解析実例とともに学ぶNDVI(正規化植生指標)の基本と扱う上での注意点【コード付き】
衛星データの解析で度々利用されるNDVI(正規化植生指標)について、実践形式でまとめてみました。衛星データをまずは触ってみたいという方はぜひご覧ください。githubも準備しています。
衛星データの解析でよく利用される正規化植生指標、通称 NDVI (Normalized Difference Vegetation Index) 。
しばしば衛星データの解析で使用する NDVI ですが、このNDVI がどのような振る舞いをするのか、また、利用においての注意点や弱点、モデリングパターンをを実装レベルで本記事では紹介します。
リモートセンシング、特に農業分野や森林資源監視ではNDVIの活用が多いので、それらの用途でのサービス化を検討する際は、ぜひ参考にしていただけますと幸いです。
※NDVIについての説明や事前知識は「衛星で農作物の生育状況を把握!農業分野で利用が進む「植生指数時系列情報」の使い方」や「光の波長って何? なぜ人工衛星は人間の目に見えないものが見えるのか」をご覧ください。
衛星で農作物の生育状況を把握!農業分野で利用が進む「植生指数時系列情報」の使い方
光の波長って何? なぜ人工衛星は人間の目に見えないものが見えるのか
NDVI の算出と利用する上での3つの注意点
今回利用する衛星データはNDVIがよく利用されるSentinel-2と光学衛星最高解像度のMaxar WorldViewです。
まずは Sentinel-2 の Python の読み込みをします。
PATH_5_2_B4 = './sentinel-2/5_2/B04.jp2'
PATH_5_2_B8 = './sentinel-2/5_2/B08.jp2'
img_b4 = cv2.imread(PATH_5_2_B4, cv2.IMREAD_ANYDEPTH)
img_b8 = cv2.imread(PATH_5_2_B8, cv2.IMREAD_ANYDEPTH)
img_b4.shape, img_b4.dtype出力:((10980, 10980), dtype(‘uint16’))
次に Maxar の場合の Python 読み込みです。
PATH_MAXAR = './maxar/20APR04014122-S2AS_R1C1-015150647030_01_P001.TIF'
img = tifffile.imread(PATH_MAXAR)
img.shape, img.dtype 出力:((4, 16384, 16384), dtype(‘uint16’))
NDVIの計算式は以下のようなものになっています。
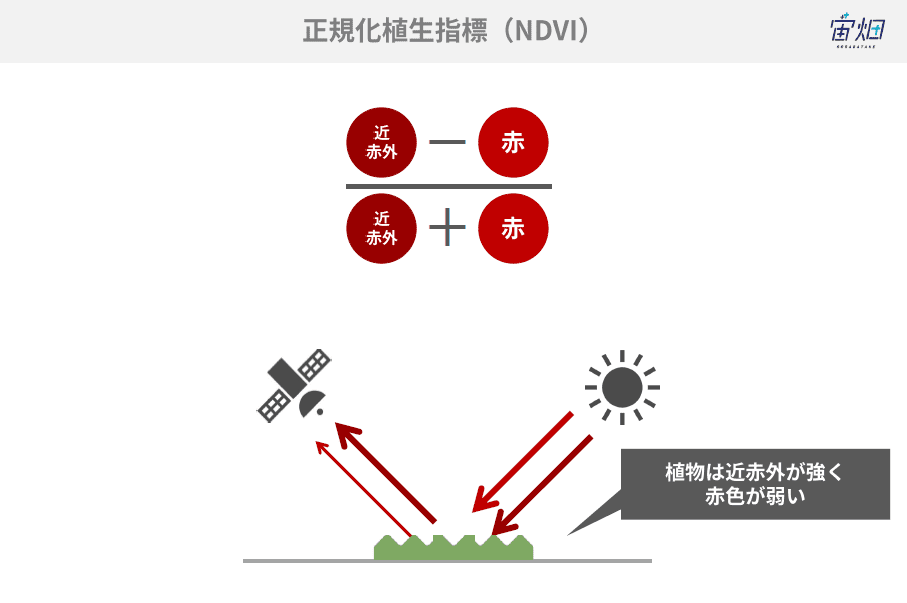
計算式の考え方について詳しく知りたい方は、以下の記事をご覧ください
課題に応じて変幻自在? 衛星データをブレンドして見えるモノ・コト #マンガでわかる衛星データ
各衛星データについて、先ほど紹介したNDVIの計算式を実装すると以下のようになります。
Sentinel-2
ndvi = (img_b8 - img_b4) / (img_b8 + img_b4)Maxar
