超解像×衛星画像でできること。関連論文の紹介とTellusでやるには
衛星画像を超解像することでどのようなことができるようになるのか、論文も合わせてご紹介。Tellusでの衛星画像の超解像方法についても解説するので、ぜひチャレンジをしてみてください!
画像系の機械学習の分野の1つである「超解像」。一般画像の超解像がよく行われていますが、衛星画像に適用する例も見られてきています。
衛星画像を超解像することでどのようなことができるようになるのか、論文も合わせてご紹介。Tellusでの衛星画像の超解像を実施してみる際のヒントについても解説するので、ぜひチャレンジをしてみてください!
1.超解像×衛星画像で何ができるか
1.1 衛星画像分野で機械学習が必要になっている背景
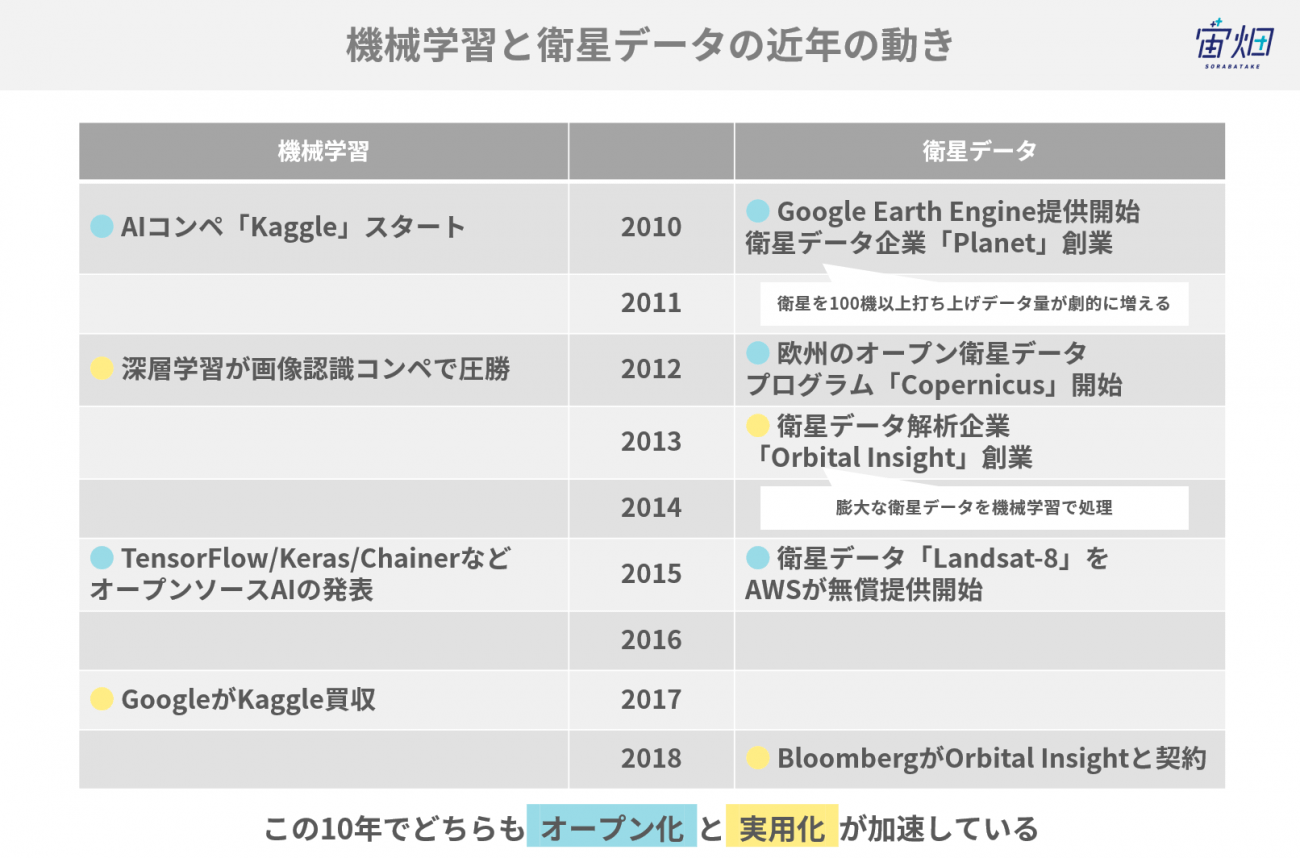
近年、超解像に関わらず、衛星画像の分野で機械学習を適用しようという動きが盛んになっています。
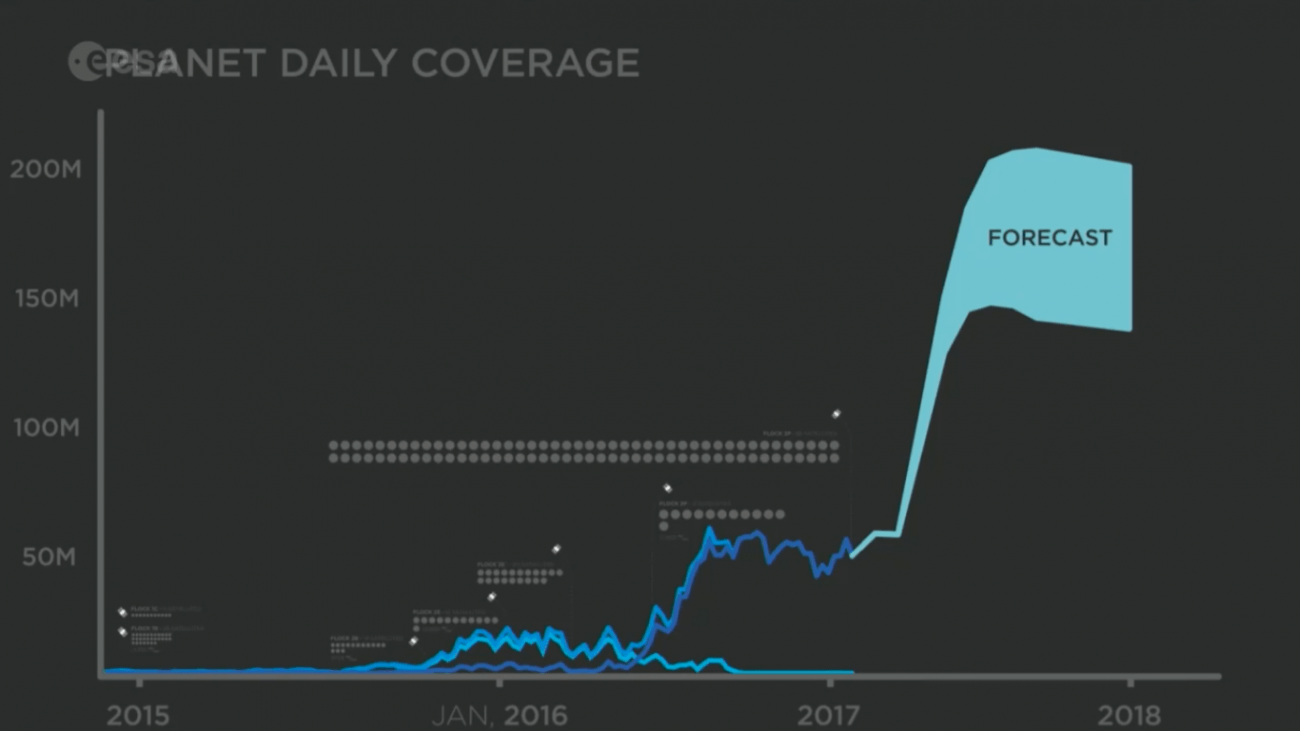
理由は、この10年で打ち上げられる衛星の数が爆発的に増え、それに合わせて衛星が撮影する衛星画像の量が爆発的に増えているからです。
衛星画像の量が増えると、人が1枚1枚画像に何が写っているのか確認するわけにも行きません。そこで、機械学習を使って大量の衛星画像に何が写っているのか把握しようという動きが世界中で行われています。
