Sentinel-2を用いた雲検知モデルから被雲率を求める方法とその精度向上【学習済みモデル付き】【コード公開】
Sentinel-2のデータから雲を検知して、被雲率を求めるモデルの実装方法と精度を向上する方法を紹介します。本記事は学習済みモデルと合わせてGitHubでコードも公開しています。

光学衛星において、取得した衛星データが使えないとなってしまう原因の大部分を占める雲。
自動的に検知して選別したり、雲がない場所だけ抽出したりすることで、観測データをより有効に使うことができます。
そこで、本記事では雲を検知するモデルを作成する方法を紹介しています。
はじめに
光学衛星は可視光で地上を観測するため、人間の目で確認できるものはすべて観測されます。つまり、肉眼で確認できる雲も観測されます。この雲が存在するために、地上の光を観測できず、しばしば光学衛星が取得したデータは判読や解析を行ううえで使えないものとなってしまいます。

以下のように衛星プラットフォームでは「被雲率」と呼ばれる画像全体の中に何%が雲に覆われているかの事前設定や検索機能があります。
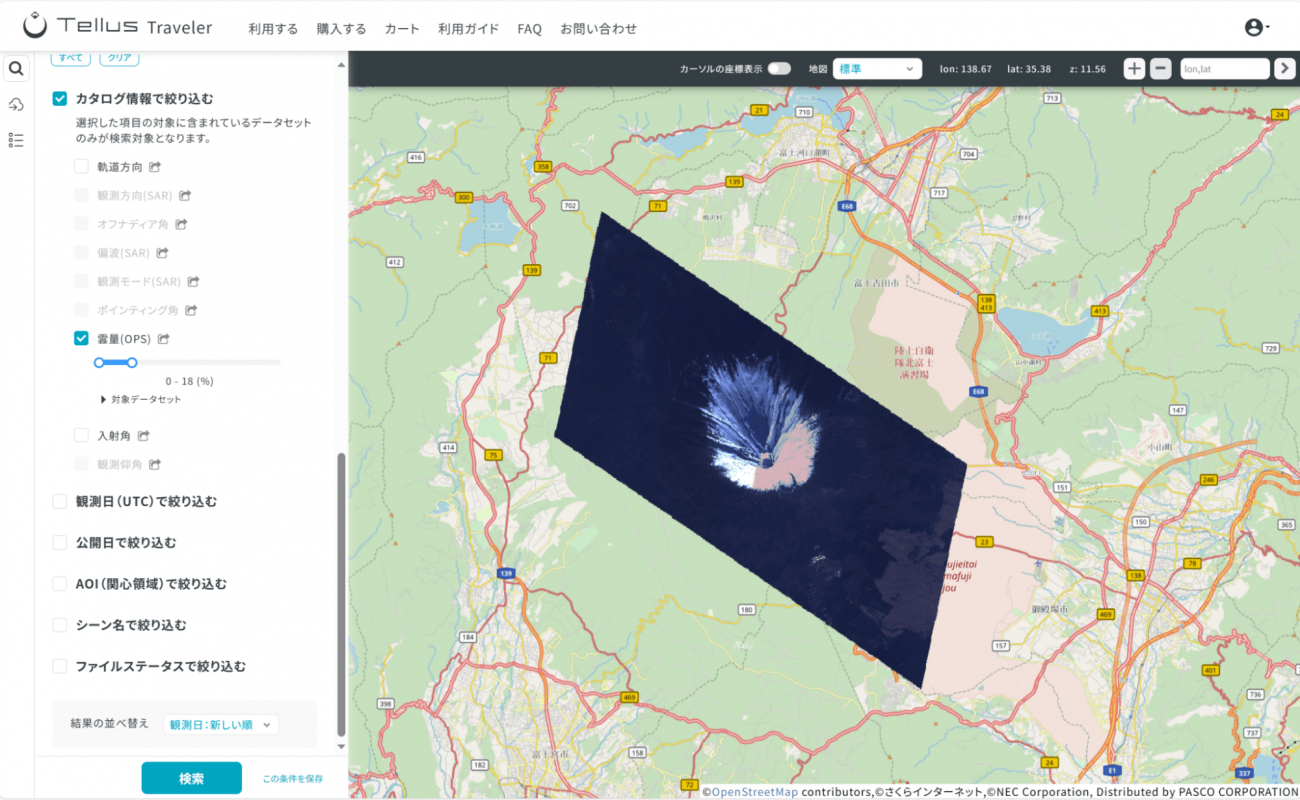
しかしながら、アプリを開発する場合、データを取得するAPI でそのような設定を提供していないことも。そのような時に自身で「被雲率」を見積もったり、前処理として不要なデータを削除したりすることが大切になってきます。
実際に実務でも解析やモデル作成時には以下の記事のように求めていない値になってしまう原因にもなってきます。
解析実例とともに学ぶNDVI(正規化植生指標)の基本と扱う上での注意点【コード付き】
使用する衛星データ
本記事では、Sentinel-2 というコペルニクスの光学衛星の画像を利用します。
無償提供であることに加え、撮像頻度が多いことから公開データセットも多いです。業務でも、趣味でも利用しやすいと思い、選定しました。
Sentinel-2 のバンドについては以下に一覧を記載しています。
衛星から桜は見える! 衛星画像を使った桜の探し方
今回使用するデータセットは Kaggle Dataset で提供されている以下のものです。
・https://www.kaggle.com/datasets/hmendonca/cloud-cover-detection
光学衛星画像と画像内で雲の被雲エリアのマスク画像がセットになっています。
衛星データの解析と可視化
このデータセットのバンドには B02, B03, B04, B08 があります。それぞれ地上分解能約10mの青色、緑色、赤色、近赤外の波長で観測した画像になります。
plt.figure(figsize=(16, 6))
for b, c in zip(BANDS, CMAPS):
PATH_IMG = f'{PATH_IMG_ROOT}/{row.chip_id}/{b}.tif'
img = cv2.imread(PATH_IMG, cv2.IMREAD_UNCHANGED)
print(f'band: {b} | shape: {img.shape} | dtype: {img.dtype}')
plt.subplot(1, 4, BANDS.index(b) + 1)
plt.imshow(img, cmap=c)
plt.title(b)
plt.colorbar(shrink=0.85, orientation='horizontal')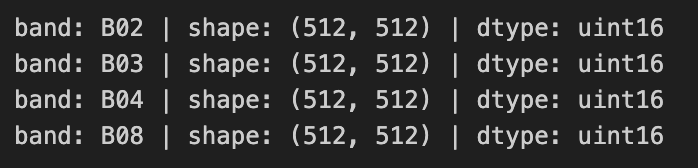
