【2024年4月】衛星データ利活用に関する論文とニュースをピックアップ!
2024年4月に公開された衛星データの利活用に関する論文の中でも宙畑編集部が気になったものをピックアップしました。
宙畑の新連載「#MonthlySatDataNews」では、前月に公開された衛星データの利活用に関する論文やニュースをピックアップして紹介します。
実は、本記事を制作するために、これは!と思った論文やニュースをTwitter上で「#MonthlySatDataNews」をつけて備忘録として宙畑編集部メンバーが投稿していました。宙畑読者のみなさまも是非ご参加いただけますと幸いです。
2024年4月の「#MonthlySatDataNews」を投稿いただいたのは3人でした!
RADARSAT-2 での4偏波解析を活用して時系列統計解析
植生と体積散乱の相関検証だけど、しっかり現れてる
逆に、Cバンドで Sentinel-2 の強だけと比べてどれくらい強力なのか気になる#MonthlySatDataNewshttps://t.co/guU17U1pX5 pic.twitter.com/hKHNrwbwSJ— emmyeil (@emmyeil) April 17, 2024
ラスターデータの操作、分析用のPythonライブラリとGUIである「Raster Forge」を開発。
GISや既存のPythonライブラリは専門知識がいたり、使うためにある程度調査が必要であり、初心者にとって敷居が高いという課題の解決を目指す。▼ 論文https://t.co/dEqtUvHDPq#MonthlySatDataNews
(1/2)— ぴっかりん (@ra0kley) April 14, 2024
Garlic Crops’ Mapping and Change Analysis in the Erhai Lake Basin Based on Google Earth Engine https://t.co/47qxLGFJPA #mdpiagronomy @Agronomy_Mdpiより #MonthlySatDataNews
知らんかった,汎用的ではないだろうが,にんにくの識別もできるのね— たなこう (@octobersky_031) April 9, 2024
それではさっそく2024年4月の論文を紹介します。
Riverine litter monitoring from multispectral fine pixel satellite images
【どういう論文?】
・本論文は、衛星画像から河川の水面に浮かぶゴミを検出・追跡するためのアルゴリズムを提案する
【技術や方法のポイントはどこ?】
①研究対象地域
・セルビア、モンテネグロ、ボスニアヘルツェゴビナからの水域を排出するドリナ川

Shungudzemwoyo P. Garaba ,Young-Je Park(2024).Riverine litter monitoring from multispectral fine pixel satellite images
②利用データ
・GeoEye:初期分析のために使用し、調査範囲/精度を向上させるためにPlanetScopeおよびSkysatデータセット
・PlanetScope: 約200機のDove CubeSats衛星が日々地球全体を観測し、3~5mの解像度で4~8つの波長バンドのデータを提供する
(低解像度ながら広い地域のデータを毎日収集するため、広範囲での継続的な観測に適している)
・Skysat:0.5mの細かな解像度を持ち、4つの波長バンドで画像を提供することに加え、ユーザーが特定の地域をリクエストするオンデマンドミッションであり、ニーズに応じたタイミングでの画像取得が可能である
(リクエストに応じて非常に高解像度の画像を取得できるため、特定の地域の詳細な観測に利用される)
③対象領域選定
・浮遊ゴミの検出においては、裸地や植生などが浮遊ゴミと類似した反射特性を持つため、誤検出を防ぐ必要がある
・そこで、ポリゴンを事前設定する際にターゲットを背景水と(予想される)浮遊ゴミに限定する、裸地や植生の影響を最小限に抑えることで、浮遊ゴミと川のピクセルのみを検出できるようにした
④アルゴリズム
・浮遊ゴミのある部分と水だけの部分は、それぞれ異なるスペクトル特性を持つ
・浮遊ゴミは、水よりも特定の波長、特に近赤外光(NIR)での反射率が高く、それを利用して識別することが可能である
・対象領域近くの川部分の反射率を平均して浮遊ゴミが存在しない水面の基準値として設定し、浮遊ゴミのある部分と比較する
⑤データ処理
・衛星が取得する画像データ(放射量)を地表からの反射光の割合を表す「反射率」に変換する
(変換率は衛星のセンサー特性や校正データに基づいて事前に計算され、各衛星画像のメタデータに添付されれている)
・次に、大気による光の散乱を補正するためにRayleigh散乱補正を行い、反射光から大気の影響を除去し、より正確な反射率を取得する
・明るい部分をマスキングすることで、雲、陸地などの明るいピクセルを除去しつつ、対象となる水面のゴミをより正確に分析できるようにする
・浮遊ゴミを検出するためにピクセルのパターンをチェックし、周囲のピクセルが水であれば、中心のピクセルがゴミを含む可能性が高いと分類する
・純粋な水(川)だけのピクセルを残し、基準反射率として平均化し、他のピクセルのゴミ検出基準を作成する
・水の基準反射率と各ピクセルの反射率の差分から、ゴミが浮いているかどうかを判断する
【議論の内容・結果は?】
◾️バンド差異と部分的なごみ分布エリア分析
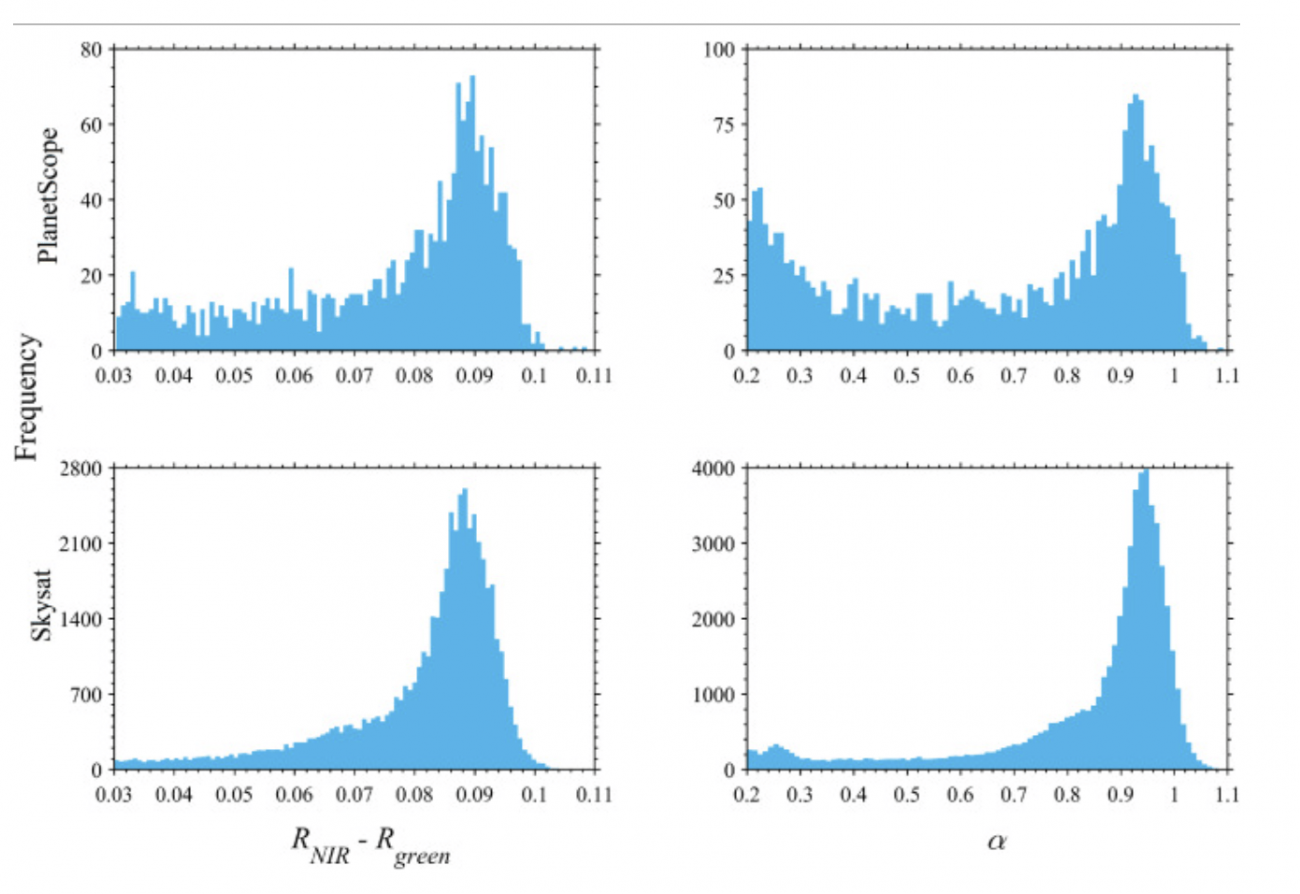
①指標
・Δb:2つの異なる光のバンドの差異(近赤外(NIR)と緑(Green))で測定された空間的な異常値