例えば、駐車場の車の台数を機械学習で数えることで、スーパーマーケットやアミューズメントパークの売上を予測することができます。

広範囲に撮影できるという人工衛星の利点を活かし、衛星画像から日々アップデートされる地図を作ろうという試みも行われています。
機械学習を用いて衛星画から道路を自動抽出することができれば、世界中の地図を日々アップデートすることができ、自動運転などに役立つとされています。
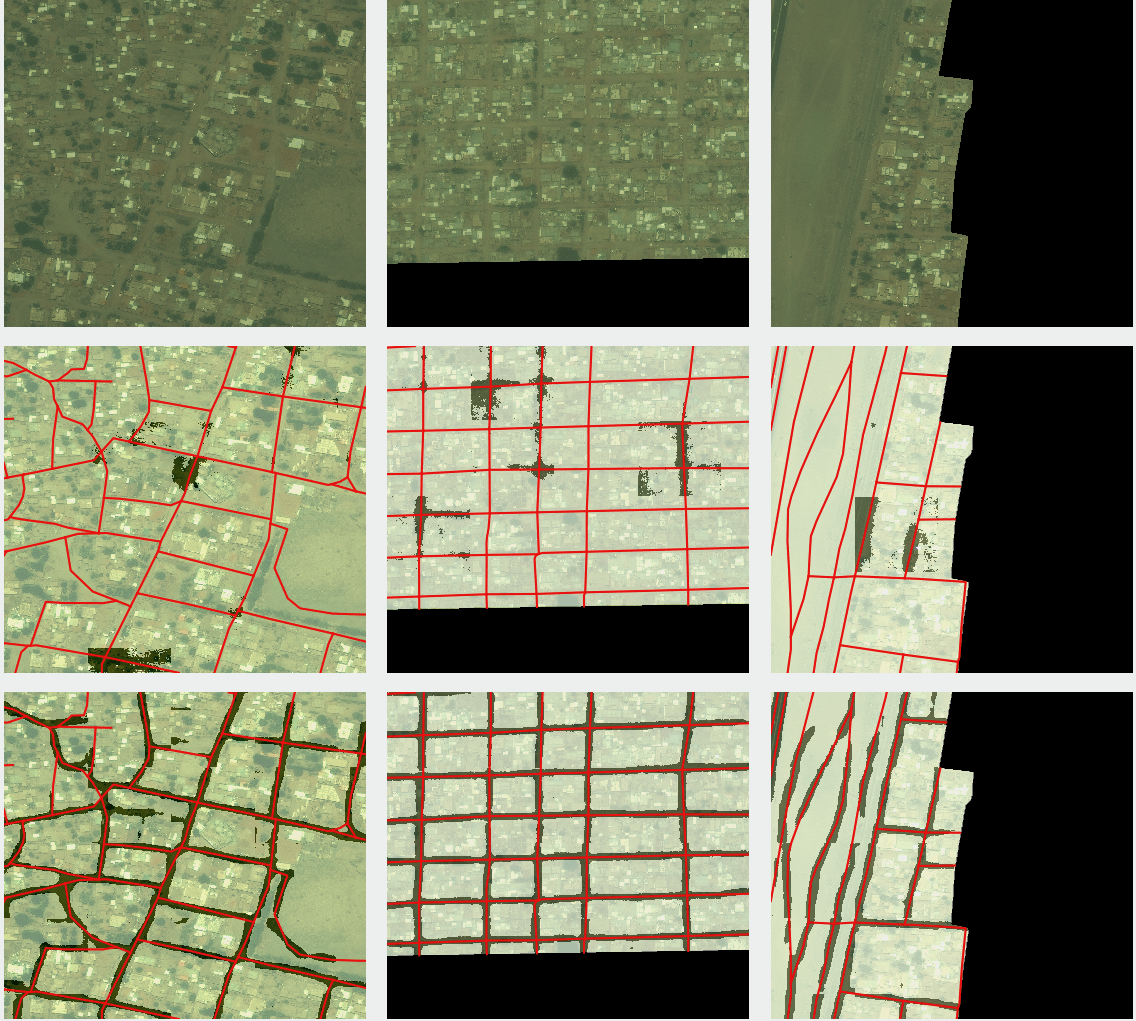
1.2 超解像×衛星画像でできるようになること
衛星画像を超解像することで、人が目で見た際に写っているモノを識別しやすくなることはもちろんですが、先に上げた機械学習による物体識別の精度を上げることが期待されています。
海外でも、例えば欧州の衛星データプラットフォームUP42で中解像度の衛星画像から超解像を行う技術が研究されています。

https://medium.com/up42/quadruple-image-resolution-with-super-resolution-6e5cbab81cd7
衛星画像は、衛星毎に色味が異なっていたり撮影する時の気象条件で太陽の当たり方違っていたりするので、一般的な画像を用いて行う超解像とは違った難しさもあるようです。
そこで今回の記事では、今、衛星データ分野でアツイ、超解像や衛星画像に対しての適用を行った論文をご紹介します。
2. そもそも「超解像」ってなに?
