TellusでPALSAR-2のL2.1標準処理データを使って 土地被覆の抽出にチャレンジ
本記事では、Tellusで公開しているPALSAR-2のL2.1標準処理データを取得する方法から、複数の偏波データを使って、土地被覆情報を抽出する方法を解説します。後半では、簡単な機械学習による評価結果も紹介します。
記事作成時から、Tellusからデータを検索・取得するAPIが変更になっております。該当箇所のコードについては、以下のリンクをご参照ください。
https://www.tellusxdp.com/ja/howtouse/access/traveler_api_20220310_
firstpart.html
2022年8月31日以降、Tellus OSでのデータの閲覧方法など使い方が一部変更になっております。新しいTellus OSの基本操作は以下のリンクをご参照ください。
https://www.tellusxdp.com/ja/howtouse/tellus_os/start_tellus_os.html
Tellusでは、Tellus OS(ブラウザ上)で手軽に確認できるタイル化したデータに加えて、衛星データの提供元オリジナルデータを配信する機能をリリースしています。
詳しくはこちらの記事をご覧ください。
【ゼロからのTellusの使い方】提供元オリジナルデータを取得する
【コード付き】TellusでPALSAR-2のL1.1の 画像化にチャレンジしてみた
オリジナルデータは衛星データの知識がないとなかなか触るのが難しい代物ではありますが、使い方が分かるとグッと世界が広がります。
本記事では、Tellusで公開しているPALSAR-2のL2.1標準処理データを取得する方法から、複数の偏波データを使って、土地被覆情報を抽出する方法を解説します。後半では、簡単な機械学習による評価結果も紹介します。
PALSAR-2の処理レベルL2.1って?
L2.1は解像度補正・オルソ補正済みの強度画像
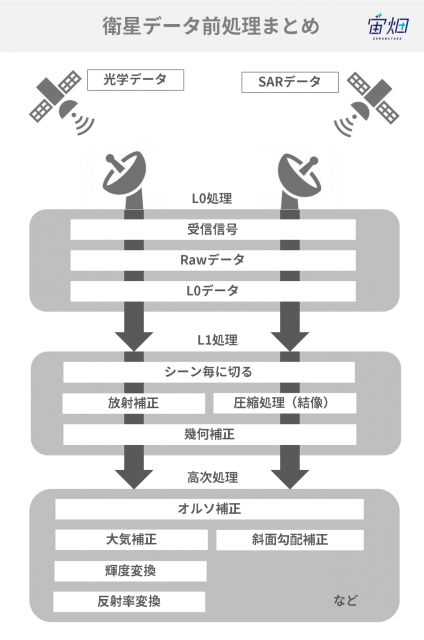
SAR画像には、いくつかの処理レベルがあります。L2.1は、解像度の補正、オルソ補正が行われ、その後の高次処理のベースとなるプロダクトです。情報は受信電波の強度情報のみですが、画像の見え方は光学画像に近いため、物体検出、植生分類、土地被覆分類など様々なアプリケーションがこの処理レベルから作成可能になります。
最大の特徴は偏波情報を持っていること
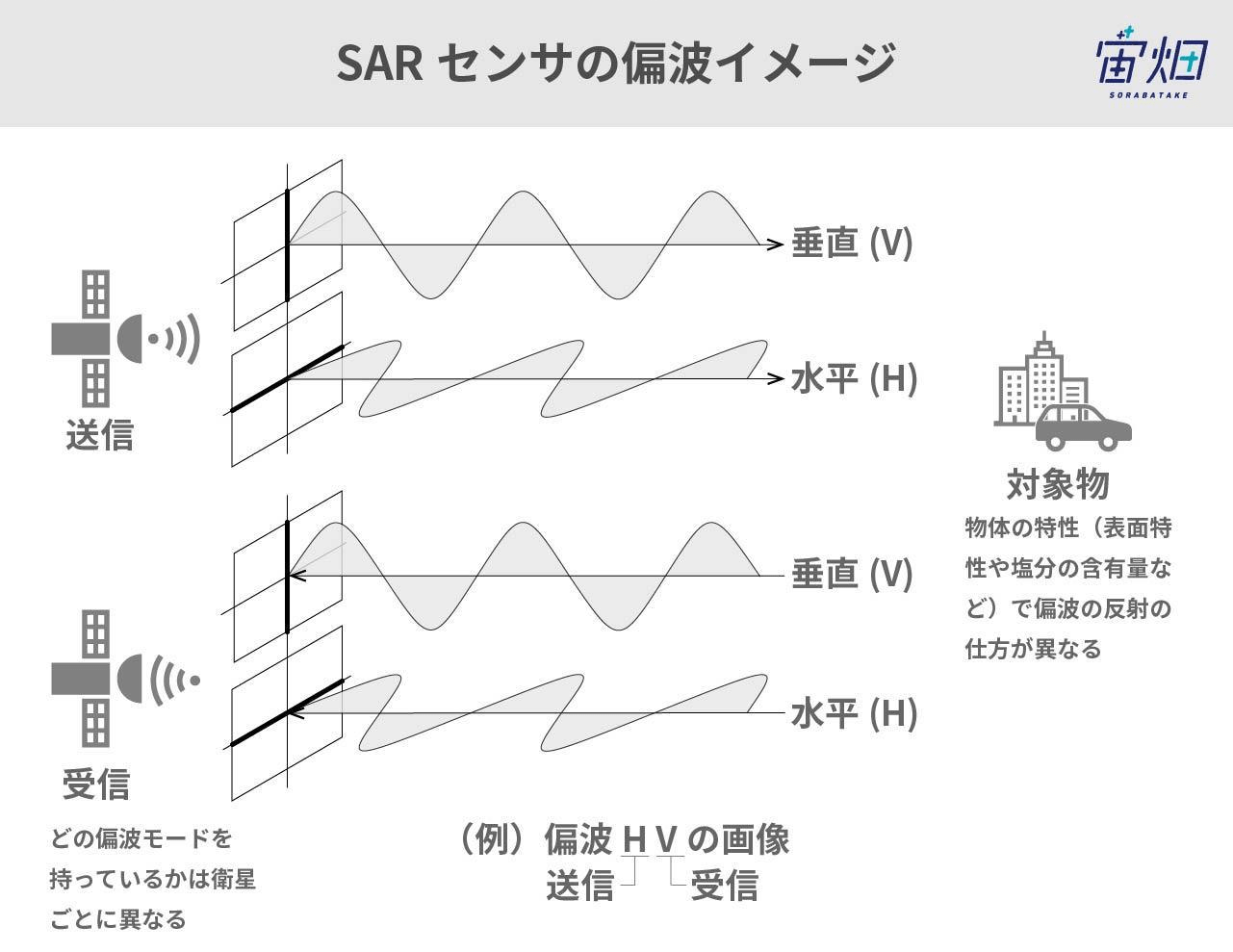
データの種類は偏波(へんぱ)と呼ばれる送受信の電波の種類によって、最大で4種類(HH, HV, VH, VV)あります。送信(1文字目)と受信(2文字目)それぞれについて垂直偏波(V)か水平偏波(H)かを表しています。これにより、受信強度だけでなく、対象物の偏波特性に応じた画像解析が可能になります。
SARデータの前処理について、詳しくは以下をご覧ください。
【図解】衛星データの前処理とは~概要、レベル別の処理内容と解説~
PALSAR-2 L2.1の標準処理データを取得しよう
Tellusで開発環境(Jupyter Lab)を使う方法は、「Tellusの開発環境でAPI引っ張ってみた」をご覧ください。