(このバンド差異を使うことで、画像内の特定のピクセルや領域の光学的特性の違いを強調することができる)
※近赤外(NIR)バンド:845 – 885 nm(PlanetScope)、740 – 900nm(Skysat)
※緑(Green)バンド: 500 – 590nm(PlanetScope)、515 – 595 nm(Skysat)
②結果
・FΔ:Δbのヒストグラムで95パーセンタイルに対応する値を基準とした指標
(データの中で上位5%に該当する値で、異常値やピークを見つけるために使われる)
・FΔが0.5以上の場合、両衛星でのごみの推定面積がほぼ一致した
Shungudzemwoyo P. Garaba ,Young-Je Park(2024).Riverine litter monitoring from multispectral fine pixel satellite images
◾️ごみ面積の時系列データ分析
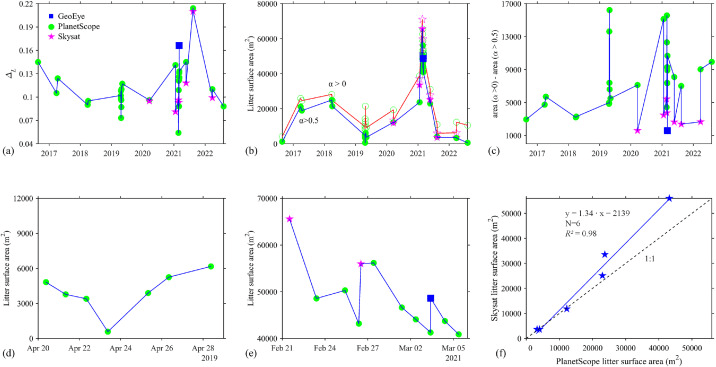
①図(a)
・バンド差異(Δb)の時系列トレンドを示している
②図(b)
しきい値α > 0およびα > 0.5を用いて、ゴミ面積が異なる時間帯でどのように変化しているかを示している
③図(c)
・しきい値(α > 0およびα > 0.5)ごとのごみ面積の差異を示している
・特にPlanetScopeデータでの5000平方メートルを超える大きな差異が顕著であることが分かる
④図(d-e)
・α > 0.5のしきい値でのごみ面積のほぼ日次の時系列データを示している
・2019年と2021年のデータを利用して、PlanetScope衛星がごみの監視に効果的に活用できることを示している
⑤図(f)
・SkysatとPlanetScopeの同じ日付で得られた画像に基づくごみ面積の相関プロットである
・非常に強い相関関係(線形相関)が得られており、衛星の観測タイミングの違いがごみ面積の推定に与える影響は小さいことが示唆されている
(異なる衛星が同じ地域を異なる時間に撮影しても、得られるデータの一貫性が保たれている)
#GeoEye #PlanetScope #Skysat #河川 #ゴミ #近赤外光 #NIR
Generating Synthetic Satellite Imagery With Deep-Learning Text-to-Image Models -- Technical Challenges and Implications for Monitoring and Verification
【どういう論文?】
・本論文は、最新のディープラーニングモデルであるStable DiffusionやDALL·E 2を活用した衛星画像生成に関する技術要件を検討する
【技術や方法のポイントはどこ?】
◾️データセット
①核施設データセット
・ドイツの原子力発電所の画像を、利用可能なトレーニングデータを増やすべく、ズームレベルや回転を変化させて複数のバリエーションを生成する(画像左)
・Google Earth Engineとウェブスクレイピングツールで世界中の核施設画像を収集し、品質の低い画像を排除して、185か所の核施設から202の画像を取得する(画像右)

②UC Merced 土地利用データセット
・2010年に構築されたベンチマークデータセットで、アメリカ合衆国の都市部の航空写真となる
・各画像は256×256ピクセルで、解像度は約30cmとなる
・21のクラスにわたる2100枚の画像(各クラス100枚)が含まれる
・土地利用分類のベンチマークとして、さまざまなクラスの合成画像生成モデルの評価に使用する
◾️手法
①Generative Adversarial Networks (GANs)
・GANは、ジェネレータとディスクリミネータという2つのニューラルネットワークが互いに競い合いながら学習を行う枠組みである
・ジェネレータが生成した画像を、ディスクリミネータが本物か偽物かを判定する役割を担う
・上記の対立的な学習により、ジェネレータは徐々にリアルな画像を生成できるようになる
・GANはトレーニングが難しく、学習の安定性が課題となる場合がある
②Diffusion Models (DMs)
・DMsは、画像生成のための2段階のプロセスを持ちつ
・まず、元の画像にランダムノイズを徐々に加えて、元の画像を破壊する「順方向」のプロセス(フォワードプロセス)を経て、次にそのノイズを除去し、元の画像を再構築する「逆方向」のプロセス(リバースプロセス)を実行する
・GANと比べて、DMsはトレーニングが安定しており、画像の多様性や品質が向上するが、計算コストが高い傾向にある
③Stable Diffusion
・Stable DiffusionはLatent Diffusion Models (LDMs)という、オートエンコーダを使ったDMsの一種である
・画像を低次元の潜在空間に圧縮し、その空間でノイズ除去を行うため、計算効率が高く、画像の品質も維持される
・DMsと比較して、画像の圧縮と生成を分離して行うため、より効率的に高品質な画像を生成できる
④DreamBooth (DB)
・DBは、特定の対象に特化した生成モデルを作るためのファインチューニング技術である
・Stable DiffusionモデルのU-Netコンポーネントを対象に、特定の場所やオブジェクトに関連する画像生成を最適化する
・データに基づいた具体的な条件(例えば、特定の施設やシーン)での画像生成が可能であり、特定用途向けにカスタマイズできる
⑤Textual Inversion (TI)
・TIは、事前訓練されたテキストエンコーダーの埋め込み空間を使って、特定のプロンプトに基づいた画像生成を行う
