【コード付き】画像用Transformerを利用して衛星画像の分類機械学習モデルを作成する
色々な分野で応用され始めているTransformerの簡単な解説と実際に衛星画像を利用した雲判定機械学習モデルを作成していきます。
宙畑の2020年Kagglerのアンケート記事でも触れましたが、最近は自然言語処理で使われていたTransformerという技術が、自然言語処理以外の分野でも利用されるようになり、精度の高い結果を出すようになりました。
Kaggleランカーの9人に聞いた、2020年面白かったコンペ9選と論文9選
今回の記事では、Transformer や画像を扱うための Vision Transformer(ViT) についての簡単な解説をおこない、実際に ViT を利用して衛星画像の分類タスクを行います。コードはGoogle Colaboratory(GPU) 上で動かすことを想定していますので、すぐに実行できるようになっています。
Transformer
Transformer は2017年の論文 「Attention Is All You Need」
で発表され、それまでRNNやCNNが主流だった自然言語処理の分野で、Attention という仕組みをメインに利用したモデルを用いて、学習速度や精度を向上させることが可能になりました。
既存の自然言語モデル(RNN)
まずは、Transformerが出る以前の自然言語の基本的なRNNモデルを見ていきます。
英語を日本語に翻訳するタスクで処理の流れを確認していきます。
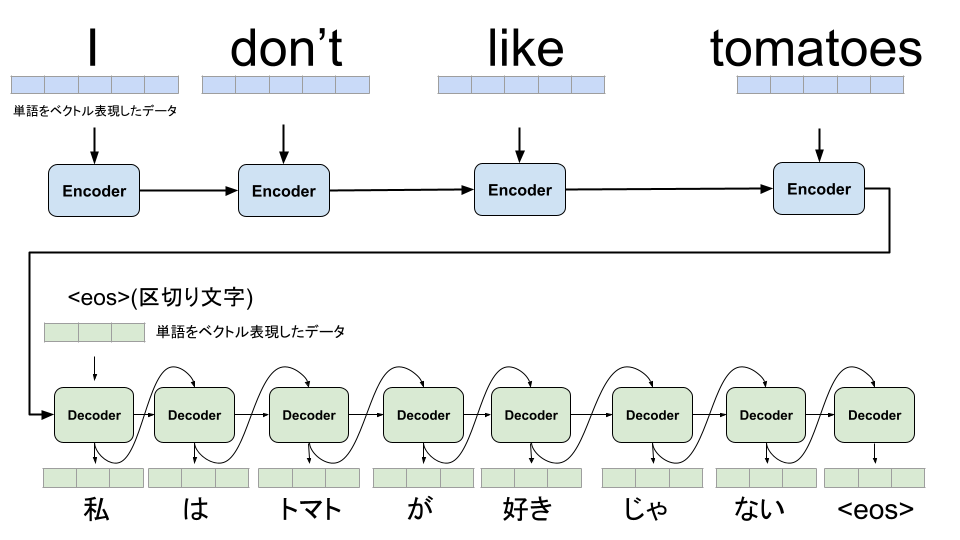
RNNの場合は学習や予測においても、逐次前回の出力結果を次の入力に利用する必要があります。文脈全体の内容を反映することができるようになっていますが、まとめて並列に学習することができずに学習時間が長くなる傾向がありました。
Attention
Transformerでメインに使われている Attention は、データのどこの部分に注目(Attention)するかの情報を学習していく仕組みです。
画像タスクでの猫の種類を分類をするタスクでの Attention を例に説明していきます。
ノイズも混ざった画像全体から猫の種類を分類するよりも、Attention を加えることで、画像のどこに注目をすれば良いかも一緒に学んでいきます。

画像左側は入力画像、右側はAttentionでどこの部分の情報が猫の分類に必要なのかを示しています。(実際のAttentionレイヤーでは0,1での表現ではなく分布して広がりを持っています)モデルの学習が進むに連れて、Attentionの精度が良くなり分類に必要な部分を見つけて、分類の精度も良くなります。
自然言語の Attention でも同じように文章のどの単語に注目すれば良いのかを学んでいきます。
Transformerの学習
Transformerで学習する際には、RNNのように順に単語を渡していくのではなく、Encoderには時系列順に並べた文章データを渡します。Encoder側ではSelf-Attentionと呼ばれる、入力の文章の単語間での結びつき(関連度)を学習します。例であげている文章 I don’t like tomatoes. の場合、don’t は動詞の否定をする単語のため、入力文章の単語間では like と一緒に注目した(単語間の関連度を高める)方が精度がよくなります。このように単語間の関連度情報を持つことで、翻訳等をする際にも、どの情報を一緒に利用すると良いのかを学習していきます。
また、単語のデータが時系列順に並んでいるという情報を表現するために、位置エンコーディングという処理を追加します。
Decoder側には正解データである翻訳後の情報に開始と終了のマークとを加えた文章データを入力して、Encoder側からのAttention情報を組み合わせてDecoder側でもAttentionを利用して、単語毎の確率分布を出力します。この際、Decoder側の入力された単語部分より時系列で後の単語についての情報はマスク処理をかけることで学習時には取得できないようにしてあります。最終的に出力された確率分布を元にモデルの結合重みを更新して学習を行います。
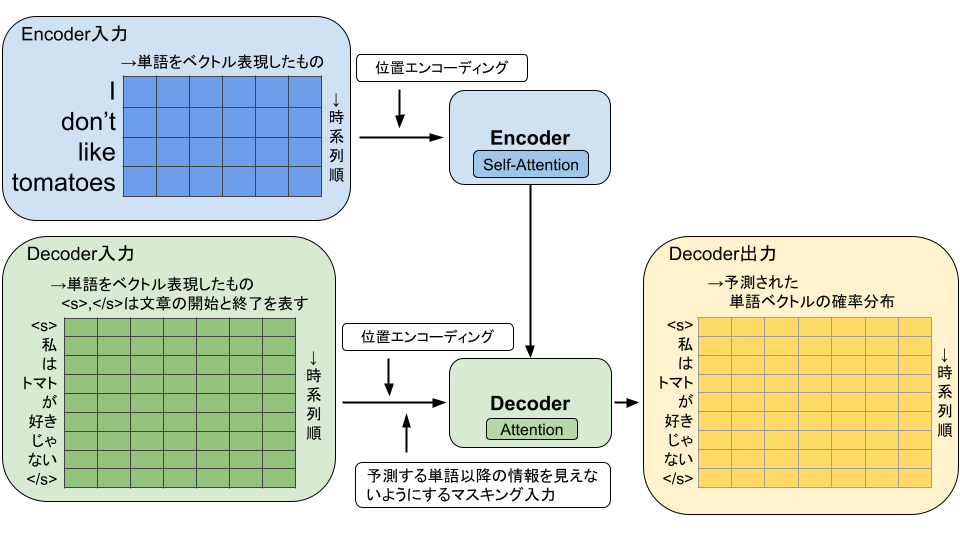
Transformerでは学習時には、RNNのように逐次結果を入力に利用するのではなく、まとめて(並列)処理ができるようになったため、学習の速度が向上しています。
