【コード・データ付き】学習済みモデルを利用して手軽にゴルフ場が写っているかを判定できる機械学習モデルを作成する
学習済みモデルを利用した転移学習で機械学習モデルを作成することで、手軽に画像識別予測を行うことができるます。ゴルフ場が写っているか写っていないかの分類を例にコードと合わせて解説します。
記事作成時から、Tellusからデータを検索・取得するAPIが変更になっております。該当箇所のコードについては、以下のリンクをご参照ください。
https://www.tellusxdp.com/ja/howtouse/access/traveler_api_20220310_
firstpart.html
2022年8月31日以降、Tellus OSでのデータの閲覧方法など使い方が一部変更になっております。新しいTellus OSの基本操作は以下のリンクをご参照ください。
https://www.tellusxdp.com/ja/howtouse/tellus_os/start_tellus_os.html
はじめに
この記事は、Tellusを使い始めて、何か機械学習に取り組んでみたいけど、何から取り組んでいけばいいのか迷っている人向けです。
この記事を読むことで、自分で識別したい対象(今回はゴルフ場)が写り込んでいる衛星画像を用意して、ラベル付けを行い、PyTorchを用いて未知の衛星画像に対しても対象のものが写り込んでいるか判定してくれる機械学習モデルを作る一通りの作業を体験することができます。最後にはTellus上で新しい衛星画像を取得して実際に判別できるのかを試していきます。
今回は、PyTorchの画像を扱いやすくするためのライブラリであるtorchvisionの機能でラベル付けを楽にしてくれるImageFolderや学習済みモデルを利用した転移学習で学習時間が短くても精度を良くすることができる方法等も紹介していきます。
なお、学習時間が短くなるといってもCPU環境での画像データ学習は時間がかかるため、今回のコードはGPU環境で動かすことが前提になっています。Google Colabなどをご利用ください。
※Tellusでの衛星画像取得と予測部分はCPUのTellus開発環境を前提に書いています。
■本記事は次のような方を想定しています
・プログラミングの経験があり、機械学習も触ったことがある
・ニューラルネットワークがどのように学習や予測を行うかが、ある程度理解している(コードが書けなくても大丈夫です)
今回、本記事で利用するコードと画像データはgithubで公開しています。
(1)ゴルフ場が衛星画像に写っているかを識別する
学習データ
千葉県と兵庫県のゴルフ場が写っている(Positive)と写っていない(Negative)を用意してあります(画像サイズは256 x 256)。簡単な識別であれば、それぞれ100枚位揃っていれば、精度が上がってきます。
また、Tellusではローカルへのダウンロードの制限等もありますのでご注意ください。
データ例


フォルダ構成例
ラベル付けの際にフォルダで分けておく必要があるため、次のようなフォルダ構成にしてあります。
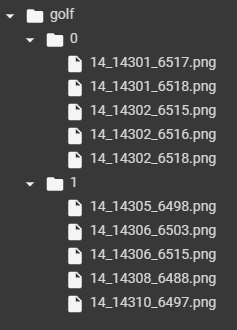
0フォルダ(ゴルフ場が写っていない画像)、1フォルダ(ゴルフ場が写っている画像)で分けています。
※実際の画像ファイル数はもっと多いです
今回は、写っているか写っていないかの2択なので0,1のバイナリで表現していますが、フォルダ名を対象のものにすれば「golf, school, else」のように多クラス分類用のラベルを付けることも可能です。
コードと解説
冒頭でもお伝えした通り、本記事で利用するコードと画像データはgithubでも公開しています。
モデル構築と学習(GPU環境)
利用するライブラリ
PyTorchのライブラリや画像を扱うためのライブラリを使うので呼び出しておきます。
import numpy as np
from tqdm import tqdm
from PIL import Image
import torch.nn as nn
from torch.autograd import Variable
import torch
import torchvision.transforms as transforms
import torchvision.models as models
import torchvision
画像を読み込む