・新たな単語や概念をモデルに導入するために使われる
・テキストプロンプトの条件付けを強化できるため、特定のキーワードに基づく生成が容易になる
⑥Text-to-Image (Text2Img) Fine-Tuning
・Text2ImgはStable DiffusionモデルのU-Netコンポーネントをファインチューニングし、より適切な画像生成を目指す手法である
・埋め込みをベースに、特定のプロンプトに対して高精度な画像生成が可能である
・テキストプロンプトからの画像生成に特化しているため、キーワードやフレーズに基づいた複雑な画像生成をできる
【議論の内容・結果は?】
◾️評価指標
①Inception Score (IS)
・画像生成モデルの性能評価に用いられる指標で、主に生成された画像の品質と多様性を評価する
・本スコアは以下の2つの要素に基づいている
(1)画像の明確さ
– 各生成画像がどれだけ特定のクラスに属するか明確であるか
– 高品質な画像に関して、モデルがその画像を1つのクラスに強く分類する傾向がある
(2)画像の多様性
– 生成した画像セットが多様なカテゴリーにまたがっているかどうか
– モデルが多種多様な画像を生成できる能力を示す
②Fréchet Inception Distance (FID)
・生成画像と実画像の間の統計的な距離を測定して画像の品質を評価する
・距離が小さいほど、生成画像の品質が高いと考えられる
◾️生成結果
①原子力発電所データセット
・DreamBoothを用いて生成した原子力発電所のサンプル画像
・DreamBoothは画像の忠実度を維持し、特徴的な要素を再現するのが特に優れている
・また、入力画像の数が少ないほど、主題を対象としたファインチューニング方法で効果的に機能することがわかった
・入力画像が多すぎると細かなディテールを単一の識別子やトークンに結び付けるのが難しくなるためであると考えられる

②核施設データセット
・各手法で生成されたサンプルを観察すると、Stable Diffusionモデルをファインチューニングすることで、リモートセンシング領域に適した画像を生成できることがわかった
・また、Text2Imgモデルを使うと、望ましい視点である上(上空)からの視点が保持されやすかった

Shungudzemwoyo P. Garaba ,Young-Je Park(2024).Generating Synthetic Satellite Imagery With Deep-Learning Text-to-Image Models -- Technical Challenges and Implications for Monitoring and Verification Retrieved from https://arxiv.org/abs/2404.07754
◾️定量結果
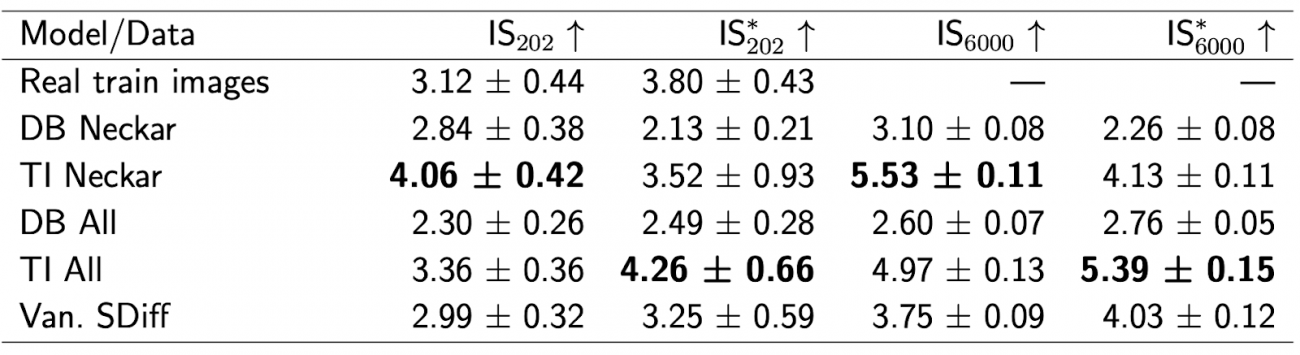
①原子力発電所データセット
・モデル毎にInception Score (IS) およびModified Inception Score(IS*) に基づく評価を行なった
・Textual Inversion (TI) Neckarというモデルが、ISとIS*の両方で最も高いスコアを記録した
・他のモデル (DreamBooth (DB) と Vanilla Stable Diffusion (SDiff)) も比較したが、ISとIS*において一定のスコアを示したもののTIには及ばなかった
②UC Merced Land-use Dataset
・複数のメトリクス(IS、IS*、Frechet Inception Distance (FID)、Frechet Clip Distance (FCD)など)を使用して評価を行なった
・Text2Img が他のモデルよりも優れたパフォーマンスを示し、特にFIDとFCDの低い値が高品質な画像生成能力を示した

◾️ユーザースタディ
・各モデルによって生成した合成画像に対して実際のユーザーが評価を行なった
・Text2Imgが57%の合成画像を「実物」と誤認され、最も高い成功率を達成した
・DB、TIの次に高い認識率を示しましたが、それぞれの成功率は55%、33%と低下した

#GANs #DiffusionModels #StableDiffusion #DreamBooth #TextualInversion #Text-to-Image #InceptionScore #FID
Fusion of satellite and street view data for urban traffic accident hotspot identification
【どういう論文?】
・本論文は、衛星データとストリートビューの情報を組み合わせることで、交通事故ホットスポット特定精度を向上する手法を提案する
【技術や方法のポイントはどこ?】
◾️データセット
①分類方法
・交通事故ホットスポット(APs)と非ホットスポット(Non-APs)の2つのカテゴリーを識別する
・2021年の交通事故データを収集して事故の場所をマップにプロットする
・クラスタリング手法としては、DBSCAN(密度ベースクラスタリング)アルゴリズムを使用する
・ハイパーパラメータはepsilon(各データポイントを中心とした半径65mの円内に含まれる事故数)とminPoints(50件以上の事故)を利用する
・DBSCANでepsilonを65mに設定し、65m以内に少なくとも50件以上の事故がある場合には、その場所を「事故ホットスポット(AP)」としてラベル付けする
②衛星データ収集
・2021年のGoogle Earthの衛星データ(約2m/ピクセルの空間解像度)を使用する