ndvi = (img[3, :, :] - img[2, :, :]) / (img[3, :, :] + img[2, :, :])ここで、衛星データを利用する上で注意すべきことが3つあります。
1つ目はバンドの扱いです。Sentinel-2はバンドごとに保存されている一方で、Maxarはバンドがまとめて保存されています。このように、バンドの扱いは、プロバイダーや衛星画像の処理レベルによって変わってきます。
処理レベルについては「【図解】衛星データの前処理とは~概要、レベル別の処理内容と解説~」で詳しく解説しています。
2つ目はデータ型です。Sentinel-2とMaxarのいずれも、Numpy の型では uint16(符号なし整数型)です。NDVIのような負の演算が含まれる場合は必ず型をマイナス計算できるように変更してあげましょう。NDVIの値が1を超えるような場合は大抵この間違いが多いです。
具体的には以下のように型を変更します。
Sentinel-2
# 型の変換
img_b4 = img_b4.astype(np.float32)
img_b8 = img_b8.astype(np.float32)Maxar
# 型の変換
img = img.astype(np.float32)3つ目は値の前処理です。観測データには観測の問題や地理空間処理の都合などにより欠損値が出てきます。例えば、NaN などです。
他にも、欠損値ではなくてもNDVIの計算は除算なので分母に0が含まれていると以下のような警告が出て正しく計算ができていない場合があります。
RuntimeWarning: invalid value encountered in divide
知らず知らずの内に間違った値を使用して衛星データの解析を行ってしまわないように基本的な前処理を行います。
Sentinel-2
# NaNの値を0に変換
img_b4[img_b4 == np.nan] = 0.
img_b8[img_b8 == np.nan] = 0.
# 非負値に変換
img_b8[img_b8 < 1.] = 1.Maxar
# NaNの値を0に変換
img[np.isnan(img)] = 0
# 非負値に変換
img[img < 1.] = 1.これでようやく正しくNDVIの計算ができます。
基本解析
まずは、Sentinel-2とMAXARのそれぞれでNDVIを可視化する基本解析を紹介します。
・Sentinel-2の画像でNDVIを確認する
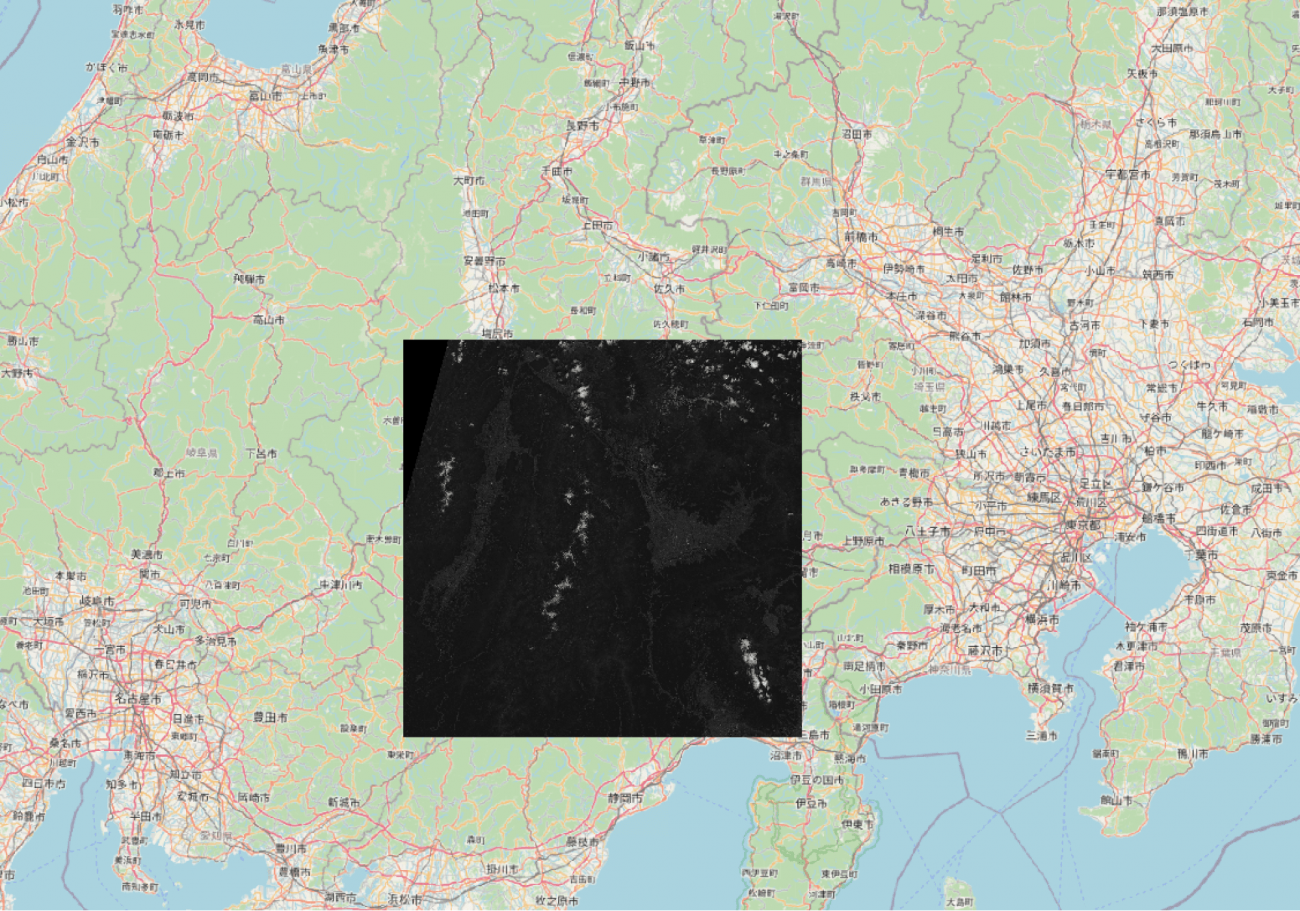
Sentinel-2 の衛星データでNDVIを確認する場所は中心座標 WGS84 (254443,3944471)で、静岡県の北部から北にかけてです。
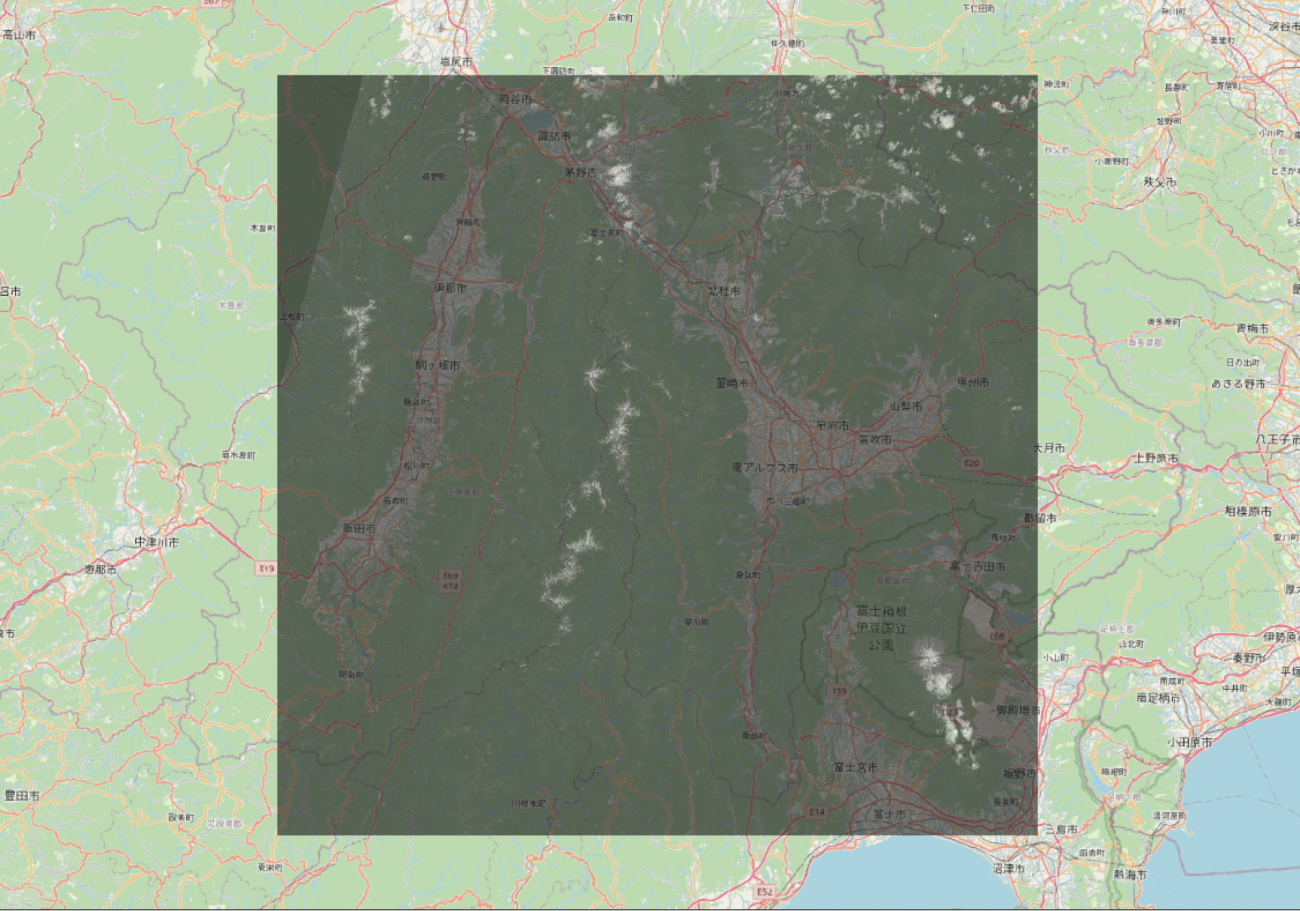
地形情報としては山岳地で渓谷には市街地や湖も含まれるエリアであることが地図からわかります。
Python 上でNDVIを可視化してみた結果が以下です。
plt.imshow(ndvi, cmap='YlGn')
plt.colorbar(shrink=0.5)
NDVI値の分布も可視化してみましょう。
plt.hist(ndvi.ravel(), bins=200, range=(-1, 1))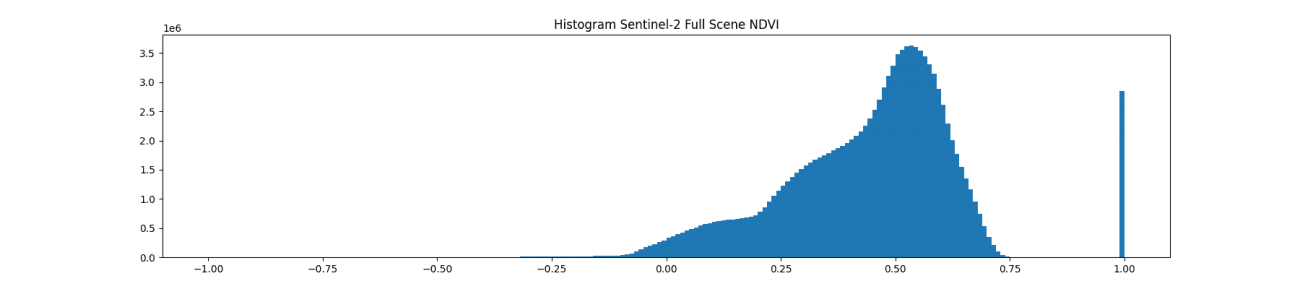