今回はImageFolderを利用することで、フォルダ構成例のような状態になっているとそれに対応したラベルが自動的にデータに付くようになります。そのため手動でデータフレーム等でラベルデータの作成は必要なくなります。
transform には読み込む際の画像データ処理をまとめて記述することができます。
データ数が少ない場合に備えて Augmentation (データを増やす処理)も行っています。
transform = transforms.Compose(
[
# 画像サイズが異る場合は利用して画像サイズを揃える
# transforms.Resize((256,256)),
# 左右対称の画像を生成してデータ量を増やす(Augmentation)
transforms.RandomHorizontalFlip(),
# PyTorchで利用するTensorの形式にデータを変換
transforms.ToTensor()
])
# google colab等で実行する際にフォルダ内に .ipynb_checkpoints があると、ラベルの対象になるので削除
!rm -rf golf/.ipynb_checkpoints
# ImageFolder を利用して読み込む
data = torchvision.datasets.ImageFolder(root='./golf', transform=transform)
次のコードを実行して
data.class_to_idx
実行結果> {'0': 0, '1': 1}
のような結果になれば正しくラベル付けがされています。
学習用と評価用のデータに分割する
画像データを学習用(train)と評価用(validation) に分けていきます。random_split を利用することで、指定した割合にランダムで分割してくれます。
train_size = int(0.8 * len(data))
validation_size = len(data) - train_size
data_size = {"train":train_size, "validation":validation_size}
data_train, data_validation = torch.utils.data.random_split(data, [train_size, validation_size])
train_loader = torch.utils.data.DataLoader(data_train, batch_size=16, shuffle=True)
validation_loader = torch.utils.data.DataLoader(data_validation, batch_size=16, shuffle=False)
dataloaders = {"train":train_loader, "validation":validation_loader}
モデル作成
今回は画像認識タスクにおいて、高い予測性能を持つresnet18というモデルの学習済みモデルを使います。
model = models.resnet18(pretrained=True)
model
上記のコードを実行すると、次のようなモデルのネットワーク層の構成が表示されます。
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
・・・
(中略)
・・・
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)
このままだと、最後の層の出力(out_features)が1000になっているので、目的である0か1かにするため、2に減らします。また学習済みモデルのため、最終的な出力の層のみ学習が行われるように学習済みの部分の結合は固定するように設定します。
※ネットワーク全体を学習対象にしてしまうと過学習が起きやすいので注意してください
# 現在のモデルすべてのパラメータの requires_grad を False にすることで
# ネットワークの重みを固定することができる
for parameter in model.parameters():
parameter.requires_grad = False
# 今回は0,1の予測のため、最終的な出力を2個に設定
model.fc = nn.Linear(512, 2)
# CPU環境の場合は不要
model = model.cuda()
モデル学習
作ったモデルを学習していきます。
