Kaggleランカーの9人に聞いた、2022年面白かったコンペ7選と論文7選
9名のKagglerの方にアンケートにご協力いただき、2022年に面白かったコンペと論文を教えていただきましたのでその結果を紹介します。
2022年も数多くのデータ解析コンペが開催され、興味深い機械学習に関する論文が多く発表されました。
私たち宙畑は、衛星データの利活用促進を目指して活動をしているメディアですが、衛星データの量は年々増加していることから、人の目による判読では手が回らず衛星データ分野への「機械学習」の適用が進んできています。
そこで、宙畑では毎年Kaggle等のデータサイエンスコンペティションに取り組んでおられる人達にアンケートを実施し、その年の面白かったコンペや論文をまとめてきました。
Kaggleランカーの7人に聞いた、2021年面白かったコンペ7選と論文7選
Kaggleランカーの9人に聞いた、2020年面白かったコンペ9選と論文9選
Kaggle上位ランカーの5人に聞いた、2019年面白かったコンペ12選と論文7選
そして本年も9名のKagglerの方にアンケートにご協力いただき、2022年に面白かったコンペと論文を教えていただきましたのでその結果を紹介します。
(1)回答いただいたKaggler9名のご紹介
まずは今回のアンケートに回答いただいたのは以下9名のKagglerの方です。
杏仁まぜそば
YujiAriyasu
カレーちゃん
shinmura0
俺人〜Oregin〜
Hiroki Yamamoto
SiNpcw
ころんびあ
regonn_haizine
※Twitterアカウント、アルファベット順
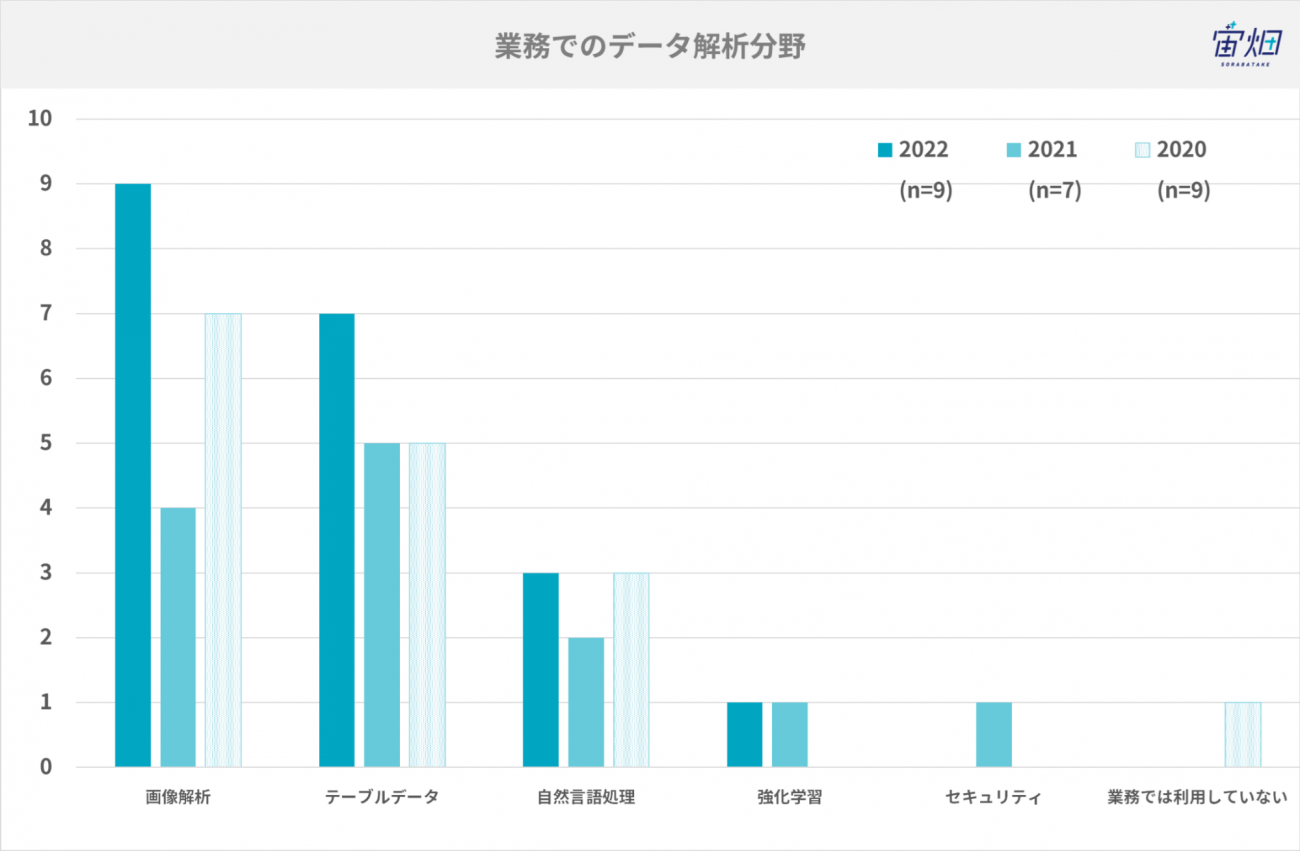
業務でのデータ解析分野
普段業務で利用しているデータ解析分野は、以下の通りです。今年は画像解析業務の方が多くいました。
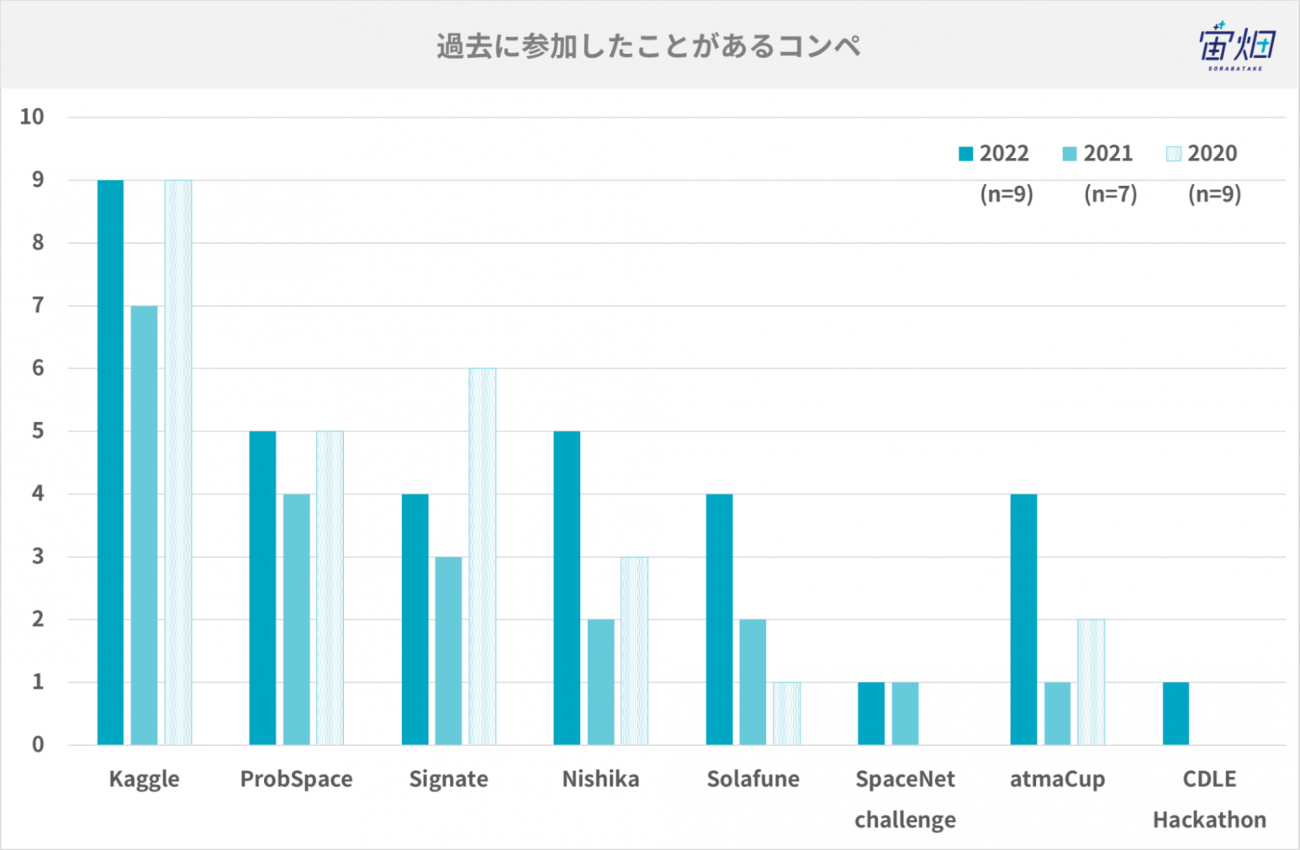
過去に参加したことがあるコンペ・コンペに参加する理由
過去に参加したことがあるコンペは以下の通りです。やはりKaggleが最も多く、次いでProbSpace、Nishikaといった国内のコンペティションに参加されている方が多いようです。今年はSolafuneやatmaCupなどに参加した方も多かったです。
続いて、コンペに参加している理由を伺ったところ、以下のような理由を回答いただきました。
・効率よく学習するため。
・自己研鑽のため
・楽しい、最先端の技術に触れやすい
・身に着けたスキルや、最新の論文に関する知識を実際のコンペに活用することで、その有用性を理解したり、新たな気づきを得たりするため。
・最新技術の習得、趣味
・機械学習の知見を得るため・データの分野に興味があるなどが理由として大きい。
・コンペに参加することが楽しいことと,勉強になるため
・コンペで競うのが面白い & データ分析能力の向上につながるので
・業務に役立てるため
コンペに参加する理由として目立ったのは「楽しいから」「知見を増やす・スキルアップのため」という理由です。
では、実際にどのようなコンペや論文を2022年は面白い、興味深いと思われたのか、回答者のお一人でもある恋言(regonn)さんに解説いただきながら紹介します。
(2)2022年、面白かったコンペ
2022年からは、自然言語(普段の会話や文章で使う言葉)のコンペティションが増えてきました。また、画像だけでなく、動画等の扱うデータ量が増えてきているのも特徴です。
画像解析
DFL – Bundesliga Data Shootout
https://www.kaggle.com/competitions/dfl-bundesliga-data-shootout
コメント@shinmura0
本コンペはサッカーの動画分析であり、推論時間が限られていた。トップsolutionは推論時間を考慮して、モノクロ画像に変換して処理していた点が面白かった。
コメント@regonn