まずは超解像についてあまり詳しくない方向けに、簡単に超解像についてご紹介します。すでにご存じの方は読み飛ばしてください。
2.1 超解像とは
「超解像」という言葉、GoogleのスマートフォンPixel4のCMで聞いたことがあるという方もいらっしゃるかもしれません。
超解像とは、元の画像の解像度を擬似的に上げる技術のことを言います。
英語ではSuper-Resolution、略してSRと表記されることが多いです。

時間の異なる複数の画像を組み合わせたり、異なったセンサからの複数の画像を取得して、そこから解像度を上げる技術などもありますが、今回は1枚の低解像画像をインプットにして、1枚の高解像度画像を予測する「単眼超解像(Single image super-resolution)」にスポットを当てて説明をしていきます。
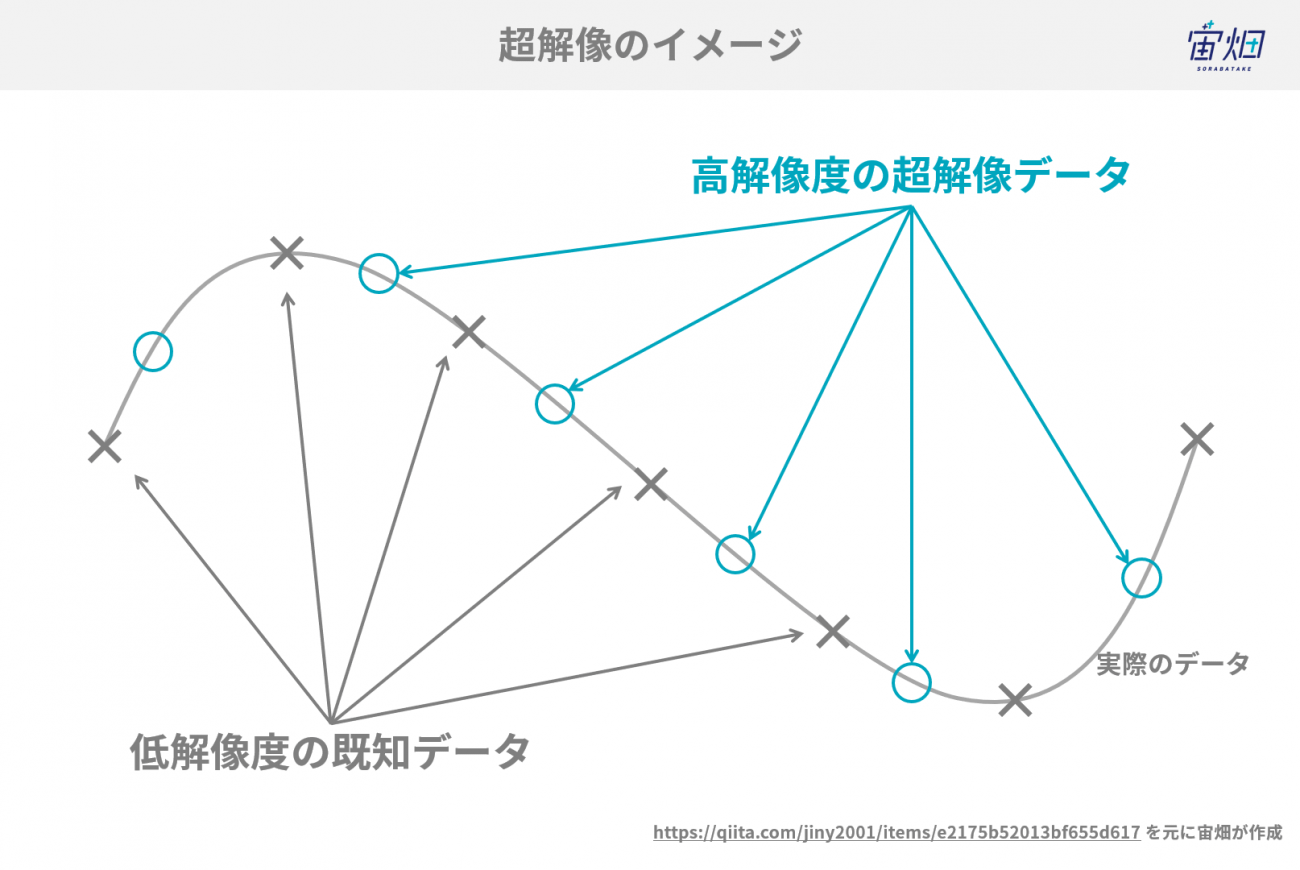
単眼超解像は、既知のデータから間のデータを予測するということです。
2.2 一般的な補間方法
機械学習による超解像を紹介する前に、ベースとなる一般的な補間方法について触れておきます。
よく用いられるのは、以下の3種類です。
・Nearest Neighbor(最近傍補間)
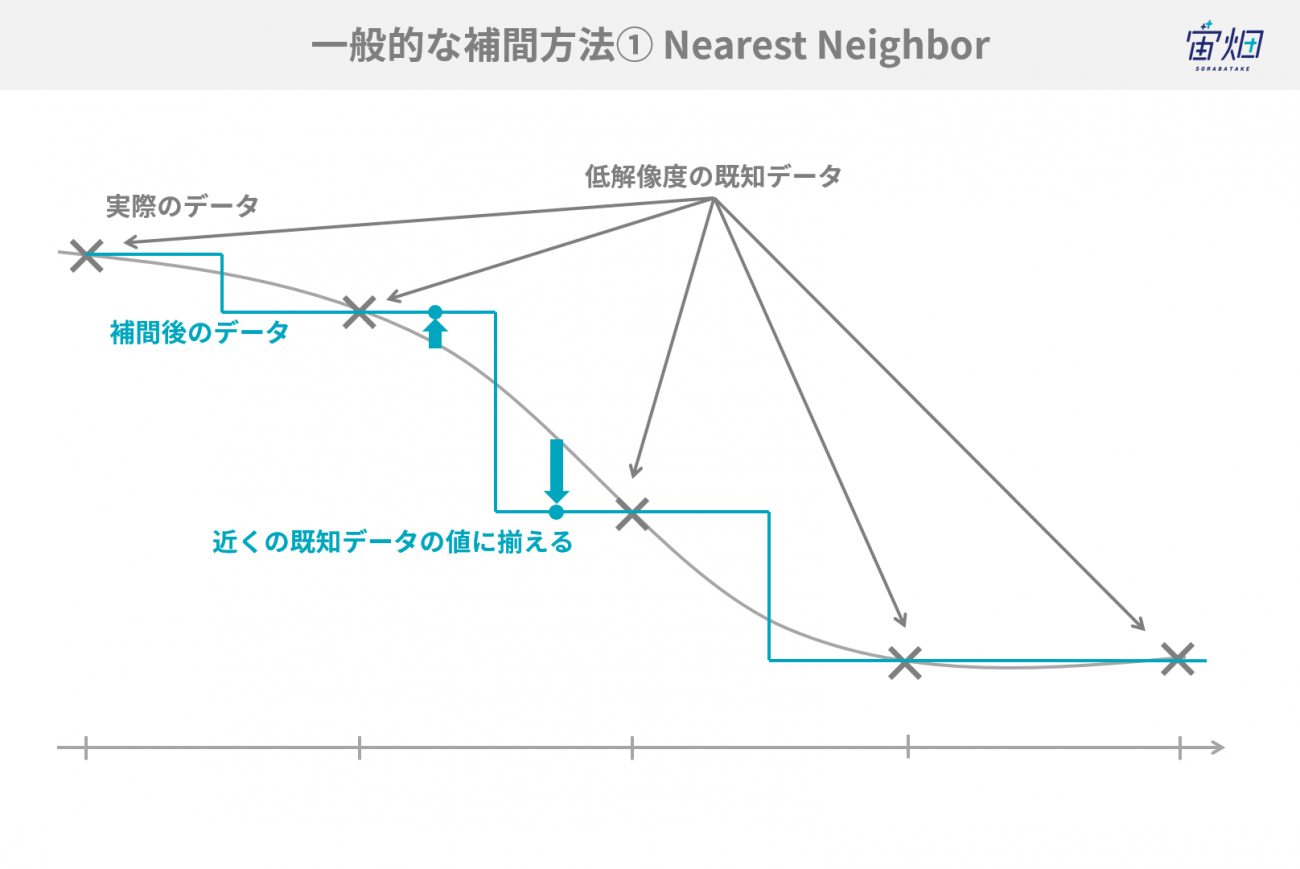
Nearest Neighborは最もシンプルな補間方法で、補間したい点から最も近い点の値を取ってくる方法です。
・Bilinear Interpolation(双一次補間)
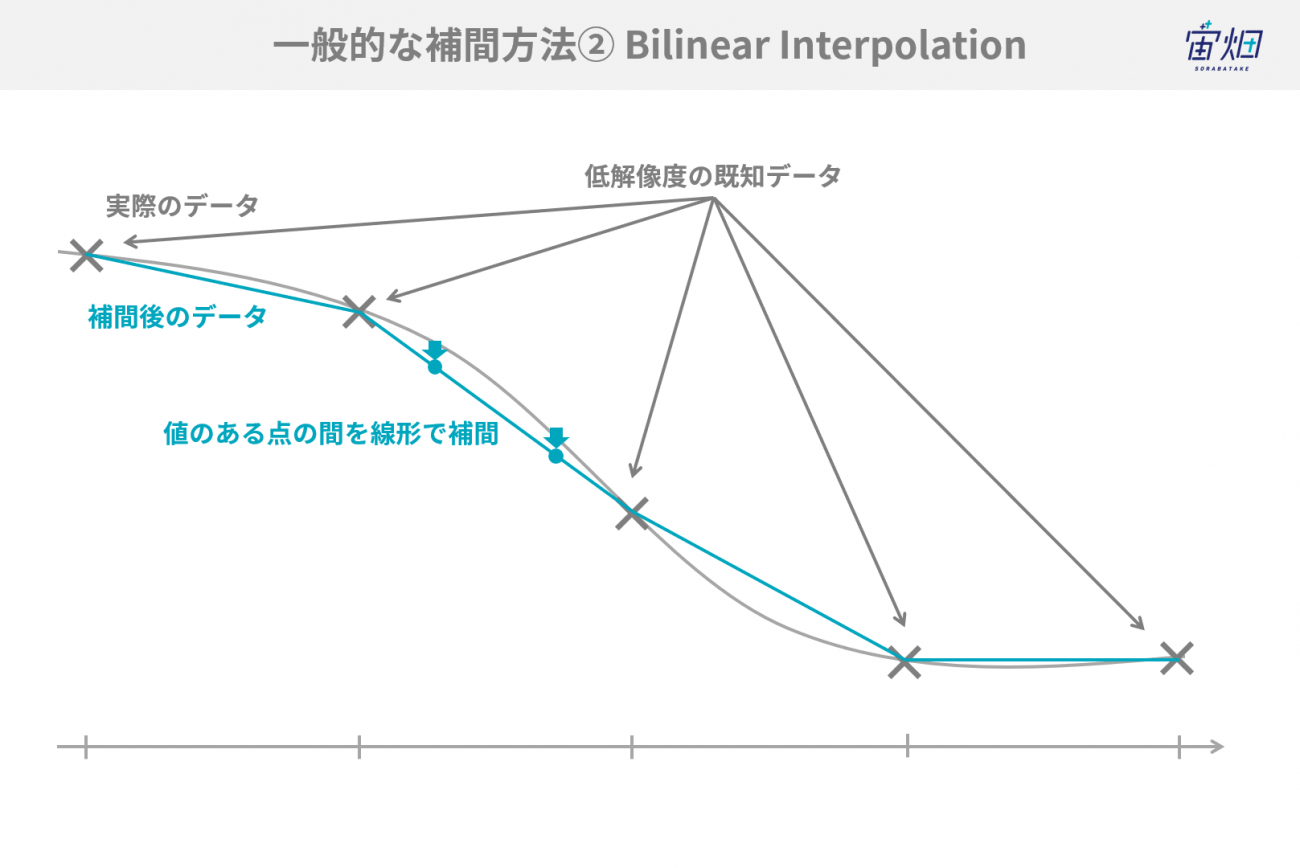
Bilinear Interpolationは、値のある点の間を線形(直線)で補間します。
・Bicubic Interpolation(双三次補間)