右端の1に近い値が多いように見受けられますがこれは前処理で赤外波長のみ欠損値を1にしたためです。NDVIが0周辺にも分布が点在するので前処理段階では0に置換するとヒストグラム上で見分けが付きにくくなるのでお勧めしません。
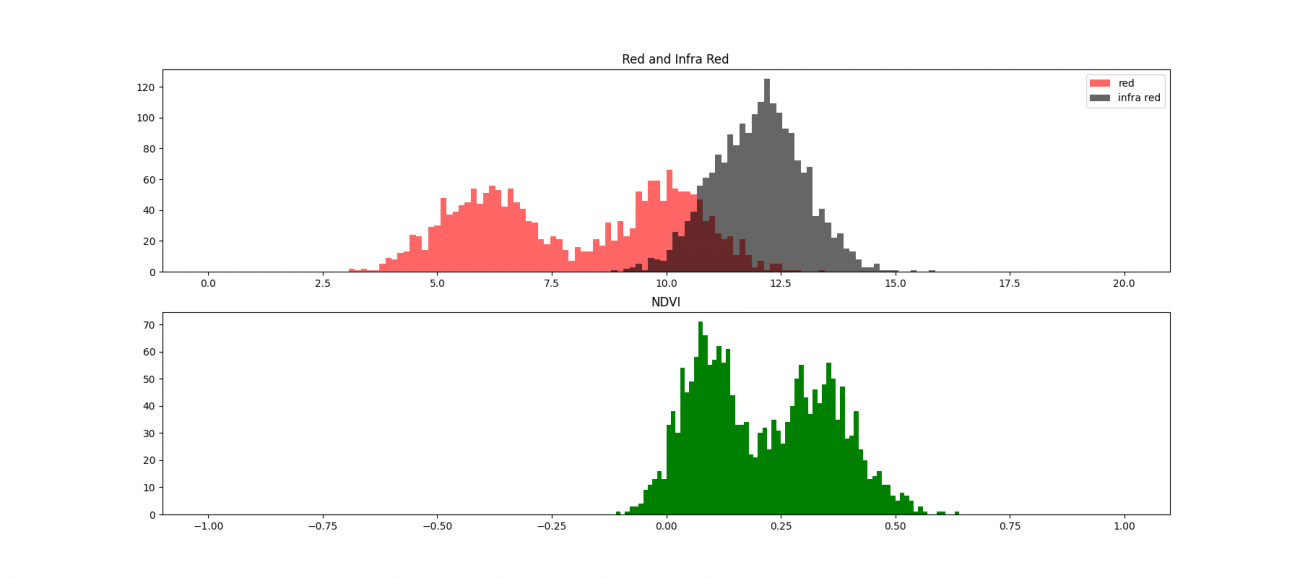
ところで、上で示したNDVIの値の分布が少しいびつな形になっていることが気になりませんか? NDVIの分布をみると、ほとんどの場合が多峰性分布になっています。それは赤色波長と近赤外線波長の値の山に差がある部分と差がない部分があるためです。特にこの差は植生によく見られるため、植生指標にもなっています。
植生を少しずつ増やした場合の赤色波長の分布とNDVIの分布のシミュレーションをすると以下の図になります。
赤色が赤色波長で黒色が近赤外波長、緑色がNDVIのそれぞれ分布です。植生を増やして赤色波長が吸収されて減る変化とそれに伴ってNDVIの値も増加する経過をみています。
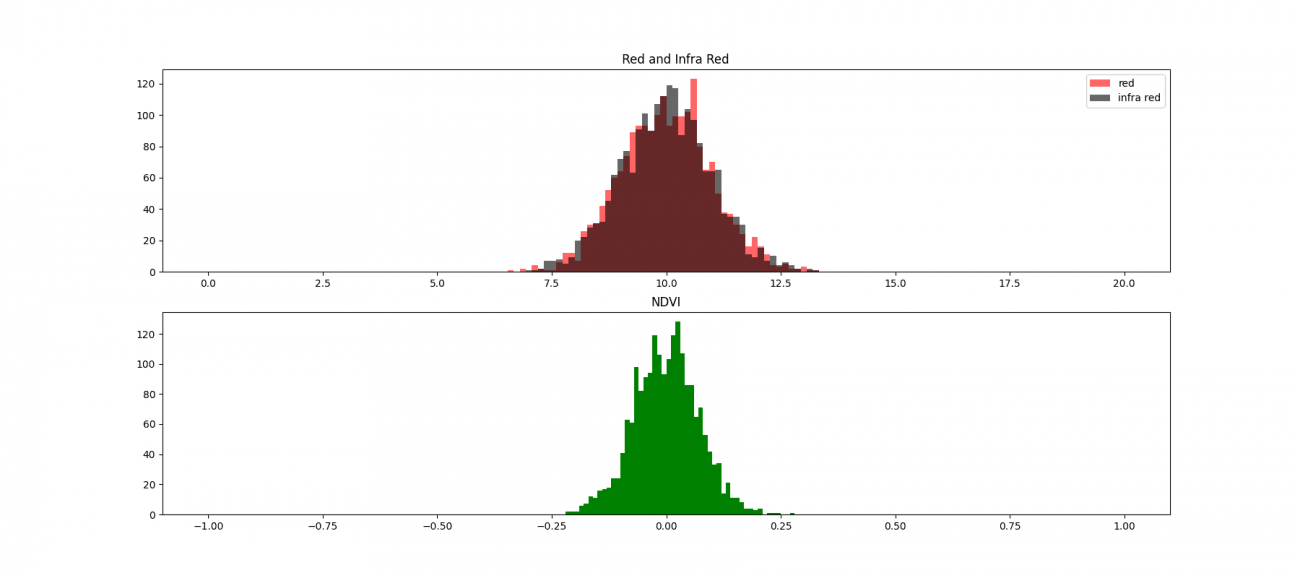
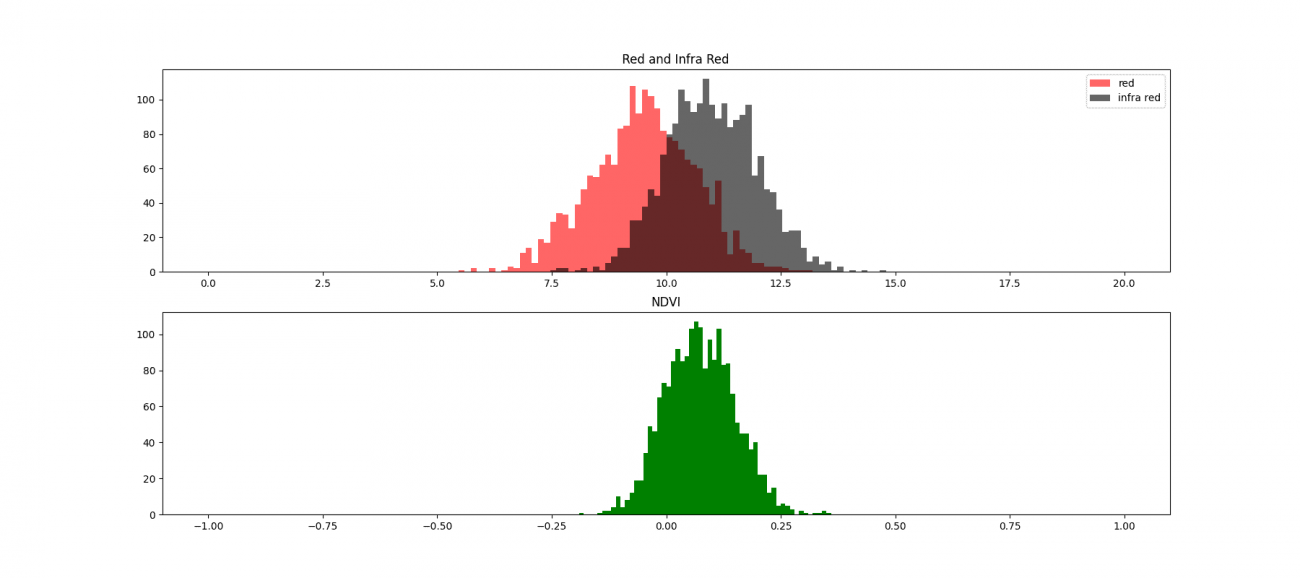
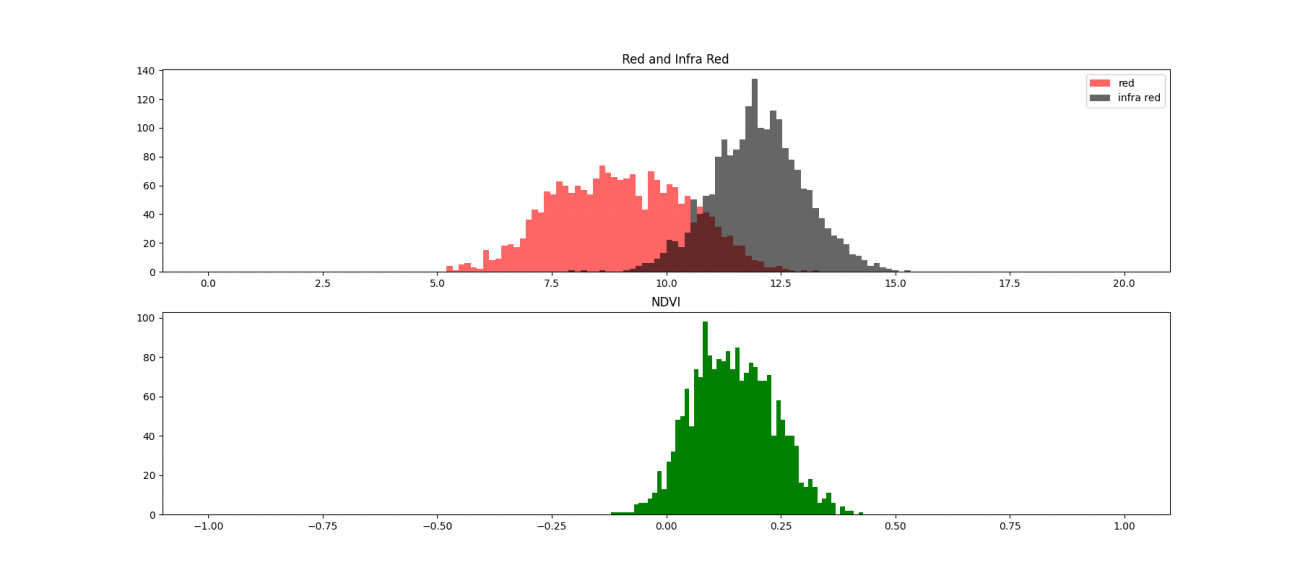
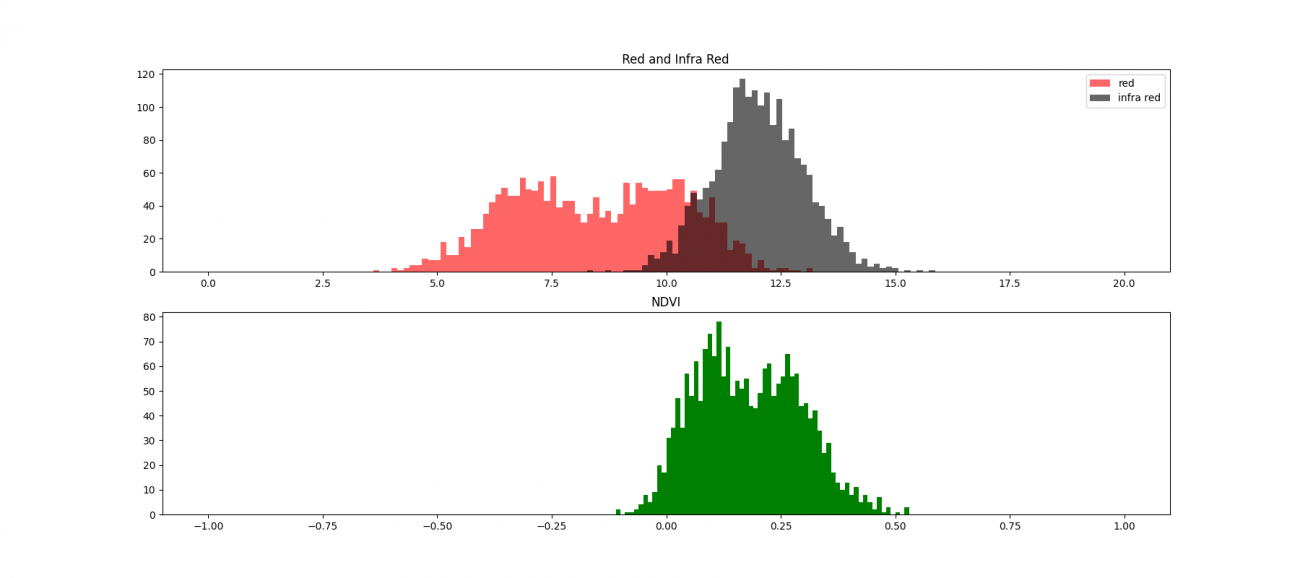
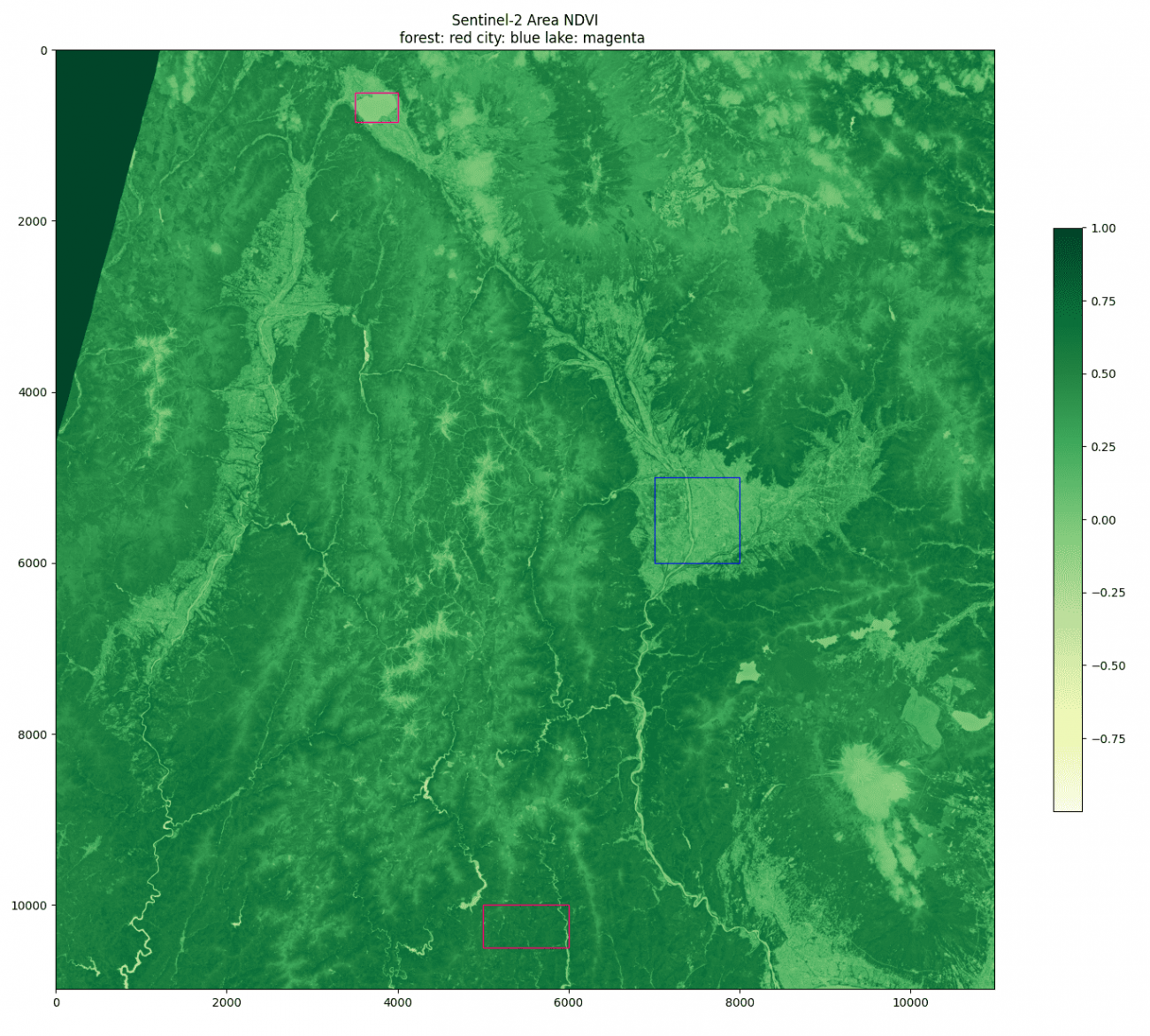
では実際に多峰性分布の一部を見ていきましょう。最初に対象となるAOI(Area of Interest:関心領域)の定性確認です。
plt.imshow(ndvi, cmap='YlGn')
for i, (bbox, name, color) in enumerate(zip(bboxes, names, colors)):
p = patches.Rectangle(xy=(
bbox[0][0], bbox[0][1]
),
width=bbox[1][0] - bbox[0][0],
height=bbox[1][1] - bbox[0][1]
, color=color, fill=False)
ax.add_patch(p)
plt.colorbar(shrink=0.5)| エリア | 凡例 | NDVI 定性評価 |
|---|---|---|
| 森林 | 赤 | 高め |
| 市街地 | 青 | 中間 |
| 湖 | マゼンタ | 低め |
次に分布の定量確認をします。
for i, (bbox, name, color) in enumerate(zip(bboxes, names, colors)):
plt.hist(ndvi[
bbox[0][1]:bbox[1][1], bbox[0][0]:bbox[1][0]
].ravel(),
bins=200, range=(-1, 1),
label=name, color=color,
alpha=0.7)
plt.legend()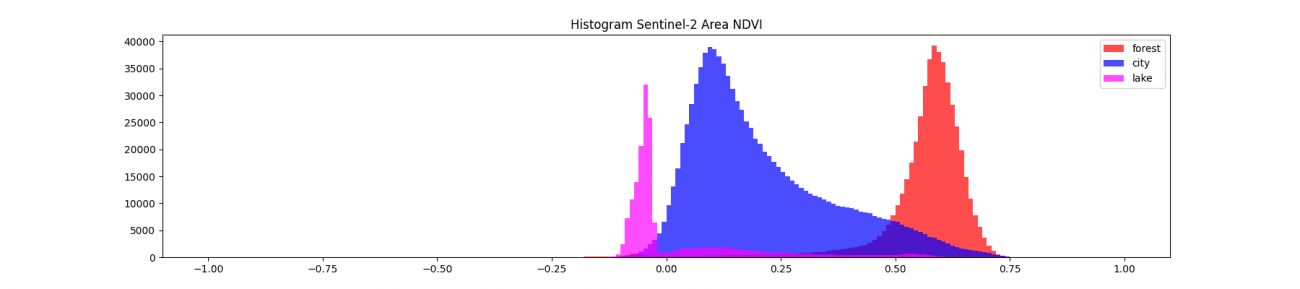
・MAXARの画像でNDVIを確認する
一方のMaxarの衛星画像は、以下に示しているような、東京の渋谷から代々木にかけてのエリアの解析を行います。画像の右端に白くて丸い建物が見えているのは国立競技場、真ん中に見えるのは代々木公園です。

