Kaggle上位ランカーの5人に聞いた、2019年面白かったコンペ12選と論文7選
2019年も様々なデータサイエンス関連のコンペが実施され、論文が発表されました。その中でも面白かったものはどれか、5人のkagglerの方に直接お伺いしました。
2019年はTellusxSIGNATEで実施された衛星データコンペの解説(第1回・第2回)が、データサイエンティストの方に読んでいただいた宙畑のヒット記事としてランクイン。
では、データサイエンティストの方は他にどのようなコンペや論文に興味を持たれていたのか……と気になった宙畑編集部。
今回、以下5名のKagglerの方に協力いただき、2019年の振り返りとして面白かったコンペと論文、そしてその理由を教えていただきました。
あきやま様(@ak_iyama)
jsato様(@synapse_r)
Hiroki Yamamoto様(@tereka114)
smly様(@smly)
※順不同
※1名、非公表
Kaggleについては「世界的な機械学習プラットフォーム「Kaggle」の概要と衛星データコンペ事例まとめ」でもご紹介しています。
(1)今回のアンケート内容
まず、今回5名のKagglerにお伺いしたのは以下項目。
===
・2019年面白かったデータサイエンスコンペ
a.技術的に面白かったコンペとその理由
b.テーマ設定が面白かったコンペとその理由
c.扱っているデータが面白かったコンペとその理由
・2019年面白かったデータサイエンス関連の論文
a.技術的に面白かった論文とその理由
b.テーマ設定が面白かった論文とその理由
c.扱っているデータが面白かった論文とその理由
・今、取り組んでいること、もしくは2020年取り組んでいきたいことを教えてください
・衛星データを使ってやってみたいことがあれば教えてください
===
以上、大きく分けて4つの質問にご回答いただきました。最後の質問は宙畑都合の任意回答とさせていただいておりましたが、回答いただきありがたい気持ちでいっぱいです。
それでは、ご回答いただいた内容をひとつひとつ見ていきましょう。
(2)2019年面白かったデータサイエンスコンペは?
a.技術的に面白かったコンペとその理由
【コメント】
単純な分類問題ではなく、個体推定の問題でした。そのため、通常のPretrain+学習のみならず、ArcFace、CosFace、TripletLossなど様々な手法を試すことができ、新しい知見を獲得できた。
コンペ2:NFLプレイヤーのデータを元に、プレイヤー別に何ヤード進められるかを予測する
【コメント】※2名の方が面白かったコンペと回答
・テーブルデータでありながら、ディープラーニングで処理をしているチームが上位に多くいたため。選手間の相対関係を、畳み込みによって表現を得ることで手作業での特徴エンジニアリング以上の性能を発揮しているように感じた。
・ニューラルネットワークのモデリング力が活かせるコンペティションだったため。
コンペ3:データセットの中から指定したランドーマークが入っている画像を分類する