このコンペでは、サッカーの試合動画から、スローイン等のプレイが発生したタイミングを見つけるタスクでした。Kaggleでは、推論結果のみ提出するパターンと、コードを提出して、公開されていないデータをKaggleのサーバー側で推論するパターンが存在し、このコンペティションもKaggleのサーバー側で推論しなければならないため、推論時間を短縮させるための工夫が必要だったみたいです。
Happywhale – Whale and Dolphin Identification
https://www.kaggle.com/competitions/happy-whale-and-dolphin
コメント@YujiAriyasu@aryyyyy221
課題も難しく参加者のレベルも高かったので。触れたことのない技術に触れられたのも良かった
コメント@SiNpcw
類似画像検索系のタスクの基礎的な考え方や技術を身につけるうえでとても良いコンペであること。またドメインとしてもクジラのヒレのような撮影画像は業務で扱うこともないため、新鮮さがあることが挙げられる。
コメント@regonn
イルカとクジラの画像から個体識別を行うことがテーマのコンペティションでした。多くのチームが、与えられた画像をそのまま利用するのでなく、各パーツを物体検出モデルで検出し、その画像を利用するなど工夫がされていたみたいです。
マルチ解像度画像の車両検出
https://solafune.com/ja/competitions/25012781-b1e8-499e-9c8c-1f9b284d483e
コメント@Oregin2
航空写真のデータから車両を検出するというタスクだったのですが、航空写真が用意されている点もさることながら、画像データの中でどの範囲が車両なのかというアノテーションを実施してあるデータに対して分析できるということで、非常にお得感のあるコンペでした。
個人でこのような分析を実施する場合、データ収集にもアノテーションにも多大な労力を要するので、このような興味深いテーマに簡単に取り組める点で非常にありがたいコンペでした。
コメント@regonn
Solafuneは衛星データを利用したコンペティションをメインに開催しています。今回のコンペティションで特徴的なのは、解像度が異なるデータセットが利用されていることです。一般的に衛星データ等で精度を上げるためには、なるべく同じ解像度のデータをつかうことが多いですが、複数の解像度に対応できる機械学習モデルであれば、異なるデータリソースからデータを調達することが可能で、衛星データ分析の際にも利便性が上がります。
Sartorius – Cell Instance Segmentation
https://www.kaggle.com/competitions/sartorius-cell-instance-segmentation
コメント@tereka(Hiroki Yamamoto)
Instance Segmentationについて論文を読んだことはあったが、実際に取り組んだのははじめてでした。画像に物体が大量にあるコンペであり、様々なことを試して面白かった。
コメント@regonn
このコンペティションでは、アルツハイマー等の病気に対する創薬に役立てる目的で、投薬における試験細胞の反応を見分ける内容でした。Segmentationでよく使われる、COCOというデータセットでも一枚の画像に100個程度でしかオブジェクトは存在しませんが、このコンペティションのデータでは一枚の画像に500個以上のオブジェクト数が存在しており、そういったモデルのパラメータの変更なども考慮する必要があるみたいでした。
Data Purchasing Challenge 2022
https://www.aicrowd.com/challenges/data-purchasing-challenge-2022
コメント@regonn_haizine
このコンペティションでは塗装された金属板の製造上の損傷の画像分類タスクなので、データ自体はそこまで珍しくはないです。しかし、このコンペティションでは購入フェーズというものが用意されていて、初期の学習用のデータセットとは別に教師データのない金属板の画像のなかから決められた枚数を自分で選んで学習データに利用することができます。