さっそくNDVIを見ていきます。

公園や競技場はわかりやすく浮かびあがっていますね。解像度が高いので細かい植生についてもしっかりと検知できそうです。
続いて、場所ごとに代々木公園とスクランブル交差点の分布を可視化します。

分布を解析した結果が以下です。
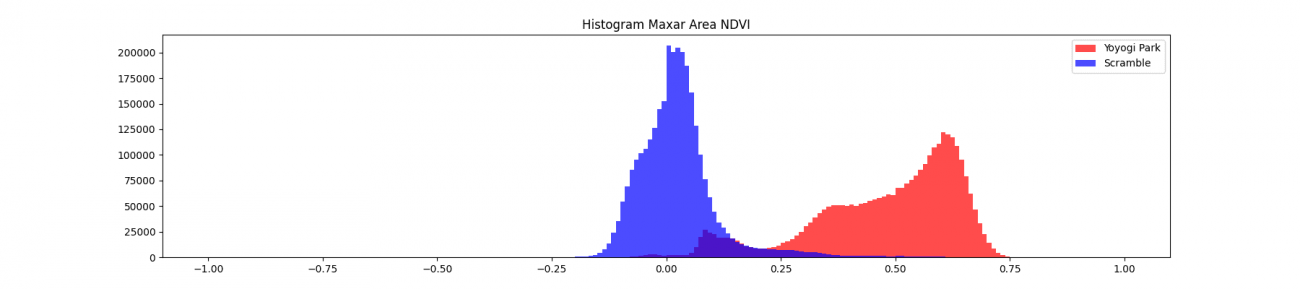
スクランブル交差点だと植生が全くなく、Sentinel-2のデータで見た湖のような水域レベルまで低い値になっています。逆に代々木公園は Sentinel-2 の森林レベルの値が観測できていると分かります。
一般的には、Sentinel-2のデータでみたように、森林は植生ばかりのため値がかなり高く、単峰の正規分布に近い形です。赤外波長の値が独占的であるからです。
市街地は人工物などの値が低く、AOIの西(MAXAR図上では左)の方にビニールハウスなどが見受けられることから農地も含まれる影響で右裾の長い分布が出来上がっています。
湖はNDVI値だけではわからないですが、地図上では諏訪湖ということが確認できます。水域はほぼ反射が変わらないか、むしろ赤色波長の値の方が大きいです。
これらをまとめると大体は以下のような値であれば、異常や変化がないことがざっくりですが確かめられると思います。
| 対象エリア | NDVI | 分布 |
|---|---|---|
| 森林 | 0.5 ~ 0.9 | 単峰分布 |
| 農地 | 0.2 ~ 0.7 | 多峰分布 |
| 市街地 | 0.0 ~ 0.3 | 多峰分布 |
| 水域 | -0.1 ~ 0.1 | 単峰分布 |
| 欠損値 | 1 | 定常値 |
以上が、NDVIにおける基本解析の紹介でした。続いて、応用解析についても一部ご紹介します。
応用解析
ここまででNDVI で植生の観測ができることはわかってきたと思います。
応用解析の章では2時期の変化と1年間の時系列の変化を可視化し、NDVIの特性を確認します。
NDVIの2時期を定性的に比較します。
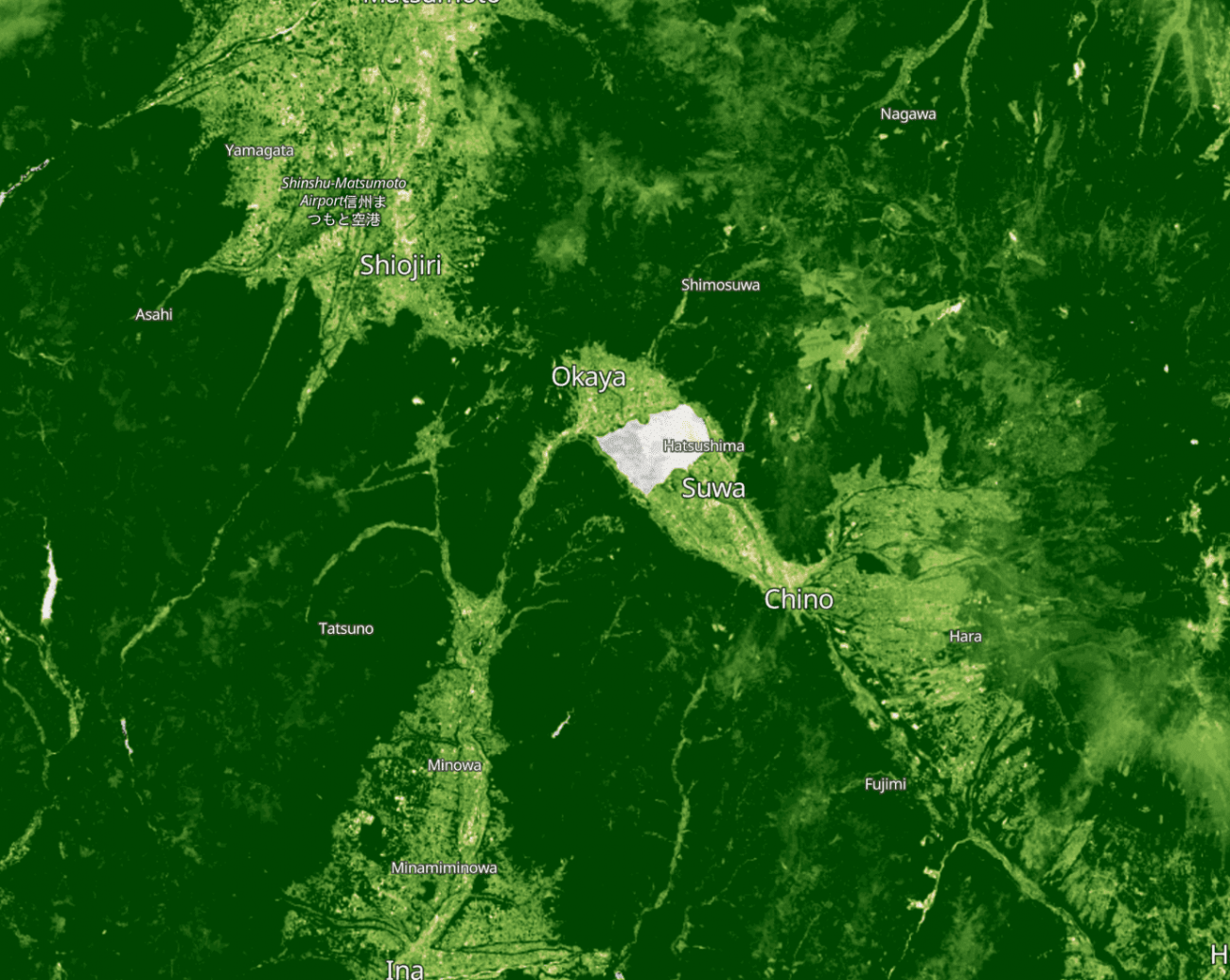
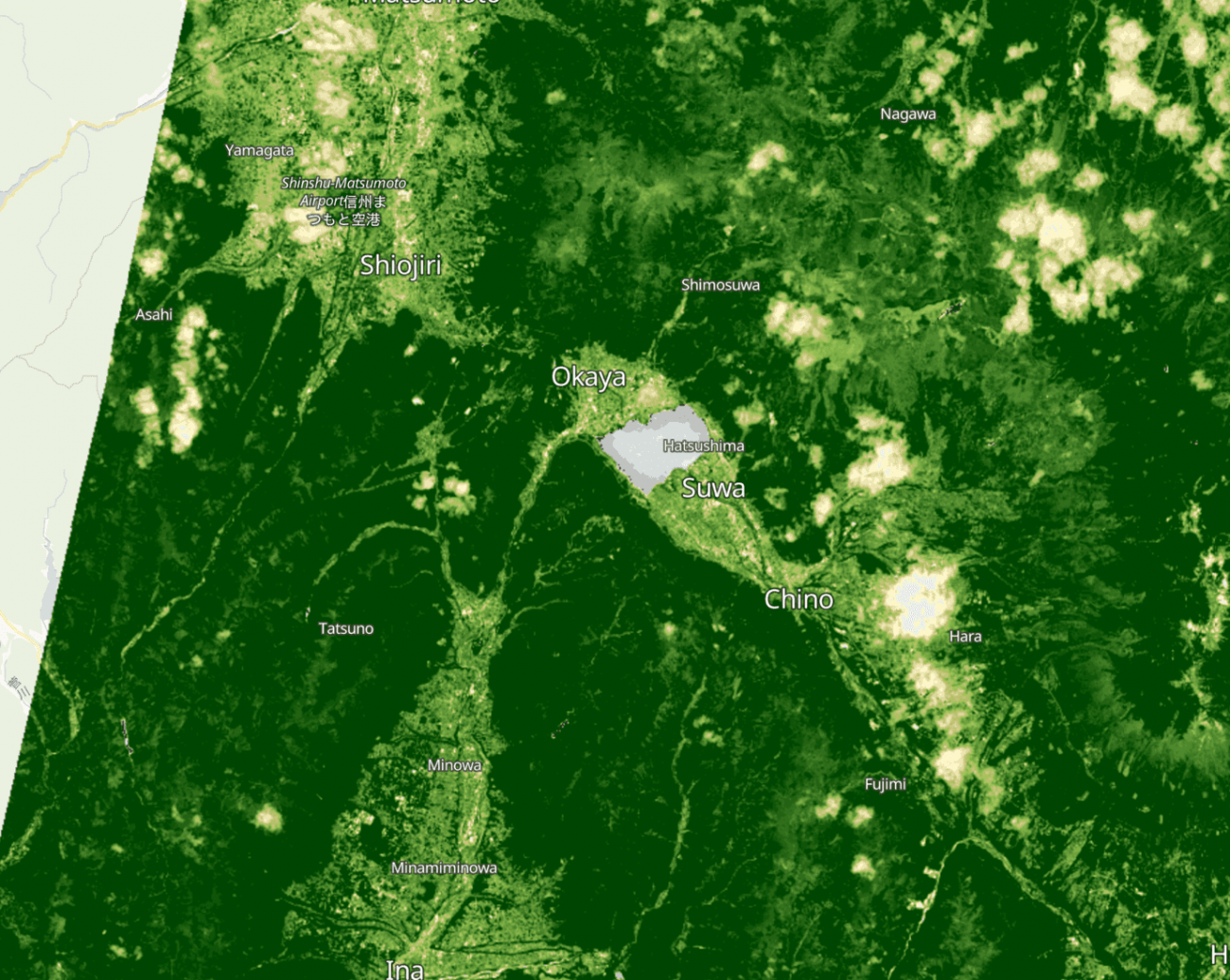
この2時期は5日違いなので画像全体ではそんなに変化はないはずです。
しかしながら、所々に白く変化している部分があります。

これはRGBの可視光の衛星画像を見ると原因が雲だとわかります。NDVIの弱点として、特に読者の皆様に知っておいていただきたいのは、雲による地表観測の失敗です。
光学の衛星データを解析する際は、雲のエリアを処理することを忘れないようにしましょう。
また、細かい値は観測条件による違いやノイズによって微妙に値が変化しますので丁寧な前処理やフィルターを利用することで近づけていくことも重要です。
ここでは「平滑化フィルター」「ガウシアンフィルター」の2つのフィルターの実装方法をご紹介します。
平滑化フィルターの実装
平滑化フィルターは、値を平均的に処理してくれます。周囲のピクセルの影響を混ぜるために使用します。
# 平滑化
K = 5 # カーネルサイズ
ndvi_blur = cv2.blur(ndvi, (K, K))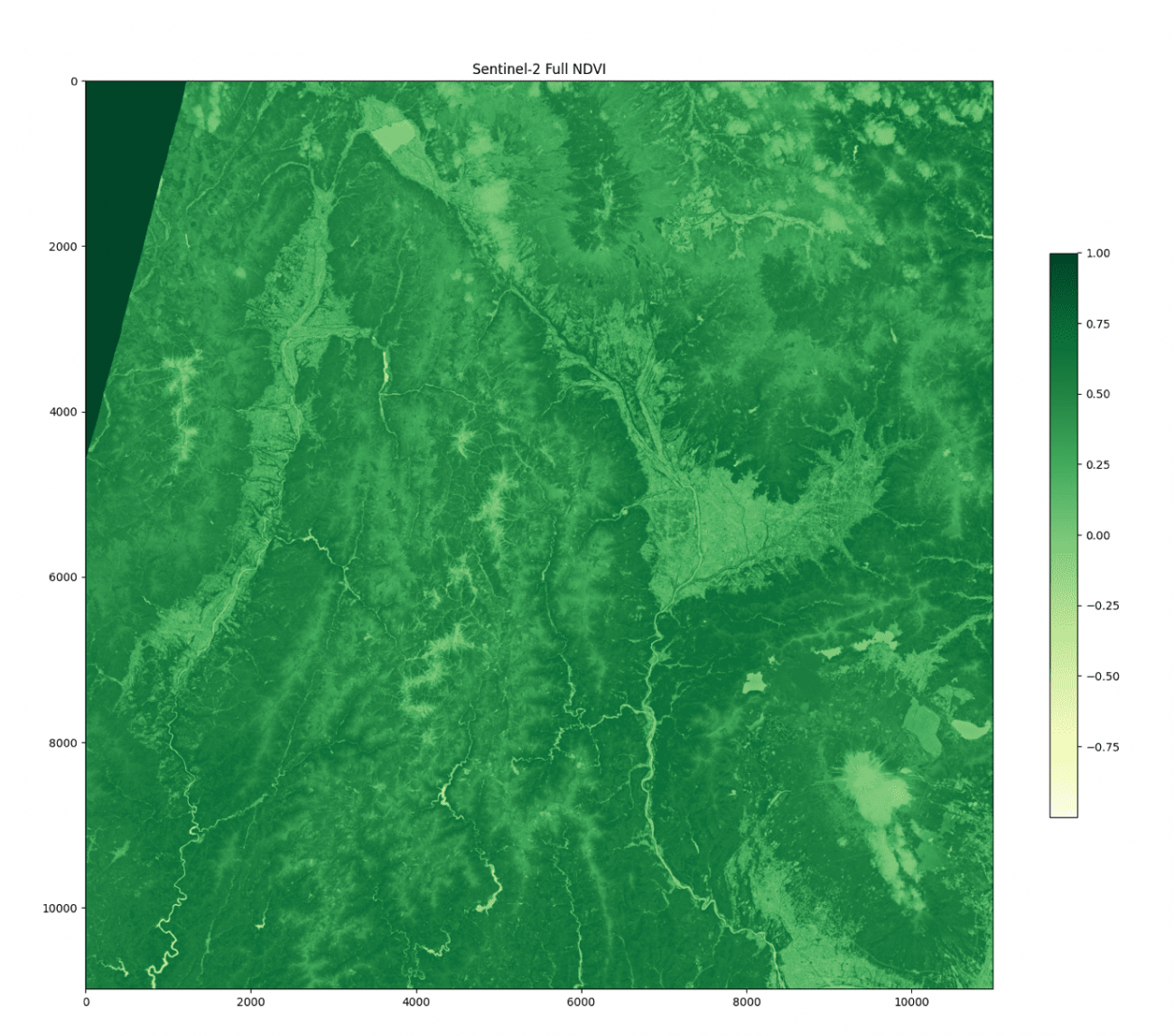
