Kaggleランカーの7人に聞いた、2021年面白かったコンペ7選と論文7選
7名のKagglerの方にアンケートにご協力いただき、2021年に面白かったコンペと論文を教えていただきましたのでその結果を紹介します。
2022年8月31日以降、Tellus OSでのデータの閲覧方法など使い方が一部変更になっております。新しいTellus OSの基本操作は以下のリンクをご参照ください。
https://www.tellusxdp.com/ja/howtouse/tellus_os/start_tellus_os.html
2021年も数多くのデータ解析コンペが開催され、興味深い論文が多く発表されました。
毎年Kaggle等のデータサイエンスコンペティションに取り組んでおられる人達にアンケートを実施し、その年の記事をまとめてきました。
Kaggle上位ランカーの5人に聞いた、2019年面白かったコンペ12選と論文7選
Kaggleランカーの9人に聞いた、2020年面白かったコンペ9選と論文9選
そして本年も7名のKagglerの方にアンケートにご協力いただき、2021年に面白かったコンペと論文を教えていただきましたのでその結果を紹介します。
(1)回答いただいたKaggler7名のご紹介
まずは今回のアンケートに回答いただいたのは以下7名のKagglerの方です。
(@aryyyyy221)
(@currypurin)
(@Maxwell_110)
(@Oregin2)
(@regonn_haizine)
(@SiNpcw)
(@tereka114)
※Twitterアカウント、アルファベット順
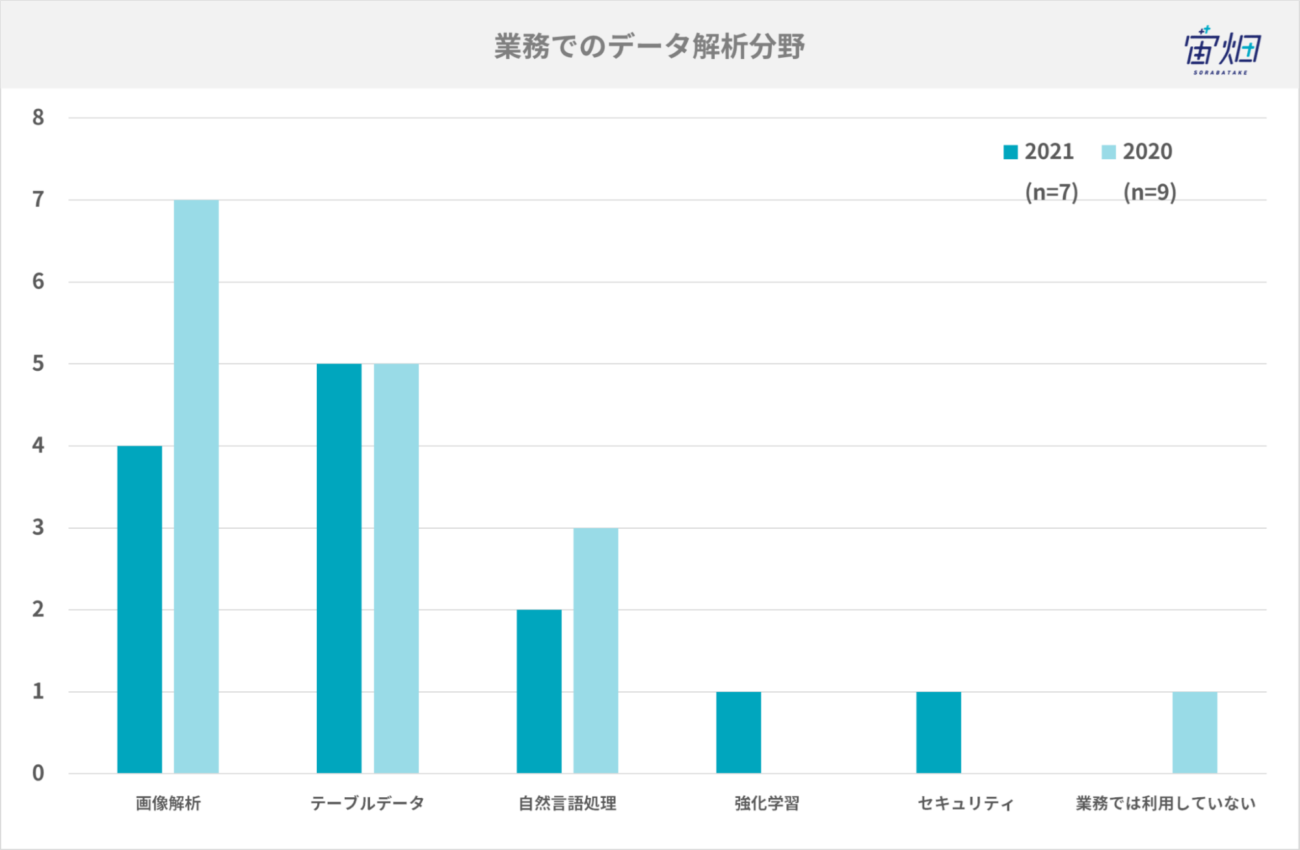
業務でのデータ解析分野
普段業務で利用しているデータ解析分野は、以下の通りです。去年は画像解析業務の方が多くいましたが、年々分野の広がりを感じます。
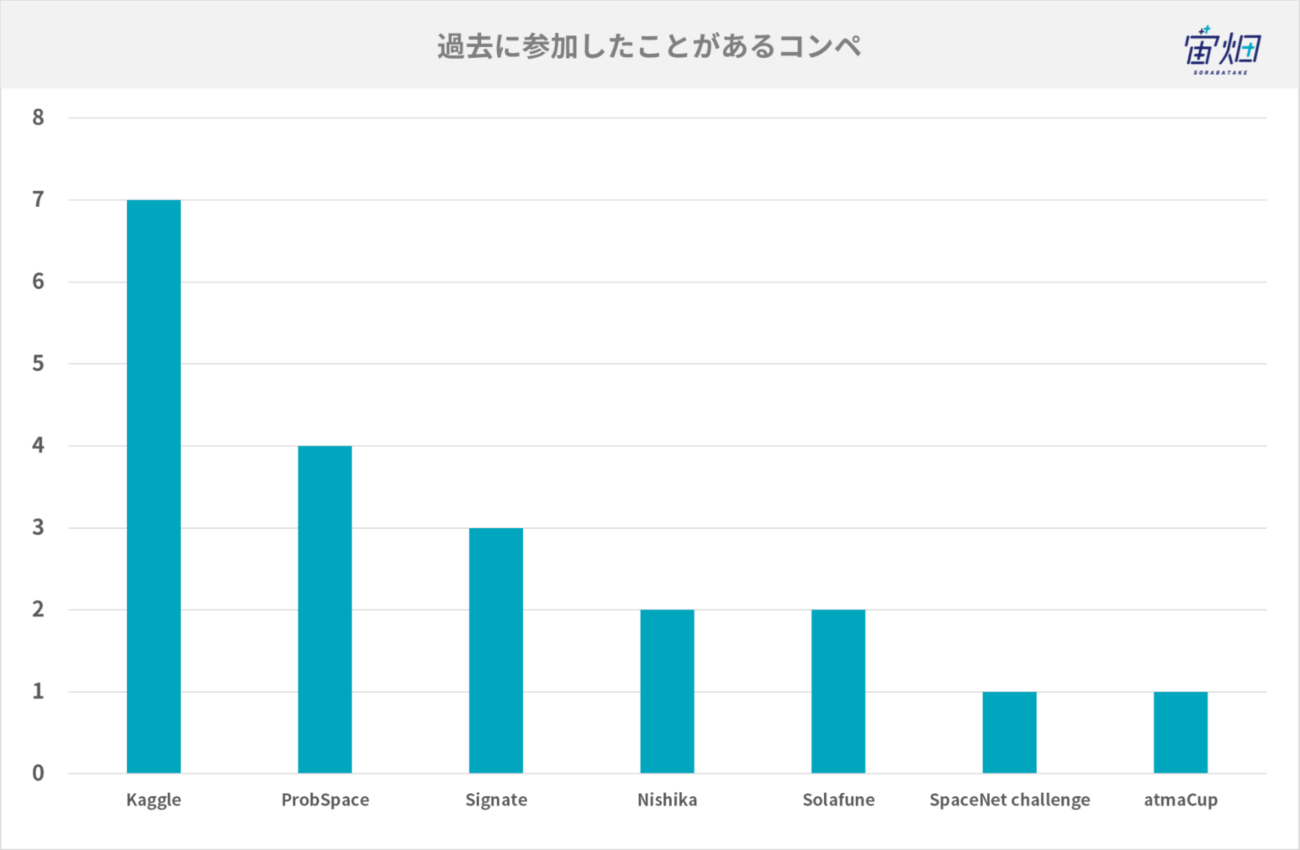
過去に参加したことがあるコンペ・コンペに参加する理由
過去に参加したことがあるコンペは以下の通りです。やはりKaggleが最も多く、次いでProbSpace、SIGNATEといった国内のコンペティションに参加されている方が多いようです。
続いて、コンペに参加している理由を伺ったところ、以下のような理由を回答いただきました。
・自身が身につけた知識やスキルの確認と、実装スキルの向上のため
・楽しいから
・最新技術のキャッチアップ
・技術獲得のため
・普段業務で扱うデータがテーブルデータ他のデータ(画像など)にも触れておくため
・最新の技術を応用実験する場
・コンペが楽く、また楽しみながらデータ分析を学ぶことができるので参加しています!
・業務で利用できる知識の幅を広げるため
7名がコンペに参加する理由として目立ったのは「楽しいから」「知見を増やす・スキルアップのため」という理由です。
では、実際にどのようなコンペや論文を2021年は面白い、興味深いと思われたのか、回答者のお一人でもある@regonn_haizineさんに解説いただきながら紹介します。
(2)2021年、面白かったコンペ