プロダクトIDの取得・データセットのダウンロード
PALSAR-2のL2.1プロダクトをダウンロードするためには、プロダクトIDを指定する必要があります。プロダクトIDは検索して好きなものを選べばよいのですが、今回は、複数の偏波データが収録されているプロダクトを検索することにしました。
import requests
TOKEN = "自分のAPIトークンを入れてください"
def search_palsar2_l21(params={}, next_url=''):
if len(next_url) > 0:
url = next_url
else:
url = 'https://file.tellusxdp.com/api/v1/origin/search/palsar2-l21'
headers = {
"Authorization": "Bearer " + TOKEN
}
r = requests.get(url,params=params, headers=headers)
if not r.status_code == requests.codes.ok:
r.raise_for_status()
return r.json()
def main():
for k in range(100):
if k == 0:
ret = search_palsar2_l21({'after':'2017-1-01T15:00:00'})
else:
ret = search_palsar2_l21(next_url = ret['next'])
for i in ret['items']:
if len(i['polarisations']) > 1:
print(i['dataset_id'],i['polarisations'])
if 'next' not in ret:
break
if __name__=="__main__":
main()
このプログラムを実行すると、2017年以降のデータで、偏波データが2種類以上のプロダクトIDが出力されます。その中で一つのプロダクトIDを選んで、以下のコードで、プロダクトに含まれるデータセットをダウンロードします。
import os, requests
TOKEN = "自分のAPIトークンを入れてください"
def publish_palsar2_l21(dataset_id):
url = 'https://file.tellusxdp.com/api/v1/origin/publish/palsar2-l21/{}'.format(dataset_id)
headers = {
"Authorization": "Bearer " + TOKEN
}
r = requests.get(url, headers=headers)
if not r.status_code == requests.codes.ok:
r.raise_for_status()
return r.json()
def download_file(url, dir, name):
headers = {
"Authorization": "Bearer " + TOKEN
}
