The 4th Tellus Satellite Challenge実施!~入賞者たちの手法を解説~
Tellus Satellite Challengeの第4弾「海岸線抽出」が行われました。本記事では、入賞者のアプローチを比較しながら眺めていき、他の(衛星)画像データコンペティションにも応用できるように手法をまとめていきます。
Tellus Satellite Challengeの第4弾「海岸線抽出」が行われました。本記事では、入賞者のアプローチを比較しながら眺めていき、他の(衛星)画像データコンペティションにも応用できるように手法をまとめていきます。
今回は、ご自身もコンペに参加された田上健太さんに執筆をお願いしました。
(1)「Tellus Satellite Challenge」とは?
「Tellus」は、産業利用を目的とした衛星データプラットフォーム。日本政府の「宇宙産業ビジョン2030」が掲げる「2030年代早期に宇宙産業全体の市場規模を倍増する」という目標に向けて立ち上げられた事業です。このTellus事業の一環として、衛星データの利活用事例の可視化、優秀なデータサイエンティストの発掘、衛星データの周知・啓蒙、Tellusの利活用促進を目的としたデータ分析コンテスト「Tellus Satellite Challenge」が実施されています。
過去3回のTellus Satellite Challengeでは、それぞれ
第1回:土砂崩れ検出
第2回:船舶検出
第3回:海氷領域の検知
をテーマとしたコンテストが実施され、その成果は以前の記事にて紹介しました(第1回、第2回、第3回)。
これらのチャレンジでは世界中のAI人材が参加し、SARや高解像度光学データを用いた課題に挑戦。衛星データ活用のベストプラクティスが得られました。
そしてこの度、Tellus Satellite Challengeの第4弾「海岸線抽出」が行われました。
(2)第4回の概要
第4回のテーマは「海岸線抽出」です。
テーマの意義や今回使われているSARデータについてはこちらの記事にまとめられています。
第4回Tellus Satellite Challenge開催!テーマは「海岸線抽出」
特に衛星データにおいて、SARデータは光学データよりも高解像度であることが多く天候にも影響を受けにくいため、今回のコンペティションを振り返ることは、他の衛星データでのコンペティションや衛星データを活用する際にも役立つでしょう。
第4回目のチャレンジでは、2020年の夏頃に開催されたTellusのイベントTellus SPACE xData Fes. -OnlineWeeks 2020-の影響もあってか参加者は803人(前回比 +246人)、投稿されたモデルは2783件(前回比 +709件)でした。衛星データコンペティションの人気の高まりも感じます。
(3)課題概要
SARデータのグレースケール画像と海岸線の教師データから、海岸線を予測できるようにしていきます。

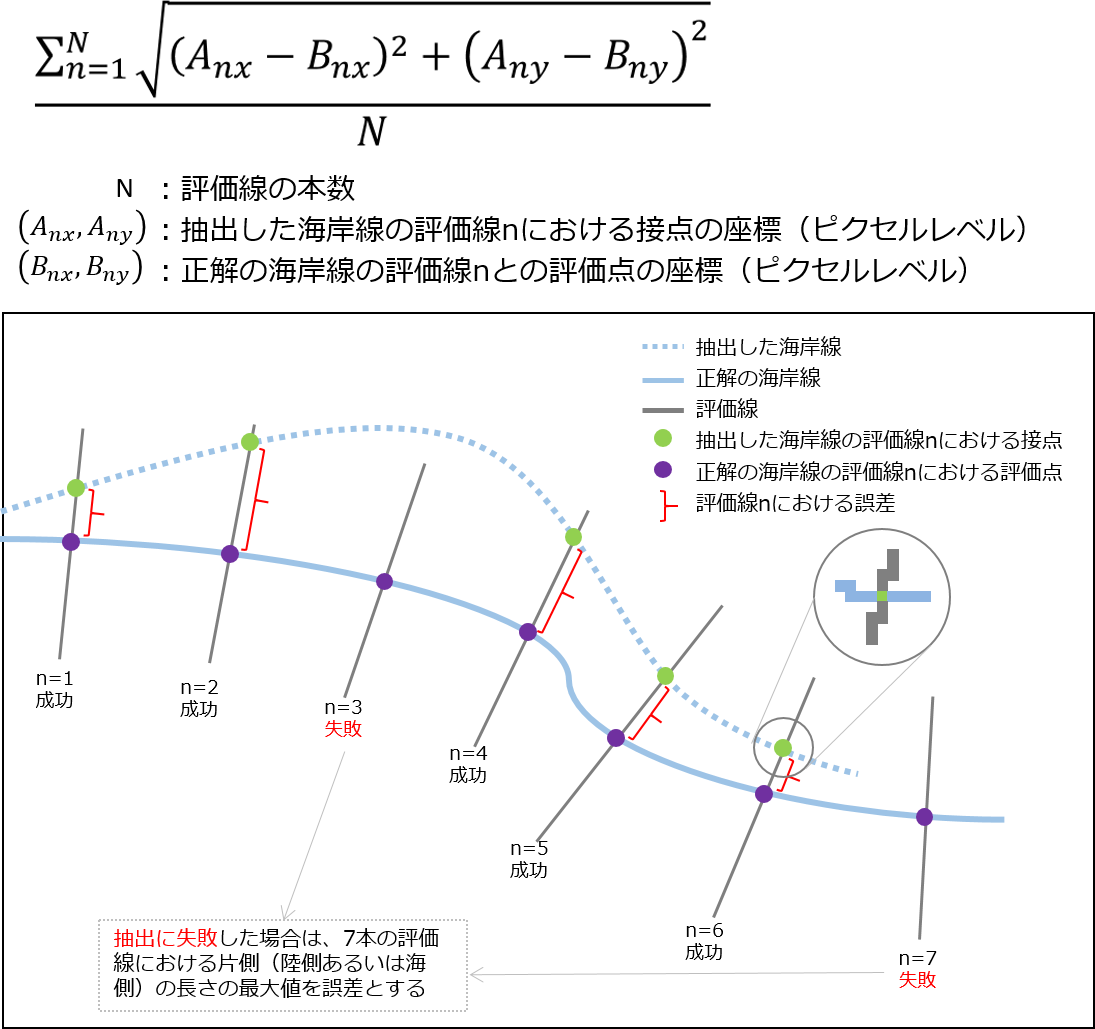
評価指標
次のように、正解の海岸線データには一定の間隔で評価線が海岸線と垂直に存在していて、なるべく誤差が小さくなるように海岸線を予測していきます。
(4)入賞者
入賞した上位3チームについての情報です。
1位
BloodAxe チーム
この記事を書いている2021年1月の時点でSIGNATE全体のランキング1位の方です。
https://signate.jp/users/25647
Kaggleでもコンペティショングランドマスターの称号を持ち、The 1st Tellus Satellite Challenge でも3位に入賞しています。
今回はソロでの優勝でした。
2位
IRAFM-AI チーム
SIGNATEの 第3回AIエッジコンテスト で2位のチームです。当時のインタビュー動画も公開されています。