ガウシアンフィルターの実装
ガウシアンフィルターは、平滑化フィルターより元のピクセルの値に重きを置いて、周囲のピクセルの特徴を少し混ぜます。
# ガウシアンフィルタ
K = 5 # カーネルサイズ
ndvi_gauss = cv2.GaussianBlur(ndvi, (K, K), K)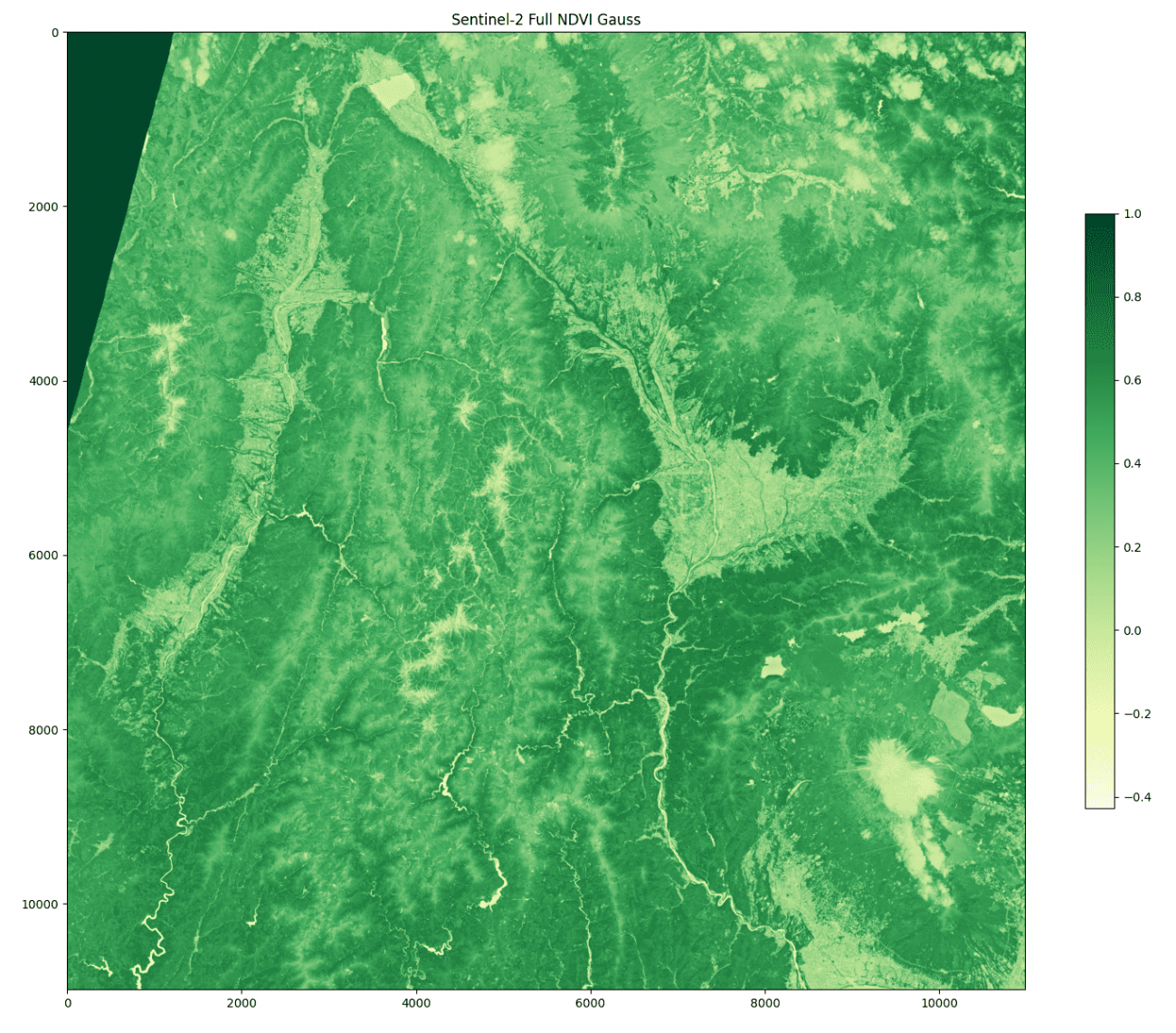
どちらも細かいエッジがなくなって過度な変化が減り、丸くなった衛星画像になったと思います。
カーネルサイズを大きくすると、ぼかしの範囲が広がりより効果が強くなります。
検出対象物に適した処理をしましょう。
次に紹介するのは、1年間の季節性変化の解析です。
特に植生の変化の見られる地域での理想的なパターンは以下です。
df_year_dummy['ndvi'].plot(rot=-15, label='ndvi', color='green')
plt.legend()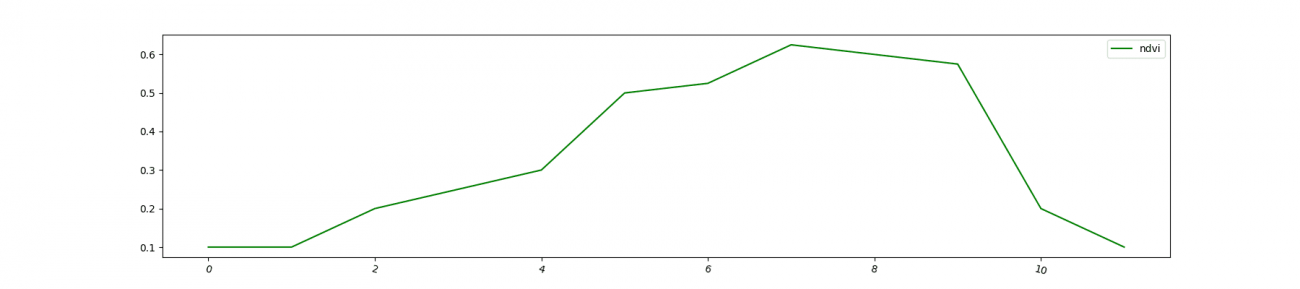
縦軸がNDVIで、横軸が観測月(日付)です。
植物が生い茂る夏はNDVI値が高くなり、逆に冬は低い値に変化します。これが年度ごとに周期的に変化していきます。
この特性を利用して農業モニタリングや土壌監視などに応用されています。
予測モデリング
応用解析でNDVIの特性がわかってきたと思いますので、それらを利用したプロジェクトでのモデリングや実装パターンを紹介します。
1. NDVIと回帰モデル
NDVIで圃場観測ができるのであれば、農作物の価格予測もできるのではという考えが古くからあります。その価格を回帰するモデリングです。
まずは、作成した価格データを可視化します。
ratio = 0.1
df_year_dummy['price'] = (
df_year_dummy['ndvi'].values * np.random.normal(1, 0.15, size=len(df_year_dummy)) * ratio
) * 1E4
df_year_dummy['price'].plot(rot=-15, label='price', color='red')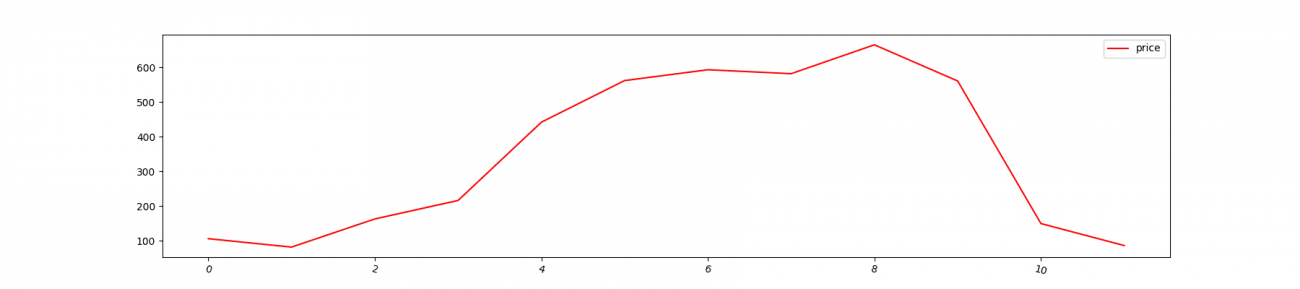
上記ではNDVIデータに対して、ランダムなノイズを加えて価格を作成しています。
このノイズの割合がより高い方が価格データの予測は難しくなります。皆さんのお手元で ratio を変更して難しいデータにして実験してみても面白いかもしれません。
NDVIのデータと合わせた分散の可視化は以下です。
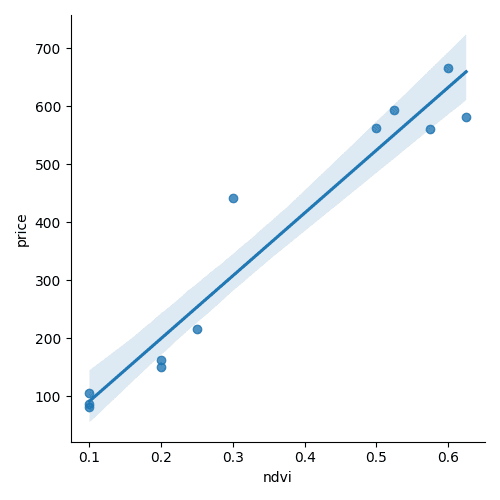
もうすでに図が似ていますが相関分析をしていきます。
df_cor = df_year_dummy[['ndvi', 'price']].corr()
sns.heatmap(df_cor, vmin=-1, vmax=1, annot=True, cmap='coolwarm')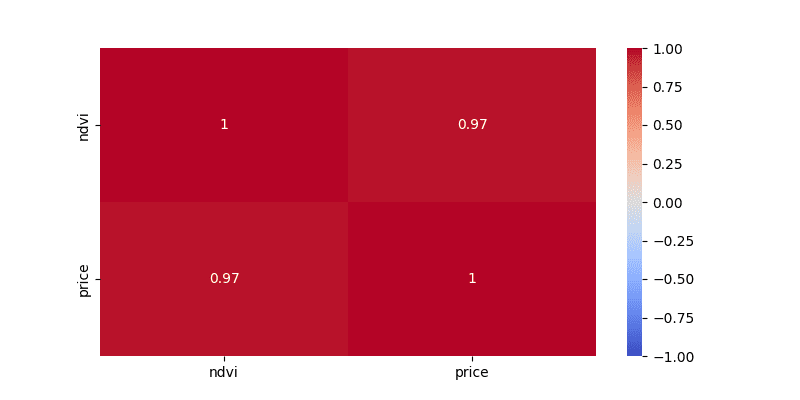
相関係数 0.97 という実データではちょっとあり得ない結果になっています。
