスが向上した
③DINOv2プロトタイプの効果
・視覚モデルDINOv2を使用したプロトタイプは、SIMDデータセットで高いパフォーマンスを示したが、DIORデータセットではパフォーマンスが低下した
・これは、DIORデータセットに含まれるオブジェクトがDOTAデータセットのオブジェクトと大きく異なるため、適切な領域提案を得ることが難しいことが原因と考えられる

Credit : Xavier Bou, Gabriele Facciolo, Rafael Grompone von Gioi, Jean-Michel Morel, Thibaud Ehret, Universite Paris-Saclay, CNRS, ENS Paris-Saclay, Centre Borelli, France, City University of Hong Kong, Department of Mathematics, Kowloon, Hong Kong. (2024).Exploring Robust Features for Few-Shot Object Detection in Satellite Imagery Retrieved from https://arxiv.org/pdf/2403.05381.pdf
#YOLO #Faster- RCNN #Few-Shot #領域提案ネットワーク #DOTA #SIMD #DIOR #mAP50
以上、2024年3月に公開された論文をピックアップして紹介しました。
皆様の業務や趣味を考えた時に、ピンとくる衛星データ利活用に関する話題はありましたか?
来月以降も「#MonthlySatDataNews」を続けていきますので、お楽しみに!