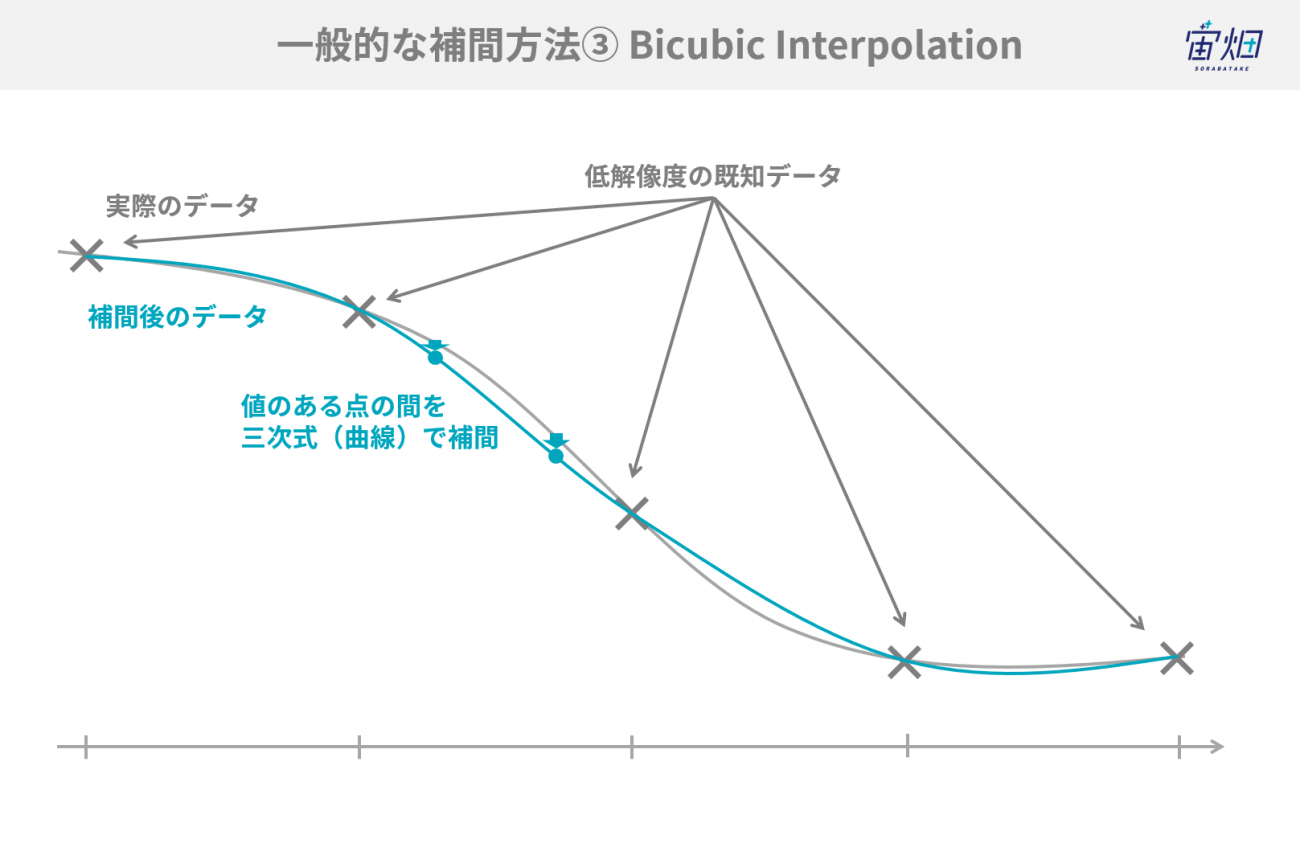
Bicubic Interpolationは値のある点の間を三次式(曲線)で補間します。
Nearest Neighbor、Bilinear Interpolation、Bicubic Interpolationの順に精度は高くなりますが、計算量は多くなるため時間がかかることになり、状況に応じて適切なものが選択されます。
2.3 ニューラルネットワークを用いた超解像「SRCNN」
[SRCNN]
“Image Super-Resolution Using Deep Convolutional Networks”
2014年に初めて畳み込みニューラルネットワーク(CNN)を用いた超解像が発表されました。
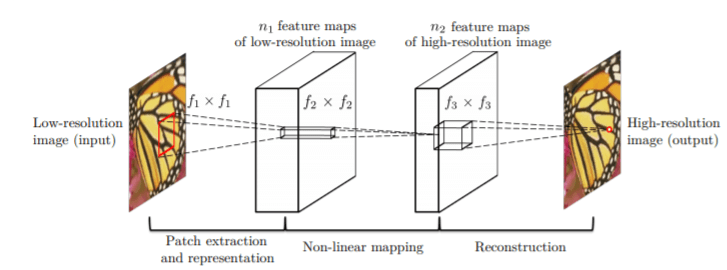
SRCNNというこの手法は、Sparse-coding-based methodという従来の方法をCNNで置き換えたもので、シンプルに3層で構成されます。1層目はパッチの抽出、2層目は非線形マッピング、3層目は再構築となっていますが、そのいずれもCNNで表現できるところが面白いところです。
実験により、少ない画像でも過学習せず性能が出ること、また、層を増やすと収束までに時間がかかり必ずしも性能が良くなるわけではないことを述べています。損失関数としてはMSE(Mean Squared Error 平均二乗誤差)を用いています。
さらに論文では、画像の輝度だけでなくカラー画像のチャンネルを考慮する方法の検討も行っています。カラーの表現方法として、RGBという表現方法と、YCbCr(輝度、青の色差、赤の色差)で表現する方法があり、論文ではどちらも試していますが、RGBの3チャンネルで超解像を行うと精度が向上することを明らかにしています。