前回の The 3rd Tellus Satellite Challenge でも6位と好成績を残しています。
今回はさらに日本人の人もチームに加わり3人での参加でした。
3位
aknk チーム
株式会社インテックの社員で構成されたチームです。
解法をQiita記事で公開されているので、こちらも参考にされるとより理解が深まると思います。
【SIGNATE】The 4th Tellus Satellite Challenge振り返り【3rd place】 – Qiita
(5)入賞者の手法
入賞した3チームにはそれぞれ、解法について回答してもらったので内容をまとめていきます。
処理の全体像
処理全体を次の順番に見ていきます。
- ●前処理
- 〇画像データ処理
- 〇ラベルデータ作成
- ●学習
- 〇利用モデル
- 〇オーグメンテーション
- ●後処理
- 〇予測
- 〇海岸線抽出
前処理
画像データ処理
| BloodAxe チーム | IRAFM-AI チーム | aknk チーム |
| 画像を65535(16bit – 1の値)で割って、平方根を取り[0~1]の範囲に正規化。 | 画像を[0~1]の範囲にするために ・線形的な変換(65535で割る) ・非線形的な変換(logを活用) を行い、画像としても別々に利用した。 |
同じ大きさになるように、海岸線付近の領域を切り取る。データは8bitに変換。 学習データではアノテーションされた海岸線付近を切り取り、テストデータでは画像処理である程度の海岸線付近を見つける。 |
早速、チーム毎にアプローチが異なっていますね。
aknkチームのQiita記事にもあるように実際のデータのままだと、差分がわかりづらく真っ暗な状態のままなので、何かしらの処理を加えて扱いやすいデータにする必要があります。
また、IRAFM-AI チームとaknk チームでは、全ての画像において同じ物理的解像度を持っているため、画像をリスケールすることはなく基本的に切り取るだけにしているようです。
ラベルデータ作成
| BloodAxe チーム | IRAFM-AI チーム | aknk チーム |
| 2値分類 ・海岸線: 1 ・それ以外: 0 0,1だとデータの偏りがあるため、ヒートマップを利用して海岸線から[0~1]の範囲で広がりをもつようにする。 |
2種類の学習データを作成 2値分類 ・海岸線: 1 ・それ以外: 0 データの偏りがあるため、label smoothing処理を加えることで[0~1]の範囲にする。 3クラス分類 ・海: 0 ・無(no-data): 1 ・陸: 2 |
2値分類
・陸: 1 ・海: 0 前処理で海岸線付近の領域を抽出しているため、この領域のみを陸と海に分けた ラベルを使用する。欠損値が入った場合は0とする。 |
特に今回のデータですと、画像の中に情報が欠落している部分もあるため、上位2チームのように ‘海岸線’ or ‘それ以外’ をラベルとして利用するか、IRAFM-AI チームのもう一つの手法のように、欠落データ(no-data)自体をラベルにして分類してしまう方法がありそうです。
aknk チームでは、最初の画像処理の段階で海岸線付近のデータのみを抽出することで、なるべく欠落データの部分を避けて対処しているようです。
また、’海岸線’ or ‘それ以外’で予測しようとすると、ほとんどの画像の部分は ‘それ以外’ のデータになるため、ヒートマップであったり、label smoothing処理を加えることで、分布の偏りを減らせています。
BloodAxe チームによると、教師データであるアノテーションデータも手動のため不完全な部分もあり、ヒートマップにすることで実際のアノテーションがずれていたとしてもモデルが柔軟に対応しやすくなるようです。
学習
利用モデル