・事故データポイントをGoogle Earthの地図上にプロットする
・各事故ポイントにバッファゾーン(半径65m)を作成し、バッファゾーンを統合する
・周辺のシーン情報も含めるためにバッファゾーンの半径とepsilonを一致させる
・APsを生成して該当する衛星画像を取得する
③ストリートビュー画像収集
・2021年にBaiduから提供されたストリートパノラマ画像データを利用する
・事故ホットスポットとされたエリアの道路で、等間隔に4枚のストリートビュー画像を撮影して該当エリアの視覚的な状況を捉える
・ストリートビューとそのエリアの衛星画像を組み合わせて、マルチモーダルデータセットを作成する
・ホットスポットエリアの中から1本の道路をランダムに選び、その道路に沿って4枚のストリートビュー画像を撮影する
◾️TCFGC-Net アーキテクチャ適用
①概要
・Two-Branch Contextual Feature-Guided Converged Network (TCFGC-Net) という、交通事故ホットスポットを予測するために開発されたマルチモーダルなニューラルネットワークアーキテクチャを利用する
・3つの主要コンポーネント、Satellite Branch (Trans-CFCCNN)、Street View Branch (SFRAN)、および Feature Fusion Structure (MBFAF)
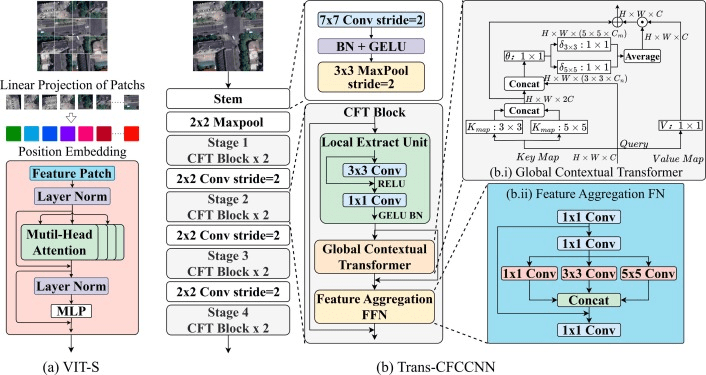
②Satellite Branch (Trans-CFCCNN)
・Trans-CFCCNN は、CNN(Convolutional Neural Network)とTransformerを組み合わせた新しいアーキテクチャであり、衛星画像に埋め込まれた局所的な特徴を捉える
・構成としては、Local Extraction Unit、Global Contextual Transformer、Feature Aggregation Feedforward Networkの3つで構成されている
・その中でも、Local Extraction Unitは、衛星画像で見られる道路や建物、駐車場などの微細な構造を正確に把握するために使用し、たとえば、道路の方向や幅を捉えることで、交通事故が起きやすい交差点や交差部を特定できる
・Global Contextual Transformerは、衛星画像全体で、都市部や田舎、工業地帯などの異なるマクロな環境を特定するのに役立ち、たとえば、道路の全体的なレイアウトや、緑地の配置から交通事故が起きやすいゾーンを特定する
・Feature Aggregation Feedforward Networkは、駐車場や交差点のマクロな特徴を取りまとめることで、事故の発生リスクが高い地点の予測を支援する
②Street View Branch (SFRAN)
・Sequential Feature Recurrent Attention Network (SFRAN) では、ストリートビュー画像から事故関連の特徴を時間的に捉える
・構成としては、EfficientNetとCA-ConvBiGRUの2つで構成されている
・EfficientNetは、ストリートビュー画像で見られる信号、横断歩道、歩行者などの局所的な特徴を捉え、連続した画像を解析し、事故が発生しやすい交差点などのリスク要因を捉えるのに役立つ
・CA-ConvBiGRU (Contextual Attention Convolutional Bidirectional GRU)は、信号の変化、歩行者の動き、車の停車・進行などの時間的な特徴を、過去と現在の画像を組み合わせて捉えることで、事故のリスクが高まる状況を認識する
・CA-Module (Contextual Attention Module)は、横断歩道の混雑状況や信号の点滅、歩行者の流れなど、ストリートビュー画像の複数の要素を組み合わせ、特定の瞬間のリスクを評価する
③Feature Fusion Structure (MBFAF)
・衛星画像のマクロな特徴とストリートビュー画像のミクロな特徴を融合し、APs の予測に必要な情報を確保する
・Multi-Branch Feature Adaptive Fusion (MBFAF) では、衛星データとストリートビューの特徴を組み合わせ、APs の予測に必要な統合情報を取得する
・MFSA-Module (Macro-feature Spatial Attention Module)は、衛星画像全体から、都市部や農村部、インフラの配置などを把握し、事故リスクが高い地域を特定する
・MFOA-Module (Micro-feature Object Attention Module)は、ストリートビュー画像から、重要な物体 (車や歩行者、信号など) に集中することで、交通事故のリスク要因を把握する
・HFMF-Module (Heterogeneous Feature Multilevel Fusion Module)は、衛星画像とストリートビュー画像のマクロ・ミクロ特徴を組み合わせ、異なる視点のリスク要因を統合する
【議論の内容・結果は?】
・都市における事故ホットスポット(APs)の識別のために、衛星画像とストリートビューデータの融合に基づくTwo-Branch Contextual Feature-Guided Converged Network(TCFGC-Net)を提案している
・本モデルは、衛星ブランチ(Trans-CFCCNN)、ストリートビューブランチ(SFRAN)、および融合構造(MBFAF)の3つのコンポーネントから構成されている