予測時においてはDecoder側の入力は用意されていないため、<s>から順に入力していき、予測した確率分布を次の予測の入力に渡して、</s>が出てくるまで生成していく必要があります。
BERT
BERTは2018年の論文
「BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding」 で発表され、今回扱うような Vision Transformer 等の基礎の部分になっていて、主にTransformerのEncoderの部分を利用しています。
TransformerのDecoder部分は使わずに、Encoder部分のみを利用し、文章を抽象化した状態で利用できるようになるため、色々なタスクに応用することが可能になりました。
BERTでは次のような事前学習(Pre-training)を行います、
入力: 一部の単語が隠された(マスクされた)2つの文章
タスク1: マスクされた単語に何が入るかを予測するMLM(=Masked Language Modeling)
タスク2: 2つの文章が内容的に連続しているものなのかを予測するNSP(Next Sentence Prediction)
この事前学習でエンコーダ部分を学習させたものに対してファインチューニング(実際にBERTを利用したいデータセットを用いての学習)を行い、各自の利用したいタスクに適用させます。
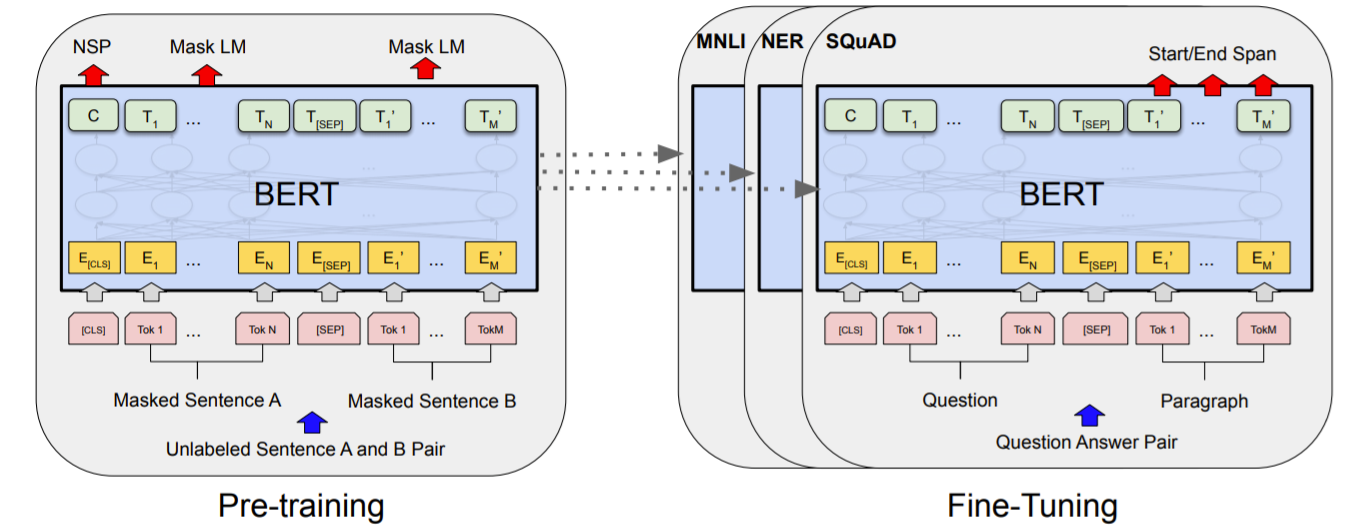
事前学習には、大量の計算リソースが必要なため、個人で利用する場合等においては、公開されている事前学習済みのモデルを利用することが多いです。その時も、TensorFlowやPytorch等のライブラリでも利用可能な学習済みモデルは異なるため注意が必要です。
Vision Transformer(ViT)
自然言語処理で処理速度や精度を上げてきた Transformer を別の分野でも利用する動きが出てきて、その中でも画像の処理でてきたのが Vision Transformer(ViT)です。
ViTは2020年の論文 「An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale」で発表されました。
CNNを全く使わずにAttentionのみでモデルが構築されています。画像タスクでも同じくAttentionの強みが利用でき、CNNでは難しかった画像の離れた位置の情報も利用しやすくなりました。
自然言語タスクでは単語をベクトル化していましたが、ViTでは画像を複数枚に分割することで、入力情報とします。
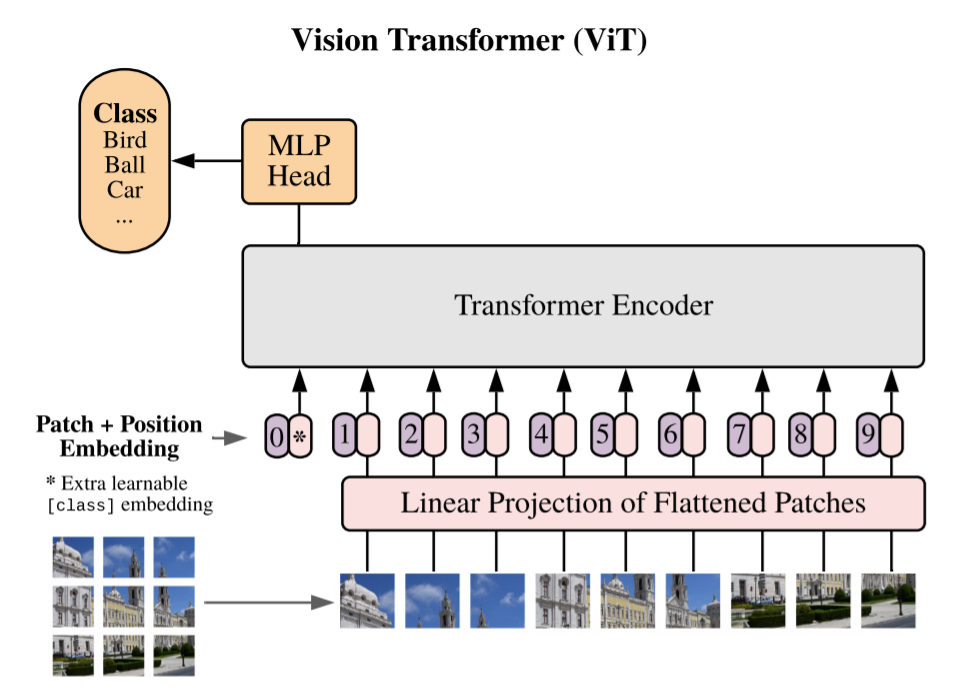
ViTでも事前学習には大量の学習データや学習時間が必要です。
Googleが保持している大量の非公開の画像データセットで学習した、事前学習済みのモデルは公開されているため、その学習済みのモデルを利用してファインチューニングをすることで、独自のデータセットやタスクに対応できます。
ViTを利用した画像分類
それでは実際に自分たちで用意した画像を利用して分類していきます。
今回のソースコードは以下で公開していますので、適宜参照してください。
https://github.com/sorabatake/article_20454_transformer
利用するデータ
以前の宙畑の記事で利用された、雲画像の分類を行っていきます。
CNNを使って衛星データに雲が映っているか否か画像分類してみた
このデータセットは、衛星画像に雲が写っている(cloudy)か、写っていない(clear)かの分類タスクです。


ViTを利用するためのライブラリ
今回はPyTorchで学習を行います。Google Colab 上で動かす想定のためバージョン等も現在(2021年5月時点)での環境で実行しています。
モデル構築は PyTorch で学習済みの画像処理モデルが扱える、pytorch-image-models というライブラリを利用していきます。
https://github.com/rwightman/pytorch-image-models
ここからGoogleColab用のコードを記述していきます。実行する時にはメニューの「ランタイム」から「ランタイムのタイプを変更」を選択して、ハードウェアアクセラレータはGPUを選択してください。