【コメント】
画像検索は研究として大きく成長している過程にあるため。昨年の同じコンテストの優勝アルゴリズムから大幅に性能を改善しました。また近傍探索や距離空間、グラフ探索など構成要素が比較的多いため学ぶことが多い。
コンペ4:音声認識を行い、自動でタグをつけるアルゴリズムの構築
【コメント】
cleanなデータとnoisyなデータの取り扱いが大きくスコアに影響したから。
b.テーマ設定が面白かったコンペとその理由
【コメント】
都合で参加できませんでしたが、Kaggle内でGANの利用&Kernelは初めて。
そのため、この手のコンペを深めていくと、非常に面白い形式のコンペができるため。
コンペ2:土地・建物の特性、周辺環境等のデータから、土地・建物を合わせた販売価格を予測する
【コメント】
当時家探しをしていた関係でもともと不動産に興味があり、コンペを進めているうちに不動産価格の決定に重要な要素を知ることができたため。評価指標がパーセント誤差だった点も実用的で面白いと感じた。
コンペ3:昔の日本語(くずし字)を、現代の日本語として認識するアルゴリズム構築
【コメント】
人文学という普段はあまり接点のない分野であり、かつ社会的に意義のあるテーマであるため。
コンペ4:NFLプレイヤーのデータを元に、プレイヤー別に何ヤード進められるかを予測する
【コメント】
細胞や化学を題材にしたコンペティションに比べて、スポーツなので馴染みやすかったため。
【コメント】
過学習待ったなし。trainingデータが極端に少ない状況で予測モデルの精度を競っていたから。
c.扱っているデータが面白かったコンペとその理由
【コメント】
鉄の欠損推定は実社会(製造業)系で非常に面白いデータセット。推定することで傷がないかを自動推定でき、まさにAIでこの手の点検の問題を解決できそうであったため。
【コメント】
200列以上ある全てのデータが匿名かつ独立かつほぼ同じ形の分布を持つという特殊なデータであったため。仮説をもってデータを検証し考察するというプロセスの組み合わせで知見を蓄積し、精度を上げていく作業はとても楽しかった。(なお、データの意味やコンペの意義等は最後まで不明だった。)
コンペ3:顔や声の特徴から、AIが自動生成したフェイクのビデオを特定する
【コメント】
ディープフェイクは比較的新しい分野であり、多様な手法で生成した動画からデータセットが構成されているため。
コンペ4:NFLプレイヤーのデータを元に、プレイヤー別に何ヤード進められるかを予測する
【コメント】
普段の業務では扱えないデータで、新鮮味があった。
コンペ5:失明になってしまう前に糖尿病性網膜症を検出するアルゴリズム
【コメント】
自分の専門分野である医学において、糖尿病網膜症の画像データセットでこれほど大きなものは珍しかったから。
(3)2019年面白かったデータサイエンス関連の論文は?
a.技術的に面白かった論文とその理由
【概要】
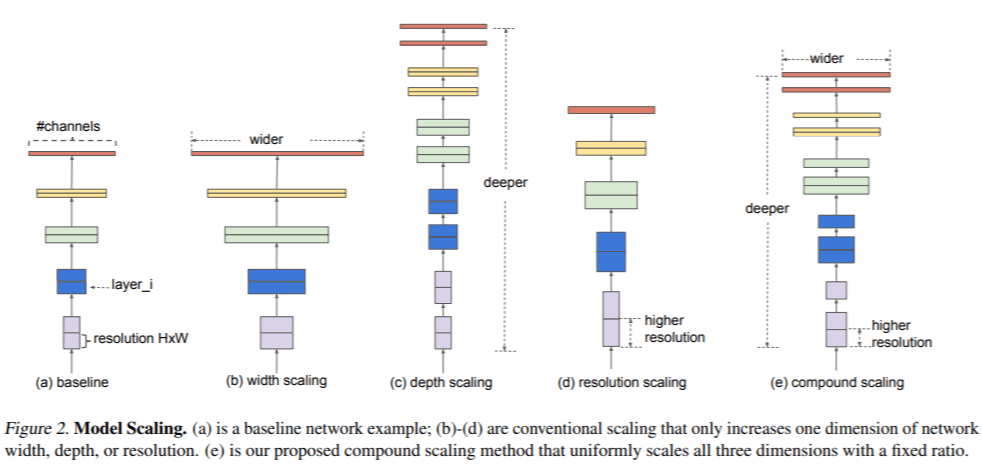
CNN(*1)のスケールアップ(拡張)における複合的なスケーリング手法の提案