2021年は前回の記事(2020年)のように、画像解析部門などに分けるのは難しく、複数の種類のデータを扱う複合的なコンペティションが増えてきています。また、2021年は金融や強化学習のコンペティションも増えてきました。
次の一投の行方を予測! プロ野球データ分析チャレンジ | PROBSPACE
https://comp.probspace.com/competitions/npb
PROBSPACEで開催された、プロ野球の試合の投球データや試合状況等から、ストライク・アウト・ホームランといった投球結果を予測するコンペティションでした。特に野球は他のスポーツと異なり投球毎に結果を確認しやすいため、データ分析とは相性がよく他のコンペティションサイトでも題材にされていたりします。
コメント@Oregin2
プロ野球選手の実名データを扱っており、実際の状況を想像しながら取り組めたこと。また、野球は、スポーツの中でも戦略やゲーム性の高いスポーツなので、分析が実際に使われて、機械学習も応用されていくのではないかと思われること。
NFL Health & Safety - Helmet Assignment | Kaggle
https://www.kaggle.com/c/nfl-health-and-safety-helmet-assignment
スポーツ系のコンペティションが続き、こちらは毎年Kaggleで開催されている NFL(The National Football League) のコンペティションです。毎回題材が変わり、今回は映像データからIDの振られた選手のヘルメットを検出し、トラッキングを行うことでした。
選手がつけているウェアラブル端末の位置情報などCSVも含めた、テーブルデータと映像データの複合したデータを利用するコンペティションでした。
コメント@aryyyyy221
・色々な解法が存在しうる
・データが豊富
・データが面白い
・適度に難しい
・ホストの対応が最高などなど、色々な要素が重なった良コンペだったと思います。前回のNFLも良コンペだったので、次のNFLも期待してます
Shopee - Price Match Guarantee | Kaggle
https://www.kaggle.com/c/shopee-product-matching
ECプラットフォームであるShopeeが開催したコンペティションで、ユーザが投稿した画像とテキスト情報から類似した商品を検索するという課題でした。こちらは、画像と自然言語処理が必要なコンペティションでした。
コメント@tereka114
汎用的に利用できるECサイトのデータ分析であり、マルチモーダルのデータを扱えるものであったため。
G2Net Gravitational Wave Detection | Kaggle
https://www.kaggle.com/c/g2net-gravitational-wave-detection
世界に3つある重力波検出器の観測をシミュレートし、重力波が含まれているかどうかを判定する二値分類のコンペティションでした。コメントにもある通り、音声や信号のセンサデータは一度変換を行い時系列での周波数帯を画像にして解析する手法が用いられることが多いですが、今回の上位チームの手法は違ったようです。
コメント@SiNpcw