pytorch-image-models は timm で登録されているので、pipを利用してインストールします。
!pip install timm主なライブラリのバージョン等は次の通りです。
torch==1.8.1+cu101
torchvision==0.9.1+cu101
timm==0.4.5
Pillow==7.1.2利用するライブラリをインポートしていきます。
import argparse
import operator
import os
import time
from collections import OrderedDict
import timm
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from PIL import Image
from timm.data import create_dataset, create_loader, resolve_data_config
from timm.optim import create_optimizer
from timm.utils import AverageMeter, accuracy
from timm.utils.summary import update_summary
from torch.autograd import Variable
from IPython.display import display
データの配置や設定値
学習時に利用するパラメータの設定等を記述していきます。timm側で用意されている、いくつかの機能がCLIでの引数を前提とした形式でしたので、argparseを利用しています。
parser = argparse.ArgumentParser(description="Training Config", add_help=False)
parser.add_argument(
"--opt",
default="sgd",
type=str,
metavar="OPTIMIZER",
)
parser.add_argument(
"--weight-decay", type=float, default=0.0001
)
parser.add_argument(
"--lr", type=float, default=0.01, metavar="LR"
)
parser.add_argument(
"--momentum",
type=float,
default=0.9,
metavar="M",
)
parser.add_argument(
"--input-size",
default=None,
nargs=3,
type=int,
metavar="N N N",
)
args = parser.parse_args(["--input-size", "3", "224", "224"])
EPOCHS = 30
BATCH_SIZE = 32
NUM_WORKERS = 2
今回利用するデータセットは、全体で200MB弱なので、直接Colabのインスタンスにアップロードも可能ですし、GoogleDriveなどと連携して、利用することも可能です。
# 適宜GoogleColab上のデータセットディレクトリ(train, validation, testが含まれれるディレクトリ)のパスを指定してください
dataset_path = '/content/drive/MyDrive/VisionTransformer/'
モデルの構築
モデルの構築を行います。
# 対応モデルを確認
model_names = timm.list_models(pretrained=True)
model_names
timmで利用できる、学習済みモデル一覧を確認できます。ViT以外も豊富に用意されていますが、目的のものは ‘vit_*’ という形式で用意されているので、今回は ‘vit_base_patch16_224’ を利用します。
NUM_FINETUNE_CLASSES = 2 # {'clear': 0, 'cloudy': 1} の2種類
model = timm.create_model('vit_base_patch16_224', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
model.cuda()データの設定値やPyTorch処理用のデータセット・ローダを作成していきます。