これは、普段の機械学習での業務でも学習用データは無料で手に入るものではなく、コストをかけたり、ノイズがあるものを取り除いたりしないといけない作業に似ていて、モデルの精度だけでなく、限られたコストのなかで必要な学習データを手に入れることができるかも考えてモデルを作成しなければならないコンペティションで今までにない形式だったので興味深かったです。
テーブルデータ、自然言語処理
Foursquare – Location Matching
https://www.kaggle.com/competitions/foursquare-location-matching
コメント@currypurin
位置情報が与えられて、同じ位置のものがあるか予測するコンペでしたが、このタスクはこれまでにないタイプのコンペであり、またデータ数も多いためGPUを使用しての高速なマッチング判定も求められました。
そのためコンペの期間中に検討することがとても多く、またコンペ終了後にコンペの解法を参考にして取り組める応用例も多く、面白いコンペでした。
コメント@regonn
このコンペも推論はKaggle上で行う必要がありました。巨大なデータの中から同じ位置である情報を位置情報や登録された建物名等とマッチングさせて探してくるため、限られたリソースの中でテーブルデータと自然言語処理を同時に扱い、いかにモデルの軽さと精度のバランスを取るかが求められるコンペティションでした。
自然言語処理
NBME – Score Clinical Patient Notes
https://www.kaggle.com/c/nbme-score-clinical-patient-notes
コメント@an_nindouph
言い換えの抜き出し問題という珍しい問題設計だったから
コメント@regonn
米国の医師免許試験において、患者の症状のメモを取る試験があり、受験者はテスト患者から症状を聞き出して患者メモを取り採点者が採点するのですが、採点作業には多大な時間と人的・経済リソースを必要とするため、作業コストを軽減させるための取り組みとしてのコンペティションでした。タスクでは「食欲減衰」のような臨床概念と、メモに書かれている様々な表現方法(例: 「食事量が少ない」「服がゆったりしている」)を対応づけていきます。実際に人が書いたものから該当する部分を見つけるため、表記揺れ等にどう対応していけるのかが求められるコンペティションでした。
Feedback Prize – Evaluating Student Writing
https://www.kaggle.com/c/feedback-prize-2021
コメント@ころんびあ
自然言語処理における固有表現抽出のタスクで,通常のBERTやRoBERTaでは扱えない長い文章を処理する必要がありました.そのため構造が違う言語モデルを検討することや,後処理を工夫する必要があるところが面白く,上位の解法が多様だったのも楽しめるポイントでした.
その後の言語処理コンペで使われるようになったDeBERTa系のモデルやAdversarial Weight Perturbation(AWP)などが上位解法で採用されており,コンペに参加しながら学べるところも多かったのがよかったです.
コメント@regonn
学生が書いた文章が与えられて、それぞれの文が、論証的な文章のどの部分(序論、主張、反証等)にあたるのかを分類していくタスクでした。単純に段落毎に分類されるだけでなく、段落内でも複数の要素に分類されているため、モデルのアンサンブル等をするにしても、平均をどう扱うか等の推論後の処理にも工夫が必要になるコンペティションでした。
(3)2022年、面白かった論文
前年である2021年の面白かった論文は全て画像解析に関連していましたが、2022年では、そこから更に発展して、画像解析や自然言語処理の論文が注目を集めたようです。
Multimodal Data
Learning Multimodal Data Augmentation in Feature Space
https://arxiv.org/abs/2212.14453
コメント@currypurin