これまで音声や信号といったセンサデータの処理はスペクトログラム画像化などを行い、2D-CNNで処理すればよいという頭で凝り固まっていた。しかし、解法としてはその考えを覆す結果となった。Discussionなどでも挙げられたが多くの上位チームに1D-CNNを採用しており、また1D-CNN、 2D-CNNのアンサンブルがより大きな効果を発揮していた。結果として2D-CNNだけでも十分に精度を得る方法が存在していたようであるが、1D-CNNで取り扱うこと、入力データを複数の系統で用いられないかを検討することが重要と認識できた。
Hungry Geese | Kaggle
https://www.kaggle.com/c/hungry-geese
Kaggleでは2020年から強化学習系のコンペティションも開催され、今年はこの Hungry Geese と じゃんけん、Lux AI が強化学習コンペティションとして開催されました。強化学習系のコンペティションではランキングが近いモデル同士で対戦して評価値が更新されていくので、最後までランキングが更新されていくため面白いです。
Hungry Geese ではスネークゲームのように、アイテムを取得して、自分の体を伸ばしていき、自分や相手にぶつからないように生き残っていくルールでした。
コメント@currypurin
ヘビゲームを基にした4チーム対戦のゲームの強化学習で、ルールは簡単だけれど、奥の深いゲームで、はじめて深層強化学習に取り組み、また上位に食い込むことができたので面白かった。
コメント@Maxwell_110
これまで私が Kaggle で参加してきたコンペのタスクは、基本的には与えられた定常的なデータに対して予測をするという枠に収まっていたものでした。一方で、今回参加した強化学習のコンペは、状況(対戦相手や周囲環境)が自身の行動に応じて変化し、逐次的に自分がとるべき最適な行動を予測できるようにモデル(agent)を学習させなければいけないというものでした。強化学習なのでそれは当たり前といえば当たり前なのですが、それでも、これまで参加してきたコンペと大きく異なり新鮮でした。
何よりも印象に残ったのは、LB(Leader Board; 参加したコンペは public と private の区別無)に示される対戦成績による評価(順位)とローカルにおける agent の性能評価との相関をとるのが難しい点でした。
難しさの理由としては、
・Agent を評価するリーグがコンペ参加者の agent 群の性質によって動的に変化する(カードゲームの大会などでよく言われるメタ的な要素がある)
・十分な対戦数を確保するには計算コストがとても大きい(GPU のみならず十分な数の CPU 数が必要)
など、いくつかのポイントが挙げられると思います。
DeepMind のように膨大な計算資源があるわけではありませんので、未だに「こうやれば良いだろう」とあたりさえつけられていない状況です(笑)
Data-Centric AI Competition
https://https-deeplearning-ai.github.io/data-centric-comp/
コメント@regonn_haizine