サイズは 512pixel四方で、符号なし 16Bit整数の画像です。
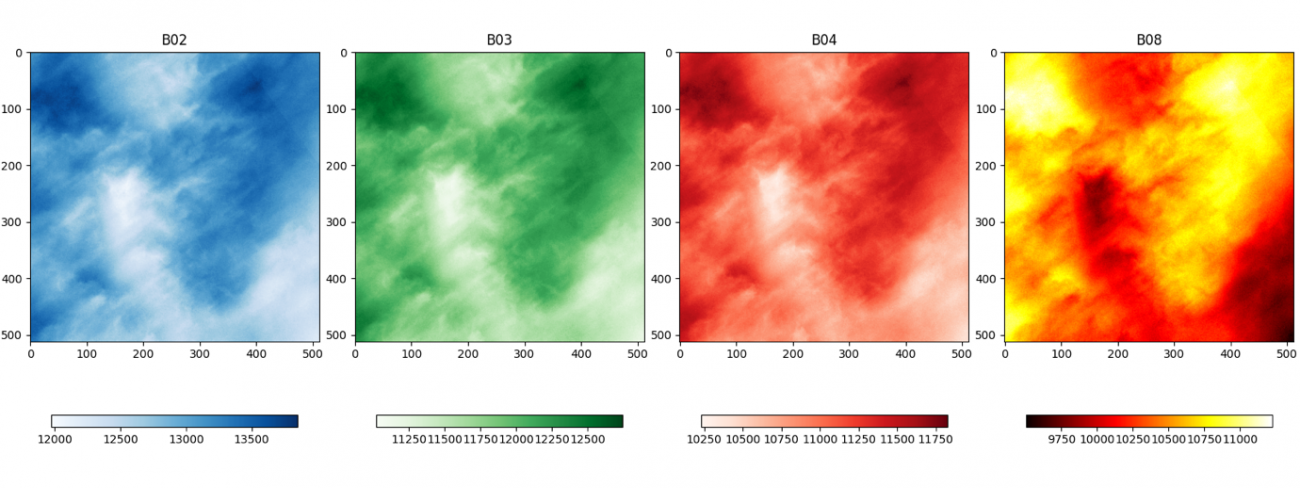
次に、セットで取得した雲の被雲エリアのマスクも合わせて可視化します。
for IDX in range(10):
row = df.iloc[IDX]
plt.figure(figsize=(18, 6))
for b, c in zip(BANDS, CMAPS):
PATH_IMG = f'{PATH_IMG_ROOT}/{row.chip_id}/{b}.tif'
img = cv2.imread(PATH_IMG, cv2.IMREAD_UNCHANGED)
plt.subplot(1, 5, BANDS.index(b) + 1)
plt.imshow(img, cmap=c)
plt.title(b)
plt.colorbar(shrink=0.85, orientation='horizontal')
plt.axis('off')
PATH_LABEL = f'{PATH_LBL_ROOT}/{row.chip_id}.tif'
img = cv2.imread(PATH_LABEL, cv2.IMREAD_UNCHANGED)
plt.subplot(1, 5, 5)
plt.imshow(img, vmin=0, vmax=1,)
plt.title('Cloud Mask')
plt.colorbar(shrink=0.85, orientation='horizontal')
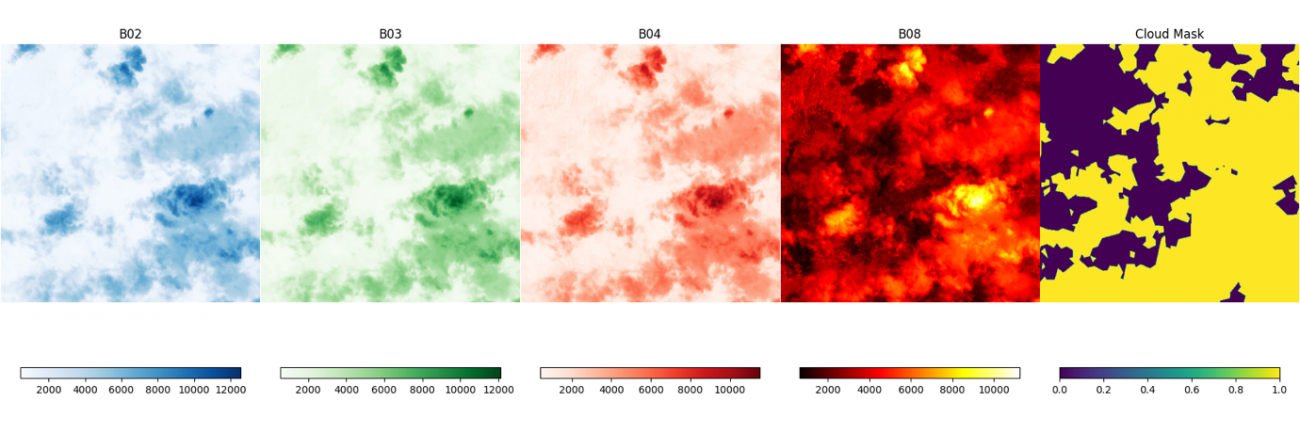
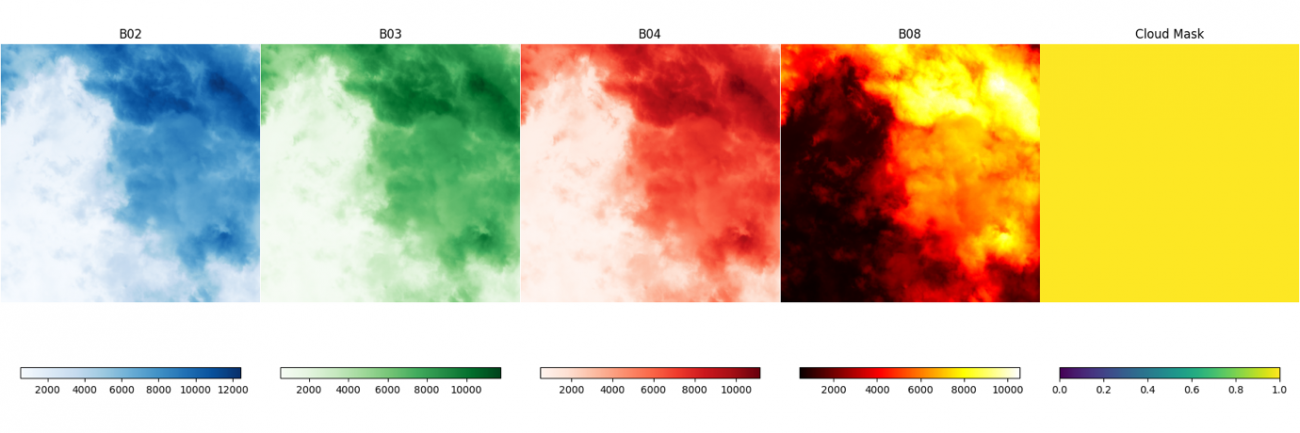
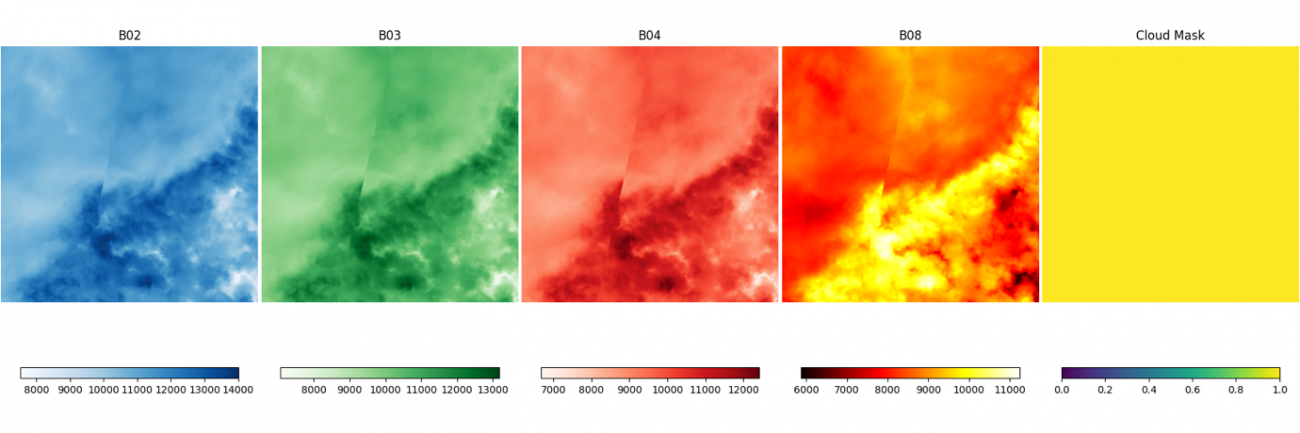
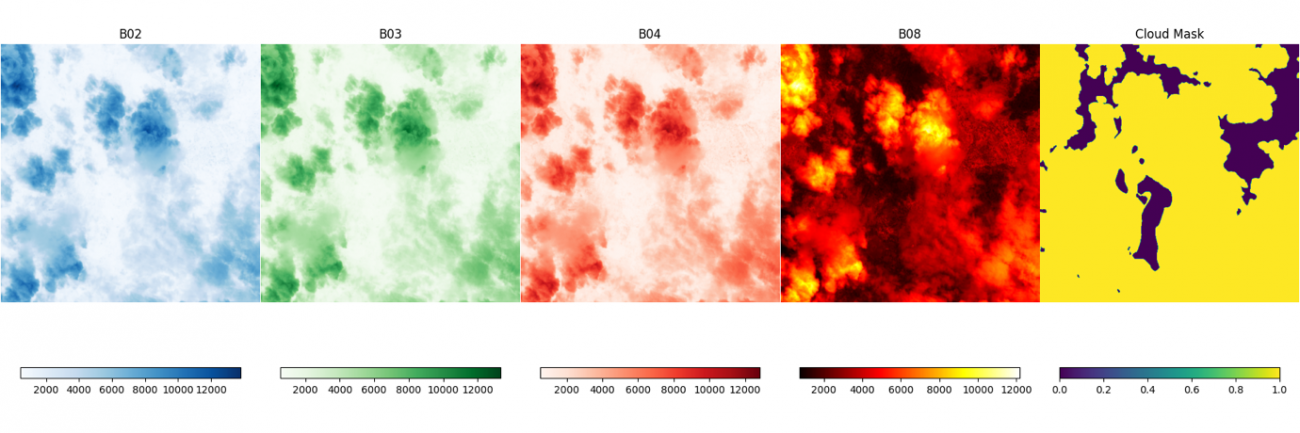
画像を並べて見ていただくと、定性的に、雲の部分の値が非常に大きくなっていることがわかります。
次に、センサーの取得強度の分布について可視化します。画像の順番は上記で並べたシーンの順となっています。
for IDX in range(10):
row = df.iloc[IDX]
plt.figure(figsize=(18, 8))
for b, c in zip(BANDS, COLORS):
PATH_IMG = f'{PATH_IMG_ROOT}/{row.chip_id}/{b}.tif'
img = cv2.imread(PATH_IMG, cv2.IMREAD_UNCHANGED)
plt.subplot(5, 1, BANDS.index(b) + 1)
plt.hist(img.flatten(), color=c, bins=300, range=(300, 8000))
plt.title(b)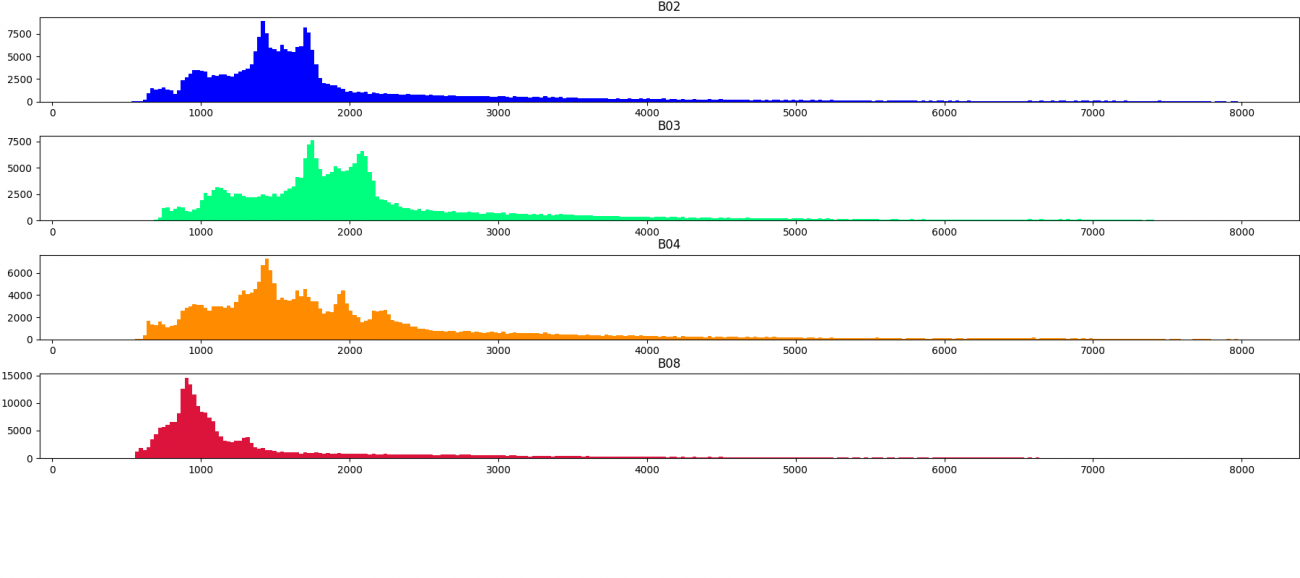
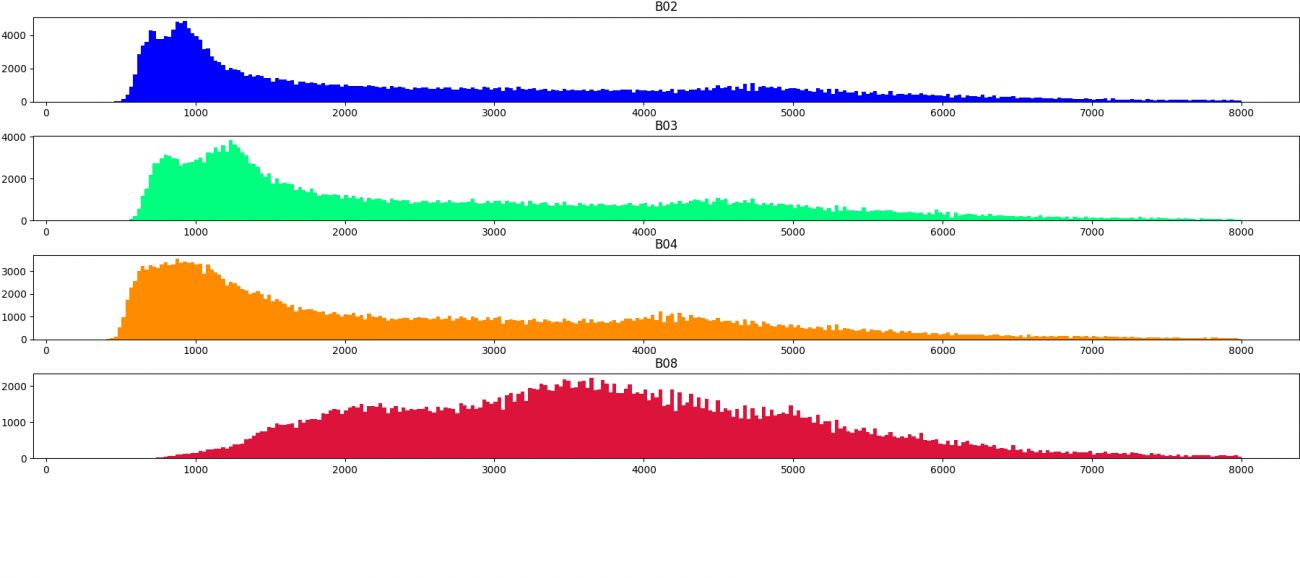
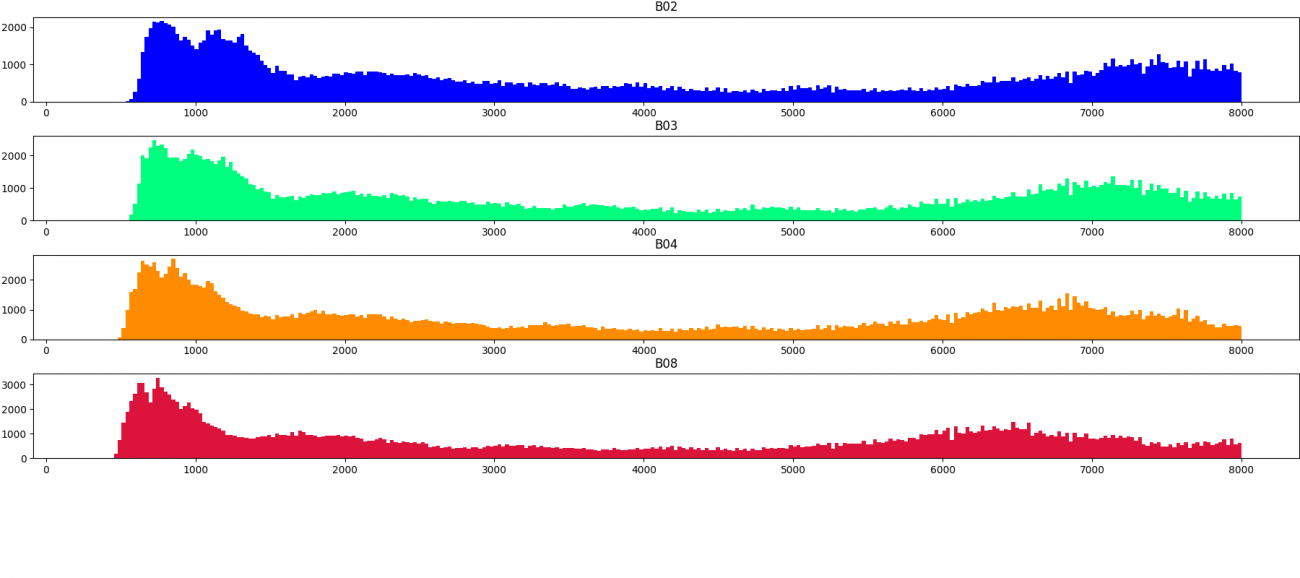

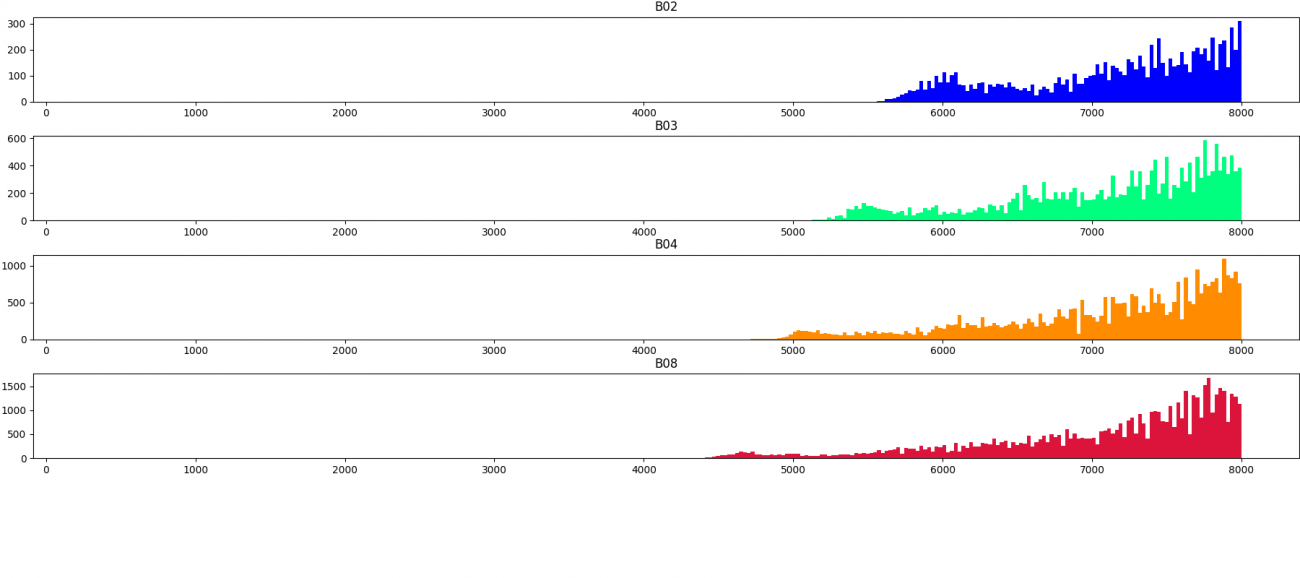
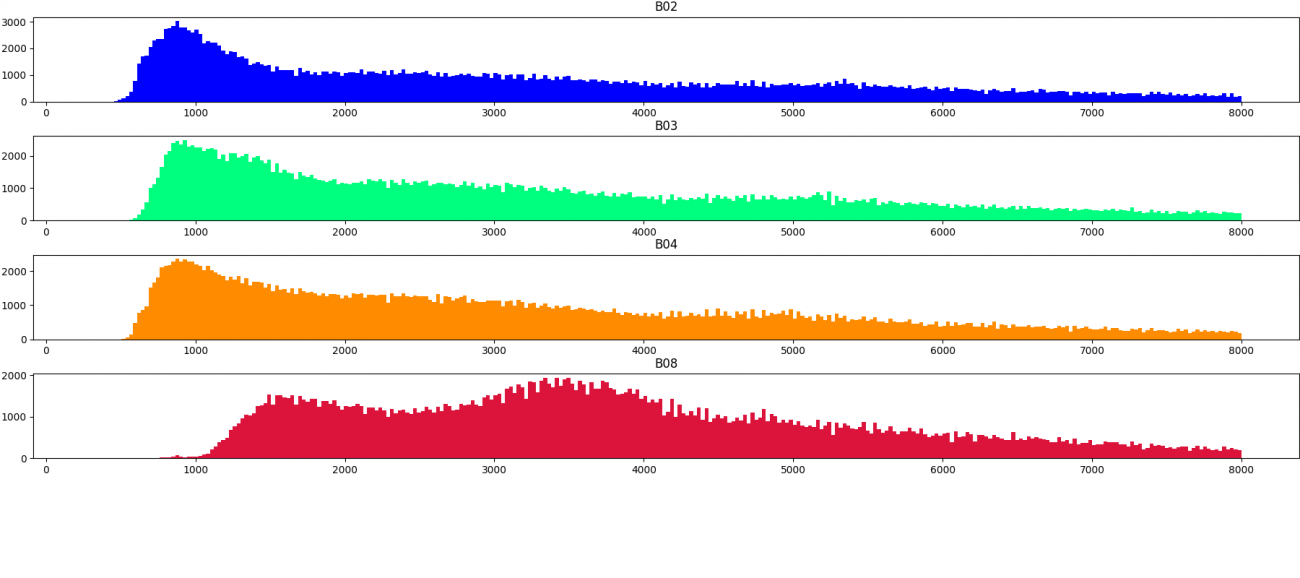
上記の分布から定量的にも雲の領域は値が大きいことがわかりました。
最後に可視光のバンドを合わせて、RGB画像を作成してみます。
row = df.iloc[IDX]