この論文では、マルチモーダルデータのAugmentationについて、複数モーダルの情報を使ってAugmentationをすることを提案しています。マルチモーダルデータについてはAugmentation手法が確立されていないと思うので、更に発展して欲しいと思い、面白いと思いました。
コメント@regonn
Kaggleでも最近は、画像のみ等のコンペティションから、画像や自然言語処理を組み合わせたようなマルチモーダルデータでのコンペティションが増えてきました。そのときのAugmentation(学習データのかさ増し)する際には、色々と注意が必要になってきます。例えば「右を向いた人」という言葉と画像のデータがあったとして、Augmentationで画像を反転してつくった際に「右を向いた人」と画像では矛盾したデータになってしまう可能性が高いです。こういった問題を防ぎつつ、データを増やしていけるような手法は、今後も重要になってくると思われます。
画像解析
Training Vision Transformers with Only 2040 Images
https://arxiv.org/abs/2201.10728
コメント@shinmura0
今や当たり前のように使われているViTについて、少量の学習データでも十分な精度を示したと報告する論文。技術的には、従来からある技術(ラベルスムージング)を使っているが、少量のデータ量でも学習できたことを示しているところが面白い。
コメント@regonn
ViT(Vision Transformer) については宙畑の記事でも以前取り上げました。【コード付き】画像用Transformerを利用して衛星画像の分類機械学習モデルを作成する
ViTは畳み込みニューラルネットワーク(CNN)よりも、採用される機会が増えましたが、ImageNetといった大規模な画像データセットで事前学習をすることが多く、この論文では、2040枚の画像という限られたデータでの条件下でのトレーニング方法を扱った内容でした。最近はデータセットも規模が大きくなっていく傾向にあるので、必要データ量を少なくできる研究が進んでくるとコストの改善が期待されます。
A ConvNet for the 2020s
https://arxiv.org/abs/2201.03545
コメント@YujiAriyasu@aryyyyy221
現状最強の画像モデルConvnextの論文。Transformerのアイデアも入れつつCNNの集大成的なモデルになっています。SwinTransformer派だったんですが、今はConvnext派です。浮気してごめんねCNN
コメント@regonn
CNNからViTへと移り変わりつつありますが、CNNにモダンな設計を取り入れて、過程の性能差を追っていくことで、どのコンポーネントが寄与しているかを調査しつつ、CNNのシンプルさと効率性を維持しながら、COCOの物体検出タスク等において、Swin Transformerより優れた性能を実現しています。どのようにモデルを修正していくと、精度が良くなっていくのかが段階的にわかるようになっていて、そういったところも面白いです。
Optimal Correction Cost for Object Detection Evaluation
https://arxiv.org/abs/2203.14438
コメント@Oregin2
従来のmAP(Mean Average Precision)という評価指標に比べ、余分な検出に対してもペナルティを積極的に与える、画像1枚に対する検出においても精度が評価できる、分類の誤差と領域の誤差の評価を同時に行えるなどの利点があり、実際につかってみて、とても効率的に評価を行うことができたので、有意義な論文でした。
コメント@regonn
Solafune の マルチ解像度画像の車両検出で利用された手法です。Oreginさんの宙畑での記事や、論文著者の方が日本語での解説記事を公開されています。 既存の物体検出の評価で多く利用されている、mAPの問題点等を取り上げて、新たな評価方法を提案しており、今後の物体検出タスクにおいて評価指標のスタンダードになっていくかもしれません。
Registration based Few-Shot Anomaly Detection
https://arxiv.org/abs/2207.07361