ある程度強い相関がある場合は堅牢性を高めるために統計モデルの線形回帰モデルを使用します。
model = LinearRegression()
# 学習
model.fit(df_year_dummy[['ndvi']], df_year_dummy['price'])
# 予測
df_year_dummy['predict'] = model.predict(df_year_dummy[['ndvi']])予測を可視化します。
df_year_dummy['price'].plot(rot=-15, label='price', color='red')
df_year_dummy['predict'].plot(rot=-15, label='predict', color='blue')
plt.legend()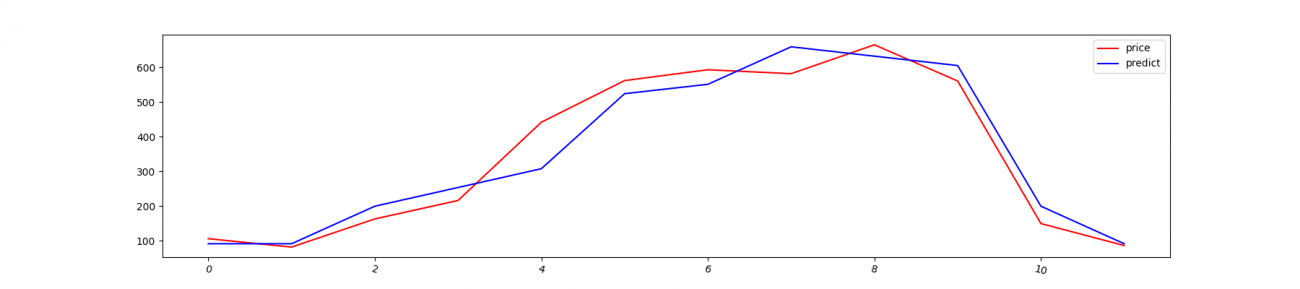
誤差の平均を見てみましょう
df_year_dummy['diff'] = abs(df_year_dummy['price'] - df_year_dummy['predict'])
df_year_dummy['diff'].mean()出力:43.55001886633696
ここでわかる例としては、価格予測が5円レベルの誤差で知りたい場合などはNDVIだけではサービス化は全然できないことになります。
衛星データだけではなく、他のデータと組み合わせたりすることで特徴量を増やしして改善する。または商品化での誤差のイメージや認識共有に使っていきましょう。
2. NDVIと分類モデル
NDVIで農作物の変化がわかるのであれば、出荷予測などのある特定の時期かどうかの分類をNDVIから予測するタスクもあります。
今回は9、10月を出荷時期として、その予測を2値分類するモデルを作成します。
df_year_dummy['harvest'] = [0] * 8 + [1] * 2 + [0] * 2
df_year_dummy['ndvi'].plot(kind='bar', rot=-15, label='ndvi', color='green', alpha=0.7)
df_year_dummy['harvest'].plot(kind='bar', rot=-15, label='harvest', color='red', alpha=0.5)
plt.legend()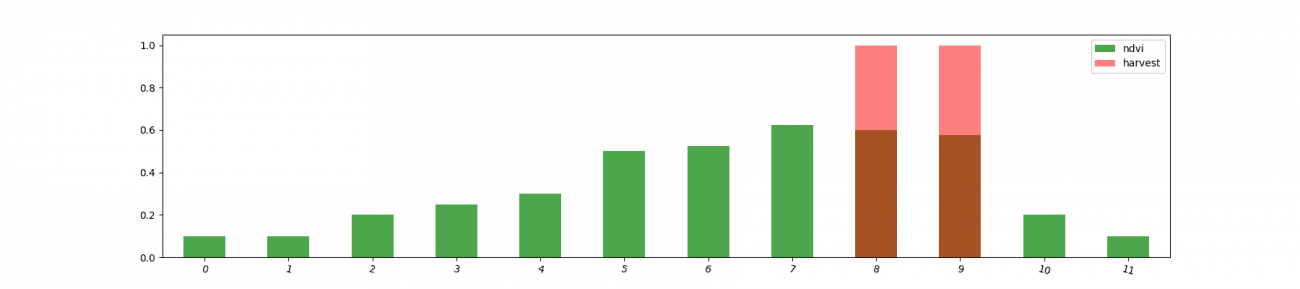
NDVI を見ると、時系列順で値が下がり始めている時期に収穫が起きています。このように時系列の特徴がある場合は過去のNDVIも特徴量に追加しましょう。
df_year_dummy['ndvi_shift'] = df_year_dummy['ndvi'].shift(1)
df_year_dummy['ndvi'].plot(rot=-15, label='ndvi', color='green')
df_year_dummy['ndvi_shift'].plot(rot=-15, label='ndvi_shift', color='black')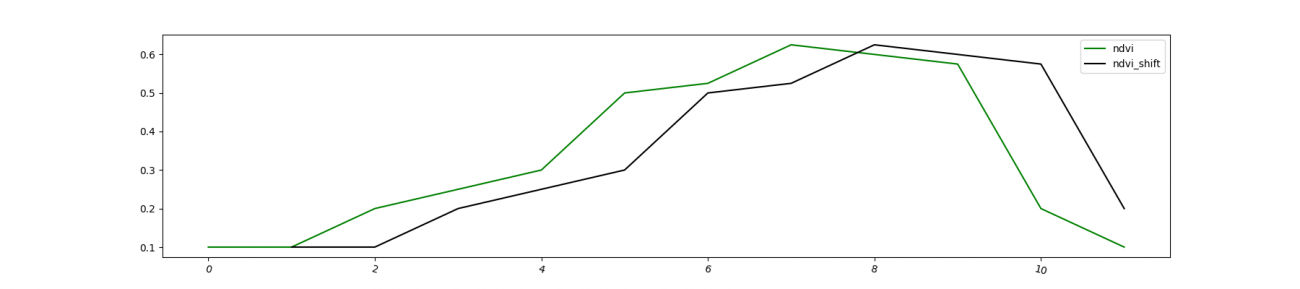