r = requests.get(url, headers=headers, stream=True)
if not r.status_code == requests.codes.ok:
r.raise_for_status()
if os.path.exists(dir) == False:
os.makedirs(dir)
with open(os.path.join(dir,name), "wb") as f:
for chunk in r.iter_content(chunk_size=1024):
f.write(chunk)
def main():
dataset_id = 'ALOS2236422890-181009' #選んだプロダクトIDを入力
print(dataset_id)
published = publish_palsar2_l21(dataset_id)
for file in published['files']:
file_name = file['file_name']
file_url = file['url']
print(file_name)
file = download_file(file_url, dataset_id, file_name)
print('done')
if __name__=="__main__":
main()
以上でデータの取得が完了しました。カレントディレクトリに、プロダクトIDと同名のフォルダが作成され、その中にデータが保存されています。
偏波データを土地被覆データとして可視化してみる
さっそく偏波データを可視化してみましょう。今回は、HH偏波とHV偏波のデータがありますので、その差分値を合わせた3種類のデータを、トゥルーカラーとして表示してみます。そうすることで、それぞれの偏波特性が、どのような土地被覆データと相関があるかを、調べることができます。
from osgeo import gdal, gdalconst, gdal_array
import os
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
def normalization(arr):
min = np.amin(arr)
max = np.amax(arr)
ret = (arr-min)/(max-min)
return ret
dataset_id = 'ALOS2236422890-181009'
offx = 14000
offy = 16000
cols = 5000
rows = 5000
tif = gdal.Open(os.path.join(dataset_id,'IMG-HH-'+dataset_id+'-UBDR2.1GUD.tif'), gdalconst.GA_ReadOnly)
HH = tif.GetRasterBand(1).ReadAsArray(offx, offy, cols, rows)
tif = gdal.Open(os.path.join(dataset_id,'IMG-HV-'+dataset_id+'-UBDR2.1GUD.tif'), gdalconst.GA_ReadOnly)