コメント@tereka(Hiroki Yamamoto)
異常検知を汎用的に実施できるモデルを作成する手法の論文です。
異常検知はデータセットも少なく、比較的特殊な問題設定で難易度も高いので技術的な興味があった。
コメント@regonn
従来の異常検知では、カテゴリ毎に再学習(またはFine Tuning)の必要がありましたが、カテゴリ依存をなくして、データ量を抑えることに成功している内容でした。実際に異常検知のデータを収集する際にもデータ量には制限がある場合が多く、そういった点でも重要な研究です。
Robust fine-tuning of zero-shot models
https://arxiv.org/abs/2109.01903
コメント@SiNpcw
学習中に出力したモデルパラメータを混ぜ合わせるだけというシンプルな手法でありながら、 論文に記載されているようにZero-shotでの汎化性能を上げる効果が得られる手法である。実装としてもPyTorchであれば数行のコードで実現できるという非常に簡単なものであり、実際にGoogle Universal Image EmbeddingコンペなどでもViTモデルと合わせて使用して効果もあったこともあったことから非常に興味深いテクニックだと感じた。
コメント@regonn
CLIPやALIGNといった大規模な事前学習モデルでは、zero-shot(特定のデータセットでのFine Tuning無しの状態)でも様々なデータ分布に対して一貫した精度を出せていますが、既存の Fine Tuning の手法だと、分布の異なるテストデータの場合に精度が出ない場合があり、そういった既存の Fine Tuning での弱点を、Fine Tuningモデルと元のモデルの重みをアンサンブルすることで、Fine Tuningのみをした場合に比べて、分布の異なるテストデータ等に対しての精度を上げることができているみたいです。計算コストを増加させることなく、既存のFine Tuningに追加できる手法のため、利用できる場面も多いと思います。
Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
https://arxiv.org/abs/2201.05989
コメント@regonn_haizine
2022年には、Instant NeRF を始めとした、3D生成関連の論文等が多くなってきた気がします。Stable Diffusion のような2次元画像生成はある程度精度が出てきて、その次の3次元(3D)でのデータ生成系は今も盛んに新しいサービスや論文が出てきています。この Instant NeRF は NVIDIA の研究チームが出したもので、NeRF(Neural Radiance Fields)という、複数の角度から撮られた写真から、3Dの物体を生成するためのニューラルネットワークを利用した既存手法を並列化や汎用性を高めることで、学習スピードをタスクによっては1000倍にも早めることを実現した手法でした。
コードやモデルも公開されて、このモデル公開をきっかけに、写真から3D空間を作り出し作品を公開していく人も多く見られました。
最近だと、文章などから3Dモデルを生成できるようになるなど、StableDiffusionの3次元モデル版のサービス等も出てくるようになりました。ここらへんの3D生成の精度が上がってくることで、メタバースといった他の分野のビジネスへも色々と波及していきそうな内容だと思って情報を追っています。
自然言語処理
DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing
https://arxiv.org/abs/2111.09543
コメント@ころんびあ
DeBERTaV3の論文です.DeBERTa自体,コンペでの使用感的に従来の言語モデルよりも学習させやすく,精度が出やすい,またAttention構造の改良によって長い文章長でも処理できる点が魅力です.DeBERTaV3はそのDeBERTaの事前学習を改良することにより,同様の構造を持つモデルよりも高い精度を達成できたモデルです.