imgs = []
plt.figure(figsize=(8, 6))
for b, c in zip(BANDS, CMAPS):
PATH_IMG = f'{PATH_IMG_ROOT}/{row.chip_id}/{b}.tif'
img = cv2.imread(PATH_IMG, cv2.IMREAD_UNCHANGED)
img = img.astype(np.float32)
img = np.clip(img, 400, 2400) / 2400
imgs.append(img)
imgs = np.stack(imgs, axis=2)
imgs = (imgs * 255).astype(np.uint8)
plt.imshow(imgs)
plt.title('Optical Image')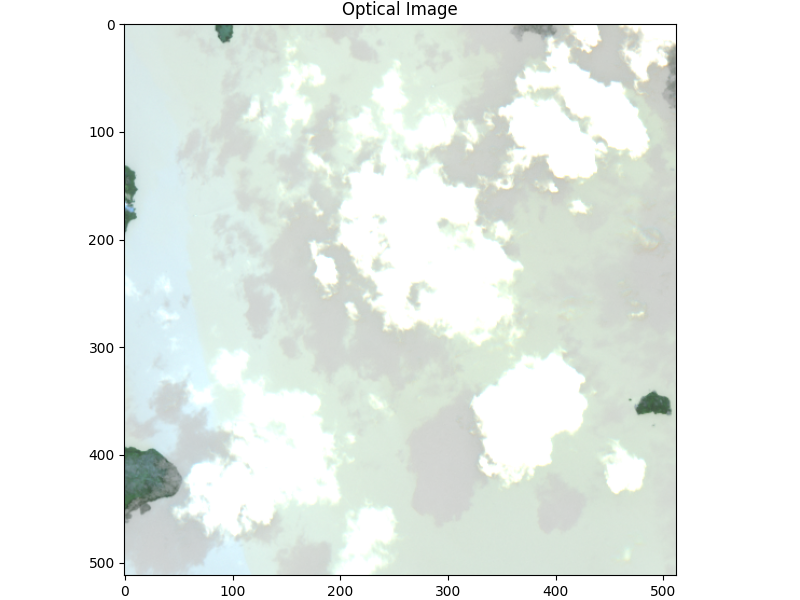
見慣れている画像になりましたね。可視化して値が高い場所が本当に雲なのか、定性的に可視光でも確認することをお勧めします。
モデリング
今回はSentinel-2を利用するため、データ量もあるので、今回はディープラーニングでモデルを作成します。インプットは可視光の3チャンネル画像です。一般的な RGB のモデルです。モデルのアウトプットは雲が存在する確率を予測します。
モデルのアーキテクチャーは、MaxViT を使用した UNetです。
このモデルを選んだ理由は Kaggle のコンペティション「Google Research – Identify Contrails to Reduce Global Warming」の優勝者が使用していたモデルだからです。
こちらに解法も紹介されています。
・https://www.kaggle.com/competitions/google-research-identify-contrails-reduce-global-warming/discussion/430618
MaxViTの論文は以下です。
・https://arxiv.org/abs/2204.01697
モデルのデータのインプットとアウトプットは以下のようなイメージです。
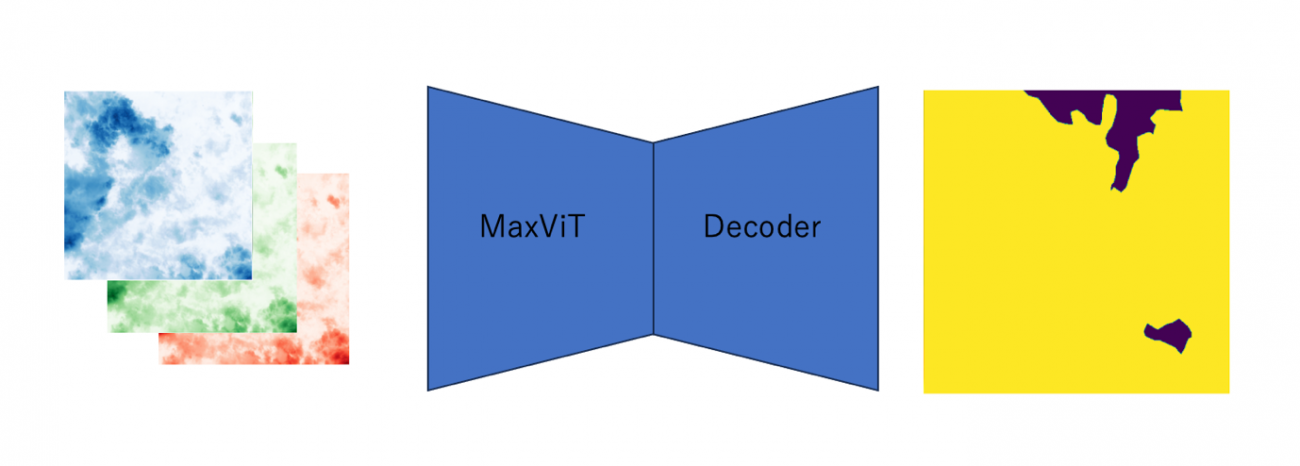
入賞者のコードを参考にインプット部分を変更しています。
class DecoderBlock(nn.Module):
def __init__(
self,
in_channels,
skip_channels,
out_channels,
use_batchnorm=True,
dropout=0,
):
super().__init__()
conv_in_channels = in_channels + skip_channels
# Convolve input embedding and upscaled embedding
self.conv1 = md.Conv2dReLU(
conv_in_channels,
out_channels,
kernel_size=3,
padding=1,
use_batchnorm=use_batchnorm,
)
self.conv2 = md.Conv2dReLU(
out_channels,
out_channels,
kernel_size=3,
padding=1,
use_batchnorm=use_batchnorm,
)
self.dropout_skip = nn.Dropout(p=dropout)