data_config = resolve_data_config(vars(args), model=model)
dataset_train = create_dataset('train', root=os.path.join(dataset_path, 'train'), is_training=True, batch_size=BATCH_SIZE)
dataset_eval = create_dataset('validation', root=os.path.join(dataset_path, 'validation'), is_training=False, batch_size=BATCH_SIZE)
dataset_test = create_dataset('test', root=os.path.join(dataset_path, 'test'), is_training=False, batch_size=BATCH_SIZE)
loader_train = create_loader(dataset_train, input_size=data_config['input_size'], batch_size=BATCH_SIZE, is_training=True, num_workers=NUM_WORKERS)
loader_eval = create_loader(dataset_eval, input_size=data_config['input_size'], batch_size=BATCH_SIZE, is_training=False, num_workers=NUM_WORKERS)
loader_test = create_loader(dataset_test, input_size=data_config['input_size'], batch_size=BATCH_SIZE, is_training=False, num_workers=NUM_WORKERS)
損失関数やオプティマイザを作成していきます。
train_loss_fn = nn.CrossEntropyLoss().cuda()
validate_loss_fn = nn.CrossEntropyLoss().cuda()
optimizer = create_optimizer(args, model)学習
学習部分を記述していきます。
先に1エポック分の学習用関数を定義します。
def train_one_epoch(epoch, model, loader, optimizer, loss_fn, args, output_dir=None):
second_order = hasattr(optimizer, "is_second_order") and optimizer.is_second_order
batch_time_m = AverageMeter()
data_time_m = AverageMeter()
losses_m = AverageMeter()
model.train()
end = time.time()
num_updates = epoch * len(loader)
for _, (input, target) in enumerate(loader):
data_time_m.update(time.time() - end)
output = model(input)
loss = loss_fn(output, target)
optimizer.zero_grad()
loss.backward(create_graph=second_order)
optimizer.step()
torch.cuda.synchronize()
num_updates += 1
batch_time_m.update(time.time() - end)
end = time.time()
if hasattr(optimizer, "sync_lookahead"):
optimizer.sync_lookahead()
return OrderedDict([("loss", losses_m.avg)])
続いてバリデーション用の関数も定義します。
def validate(model, loader, loss_fn, args):
batch_time_m = AverageMeter()
losses_m = AverageMeter()