| BloodAxe チーム | IRAFM-AI チーム | aknk チーム |
| UNet
EfficientNet B4 |
UNet
EfficientNet |
UNet++
EfficientNet B5 |
どのチームも UNet(++) と EfficientNet の組み合わせでした。
UNetについては第3回の解説記事でも紹介されています。セグメンテーションタスクにおいては、よく使われている手法です。
IRAFM-AI チームは損失関数や最適化手法についても言及していて、彼らは複数のモデルにおいて、損失関数は Dice Loss と Focal Loss を組み合わせたものや Binary Cross Entropy を利用して、最適化手法については、Adam と AdaDelta を利用しているようです。
また、IRAFM-AI チームでは利用するモデルを決めるために、https://paperswithcode.com/task/semantic-segmentation のベンチマーク等も参考にしたみたいです。この Papers with Code というサイトでは論文と公開されているコードのURLが一緒に掲載されており、タスク別の比較もできるようになっていて、最新のモデル等を調べる際にも役に立ちます。
オーグメンテーション
今回は学習データの画像は25枚と少なかったため、どのチームも学習データを増やすためにオーグメンテーション(データ水増し)を利用しています。
| BloodAxe チーム | IRAFM-AI チーム | aknk チーム |
| Albumentationsライブラリを使用 ・random rotation by 90 degree ・random transpose ・grid shuffle ・coarse dropout ・affine shift ・rescale ・rotation ・elastic transformation ・grid distortion ・perspective distortion ・random change of brightness & contrast ・gaussian blur & noise |
強度の増強 ・multiplicative intensity shift ・cutout 空間の増強 ・flip ・rotation ・rescale ・random crops ・multi-sample mosaicing |
・random crop ・rotation ・ごま塩ノイズ ・random erase ・random flip |
全ての手法を説明すると長くなってしまいますが、BloodAxe チームが使っているAlbumentationsは色々な画像処理が可能で公式のサンプルコードを見てもらえれば、どういったことができるのか理解しやすいです。
また、IRAFM-AI チームの ‘multi-sample mosaicing’ はオリジナルの手法らしく、データサンプルをn個の長方形に分割して、その一部をトレーニングセットとは別の画像の同じ部分で置き換えることで、過学習を防ぐようです。
後処理
予測
| BloodAxe チーム | IRAFM-AI チーム | aknk チーム |
| 自作のオープンソースライブラリの Pytorch-toolbelt を利用して、大きな画像を重なるように分割してTTAで予測。 | Floating Windowという手法で重なり合う予測データを作成。 | 画像処理で抽出した海岸線を元に切り取った画像を利用。また、切り取りも重なるようにしてTTAで各予測を平均する。 |