def forward(self, x, skip=None):
x = F.interpolate(x, scale_factor=2, mode='nearest')
if skip is not None:
skip = self.dropout_skip(skip)
x = torch.cat([x, skip], dim=1)
x = self.conv1(x)
x = self.conv2(x)
return x
class UnetDecoder(nn.Module):
def __init__(
self,
encoder_channels,
decoder_channels,
use_batchnorm=True,
dropout=0,
):
super().__init__()
encoder_channels = encoder_channels[::-1]
# Computing blocks input and output channels
head_channels = encoder_channels[0]
in_channels = [head_channels] + list(decoder_channels[:-1])
skip_channels = list(encoder_channels[1:]) + [0]
out_channels = decoder_channels
self.center = nn.Identity()
# Combine decoder keyword arguments
blocks = [
DecoderBlock(in_ch, skip_ch, out_ch, use_batchnorm=use_batchnorm, dropout=dropout)
for in_ch, skip_ch, out_ch in zip(in_channels, skip_channels, out_channels)
]
self.blocks = nn.ModuleList(blocks)
def forward(self, features):
features = features[::-1] # reverse channels to start from head of encoder
head = features[0]
skips = features[1:]
x = self.center(head)
for i, decoder_block in enumerate(self.blocks):
skip = skips[i] if i < len(skips) else None
x = decoder_block(x, skip)
return x
in_chans = 3
cfg = yaml.safe_load(f"""
model:
encoder: maxvit_tiny_tf_512.in1k # I also use resnest26d
pretrained: False # Use True! False due to internet connection
decoder_channels: [256, 128, 64, 32, 16]
dropout: 0.0
in_chans: {in_chans}
""")
def _check_reduction(reduction_factors):
"""
Assume spatial dimensions of the features decrease by factors of two.