2021年は「データ中心のAI(DCAI:Data-Centric AI)」という概念が出てきて、Kaggleのような固定のデータセットでモデルを改善し予測精度を競うコンペティションとは異なり、機械学習モデルを固定してデータ側を修正して改善することで予測精度を競う、Data-Centric AI Competitionというコンペティションが開催されました。機械学習というと、モデル構築がメインに思われることも多いですが、実際のビジネスで利用する場合には、データの取得等も大事な要素なので、こういったコンペティションが増えてくるとモデル構築技術以外の能力やノウハウも身につくので良いなと思いました。
(3)2021年、面白かった論文
続いて、2021年面白かった論文についてご紹介していきます。
コンペティションでは色々な分野が選ばれた結果となりましたが、面白かった論文では全て画像解析に関連した論文が選ばれました。VisionTransformer 等のモデルが出てきて、分野としての注目度も高いのかもしれません。
[2107.10833] Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data
https://arxiv.org/abs/2107.10833
超解像化に関する論文です。2021年には、衛星データ専門のコンペティションサイトの Solafune でも 市街地画像の超解像化コンペティション が開催されるなど、衛星データ界隈においても重要な技術です。
コメント@Oregin2
画像の低解像度から高解像度に変換する超解像化に関する技術で、通信速度が遅い回線でも、受信側でこの技術を用いることで、高解像化された画像を閲覧するなど、応用の幅が大きいと思われるため。
[2003.14749] Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks
https://arxiv.org/abs/2003.14749
画像分類タスクにおけるテストデータのラベルミスに着目して、精度等にどのように影響してしまうかを調査した論文です。
コメント @regonn_haizine
Data-Centric AIと関連して、モデルの精度を上げるためには、そのままデータセットを使うのではなくデータの質も考慮しないといけないのは、実際の機械学習の業務でも求められる内容なので、ちゃんと考えておきたいです。
コメント @aryyyyy221
テストの問題って結構根深いものがあると前々から思っていて、例えば多くの画像認識モデルが多かれ少なかれImageNetにoverfitしやすい状況にあるなあと。ラベルノイズも含め、色々な課題がある分野だと思うので、いつか機会があったら真剣に考えてみたいです。
Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows
VisionTransformer等のクラス分類に特化したモデルに存在していた課題を階層的な特徴抽出や shifted window という手法を用いることで、オブジェクト検出やセグメンテーションといった汎用的なタスクに利用できるようにしたモデルについての論文です。
コメント@tereka114