accuracy_m = AverageMeter()
model.eval()
end = time.time()
with torch.no_grad():
for _, (input, target) in enumerate(loader):
input = input.cuda()
target = target.cuda()
output = model(input)
if isinstance(output, (tuple, list)):
output = output[0]
loss = loss_fn(output, target)
acc1, _ = accuracy(output, target, topk=(1, 2))
reduced_loss = loss.data
torch.cuda.synchronize()
losses_m.update(reduced_loss.item(), input.size(0))
accuracy_m.update(acc1.item(), output.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
metrics = OrderedDict([("loss", losses_m.avg), ("accuracy", accuracy_m.avg)])
return metrics
続いて、実際に学習を実行していきます。バリデーションデータで指標(今回は単純な正答率)が良かったモデルを保存していきます。
num_epochs = EPOCHS
eval_metric = "accuracy"
best_metric = None
best_epoch = None
compare = operator.gt
# 学習結果CSVファイルやファインチューニング後のモデルデータの出力先
output_dir = "/content/drive/MyDrive/VisionTransformer/output"
for epoch in range(0, num_epochs):
train_metrics = train_one_epoch(
epoch, model, loader_train, optimizer, train_loss_fn, args, output_dir=output_dir
)
eval_metrics = validate(model, loader_eval, validate_loss_fn, args)
if output_dir is not None:
update_summary(
epoch,
train_metrics,
eval_metrics,
os.path.join(output_dir, "summary.csv"),
write_header=best_metric is None,
)
metric = eval_metrics[eval_metric]
if best_metric is None or compare(metric, best_metric):
best_metric = metric
best_epoch = epoch
torch.save(model.state_dict(), os.path.join(output_dir, "best_model.pth"))
print(epoch)
print(eval_metrics)
print("Best metric: {0} (epoch {1})".format(best_metric, best_epoch))
私の実行環境では次のような結果になりました。21エポック目での結果が良かったので、もう少し学習数を減らしても良いのかもしれません。
29
OrderedDict([('loss', 0.1153580967305849), ('accuracy', 95.66666666666667)])
*** Best metric: 97.66666666666667 (epoch 21)テスト
今度はテストデータを利用して精度を確認していきます。
一番良かったモデルの情報を読み込みます。
model.load_state_dict(
torch.load(
os.path.join(output_dir, "best_model.pth"), map_location=torch.device("cuda")
)
)評価モードに変更し、画像単体での予測を出せるようにします。