For example, convnext start with stride=4 cannot be used in my code.
"""
r_prev = 1
for r in reduction_factors:
if r / r_prev != 2:
raise AssertionError('Reduction assumed to increase by 2: {}'.format(reduction_factors))
r_prev = r
class Model(nn.Module):
# The main U-Net model
# See also TimmUniversalEncoder in Segmentation Models PyTorch
def __init__(self, cfg, pretrained=True, tta=None):
super().__init__()
name = cfg['model']['encoder']
dropout = cfg['model']['dropout']
pretrained = pretrained and cfg['model']['pretrained']
self.encoder = timm.create_model(name,
features_only=True,
pretrained=pretrained,
in_chans=cfg['model']['in_chans'],)
encoder_channels = self.encoder.feature_info.channels()
_check_reduction(self.encoder.feature_info.reduction())
decoder_channels = cfg['model']['decoder_channels'] # (256, 128, 64, 32, 16)
print('Encoder channels:', name, encoder_channels)
print('Decoder channels:', decoder_channels)
assert len(encoder_channels) == len(decoder_channels)
self.decoder = UnetDecoder(
encoder_channels=encoder_channels,
decoder_channels=decoder_channels,
dropout=dropout,
)
self.segmentation_head = smp.base.SegmentationHead(
in_channels=decoder_channels[-1],
out_channels=1, activation=None, kernel_size=3,
)
initialize_decoder(self.decoder)
def forward(self, x):
features = self.encoder(x)
decoder_output = self.decoder(features)
y_pred = self.segmentation_head(decoder_output)
return y_pred
model = Model(cfg=cfg)
次に、データパイプラインのループ処理です。
class DataTransform():
def __init__(self):
self.data_transform = {
"train": A.Compose(
[
A.HorizontalFlip(p=0.25),
A.VerticalFlip(p=0.25),
A.Transpose(p=0.5),
ToTensorV2()
]
),
"val": A.Compose(
[
ToTensorV2(),
]
)
}
def __call__(self, phase, img, anno_class_img):
return self.data_transform[phase](image=img, mask=anno_class_img)
class CloudDataset(Dataset):
def __init__(self, df, phase, transform, bands=BANDS[:3]):
self.ids = df['chip_id']
self.phase = phase
self.transform = transform
self.bands = bands
def __len__(self):
return len(self.ids)
def __getitem__(self, index):
imgs = []
_id = self.ids.iloc[index]
for b in self.bands:
PATH_IMG = f'{PATH_IMG_ROOT}/{_id}/{b}.tif'
img = cv2.imread(PATH_IMG, cv2.IMREAD_UNCHANGED)
imgs.append(img)
imgs = np.stack(imgs, axis=2)
imgs = imgs.astype(np.float32)
anno = cv2.imread(f'{PATH_LBL_ROOT}/{_id}.tif', cv2.IMREAD_UNCHANGED)
anno = anno.astype(np.float32)
img_and_anno = self.transform(self.phase, imgs, anno)
img = img_and_anno["image"]
anno = img_and_anno["mask"]
return img, annoPyTorchとAlbumentationで実装しています。
学習サンプルは 10000画像以上あったのですが、説明のために学習データは 500サンプルで検証データは 1500 サンプルにリサンプリングしています。精度を出すときは、サンプル数を変更してください。

loss_fn = torch.nn.BCEWithLogitsLoss()
optimizer = torch.optim.AdamW([dict(params=model.parameters(), lr=1e-4),])損失関数は Binary Cross Entropy で、最適化法は AdamW と一般的なものを使用します。
最後に、学習ループです。
EPOCHS = 20
best_score = 1E5
train_loss = []
valid_loss = []
model = model.cuda()