Transformerを利用して成果を上げてきた論文の一つで、Classification/Detection/SegmentationのBackboneに利用されている。
Emerging Properties in Self-Supervised Vision Transformers
https://arxiv.org/abs/2104.14294
Facebook AI Researchの研究者らによって提案された自己教師あり学習画像モデルDINOについての論文です。画像データセットに用意されている正解ラベル情報を利用しなくても、学習を行い物体認識タスクなどができるようになり、特に画像モデル部分にVision Transformer を用いると、セグメンテーションのような情報も取得できるようになるようです。
コメント@SiNpcw
一般にTransformerには巨大なデータを用いた事前学習が大切とされているため、モデルのパラメータを壊すこと、例えばレイヤーを変えるなどがやりにくい。それを自己教師あり学習によって影響を低減・回避できるのであれば様々な場面での適用や応用がし易くなると考えている。またDINO自体も比較的シンプルな手法で実現されており、自己教師あり学習の分野の展望としても期待できる。
MRI-Based Deep-Learning Method for Determining Glioma MGMT Promoter Methylation Status
http://www.ajnr.org/content/42/5/845.long
MRI 画像解析の精度を上げることができた手法について書かれている論文です。2021年は Kaggleでも多くの医療系(画像・テーブルデータ)コンペティションが開催されました。
コメント@Maxwell_110
昨年とは違い、今年は異なった目線で回答したいと思います。ご紹介した論文は、Kaggle で北米放射線学会が開催した RSNA-MICCAI Brain Tumor Radiogenomic Classification(https://www.kaggle.com/c/rsna-miccai-brain-tumor-radiogenomic-classification/overview)というコンペティションのテーマに関連したものです。
興味深かった点は、論文とコンペはほぼ似たようなデータセットとターゲット(MRI 画像をもとに、脳の MGMT promoter methylation という組織部位の有無を二値分類する)を前提としているにも関わらず、論文内で主張されているような精度がコンペでは全くでなかった点です。論文で報告されている AUC は 0.90前後でしたが、Kaggle の参加者の AUC は 0.60前後(1st place でも 0.62 程度; https://www.kaggle.com/c/rsna-miccai-brain-tumor-radiogenomic-classification/leaderboard)と大きくかけ離れていました。私も論文とほぼ同じ手法をローカルで実装して実験していたのですが、やはり 0.60 程度の AUC でした。