1エポックの中で学習(train)と評価(validation)を毎回行っています。
損失関数はクロスエントロピーを利用しています。
lr = 1e-4
epoch = 50
optim = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=1e-4)
# CPU環境の場合は cuda() は不要
criterion = nn.CrossEntropyLoss().cuda()
def train_model(model, criterion, optimizer, num_epochs):
for epoch in tqdm(range(num_epochs)):
epoch_loss = 0
epoch_acc = 0
for phase in ['train', 'validation']:
if phase == 'train':
model.train()
else:
model.eval()
current_loss = 0.0
current_corrects = 0
for data in dataloaders[phase]:
inputs, labels = data
# CPU環境では不要
inputs = inputs.cuda()
labels = labels.cuda()
outputs = model(inputs)
_, preds = torch.max(outputs.data, 1)
loss = criterion(outputs, labels)
if phase == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
# CPU環境では item() 不要
current_loss += loss.item() * inputs.size(0)
current_corrects += torch.sum(preds == labels)
epoch_loss = current_loss / data_size[phase]
# CPU環境では item() 不要
epoch_acc = current_corrects.item() / data_size[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
return model
trained_model = train_model(model, criterion, optim, epoch)
ログに train と validation データの損失(Loss)と正答率(Acc)を出しているので、学習が行われて validation の Loss が減少し、Acc が増加していることを確認してください。100% まで Acc が上がっていると過学習の可能性もあります。
モデルのファイル出力
Tellusの開発環境では、この学習したモデルをファイルに保存してアップロードして使います。
torch.save(trained_model.state_dict(), './golf-model.pth')予測
正しく学習できているのかを確かめるために、学習に使ったデータを取ってきて予測します。それぞれの学習データフォルダから1個画像を取ってきて train-positive.png と train-negative.png という名前で保存してあります。学習に使ったデータのため、精度は高くなるので注意してください。
モデルを評価モードに変更して、テスト用の画像読み込みをして、モデルに渡せる形式にします。
trained_model.eval()
imsize = 256
loader = transforms.Compose([transforms.Scale(imsize), transforms.ToTensor()])
def image_loader(image_name):
image = Image.open(image_name).convert("RGB")
image = loader(image)
image = Variable(image, requires_grad=True)
image = image.unsqueeze(0)
# CPU環境の場合は cuda() は不要
return image.cuda()
m = nn.Softmax(dim=1)
train-positive.png と train-negative.png をそれぞれ、予測してみて、ネットワークから出力される結果を見てみます。