2022年の言語コンペでは幅広く使われて,長い文章長を扱う必要がある固有表現タスクのFeedback PrizeやNBME,またプログラミング言語も扱う必要があるAI4Codeでも上位解法で使われており,特に,優勝解法では推論時に最大トークン長を5000以上に設定したdeberta-v3-largeが使われていたのが印象的でした.
コメント@regonn
DeBERTa はマイクロソフト社が開発しているモデルで、コードがオープンになっていたり、他の大規模モデルと比較して、パラメータ数が少ない等の理由から扱いやすく、日本語で学習し直したモデルが公開されていたり、Kaggleのコンペティションでも利用されることが多いモデルです。その、DeBERTa の最新バージョンが v3 であり、今後も利用されていきそうです。
自然言語処理, 深層学習全般
Adversarial Weight Perturbation Helps Robust Generalization
https://arxiv.org/abs/2004.05884
コメント@an_nindouph
(2022年発の論文ではないですが)深層学習に取り入れることが容易で、汎用性がある。性能改善をすることが多く、必ず試したいものとなっている。
コメント@regonn
頭文字を取ってAWPと呼ばれる手法で、Kaggleでもよく利用されています。ニューラルネットワークの重みを更新する際に誤った選択をしやすくなる場合(敵対的に摂動された例)を一緒に学ぶことで、精度を改善しやすくなります。コード的にも追加しやすく、試しやすい手法です。
(4)2022年、面白かったサービス
今回から、更に注目のAIサービスもアンケート調査項目に追加しました。AIを普段扱っている人達が注目するサービスにはどのようなものがあるでしょうか?
ChatGPT
https://openai.com/blog/chatgpt/
コメント@an_nindouph
質問への応答が革命的に改善されたのを感じる。まだ荒いところもあるが、未来の検索にとってかわるシステムのプロトタイプのように感じる。
コメント@tereka(Hiroki Yamamoto)
これまでここまで高精度なチャットボットが公開されることはなかった。
応用の幅が広く、AIをどう使っていくのかをAIエンジニアのみならず一般的なユーザも考える必要が出てきた。
コメント@SiNpcw
LLMにテキストチャットを介して質問することで、そしてそれらしい回答を実現できている。いままでの言語モデルでは満足に解決できないこともあったように思う。しかしChatGPTではかなり適切と思われる回答が返されることも多く、世間一般でも話題になるレベルのものに仕上がっている。課題として論理的ではない回答をすることがあることや、誤りが含まれていても断定的に答えるなどがあるが、用途次第では十分に使えるものであるため。
コメント@currypurin
チャットでAIに質問したり、お願いしたりして回答をもらえるという夢のようなサービスで、これまでのAIと比べると、満足度やできることの多様さが1つ上の段階になったと思ったので。
コメント@regonn
今までのAI系のサービスに比べても急激に一般層へも普及したサービスだと思います。私も普段の業務で利用しています。
Midjourney
コメント@shinmura0
機械学習技術単体で、ビジネスとして成功しているのが面白い。従来では、機械学習は何かのサービスに付随して使われていたが、このサービスは機械学習技術一本で勝負できているところが斬新。
コメント@regonn
Midjourney は Stable Diffusion が使われている Dream Studio と同じく、画像生成系のサービスです。Midjournery は Discord 上で動き、プロンプトと呼ばれる文章を入力することで、画像を生成してくれます。学習コストに何億もかかる大規模モデルですが、それを利用して、精度の高い画像を出力してくれます。あくまで傾向ですが、Stable Diffusion は写真のようなリアルな画像で、Midjourney はイラストのような画像生成が得意です。
TURING
https://www.turing-motors.com/
コメント@YujiAriyasu@aryyyyy221
創業から1年ちょっとで車販売!twitterで日々の躍進を見ているのがもう面白いです
コメント@regonn
コンピューター将棋のPonanzaの作者である、山本一成氏が共同創業者の会社です。We overtake Tesla をミッションとして、急成長しています。
mimic
コメント@Oregin2
画像をアップロードすることによって、AIがその特徴を学習し絵柄や画風といった“描き手の個性が反映されたイラストメーカー”を作成できるというサービスでした。8月29日にベータ版がリリースされた際、「悪意のある第三者が他人の作品を学習させ、画風・絵柄を模倣したイラストを自身の作品として利用するのではないか」という懸念から批判が殺到しました。ガイドライン上では「他人のイラストを勝手にアップロード」する行為は明確に禁止されていたものの、社会的な影響を鑑み僅か1日でサービスを停止するということになりました。これらの経緯も含め、AIにおけるサービスにおいて、様々な面でのリスクを検討し、適切に対処するための「AIガバナンス」が非常に重要であると、改めて感じさせられたサービスでした。
コメント@regonn
AIと著作権の問題は切り離しにくく、すでに紹介された Stable Diffusion や Midjourney も学習に利用したデータについての集団訴訟が提起されています。また、今後もAIで作られたものの著作権等、色々と法律との問題や社会的責任が求められそうです。
Github Copilot
https://github.com/features/copilot
コメント@ころんびあ
単純にコーディング作業が楽になり,大規模言語モデルを用いた文章(コード)生成系サービスの先駆けとなったサービス?だったため.