【要約】
– 一般的にCNN(*1)はネットワーク内部のレイヤーをスケールアップする事で精度の向上が見込まれる。
– 実際に ResNet(He et al.,2016)は、より多くのレイヤーを使用してResNet-18からResNet-200にスケールアップでき、GPipe(Huang et al.,2018)は、ベースラインモデルを4倍に拡大することにより、ImageNetのトップ1の精度を84.3%達成。
– ただし、CNN(*1)のスケールアップのプロセスはあまり理解されておらず、CNN(*1)のスケールアップ方法は深さ/幅/画像解析度のうち1つだけをスケールアップすることが一般的だった。
– そこで、深さ/幅/画像解析度 全ての次元のバランスを取りつつ一定の比率で(均一に)複合的にスケールアップさせる手法を提案。
– 上記スケールアップ手法を用いる事で、ResNet(He et al.,2016)やGPipe(Huang et al.,2018)よりも使用するパラメータは8.4倍少なく、推論では6.1倍高速になっており、精度の面でもFLOPSでトップ1の精度を76.3%から83.0%(+ 6.7%)に改善。
*1…ConvolutionalNeuralNetwork
【コメント】
EfficientNetは精度と性能のバランスが良いモデル。近年NASを利用したアーキテクチャの設計が増えているが、今年は制約や性能を考慮しつつ精度を向上させたものが増えてきた印象。EfficientNetはそのモデルの中の一つで、今年、様々なコンペティションでよく利用されてきた。
【概要】
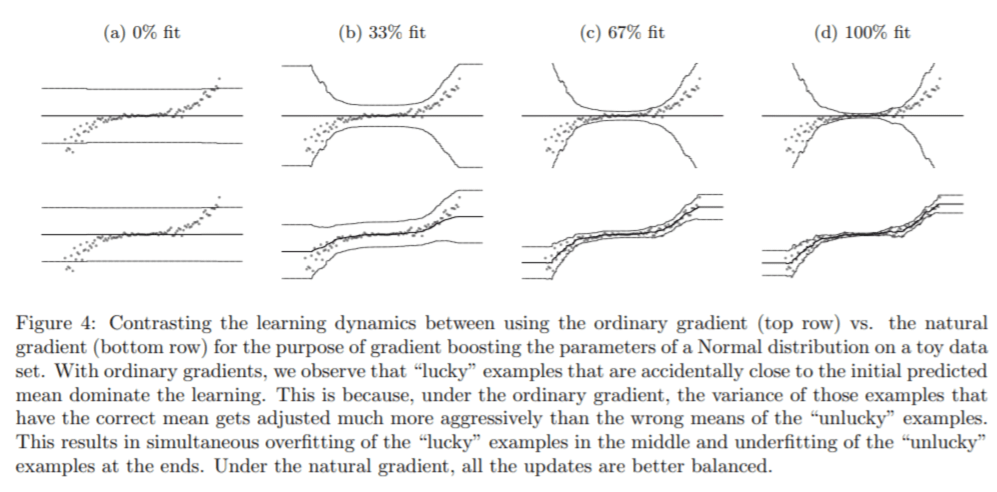
自然勾配法を利用した確率的予測機能の紹介
【要約】
– 教師あり機械学習モデルが適用される問題の多くは、天気予報や臨床予測など、表形式の機能と実際に価値のある教師データがある。
– しかし、機械学習モデルが出力する予測は完全に当たる事はめったにない。
– このような場合、予測の不確実性を推定することが重要になる。
– これまでにブースティングマシンは、構造化データの予測タスクでは様々な予測問題に対して、比較的高い精度を誇っている。
– しかし、出力の確率的予測の為の単純なブ―スティング方法はまだ提案されていない。
– そこで、自然勾配を使用する勾配ブ―スティングアプローチを適用し、一般的に困難な確率的予測を対処する。
【コメント】
確率分布を出力するという技術は、面白い上に実用的であると感じたため。上述の(面白いと思ったコンペで挙げた)アメフトのコンペに取り組む上でも参考になった。
論文3:Guided Similarity Separation for Image Retrieval(画像検索のためのガイド付き類似性分離)
【概要】
GCN(*2)を活用して近隣情報を直接画像記述子にエンコードする手法の提案
*2…Graph Convolution Network

【要約】