HV = tif.GetRasterBand(1).ReadAsArray(offx, offy, cols, rows)
HH = 10*np.log(HH) - 83.0
HV = 10*np.log(HV) - 83.0
HH = normalization(HH).reshape(rows*cols,1)
HV = normalization(HV).reshape(rows*cols,1)
HHHV = normalization(HH-HV).reshape(rows*cols,1)
img = np.hstack((HH,HV,HHHV)).reshape(rows,cols,3)
plt.figure()
plt.imshow(img, vmin=0, vmax=1)
plt.imsave('sample.jpg', img)
得られた画像と、Tellusから取得したAVNIR-2の画像と比較してみるとこのようになります。
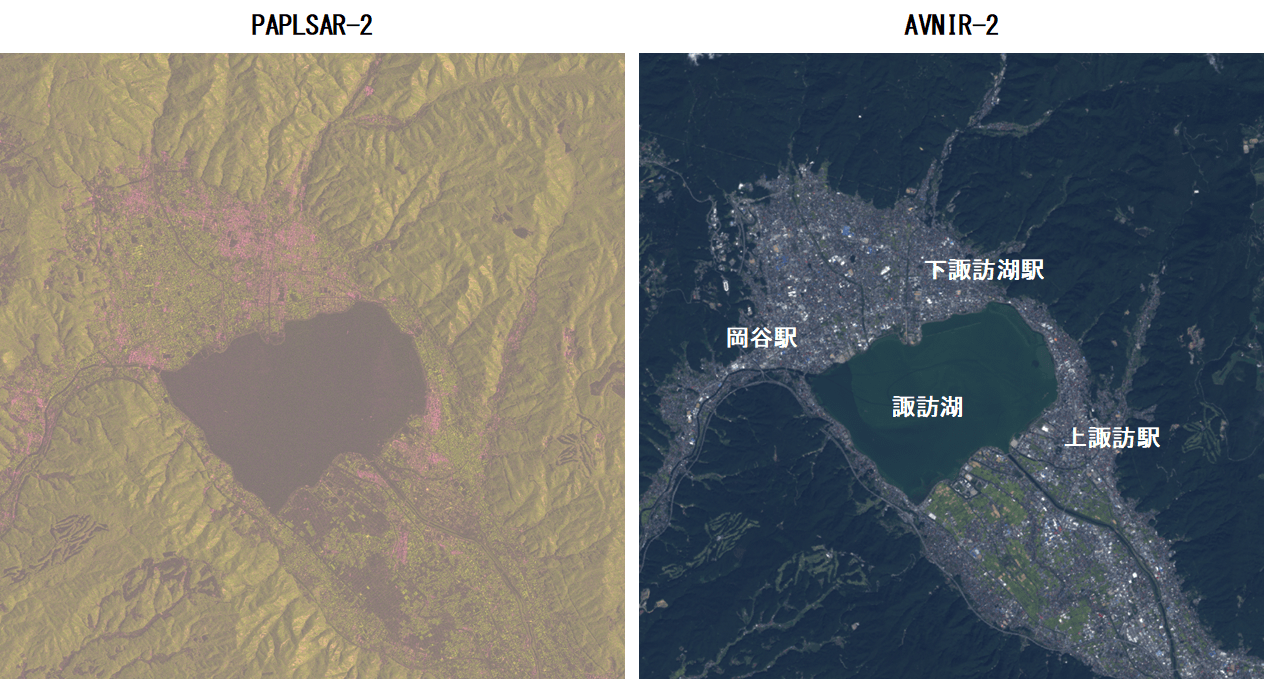
今回は、諏訪湖周辺の画像を選んでみました。HHがRed, HVがGreenなので、都市部がHHが強く、緑地が緑に対応していることがわかります。また、諏訪湖は反射強度が弱いため、暗くなっています。このように、2種類の偏波であっても、ある程度の土地被覆分類に役立てそう、ということがわかりました。
機械学習で土地被覆推定をやってみる
最後に、応用編として、機械学習をやってみた結果を紹介します。JAXAが行った、土地被覆分類の結果を使って、機械学習による土地被覆分類の推定モデルを作成してみました。
ラベルデータとなる画像はこのような感じになっています。
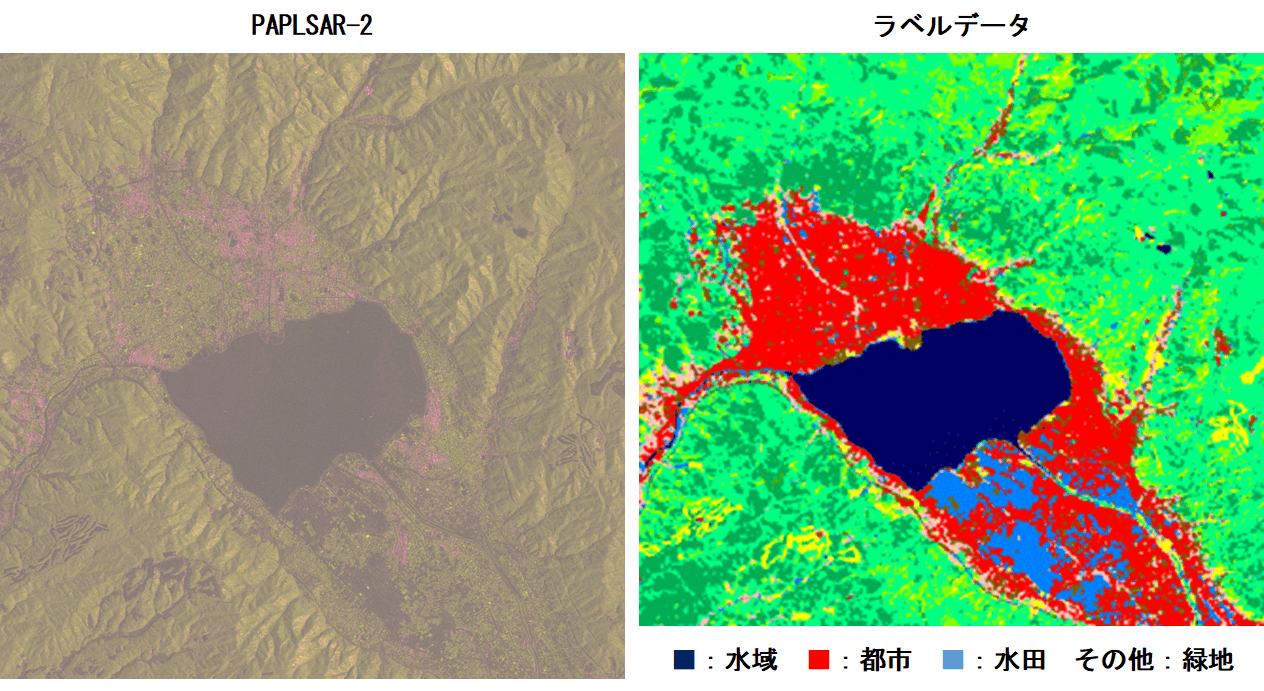
このラベルデータは、実際には10種類にクラス分けされているのですが、今回はラベルデータの分解能が30mと低いこと、訓練画像が3偏波(HH, HV, HH-HV)の情報のみであることから、「水域」「都市」「水田」、その他を「緑地」とした4種類にデグレードして使用します。
データセット・CNNの作り方
今回は、衛星画像もラベル画像も、GeoTiff形式のため、それぞれの画像の各ピクセルの緯度経度が取得できます。しかし解像度が異なるため、低い解像度のラベルデータをオーバーサンプリングする必要があります。具体的な手順としては以下の通りです。
①衛星画像と同じピクセル数の空の二次元配列を用意する
②衛星画像の各ピクセルの緯度経度を含む、ラベル画像のピクセルを検索する
③そのセルのラベルデータを①で用意した空の配列に格納する
以上で、衛星画像と全く同じ解像度に対応したラベルデータが作成できます。for 文で全てのピクセルを走査しても、それほど時間はかかりませんので、上記の手順でどなたでも作成できると思います。
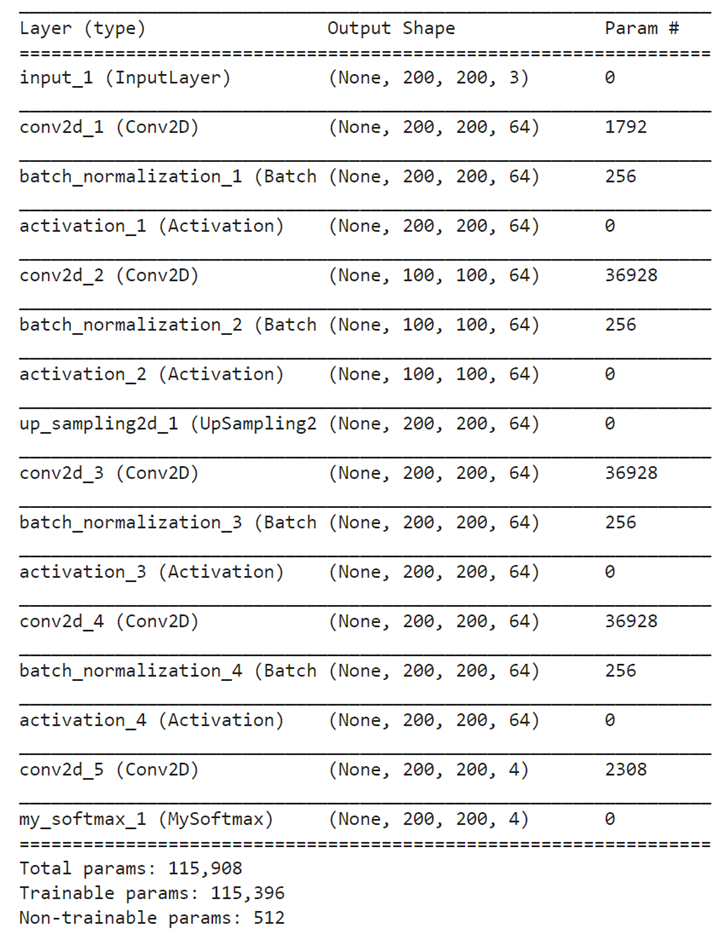
学習モデルには、宙畑の他の記事などを参考に、Keras, Tensorflowを用いてCNNを構築しました。諏訪湖を中心とした5400×4600ピクセルの画像を、200×200ピクセルに分割して、合計621枚のデータセットを作成しました。衛星画像の解像度に合わせて、30m解像度のラベルをオーバーサンプリングしています。訓練用、検証用、テスト用として約7:2:1の比率でランダムに振り分けました。