2.4 GANを適用した超解像「SRGAN」
[SRResNet][SRGAN]
“Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network”
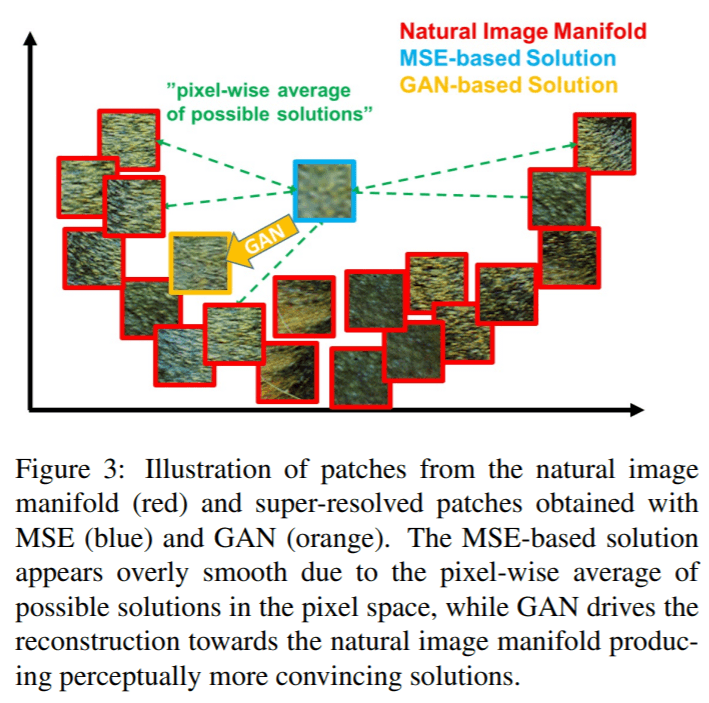
2016年に出されたこの論文では、よく用いられているPSNRやMSEではテクスチャを評価できておらず、人の知覚とズレがある点を指摘しています。MSEは平均的に誤差の小さいものになるのでぼやけた画像になるということです。
この論文では、超解像にGANにを適用しています。
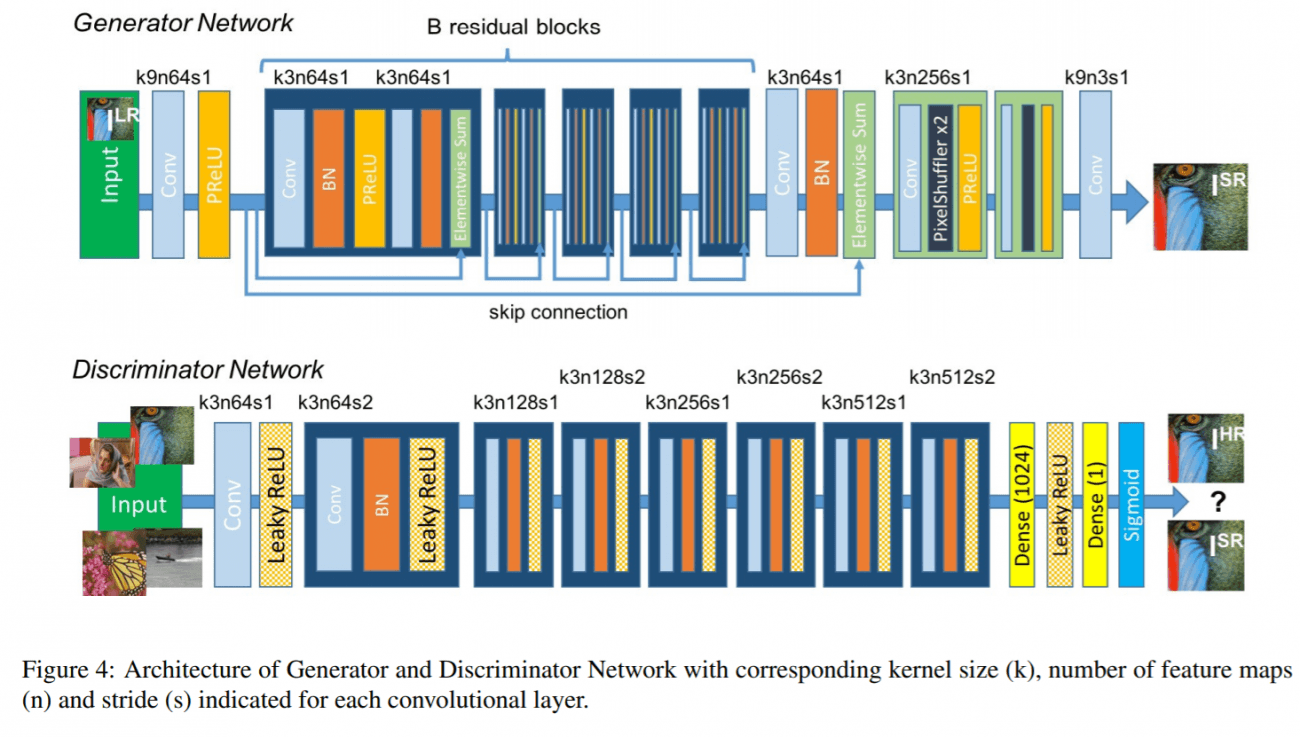
Generatorとして用いるのは、SRResNet(上図上側)で、Discriminatorは上図下側になります。
損失関数としてPerceptual loss function(知覚的損失関数)を定義し、content lossの中で、従来のMSEを用いる方法と、19層のVGGネットワークで事前学習したReLUの活性層がベースになっているVGGを用いる方法を用意し、効果を比較しています。
また、評価方法としてPSNRだけでなく、人の目による評価(Mean Opinion Score(MOS))を導入し、PSNRでは評価できない人の知覚による評価を取り入れています。
広く一般に用いられているPSNRを用いて、SRResNetという深層残余ネットワークを評価し、その性能が良いことを示すとともに、MOSの評価によって、SRGANの性能が高いことを示しています。
3.超解像×衛星画像の論文紹介
簡単に超解像の技術について触れたところで、本題の超解像×衛星画像の論文を読んでいきます。
3.1 教師データが与える影響
On Training Deep Networks For Satellite Image Super-resolution,