もちろん、論文には明記されていないようなデータセットの性質やラベリング条件、何か見落としがある、等の原因でこういった事になっている可能性はあるとは思います。
Kaggle に参加していると、論文の再現実験をしているような状況になることがたまにあるのですが、論文とコンペでここまで結果が大きく異なったのは初めてで、とても印象に残りました。皆さんも「SOTA と論文で主張されているので期待して実装したら、既存手法に全然及ばなかった!」なんていうシチュエーションに遭遇されたことがあるのではないでしょうか。
(Reference in discussion of Kaggle competition: https://www.kaggle.com/c/rsna-miccai-brain-tumor-radiogenomic-classification/discussion/266173#1503997)
[2102.12092] Zero-Shot Text-to-Image Generation
https://arxiv.org/abs/2102.12092
ニュースなどでも一時期取り上げられ話題になった、テキスト情報から画像を生成するモデルを作成した論文です。120億個のパラメータや2億5千万の画像キャプションデータといった巨大なデータを学習するためのテクニック等も紹介されています。
コメント@currypurin
テキストで作りたい画像の内容を入力すると、その画像を生成することができるという論文ですが、「アボカドの形をしたアームチェア」というような、この世に存在するかわからないような物体であっても生成することができ、今後のAIの可能性が広がったようで面白いと思いました。
(4)今後のデータ解析コンペや技術への期待と目標
最後にKagglerの皆様に今後のコンペや技術への期待や目標をお伺いしました。
今後どのようなコンペがあると面白いと思いますか?
・強化学習を用いたロボットコンテスト。
・とにかく難しいの希望です。知恵を絞った人が勝つやつ。
・問題設定が面白いものだと嬉しいです。
・マルチモダリティのあるコンペティションやアクティブラーニングのような枠組みのコンペティション。
・Kaggle に限ってお話をさせていただきますと、モデルの学習にも一定のリソース制限があるようなコンペが開催されると良いなと思っています。例えば、学習用のデータが iteration を回すにつれ少しずつ追加されていき、そのデータを使いモデルを学習・アップデートしていくような、オンライン学習的なコンペなどは面白いのではないかと思っています。
・前処理から学習も含めて同じ環境でしないといけないような、参加者間の条件が公平であるコンペが増えると面白いと思います。
・ブロックチェーンに関するデータ分析。現在も価格予想等は行われているが、他にもどれだけ取引が行われているかなど公開されている情報なので、そこから新しい価値を作り出すことも色々とできそう。
傾向としては、難しく複合的なコンペティションが求められる一方、分析環境のリソース(GPU等)で差がついてしまわないように、リソース制限等で条件が揃えられているコンペティションが求められているようです。
今後どのような技術が生まれると面白いと思いますか?