コメント@regonn
コード管理を行うGithubのサービスで、学習するためのコードデータが揃っており精度も高く、親会社のマイクロソフト社が提供する、VSCodeエディタで利用できるため普及しやすかったと思います。私も、普段のプログラミング作業で利用していて、メソッド名やコードコメントを先に書いておくと、そのコンテキストに適したコードが推論されて、コーディング作業がとても捗ります。
Luma AI
コメント@regonn_haizine
論文でも取り上げましたが、NeRFという技術を使った動画や画像から3Dオブジェクトを生成してくれるサービスです。どうしても画像等から3次元のモデルを生成する場合に、背景や地面との境目がノイズになってしまい、ゲームエンジンに取り込む際に処理が必要になってきますが、この Luma AI では、他のサービスに比べて、物体の切り抜きやノイズが少なく、光沢等も表現できていて、他のサービスよりも一歩進んでいる気がします。さらに、テキストからの3次元モデル生成サービスも公開されつつあるので、色々と興味があります。
(5)今後のデータ解析コンペや技術への期待と目標
最後にKagglerの皆様に今後のコンペや技術への期待や目標をお伺いしました。
今後どのようなコンペがあると面白いと思いますか?
様々なアイデアがありましたが「マルチモーダル」「生成系」はキーワードとなりそうです。
・画像+音+テーブルデータで構成されるマルチモーダルなコンペ
・入出力の形式が珍しいものやマルチモーダルなデータを扱うもの。そういう意味では地理空間情報の題材はなかなか良いように感じる。ただし参加障壁も高くなるので質の良いベースラインのコードの有無がコンペの盛り上がりを分けそうである。
・工夫のしがいがあるものであれば割となんでも。難しいのがいいです
・AIを作成するAIのコンペがあると面白いと思います。
・AI生成(例:StableDiffusion) VS 人間を見分けるコンペ
・話題もそれなりに未だあり、社会的な意義があると思います。どこまで汎用的にAIを見分けられるのかが重要になるので問題設定をうまく作れば面白いと思います。
・人間の声を認識しその回答や出力の精度を競うコンペ。評価方法の設計が難しいが、業務としてありがちな議事録や要約作成、コールセンター対応など、多くの社会課題を解決につながるコンペになるように思う。
・大規模言語モデルを始めとする基盤モデルの小型化(処理速度をメインとした評価指標で)
・複数のタスクからなるzero-shot learningコンペとかあっても面白そう(特定のプロンプトが与えられて,画像ならセグメンテーションやクラス分類などを行うようなコンペ?)
・チャットボットや汎用人工知能をテーマとしたデータ分析コンペが行われると思いますし、面白いと思います。
・評価は難しいですが、生成系のコンペが増えてくると、見ている方も楽しめるコンペになる気がしています。
今後どのような技術が生まれると面白いと思いますか?
2022年はChatGPTやStable Diffusionなどサービス化したAIが多く生まれた年でもありました。結果としてその先の技術を期待する声が多かったです。
・データ分析のトピックからは若干ずれますが、自然言語というプロトコルではなく、何か効率の良い概念伝達手段が生まれると良いと思う。人間の思考を補助したり、学習を支援したりするのが圧倒的に効率化される。
・動画生成AI
・シンプルに精度があがるのが一番嬉しいです
・AIが自らAIを作成する技術
・低リソース、低時間で実現できる強化学習。
・現行のはどうしても資材・時間がかかるので、短い時間である程度の精度を担保できるようになると面白い応用例が出てくると思います。”
・ChatGPTやStable DiffusionなどからAIでテキストやイラストを生成するエンターテインメントに近しい分野ではかなり広まったと考えている。特にイラストなどの部分ではほぼ人間が書いたかどうかが区別がつかないものとなっている。今後は他分野においてもそういった人間と差がないレベルであったり、出力として論理的で破綻のない回答をするモデルなどを実現する技術が生まれると面白いと考える。
・ChatGPT系のモデルが単一GPUで動くぐらいの量子化や蒸留技術,新しいモデルなどが提案されると嬉しいなと思います.