1つ目に読んだのは、衛星画像で超解像を行う際に、教師データが与える影響についてまとめた論文です。
この研究では、学習データとしてDIV2Kの一般画像を使ったものと、欧州の衛星で無料で公開されているSentinel-2という衛星の画像の2種類を用いています。
教師データとして低解像度と高解像度の画像を用意する必要がありますが、ここでも以下の2種類を用意します。
①元の画像を高解像度画像とし、デグレードさせて粗くしたものを低解像度画像とする②上述したSentine-2の画像(解像度10m)を低解像画像とし、別のより解像度の良い衛星画像(SPOTやWorldWiew-4という名前の衛星)を高解像度画像とする
①ではさらにデグレードさせる方法として、nearest neighber, bilinear, bicubicとLanczosなど様々な方法を試しています。
一般的な超解像の論文では主に①の方法で超解像のアプローチが研究されていますが、衛星画像で超解像を行う場合、元の画像よりも詳細に見えるようにする事が目的のため、自身の画像をデグレードして低解像度画像を設定する①のアプローチではあまり意味がありません。
②で述べたように、高解像度側の画像として、他の衛星の画像を用いなければならないことは、衛星画像を超解像する上での1つの特徴と言えるでしょう。
論文の中でモデルとして用いられているのは、FSRCNNとSRResNetの2つです。
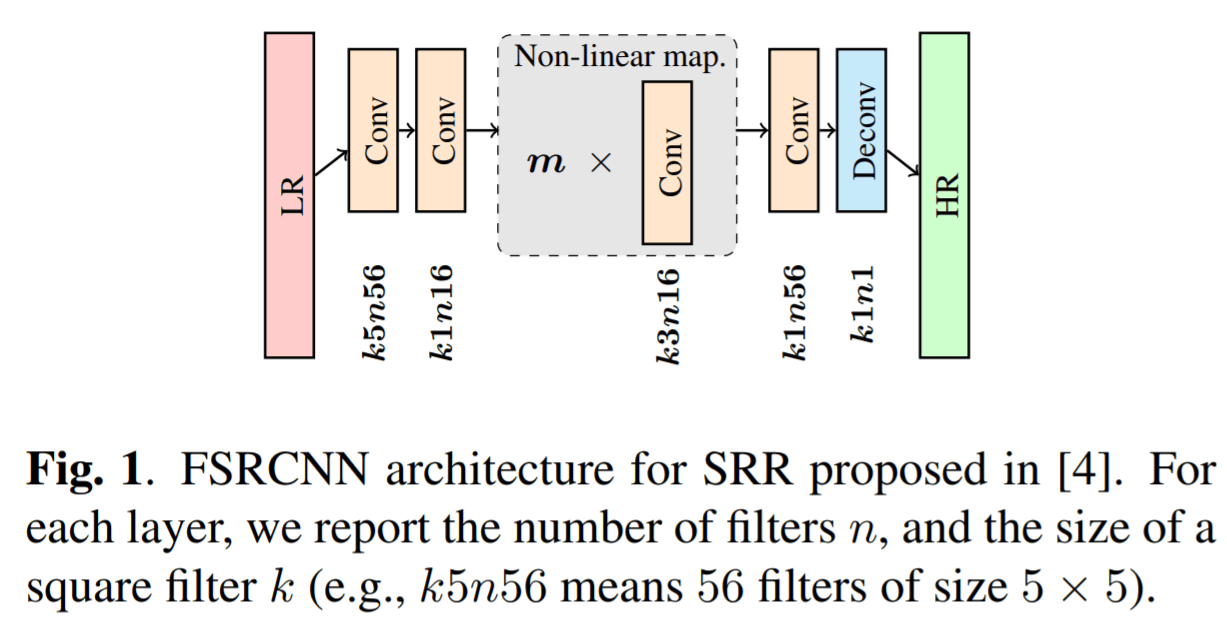
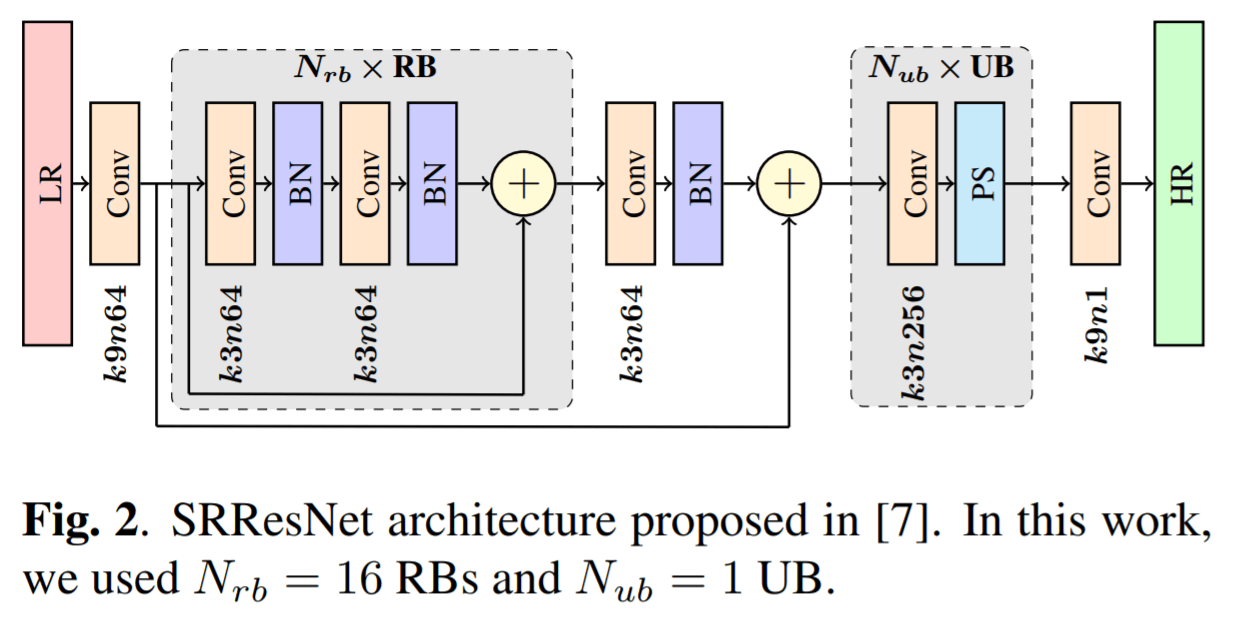
実験結果として、まず学習データについていうと、DIV2Kの一般画像のみで学習させた場合よりも、衛星画像で学習させたものの方が良い結果になることが分かりました。