・セキュリティ分野では、攻撃側が圧倒的に有利になるため、このアンバランスを解消するための機械学習を応用した技術。
・MLP Mixerをkaggleで使うのを楽しみにしてます。
・Transformer + CNN + MLPの画像認識モデル。
・マルチモーダル化された技術、強化学習の発展。例えばOpenAI CLIPのような画像と自然言語を組み合わせた技術なども生まれており、今後も複数のモダリティを組み合わせた解析技術が生まれるのではないかと思う。またゲームでの限定的環境ではあるがグランツーリスモ・ソフィーなどが強化学習を用いて開発されており、自動運転などにも生かせるような技術として実現されるのではないかと考えている。
・今年の機械学習トレンドの一つとされているマルチモーダルなモデルに着目しています。自然言語と画像は最もよくあるモーダリティの組み合わせですが、人間の五感全てをもつようなモデルがでてくると面白いかもしれません(嗅覚・味覚の数値化は大変そうですが・・・)。少し妄想しすぎですかね(笑)
・現在、深層学習にはGPU・TPUでの計算が必要という意味でのボトルネックがありますが、このボトルネックを解消するような技術が生まれると、AIを多くのが人がカスタマイズしたり、使ったりすることができるようになり、多くの人のAIとの付き合い方が変わるので面白いと思います。
・アノテーションの補助ツールやデータの質を自動で高められるツール。
こちらの傾向としても、色々な種類のデータをまとめて扱える技術が求められているようです。
2022年の目標を教えてください
Kaggleでのさらなる飛躍や、そこで得た知見の適用、もっと別の分野への興味を広げている方もいらっしゃいました。
・自身のドメイン知識(セキュリティ)に機械学習を応用することで新しい技術を生み出していきたい。
・自分が勝てなそうなコンペに出る年にしたいです
・面白い問題設定のデータ分析コンペティションへの参加と技術発信の拡大
・自然言語や強化学習など技術として理解が足りていない部分の技術の補強
・ここ最近は、コンペに取り組む時間的余裕がなくなってきてしまっていますが、年に 2 回くらいはなんらかのコンペに参加するようにしたいと思っています。また、テーブルデータ・音声・画像・強化学習と・・・、一通りのコンペに参加してきましたので、次は参加できていなかった自然言語系のコンペに、コンペ仲間と取り組めたら良いなとも思っています。
・Kaggleで金メダルと1位を取りたい。
・衛星データとメタバースの連携。衛星データで獲得した情報で、リアルな世界を作っていきたい。
(5)Kagglerの皆様に聞いた衛星データ使ってやってみたいこと
最後に、本記事を掲載している「宙畑(そらばたけ)」が宇宙ビジネスメディアということで、「衛星データ」についてもお伺いしました。地球規模での課題解決やより衛星データを使いやすくするという視点でコメントをいただきました。
・衛星データを用いた鉄道建設の最適ルート探索
・農耕地の収穫量予想
・「保険・医療と衛星データを掛け合わせた分析に興味があります。保険分野では損保の災害関連で既に色々な試みがなされていると思います。一方で、私が不勉強なだけかもしれませんが「医療 × 衛星」はあまり聞いたことがありません。例えば、COVID-19 のようなパンデミックと関連した形で何か提案できればと思っています。
・衛星データから株価予測に使えるデータ生成までの自動パイプライン構築
(6)2021年に開催された衛星データコンペ
2021年には衛星データ専門のコンペティションサイト Solafune で2つのコンペティションが開催されました。
また、日本人の参加者は少なかったようですが、アメリカのNGA(国家地理空間情報局)が主催の、衛星画像データから建物の高さを推定するコンペティションも開催されていました。
2021年は2020年に比べて、衛星データのコンペティションの数は減ったようにも思えますが、Kaggleや日本のコンペティションサイト以外にも海外にはコンペティションサイトが存在するので、情報が拾えきれていないだけで、もっと多くのコンペティションが開催されているかもしれません。
(7)まとめ
本記事では、Kaggler7名の方にご協力いただき、2021年の面白かった機械学習コンペや論文について、ご紹介をしました。
2021年にはメタバースといった仮想現実世界が話題になり、実際に衛星データが利用されている事例も出てきています。
衛星データには唯一無二の価値がある。メタバース空間のゼロ地点を作るスペースデータ佐藤さんを突き動かす衝動とは
また、コンペティションサイトでは、金融系コンペティションも多く開催されており、衛星データからオルタナティブデータとしての利用価値も高まってくると考えられます。
「オルタナティブデータとしての衛星データ活用の可能性」SPACETIDE 2021 WINTER/Day2 第1部レポート
ご興味を持っていただけた方はぜひご覧いただければと思います。
また、2021年には Tellus は Ver.3.0 が提供開始され、Tellus Satellite Data Travelerといった衛星データ購入の仕組みや、新しいツールも追加されていますので、この記事を読んで衛星データに興味が出てきた方や以前触っていた方も、一度新しくなった Tellus を触ってみてください。