線形的な単純な変化の可視化ではみられなさそうなので今回はKaggleなどのコンペでも使用されるモデル LightGBM を使用します。
params = {
'objective': 'binary',
'metric': 'auc',
'verbosity': 0,
'num_leaves': 2,
'max_depth': 1,
'min_data': 1,
'force_col_wise': True,
}
lgb_train = lgb.Dataset(df_year_dummy[['ndvi', 'ndvi_shift']], df_year_dummy['harvest'])
# 学習
model = lgb.train(params, lgb_train,
num_boost_round=20,
)
# 予測
df_year_dummy['predict_harvest'] = model.predict(df_year_dummy[['ndvi', 'ndvi_shift']])予測結果を可視化します。
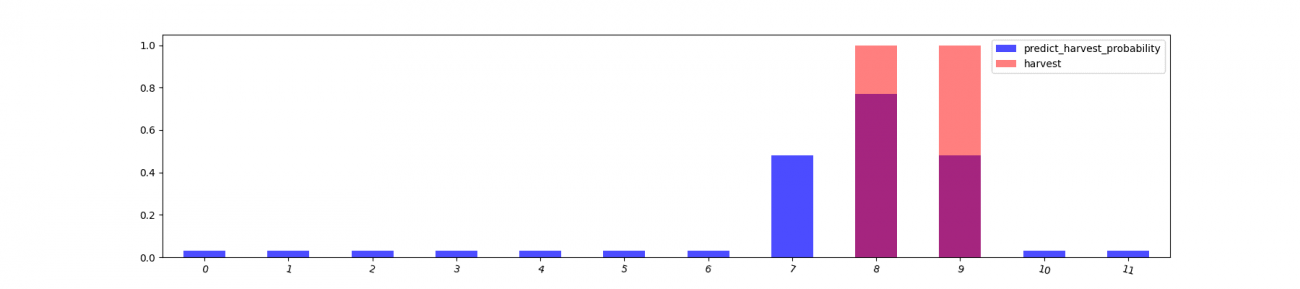
7月は異なりますが、収穫の確率はほとんど正しいです。
実験的に、過去の日付を追加する粒度や期間を変えると面白いかもしれませんね。
以下は、NDVI の値の変化と共に収穫時期予測を可視化したものです。単純に現在の撮像NDVIの値だけから予測していないこともわかります。
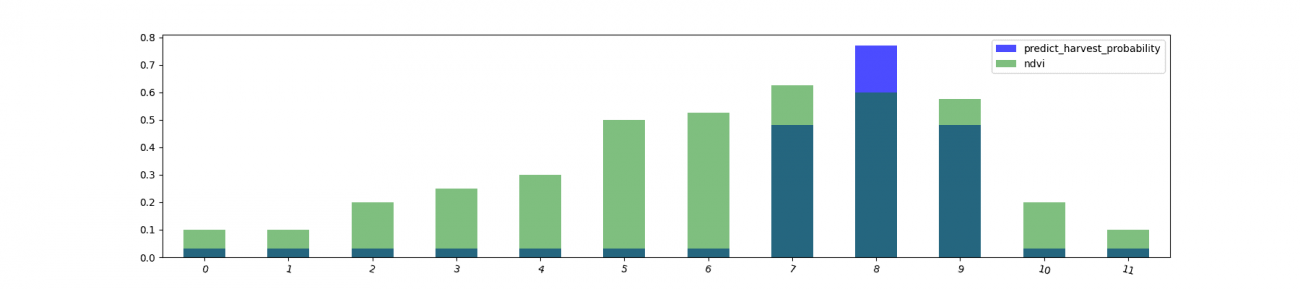
衛星データは定点観測の利点を生かして時間による変化検知を可能にします。それが一番効果を発揮する分野でもあると思っています。
他にも圃場ごとの予測であれば、AOIの面積の最大、最小、平均などの集約値を特徴量にすることでモデル安定化や精度向上が見込めます。
3. NDVIとディープラーニング
ピクセル処理だけでは対応できないような複雑な予測はディープラーニングを使用することが多いです。
UNetなどの End-to-End で解決するようなソリューションも出てきています。ぜひ、NDVIを活用してみてはいかがでしょうか。
別途、雲検知の記事ではNDVIを利用した Deep Learning のモデル作成と実験について記載した記事も公開予定です。その際はぜひご覧いただけますと幸いです。
宙畑におけるNDVI利用に関する記事
他にも宙畑にはNDVIの記事が豊富なのでぜひ参考にしてみてください。
【コード付き】衛星画像を使って青森県の水田割合の変化を比較する~考察編~
題材は水田モニタリングです。
NDVIと閾値処理で検知を行っています。
植物の分布から田畑の利用状況を推測する衛星データの利活用方法
題材は圃場モニタリングです。
NDVIから農地の耕作判定を行っています。
「しきさい」(GCOM-C)のNDVI(正規化植生指数)データをTellusOSで公開開始!
題材は植生監視です。
Tellusで「しきさい」のNDVIを見ています。
火災時の定性変化が載っています。
お米の食味ランク別に農地の様子を衛星データで比較してみた
題材は水稲です。
食味ランクとの関係性を分析しています。
衛星データを使って市区町村の緑地率を算出して平均寿命・自殺率との相関を調査してみた
題材は市街地の緑地率です。
社会的なデータとの関係性を分析しています。