大規模言語モデルの発展も嬉しいですが単一GPUで学習から推論が可能な比較的小さな言語モデルもどんどん発展していけば何よりです(また日本語言語モデルも発展していってほしい)
・現在、大規模言語モデルと呼ばれているものが、軽量化してスマホデバイスで動くようになりそして音声で指示できるようになると、全員が手元でこのAIに質問したり、作業をお願いできる状況となり、これまでとは違う世界になりそうで面白そうです。
・基本的に、どのモデルもGPUを大量に消費するので、精度を保ちつつ省エネGPUモデル等が出てくると、更に普及もしやすくなるのかなと思います。
2022年の目標を教えてください
Kaggleでのさらなる飛躍や、そこで得た知見の適用、もっと別の分野への興味を広げている方もいらっしゃいました。
・様々な形式のデータに触れてみたいです。
・Kaggleのグランドマスターになること
・NLPや強化学習にも目を向けたいです
・これまでは、論文を読んだり、コンペに参加する側でしたが、2023年は論文を発表したり、コンペで利用していただける技術を開発したりできる1年としたいです。
・KDDやRecSysなど今までやったことない学会やコンペに参加して技術の幅を広げたいです
・ChatGPTの登場などでまた大きな波が起きる可能性があると感じている。そのため、世間のAI技術動向を追いつつ、興味のある分野やデータのコンペ参加を通して自身の分析技術を磨いていきたいと思う。
・データ分析コンペとしても戦い方やコンペのタスク自体が変わりそうな年なので新しい技術を身につけていけばいいなと思います.
・競技プログラミング頑張ります!
・仕事はChatGPTに奪われていきそうなので、生成系で色々な作品を作っていきたい。
(6)Kagglerの皆様に聞いた衛星データ使ってやってみたいこと
最後に、本記事を掲載している「宙畑(そらばたけ)」が宇宙ビジネスメディアということで、「衛星データ」についてもお伺いしました。地球規模での課題解決や3Dデータへの取込みなどでコメントをいただきました。
・衛星画像などの情報から3Dデータに復元できたらかなり夢がある。広範囲で高度な気流シミュレーションなどにつながりそうだと感じた。また、電波のアンテナを設置するのに最適な位置を求めるといったタスクにも使えそうである。
・衛星データとテーブルデータを組み合わせたマルチモーダルなコンペ
・衛星データを使った広域での防犯
・画像を用いた交通量把握(車の数計算で可能?)、駐車場にどの程度車がある、人がどの程度いる、道路に何台の車があるなど、衛生データから得られて活用できる情報は多い。
・衛星画像から天候や雲量から対象地域の日照条件を割り出すことで作物の収穫量予測や品質・出来などが予測できると面白いかもしれない。航空や漁業向けとして衛星画像から海上の気流・気象変化などをより精緻に算出できないかなどを取り組んでみたい。
・Plateauのデータと合わせてのデータビジュアライゼーション
(7)2022年に開催された衛星データコンペ
SpaceNet8: Flood Detection Challenge Using Multiclass Segmentation
世界的な衛星データを使った機械学習コンペを行っているSpaceNetでは第8回として、洪水で冠水した道と建物の検出をテーマにコンペが開催されました。
コンペで用いられたデータやアルゴリズムも公開されています。
Flood Vulnerability Detection Challenge Using Multiclass Segmentation
Rainfall prediction with satellite image information / kaggle
今回アンケートに回答いただいた方も多かったkaggleでは、衛星の赤外画像を元に、降水予測を行うコンペが開催されました。
CS273A Data Competition at UCI, Winter 2022 | Kaggle
AI:ML Coding Challenge for 8,860,1.00: Machine Learning, FS22. Satellite image classification. / kaggle
衛星のマルチスペクトル画像(様々な波長で撮影された画像)から土地被覆分類を行うチャレンジです。
8,860,1.00: Coding Challenge | Kaggle
マルチ解像度画像の車両検出 / solafune
日本ではsolafuneが、解像度の異なる衛星画像を使った車両の検出コンペを実施しました。
宙畑ではコンペに参加された方のチャレンジログの記事を公開しています。
異なる解像度の衛星画像から車両検出するコンペSolafuneのチャレンジログ
(8)まとめ
本記事では、Kaggler9名の方にご協力いただき、2022年の面白かった機械学習コンペや論文についてご紹介をしました。
機械学習×衛星データというテーマで実際に手を動かしていただけるサンプルコード付きの記事も連載で公開しています。
衛星データ×機械学習タスクの代表的な分類まとめ~物体検出、セマンティックセグメンテーション、画像分類、超解像~
衛星データからの石油タンク検出①データ前処理とYOLOXを使った学習
衛星データからの石油タンク検出② Tellusの衛星データ用いて検出結果を確認する
また、宙畑では2022年8月より、衛星データと機械学習に関する論文を毎月まとめて紹介しています。興味があればこちらもぜひご覧下さい。
その中でも特に、衛星画像や航空写真を使った地上位置の推定の論文が増えてきたため、こちらについては関連論文をまとめています。