image = image_loader('./train-positive.png')
print(m(model(image)))
実行結果> tensor([[0.2003, 0.7997]], device='cuda:0', grad_fn=)
image = image_loader('./train-negative.png')
print(m(model(image)))
実行結果> tensor([[0.7765, 0.2235]], device='cuda:0', grad_fn=)
0~1の範囲で [negativeの可能性, positiveの可能性] という形式で出力されるので、このような形でtrain-positive.pngが右側、train-negative.pngが左側の数値が大きくなっているのでちゃんと予測できているっぽいです。
(2)Tellusでの画像取得と予測(CPU環境)
今度は、実際に未知のデータでも、正しく予測できているか確認しようと思います。
トレーニングデータは神奈川県と兵庫県でしたが、私の故郷の埼玉県飯能市にもゴルフ場がいくつか存在していてデータとしては良さそうなので、そこのデータをTellus上で探して、Tellus開発環境上でダウンロードして、予測が正しくできているかを確認していきます。
Tellus上のデータの探し方・取得方法
今回学習に使ったデータは、ゴルフ場の画像ですが、一度未知のデータで試してみたら精度があまり良くありませんでした。
実際に画像を見比べた結果、学習データは寒い時期のデータで、雪等の影響はありませんでしたが、芝も枯れている状態で、未知のデータでは夏の青く茂った芝でした。
そういった、学習データと異なる時期のものを予測する場合などには注意が必要みたいです。精度を上げるには、色々な季節も学習データに混ぜられるといいのかもしれませんね。
また、TellusOS上での、特定の日時の衛星画像取得方法についても説明しておきます。
まず、該当する衛星を左から選び、右上の格子状のアイコンをクリックして、タイル情報を反映させておきます。
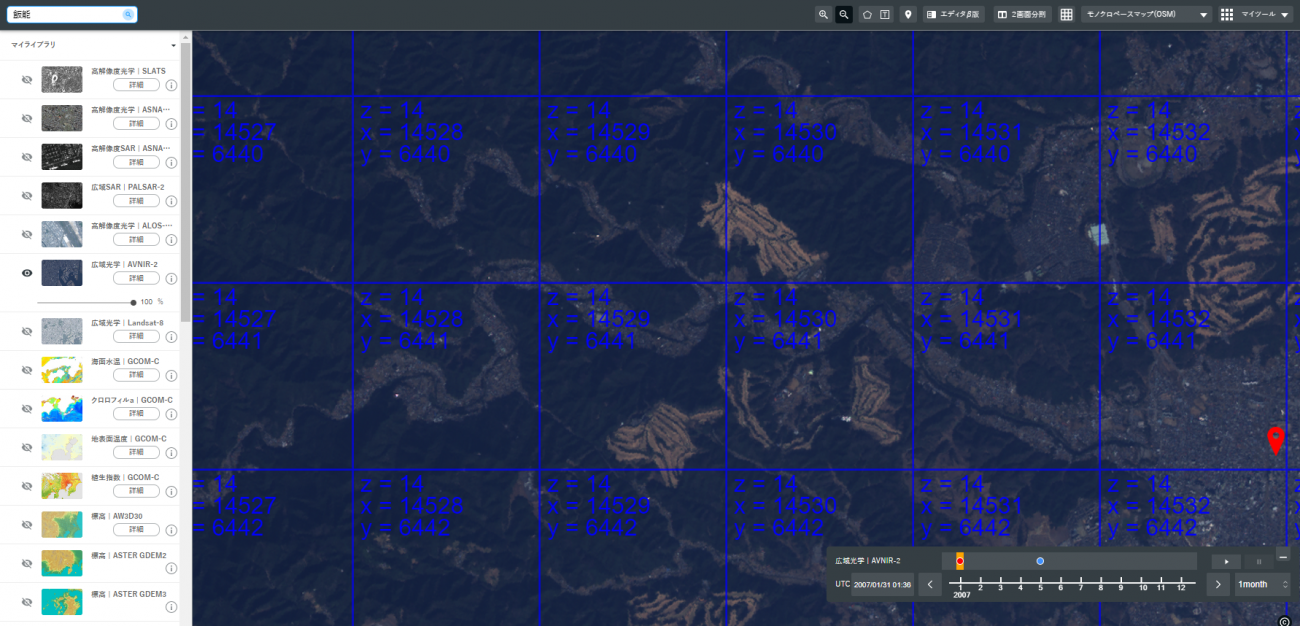
今回は、(x=14528, y=6441, z=14) を negative、隣のタイルの (x=14529, y=6441, z=14) を positive に選び画像を取得しようとしました。
しかし、このままAPIで「https://gisapi.tellusxdp.com/blend/{z}/{x}/{y}.png」で取得しても、最新の衛星画像になってしまうので、画面の右下のバーで選択した日時の衛星画像が欲しい場合には左側のメニューにある該当の衛星の「詳細」ボタン(今回はAVNIR-2のもの)を押します。
すると、次のような画面が現れて右側に複数の候補が現れるため一つを選びます。
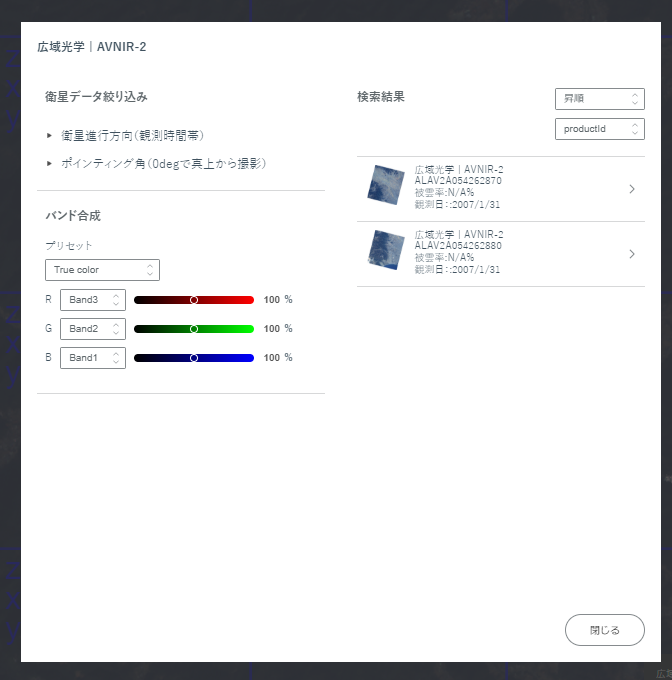
すると、今度は更に詳しい衛星画像についての情報が出てきて、そこにある、tile_path に書かれている path を利用することで、この特定の日時の衛星データを取得できるようになります。

これで、画像取得先もわかったので実際にTellus開発環境上で画像を取得していきます。
また、先程学習した際に出力した golf-model.pth もアップロードしておいてください。
利用するライブラリ
ライブラリも先ほどとはあまり変わらず、画像取得・表示用のライブラリが増えています。
import torchvision.transforms as transforms
import torchvision.models as models
import torch.nn as nn
import torch
from torch.autograd import Variable
import requests
from PIL import Image
from io import BytesIO
import matplotlib.pyplot as plt
%matplotlib inline
画像を取得する
トークンを設定して、先程指定された path から画像を取得できるメソッドを定義します。
TOKEN = 'YOUR-TOKEN'
def get_image(rspid, productid, z, x, y):