os.makedirs(PATH_OUTPUT, exist_ok=True)
for i in range(0, EPOCHS):
loss_epoch = []
for phase in ['train', 'valid']:
print(f'Epoch: {i} Phase {phase}')
for (img, anno) in tqdm(dataloaders_dict[phase],
total=len(dataloaders_dict[phase]),
leave=True,
dynamic_ncols=True):
img, anno = img.cuda(), anno.cuda()
if phase == 'train':
model.train()
output = model(img)
loss = loss_fn(output.squeeze(dim=1), anno.squeeze(dim=1))
loss.backward()
optimizer.step()
optimizer.zero_grad()
loss = loss.cpu().detach().numpy()
else:
with torch.no_grad():
model.eval()
output = model(img)
loss = loss_fn(output.squeeze(dim=1), anno.squeeze(dim=1))
loss = loss.cpu().numpy()
loss_epoch.append(loss)
if phase == 'train':
train_loss.append(np.array(loss_epoch).mean())
else:
loss_mean = np.array(loss_epoch).mean()
valid_loss.append(loss_mean)
if best_score > loss_mean:
best_score = loss_mean
torch.save(model, os.path.join(PATH_OUTPUT, 'best_model.pth'))損失関数の結果の学習推移を可視化します。
plt.figure(figsize=(12, 4))
plt.title('Loss train')
plt.plot(np.array(train_loss), label='train')
plt.plot(np.array(valid_loss), label='valid')
plt.legend()
plt.savefig(f'{PATH_OUTPUT}/loss.png')
plt.show();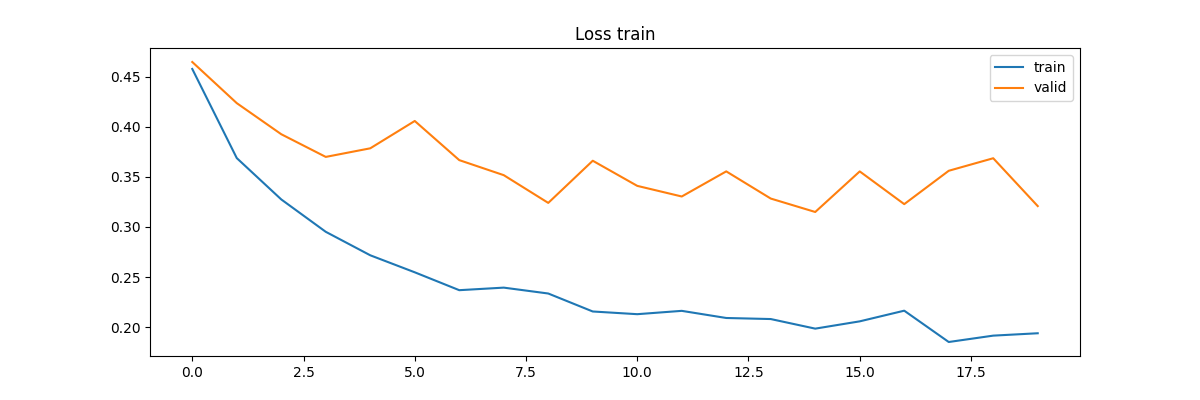
定量的には、学習データほどではないですが、検証データでも指標が下がっていることがわかります。
test_dataset = CloudDataset(df_val, phase="val", transform=DataTransform())
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
model = torch.load(f"{PATH_OUTPUT}/best_model.pth")
model.eval()
for i, (img, anno) in tqdm(enumerate(test_dataloader)):
with torch.no_grad():
img, anno = img.cuda(), anno.cuda()
output = model(img)
output, anno = output.squeeze(dim=1), anno.squeeze(dim=1)
loss = loss_fn(output, anno)
preds = torch.sigmoid(output)
loss = loss.cpu().numpy()
print(f"Loss: {loss}")
for batch_i, (pred, an) in enumerate(zip(preds.cpu().numpy(), anno.cpu().numpy())):
plt.figure(figsize=(6, 6))
_id = df_val['chip_id'].iloc[i*BATCH_SIZE + batch_i]
plt.title(f'Prediction with Mask ID {_id}')
plt.imshow(an, alpha=0.7, cmap='gray', vmin=0, vmax=1)
plt.imshow(pred, cmap='jet', alpha=0.3, vmin=0, vmax=1)
plt.colorbar()
plt.savefig(f"{PATH_OUTPUT}/predict_{_id}.png")
plt.show();
break予測したデータを定性的に確認します。
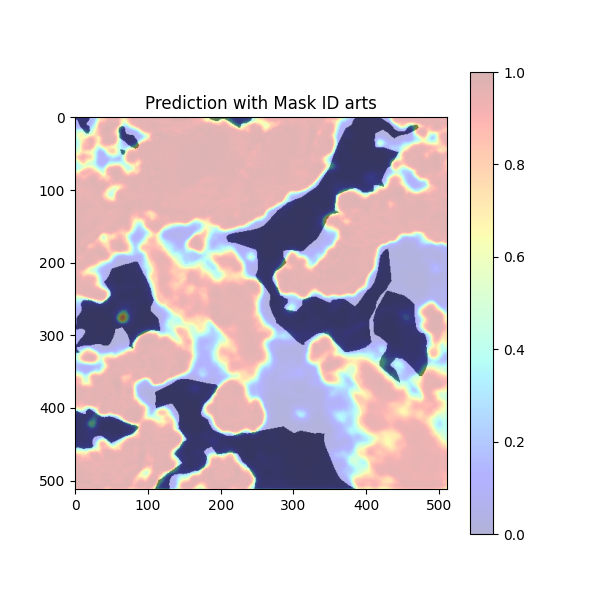
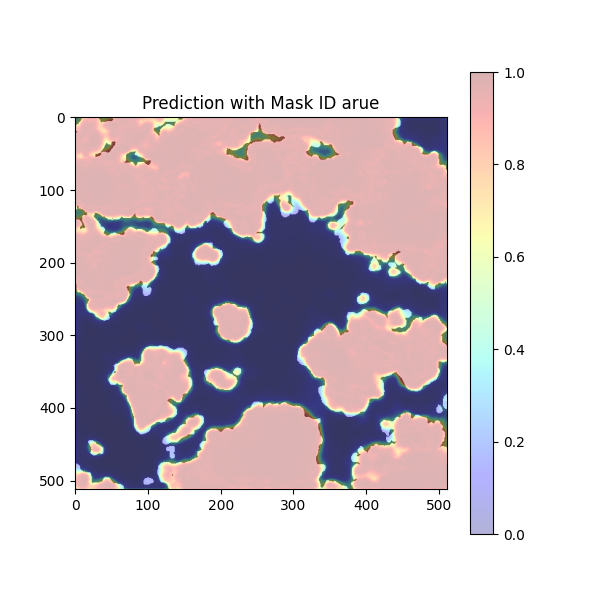
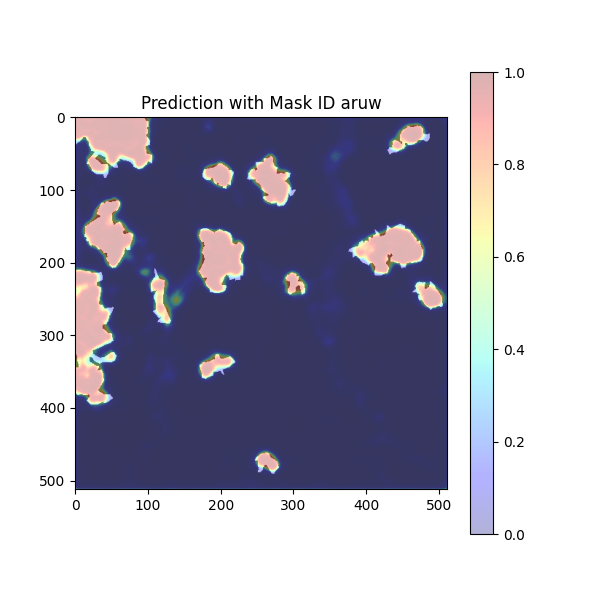
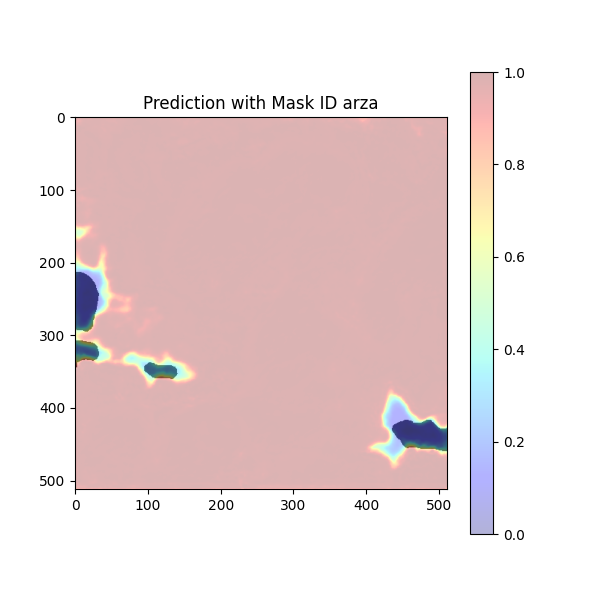
雲である白い領域のほとんどでヒートマップは赤く値が高くなっています。これで概ね、雲の領域が検知できているのが確認できます。
しかし、まだ検知仕切れてない部分もあります。それは可視光バンドだけの特徴量では判断の限界であるということです。さて、次ではその改善方法の1つをご紹介します。
衛星データによる精度向上
衛星データは複数のセンサーで取得したデータが利用できる関係で、複数のバンドの組み合わせという、いわゆる、バンド演算や単純に畳重することで真価を発揮します。今回の場合は近赤外バンド(B08)NIR を追加してモデルを学習してみます。
BATCH_SIZE, NUM_SAMPLE, NUM_RESTRECT = 8, 500, 2000
assert NUM_SAMPLE < NUM_RESTRECT
df = df[:NUM_RESTRECT]
df_train = df[:NUM_SAMPLE]
df_val = df[NUM_SAMPLE:]
train_dataset = CloudDataset(df_train, phase="train", transform=DataTransform(), bands=BANDS)