また、①の元の画像をデグレードさせて超解像を行う実験では、デグレードの手法して、Nearest Neighborが最も良い性能を示す結果となりました。
さらに、①の元の画像をデグレードさせる超解像と②異なる衛星画像間の超解像では、やはり②の方が性能は悪く、一般画像での学習と衛星画像での画像の優劣は分からないという結果となっています。
モデルとしては、FSRCNNとSRResNetの2種類が用いられましたが、適切な教師データを用いれば、層の深いSRResNetが比較的シンプルなFSRCNNと比較して一概に良いとは言えない結果となっています。
3.2 衛星画像毎に適切なモデルを選択する
深層学習を用いた衛星画像の超解像手法、川嶋一誠、中村良介、2018、RSSJ
続いて、ご紹介するのは日本の研究者の論文です。
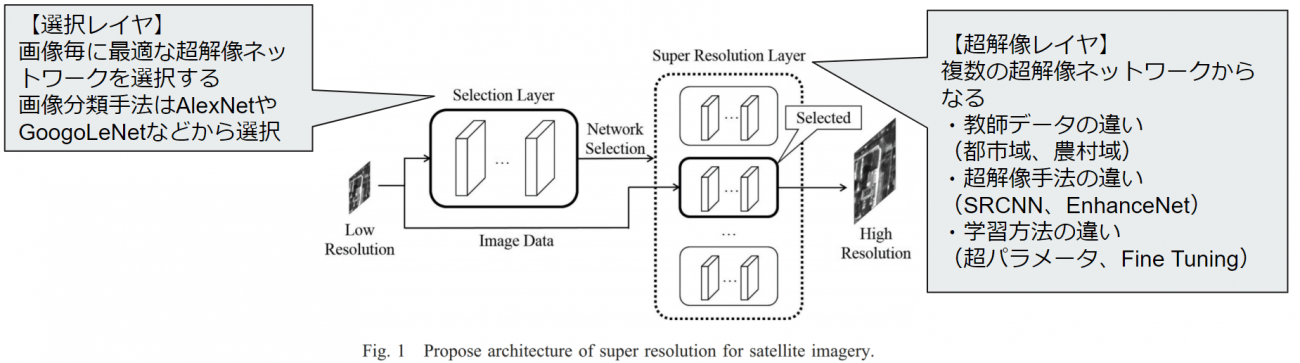
この論文では、1つ前でご紹介した論文から衛星画像の複雑さや多様さに配慮することが重要であるとし、異なる地物のそれぞれに最適化された複数の超解像ネットワークを画像毎に選択することを提案しています。
まず、衛星画像に対する超解像技術の特徴評価を行っており、以下の3点について言及しています。
・自然画像で学習したネットワークは良い結果が得られていない
・都市域の評価は都市域で学習したネットワークが良い
→複雑な領域は同種の複雑な地形で学習した方が良い。
・農村域の評価は都市域/農村域いずれのでも良い結果
→田畑の直線的な形状は複雑さが低いため、より複雑な都市域の教師データを用いた場合でも同等の結果がでる。
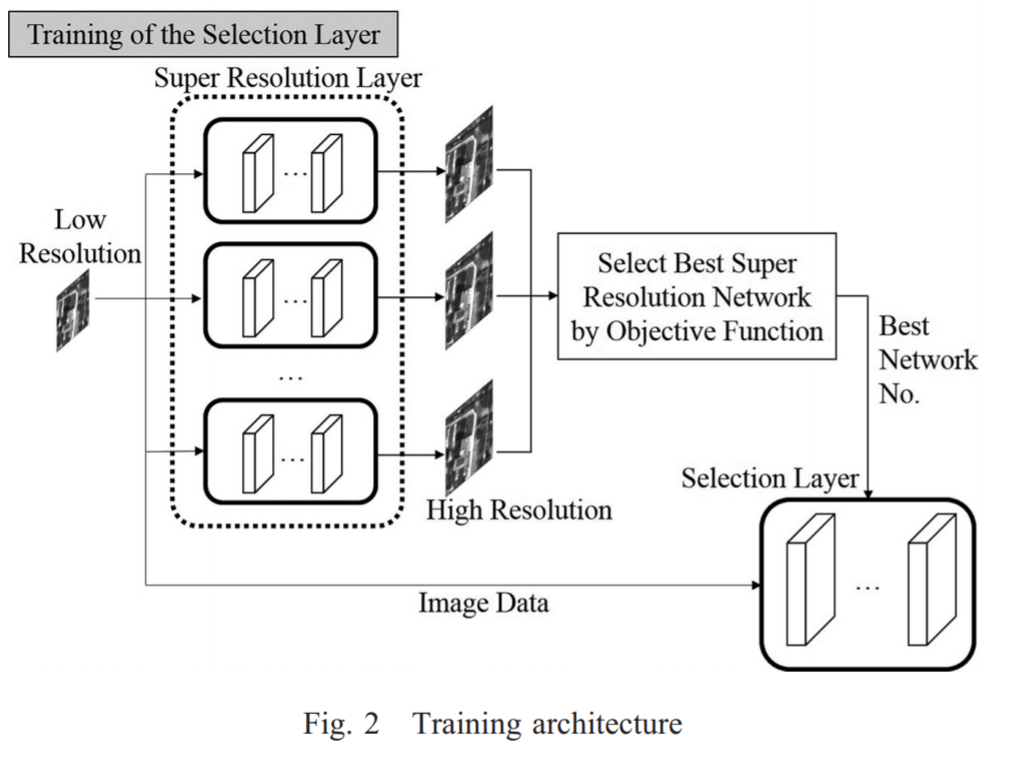