– コンピュータビジョンの最近の進歩にもかかわらず、画像検索は今だ未解決な問題が多く残っている。
– 視野角や照明、オクルージョン等のさまざまな要因が、堅牢で効率的なモデルの設計を困難にしている。
– 一般的に、現在の主流なアプローチとして下記の2通りがある。
-①クエリ拡張(QueryExpand)とその変形を行い、記述子を結合し、隣接する画像を形成する方法と②最近傍グラフにランダムウォークを適用し、類似性の伝播/拡散をする方法。
– 上記の2通りの手法は、どちらも手作業でハイパーパラメータの調整をする必要があり、通常学習が行われない。
– そのため、ベースとなる記述子に大きく依存しており、モデルの表現力が制限されてしまっている。
– それらを改善するために、GCNを使用して、近隣情報を画像記述子にエンコードする方法を提案。
– 公開ベンチマークでの実験は、主要なベースラインと比較して最大24%のmAPの改善が見られた。
【コメント】
画像検索における近傍グラフを graph convolution network によってエンコードするアイディアの面白さと、提案手法を最適化する損失関数がよくマッチして面白い。
論文4:ArcFace: Additive Angular Margin Loss for Deep Face Recognition(顔認証へ加算角マージンを適用する)
【概要】
顔認識技術における高度な識別の特徴を得るためにマージン損失の組み込み提案

【要約】
– 顔認識において、DCNN(*3)を利用した顔の埋め込み表現はよく利用されている手法。
– DCNNを利用した顔認識の学習には① softmax損失を利用したマルチクラス分類器の学習と②Triplet損失を利用し、直接的な埋め込み行列の学習の主に2通りあり、それぞれが顔認識で優れたパフォーマンスを得ることが出来ている。
– しかし、softmax損失 / Triplet損失 の利用においてはいくつかの欠点が存在する。
– それらの欠点を解消し、顔認識モデルの識別力をさらに向上させるために、マージン損失の適用を提案。
– マージン損失を適用することで、より直感的な理解/精度向上/簡単な実装/効率的な学習に寄与する。
*3… Deep Convolutional Neural Network
【コメント】
従来まではMetric LearningといえばTriplet LossやContrastive Lossが主流だったが、正規化処理を加えた分類タスクに落として、精度での有効性も示されているため。
Kaggleにおける複数のコンペティションにおいても手法の有効性が示されている。
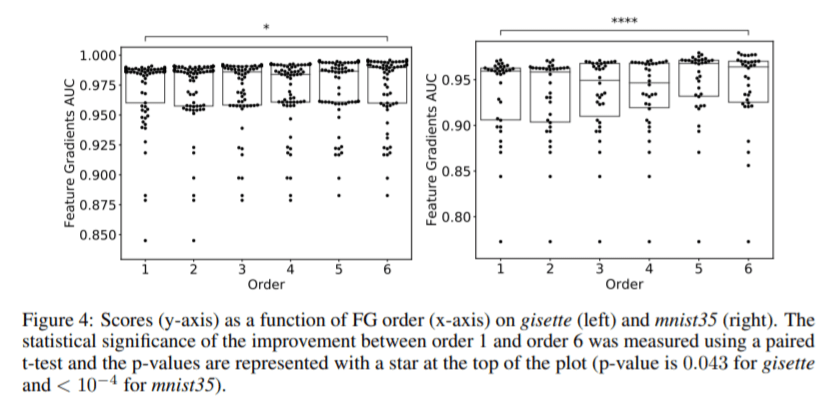
論文5:Feature Gradients: Scalable Feature Selection via Discrete Relaxation(特徴勾配:離散緩和によるスケーラブルな特徴選択)
【概要】
– 特徴量選択のために勾配ベースの検索アルゴリズムである特徴勾配を紹介する
【要約】