url = f"https://gisapi.tellusxdp.com/blend/av2ori/{rspid}/{productid}/{z}/{x}/{y}.png"
headers = {
'Authorization': 'Bearer ' + TOKEN
}
r = requests.get(url, headers=headers)
return Image.open(BytesIO(r.content))
まずは、ゴルフ場が写っているpositiveの方のデータをダウンロードして、表示して、test-positive.png という名前をつけて保存します。
im_array = get_image('D069P3', 'ALAV2A054262870', 14, 14529, 6441)
plt.imshow(im_array)
im_array.save('test-positive.png')

今度は隣のタイルですが、こちらはゴルフ場が写っていないので、test-negative.png という名前で保存します。
im_array = get_image('D069P3', 'ALAV2A054262870', 14, 14528, 6441)
plt.imshow(im_array)
im_array.save('test-negative.png')

モデル読み込み
ローカルでやったように、resnet18をダウンロードして、出力部分を揃えたあとに、アップロードしたモデルのネットワークデータを反映させます。GPUで学習したデータをCPUで使おうとしているので、map_locaitonを指定しています。
model = models.resnet18(pretrained=True)
model.fc = nn.Linear(512, 2)
model.load_state_dict(torch.load('./golf-model.pth', map_location=torch.device('cpu')))
画像読み込み
ローカルでの予測と同じように、画像を変換してモデルに渡せる形にします。
model.eval()
imsize = 256
loader = transforms.Compose([transforms.Scale(imsize), transforms.ToTensor()])
def image_loader(image_name):
image = Image.open(image_name).convert("RGB")
image = loader(image)
image = Variable(image, requires_grad=True)
image = image.unsqueeze(0)
return image
m = nn.Softmax(dim=1)
予測する
先程取得した画像を読み取って予測します。
image = image_loader('./test-positive.png')
m(model(image))
実行結果> tensor([[0.0111, 0.9889]], grad_fn=)
右側のほうが数値が高く、ゴルフ場が写っている可能性が高いことを表しています。
image = image_loader('./test-negative.png')
m(model(image))
実行結果> tensor([[0.8987, 0.1013]], grad_fn=)
左側のほうが数値が高く、ゴルフ場が写っている可能性が低いことを表しています。
無事、ゴルフ場が写っているかの判定ができるモデルが出来上がりました。
同じような仕組みで、建造物等(メガソーラー発電所とか)の検出もできると思いますので、試してみてください。
(3)Tellusユーザグループの紹介
最後に、DiscordにあるTellusユーザグループを紹介します。
Tellus公式のサポートとは別に、本記事の著者である田上さん管理人のもと、技術的に躓いたところなども、ユーザ同士で解決できたり、定期的な勉強会開催ができるコミュニティを目指して活動しています。
現在はモブプログラミングという、複数人で一つのコードを書いていくイベントを毎週Discord上で開催しており、このゴルフ場判定のコードもモブプログラミングをしながら作成されています。
もし、Tellus触っていきたいけど、何をしたらいいかわからない人などは参加してもらえると、衛星データに関する知識を身につけていけることができると思いますので、ぜひ下記の招待リンクからお気軽にご参加ください(無料)。