複数の超解像ネットワークから最適なネットワークを選択する選択レイヤの学習について、各超解像ネットワークによる超解像実施後の画像に対し、評価指標をもとに決定した最良のネットワークを入力画像の正解ラベルとして学習することを行っています。
提案手法で超解像を行った結果、都市域の画像では、単一の超解像ネットワークの方が良い結果になりましたが、農村域では提案手法の方が良い結果になったことが分かっています。
4.Tellusで衛星画像の超解像をやってみるには
ここまで、超解像についての論文と、衛星画像に適用させる論文についてご紹介しました。衛星画像に超解像を適用するのはここ数年で始まっったばかりで、まだまだ分からないことも多い分野です。
もし、興味を持っていただけた方がいらっしゃいましたら、衛星データプラットフォームTellusでぜひお試しください。
衛星データプラットフォームTellus(テルース)
https://www.tellusxdp.com/
4.1開発環境申し込む
Tellusでは、衛星画像だけでなく開発環境も提供しています。
https://www.tellusxdp.com/ja/developer/
現在提供しているのは以下の3種類です。

現在は無料で提供しており、ユーザー登録後ダッシュボードから申込めるようになっています。
※GPUは台数に限りがありすぐに提供できない場合もあります。
4.2 超解像サンプルコード(SRGANをpytorchで実装してみた)
Tellusのコードではありませんが、超解像のサンプルコードという意味では以下が参考になるかもしれません。
SRGANをpytorchで実装してみた
https://qiita.com/pacifinapacific/items/ec338a500015ae8c33fe
衛星画像を用いた超解像にぜひチャレンジしてみてください。
SRCNNを用いてTellus上でチャレンジしてみた結果は、以下の記事で紹介しています。