今回は、Jupyter Notebook上で、各データをメモリに保存しながら、機械学習を実行しました。そのため、学習開始時点で外部にファイル出力はしていません。具体的には、以下の配列をNumpy Arrayとしてメモリに格納した状態で、機械学習を実行していきます。()内はNumPy Arrayの配列サイズです。振り分ける比率や画素数は自由に変えても構いません。
訓練用:
X_train(435, 200, 200, 3)
Y_train(435, 200, 200, 4)検証用:
X_train(124, 200, 200, 3)
Y_train(124, 200, 200, 4)テスト用:
X_train(63, 200, 200, 3)
Y_train(63, 200, 200, 4)また、構築したCNNは以下の通りです。データセットを作成した上で、実行してみてください。
import tensorflow as tf
import keras
from keras import backend as K
from keras.layers import Input, Dropout, Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D, UpSampling2D, Activation
from keras.layers.normalization import BatchNormalization
from keras.models import Model
from keras.activations import softmax
from keras.engine.topology import Layer
class MySoftmax(Layer):
def __init__(self, **kwargs):
super(MySoftmax, self).__init__(**kwargs)
def call(self, x):
return(softmax(x, axis=3))
# parameter
img_size = 200
npol = 3
nclass = 4
# create model
input_shape = (bsize, bsize, npol)
input = Input(shape=input_shape)
act = 'relu'
net = Conv2D(filters=64, kernel_size=(3,3), strides=(1,1), padding="same", kernel_initializer="he_normal")(input)
net = BatchNormalization()(net)
net = Activation(act)(net)
net = Conv2D(filters=64, kernel_size=(3,3), strides=(2,2), padding="same", kernel_initializer="he_normal")(net)
net = BatchNormalization()(net)