・各コンポーネント(モデル)は、類似手法より以下の通り高い成績を示した
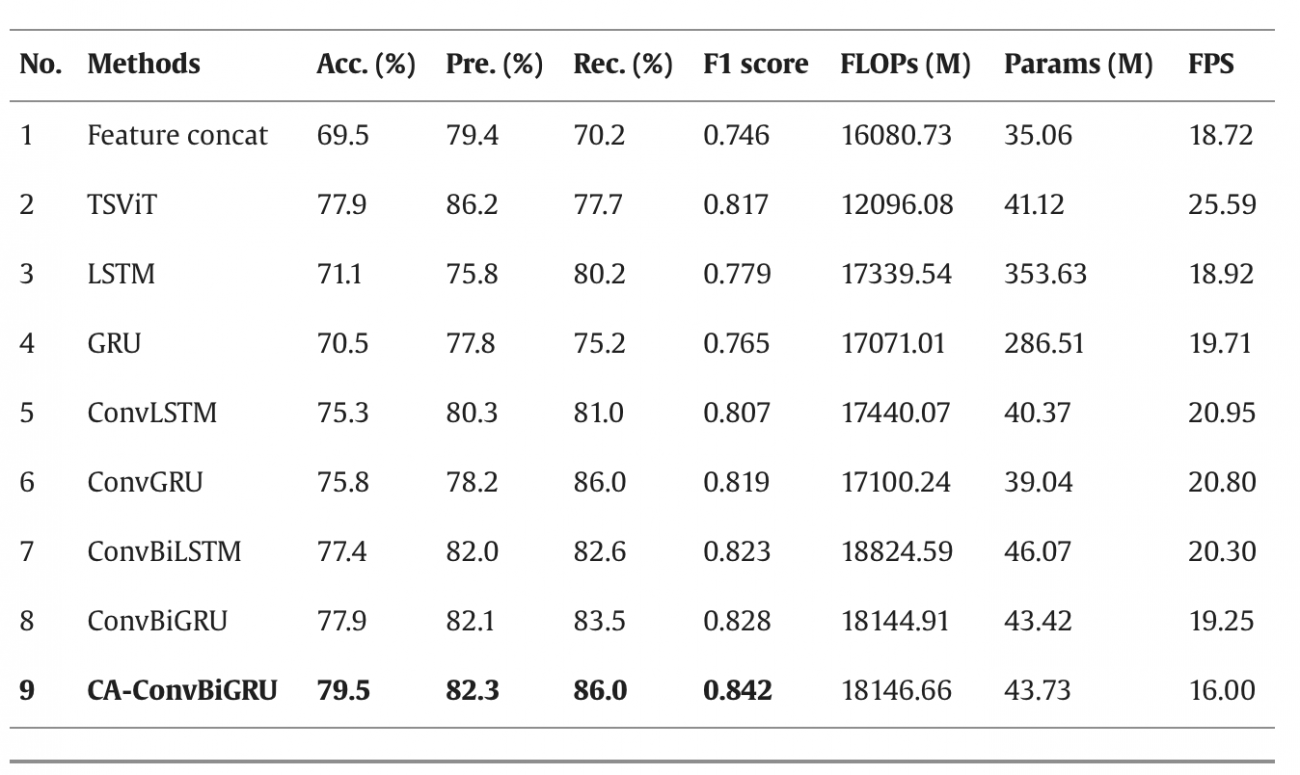
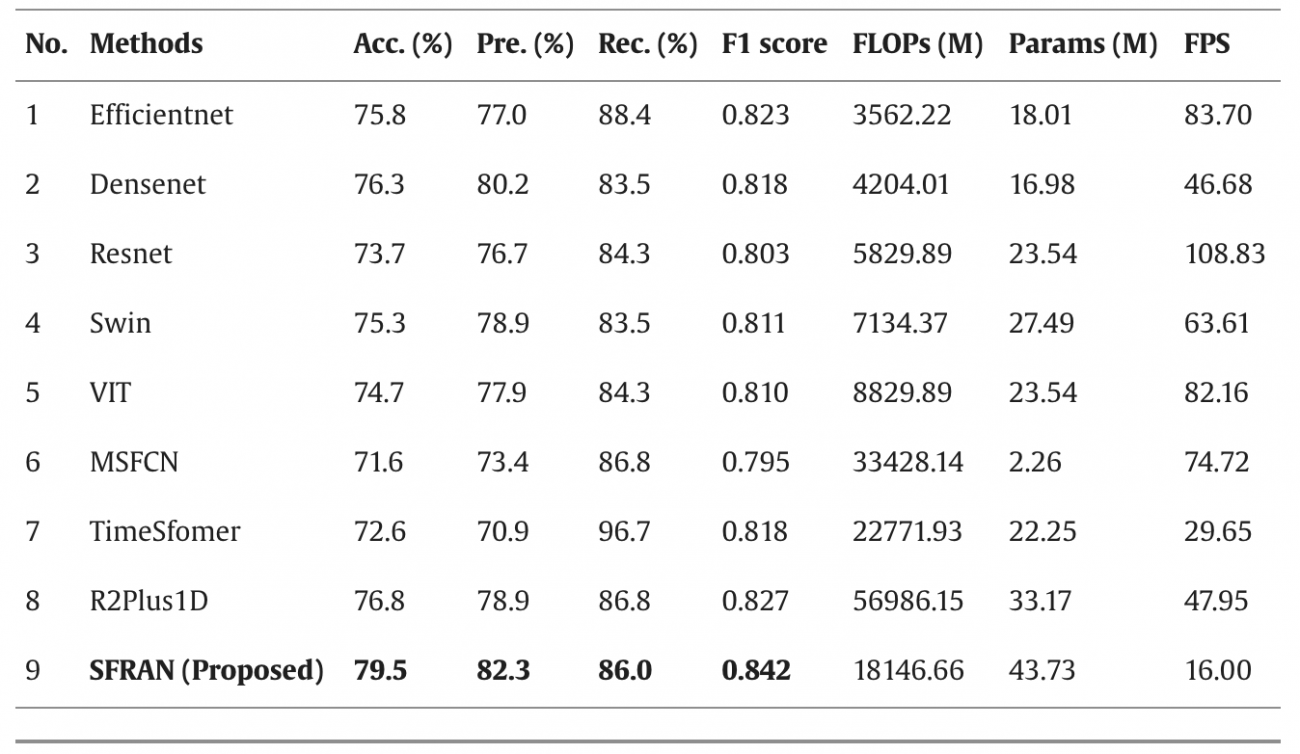
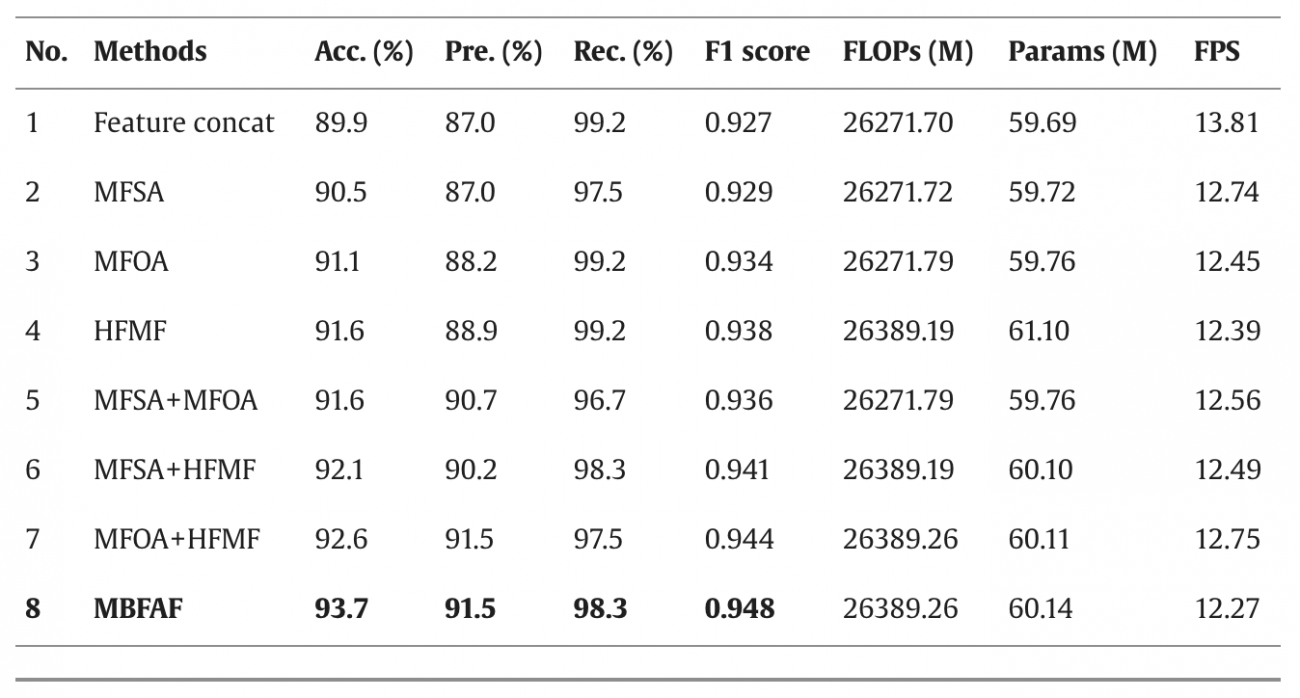
・3つのコンポーネントを組み合わせたTCFGC-Netに関して、Trans-CFCCNNとSFRANで異なる予測結果が出た検証セットの50サンプルにおいて、TCFGC-Netは50サンプル中43サンプルを正確に予測し、86%の精度を達成した
・上記結果によりマルチモーダル融合による識別精度の向上が明確になった
・TCFGC-Netと他の既存モデルとの性能比較では、TCFGC-Netは全体的に最高のパフォーマンスを示した(識別精度93.7%、適合率91.5%、再現率98.3%を達成)
・TCFGC-Netのフレームレートは12.27 FPSと他のモデルよりも低いが、リアルタイムの事故ホットスポット識別要件を満たすには十分な速度である
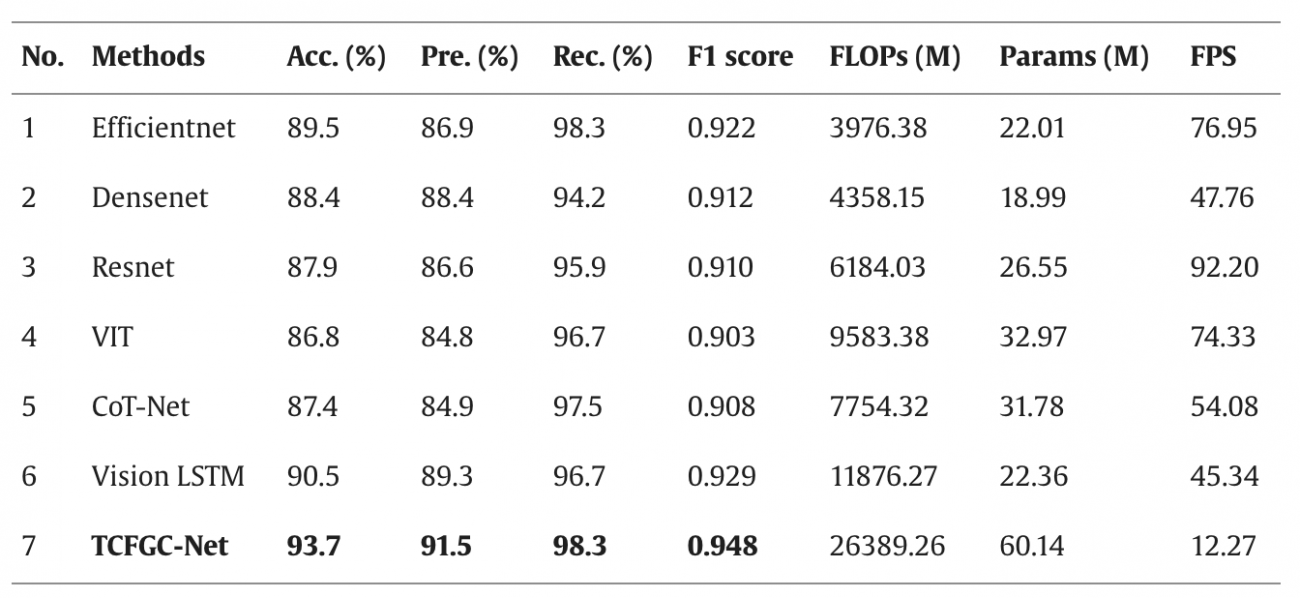
#TCFGC-Net #Trans-CFCCNN #SFRAN #MBFAF #交通事故 #道路
Deep Learning for Satellite Image Time Series Analysis: A Review
【どういう論文?】
・本論文は、ディープラーニング手法を用いて、地球観測衛星の時系列画像から環境、農業、その他の地球観測変数をモデリングする最先端手法の概要をレビューする
【レビュー対象となる地球観測衛星】
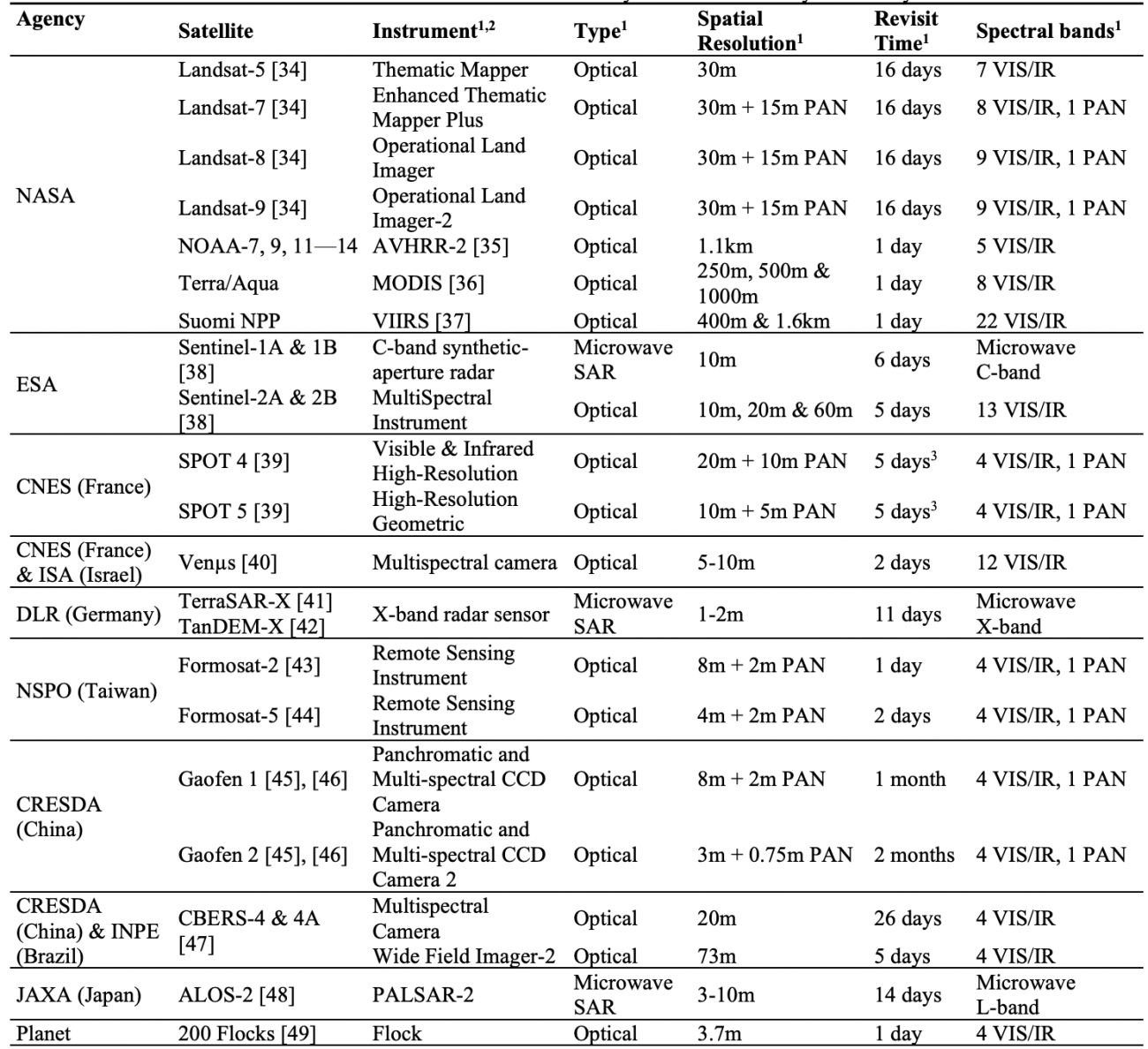
【地球観測衛星の概要】
①全体像
・地球観測データは、地球を観測する1200基以上の衛星によって収集される
・これらの衛星は、様々な空間的・時間的な解像度とスペクトルの周波数で観測を行い、多様なパラメータを測定している
②軌道
・多くの地球観測衛星は低軌道(600~1000km)で運用され、90~100分ごとに地球を1周する
・上記衛星は極軌道または準極軌道を取り、ほぼ地球全体をカバーする
・多くの衛星が太陽同期軌道で運用され、毎回同一の時間に赤道を通過する
・1基の衛星で地球全体をカバーするには数日かかるため、複数の衛星が連携して頻繁な観測を実現することが多い
③センサー
・センサーには、空間的・スペクトル的な解像度と高頻度の取得との間にトレードオフが存在する
・例えば、スペクトル解像度と信号対雑音比、空間解像度とデータ容量、空間解像度と時間解像度などが関係する
・1970年代以降の気象学用センサーである「高度非常高解像度放射計(AVHRR)」は、1日に1回すべての表面を撮影していた
・その後、フランスが1978年に地球観測衛星「SPOT」プログラムを開始し、ADAM実験で高解像度データを用いた植生季節変化の研究を開始した
・さらに、SPOTシリーズに続いて「MODIS」「MERIS」などのセンサーが登場し、さらに高い解像度と頻度での観測を実現できるようになった
・近年では、「Sentinel-1/SAR-C」「ALOS/PALSAR」などのマイクロ波センサーや、3D点群を生成するセンサーも登場しており、地球観測の可能性がますます広がっている
【地球観測プラットフォーム】
①衛星データの前処理
・衛星観測によって収集された生データは、機械学習で使用する前に前処理が必要である
・データプロバイダーが商業用に向けて「分析準備データセット」を作成する際に一般的に行う前処理には、以下の手順が含まれている
– 空間整合性:データの位置合わせやジオリファレンシング
– 放射補正:太陽の光反射などを除去するための補正
– 品質管理:データ品質フラグの付加
②クラウドプラットフォームの利用
・高解像度データはファイルサイズが非常に大きいため、処理能力を超える場合も多い
・そのため、Amazon Web Services(AWS)のEarth on AWS、MicrosoftのPlanetary Computer、Google Earth Engine(GEE)などのクラウドプラットフォームが、大容量データを扱うためのストレージおよびコンピューティング資源を提供している
・Sentinel-Hubのような、衛星データ特化型のクラウドプラットフォームも存在する
【衛星画像時系列解析ソフトウェア】
①Sentinel Application Platform(SNAP)
・欧州宇宙機関(ESA)が提供するツールで、Sentinelデータの処理に特化している
・ Sentinel-1(SAR)、Sentinel-2(光学)、Sentinel-3(海洋・気候)などのデータに対応している
②Orfeo Tool Box(OTB)
・フランスのCNES(フランス国立宇宙研究センター)により開発されたオープンソースのリモートセンシングライブラリである
・多様なリモートセンシングデータを処理するためのオープンソースライブラリで、深層学習モジュール(TensorFlowやKeras等)も含まれている
③R-SITSパッケージ
・R言語での衛星画像時系列データ解析を容易にするツールセットである
・Rの強みである統計的手法を組み合わせ、時系列の変動解析やパターン検出に利用できる
・Rのグラフ機能を使い、データの視覚的な理解も容易である
【欠損データの扱い】
①原因
・気候要因:雲や雨の覆い、影、エアロゾルが原因で画像データが欠ける場合がある
・技術要因:センサの故障やデータ転送時の損失で欠損が生じる
②補間手法
[時間的な補間]
・時間的な補間では、線形・スプライン補間が一般的である
・線形補間とは、2点間を直線で結び、その間の未知の値を計算するシンプルな手法である