val_dataset = CloudDataset(df_val, phase="val", transform=DataTransform(), bands=BANDS)
print(f"train_dataset: {len(train_dataset)}", f"val_dataset: {len(val_dataset)}")
train_dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False)
dataloaders_dict = {"train": train_dataloader, "valid": val_dataloader}モデルの入力チャンネルも変更します。
in_chans = len(BANDS)
cfg = yaml.safe_load(f"""
model:
encoder: maxvit_tiny_tf_512.in1k
pretrained: False # Use True! False due to internet connection
decoder_channels: [256, 128, 64, 32, 16]
dropout: 0.0
in_chans: {in_chans}
""")
model = Model(cfg=cfg)
loss_fn = torch.nn.BCEWithLogitsLoss()
optimizer = torch.optim.AdamW([dict(params=model.parameters(), lr=1e-4), ])では再学習してみます。
EPOCHS = 20
best_score = 1E5
train_loss_nir = []
valid_loss_nir = []
model = model.cuda()
os.makedirs(PATH_OUTPUT, exist_ok=True)
for i in range(0, EPOCHS):
loss_epoch = []
for phase in ['train', 'valid']:
print(f'Epoch: {i} Phase {phase}')
for (img, anno) in tqdm(dataloaders_dict[phase],
total=len(dataloaders_dict[phase]),
leave=True,
dynamic_ncols=True):
img, anno = img.cuda(), anno.cuda()
if phase == 'train':
model.train()
output = model(img)
loss = loss_fn(output.squeeze(dim=1), anno.squeeze(dim=1))
loss.backward()
optimizer.step()
optimizer.zero_grad()
loss = loss.cpu().detach().numpy()
else:
with torch.no_grad():
model.eval()
output = model(img)
loss = loss_fn(output.squeeze(dim=1), anno.squeeze(dim=1))
loss = loss.cpu().numpy()
loss_epoch.append(loss)
if phase == 'train':
train_loss_nir.append(np.array(loss_epoch).mean())
else:
loss_mean = np.array(loss_epoch).mean()
valid_loss_nir.append(loss_mean)
if best_score > loss_mean:
best_score = loss_mean
torch.save(model, os.path.join(PATH_OUTPUT, 'best_model_nir.pth'))学習指標の推移を可視化します
plt.figure(figsize=(12, 4))
plt.title('Loss train + NIR')
plt.plot(np.array(train_loss_nir), label='train')
plt.plot(np.array(valid_loss_nir), label='valid')
plt.legend()
plt.savefig(f'{PATH_OUTPUT}/loss_nir.png')
plt.show();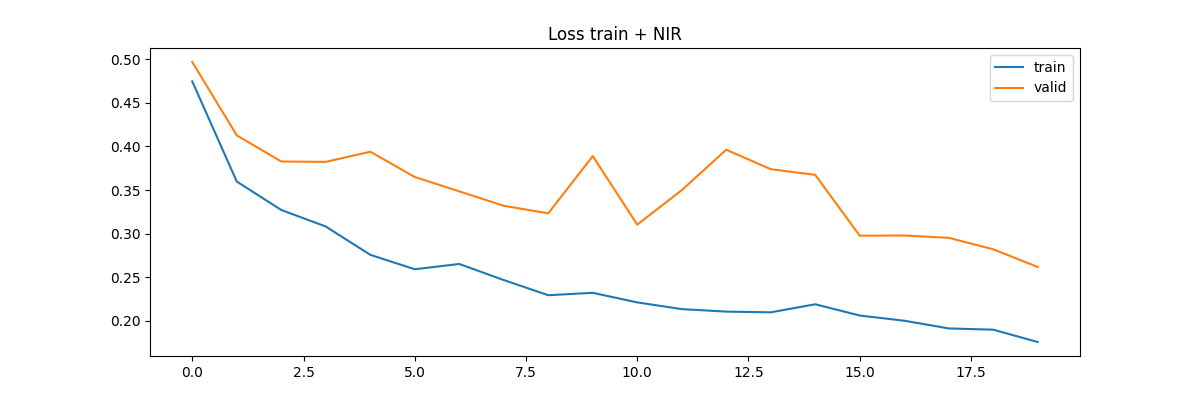
同様に検証データにおいても下がるように推移しています。
では、可視光のみの画像と比べてみましょう。
plt.figure(figsize=(12, 4))
plt.title('Compare Loss')
plt.plot(np.array(train_loss), label='train optical')
plt.plot(np.array(valid_loss), label='valid optical')
plt.plot(np.array(train_loss_nir), label='train nir')
plt.plot(np.array(valid_loss_nir), label='valid nir')
plt.legend()
plt.savefig(f'{PATH_OUTPUT}/loss_compare.png')
plt.show();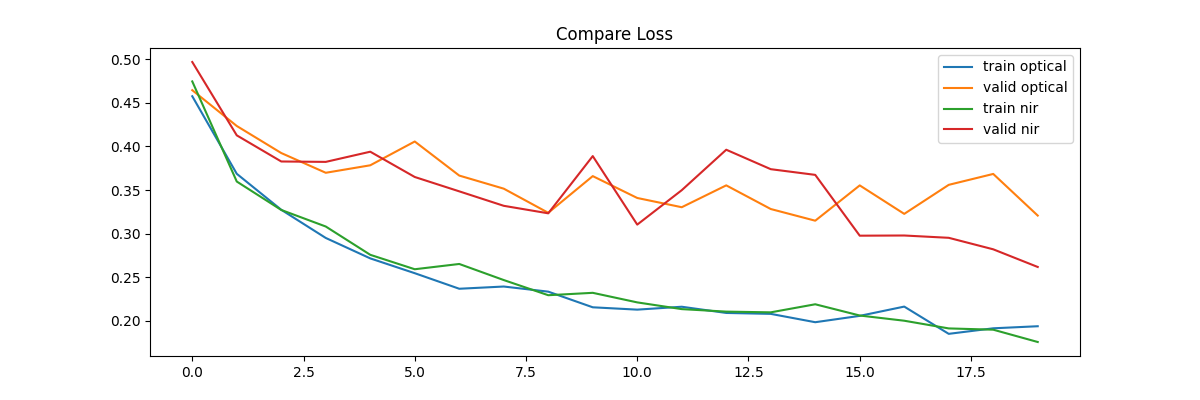
学習データでは変化はありませんが、検証データでは下がり気味に推移しています。汎化性能が向上したと思われます。これは近赤外波長のセンサーにも雲が映っていて判読に役に立つからでしょう。
最後に、被雲率の計算と共に可視化します。cover ratio が画像内の被雲率、HeatMap が予測した雲の確率です。赤いほど高い確率です。Cloud Label が教師データの雲の領域です。RGB画像は可視光波長の画像です。
test_dataset = CloudDataset(df_val, phase="val", transform=DataTransform(), bands=BANDS)
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
model = torch.load(f"{PATH_OUTPUT}/best_model_nir.pth")
model.eval()
for i, (img, anno) in tqdm(enumerate(test_dataloader)):