– 現在でも教師あり学習における特徴量選択は重要な工程の一つであり、活発に研究が続けられている。
– これまでのアプリケーションでは、利用可能な特徴量が多く、サンプルサイズが比較的小さい設定が考慮されていた。
– その中で重要なこととしては優れた特徴量の組み合わせを選択することにあった。
– いくつかの特徴量選択の方法が提案されてきましたが、計算量の増加や特徴量の相互作用を考慮する原則的な手段がない。
– そこで、サンプルサイズが特徴量のサイズよりも小さい設定で、ターゲットに対して相関の高い特徴の組み合わせを効率的に見つけ出す手法を紹介。
– これにより、計算の複雑さ/高い統計効率/高次の相互作用の効率的な検出 の実現が出来る。
【コメント】
Learnabilityの推定によってバイオ分野のマイクロアレイデータやインターネット広告分野のAd Clickデータといった大きく性質の異なるデータに適用可能である点。
b.テーマ設定が面白かった論文とその理由
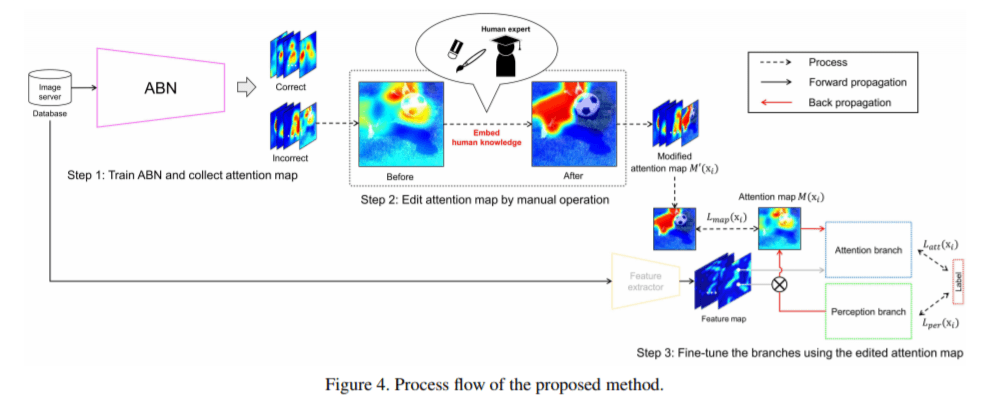
【概要】
– 人間の知識(アテンションマップ)をDNN(*4)に埋め込み分類パフォーマンスを改善する取り組みについて
*4… Deep Neural Network
【要約】
– 視覚的説明は画像分類ディープラーニングに使用される識別領域を強調するアテンションマップを視覚化して意思決定の分析を行うことで、CNNの意思決定がより明確になっている。
– ただし、認識結果のターゲット領域、つまりグラウンドトゥルース(GT)と注意領域との間に矛盾が発生する場合がある。
– また、人間の知識を深層学習モデルに埋め込む方法は広く提案されているが、従来の方法は、比較的小さな機械学習モデルに基づいている。
– そのため、モデルパラメーターの数が膨大な、人間の知識をディープラーニングモデルに組み込むことは困難。
– 人間の知識を組み込んだ編集されたアテンションマップを学習することで、より解釈可能なアテンションマップを取得し、認識パフォーマンスを向上させる事を目指す。
【コメント】
人の知識をAttention Mapに反映させることでCNNモデル自体の精度もあげるという、人と機械学習モデルのハイブリット化に取り組んだ点
c.扱っているデータが面白かった論文とその理由
論文1:Urban Semantic 3D Reconstruction from Multiview Satellite Imagery(多視点衛星画像からの都市情報の3D再構成)
【概要】
– セグメンテーション手法と正規化された3D表面抽出に焦点を当て、低ポリゴンのテクスチャメッシュモデルを推定するためのエンドツーエンドシステムを試してみる
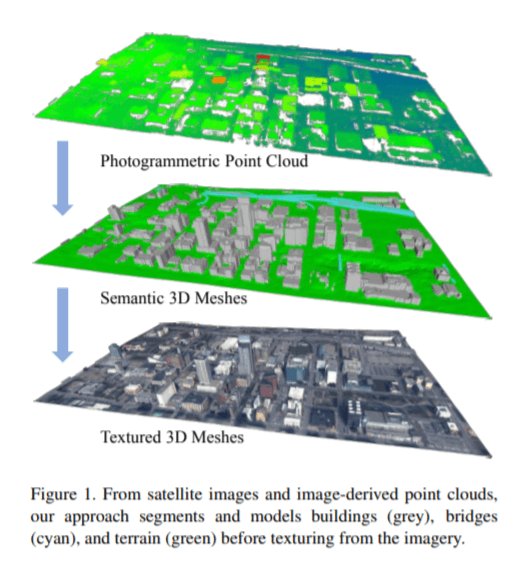
【要約】
– 都市部の正確な3D地理空間メッシュモデルは、ナビゲーションや都市計画などのさまざまなアプリケーションで使用される。
– 3Dモデルを取得するための技術はいくつか存在している。