・スプライン補間とは、連続した滑らかな曲線(スプライン)を描いてデータを補間する手法であり、線形補間よりもより自然で滑らかな曲線を描くため、データの変動が大きい場合に有用である
[空間的な補間]
・空間的な補間には、最も近い隣接点・バイリニア補間が用いられる
・隣接点の利用は、未知の値を最も近い既知の点の値で置き換えるシンプルな手法だが、滑らかさに欠けることが多い
・バイリニア補間は、4つの隣接点の重み付き平均で新しい点の値を計算する手法となっており、2次元データ(画像など)でよく使われる
・空間的な補間手法は、他には予測点からの距離に基づき重みを付けたり、クリギングという地理的な相関を考慮した手法もある
・また、マイクロ波と光学データを組み合わせて欠損データを補間する場合もある
【用途】
◾️農業への応用
①境界の識別と分類
・衛星画像時系列データは、作物の成長サイクルと土地利用の変動を年間を通して捉えることで、農業における重要な役割を果たす
・多くのアプリケーションでは、ピクセル単位での予測よりもフィールドレベルでの予測が重要であり、境界を正確にマッピングする必要がある
・マルチスペクトル衛星画像を利用し、異なる作物の生育段階の違いを活用することで、境界識別の精度を向上させることができる
②作物の種類と予測
・衛星画像時系列データを利用した作物分類や作物マッピングは、食料安全保障や貧困削減に不可欠である
・深層学習技術を使ったソリューションの中で、PSE(Pixel-Set Encoder)-TAE(Temporal Attention Encoder)は特に有望で、さまざまな研究で採用されている
・In-SeasonやEarly Crop Mappingなどの手法により、成長期の早い段階での予測も可能
③収穫量の予測
・衛星画像時系列データと深層学習は、収穫量の推定にも広く利用され、特定の作物ごとの生産予測を提供する
・成長期の早期では信頼性が低いものの、中期から後期にかけては信頼性の高い予測が可能で、数か月前に収穫量の見積もりができる
④灌漑と水管理
・灌漑作物や天水作物の監視、灌漑の範囲と頻度のモニタリング、作物の水供給量のマッピングなどに利用されている
◾️土壌と植生の水分
①土壌水分
・土壌水分は、植生の状態、農業、気候に影響する重要な変数である
・地上での測定の代わりに、リモートセンシングによる推定が可能である
・マイクロ波データは特に有用で、SAR技術を使った高解像度の土壌水分データが利用可能である
③生燃料水分含有量
・生燃料水分含有量は植生の水分含有量を示し、火災リスクの指標となる
・植生の状態を変える要因(降雨や気温の変化、土地利用の違い等)と植生状態自体(植物の成長や病害、枯れ具合等)の変化を考慮して推定する
◾️社会経済指標
①夜間光データ
・夜間光データは、都市開発の指標であり、貧困レベルの推定などに利用されている
・他のデータと組み合わせることで、詳細な地域レベルでの分析が可能になる
②時系列予測
・衛星画像時系列データを使ったモデルは、貧困レベルの時系列予測において有望な成果を示している
【深層学習アーキテクチャ】
①リカレントニューラルネットワーク (RNN)
・RNNは連続するデータに特化した構造を持つため、時系列データのモデル化に適している
・ただし、学習時間は時系列の長さに依存するため、長時間の時系列データでは計算コストが高くなる
・RNNは各時点で「隠れ状態」を生成し、次の時点に入力として利用することで、時系列データ全体を前方に伝搬し、以降の時点に影響を与えることができる
・さらに、隠れ状態はモデルの次の層に引き渡されるため、別のRNN層や異なるアーキテクチャを使用する層、あるいは出力層へと接続できる
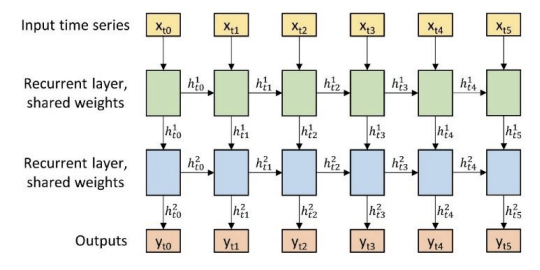

Lynn Miller, Member, IEEE, Charlotte Pelletier, Geoffrey I. Webb, Fellow, IEEE (2024).Deep Learning for Satellite Image Time Series Analysis: A Review Retrieved from https://arxiv.org/abs/2404.03936
②Convolutional Neural Networks (CNNs)
・シーケンシャルおよび多次元データの処理に適したディープラーニングモデルである
・主な構成要素は、入力に滑らせるように適用されるフィルター(カーネル)を持つ畳み込み層であり、フィルターの重みと入力のパッチ間の内積を計算することで特徴を抽出する
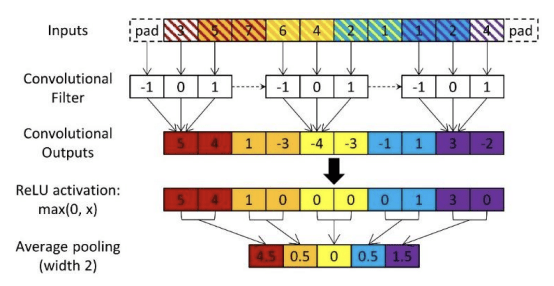
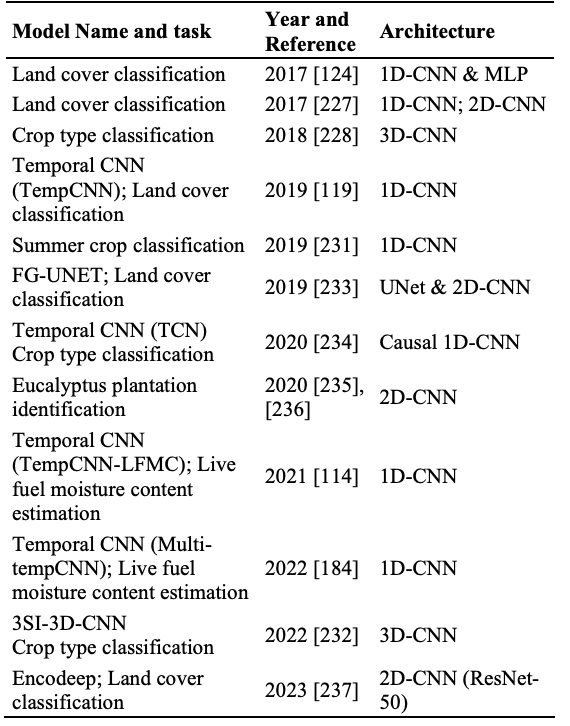
Lynn Miller, Member, IEEE, Charlotte Pelletier, Geoffrey I. Webb, Fellow, IEEE (2024).Deep Learning for Satellite Image Time Series Analysis: A Review Retrieved from https://arxiv.org/abs/2404.03936
③ハイブリッドモデル
・ハイブリッドモデルは、RNNとCNNを組み合わせたモデルである
・本モデルは、時系列データの処理に強みがあるRNNと、空間的特徴の抽出に優れたCNNの長所を組み合わせることにより、両者の制限を克服する
・特に、時間的・空間的次元を同時に扱う3D-CNNを除き、ほとんどのRNNやCNN単独のモデルでは、両次元を一緒に処理することが難しいため、パッチベースのピクセルごとの処理やセマンティックセグメンテーションなどのタスクにおいてハイブリッドモデルが有効である