どのチームも基本的には重なるようにテスト画像データを切り取り、それぞれの予測値を出しています。また、TTA(Test Time Augmentation)という手法はテスト時にもオーグメンテーションを行う手法で、最近の画像コンペティションでも良く使われています。重なった部分の予測であったり、TTAをおこなうことで、別の条件で予測を行い、予測結果を重ねることでも予測の外れ値の影響を小さくしたり、アンサンブル処理のように精度を上げることが可能になります。
海岸線抽出
| BloodAxe チーム | IRAFM-AI チーム | aknk チーム |
コンピュータビジョン系のライブラリを利用して次の手順で処理していく。
|
2値分類モデルの場合は各行で確率が最大の列を探してそこを海岸線とする。
3値分類モデルの場合は周りの3×3ピクセル分の予測を見て、周りに海と陸が両方含まれているのであれば海岸線とする。 全てのモデルの加重平均を最終的な予測値として作成、重み付けについてはモデルのパブリックリーダーボードのスコアを参考。 |
陸と海のラベルに分けているため、閾値で2値化を行ったあと、そのエッジ部分を最終的な海岸線として採用する。 |
最終的な出力に関しては、IRAFM-AI チーム以外はコンピュータビジョン系の処理を利用しているようです。
具体的なライブラリ等は書いてありませんでしたが、画像の細線化であれば https://scikit-image.org/docs/dev/auto_examples/edges/plot_skeleton.html であったり、エッジ検出もhttp://labs.eecs.tottori-u.ac.jp/sd/Member/oyamada/OpenCV/html/py_tutorials/py_imgproc/py_canny/py_canny.html が参考になると思います。
(5)優勝に寄与した要因
1位のBloodAxe チームの方が特に優勝するにあたって重要だった部分をまとめてくれていたので、その部分についても見ていきます。
入念なデータオーグメンテーション
特に学習データが少なかったため、人工的にデータを増やす必要があり、斑なノイズに対してもロバストに対応するためのオーグメンテーションが必要だった。しかし、Leeのようなノイズ除去フィルタは利用していない。
適切なクロスバリデーション
5fold CVで最終的に一番良いCVスコアのものを基準に提出した。
良いセグメンテーションモデル
UNetとEfficientNet B4の組み合わせが2値画像のセグメンテーションのSOTA(state of the art: その分野での最先端や最も良いスコアを出しているもの)として知られていて、Image-Netで事前に学習された重みを使用し転移学習を行い、検証した中で最も高いCVスコアを出した。
TTAとアンサンブル
推論時には上下左右反転と様々なスケールへ拡張を組み合わせてオーグメンテーション(水増し)を行い、5つのモデルの平均を取ることで、斑なノイズの影響が減り、海岸線の予測が滑らかになった。
(6)コンペティションを終えて
私自身も今回のコンペティションに参加しましたが、結果はメダル圏の手前という残念な結果でした。
特に今回のコンペティションでは、アノテーションデータからラベルデータ作成であったり、予測した結果から提出用データを作成する部分も機械学習の部分以上に苦労しました。
海岸線という線のアノテーションデータをセグメンテーションタスクとして扱いやすくするために、ヒートマップを使うなど、まったく思いつかなかった解法なども知ることができたので、また別の機会で画像データのコンペティションに挑む際には、ここで学んだ内容を活かしてやっていきたいです。
これからも Tellus Satellite Challenge や衛星データを利用したコンペティションが増えていくと思うので楽しみです。
(7)各入賞者からいただいた手法解説(原文)
各入賞者からいただいた手法解説(原文)は以下をご覧ください。