-たとえば、GEIGER-MODE LIDAR によるカメラスキャンする手段、マルチビュー衛星画像を利用し、ポイントモデルまたはサーフェイスモデルを再構築する手段など。
– ただし、上記の手法においてはデータ収集時の生産性やデータのノイズ性、処理性において、様々な問題が生じる可能性がある。
– そこで、商用のマルチビュー衛星画像からセグメント化された3Dビルディングメッシュモデルを作成する方法について説明。
– また、この論文では実世界での運用に重点を当てている。
– そのため、アルゴリズムやサーバーの展開、WebによるインターフェースはOSS化している。
【コメント】
都市 3D モデルを自動構築する上で非常に有用なベンチマークデータセットであり、この論文は複雑なパイプライン実装をオープンソースとして提供しておりコミュニティに大きく貢献している。
(4)今年の抱負と衛星データについて
◆今、取り組んでいること、もしくは2020年取り組んでいきたいことを教えてください
・Kaggle Grandmaster、ISUCONの本戦出場、インフラ構築の知識向上(MLOpsの高まりより)
・Kaggle Grandmasterになるために必要なこと全般
・高解像度な衛星画像や航空写真から特定のアプリケーションに特化したネットワークモデルを構築し、都市や国レベルの広域の分析を行いたい。
・Kaggle Grand Masterを目指すために、残り1つの金メダルを取得
・解析のフローを作りたい
◆衛星データを使ってやってみたいことがあれば教えてください
・個人的に人の行動や思想を分析するのが好きなので、衛星データと地上データ(POSや位置情報など?)からミクロやマクロの人の動きを追うような分析をしてみたい。
・高解像度な衛星画像から非常に小さなオブジェクト、人や動物・家畜などの Crowd Counting に挑戦したい。
・株価予測
(5)まとめ
今回は5人のKagglerの方に面白かったコンペや論文について伺いました。技術的に面白いモノ、テーマ設定として面白いモノそれぞれ多様で興味深い結果となりました。
宙畑では衛星データの利活用を推し進めていますが、「データ解析」や「機械学習」とは切っても切れない領域であり、これからも「衛星データ」と「機械学習」の組み合わせに注目していきたいと思います。
すでに以下のような記事を公開していますので、よろしければご覧ください。
宙畑おすすめ記事
世界的な機械学習プラットフォーム「Kaggle」の概要と衛星データコンペ事例まとめ
【Kaggleコンペ解説連載】衛星画像による海氷と船舶の識別
CNNを使って衛星データに雲が映っているか否か画像分類してみた
船舶の物体検出!第2回衛星データ解析コンテスト上位入賞者の解析手法紹介!
【Kaggleコンペ解説連載】衛星データから雲を理解する! 上位入賞者の手法解説
「Tellus」で衛星データを触ってみよう!
日本発のオープン&フリーなデータプラットフォーム「Tellus」で、まずは衛星データを見て、触ってみませんか?
★Tellusの利用登録はこちらから