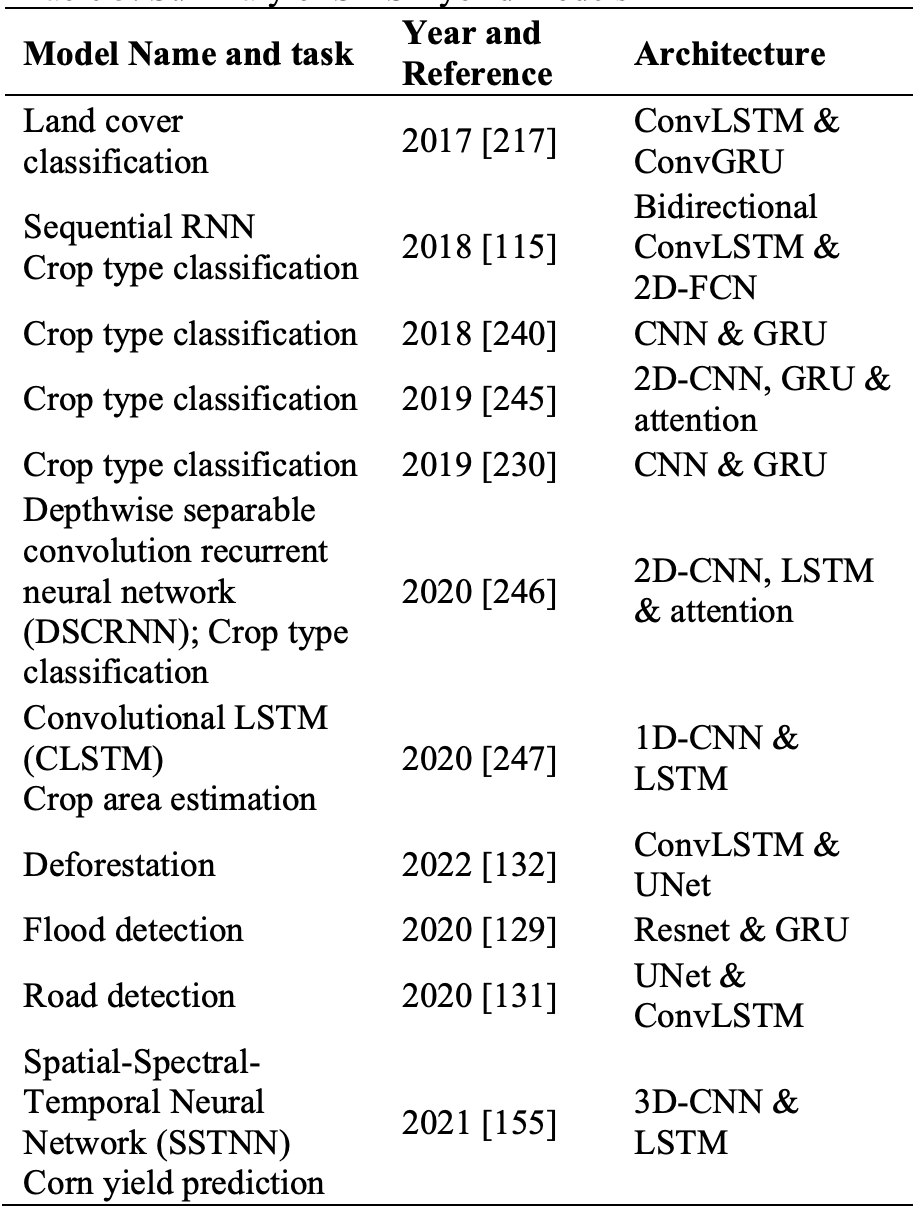
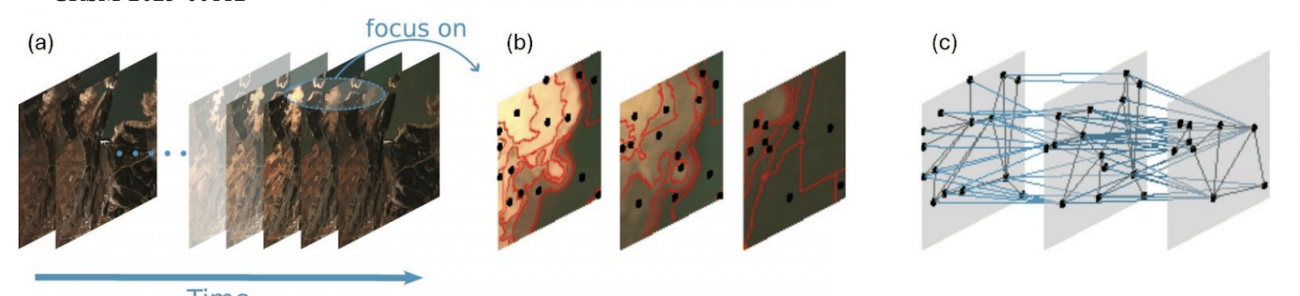
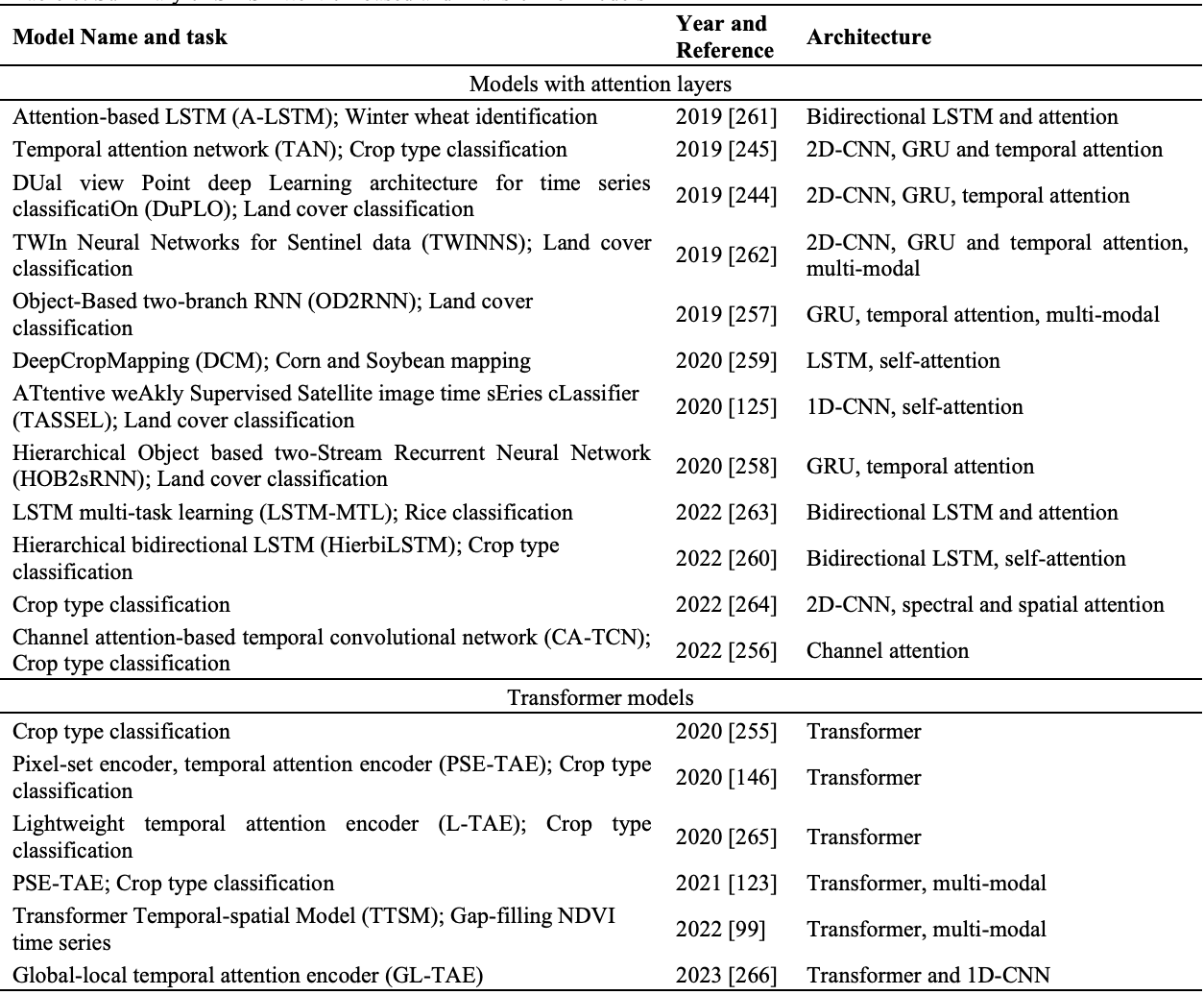
④トランスフォーマーモデル
・RNNは、短い時系列に対しては良好な性能を示すが、長い時系列データを学習する際にはいくつかの問題がある
(例えば、時系列全体での情報が伝わらずに勾配消失問題が発生する、固定サイズの隠れ層で全時系列の情報を符号化するため過負荷になる、時系列的に逐次処理するため並列化が難しい等)
・トランスフォーマーは、完全にRNN層を並列自己注意層(マルチヘッドアテンション)で置き換え、シーケンス全体を並列処理できるように設計されている
・入力に対する位置エンコーディングが追加情報を提供し、長期的な依存関係を捉え、訓練時間を短縮する
Lynn Miller, Member, IEEE, Charlotte Pelletier, Geoffrey I. Webb, Fellow, IEEE (2024).Deep Learning for Satellite Image Time Series Analysis: A Review Retrieved from https://arxiv.org/abs/2404.03936
⑤グラフニューラルネットワーク
・標準的な2D-CNN(畳み込みニューラルネットワーク)は、入力データが規則的なグリッド構造であることを前提にしている
・しかし、オブジェクトベースの処理には上記仮定が当てはまらないことがある
(オブジェクトは不規則な形状である場合が多く、グリッドで表現できない異なる数の隣接オブジェクトを持つ可能性がある)
・本問題に対応するため、グラフ構造を使用した空間学習が提案された
・グラフニューラルネットワーク(GNN)は、このグラフ構造を利用して複雑なパターンや関係性を識別する
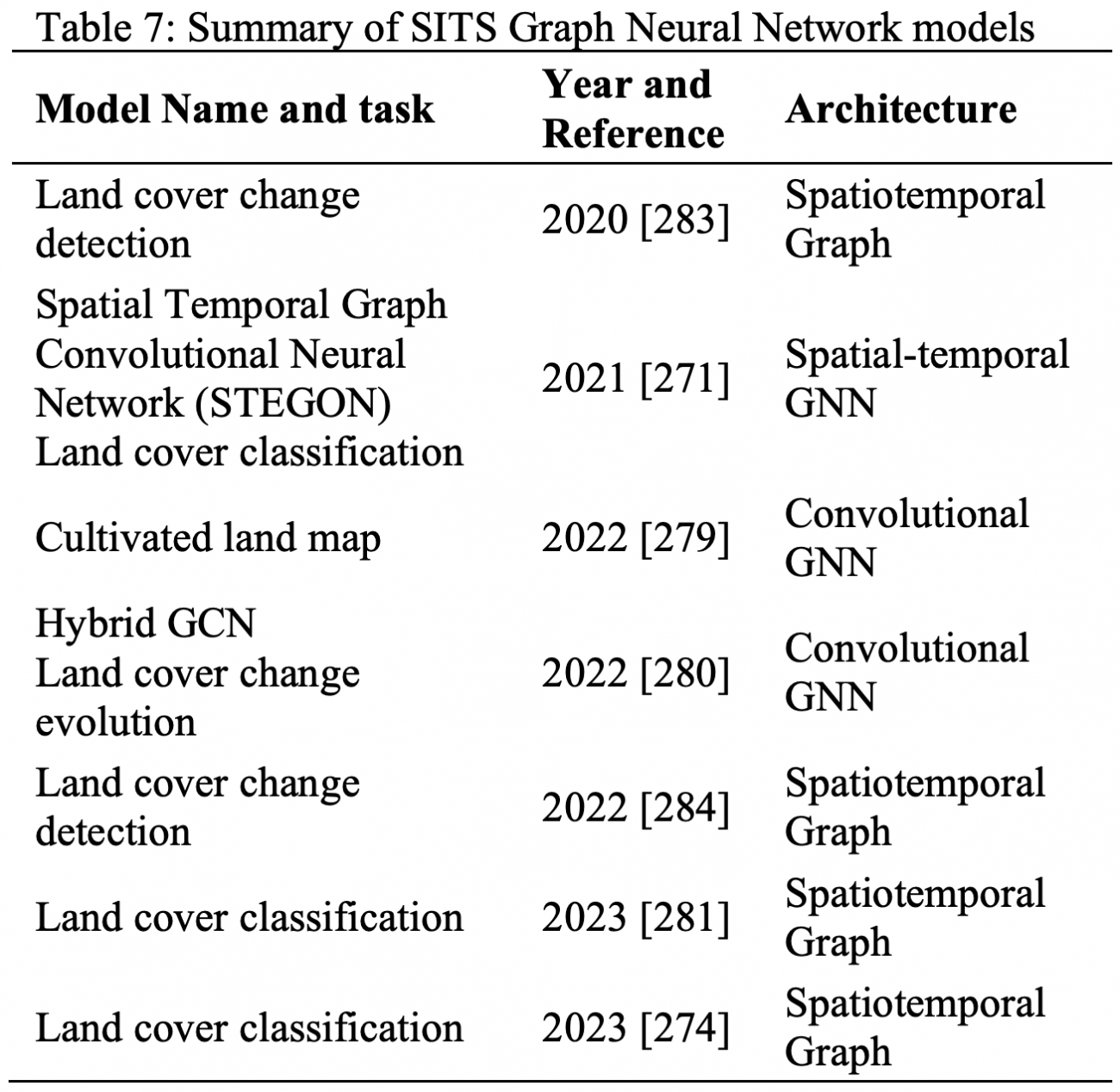
【学習戦略】
◾️教師あり学習
①ピクセル単位
・時系列での各ピクセルのデータを取得する
・周囲の情報に依存せずに直接的な予測が可能だが、画像全体の特徴を考慮せず、ノイズの混入などにより、予測精度が低下することがある
②オブジェクトベース
・オブジェクトベースの画像解析では、まず画像を均質な領域にセグメント化し、その後に各領域のターゲット値を予測する
・ピクセルごとの誤分類を減らす(ノイズに強い)一方で、事前のセグメンテーションにエラーがあると、その影響で誤分類が発生しやすい
③セマンティックセグメンテーション
・衛星データに含まれる各ピクセルにラベルを割り当てる技術であり、U-NetやPSPNetなどのアーキテクチャが利用される
・U-Netは、対称的な構造を持ち、エンコードとデコードの間で特徴を直接伝達するスキップ接続を活用するネットワークとなっており、セグメンテーション結果の一貫性を確保しやすい
・PSPNetはマルチスケールでの特徴抽出が可能となっていて、広いスケールで特徴を取り入れることで、セグメンテーションの精度向上が期待できる
④パノプティックセグメンテーション
・パノプティックセグメンテーションは、各ピクセルに2つのラベル(オブジェクトIDとクラス)を割り当てることで、各オブジェクトの位置とクラスを識別する手法である
・ オブジェクト単位でのセグメンテーションにより、特定のオブジェクトの位置とクラスが明確に認識できる
◾️教師データが少ない学習
①Semi Supervised Learning
4つの代表的なアプローチがある。
・1つ目の具体的な手法がSelf-Trainingであり、ラベルなしデータに対して擬似ラベル(モデルが自動的に生成した仮ラベル)を使ってトレーニングする
・2つ目はCo-Training and Tri-Trainingとなっていて、Co-Trainingは、同じデータに対する異なるビュー(スペクトルやテクスチャなど)を持つ2つのモデルを使用して学習し、両者のモデル予測結果を統合して精度を向上させるものである
・Tri-Trainingは、3つのモデルを使ってCo-Trainingを拡張したものとなっており、例えば、土地利用解析ではスペクトル特性と空間的テクスチャの2つのビューを活用し、それぞれのモデルで予測したラベルを交換してトレーニングする
・最後は生成モデルであり、擬似データを生成してトレーニングに利用することで、ノイズや欠損部分を含むデータからクリーンな画像を生成したり、類似画像から新たな合成画像を作成してモデルのトレーニングデータとして利用することができる
②Self Supervised Learning
2つの代表的なアプローチがある。
・1つ目が予測モデルであり、ノイズの除去やマスキングなどの事前タスクを通してデータの潜在的な表現を学習させる手法であり、例えば、SITS-BERTはTransformerアーキテクチャを使い、ピクセルにランダムなノイズを加えて除去するタスクを通じて、地理空間データの潜在的な表現を学習することができる
・2つ目が対照学習であり、似たデータの表現を近づけ、異なるデータには異なる表現を持たせるようにトレーニングさせる手法であり、地理情報において異なる時間帯の画像や、異なるセンサーで撮影された画像を使い、類似した内容を持つペアを識別するための潜在表現を学習する
③ドメイン適応
・本手法は、あるソースドメイン(データが豊富にあり、モデルの訓練に使うことができる領域)のデータで訓練されたモデルを、関連するターゲットドメイン(モデルの訓練に十分なデータが存在しない領域)で効果的に機能する手法である。代表的なアプローチが3つある