model.eval()
image_size = data_config["input_size"][-1]
loader = transforms.Compose([transforms.Resize(image_size), transforms.ToTensor()])
def image_loader(image_name):
image = Image.open(image_name).convert("RGB")
image = loader(image)
image = Variable(image, requires_grad=True)
image = image.unsqueeze(0)
return image.cuda()
m = nn.Softmax(dim=1)
clearとcloudyから1枚選んで結果を表示してみます。
clear_image_path = os.path.join(dataset_path, 'test/clear/12_3542_1635.png')
predicted_clear_image = image_loader(clear_image_path)
display(Image.open(clear_image_path))
m(model(predicted_clear_image))
[0.7519, 0.2481] という結果になっていて、1個目の数値が clear の確率、2個目の数値が cloudy の確率なので、地表にも白い建物が存在するなどしていますが clear と予測できています。
cloudy_image_path = os.path.join(dataset_path, 'test/cloudy/12_3503_1735.png')
predicted_cloudy_image = image_loader(cloudy_image_path)
display(Image.open(cloudy_image_path))
m(model(predicted_cloudy_image))

こちらは、2個目が0.9917と雲が写っている cloudy と予測できています。
今度は、テストデータ全体に対して処理を行い正答率を出してみます。
def test(model, loader, args):
batch_time_m = AverageMeter()
accuracy_m = AverageMeter()
model.eval()
end = time.time()
with torch.no_grad():
for _, (input, target) in enumerate(loader):
input = input.cuda()
target = target.cuda()
output = model(input)
if isinstance(output, (tuple, list)):
output = output[0]
acc1, _ = accuracy(output, target, topk=(1, 2))
torch.cuda.synchronize()
accuracy_m.update(acc1.item(), output.size(0))
batch_time_m.update(time.time() - end)
end = time.time()
return {'accuracy': accuracy_m.avg}
結果は、{‘accuracy’: 98.25} となり、CNNを使った宙畑の記事でのテストデータの正答率は約88%だったのに比べて精度を向上することができています。
CNNに比べて単純にモデルも複雑になっているため、精度を比較しても、あまり意味はありませんが、現在無料で公開されている技術を使って行える画像分類タスクのモデルとしては、候補に入れておいても良さそうです。
まとめ
今回はTransformer や画像を扱うための Vision Transformer(ViT) についての簡単な解説に加えて、実際に ViT を利用して衛星画像の分類タスクを行いました。Attentionを加えることで、画像の離れた位置の情報等も扱いやすくなるため、今回のような雲が写っているかの識別だけでなく、どのような雲の形状(高層雲or低層雲)なのかを分類するようなタスクにも相性が良いと思われます。ぜひ公開しているコードを参考にオリジナルのデータで衛星画像を予測してみてください。