net = Activation(act)(net)
net = UpSampling2D((2,2))(net)
net = Conv2D(filters=64, kernel_size=(3,3), strides=(1,1), padding="same", kernel_initializer="he_normal")(net)
net = BatchNormalization()(net)
net = Activation(act)(net)
net = Conv2D(filters=64, kernel_size=(3,3), strides=(1,1), padding="same", kernel_initializer="he_normal")(net)
net = BatchNormalization()(net)
net = Activation(act)(net)
output = Conv2D(filters=nclass, kernel_size=(3,3), strides=(1,1), padding="same", kernel_initializer="he_normal")(net)# class
output = MySoftmax()(output)
model = Model(input, output)
## optimizer
opt= keras.optimizers.Adam(lr=1e-3)
model.compile(loss="sparse_categorical_crossentropy", optimizer=opt)
print(model.summary())
##実際のデータを用いた学習(実行するには、事前にデータの作成が必要です)
model.fit(X_train, Y_train, batch_size=16, epochs=24, validation_data=(X_val, Y_val))
機械学習を実施し、テスト画像を用いて評価した結果、このような感じになりました。

結果を見ると、諏訪湖の湖岸の境目を教師ラベルよりも正確に解けていることがわかります。また、赤(HH偏波)が強いところを都市部、緑(HV偏波)が強いところを緑地として、ラベルよりも細かい解像度で正確に判断できているようです。ただし、残念ながら水色の水田はほぼ全て諏訪湖と同じ水域と判断されてしまいました。やはり、HHとHVの強度だけでは違いを見分けられなかったようです。
SARデータによる機械学習の研究では、例えばHVとVVのように異なる送信偏波の位相差情報を使うことが有効とされています。位相情報を使うためには、前回の記事で紹介したL1.1の情報が必要となりますので、こちらも参考にしてみてください。
まとめ
本記事では、SARデータを使って土地被覆情報を可視化する方法を解説しました。また、光学画像と同様に、SARの場合は複数の偏波情報を用いて機械学習にかけることができることもおわかりいただけたと思います。
簡単ではありますが「SAR×AI」のイメージを、掴んでいただけたのではないでしょうか。SAR画像の利用方法に関しては、光学と比べてまだまだ開発途上だと言われています。ぜひTellus上で公開されている標準処理プロダクトを活用してみてください。