with torch.no_grad():
img, anno = img.cuda(), anno.cuda()
output = model(img)
output, anno = output.squeeze(dim=1), anno.squeeze(dim=1)
loss = loss_fn(output, anno)
preds = torch.sigmoid(output)
loss = loss.cpu().numpy()
print(f"Loss: {loss}")
for batch_i, (pred, an) in enumerate(zip(preds.cpu().numpy(), anno.cpu().numpy())):
cover_raito = np.sum(pred > 0.5) / (pred.shape[0] * pred.shape[1]) * 100
plt.figure(figsize=(18, 6))
plt.subplot(1, 4, 1)
_id = df_val['chip_id'].iloc[i*BATCH_SIZE + batch_i]
plt.title(f'Mask ID {_id} NIR (cover raito: {cover_raito:.1f}%)',
fontsize=14, fontweight='bold')
plt.imshow(an, alpha=0.7, cmap='gray', vmin=0, vmax=1)
plt.imshow(pred, cmap='jet', alpha=0.3, vmin=0, vmax=1)
plt.colorbar(shrink=0.7, label='Probability', orientation='horizontal')
plt.subplot(1, 4, 2)
plt.title(f'Predict Heatmap', fontsize=14, fontweight='bold')
plt.imshow(pred, cmap='jet', vmin=0, vmax=1)
plt.colorbar(shrink=0.7, label='Probability', orientation='horizontal')
plt.subplot(1, 4, 3)
plt.title(f'Cloud Label', fontsize=14, fontweight='bold')
plt.imshow(an, vmin=0, vmax=1)
plt.colorbar(shrink=0.7, label='Cloud: 1', orientation='horizontal')
plt.subplot(1, 4, 4)
plt.title(f'RGB: True Color', fontsize=14, fontweight='bold')
rgb = img[batch_i, :3, :,:].cpu().numpy().transpose(1, 2, 0)
rgb_8 = (np.clip(rgb, 500, 2500) / 2500 * 255).astype(np.uint8)
plt.imshow(rgb_8)
plt.colorbar(shrink=0.7, label='Value Range', orientation='horizontal')
plt.tight_layout()
plt.savefig(f"{PATH_OUTPUT}/predict_{_id}_nir.png")
plt.show();
break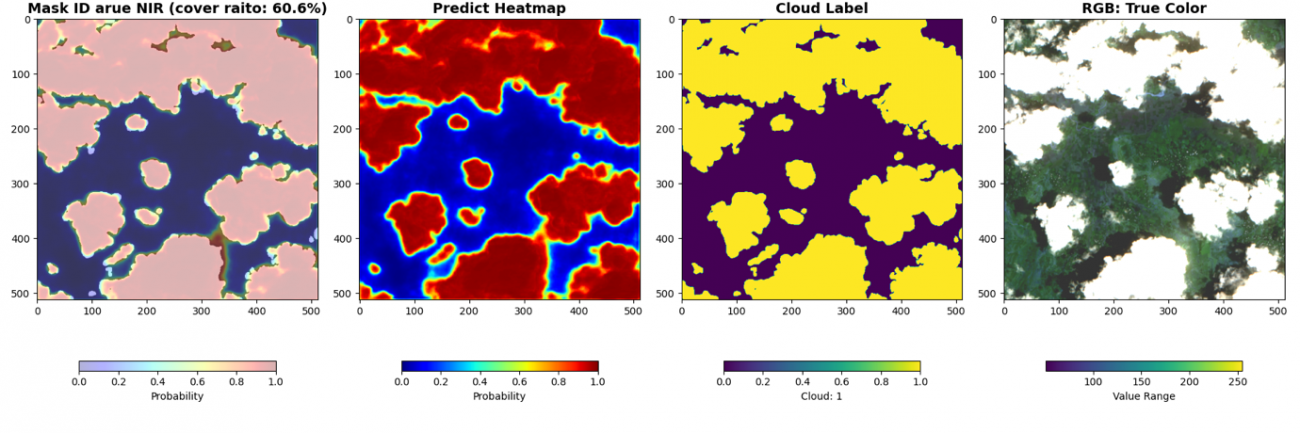
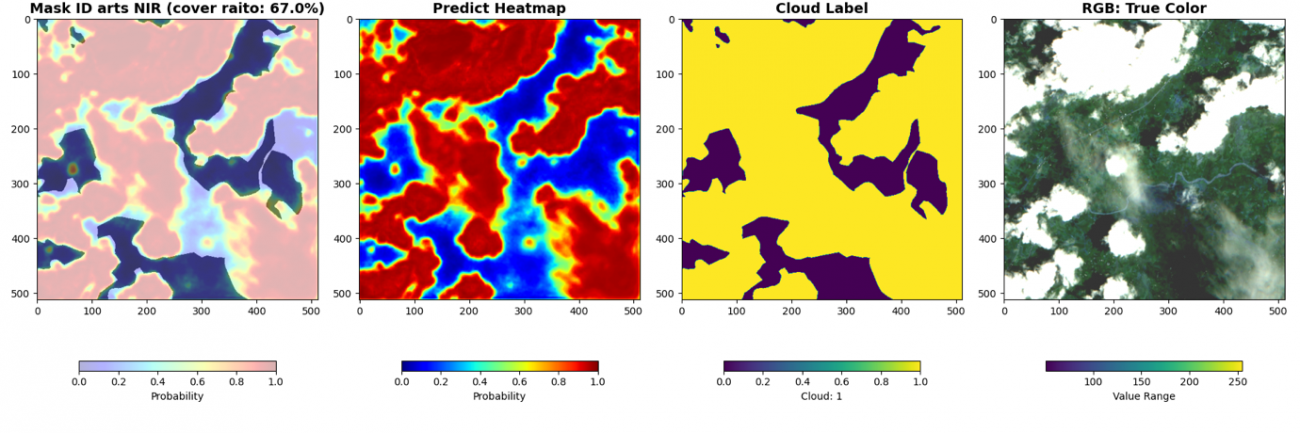
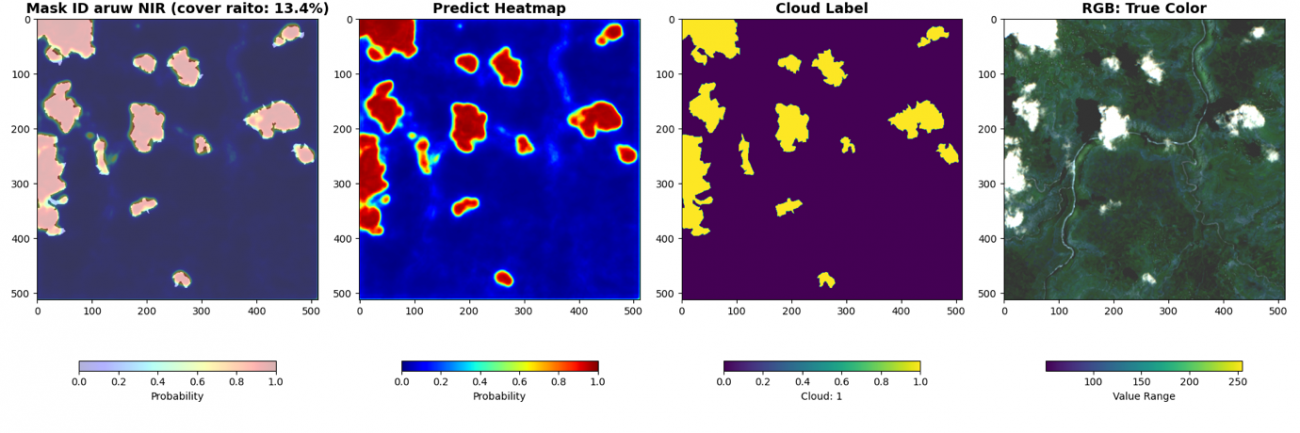
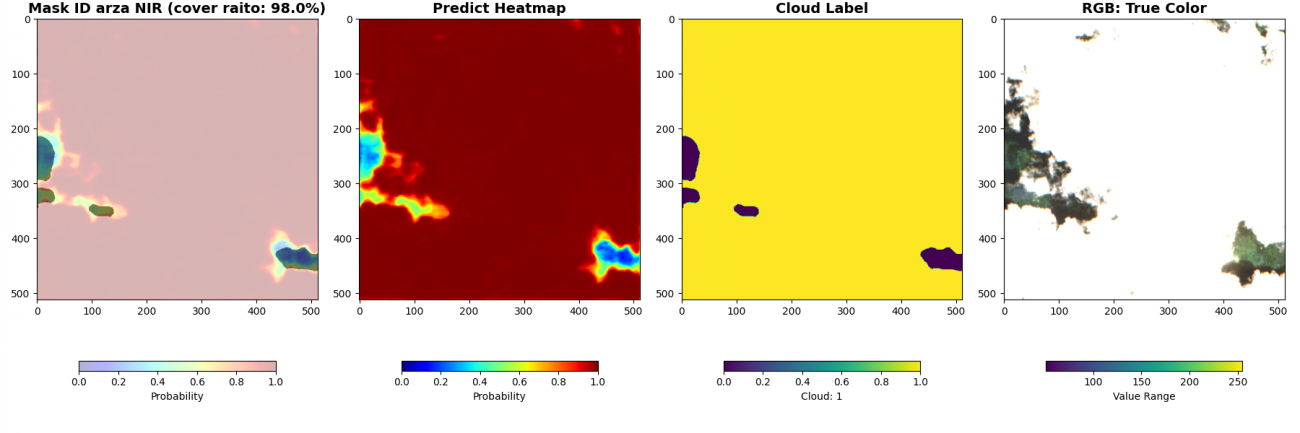
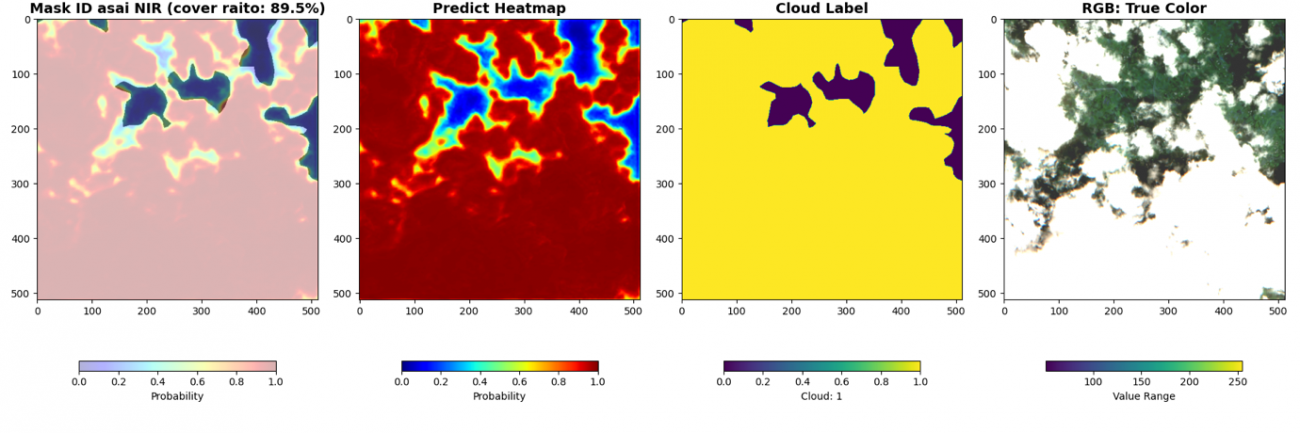
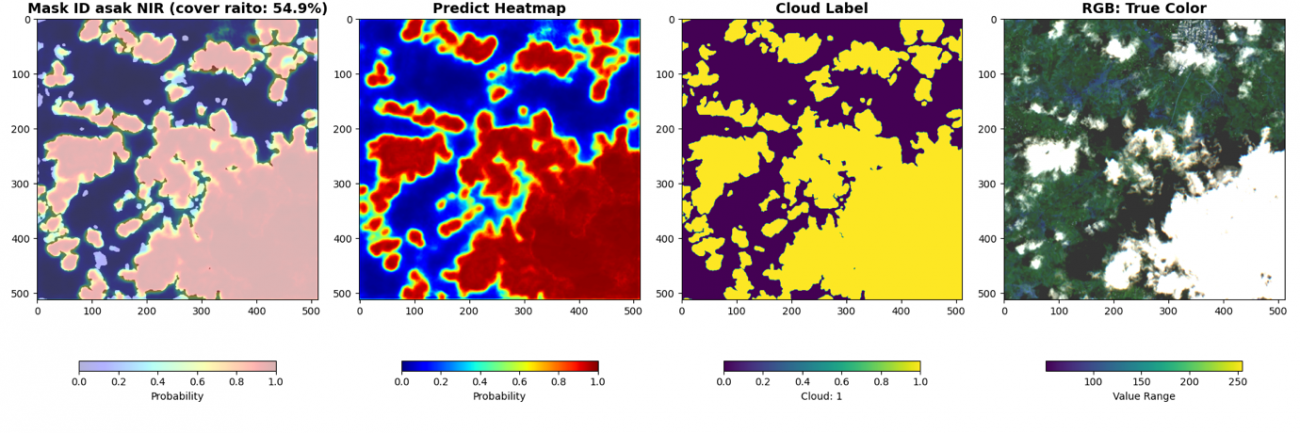
近赤外波長なしのモデルでは検知が曖昧であった薄い雲についても近赤外波長加えることで検知できています。雲は可視光波長以外でも周波数によっては反射していることが理由です。しかし、精度が良いというのは飽くまでこのデータセットの教師ラベルでの比較です。検証したい事にあった指標で判断しましょう。
このように異なるセンサーの特徴量を追加することで精度向上を図ったりするのが衛星データの楽しみの1つです。これは人間が生成した特徴量を追加するのも良いです。例えば、NDVI という植生指標やNDWI という水域指標などが挙げられます。
以下の Github では何種類もの指標が論文と共に記載していますので参考までにご覧ください。
・https://github.com/awesome-spectral-indices/awesome-spectral-indices
Github
コードは以下の宙畑の Github で公開しています。
・https://github.com/sorabatake/article_33451_cloud-detection
データの可視化
・https://github.com/sorabatake/article_33451_cloud-detection/blob/main/src/001_eda.ipynb
MaxViT
・https://github.com/sorabatake/article_33451_cloud-detection/blob/main/src/003_maxvit_unet.ipynb
雲検知のモデル
・https://github.com/sorabatake/article_33451_cloud-detection/blob/main/src/008_cloud_detection.ipynb
環境構築は以下です。
docker compose -f compose_cloud.yml up -d学習済みモデル
本記事で学習したモデルは以下で配布しています。ご自由にダウンロードしてご使用ください。
https://drive.google.com/drive/folders/1wwsQNTIEp5HIRomqFjNSgNvXLpzYdEWj
まとめ
本記事では、光学衛星の天敵である雲を検知して、被雲率の計算を行うメリットの説明と、実際に雲を検知して被雲率の計算をする方法、そして、複数のバンドを使って精度向上する方法を紹介しました。
GitHubでコードの共有と学習済みモデルの公開もしておりますので、ぜひお試しください。