Kerasを使って衛星画像内の山が独立峰か連峰かを判別するモデル作成チャレンジ
題材は山岳分類です。
NDVIをCNNの特徴としてモデリングしています。
【コード付き】衛星画像を使って青森県の水田割合の変化を比較する~考察編~
題材は水稲です。
時系列変化の可視化と分析が記載されています。
【ゼロからのTellusの使い方】正規化指標で衛星データから植物、水、砂を抽出
題材は植生です。
植生やその他の正規化指標と共に可視化しています。
空港周辺の緑地率とバードストライク率の相関を検証してみた
題材はバードストライクです。
緑地率と動植物の関係性について相関分析をしています。
衛星データから算出した耕作地面積と政府統計データを比較してみた
題材は政府統計データです。
耕作地面積と政府統計データの時系列相関を可視化しています。
琵琶湖の水草が発生しているエリアを衛星データで検出してみた
題材は水草検知です。
NDVIの定性評価を行っています。
【ゼロからのTellusの使い方】Jupyter NotebookでAVNIR-2/ALOSの光学画像から緑地割合算出
題材は緑地割合です。
Tellusのデータ取得と閾値処理での可視化をしています。
人工衛星で見ごろがわかる?紅葉エリアを調べてみた
題材は紅葉です。
紅葉とNDVIの定性評価を行っています。
年収と街の緑地率に相関があるってホント!? 衛星データで検証してみた
題材は年収です。
NDVIと年収との相関可視化を行っています。
宇宙から海洋や河川のゴミは見えるのか!?NASA主催のハッカソンでの取り組み紹介
題材は水域のごみです。
いつくかの指標で定性評価をしています。
解析環境と実装コード
今回解析で使用したコード全体は以下のレポジトリです。
Github: https://github.com/sorabatake/article_32380_ndvi
Sentinel-2 の解析ノートブック
https://github.com/sorabatake/article_32380_ndvi/blob/main/src/analysis_ndvi_sentinel-2.ipynb
Maxarの解析ノートブック
https://github.com/sorabatake/article_32380_ndvi/blob/main/src/analysis_ndvi_maxar_wv.ipynb
環境については以下の記事と同じものを使用しています。
https://sorabatake.jp/32245/
Github: https://github.com/sorabatake/article_32245_gdal
記事の内容を実践してみて、エラーが出た場合は、こちらのGoogleフォームにエラー内容のログを全てと改修したいことをリクエストいただけますと幸いです。
⇒エラー発見&改善リクエストはこちら
まとめ
本記事では、リモートセンシングや衛星データを学んでいると度々出てくるNDVIについて、実際に解析する手順と使用例を利用上の注意点とあわせて紹介しました。
NDVIは記事でも紹介した通り、農業分野でのリモートセンシング事例を検討する上では、知っておきたい・触っておきたいものです。
本記事がNDVIの解析をやってみたいと思われた方の一助となれますと幸いです。