・1つ目の具体的な手法は、ドメイン敵対的ニューラルネットワーク (DANN)というもので、ドメイン敵対的学習を使って、ターゲットドメインからのデータがソースドメインと見分けがつかないようにすることで、ソースドメインで訓練されたモデルがどちらのデータでも正確に予測できるようにする手法であり、ある気候条件の農業データで訓練したモデルを、異なる気候条件の地域の農業データに適応させて作物の予測に役立てる等の応用例がある
・2つ目がフェノロジー整列ネットワーク (PAN)というもので、GRU(ゲーティッド・リカレント・ユニット)と自己注意機構を用いて、時間的な特徴整合を行い、最大平均差異 (MMD) によってソースとターゲットの時系列データの違いを埋める手法となっており、同じ地域の異なる年の作物データを使用し、その年の気候や生育サイクルの違いを超えてモデルが予測できるようにするなどの応用例がある
・3つ目は空間的整列ドメイン敵対的ニューラルネットワーク (SpADANN)であり、DANNをベースにセマンティックな空間不変性を利用する擬似ラベリング戦略を組み合わせる手法となっていて、 同じ地理的エリアで異なる年に撮影された衛星データを使用し、時系列変化を学習したモデルが、数年後の新しいデータでも利用できるようになる
◾️教師なし学習
・ディープクラスタリングアプローチが基本的に有効である
・ディープクラスタリングアプローチとは、オートエンコーダーを使用して時系列データの表現を学習し、その後、k-平均法などの伝統的なクラスタリングアルゴリズムを使用してさらにクラスタリングを行う手法である
・オートエンコーダーは、1D-CNN、2D-CNN、または3D-CNNなどの時系列ネットワークを基盤として構築されている
◾️メタ学習
・新しい未見のタスクに対して、少数のラベル付きデータで効果的にパフォーマンスを発揮できる深層学習モデルである
・異なるタスクの共通知識をモデルパラメータに共有することで実現することができ、複数のデータセットに少量のラベル付きデータが存在する場合に特に有効である
◾️解像度向上
・データフュージョンを用いて、異なる解像度を持つ画像を統合して高い分解能を持つ画像を生成する
・パンシャープニングという手法では、高空間解像度のパンクロマチックバンド(白黒画像)と低空間解像度のマルチスペクトルバンド(多波長画像)を融合させることができる
・空間 / 時間解像度の向上という文脈では、MODIS(低空間解像度/高時間解像度)とLandsat-8(高空間解像度/低時間解像度)の画像を融合して30mの空間解像度かつ毎日の時系列データを生成したり、Sentinel-2(高空間解像度)とSentinel-3(高時間解像度)の画像をフュージョンし、Sentinel-2同様のクオリティで毎日の時系列画像を生成できる
・スーパー解像(Super-Resolution)という手法も出てきており、Multi-Image Super-Resolution (MISR)というアルゴリズムでは、一連の低解像度画像を使用して高解像度画像を再構築できる
◾️マルチモーダル融合
・本論文では、生データ融合(Raw Data Fusion)、特徴レベル融合(Feature Level Fusion)、決定レベル融合(Decision Level Fusion)の3つについて言及していますが、宙畑では以前にデータフュージョンについて詳しく解説している以下の記事がありますので、そちらをご参照ください
これからのデータ分析では常識!? 複数のデータを融合させて使う”データフュージョン”とは?
◾️階層的学習
・階層的学習は、土地被覆や作物クラスを階層構造に基づいて分類する手法である
・例えば、最上位レベルでは「農業地域」という広いカテゴリがあり、その下位には「稲作地」や「ブドウ園」などの具体的なカテゴリがある
・階層の下位カテゴリは、同じ親カテゴリを共有するため、共通の特性を持つことが多く、モデリングにおいて有用となるにもかかわらず、多くの既存分類モデルはこれらのクラスを独立したものとして扱っていることに対し、階層的学習は、広範なカテゴリと具体的なカテゴリの関係を利用して、モデルの性能を向上させる
◾️マルチタスク学習(Multi Task Learning)
・関連する複数のタスクを同時に学習する手法であり、各タスクの学習効果を向上させることができる
・例えば、農業データを使って、同じモデルで作物の種類の分類と収量の予測を同時に行うことが可能となる
#Sentinel-Application-Platform #Orfeo-Tool-Box #R-SITS #RNN #CNN #トランスフォーマー #教師あり学習 #パノプティックセグメンテーション #Semi-Supervised-Learning #Self-Supervised-Learning #ドメイン適応 #教師なし学習 #メタ学習 #解像度向上 #パンシャープニング #MODIS #Landsat #Sentinel #Multi-Image Super-Resolution #マルチモーダル融合 #階層的学習 #マルチタスク学習 #グラフニューラルネットワーク
以上、2024年4月に公開された論文をピックアップして紹介しました。皆様の業務や趣味を考えた時に、ピンとくる衛星データ利活用に関する話題はありましたか?
最後に、#MonthlySatDataNewsのタグをつけてTwitterに投稿された全ての論文をご紹介します。
ONFIRE Dataset: Monthly Gridded Burned Area data
来月以降も「#MonthlySatDataNews」を続けていきますので、お楽しみに!
